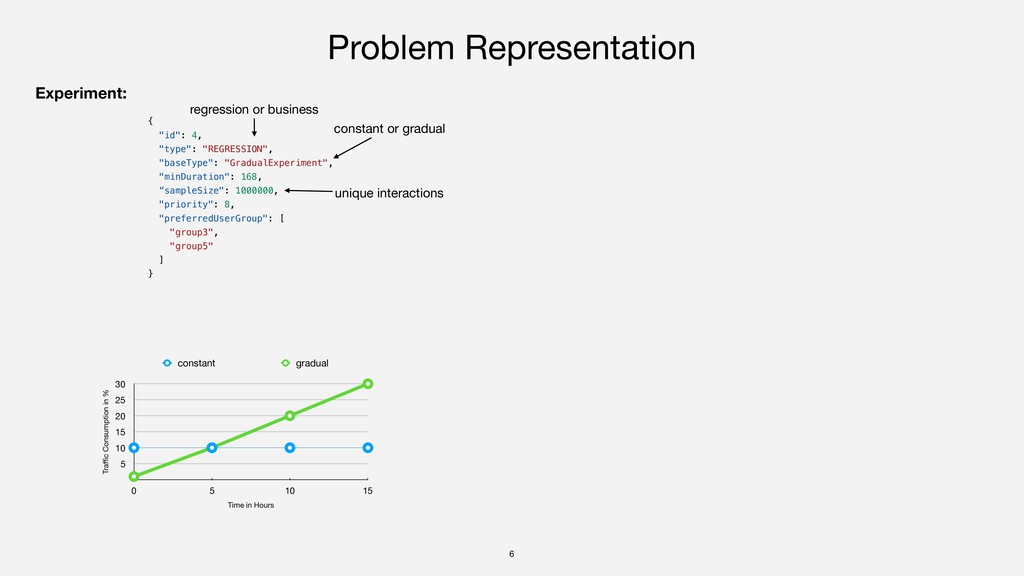
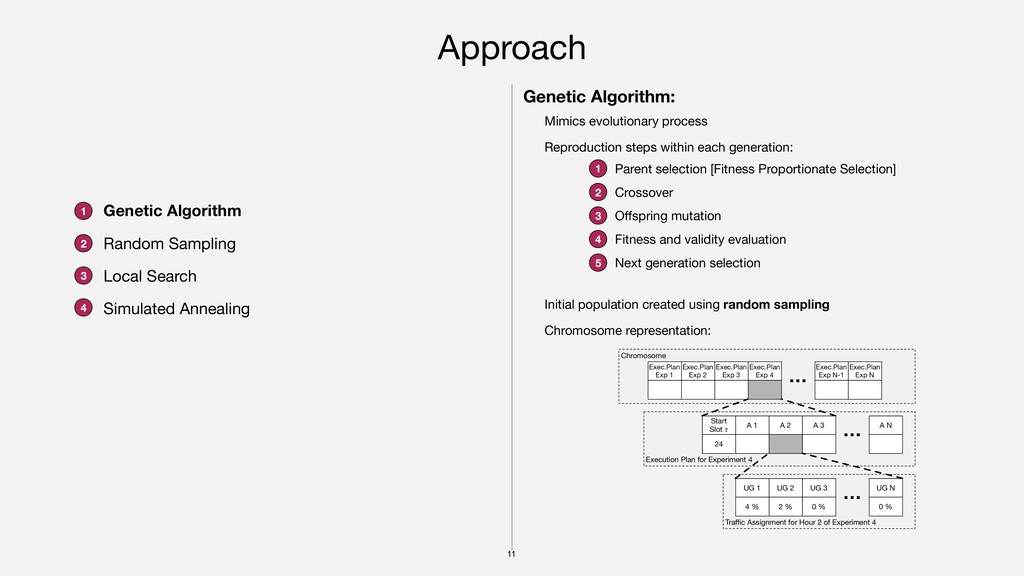
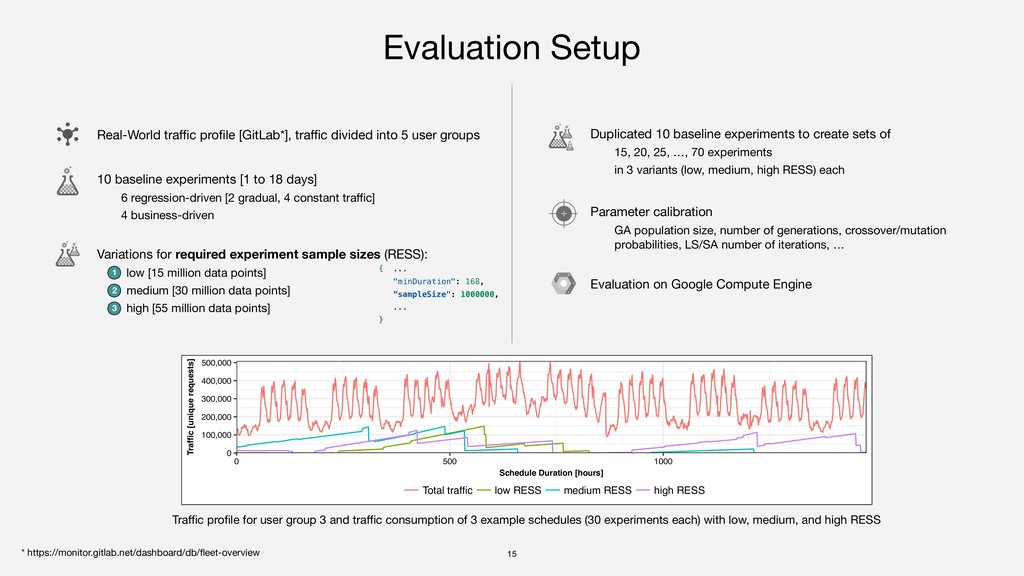
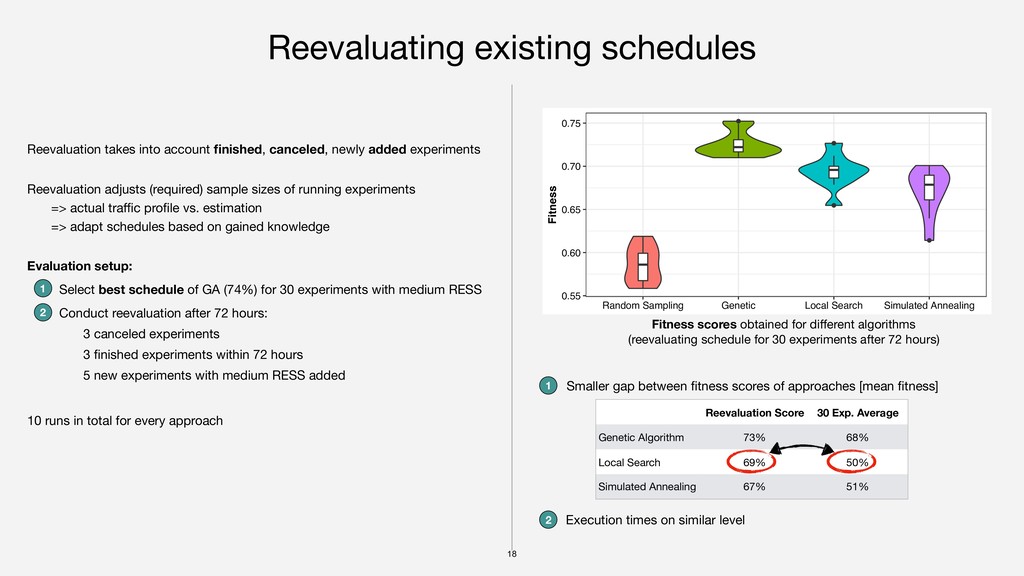
Real-World traffic profile [GitLab*], traffic divided into 5 user groups * https://monitor.gitlab.net/dashboard/db/fleet-overview Variations for required experiment sample sizes (RESS): low [15 million data points] medium [30 million data points] high [55 million data points] 10 baseline experiments [1 to 18 days] 6 regression-driven [2 gradual, 4 constant traffic] 4 business-driven 1 2 3 Duplicated 10 baseline experiments to create sets of 15, 20, 25, …, 70 experiments in 3 variants (low, medium, high RESS) each Parameter calibration GA population size, number of generations, crossover/mutation probabilities, LS/SA number of iterations, … Evaluation on Google Compute Engine 0 100,000 200,000 300,000 400,000 500,000 0 500 1000 Schedule Duration [hours] Traffic [unique requests] Total traffic low RESS medium RESS high RESS Traffic profile for user group 3 and traffic consumption of 3 example schedules (30 experiments each) with low, medium, and high RESS !15
{kind=link}
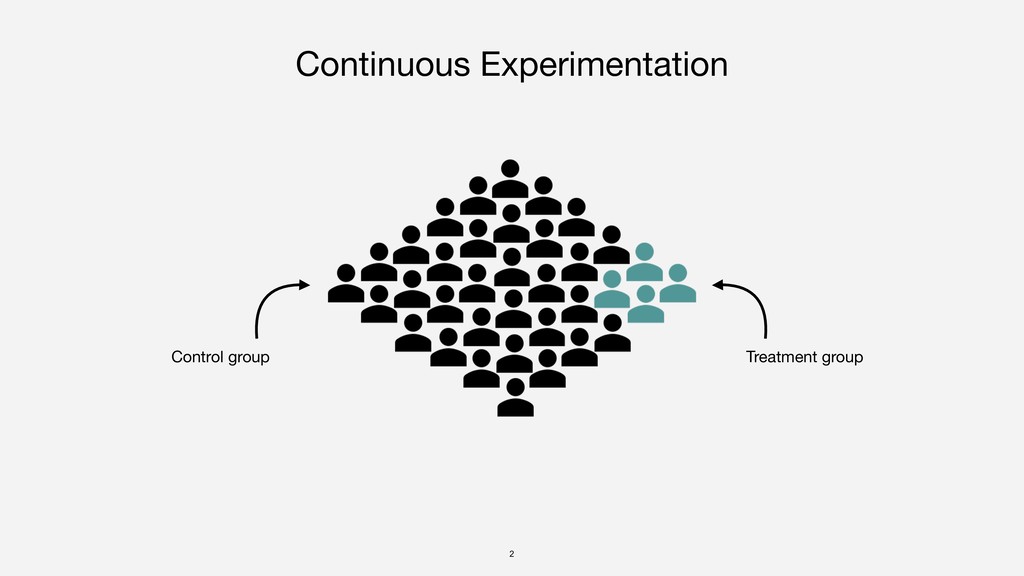{kind=link}
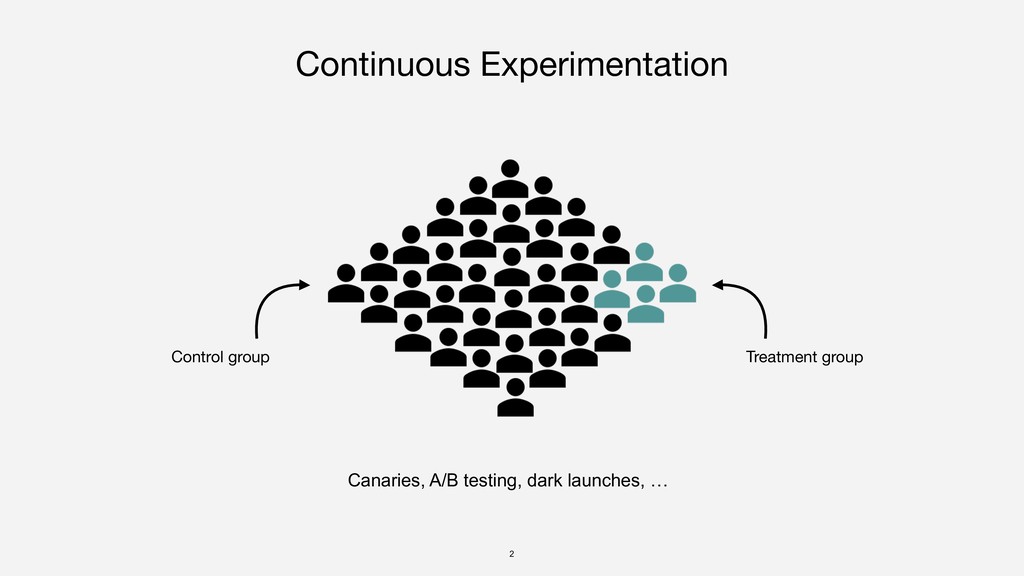{kind=link}
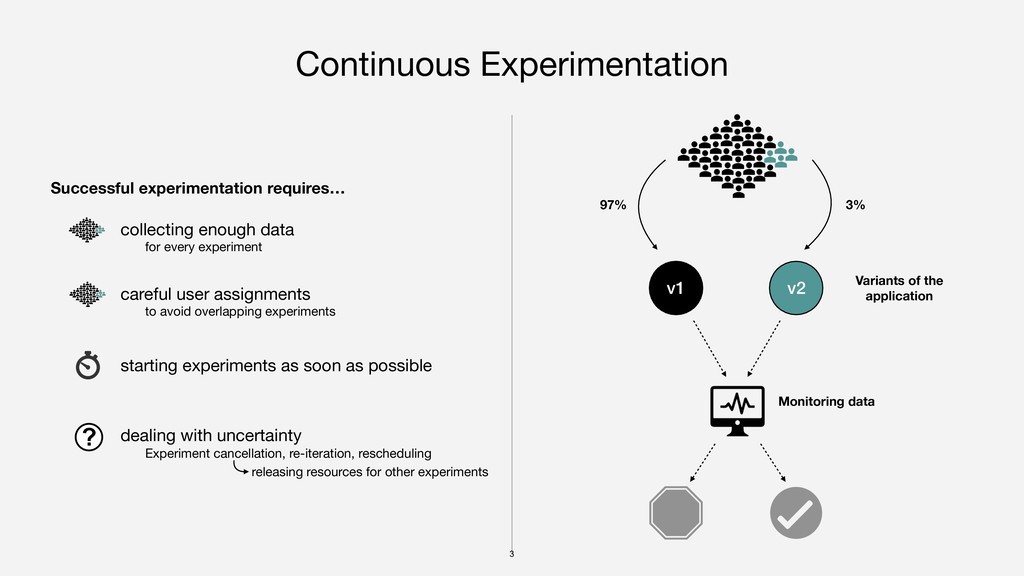{kind=link}
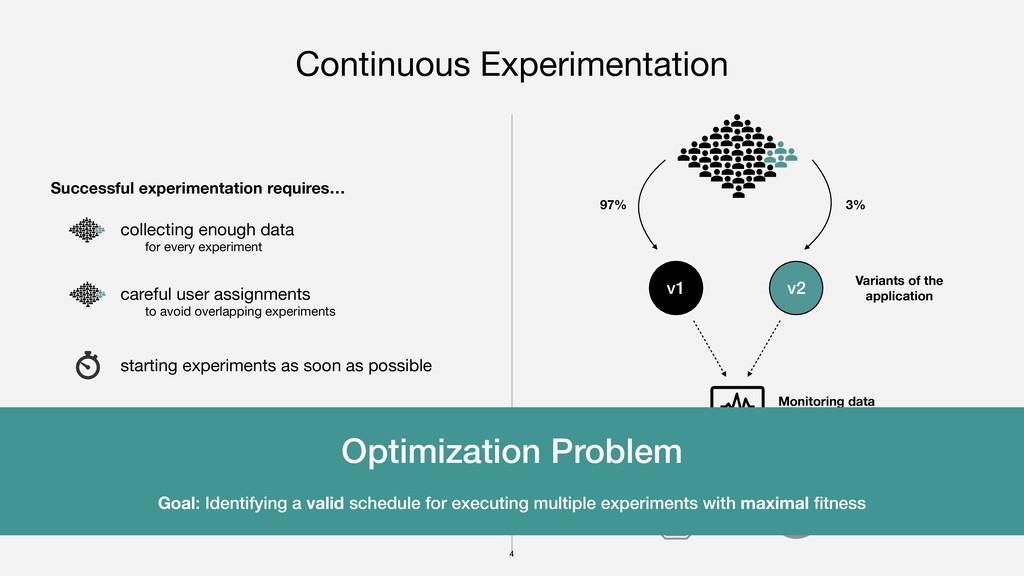{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}