Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
「REALITY」・「DADAN」におけるデータ分析基盤の運用事例
Search
gree_tech
PRO
October 13, 2023
Technology
1.9k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
「REALITY」・「DADAN」におけるデータ分析基盤の運用事例
GREE Tech Conference 2023で発表された資料です。
https://techcon.gree.jp/2023/session/TrackA-5
gree_tech
PRO
October 13, 2023
More Decks by gree_tech
See All by gree_tech
我々はどう生きるか
gree_tech
PRO
0
4
変わるもの、変わらないもの :OSSアーキテクチャで実現する持続可能なシステム
gree_tech
PRO
0
5.1k
マネジメントに役立つ Google Cloud
gree_tech
PRO
0
72
今この時代に技術とどう向き合うべきか
gree_tech
PRO
3
2.8k
生成AIを開発組織にインストールするために: REALITYにおけるガバナンス・技術・文化へのアプローチ
gree_tech
PRO
0
470
安く・手軽に・現場発 既存資産を生かすSlack×AI検索Botの作り方
gree_tech
PRO
0
470
生成AIを安心して活用するために──「情報セキュリティガイドライン」策定とポイント
gree_tech
PRO
1
2.4k
あうもんと学ぶGenAIOps
gree_tech
PRO
0
590
MVP開発における生成AIの活用と導入事例
gree_tech
PRO
0
620
Other Decks in Technology
See All in Technology
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
31
26k
LangfuseによるLLMOps基盤の構築と活用事例
zozotech
PRO
1
190
カメラ×AIで挑む「ホワイト物流」― 車両管理、自動化の壁と突破口【SORACOM Discovery 2026】
soracom
PRO
0
180
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
340
A Bag-of-Documents Model for Query Specificity
dtunkelang
0
180
システム監視入門
grimoh
5
770
NYC Summit 2026 における Amazon Bedrock AgentCore のアップデート
ren8k
3
280
【5分でわかる】セーフィー エンジニア向け会社紹介
safie_recruit
0
53k
書籍セキュアAPIについて
riiimparm
0
390
PLaMo 3.0 Primeの構造化出力サポート
pfn
PRO
0
140
AIQAのナレッジ構築について
qatonchan
1
130
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
690
Featured
See All Featured
Mobile First: as difficult as doing things right
swwweet
225
10k
The Language of Interfaces
destraynor
162
27k
What's in a price? How to price your products and services
michaelherold
247
13k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1.1k
Making the Leap to Tech Lead
cromwellryan
135
10k
30 Presentation Tips
portentint
PRO
1
360
Ruling the World: When Life Gets Gamed
codingconduct
0
290
The untapped power of vector embeddings
frankvandijk
2
1.8k
Building AI with AI
inesmontani
PRO
1
1.1k
Embracing the Ebb and Flow
colly
88
5.1k
The Cult of Friendly URLs
andyhume
79
7k
Prompt Engineering for Job Search
mfonobong
0
390
Transcript
「REALITY」・「DADAN」におけるデータ 分析基盤の運用事例 グリー株式会社 データエンジニア 熱田 慶人
自己紹介 • 名前 ◦ 熱田 慶人 (Yoshito Atsuta) • 所属
◦ 開発本部 ▪ データテクノロジー部 • データエンジニアリングチーム • 略歴 ◦ 2022年4月新卒入社 • 担当業務 ◦ データ分析基盤開発・運用 ◦ 機械学習基盤開発 2
アジェンダ • REALITYとDADANの紹介 • 分析基盤構築背景 • REALITYの分析基盤 ◦ 分析システム構成 ◦
運用中に解決した課題 • DADANの分析基盤 ◦ 分析システム構成 ◦ レコメンドシステム構成 ◦ 運用中に解決した課題 • まとめ 3
アジェンダ • REALITYとDADANの紹介 • 分析基盤構築背景 • REALITYの分析基盤 ◦ 分析システム構成 ◦
運用中に解決した課題 • DADANの分析基盤 ◦ 分析システム構成 ◦ レコメンドシステム構成 ◦ 運用中に解決した課題 • まとめ 4
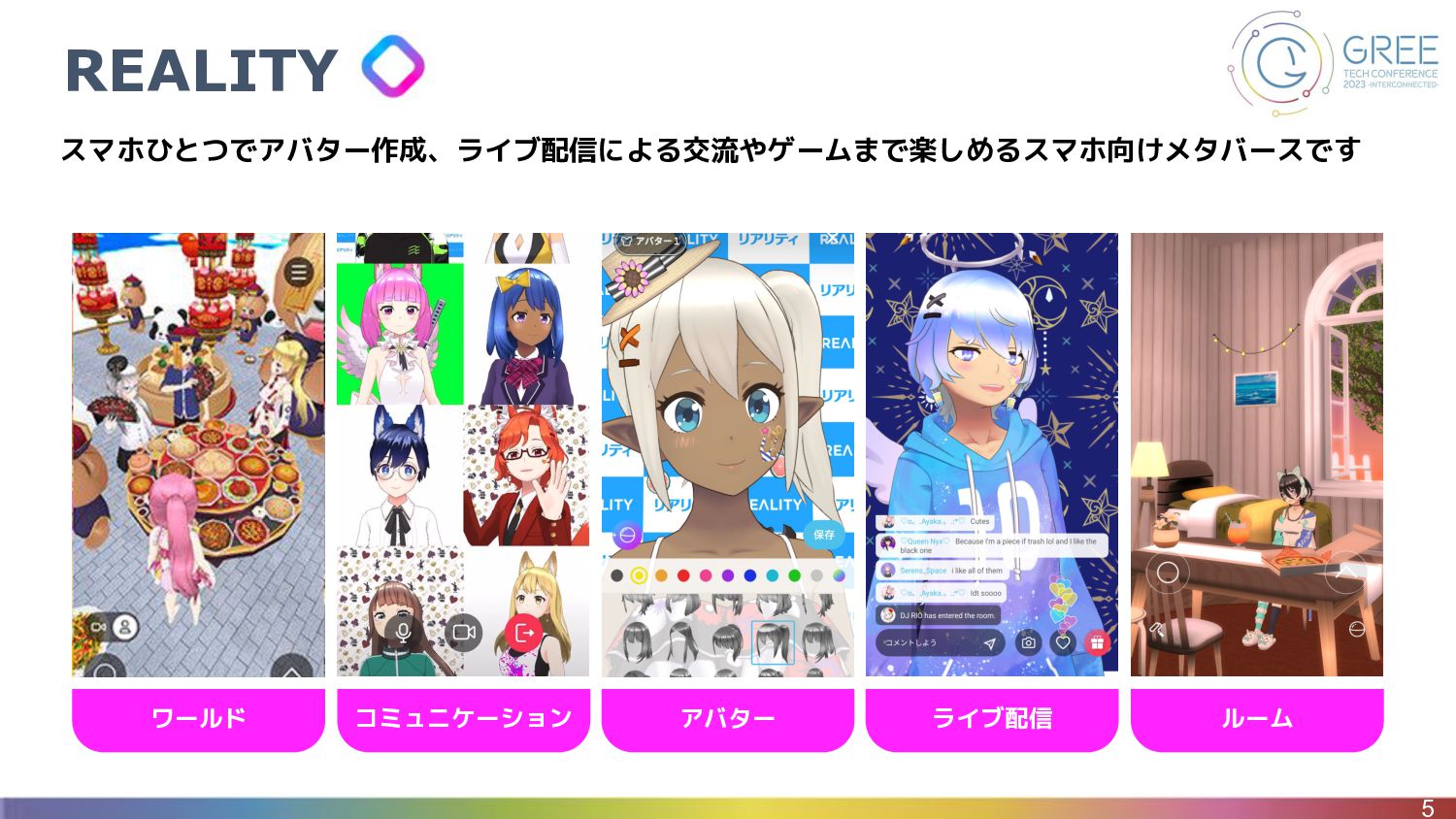
REALITY 5 スマホひとつでアバター作成、ライブ配信による交流やゲームまで楽しめるスマホ向けメタバースです アバター ライブ配信 コミュニケーション ルーム ワールド
DADAN 6 幅広いジャンルの漫画・コミックを掲載している総合マンガプラットフォームです
アジェンダ • REALITYとDADANの紹介 • 分析基盤構築背景 • REALITYの分析基盤 ◦ 分析システム構成 ◦
運用中に解決した課題 • DADANの分析基盤 ◦ 分析システム構成 ◦ レコメンドシステム構成 ◦ 運用中に解決した課題 • まとめ 7
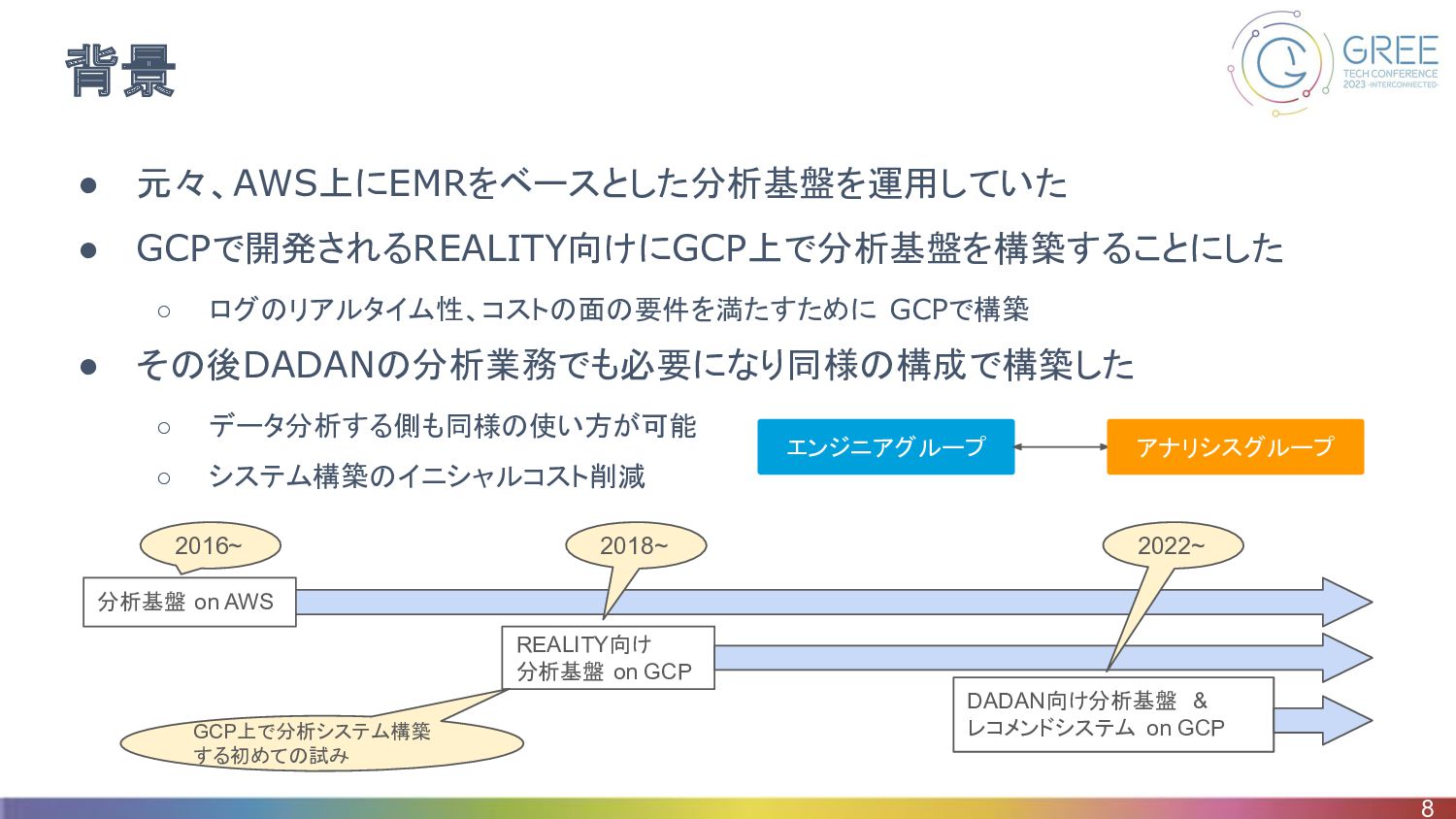
背景 • 元々、AWS上にEMRをベースとした分析基盤を運用していた • GCPで開発されるREALITY向けにGCP上で分析基盤を構築することにした ◦ ログのリアルタイム性、コストの面の要件を満たすために GCPで構築 • その後DADANの分析業務でも必要になり同様の構成で構築した
◦ データ分析する側も同様の使い方が可能 ◦ システム構築のイニシャルコスト削減 8 分析基盤 on AWS REALITY向け 分析基盤 on GCP DADAN向け分析基盤 & レコメンドシステム on GCP 2016~ 2018~ 2022~ GCP上で分析システム構築 する初めての試み エンジニアグループ アナリシスグループ
アジェンダ • REALITYとDADANの紹介 • 分析基盤構築背景 • REALITYの分析基盤 ◦ 分析システム構成 ◦
運用中に解決した課題 • DADANの分析基盤 ◦ 分析システム構成 ◦ レコメンドシステム構成 ◦ 運用中に解決した課題 • まとめ 9
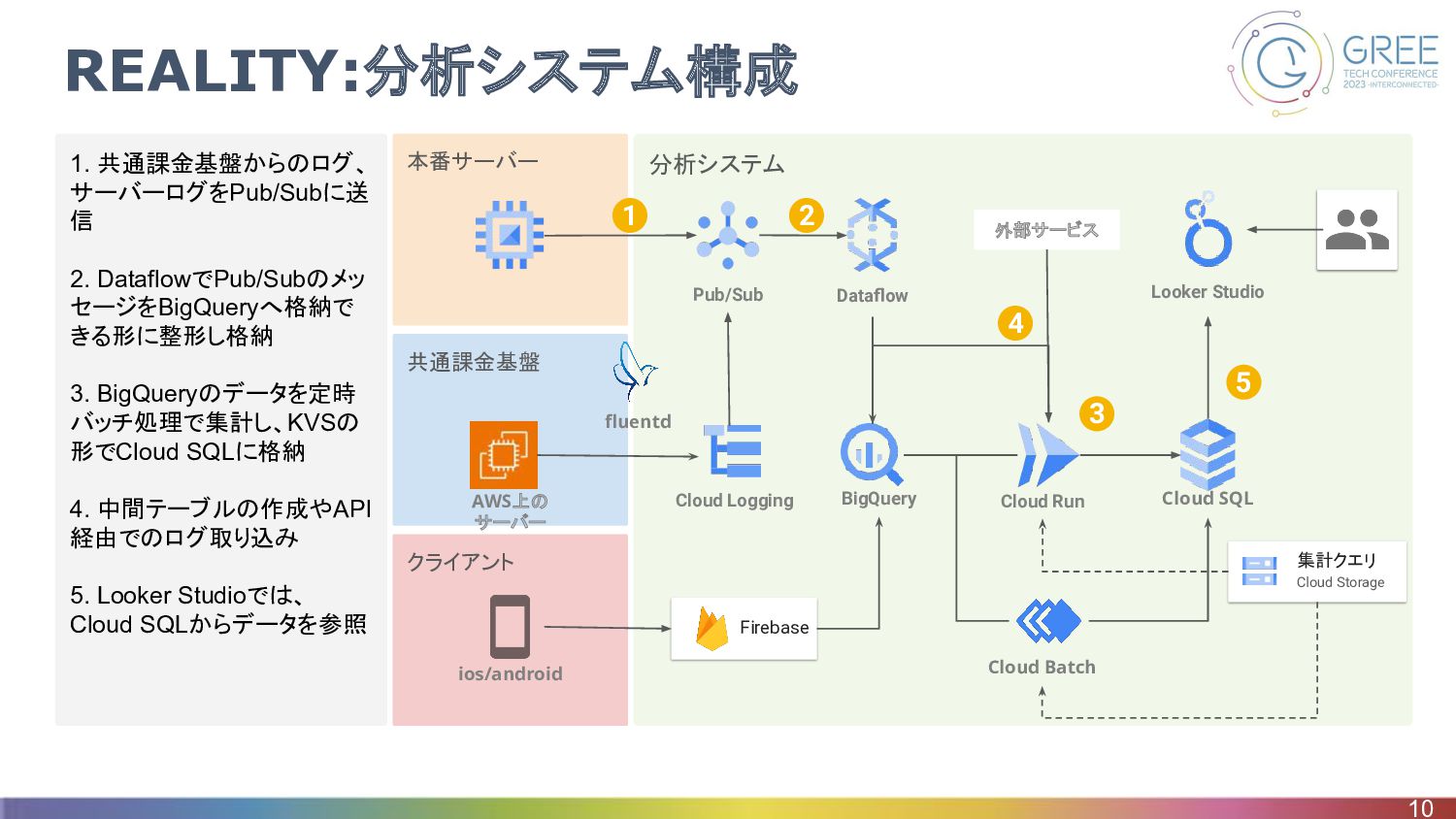
クライアント 共通課金基盤 分析システム 本番サーバー 1. 共通課金基盤からのログ、 サーバーログをPub/Subに送 信 2. DataflowでPub/Subのメッ
セージをBigQueryへ格納で きる形に整形し格納 3. BigQueryのデータを定時 バッチ処理で集計し、KVSの 形でCloud SQLに格納 4. 中間テーブルの作成やAPI 経由でのログ取り込み 5. Looker Studioでは、 Cloud SQLからデータを参照 REALITY:分析システム構成 10 Firebase BigQuery Pub/Sub Dataflow Cloud Run Cloud SQL Cloud Batch Looker Studio Cloud Logging ios/android fluentd 集計クエリ Cloud Storage 1 2 5 AWS上の サーバー 外部サービス 4 3
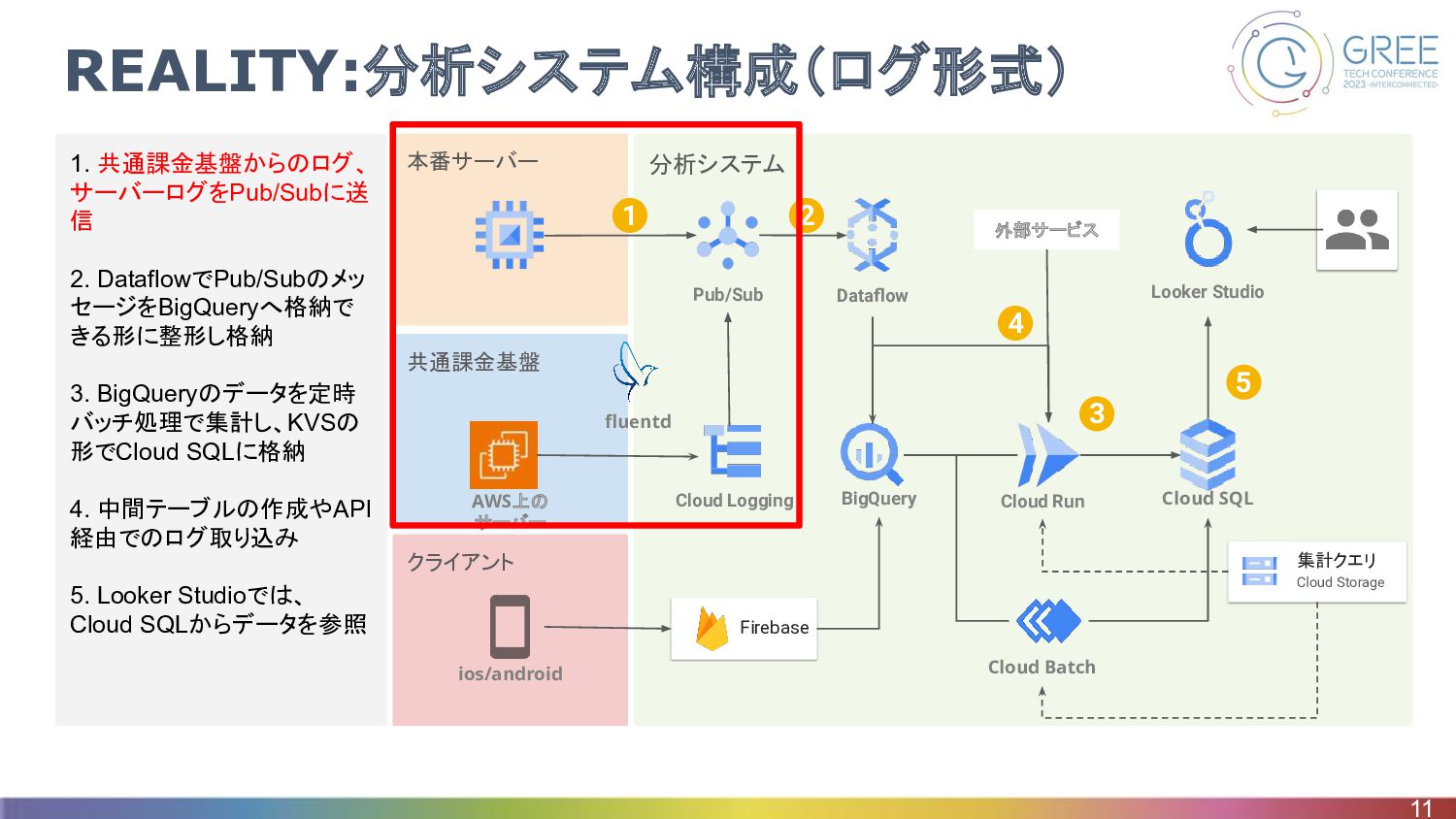
クライアント 共通課金基盤 分析システム 本番サーバー 1. 共通課金基盤からのログ、 サーバーログをPub/Subに送 信 2. DataflowでPub/Subのメッ
セージをBigQueryへ格納で きる形に整形し格納 3. BigQueryのデータを定時 バッチ処理で集計し、KVSの 形でCloud SQLに格納 4. 中間テーブルの作成やAPI 経由でのログ取り込み 5. Looker Studioでは、 Cloud SQLからデータを参照 REALITY:分析システム構成(ログ形式) 11 Firebase BigQuery Pub/Sub Dataflow Cloud Run Cloud SQL Cloud Batch Looker Studio Cloud Logging ios/android fluentd 集計クエリ Cloud Storage 1 2 5 AWS上の サーバー 外部サービス 4 3
REALITY:分析システム構成(ログ形式) • PubSubとは ◦ リアルタイムデータおよびイベントストリーム処理を行うサービス ◦ 同様のサービスとして AWSのKinesisやApache Kafkaがある •
出力フォーマットはjson ◦ 宛先テーブルとテーブルに格納する値を jsonとしてPub/Subにpush ◦ ログ定義は、分析担当のアナリシスチームが行う • 共通課金基盤からのFluentdでCloud Loggingに出力 ◦ 共通課金基盤はAWS上に構築されているため ◦ ログルーターで対象ログを Pub/Subにpush 12
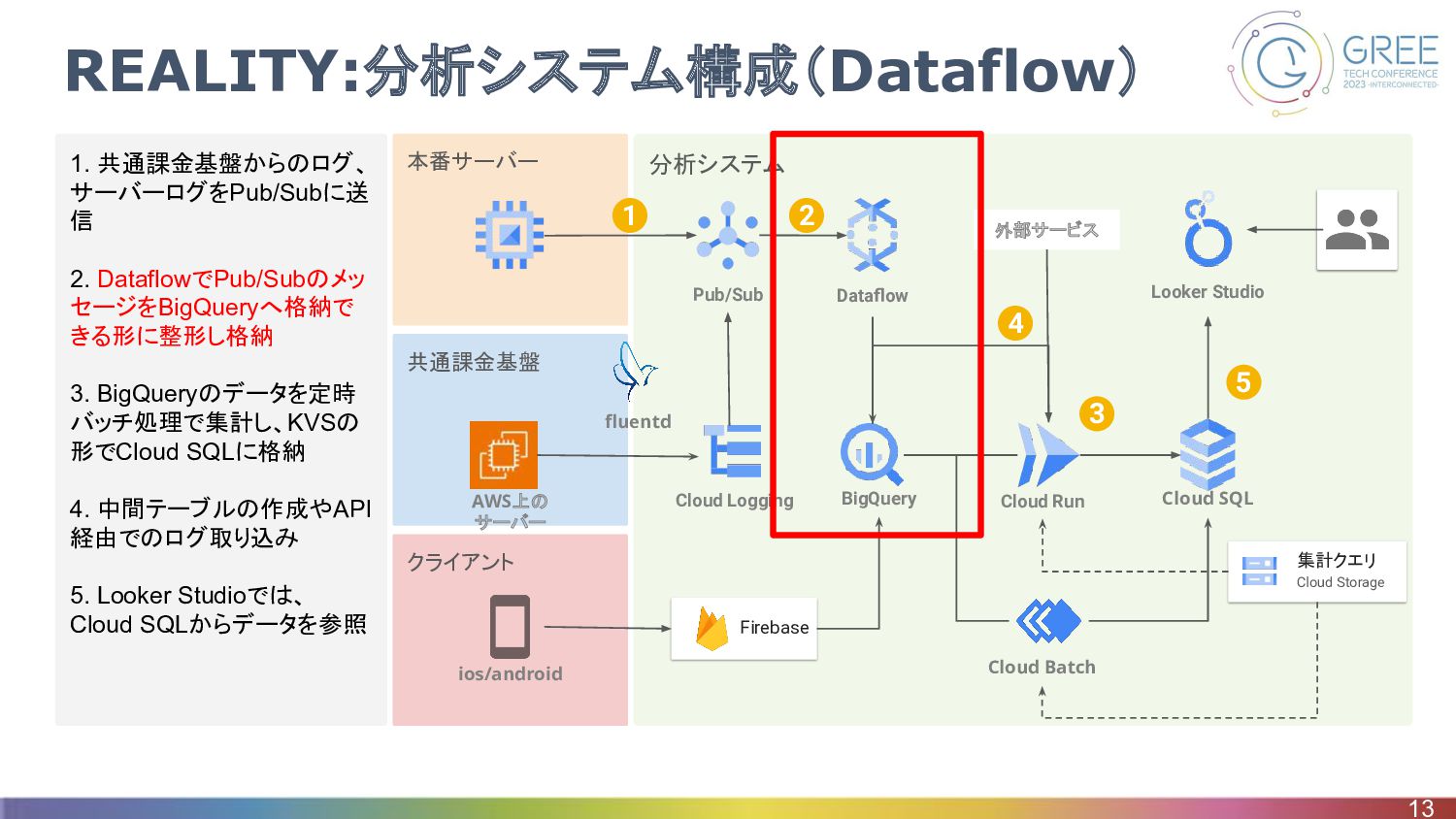
クライアント 共通課金基盤 分析システム 本番サーバー 1. 共通課金基盤からのログ、 サーバーログをPub/Subに送 信 2. DataflowでPub/Subのメッ
セージをBigQueryへ格納で きる形に整形し格納 3. BigQueryのデータを定時 バッチ処理で集計し、KVSの 形でCloud SQLに格納 4. 中間テーブルの作成やAPI 経由でのログ取り込み 5. Looker Studioでは、 Cloud SQLからデータを参照 REALITY:分析システム構成(Dataflow) 13 Firebase BigQuery Pub/Sub Dataflow Cloud Run Cloud SQL Cloud Batch Looker Studio Cloud Logging ios/android fluentd 集計クエリ Cloud Storage 1 2 5 AWS上の サーバー 外部サービス 4 3
REALITY:分析システム構成(Dataflow) • Dataflowとは ◦ ストリーミングデータおよびバッチデータの処理を効率的に行うための GCPのマネージドなETLサー ビス • Dataflow選定理由 ◦
GCEより高くなるが、Streaming Engineを使うことでスケールしやすい形にできる ◦ Dynamic Destinationsクラスを使うことで、動的に宛先テーブルを変更できる ▪ プロダクト側が自由にテーブルを増やしても、ログの宛先テーブル情報をもとに挿入先のテー ブルが決定されるので、 Dataflow側の修正が不要 • 使用言語 ◦ Java ▪ 使える機能、ドキュメントが豊富だったため選択 14
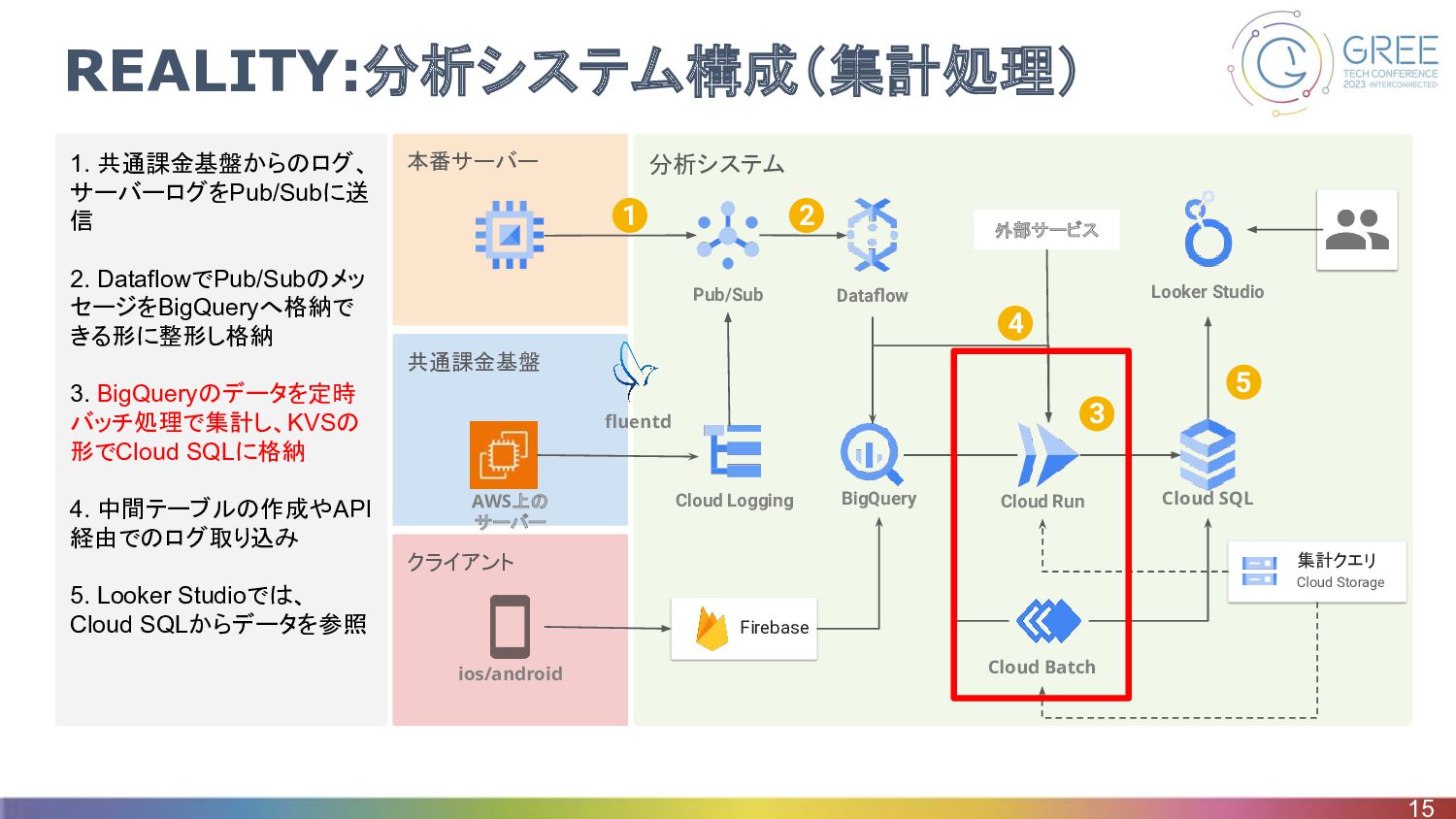
クライアント 共通課金基盤 分析システム 本番サーバー 1. 共通課金基盤からのログ、 サーバーログをPub/Subに送 信 2. DataflowでPub/Subのメッ
セージをBigQueryへ格納で きる形に整形し格納 3. BigQueryのデータを定時 バッチ処理で集計し、KVSの 形でCloud SQLに格納 4. 中間テーブルの作成やAPI 経由でのログ取り込み 5. Looker Studioでは、 Cloud SQLからデータを参照 REALITY:分析システム構成(集計処理) 15 Firebase BigQuery Pub/Sub Dataflow Cloud Run Cloud SQL Cloud Batch Looker Studio Cloud Logging ios/android fluentd 集計クエリ Cloud Storage 1 2 5 AWS上の サーバー 外部サービス 4 3
REALITY:分析システム構成(集計処理) • Cloud Run とは ◦ コンテナベースのアプリケーションをサーバーレスでスケーラブルに実行するマネージドサービス • Cloud Batch
とは ◦ バッチ処理ワークロードを実行するフルマネージドサービス ◦ 一時的にGCEインスタンスを建てて処理を実行できる • 選定理由 ◦ コンテナイメージを使い回せる ◦ 実行時間が長いものと短いもので使い分けができる • 使用言語 ◦ Typescript ▪ 他のプロジェクトでも使用されているため 16
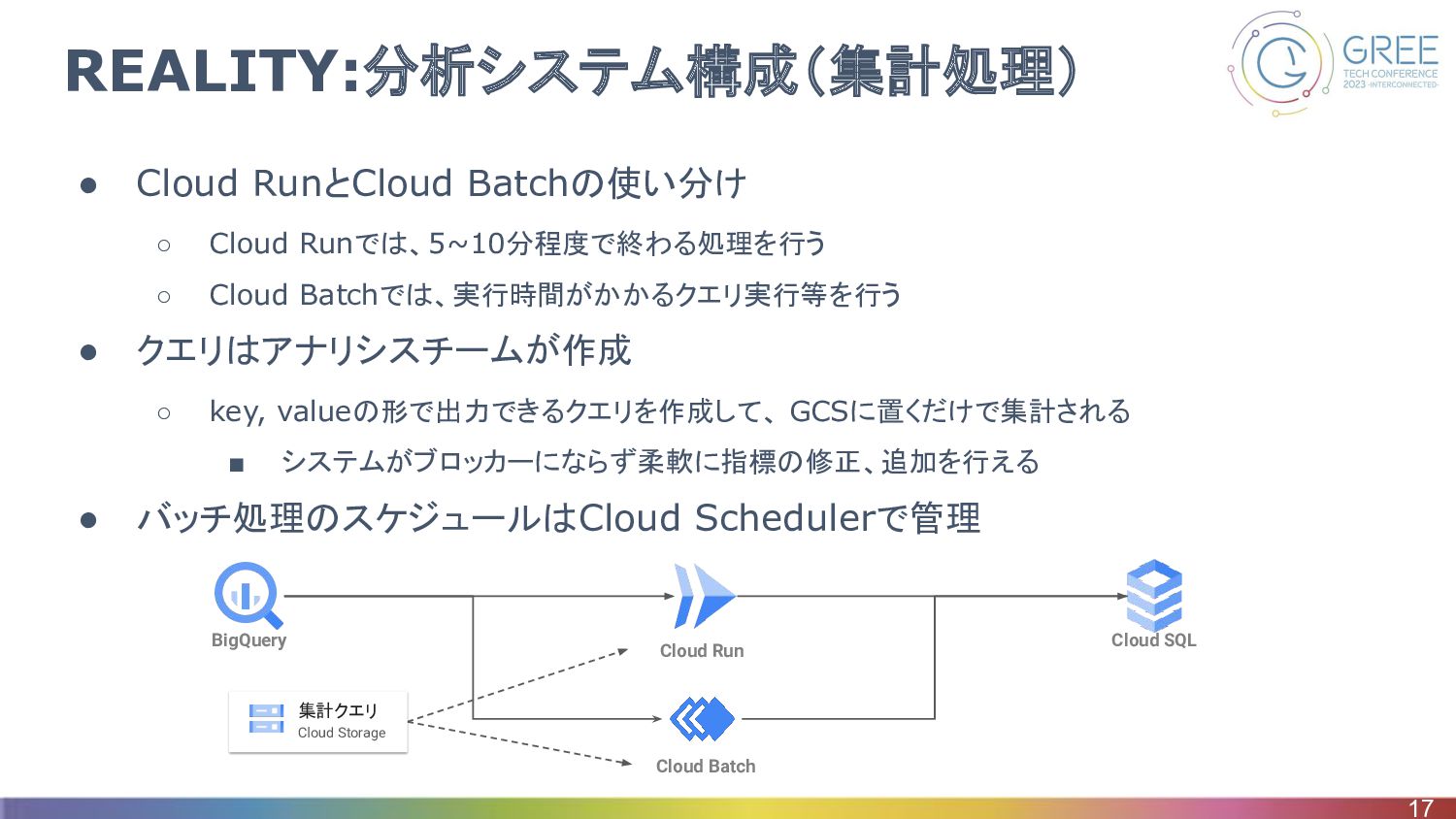
REALITY:分析システム構成(集計処理) • Cloud RunとCloud Batchの使い分け ◦ Cloud Runでは、5~10分程度で終わる処理を行う ◦ Cloud
Batchでは、実行時間がかかるクエリ実行等を行う • クエリはアナリシスチームが作成 ◦ key, valueの形で出力できるクエリを作成して、 GCSに置くだけで集計される ▪ システムがブロッカーにならず柔軟に指標の修正、追加を行える • バッチ処理のスケジュールはCloud Schedulerで管理 17 Cloud SQL BigQuery Cloud Run Cloud Batch 集計クエリ Cloud Storage
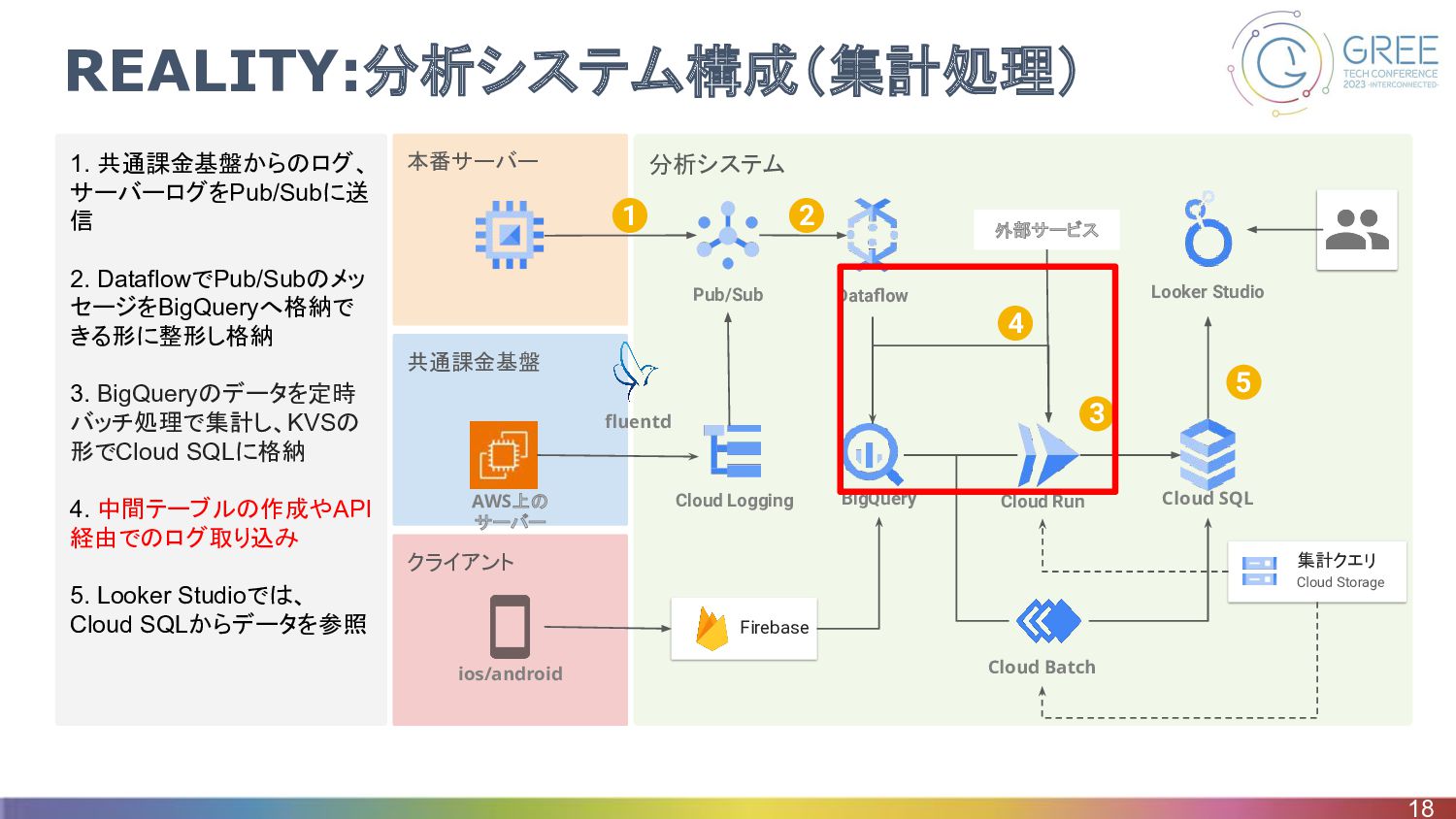
クライアント 共通課金基盤 分析システム 本番サーバー 1. 共通課金基盤からのログ、 サーバーログをPub/Subに送 信 2. DataflowでPub/Subのメッ
セージをBigQueryへ格納で きる形に整形し格納 3. BigQueryのデータを定時 バッチ処理で集計し、KVSの 形でCloud SQLに格納 4. 中間テーブルの作成やAPI 経由でのログ取り込み 5. Looker Studioでは、 Cloud SQLからデータを参照 REALITY:分析システム構成(集計処理) 18 Firebase BigQuery Pub/Sub Dataflow Cloud Run Cloud SQL Cloud Batch Looker Studio Cloud Logging ios/android fluentd 集計クエリ Cloud Storage 1 2 5 AWS上の サーバー 外部サービス 4 3
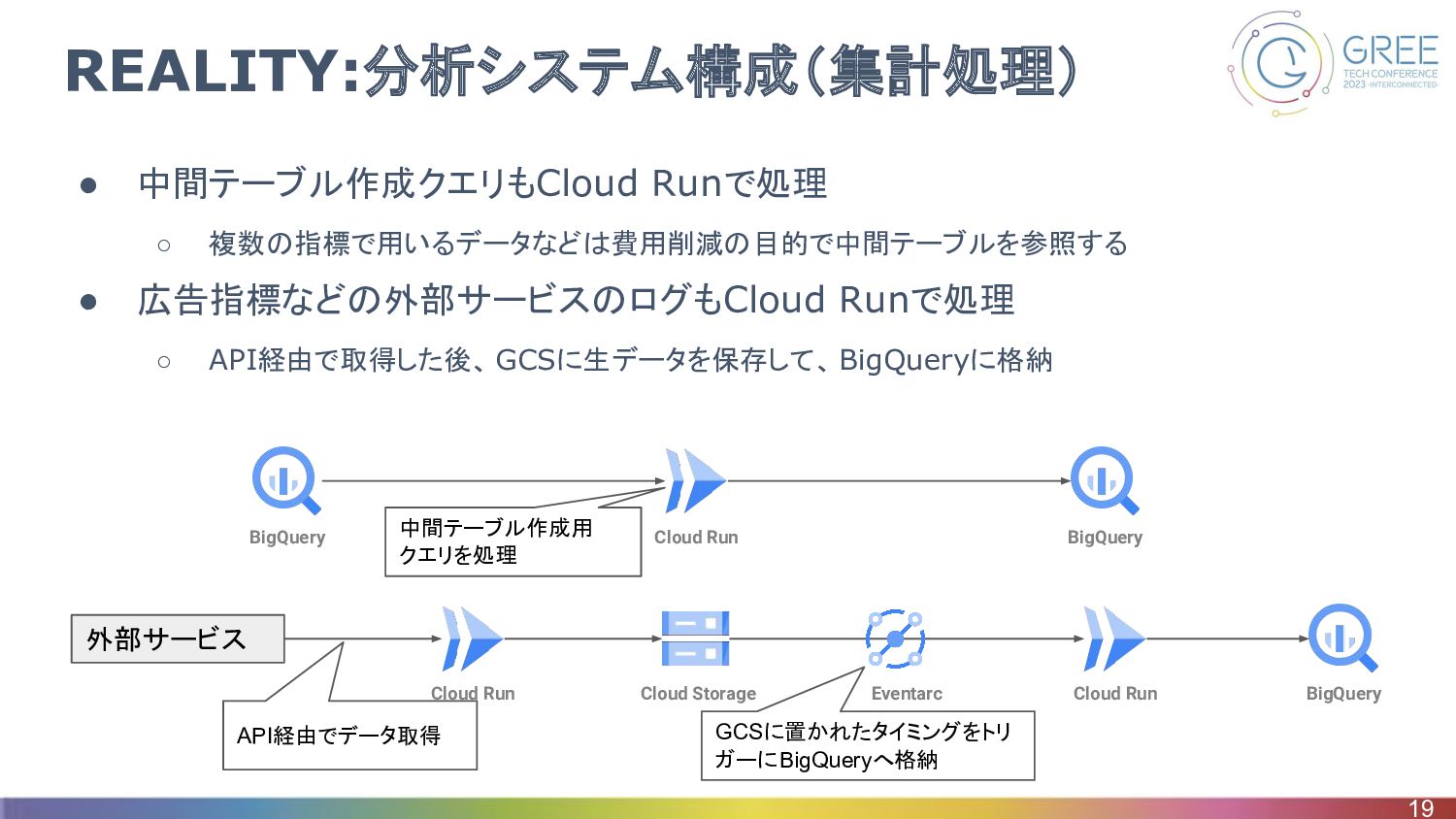
REALITY:分析システム構成(集計処理) • 中間テーブル作成クエリもCloud Runで処理 ◦ 複数の指標で用いるデータなどは費用削減の目的で中間テーブルを参照する • 広告指標などの外部サービスのログもCloud Runで処理 ◦
API経由で取得した後、GCSに生データを保存して、 BigQueryに格納 19 外部サービス Cloud Storage Cloud Run Eventarc Cloud Run BigQuery API経由でデータ取得 GCSに置かれたタイミングをトリ ガーにBigQueryへ格納 Cloud Run BigQuery BigQuery 中間テーブル作成用 クエリを処理
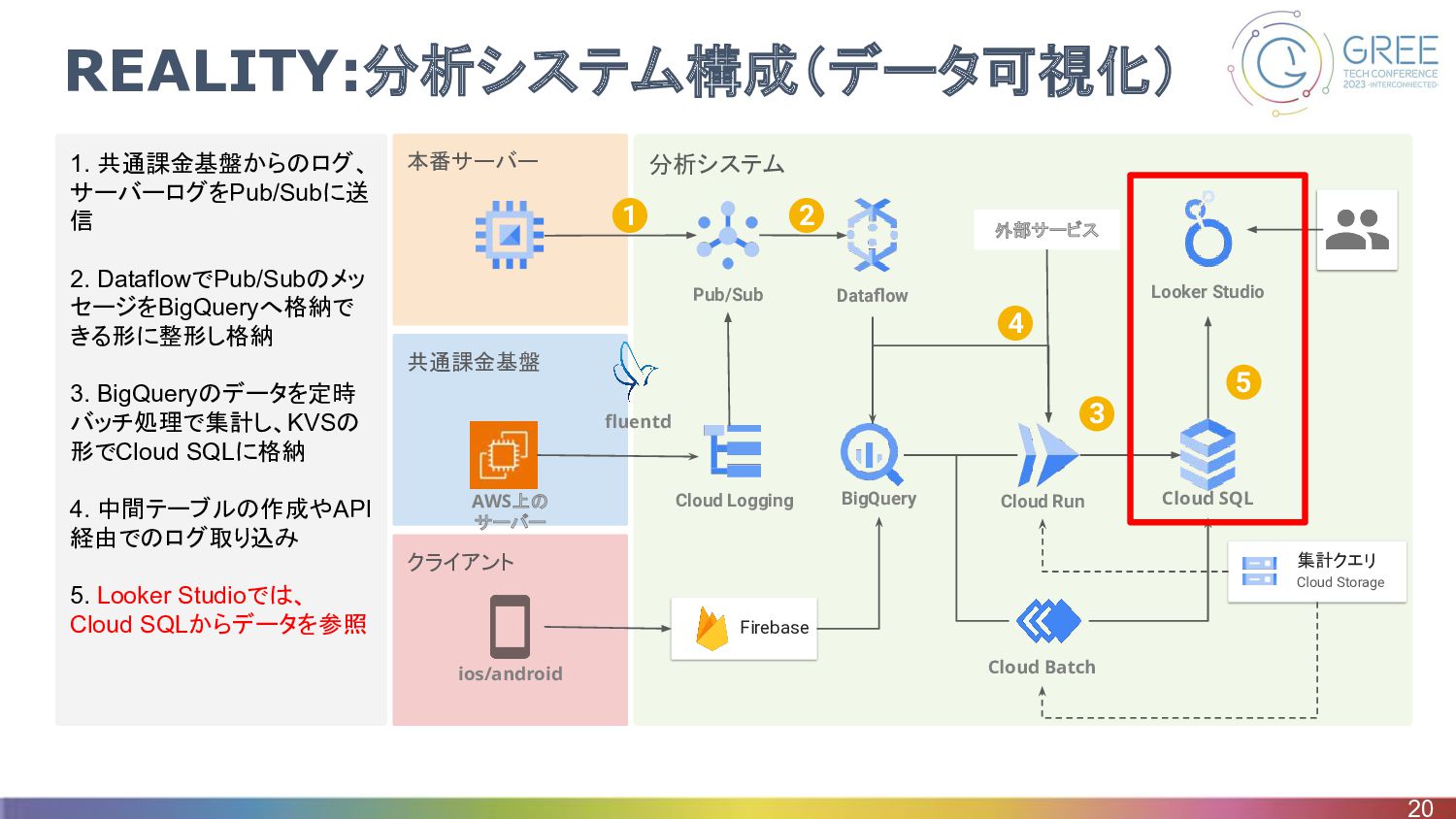
クライアント 共通課金基盤 分析システム 本番サーバー 1. 共通課金基盤からのログ、 サーバーログをPub/Subに送 信 2. DataflowでPub/Subのメッ
セージをBigQueryへ格納で きる形に整形し格納 3. BigQueryのデータを定時 バッチ処理で集計し、KVSの 形でCloud SQLに格納 4. 中間テーブルの作成やAPI 経由でのログ取り込み 5. Looker Studioでは、 Cloud SQLからデータを参照 REALITY:分析システム構成(データ可視化) 20 Firebase BigQuery Pub/Sub Dataflow Cloud Run Cloud SQL Cloud Batch Looker Studio Cloud Logging ios/android fluentd 集計クエリ Cloud Storage 1 2 5 AWS上の サーバー 外部サービス 4 3
REALITY:分析システム構成(データ可視化) • Looker StudioのCloud SQL連携でダッシュボードに可視化 ◦ 他のプロジェクトでも利用経験があったので採用 ◦ ストリーミングバッファにデータが含まれる場合は、キャッシュが利用できないので、 Cloud
SQLを 可視化の間に挟んでいる • ダッシュボードに表示している一部の値はSlackにも毎日通知 ◦ Slack通知させたい値をCloud SQLから抽出するクエリを GCSに配置して、Cloud Run上で実行 しSlackに通知 ◦ 通知内容をアナリシスチームが自由に変更可能 21 クエリ Cloud Storage Cloud SQL Cloud Run Slack
REALITY:分析システム構成(CI/CD/CM) 22 • CI/CD周りはCloud Buildを採用 ◦ イメージのプッシュと Cloud Runへのデプロイまで行う ◦
Cloud Batchはプッシュされたイメージを使う • データ取り込みの障害検知はCloud Monitoring ◦ 影響範囲が大きいDataflowのエラーはPager Duty ◦ 集計処理など、再実行すれば正しくなるものは、 slack通知 Cloud Run Cloud Batch Container Registry Cloud Build GitHub Push Build image & Push Deploy Pull
アジェンダ • REALITYとDADANの紹介 • 分析基盤構築背景 • REALITYの分析基盤 ◦ 分析システム構成 ◦
運用中に解決した課題 • DADANの分析基盤 ◦ 分析システム構成 ◦ レコメンドシステム構成 ◦ 運用中に解決した課題 • まとめ 23
REALITY:運用中に解決した課題1 • 課題 ◦ Cloud Runを使う前は、Cloud Functionsで集計処理を行っていた ◦ 長時間の処理や高負荷の集計が必要な場面で、Cloud Functionsの実行時間制限が制約になった
▪ 集計する指標や外部サービスからのログ取得の実行時間がサービス成長と共に増加した • 解決策 ◦ 長時間実行と実行スケジュールの増加へのスケーリングの要件を満たすために Cloud Functionsから Cloud Runへの移行で解決 ▪ コンテナベースの実行環境なため、さらに長時間の実行が必要になった場合、制限時間やリソー スの制限が緩いCloud Run JobやCloud Batch等のサービスに移行しやすくなった ◦ 複数のトリガーを設定できるため、同じコードを2つデプロイする必要がなくなった 24
REALITY:運用中に解決した課題2 • 課題 ◦ 新しい指標の追加における過去データの再集計がエンジニアにしかできない状況だった ▪ 長期間の再集計となると Cloud FunctionsやCloud Runでの実行時間制限を超えてしまう
ので、手元で実行する必要があった ▪ 実行環境をエンジニアしか用意できていなかった • 解決策 ◦ コードをパッケージ化、認証や Cloud SQL Proxyを設定する部分はスクリプト化して、エンジニア 以外がコードをCloud shellなどで実行できるようにした ▪ 実行したいクエリが入っているディレクトリと再集計する期間を指定するだけで再集計できる ようになった ▪ GCEに再集計環境を用意したが、複数人で利用する際に問題があった 25
REALITY:運用中に解決した課題3 • 課題 ◦ インフラ構成がIaC化できていなかった ▪ 引き継ぎコストが高かった ▪ 少人数運用のため、設定の変更等の操作確認作業がしにくかった •
解決策 ◦ Terraformで既存のインフラ構成をすべて IaC化 ▪ GoogleのTerraform使用におけるベストプラクティスに従って IaC化 ◦ 設定の変更等のコストがコードレビューのみに削減できた ▪ バッチスケジュールの追加も Cronを書き足すだけの状態にして、すべてのスケジュールで同 じ設定が適用されるようにした ▪ サービスアカウントの権限周りの管理コストも削減 26
アジェンダ • REALITYとDADANの紹介 • 分析基盤構築背景 • REALITYの分析基盤 ◦ 分析システム構成 ◦
運用中に解決した課題 • DADANの分析基盤 ◦ 分析システム構成 ◦ レコメンドシステム構成 ◦ 運用中に解決した課題 • まとめ 27
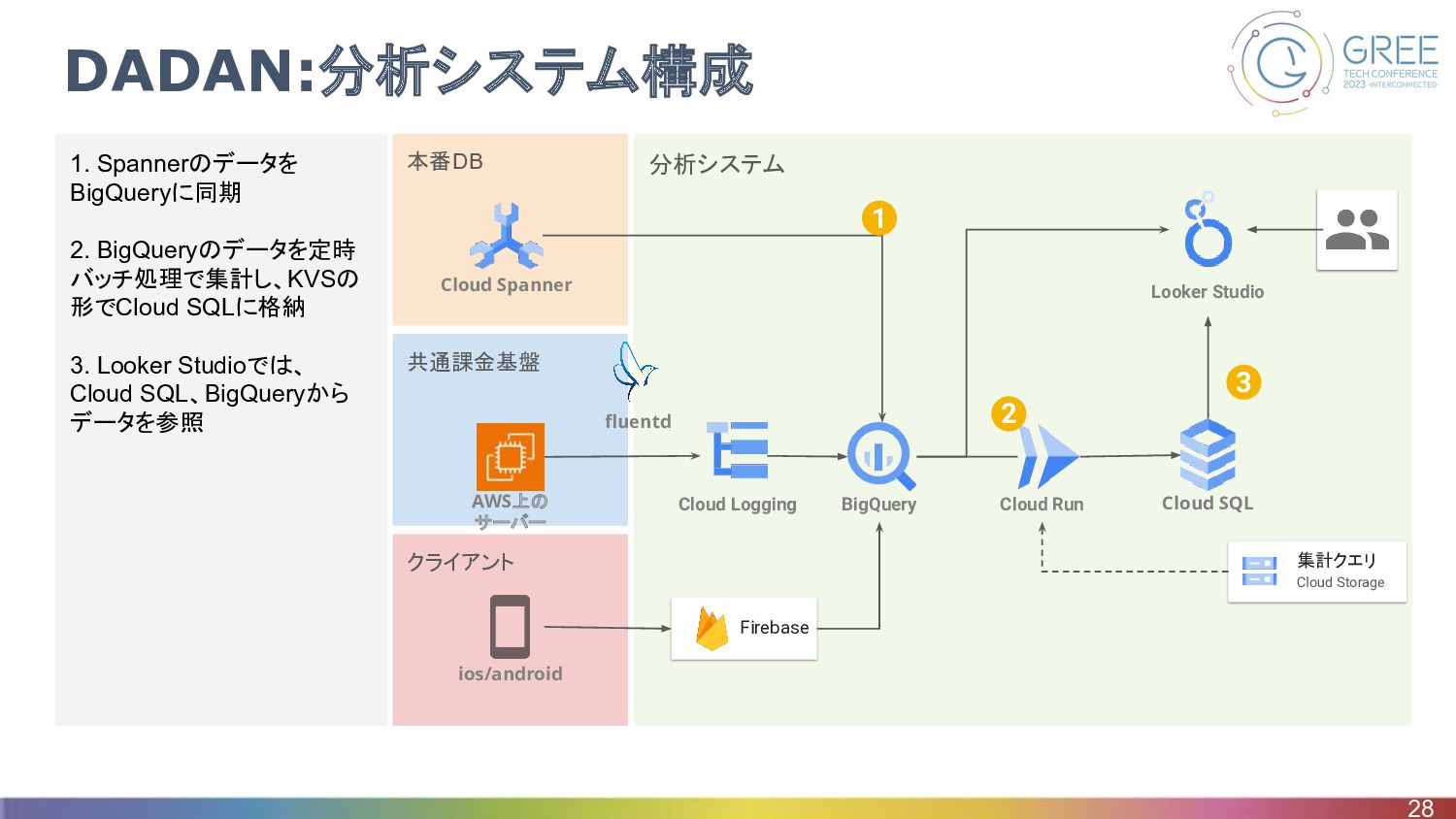
クライアント 共通課金基盤 分析システム 本番DB 1. Spannerのデータを BigQueryに同期 2. BigQueryのデータを定時 バッチ処理で集計し、KVSの
形でCloud SQLに格納 3. Looker Studioでは、 Cloud SQL、BigQueryから データを参照 DADAN:分析システム構成 28 Firebase BigQuery Cloud Run Cloud SQL Looker Studio Cloud Logging ios/android fluentd 集計クエリ Cloud Storage 2 3 Cloud Spanner 1 AWS上の サーバー
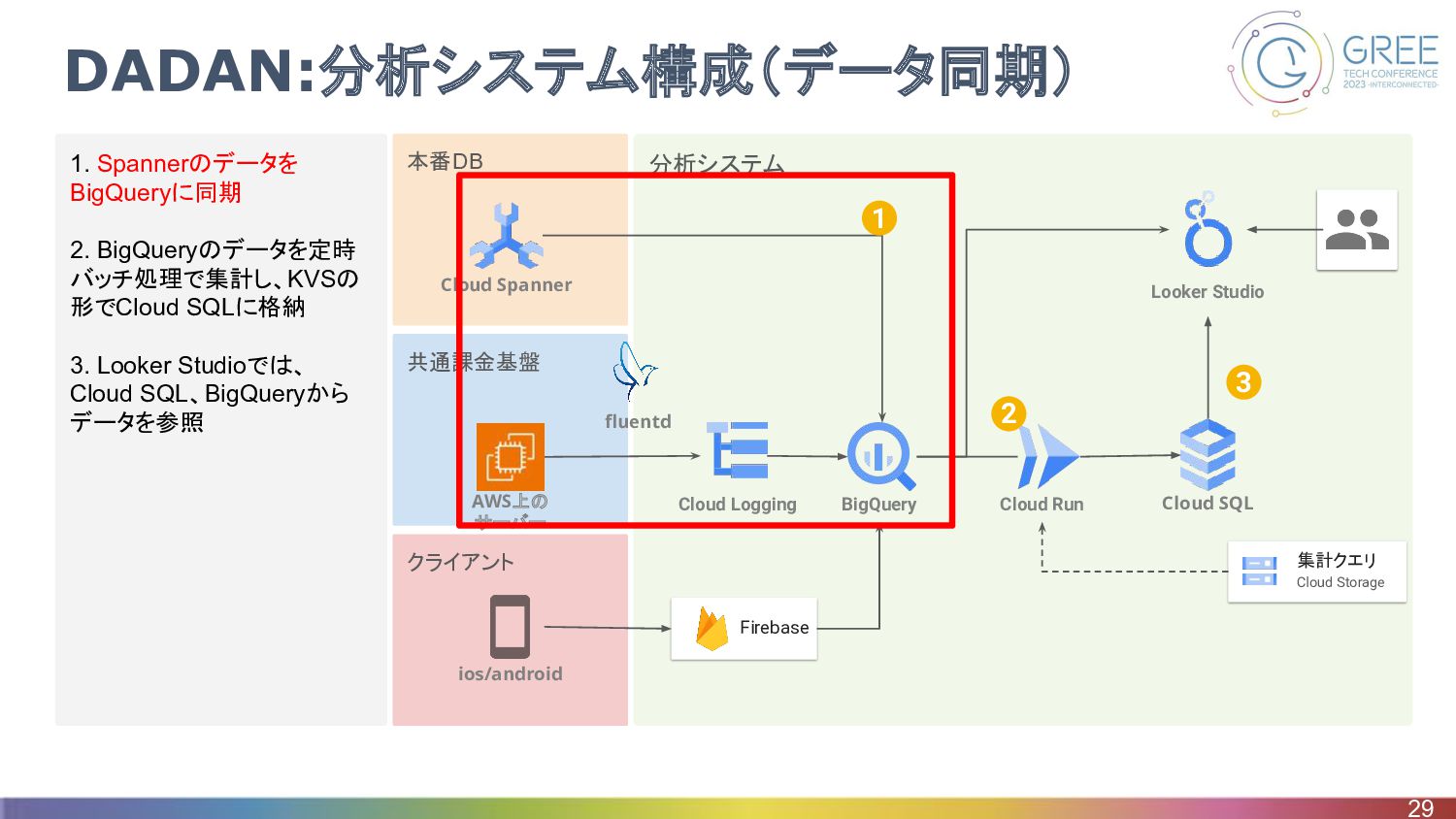
クライアント 共通課金基盤 分析システム 本番DB 1. Spannerのデータを BigQueryに同期 2. BigQueryのデータを定時 バッチ処理で集計し、KVSの
形でCloud SQLに格納 3. Looker Studioでは、 Cloud SQL、BigQueryから データを参照 DADAN:分析システム構成(データ同期) 29 Firebase BigQuery Cloud Run Cloud SQL Looker Studio Cloud Logging ios/android fluentd 集計クエリ Cloud Storage 2 3 Cloud Spanner 1 AWS上の サーバー
DADAN:分析システム構成(データ同期) • Spannerのデータを毎日BigQueryに同期 ◦ 分析頻度の高さを考慮して、外部連携ではなくスナップショットを BigQueryに同期するようにした ◦ DataflowでSpannerからGCSにエクスポートして、 BigQueryにロードしている •
共通課金基盤からのログはCloud Loggingから直接BigQueryに格納 30 Cloud Spanner Dataflow Cloud Storage BigQuery Load Export
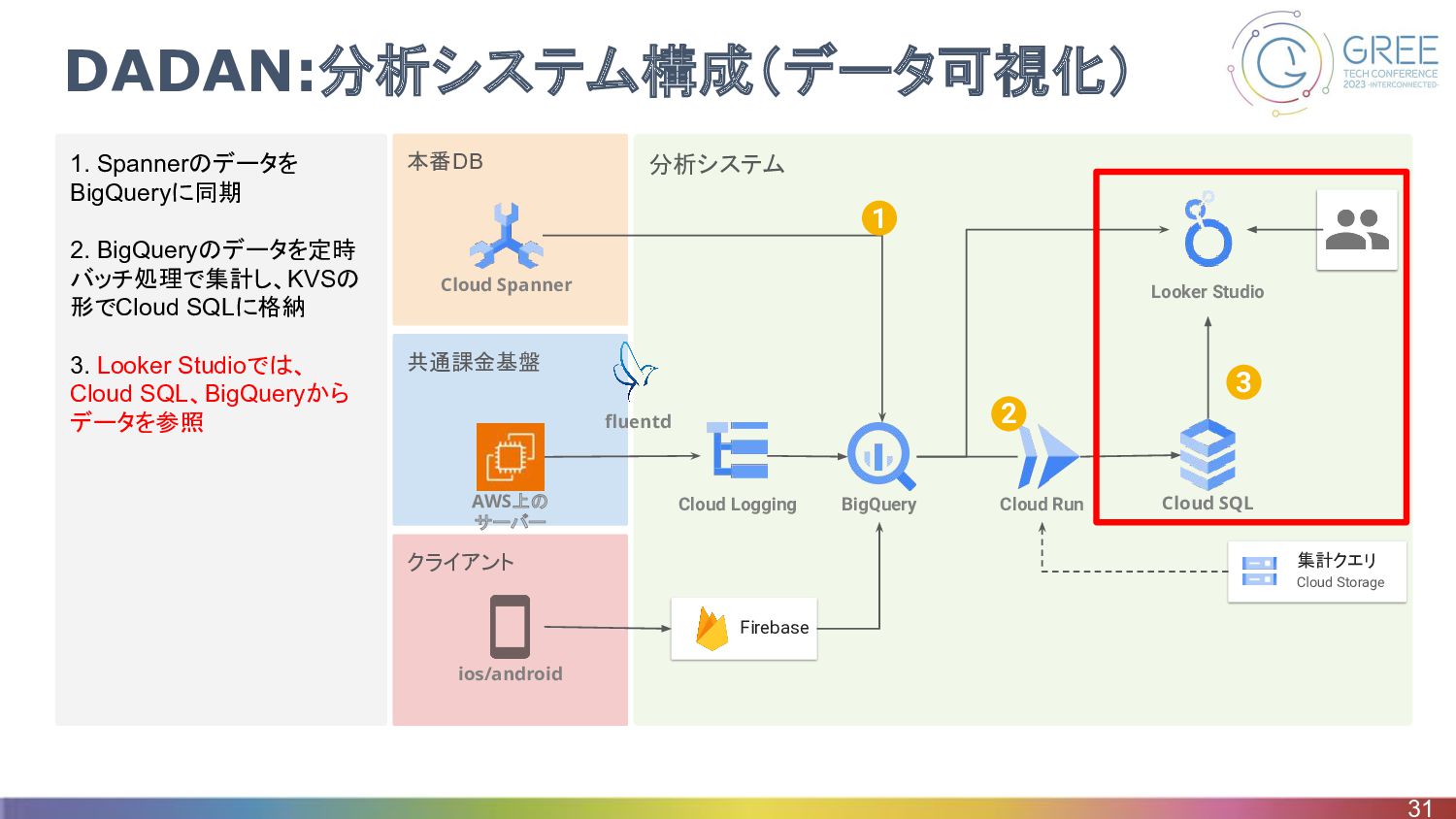
クライアント 共通課金基盤 分析システム 本番DB 1. Spannerのデータを BigQueryに同期 2. BigQueryのデータを定時 バッチ処理で集計し、KVSの
形でCloud SQLに格納 3. Looker Studioでは、 Cloud SQL、BigQueryから データを参照 DADAN:分析システム構成(データ可視化) 31 Firebase BigQuery Cloud Run Cloud SQL Looker Studio Cloud Logging ios/android fluentd 集計クエリ Cloud Storage 2 3 Cloud Spanner 1 AWS上の サーバー
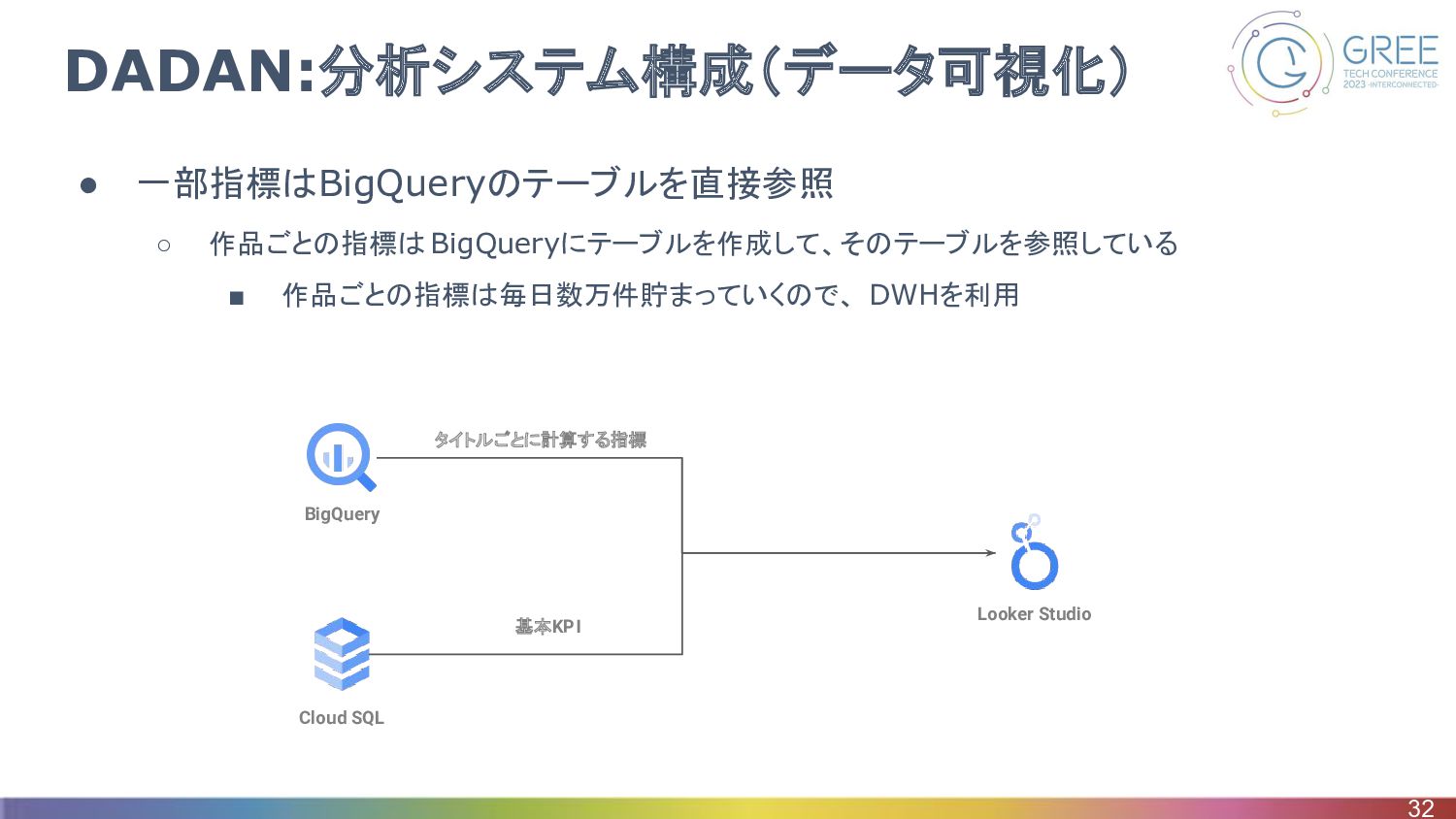
DADAN:分析システム構成(データ可視化) • 一部指標はBigQueryのテーブルを直接参照 ◦ 作品ごとの指標はBigQueryにテーブルを作成して、そのテーブルを参照している ▪ 作品ごとの指標は毎日数万件貯まっていくので、 DWHを利用 32 BigQuery
Cloud SQL Looker Studio タイトルごとに計算する指標 基本KPI
アジェンダ • REALITYとDADANの紹介 • 分析基盤構築背景 • REALITYの分析基盤 ◦ 分析システム構成 ◦
運用中に解決した課題 • DADANの分析基盤 ◦ 分析システム構成 ◦ レコメンドシステム構成 ◦ 運用中に解決した課題 • まとめ 33
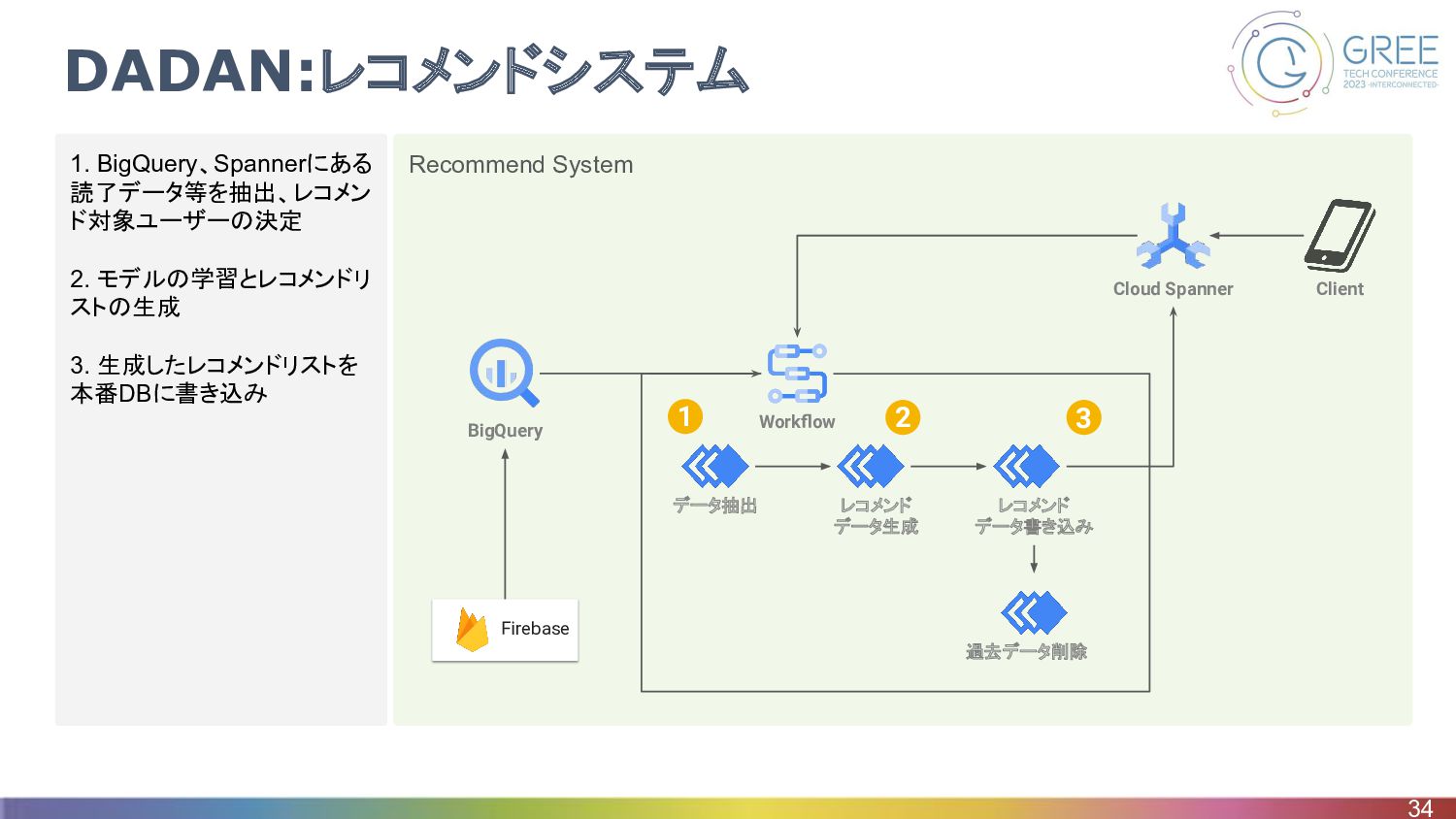
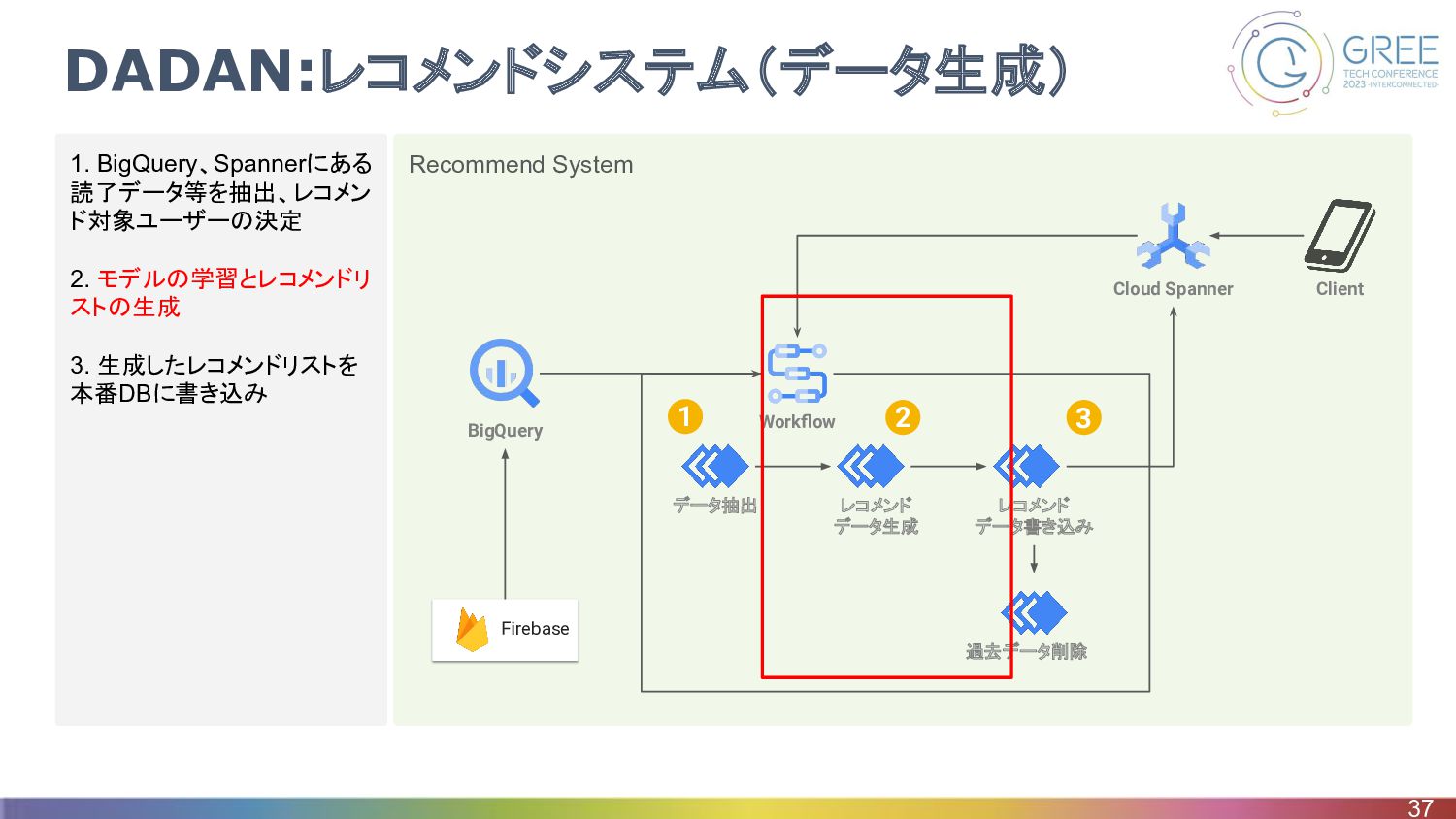
Recommend System 1. BigQuery、Spannerにある 読了データ等を抽出、レコメン ド対象ユーザーの決定 2. モデルの学習とレコメンドリ ストの生成 3.
生成したレコメンドリストを 本番DBに書き込み DADAN:レコメンドシステム 34 Firebase Workflow データ抽出 レコメンド データ生成 レコメンド データ書き込み 過去データ削除 Cloud Spanner Client BigQuery 1 2 3
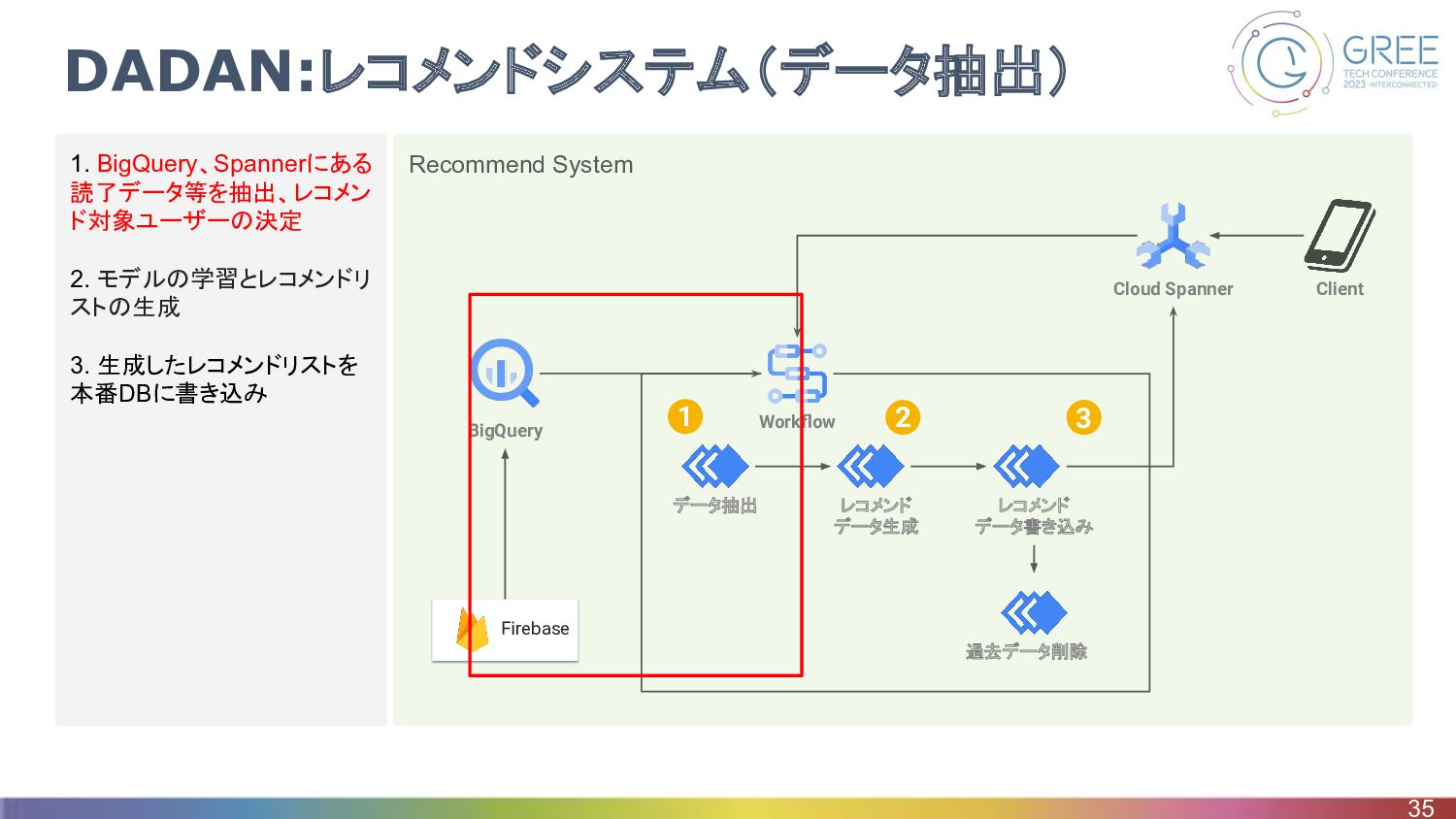
Recommend System 1. BigQuery、Spannerにある 読了データ等を抽出、レコメン ド対象ユーザーの決定 2. モデルの学習とレコメンドリ ストの生成 3.
生成したレコメンドリストを 本番DBに書き込み DADAN:レコメンドシステム(データ抽出) 35 Firebase Workflow データ抽出 レコメンド データ生成 レコメンド データ書き込み 過去データ削除 Cloud Spanner Client BigQuery 1 2 3
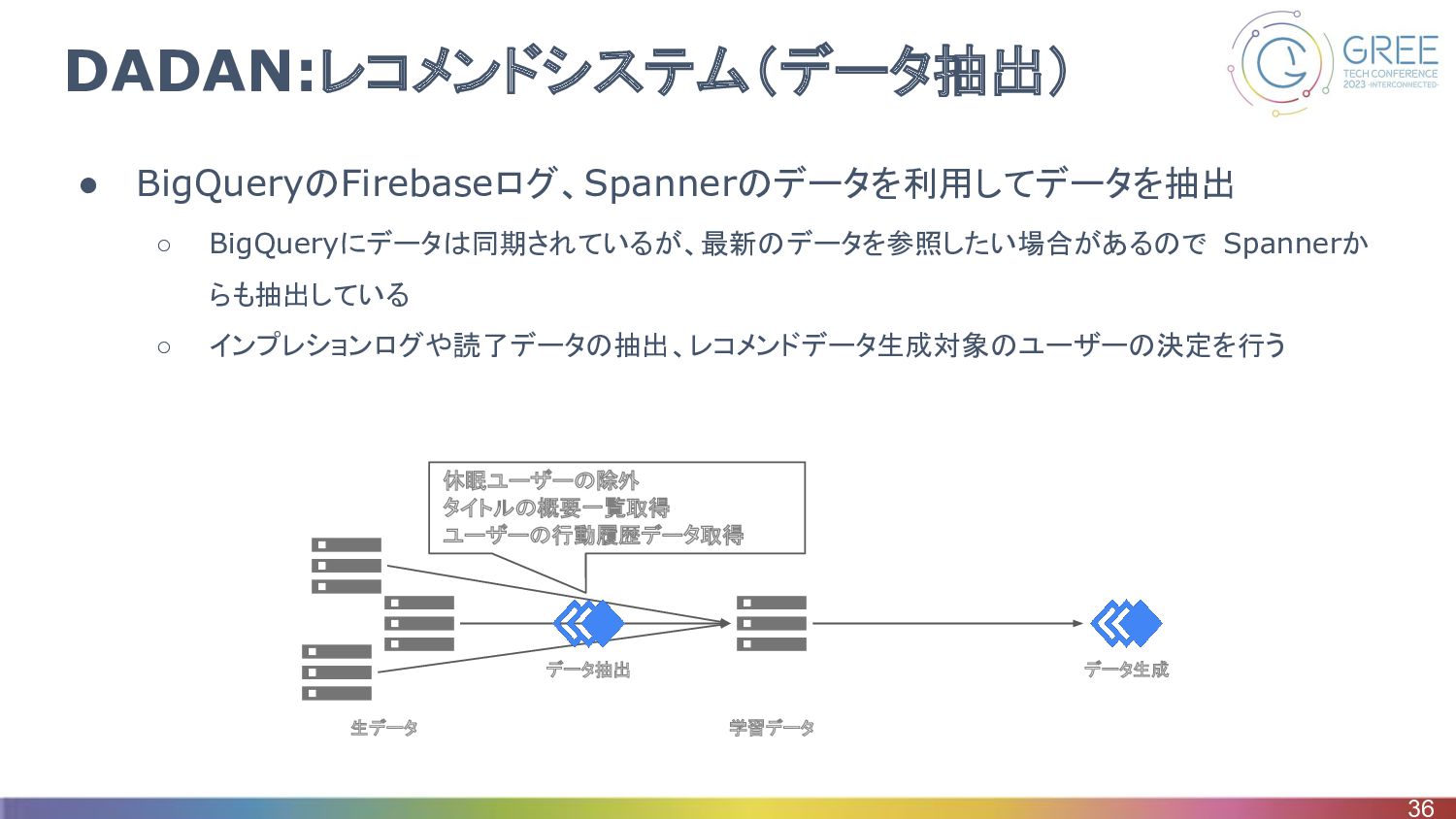
DADAN:レコメンドシステム(データ抽出) • BigQueryのFirebaseログ、Spannerのデータを利用してデータを抽出 ◦ BigQueryにデータは同期されているが、最新のデータを参照したい場合があるので Spannerか らも抽出している ◦ インプレションログや読了データの抽出、レコメンドデータ生成対象のユーザーの決定を行う 36
生データ 休眠ユーザーの除外 タイトルの概要一覧取得 ユーザーの行動履歴データ取得 学習データ データ抽出 データ生成
Recommend System 1. BigQuery、Spannerにある 読了データ等を抽出、レコメン ド対象ユーザーの決定 2. モデルの学習とレコメンドリ ストの生成 3.
生成したレコメンドリストを 本番DBに書き込み DADAN:レコメンドシステム(データ生成) 37 Firebase Workflow データ抽出 レコメンド データ生成 レコメンド データ書き込み 過去データ削除 Cloud Spanner Client BigQuery 1 2 3
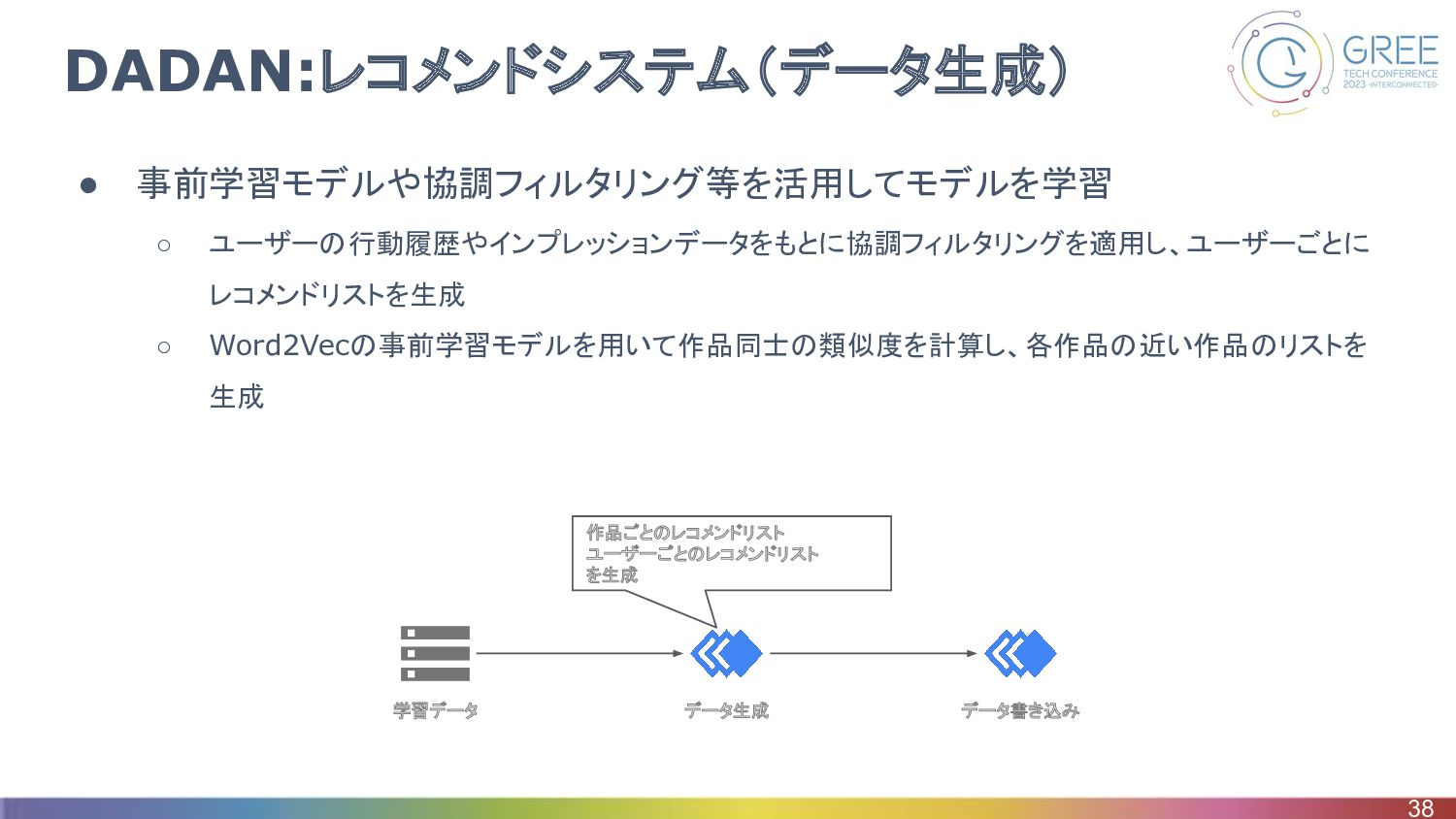
DADAN:レコメンドシステム(データ生成) • 事前学習モデルや協調フィルタリング等を活用してモデルを学習 ◦ ユーザーの行動履歴やインプレッションデータをもとに協調フィルタリングを適用し、ユーザーごとに レコメンドリストを生成 ◦ Word2Vecの事前学習モデルを用いて作品同士の類似度を計算し、各作品の近い作品のリストを 生成 38
学習データ データ生成 データ書き込み 作品ごとのレコメンドリスト ユーザーごとのレコメンドリスト を生成
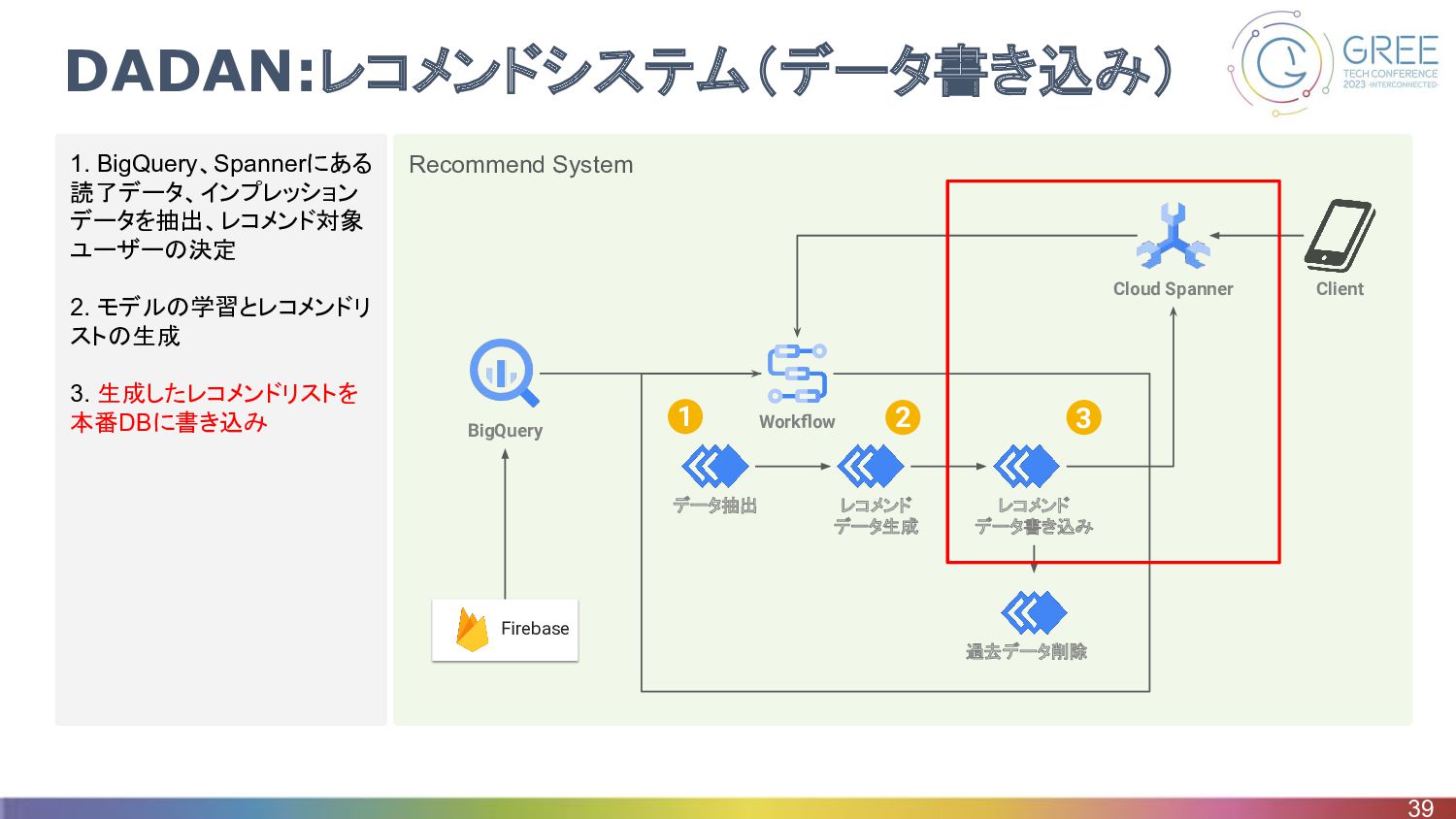
Recommend System 1. BigQuery、Spannerにある 読了データ、インプレッション データを抽出、レコメンド対象 ユーザーの決定 2. モデルの学習とレコメンドリ ストの生成
3. 生成したレコメンドリストを 本番DBに書き込み DADAN:レコメンドシステム(データ書き込み) 39 Firebase Workflow データ抽出 レコメンド データ生成 レコメンド データ書き込み 過去データ削除 Cloud Spanner Client BigQuery 1 2 3
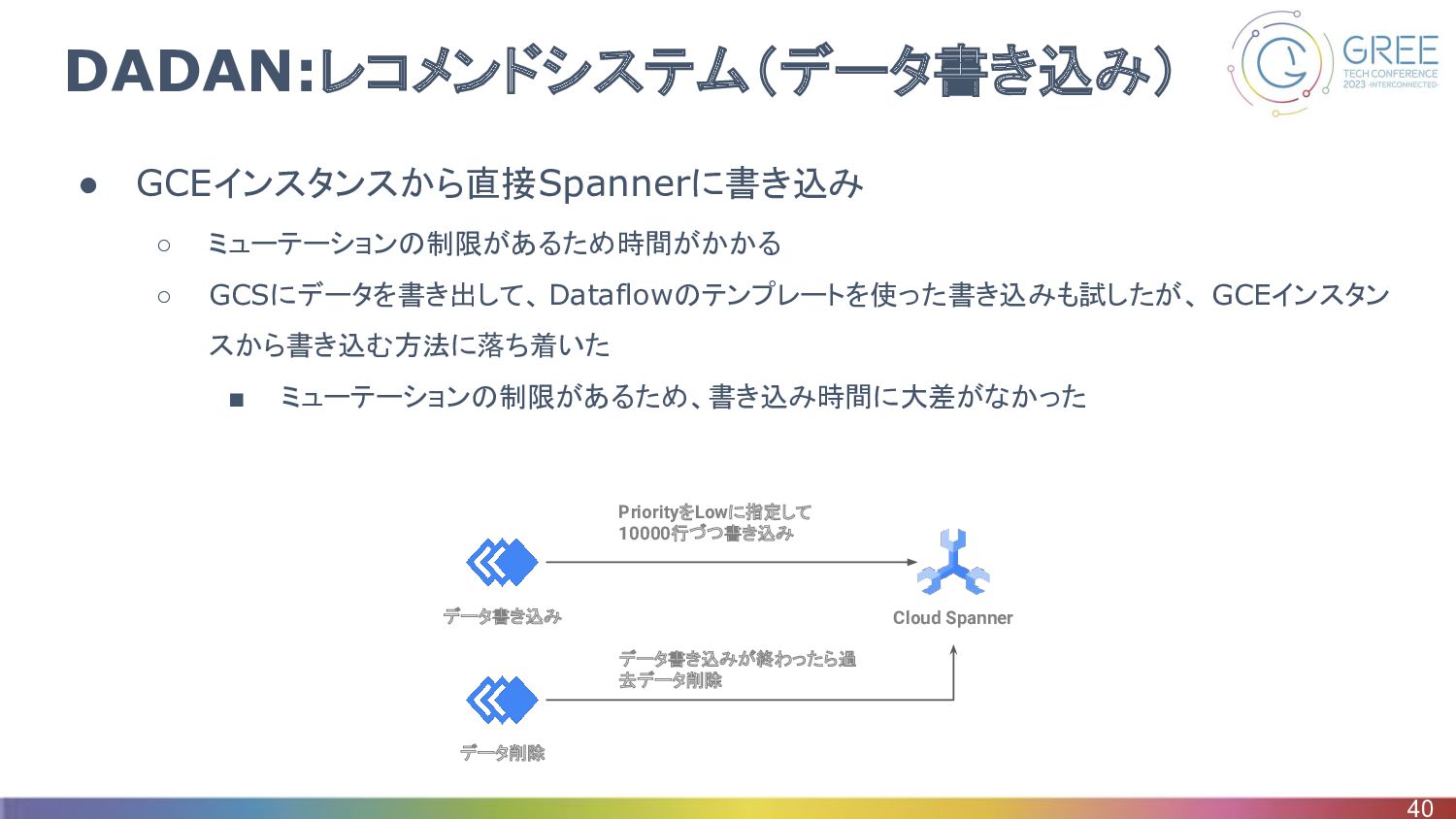
DADAN:レコメンドシステム(データ書き込み) • GCEインスタンスから直接Spannerに書き込み ◦ ミューテーションの制限があるため時間がかかる ◦ GCSにデータを書き出して、 Dataflowのテンプレートを使った書き込みも試したが、 GCEインスタン スから書き込む方法に落ち着いた
▪ ミューテーションの制限があるため、書き込み時間に大差がなかった 40 Cloud Spanner データ書き込み PriorityをLowに指定して 10000行づつ書き込み データ削除 データ書き込みが終わったら過 去データ削除
アジェンダ • REALITYとDADANの紹介 • 分析基盤構築背景 • REALITYの分析基盤 ◦ 分析システム構成 ◦
運用中に解決した課題 • DADANの分析基盤 ◦ 分析システム構成 ◦ レコメンドシステム構成 ◦ 運用中に解決した課題 • まとめ 41
DADAN:運用中に解決した課題1 • 課題 ◦ Looker Studioのデータ抽出機能の制限 ▪ 表示速度高速化のために Looker Studioのデータ抽出機能を利用していたが、作品ごとの
指標を抽出することができなくなった • 解決策 ◦ 作品ごとの指標は、BigQueryに作成したテーブルを参照するようにして解決 ▪ 作品ごとに計算する指標が複数あり、今後の作品数増加を考慮すると DWHに保存していく 方がスケーラブルに対応できるため 42
DADAN:運用中に解決した課題2 • 課題 ◦ レコメンドリストの書き込み時間がかかりすぎていた ▪ 作品数、ユーザー数が増えていくにつれ、レコメンドリストのサイズも大きくなるが、 Spanner 側のミューテーションの制限は変わらないため •
解決策 ◦ 休眠ユーザーの除外やレコメンドリストに含める作品数を制限することで対応 ▪ 1日の平均読了数や継続率等を参考に制限するラインを決定 ◦ Spanner側の制限があるため、書き込み時間の改善は難しかったが、ユーザー、タイトル数が増 えた場合も一定の書き込み速度になった 43
データ分析基盤運用から得た所感 • システムのテンプレートのようなものがあると、プロジェクトが増えたときにも迅速に システムを提供できること ◦ 事業自体が異なる場合は、こちらの方が細かい部分を柔軟に対応できる ◦ IaC化もしっかりやっておくとイニシャルコストが削減できる ◦ 1つのシステムの知識で他のシステムも対応することができる
• マネージドサービスでなるべく構成すること ◦ スケール面の対応がサービスの代替やオートスケールで解決できる ◦ ランニングコストが削減できる 44
アジェンダ • REALITYとDADANの紹介 • 分析基盤構築背景 • REALITYの分析基盤 ◦ 分析システム構成 ◦
運用中に解決した課題 • DADANの分析基盤 ◦ 分析システム構成 ◦ レコメンドシステム構成 ◦ 運用中に解決した課題 • まとめ 45
まとめ • REALITYの分析基盤 ◦ Dataflowを利用したストリーミング型のデータ分析基盤 ◦ リアルタイムにサーバーログの分析することが可能 • DADANの分析基盤 ◦
REALITYの基盤をベースにした分析基盤 ◦ ベースが同じなため低コストで運用可能 • レコメンドシステム ◦ WorkflowsとCloud Batchを利用したバッチ型のレコメンドシステム 46
47
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}