Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MySQLやSSDとかの話・後編
Search
gree_tech
PRO
December 15, 2015
Technology
730
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MySQLやSSDとかの話・後編
GREE Tech Talk #09「MySQL」での登壇資料です
http://techtalk.labs.gree.jp/
gree_tech
PRO
December 15, 2015
More Decks by gree_tech
See All by gree_tech
変わるもの、変わらないもの :OSSアーキテクチャで実現する持続可能なシステム
gree_tech
PRO
0
4.9k
マネジメントに役立つ Google Cloud
gree_tech
PRO
0
68
今この時代に技術とどう向き合うべきか
gree_tech
PRO
3
2.8k
生成AIを開発組織にインストールするために: REALITYにおけるガバナンス・技術・文化へのアプローチ
gree_tech
PRO
0
460
安く・手軽に・現場発 既存資産を生かすSlack×AI検索Botの作り方
gree_tech
PRO
0
450
生成AIを安心して活用するために──「情報セキュリティガイドライン」策定とポイント
gree_tech
PRO
1
2.4k
あうもんと学ぶGenAIOps
gree_tech
PRO
0
570
MVP開発における生成AIの活用と導入事例
gree_tech
PRO
0
600
機械学習・生成AIが拓く事業価値創出の最前線
gree_tech
PRO
0
480
Other Decks in Technology
See All in Technology
Foxgloveについて 実際にExtensionを開発して公開するまでの話 / About Foxglove: The Story of Developing and Releasing an Extension
ry0_ka
0
190
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
3k
FinOps X 2026 Recap from Engineer Side #JapanFinOps
chacco38
0
270
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.2k
はじめてのWDM
miyukichi_ospf
1
140
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.3k
NDIAS CTF 2026 問題解説会資料
bata_24
0
180
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
150
ループエンジニアリングでE2Eテストを実践
noriyukitakei
0
330
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.3k
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
12
5.6k
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
790
Featured
See All Featured
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
260
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Transcript
MySQLやSSDとかの話 後編 Takanori Sejima
自己紹介 • わりとMySQLのひと • 3.23.58 から使ってる • むかしは Resource Monitoring
も力入れてやってた • ganglia & rrdcached の(たぶん)ヘビーユーザ • 5年くらい前から使い始めた • gmond は素のまま使ってる • gmetad は欲しい機能がなかったので patch 書いた • webfrontend はほぼ書き直した • あとはひたすら python module 書いた • ganglia じゃなくても良かったんだけど、とにかく rrdcached を使いたかった • というわけで、自分は Monitoring を大事にする • 一時期は Flare という OSS の bugfix などもやってた
• 古いサーバを、新しくてスペックの良いサーバに置き換えていく際、 いろいろ工夫して集約していっているのですが • そのあたりの背景や取り組みなどについて、本日はお話しようと思 います • オンプレミス環境の話になっちゃうんですが • 一部は、オンプレミス環境じゃなくても応用が効くと思います
• あと、いろいろ変なことやってますが、わたしはだいたい考えただ けで • 実働部隊は優秀な若者たちがいて、細かいところは彼らががんばっ てくれてます 本日のお話
• 最近の HW や InnoDB の I/O 周りについて考えつつ、取り組んで おりまして •
さいきん、そのあたりを資料にまとめて slideshare で公開しており ます • 後日、あわせて読んでいただけると、よりわかりやすいかと思いま す • 参考: • 5.6以前の InnoDB Flushing • CPUに関する話 • EthernetやCPUなどの話 本日のお話の補足資料
では後編を はじめます
• ioDrive の実績上がってきたし • サービス無停止で master 統合の目処も立ったから • 大容量のSSD導入して、ガンガンDB統合していこうと思ってたんだ けど
次の課題とは?
それは
バックアップ どうしよう?
• DBのバックアップをどうやって取得しよう? • HDDのころは、masterとslaveは146GBのHDD*4でRAID10だっ たが、 バックアップファイルを取るためのslaveはHDD*6とか HDD*8とかで、データベース用の領域と、バックアップファイルを 書き出すための領域を確保できるようにしてた • 具体的には、
mysqld 止めて datadir を tar ball で固めてた • つまり、masterのサーバとバックアップファイルを取るためのサー バは、ストレージの容量が等しくなかった 次の課題
• バックアップサーバとmasterで同じ容量のSSD使うと、バックアッ プを取ることができない • DBで800GB使いきっちゃうと、 tar ball とれない • 数TBの大容量
PCI-e SSD をバックアップサーバ用に使う? • それはリッチすぎるコストパフォーマンスが悪い • HDDだとI/Oの性能が追いつかない • DBを統合するということは、それだけ更新が増えるということでもある • SSDをRAIDコントローラで束ねる? • そうするとRAIDコントローラがボトルネックになるケースも出てくる • かつては、RAIDコントローラ経由だとSMARTがとれないという課題もあった 一番容量のでかいSATA SSDを使いたい
• HDDもSSDも、ブロックデバイスは、一つのI/Oコントローラに対 して read と write を同時に発行すると遅い • read only
ないし write only のときに最大のスループットがでる • RAIDで束ねたHDD上で tar ball 取得するの、データベースが大き くなるに連れて、無視できない遅さになってきていた • SSDに移行したとしても、このままだといつか遅くなって困るんじ ゃない? 大容量のSSDを使う前から、課題意識はあった
五時間くらい 考えた
そうだ
バックアップの取り 方を変えよう
• master/slave/バックアップサーバをぜんぶ 800GB のSSDにする • バックアップサーバは ssh 経由で、同じラックにある SATA HDD
の RAID6なストレージサーバに tar ball を書き出す • $ tar cvf - ${datadir} | pigz | ssh ${storage_server} “cat - >backup.tar.gz” • SSDなので tar するときの read は速い • pigzでCPUのcoreぜんぶ使いきって圧縮するので、帯域制限にもな るし、通信量もへる。まぁ、ラックをまたがないので、全力で転送 しても困らない • HDDは sequential write only になるので、書き込むのは充分速い • 運用や監視も、既存の方法と比べて大きくは変えなくて良い 方法を変える、許容できる範囲内で
• データが巨大になると、DB再構築するのに時間がかかるようになる • 今までN+1の構成だったところはN+2にする • slaveは一台多めにしておく。一台故障したら、もう一台故障する前にじっくり 再構築 • ストレージサーバは RAID6
にする。 SATA HDD の故障率を考慮して • ストレージサーバはTB単位のデータを持っているため、電源などが故障したとき のダメージがでかいので、二台構成にする。 • バックアップサーバから書き出す先は現行系のストレージサーバにして、待機系は cron で rsync してコピーする • ストレージサーバはSATA HDDにしたから大容量にできたので、ストレージサー バ一台に対して、書き込むバックアップサーバは複数台にする。それならば、ス トレージサーバを二台構成にしてもコスト的にペイする • 最終的に、トータルで台数減ればそれでいい 破綻しないよう、考えながら集約する
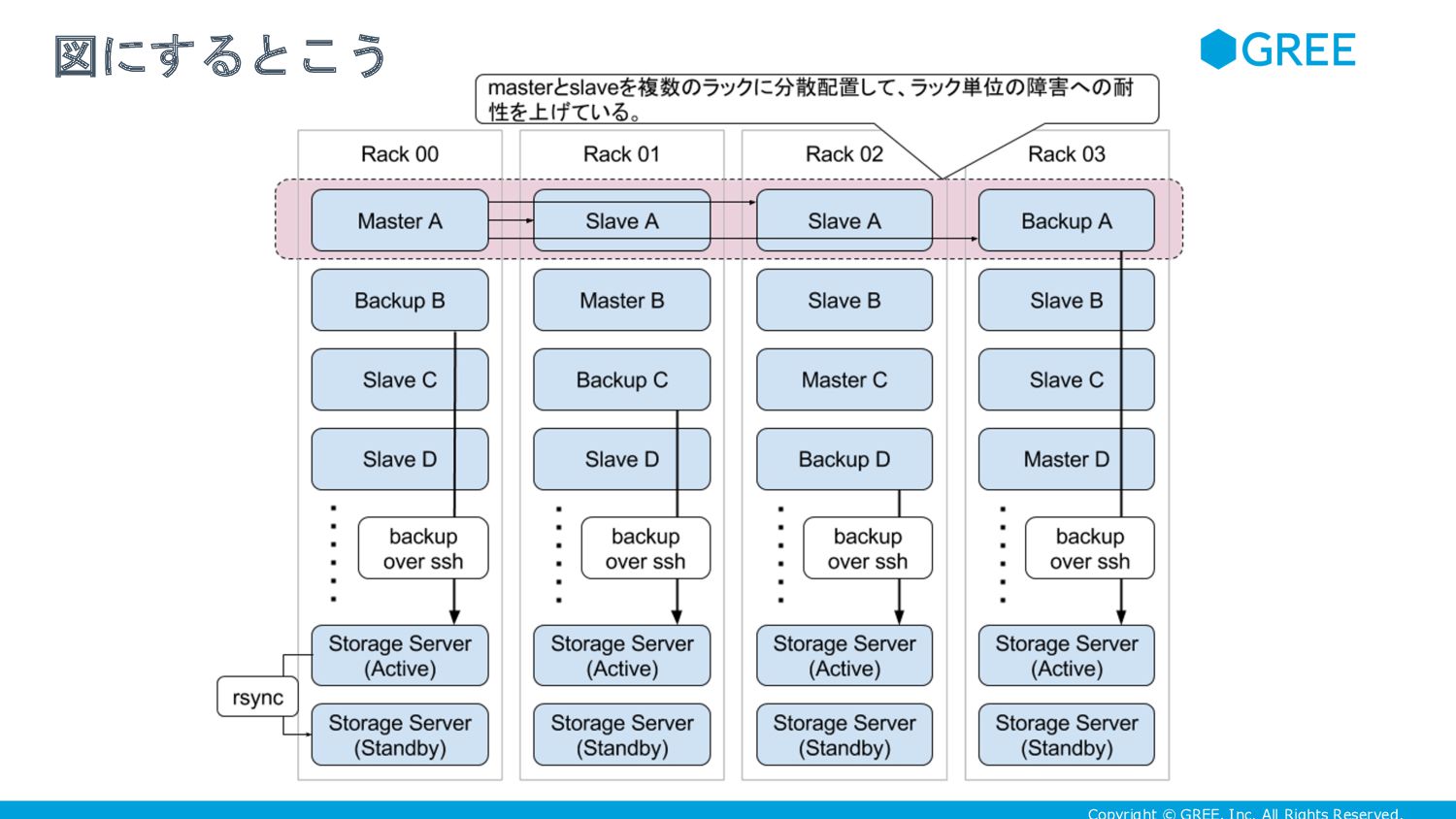
図にするとこう
• Google の Warehouse-Scale Computer ほど大きい粒度ではなく、 4本以上のラックを一つの単位として考える • replication の
traffic は、これらのラックに閉じ込めてしまう。 • RAID5がパリティを複数のディスクに分散させるように、masterや バックアップ用のサーバを複数のラックに分散させる • 万が一、ラックごと落ちたとしても、影響を受ける master の数を限定的にでき る • master -> slave 間の replication の traffic が、ラックごとに偏りにくくなる • アプリケーションサーバ <-> slave の traffic が多かったとしても、ラックごと に偏りにくくなる • バックアップサーバを分散配置することで、ストレージサーバのディスク使用量 を、ラックごとに偏らせないようにする 複数のラックをグルーピングし、RAID5の様に 扱う
• 現状のHWの特性や、今後のHWを想定している • サーバのNICの帯域が増えても、これらのラックの集合の中でその性能が活かせ る • 弊社の場合、KVSの replication の traffic
が大変多いのだが、 KVSやMySQLの replication の traffic を特定のラックに集約できると、運用上楽になる • pigz でバックアップファイルを圧縮するので、DBの集約度が上がってDBのサイ ズが増えても、CPUのコアが増えれば、バックアップの取得時間を稼ぐことがで きる • SSDの消費電力の少なさを活かして、一ラックあたりの集積度を上げていける • SSDは消費電力が少なく熱にも強いから、そのぶん CPU で TurboBoost 使って、 熱出しつつ性能を引き出す方向で行ける • TurboBoost 使うことで、NICの帯域が増えても、CPUがパケットさばけるよう にする • 現状はSATAのHDDをバックアップ用のストレージに割り当てているけど、SSD のバイト単価が十分下がっていけば、別に SSD でもかまわない このラックの使い方には、いろいろな思惑がある
• 最近は、 ioMemory や 800GBのエンタープライズグレードの SATA SSD を使い分けてたりする • SATAのSSDはコストパフォーマンスが良い。でも、GREE的には
Fusion-IOの方が実績がある • サービスの品質を担保しつつ、使い比べて、適切に使い分けていき たいので • latencyの要件厳しくないところから、SATAのSSDにしていってい る いろいろ考えたので導入してる
• 書き込み寿命の短いものも、積極的に使うようにしている • かつて、 ioDrive MLC 320GB は書き込み寿命が 4PBW だったけ
ど • ioMemory SX1300 は、 1250GB の容量で、4PBW • 容量あたりの書き込み寿命短い製品の方が安いので、積極的に書き 込みを減らす工夫をしている • こちらの資料 で double write buffer など調査してる理由の一つは、 書き込みを減らして安価な NAND Flash を使ってコストダウンした いがため • あと、 NAND Flash は微細化が進むに連れて書き込み寿命が短くな る性質なので、ハードウェアの変化に備えるために ただ、 ioMemory でも
• ファイルシステムの discard option 有効にして SATA SSD を使お うとすると、巨大なファイルの削除が遅い傾向にある。(最近の kernel
だとなおってるかもしれないが)、Linux は TRIMの最適化 がいまいち • 例外的に、Fusion-IO は discard 指定して mount しても、あまり 性能劣化しない傾向なので、 Fusion-IO 使うときだけ discard 指定 してる • MySQLでは、 binary log を purge したり、 DROP TABLE などで ファイルを削除する場合があるので、ファイル削除が遅いのはつら い • SATA SSD 使うときは discard 指定しないようにしてる。 TRIM に期待するより、InnoDB をチューニングして I/O 減らす方がいい LinuxのTRIMサポートにはあまり期待していな い
• MySQL5.6を使って • 5.7の本格導入はこれから • double write buffer は無効化 •
innodb_io_capacity=100 • いろいろやってたら、このバグ踏むことは確かにあった • default の 200 ならそんなに困らないんだけど、それでも、 innodb_adaptive_flushing_lwm までredo logがたまらないのはもったいない • 夜中などオフピークの時間帯は、redo logをためずに書いてしまうことがある • redo logが溜まってきたら、 innodb_adaptive_flushing_lwm や innodb_io_capacity_max に応じて書き込むので、 innodb_adaptive_flushing_lwm まではログをためてもいいという判断 SSDで書き込みを減らすための、最近の取り組み
• 一つは、安価なNAND Flashを使えるようにして、ランニングコスト を下げること • もう一つは、故障率を下げる試みとして • 経験上、たくさん書き込んでる NAND Flash
ほど、故障しやすいので • Facebook の論文(A Large-Scale Study of Flash Memory Failures in the Field) でも、たくさん書き込んでると、 uncorrectable な error が発生しやす いとのことなので • 故障率を下げて、よりサービスを安定稼働させたい • AWS で EBS 酷使するとしても、 iops 減らせるほうが最終的には 便利だし、コストダウンに繋がる 書き込みを減らしたいのは、幾つかの理由から
• SSD で集約して、一部のサーバのCPU使用率は上げられるようにな ってきたけど、もっとCPUを活用していきたい • 今後もCPUはCoreの数増え続けるだろうし • というわけで、性能上問題がないところは InnoDB の圧縮機能を使
って、CPUを活用し、さらに集約度を上げていってる • 秘伝のタレである my.cnf 見なおしたり • DB の設計によっては、 mutex が課題になるケースもある • TurboBoost 使ってCPUの性能を引き出すために、CPUの温度など もさいきんは取り始めた • バックアップの取り方を、さらに見直すなどもした 他にもやってる取り組み
• mysqld を止めて tar ball を取る場合、 mysqld を止めている間に master がクラッシュすると、その間のbinlog取り損なって残念
• そこで、mysqlbinlog で --read-from-remote-server --stop- never --raw を使って、 tar ball とってる間も binlog を取り続け るようにして、いざというときはその binlog を使えるようにしてお く • XtraBackup などでオンラインバックアップを取る運用に変えれば、 mysqld 止めなくてもいいから、binlog欠損しないんだけど、運用 を変えないでいいというのは、導入が容易というメリットがある MySQL5.6以降のmysqlbinlogを活用
• mysqlbinlog のコードを読んでいて、とても残念な気持ちになった • --raw の場合、 fwrite(3) でログを出力していて、masterから binlogを受け取ったとしても、それが直ちにファイルに書き込まれ るわけではない。その状態で
kill すると、最後に受け取ったbinlog のイベントが欠損する • これは mysqlbinlog の main loop が今ひとつなので、いっそ書き換えようかと 思った • いつでも SIGTERM を送ってカジュアルにプロセス終了させたい 一つだけ工夫
一時間ほど 考えた
• mysqlbinlog は master とのコネクション切れると、 fclose(3)し て ログを flush してから終了してくれるので、
nc を間に挟むこと にした • > nc -l -s 127.0.0.1 -p 13306 -w 3600 -c "/bin/nc ${Master_Host} 3306" & > mysqlbinlog --host=127.0.0.1 --port=13306 --read- from-remote-server --raw --stop-never ${Relay_Master_Log_File} & • これで、 nc に SIGTERM 送れば、 mysqlbinlog は受け取ったロ グをすべて出力してから終了してくれる netcatをはさむ
• master統合する前に、統合後の書き込みの負荷がどれくらいになる のかをテストしたかったので • 次のワンライナーを実行すると、 mysqlbinlog が io_thread、 mysql client
が sql_thread 相当の仕事をしてくれるので、レプリ ケーションしながらこれで query を流し込めばいい • trickle -s -d ${適当な値} mysqlbinlog --host=${MASTER_HOST} -- verify-binlog-checksum --read-from-remote-server --stop-never ${MASTER_LOG} 2>${LOGFILE}_log.err | tee ${LOGFILE}_log.txt | mysql --binary-mode -vv > ${LOGFILE}_client.txt 2>${LOGFILE}_client.err mysqlbinlog でもう一つ ただし、この方法は各自の責任で試してください!
• 5.6 で fix されたけど、それ以前の mysql client は、 mysqlbinlog が生成した
query をうまく処理できないケースがあ った • なので、前のページで書いた方法は、 5.6 以降の mysqlbinlog と mysql client の組み合わせで試すべき • あと、今後 MySQL の version が上がったときに、 binlog の format が変わらない保証はない • 自分で試すときは、最初に、使う可能性があるすべての version の mysql で binlog 周りのコードを読んでからにした • 当時、わたしは MySQL5.7 を待つ堪え性がなかっただけなので • いまは 5.7で multi source replication 使うほうが無難かも mysqlbinlog と mysql client の相性問題
• インフラエンジニアが、お客様に対して還元できることは • サービスの安定性を向上することと • ランニングコストを削減することくらいなので • サービスの安定性を確保しつつ、ランニングコストを削減できれば、 そのぶん、サービスの改善に活かせるはず なぜこんなことをやるかというと
• サーバを構成するハードウェア、CPU/メモリ/ストレージ/ネットワ ークのうち • この五年間でもっとも進化したのは、ストレージ • SSDになって、性能向上して、容量増えて、消費電力さがって • 書き込み寿命という概念がもたらされた •
ストレージの変化に合わせて、許容できる範囲内でシステムを見な おして • サービスの安定性を向上させつつ、ランニングコストの削減を図っ て • お客様に還元しようと思った 過去五年間を振り返って考えると
• 一つのサービスを5年以上続けていると、ハードウェアなど、周囲 の環境が変わってくる • さいきん立ち上がったサービスは、最初からSSDやAWSが当たり前 なので、それに最適な設計で始められるので、コスト面で優位に立 てる可能性が高い • 古くからあるサービスも、現代の状況に合わせてあるていど変化さ せないと、コストパフォーマンスが悪いままで、競争で不利になる。
古いサービスは先行者利益があるだけではない • 時代の変化に追随して、現代のハードウェアに対して最適な構成に 変更し、競争力を維持するよう努める 時代の変化に追随する
• 最近は、次にどんなハードウェアが進化するのか、どの構成要素の 進化が著しいのかを考えていて • それに合わせて、許容できる範囲内でシステムを見なおしてるとこ ろです • 個人的には、オンプレミスとかパブリッククラウドとかこだわりは なくって、何をどう使うのが、最終的に一番メリットあるのか考え てたりします
• 現状、オンプレミス環境は、次の2つのメリットがあるので推奨し てますが、これらも時代とともにうつろうのだろうと考えてます • サーバだけでなく、ネットワーク機材のメンテナンスもあるていどスケジューリ ングできるので、他社向けのサービスに対し、影響の少ない時間帯にメンテナン ス作業ができる • I/Oの性能がよい そういうわけで
おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}