reduce(cost = 0, n in nodes(p) | cost + n._cost) as cost where cost <= 60 and not any (x in relationships(p) where x.name = 'AreaList.id') and not any (x in relationships(p) where x.name = 'AreaObject.id') and not any (x in relationships(p) where x.name = 'Location.id') return c.id, f.realPath order by c.id, f.realPath; Characterに紐づくファイル数をIDごとに集約 実際の集約のクエリ コスト計算やガード条件で制御
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Cypherの基本 ()-[]-() () ノード [] リレーション - 接続](https://files.speakerdeck.com/presentations/a32dcb42f69e4c4ab8e152cc5081e064/slide_19.jpg){kind=link}
![Cypherを使ってグラフを表現する (:Character)-[:skillId]->(:Skill)-[:`<skillId>.png`]->(:File) CharacterレコードはSkillを経由して、スキルの素材ファイルを参照している ⽇本語 Cypher Property Graph ※࣮ࡍͷεΩʔϚ͏ͪΐͬͱෳࡶͰ͢](https://files.speakerdeck.com/presentations/a32dcb42f69e4c4ab8e152cc5081e064/slide_20.jpg){kind=link}
![関係を抽出するクエリの例 1 match p = (:Character)-[*1]->(:PcSkill) return p limit 1](https://files.speakerdeck.com/presentations/a32dcb42f69e4c4ab8e152cc5081e064/slide_21.jpg){kind=link}
![関係を抽出するクエリの例 2 match p = (c:Character)-[]-(s:PcSkill)-[]-(e:PcSkillEffect)-[]- (b:BattleEffect)-[]-(g:`.png`) return p limit](https://files.speakerdeck.com/presentations/a32dcb42f69e4c4ab8e152cc5081e064/slide_22.jpg){kind=link}
![関係を抽出するクエリの例 3 match p = shortestpath((c:Character)-[*]-(g:`.ogg`)) return p limit 1](https://files.speakerdeck.com/presentations/a32dcb42f69e4c4ab8e152cc5081e064/slide_23.jpg){kind=link}
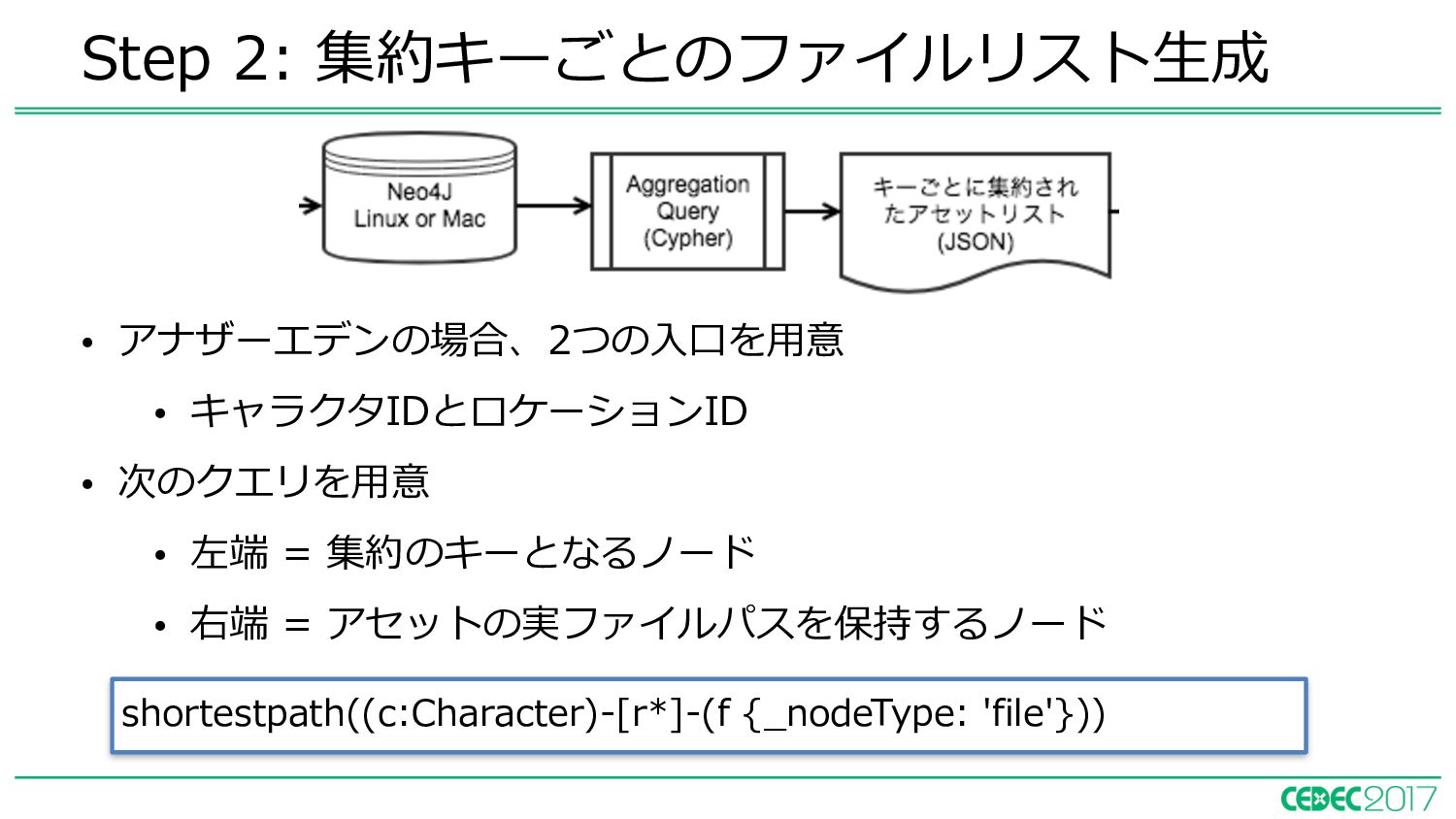{kind=link}
![match p = shortestpath((c:Character)-[r*]-(f {_nodeType: 'file'})) with c, f, p,](https://files.speakerdeck.com/presentations/a32dcb42f69e4c4ab8e152cc5081e064/slide_25.jpg){kind=link}
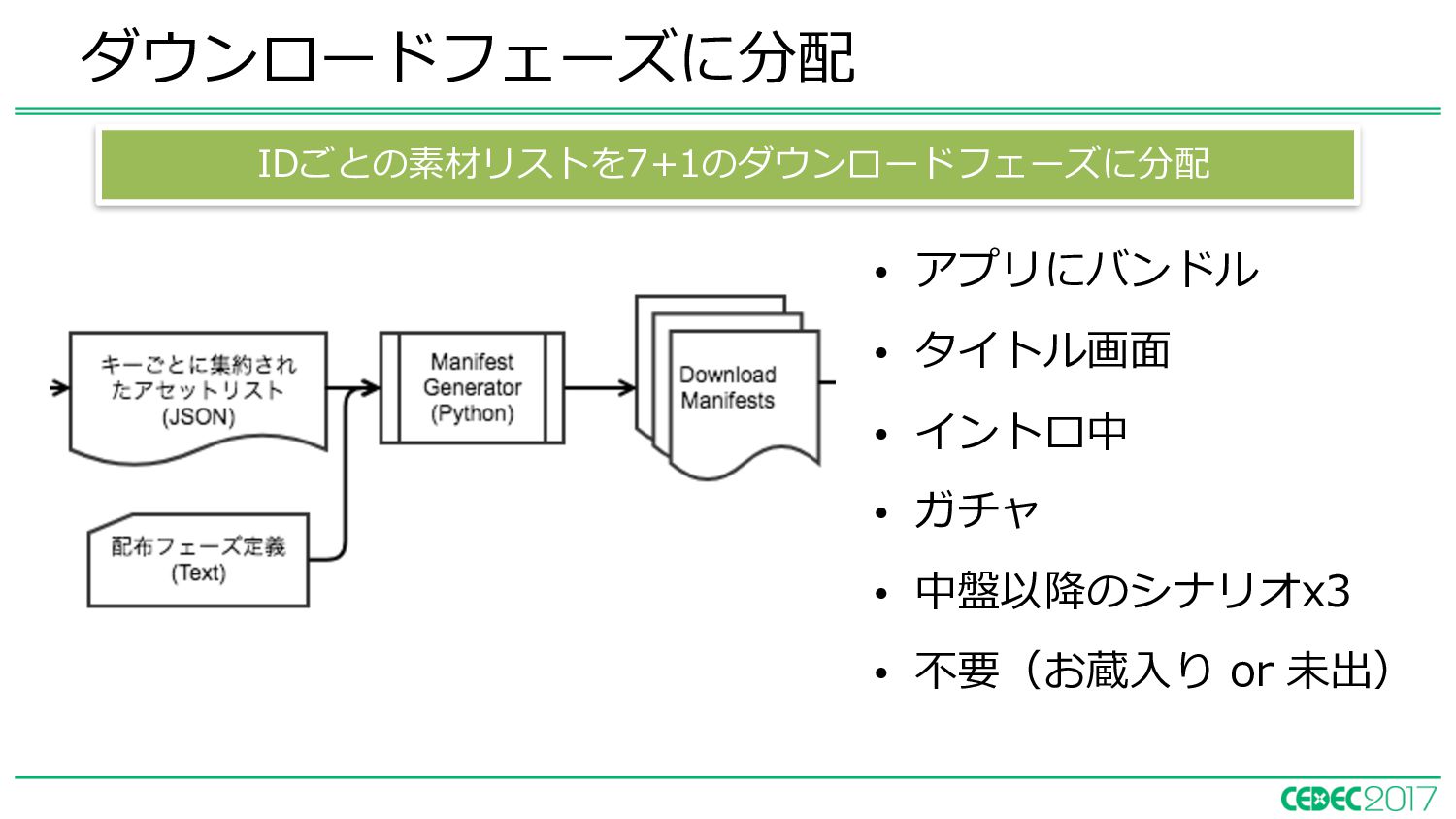{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}