Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習・生成AIが拓く事業価値創出の最前線
Search
gree_tech
PRO
October 17, 2025
Technology
500
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
機械学習・生成AIが拓く事業価値創出の最前線
GREE Tech Conference 2025で発表された資料です。
https://techcon.gree.jp/2025/session/TrackA-5
gree_tech
PRO
October 17, 2025
More Decks by gree_tech
See All by gree_tech
変わるもの、変わらないもの :OSSアーキテクチャで実現する持続可能なシステム
gree_tech
PRO
0
5k
マネジメントに役立つ Google Cloud
gree_tech
PRO
0
72
今この時代に技術とどう向き合うべきか
gree_tech
PRO
3
2.8k
生成AIを開発組織にインストールするために: REALITYにおけるガバナンス・技術・文化へのアプローチ
gree_tech
PRO
0
470
安く・手軽に・現場発 既存資産を生かすSlack×AI検索Botの作り方
gree_tech
PRO
0
470
生成AIを安心して活用するために──「情報セキュリティガイドライン」策定とポイント
gree_tech
PRO
1
2.4k
あうもんと学ぶGenAIOps
gree_tech
PRO
0
580
MVP開発における生成AIの活用と導入事例
gree_tech
PRO
0
610
コンテンツモデレーションにおける適切な監査範囲の考察
gree_tech
PRO
0
370
Other Decks in Technology
See All in Technology
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
130
20260720_クラウド女子会×PyLadiesTokyoコラボ Amazon Bedrock ハンズオン用資料
yuuka51
2
110
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
280
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
300
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
180
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1.1k
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
330
キャリアLT会#3
beli68
2
250
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
330
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
470
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Featured
See All Featured
Deep Space Network (abreviated)
tonyrice
0
230
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Designing for Performance
lara
611
70k
Embracing the Ebb and Flow
colly
88
5.1k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
410
Unsuck your backbone
ammeep
672
58k
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Transcript
機械学習・生成AIが拓く事業価値創出 の最前線 株式会社グリー マネージャー 松富めぐみ エンジニア 石原達馬
松富めぐみ 2019年グリー株式会社(現グリーホール ディングス)に中途入社。 入社後は社内向けデータ基盤のプロダクト マネジメントやAIシステム開発プロジェクト の推進役を担う 現在はPdMとエンジニアから構成される グループにてシニアマネージャーに従事。 料理とサウナが好き。 2
石原達馬 2018年グリー株式会社(現グリーホール ディングス)に中途入社。 社内データ基盤の開発運用と機械学習分野 のPoCとサービス開発運用に携わる プロフィール写真を要求されたので右の画 像を提出したところ何も言われずに通った のでモデレーターに敬意を払いこれで押し 切ろうと思う 3
アジェンダ • 私たちの組織について • 事例紹介1. 離脱ユーザー予測 • ML基盤の構築例(事例1のケース) • 事例紹介2.
電子漫画制作におけるAI活用 • まとめ
私たちの組織について 自社のデータ基盤において設計→構築→運用まで一気通貫で対応。 オンプレ→AWSへの移管やGCPベースの基盤構築実績あり。 世の中のAIをベースに独自のノウハウを加え、自社課題に合わせたソリューションを開発。 導入後もAIモデルの継続的な性能向上をサポート。 Vertex AIを活用した前処理、学習・推論、デプロイ、性能評価、監視を含む MLパイプラインにより効率的なAIモデルの運用を実現。 データ基盤 AI実装
ML基盤 自社やグループ内外の会社向けにAI・データ活用の支援やサービス提供を行い ビジネス価値の創出に貢献。 5
事例紹介1. 離脱ユーザー予測
目的: ユーザーの離脱防止による売上損失の低減 離脱ユーザー予測 背景: • 離脱率自体は高くはないが、課金ユーザーの離脱・退会による売上影響は軽視できない • 潜在的な離脱リスクがあるユーザーを検知し、早期対策を打つことで離脱を防ぐ仕組みを作る 概要: ブラウザゲームにおける、潜在的離脱ユーザーを予測するモデルの開発
7
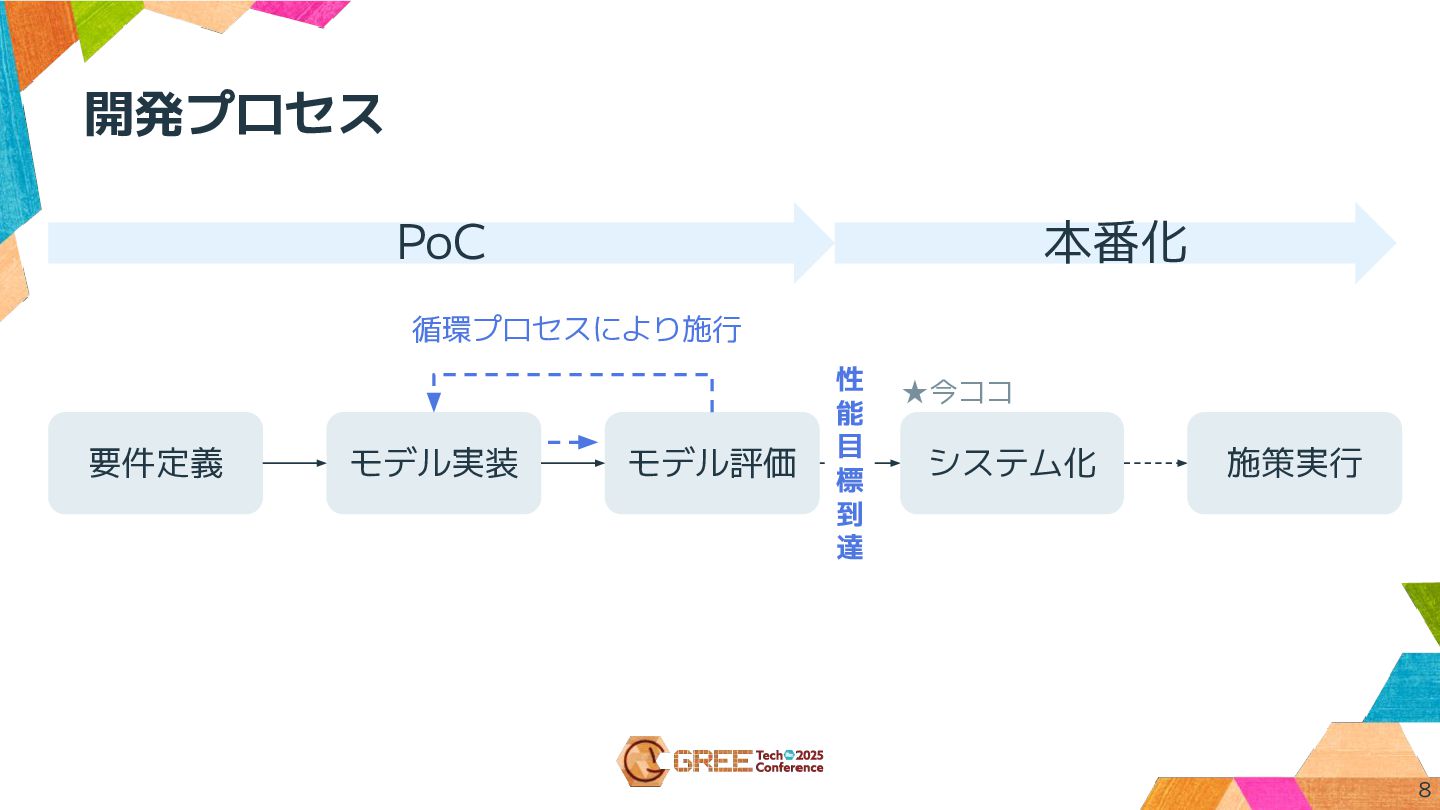
モデル実装 施策実行 モデル評価 システム化 循環プロセスにより施行 性 能 目 標 到
達 8 ★今ココ 要件定義 開発プロセス PoC 本番化
要件定義について 主に決めたこと ゴール設定 ・予測する対象である「離脱」の定義をどうするか? データ要件 ・離脱に影響しそうな変数は何か? モデル要件 ・初手としてどの機械学習モデルを用いるか? ・精度の評価指標を何に置くか?目標ラインをどうするか? 9
要件定義について 主に決めたこと ゴール設定 ・予測する対象である「離脱」の定義をどうするか? データ要件 ・離脱に影響しそうな変数は何か? モデル要件 ・初手としてどの機械学習モデルを用いるか? ・精度の評価指標を何に置くか?目標ラインをどうするか? 10
プロダクト視点での要件出し
要件定義について 主に決めたこと ゴール設定 ・予測する対象である「離脱」の定義をどうするか? データ要件 ・離脱に影響しそうな変数は何か? モデル要件 ・初手としてどの機械学習モデルを用いるか? ・精度の評価指標を何に置くか?目標ラインをどうするか? 11
プロダクト視点での要件出し 機械学習の要件に変換 データサイエンス視点での 定義化 ×
モデルのアプローチ 評価指標の設定 Recall/F2スコアを重視。離脱ユーザーを 取りこぼさないモデル設計を目指す 特徴量エンジニアリング プレイ/ソーシャル行動、課金履歴、属性、 時系列変化を捉える特徴量を設計 モデル選定と検証 LightGBMと、行動の時系列パターンを 直接学習するLSTMの両面から検証を実施
運用設計 Vertex AI Pipelinesで再現性あるMLパイプ ラインを構築。定期実行の仕組みを実装 離脱定義は「翌月・翌々月の離脱」として設計 12
ベースライン構築 LightGBMを用いた基本モデルの作成 特徴量追加とハイパラ調整 特徴量の追加や新規設計と、ハイパーパラメータの最適化 ユーザークラスタリングによるモデル分割とチューニング、新規特徴量の精査 LSTM vs LightGBM / アンサンブルの検討
LightGBMとLSTMの両軸で最適モデルの検討 最終チューニング 過学習を防ぐチューニング、相関の高い特徴量の排除 モデル改善プロセス 1 2 3 4 5 13 ハイリスク群/ロイヤル群のクラスタ分割とモデル最適化
ベースライン構築 LightGBMを用いた基本モデルの作成 特徴量追加とハイパラ調整 特徴量の追加や新規設計と、ハイパーパラメータの最適化 ハイリスク群/ロイヤル群のクラスタ分割とモデル最適化 ユーザークラスタリングによるモデル分割とチューニング、新規特徴量の精査 LSTM vs LightGBM /
アンサンブルの検討 LightGBMとLSTMの両軸で最適モデルの検討 最終チューニング 過学習を防ぐチューニング、相関の高い特徴量の排除 モデル改善プロセス 1 2 3 4 5 14 F2 : 36%
ベースライン構築 LightGBMを用いた基本モデルの作成 特徴量追加とハイパラ調整 特徴量の追加や新規設計と、ハイパーパラメータの最適化 ユーザークラスタリングによるモデル分割とチューニング、新規特徴量の精査 LSTM vs LightGBM / アンサンブルの検討
LightGBMとLSTMの両軸で最適モデルの検討 最終チューニング モデル改善プロセス 1 2 3 4 5 15 過学習を防ぐチューニング、相関の高い特徴量の排除 F2 : 59% ハイリスク群/ロイヤル群のクラスタ分割とモデル最適化
ベースライン構築 LightGBMを用いた基本モデルの作成 特徴量追加とハイパラ調整 ハイリスク群/ロイヤル群のクラスタ分割とモデル最適化 ユーザークラスタリングによるモデル分割とチューニング、新規特徴量の精査 LSTM vs LightGBM / アンサンブルの検討
LightGBMとLSTMの両軸で最適モデルの検討 最終チューニング モデル改善プロセス 1 2 3 4 5 16 過学習を防ぐチューニング、相関の高い特徴量の排除 F2 : 71.5% 目標ライン達成! 特徴量の追加や新規設計と、ハイパーパラメータの最適化
ベースライン構築 LightGBMを用いた基本モデルの作成 特徴量追加とハイパラ調整 ユーザークラスタリングによるモデル分割とチューニング、新規特徴量の精査 LSTM vs LightGBM / アンサンブルの検討 LightGBMとLSTMの両軸で最適モデルの検討
最終チューニング モデル改善プロセス 1 2 3 4 5 17 過学習を防ぐチューニング、相関の高い特徴量の排除 F2 : 75.7% 目標ライン達成! ハイリスク群/ロイヤル群のクラスタ分割とモデル最適化 特徴量の追加や新規設計と、ハイパーパラメータの最適化
達成した成果 ・高精度の離脱予測モデル構築 次フェーズの計画 • 予測結果に基づく施策の設計と実行 • 施策効果検証の仕組み構築 • モデルの他プロダクト横展開 最終的な狙い:離脱防止による売上損失の抑制
成果と今後の展開 Recall 86%/F2 76%を達成 18
ML基盤の構築事例
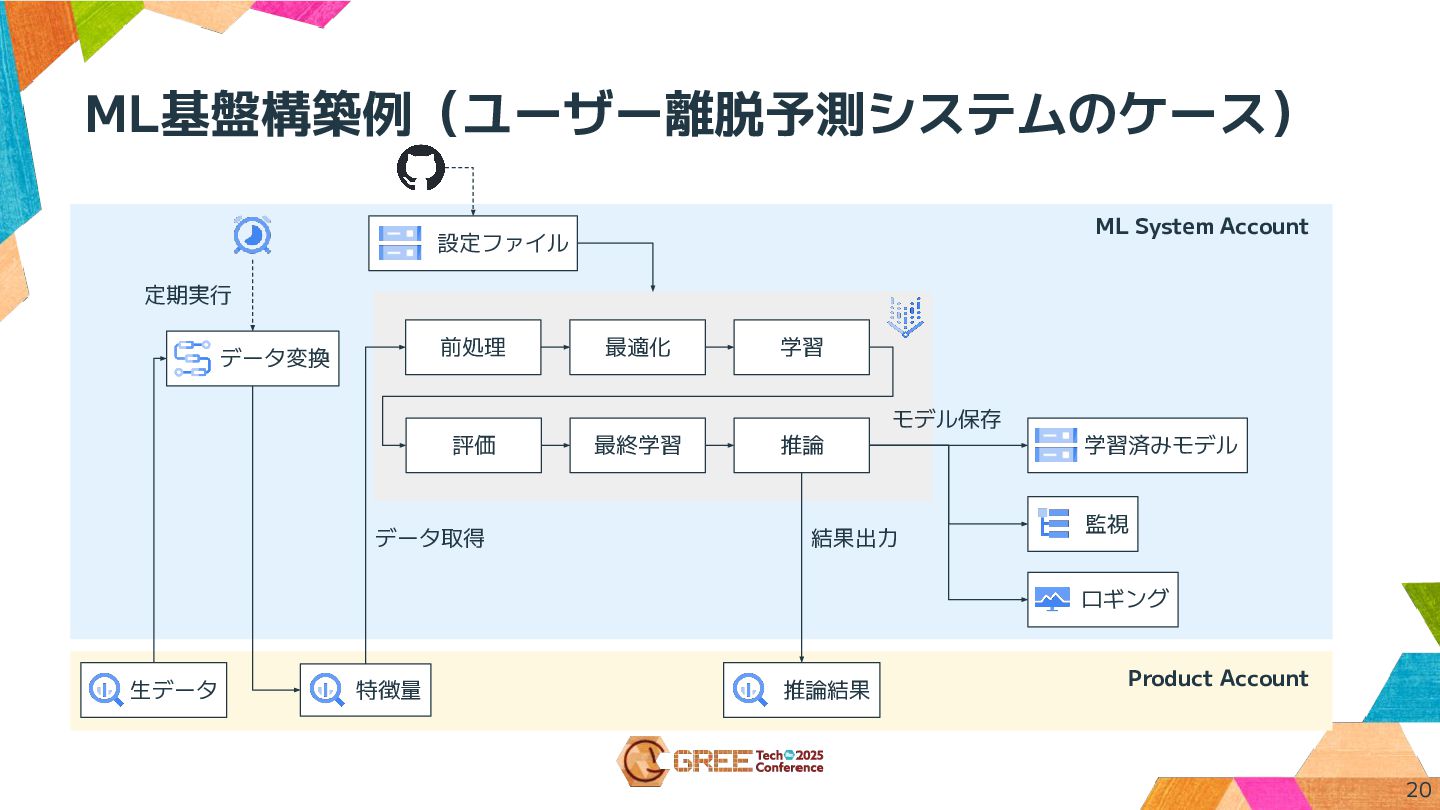
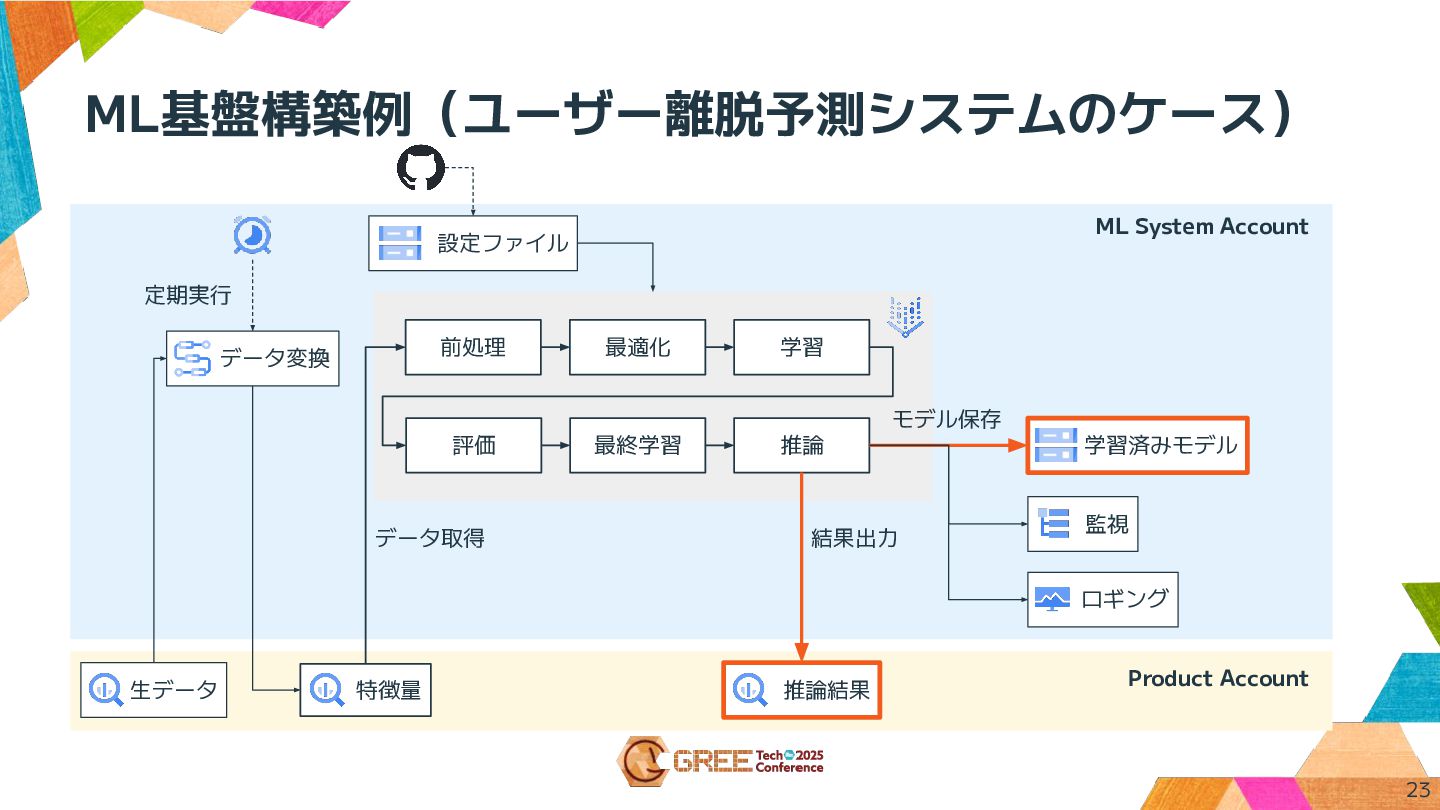
ML基盤構築例(ユーザー離脱予測システムのケース) Product Account 生データ データ変換 特徴量 前処理 最適化 学習 評価
最終学習 推論 モデル保存 データ取得 結果出力 推論結果 監視 定期実行 学習済みモデル 設定ファイル ロギング ML System Account 20
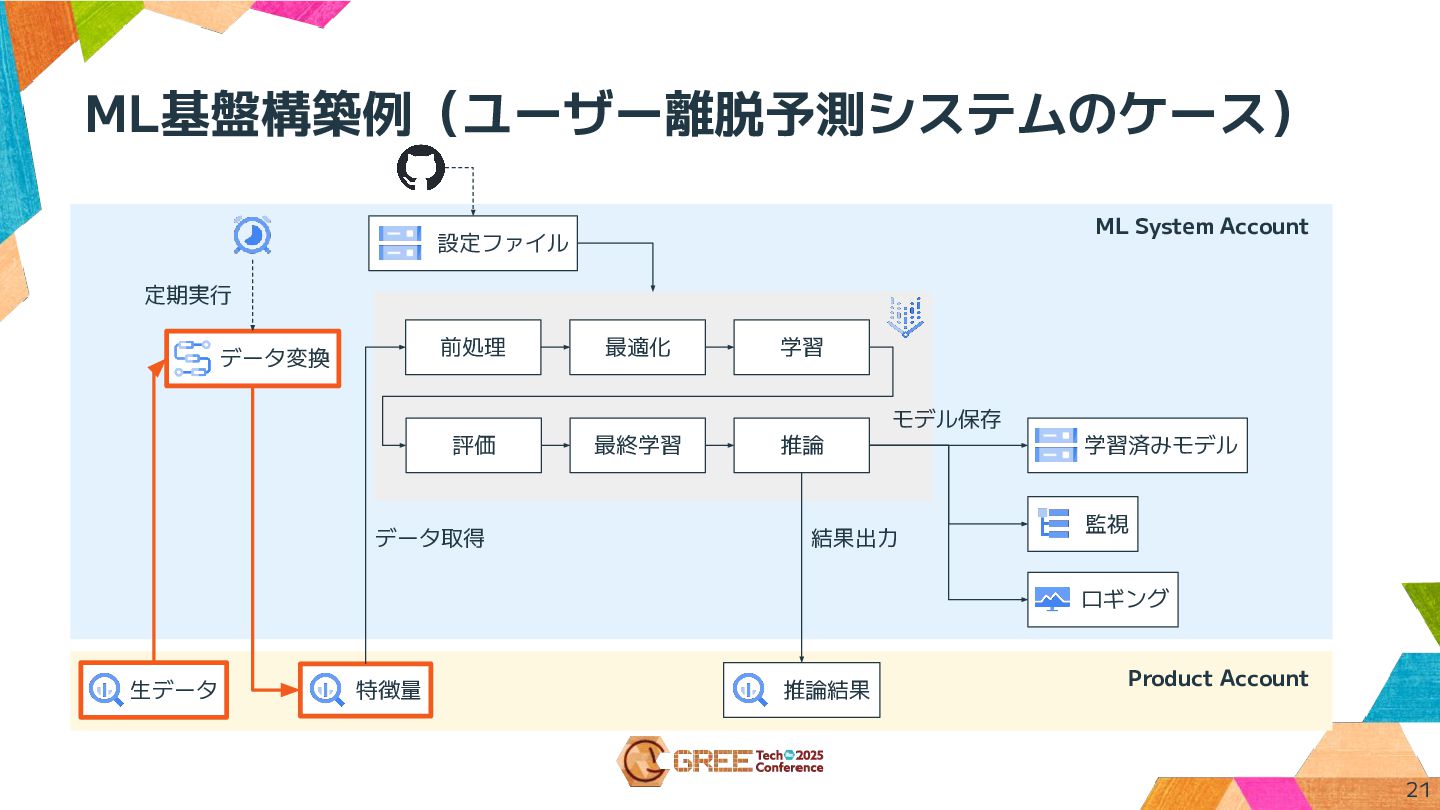
ML基盤構築例(ユーザー離脱予測システムのケース) Product Account 生データ データ変換 特徴量 前処理 最適化 学習 評価
最終学習 推論 モデル保存 データ取得 結果出力 推論結果 監視 定期実行 学習済みモデル 設定ファイル ロギング ML System Account 21
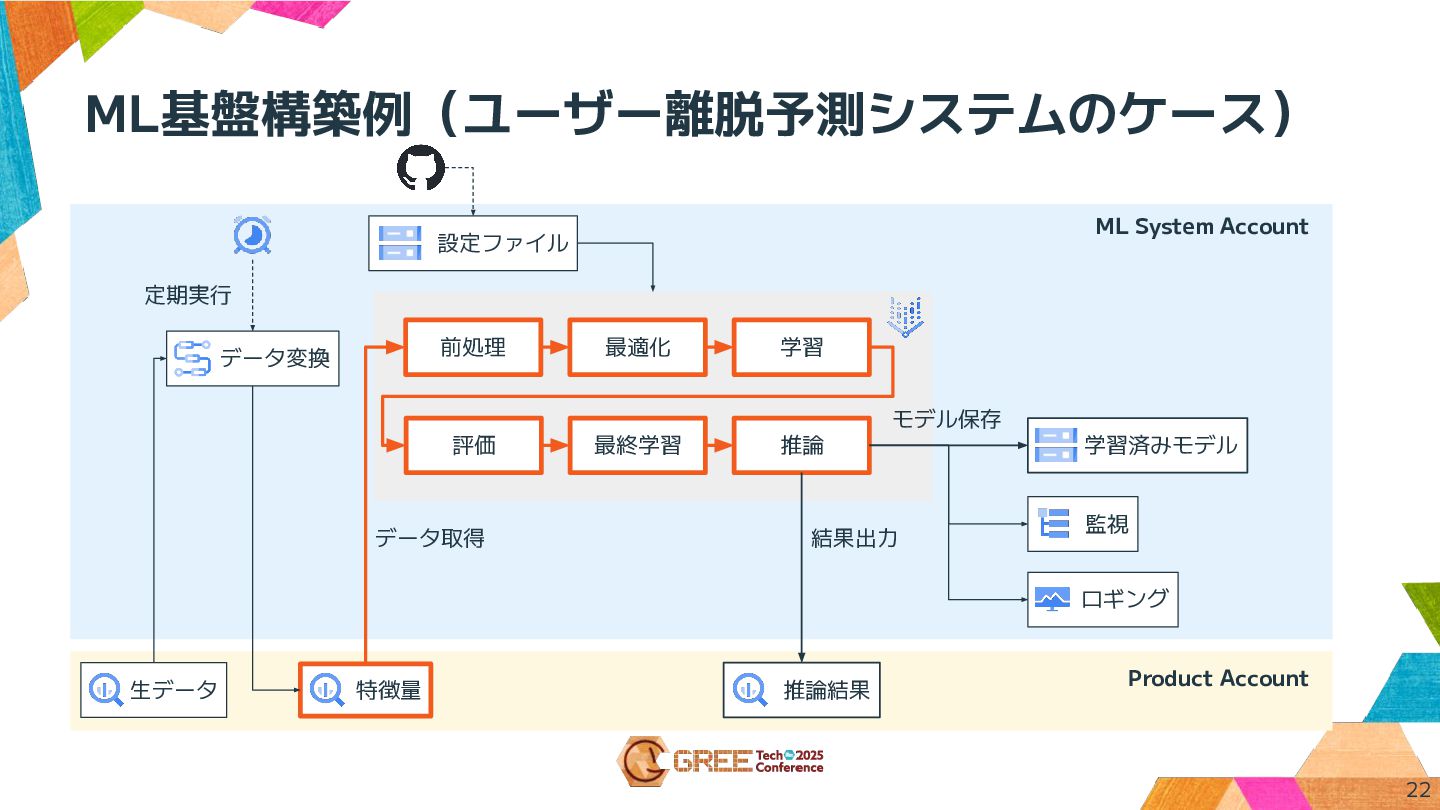
ML基盤構築例(ユーザー離脱予測システムのケース) Product Account 生データ データ変換 特徴量 前処理 最適化 学習 評価
最終学習 推論 モデル保存 データ取得 結果出力 推論結果 監視 定期実行 学習済みモデル 設定ファイル ロギング ML System Account 22
ML基盤構築例(ユーザー離脱予測システムのケース) Product Account 生データ データ変換 特徴量 前処理 最適化 学習 評価
最終学習 推論 モデル保存 データ取得 結果出力 推論結果 監視 定期実行 学習済みモデル 設定ファイル ロギング ML System Account 23
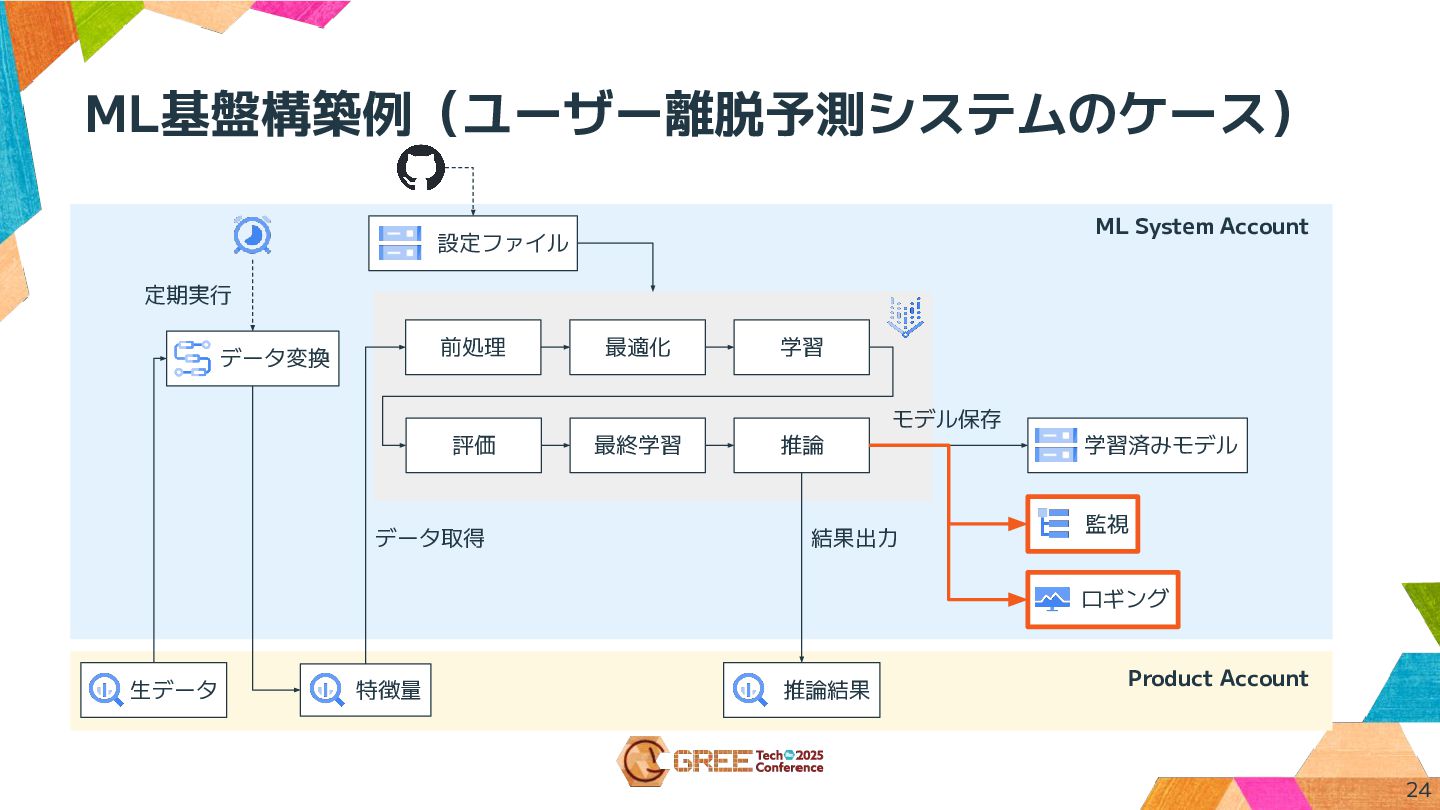
ML基盤構築例(ユーザー離脱予測システムのケース) Product Account 生データ データ変換 特徴量 前処理 最適化 学習 評価
最終学習 推論 モデル保存 データ取得 結果出力 推論結果 監視 定期実行 学習済みモデル 設定ファイル ロギング ML System Account 24
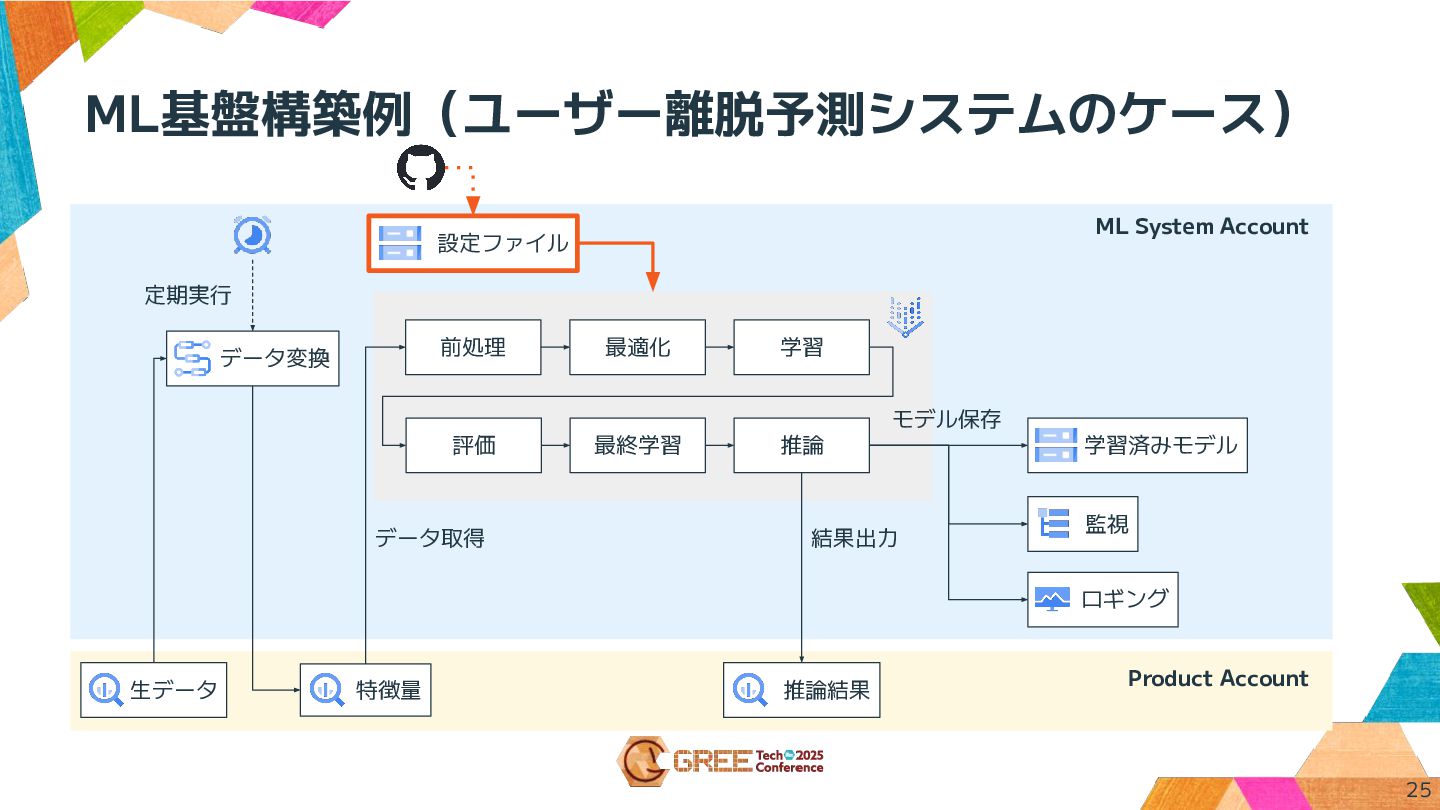
ML基盤構築例(ユーザー離脱予測システムのケース) Product Account 生データ データ変換 特徴量 前処理 最適化 学習 評価
最終学習 推論 モデル保存 データ取得 結果出力 推論結果 監視 定期実行 学習済みモデル 設定ファイル ロギング ML System Account 25
事例紹介2. 電子漫画制作におけるAI活用
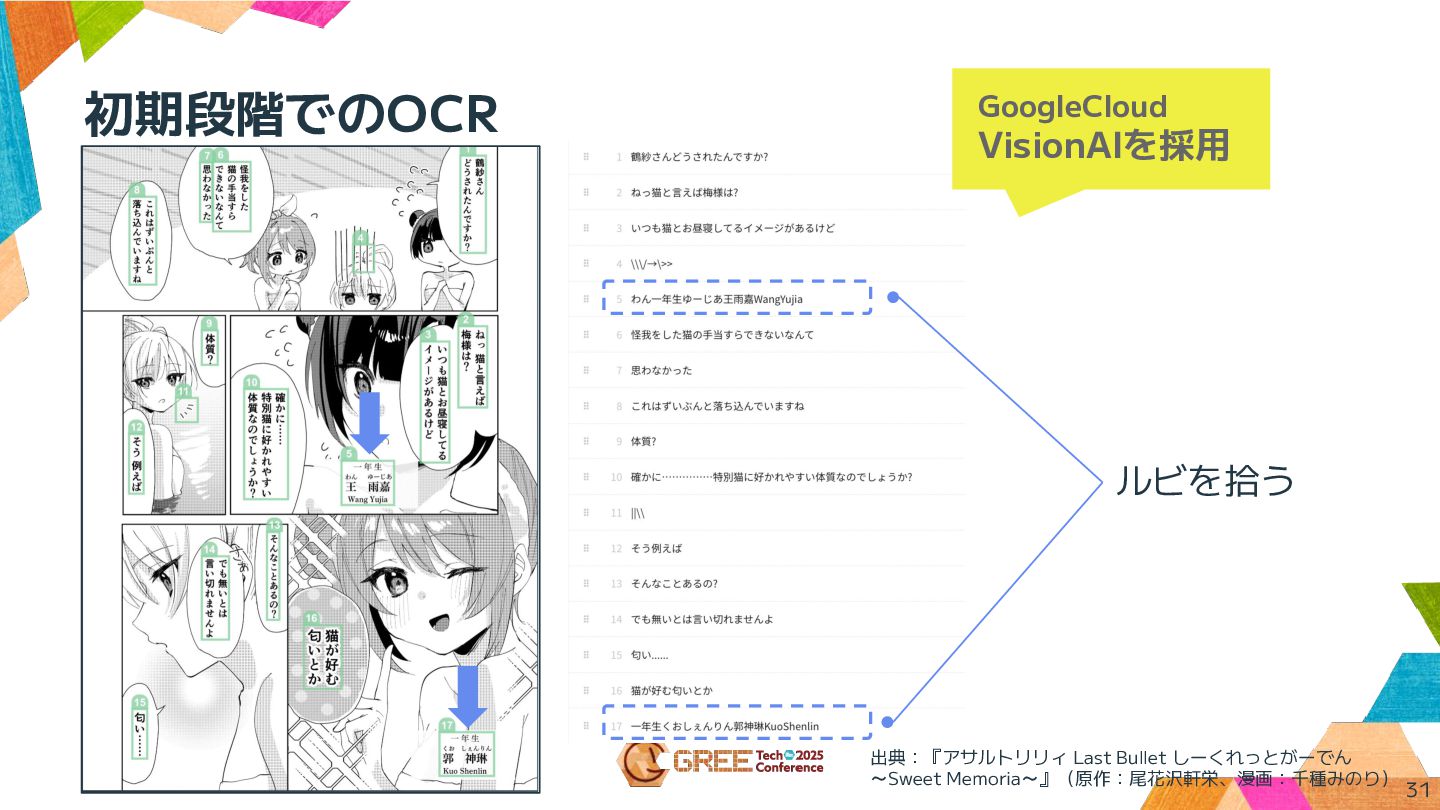
目的:クラウドツールを用いた漫画ローカライズにおける制作工数削減 開発したAIエンジン機能: • 漫画データのOCR処理(吹き出し/セリフの読み取り) • 多言語翻訳機能 • Inpainting(文字削除・背景修復)処理 電子漫画制作におけるAI活用 概要:電子漫画翻訳クラウドツールにおける、AI機能開発(グループ会社支援)
27
目的:クラウドツールを用いた漫画ローカライズにおける制作工数削減 開発したAIエンジン機能: • 漫画データのOCR処理(吹き出し/セリフの読み取り) • 多言語翻訳機能 • Inpainting(文字削除・背景修復)処理 電子漫画制作におけるAI活用 概要:電子漫画翻訳クラウドツールにおける、AI機能開発(グループ会社支援)
28 こちらに絞ってご紹介
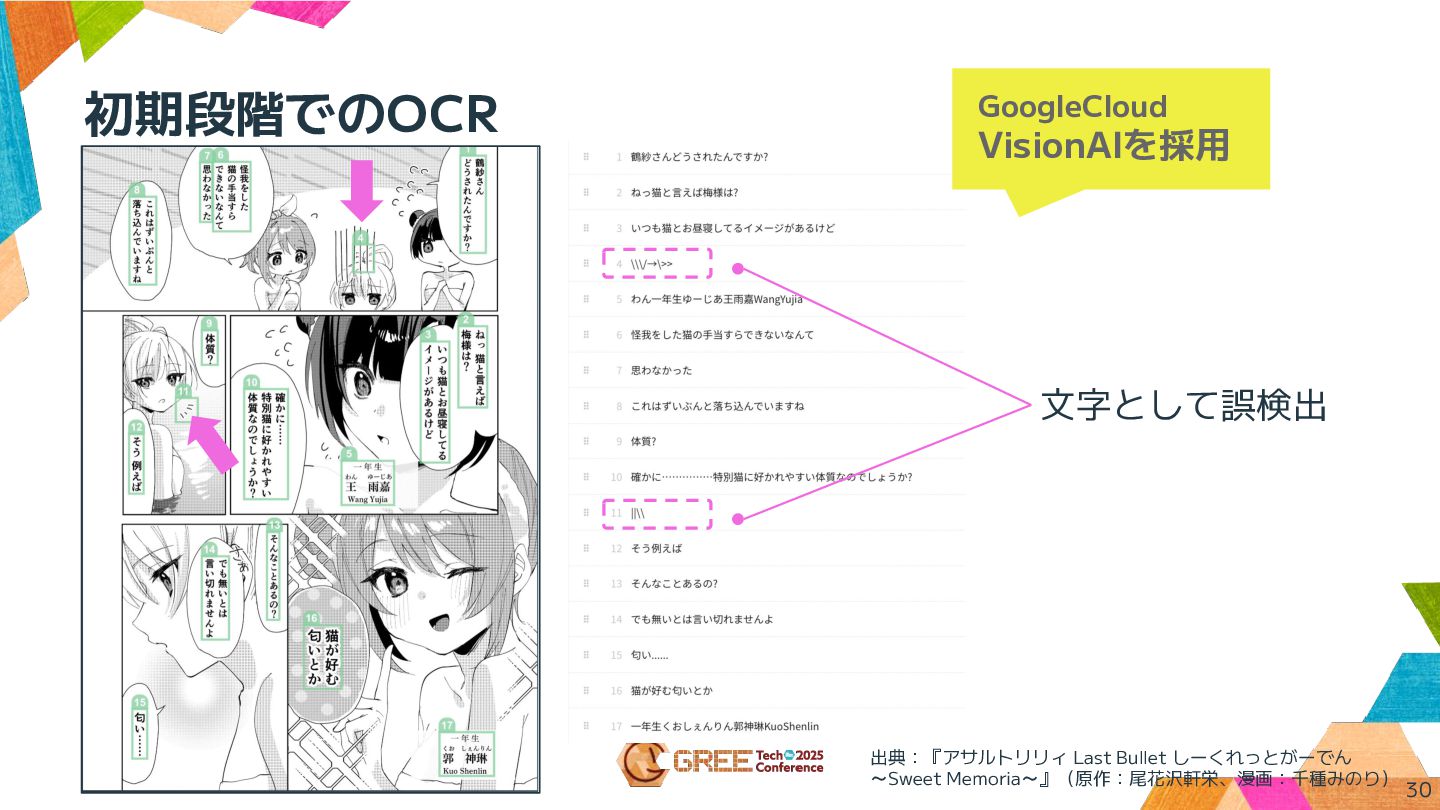
初期段階でのOCR 29 出典:『アサルトリリィ Last Bullet しーくれっとがーでん ~Sweet Memoria~』(原作:尾花沢軒栄、漫画:千種みのり) GoogleCloud VisionAIを採用
初期段階でのOCR 30 文字として誤検出 出典:『アサルトリリィ Last Bullet しーくれっとがーでん ~Sweet Memoria~』(原作:尾花沢軒栄、漫画:千種みのり) GoogleCloud
VisionAIを採用
初期段階でのOCR 31 ルビを拾う 出典:『アサルトリリィ Last Bullet しーくれっとがーでん ~Sweet Memoria~』(原作:尾花沢軒栄、漫画:千種みのり) GoogleCloud
VisionAIを採用
初期段階でのOCR 32 読順がでたらめ 出典:『アサルトリリィ Last Bullet しーくれっとがーでん ~Sweet Memoria~』(原作:尾花沢軒栄、漫画:千種みのり) GoogleCloud
VisionAIを採用
漫画のOCRの難しさ 33 漫画固有の課題への対処が必要!!
アプローチ①:Geminiへの置き換え Gemini 1.5 Proへの期待 ・マルチモーダル理解能力が高い ・BoundingBox(セリフの位置座標)が出力できる 34 そ う な
の ? "text":"そうなの?", "coords": [ { "x": 100, "y": 200 }, { "x": 300, "y": 200 }, { "x": 300, "y": 250 }, { "x": 100, "y": 250 } ] 出力例: × 位置座標が不正確 × オノマトペ(※)が検出できない (※)擬音語や擬態語 結果 →素のGeminiでは難しい
アプローチ②:Geminiのファインチューニング BoundingBoxの精度向上を目的とし、位置情報付きの学習データ400ページ分を用いて実施 Pros: 位置情報の精度は大幅に向上し、オノマトペもある程度認識 Cons: テキスト認識精度が大幅に劣化し、内容が崩壊するという問題が発生 位置情報とテキスト精度のトレードオフが課題 35
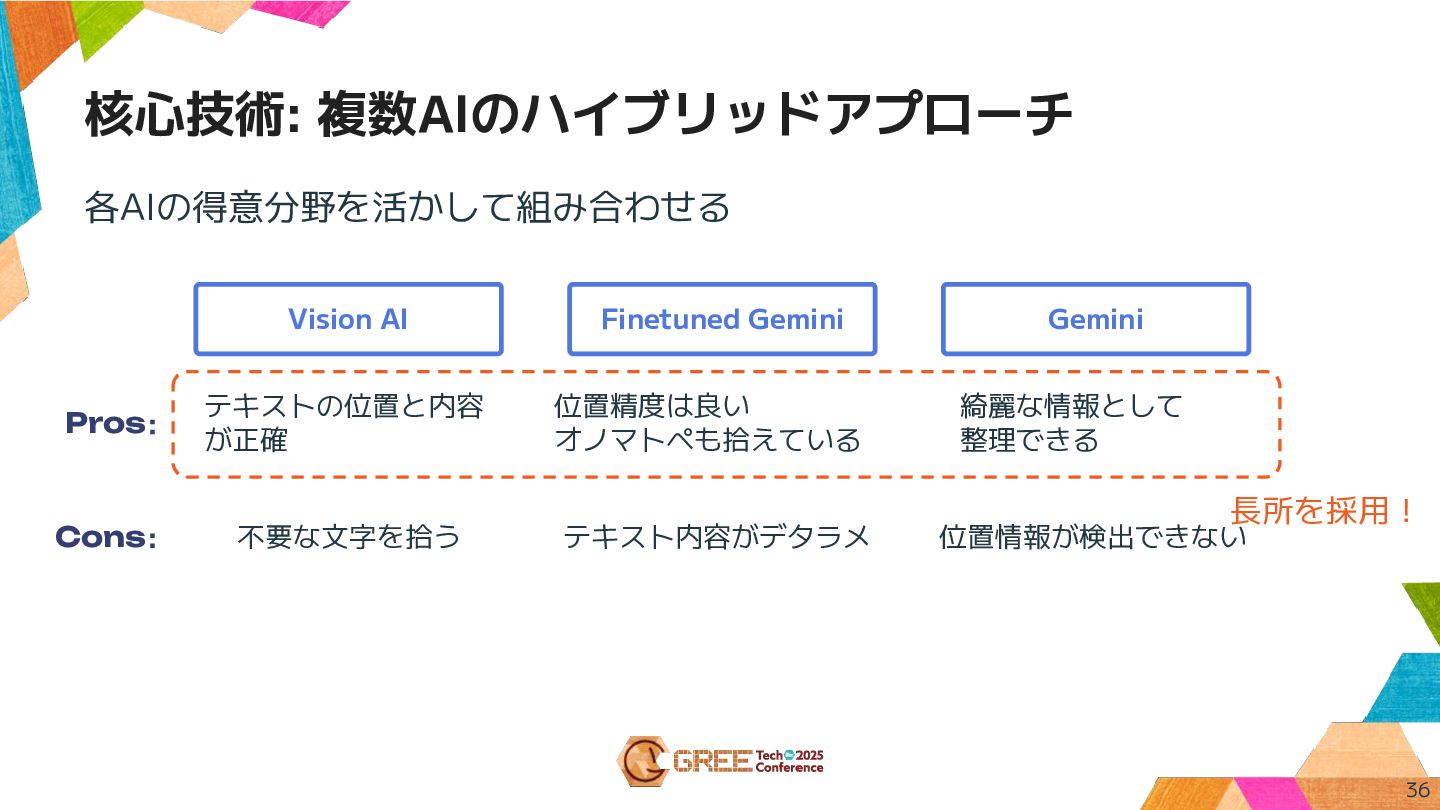
各AIの得意分野を活かして組み合わせる 核心技術: 複数AIのハイブリッドアプローチ Finetuned Gemini 36 Pros: Cons: テキストの位置と内容 が正確
不要な文字を拾う テキスト内容がデタラメ 位置精度は良い オノマトペも拾えている Vision AI 長所を採用! Gemini 綺麗な情報として 整理できる 位置情報が検出できない
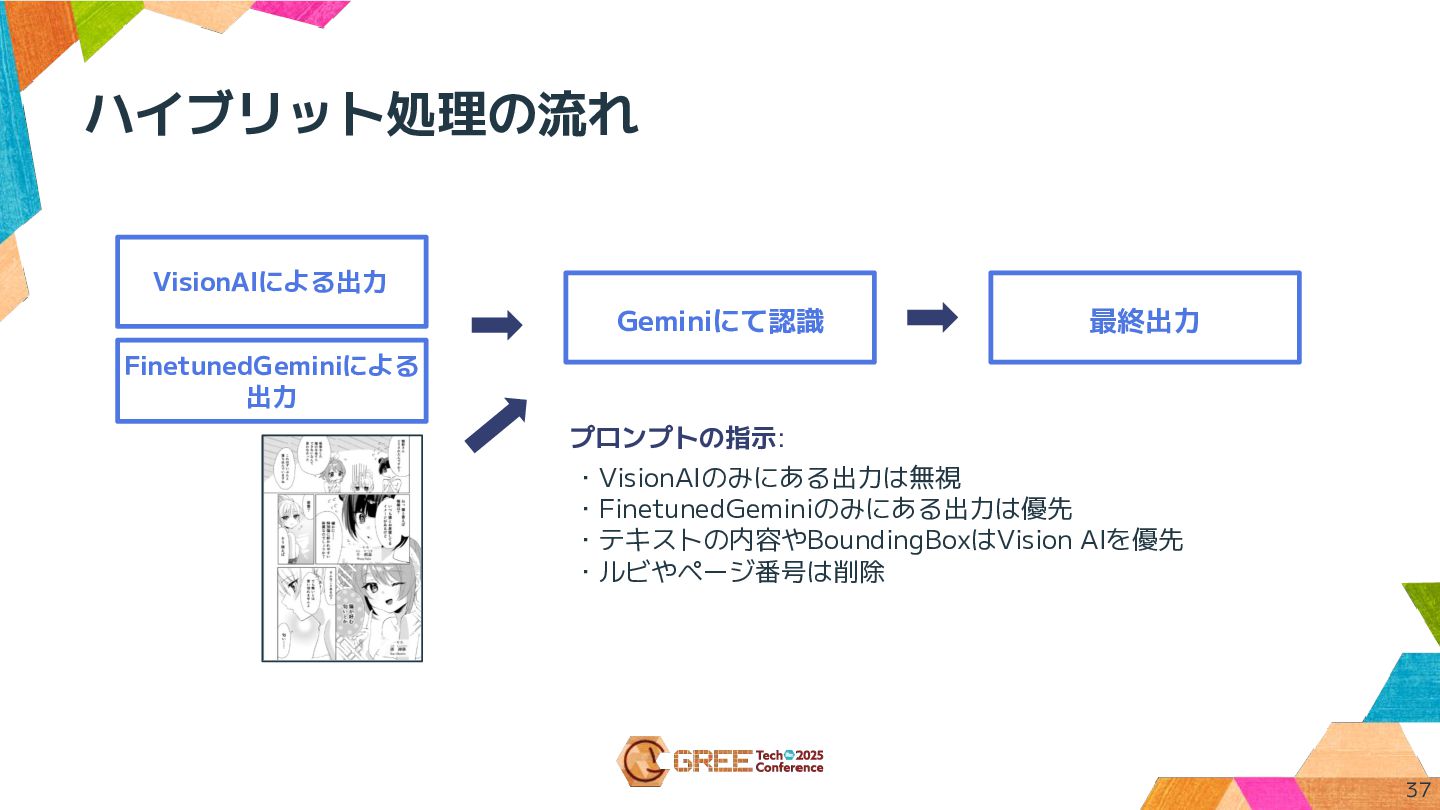
ハイブリット処理の流れ プロンプトの指示: FinetunedGeminiによる 出力 VisionAIによる出力 Geminiにて認識 最終出力 37 ・VisionAIのみにある出力は無視 ・FinetunedGeminiのみにある出力は優先
・テキストの内容やBoundingBoxはVision AIを優先 ・ルビやページ番号は削除
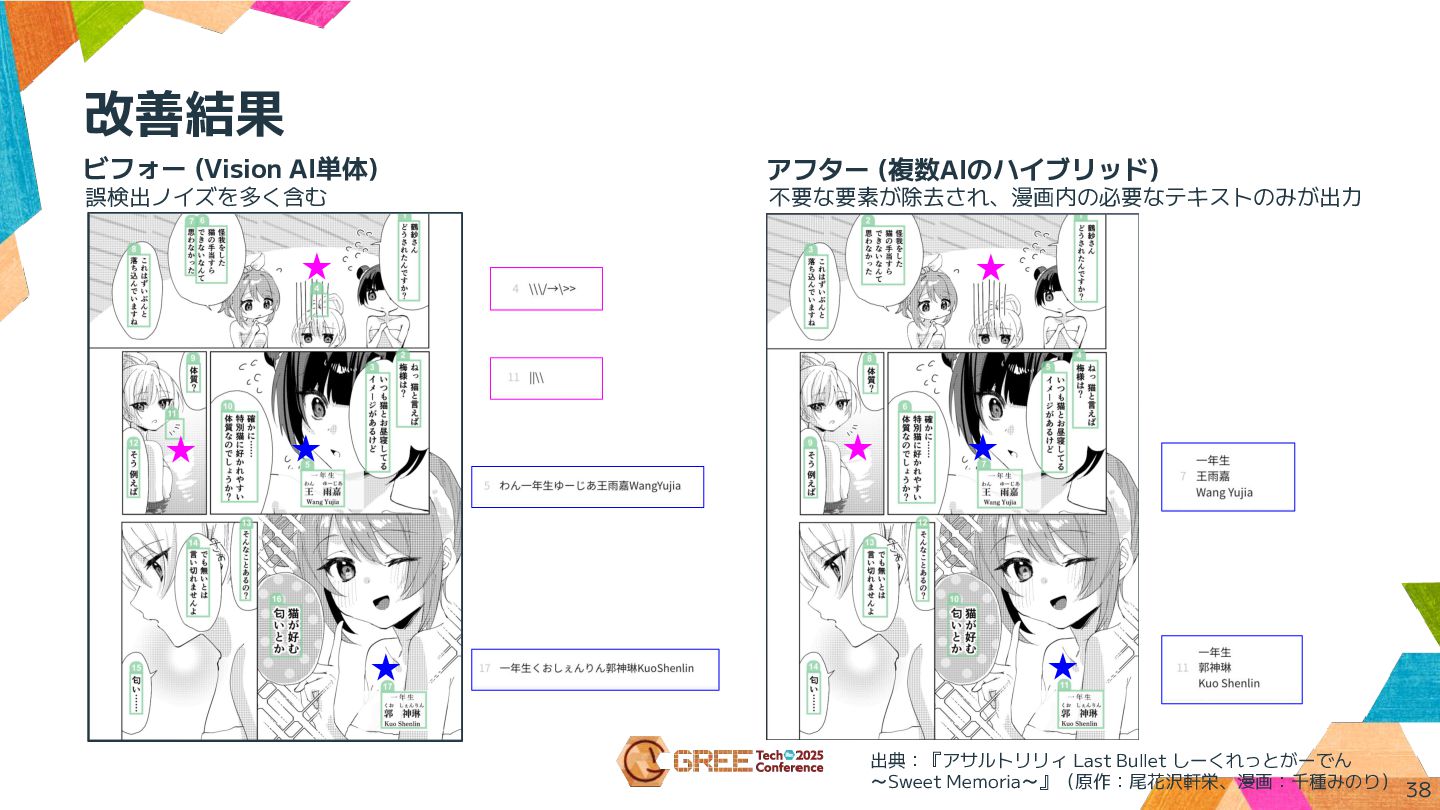
改善結果 ビフォー (Vision AI単体) アフター (複数AIのハイブリッド) 不要な要素が除去され、漫画内の必要なテキストのみが出力 38 誤検出ノイズを多く含む ★
★ ★ ★ ★ ★ ★ ★ 出典:『アサルトリリィ Last Bullet しーくれっとがーでん ~Sweet Memoria~』(原作:尾花沢軒栄、漫画:千種みのり)
追加改善:YOLO(物体検出モデル)による読順制御 39 ① ② ③ ④ ⑤ 物体検出モデル「YOLO」を活用し、マンガの「コマ」を正確に検出 コマの位置関係(右上から左下)に基づき、コマの進行順を決定 各コマの中のテキストの位置関係(右上から左下)に基づき、
セリフ順を決定 2.コマの進行順決定 3.コマの中の進行順決定 1.YOLOによるコマ検出 出典:『アサルトリリィ Last Bullet しーくれっとがーでん ~Sweet Memoria~』(原作:尾花沢軒栄、漫画:千種みのり)
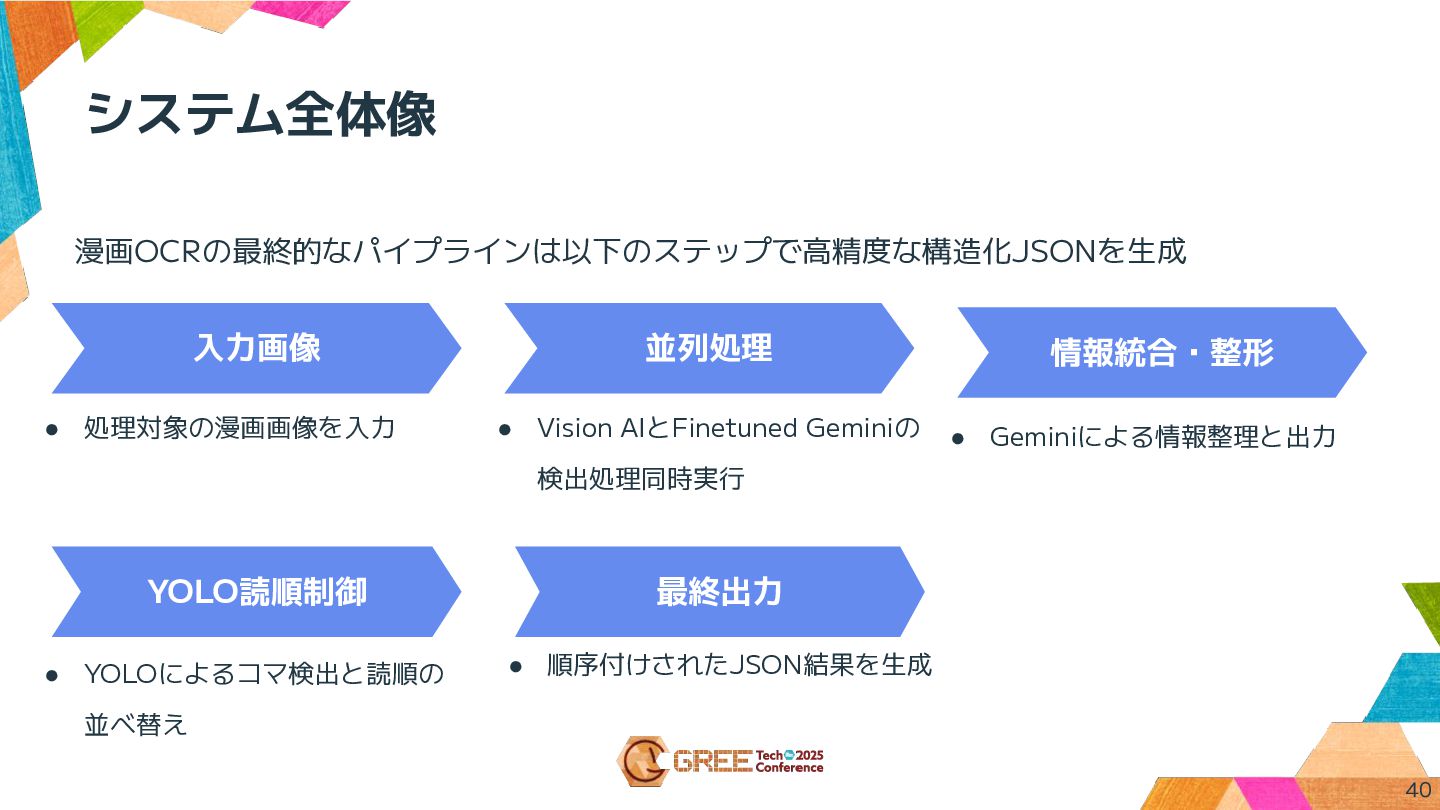
システム全体像 並列処理 • Vision AIとFinetuned Geminiの 検出処理同時実行 情報統合・整形 • Geminiによる情報整理と出力
YOLO読順制御 • YOLOによるコマ検出と読順の 並べ替え 最終出力 • 順序付けされたJSON結果を生成 入力画像 • 処理対象の漫画画像を入力 漫画OCRの最終的なパイプラインは以下のステップで高精度な構造化JSONを生成 40
その後 継続的な性能改善を進めている。 41 Geminiのバージョンアップに合わせてファインチューニングの再調整、プロンプトの微調整 を実施。 現時点では Gemini 2.0 を適用。
改善結果 42 出典:『ブラックジャックによろしく』(著者:佐藤秀峰)
改善結果 セリフについてはほぼ完璧な BoundingBoxとテキストを検出 出典:『ブラックジャックによろしく』(著者:佐藤秀峰)
改善結果 44 セリフ順も正しい 出典:『ブラックジャックによろしく』(著者:佐藤秀峰)
改善結果 オノマトペはまだ課題あり 出典:『ブラックジャックによろしく』(著者:佐藤秀峰)
実現した主な成果 90% 作業工数削減率 当初の課題だった「読み取り精度の低さによる大幅な手修正」から 手直しが約1割で済む レベルへと大幅に改善 成果 今後の展望 : 更なるGeminiの応用で翻訳プロセス全体を高速化する
1. AI翻訳の精度向上 :意訳や日本語特有の表現(オノマトペの表現など)で課題が残る 2. inpainting処理の改善 :現在はほぼ人手による修正が必要な状態 46
まとめ
まとめ 事例①: 離脱予測モデル実装 ・教科書的な手法を土台としつつ、ゲーム特性に合わせた特徴量を設計 ・モデル出力の解釈を次の改善につなげる循環的アプローチを確立 ・アナリストの分析力 × 事業部のドメイン知識 × モデル実装力により、高性能モデルを実現
事例②: OCR実装(Gemini応用) ・生成AIを適用し、ベースライン性能を維持しつつ電子漫画OCR特有の課題に対応 ・プロンプトエンジニアリングと複数モデルのハイブリッド活用により、大幅な制作工数削減を実現 48
まとめ 得られた示唆 技術 × ドメイン知識 × 推進体制 の3要素が不可欠である 今後のプロジェクトにも本アプローチを応用し、事業インパクトの最大化を目指す 事業価値につながるAI活用には
49
ご清聴ありがとうございました!
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}