Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介 4月4日
Search
gumigumi7
April 03, 2016
0
140
文献紹介 4月4日
gumigumi7
April 03, 2016
Tweet
Share
More Decks by gumigumi7
See All by gumigumi7
文献紹介 1月24日
gumigumi7
0
250
文献紹介 11月7日
gumigumi7
0
140
文献紹介 10月3日
gumigumi7
0
330
文献紹介 9月3日
gumigumi7
0
270
文献紹介 8月10日
gumigumi7
0
130
文献紹介 7月16日
gumigumi7
0
260
文献紹介 6月12日
gumigumi7
0
330
文献紹介 5月16日
gumigumi7
0
190
文献紹介 4月18日
gumigumi7
0
150
Featured
See All Featured
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.7k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.1k
Making the Leap to Tech Lead
cromwellryan
135
9.7k
A designer walks into a library…
pauljervisheath
210
24k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
120
The Curious Case for Waylosing
cassininazir
0
240
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
62
50k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
170
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
740
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
130
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
250
Transcript
文献紹介(2016/04/04) 長岡技術科学大学 B4 桾澤 優希 Microblogs as Parallel Corpora
文献 ▪ Wang Ling, Guang Xiang, Chris Dyer, Alan Black.
Microblogs as Parallel Corpora. In proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (pp.176–186)
概要 ▪ マイクロブログ(Twitterみたいなもの)からパラレルコーパス を作成する試み ▪ 一部のユーザーが2種類の言語で情報を発信することを 利用 ▪ マイクロブログ翻訳時に現存するパラレルコーパスと併用す ることで精度を向上
導入 ▪ Twitterやフェイスブックのようなマイクロブログでの文書スタ イルは様々 ▪ 口でしゃべる時のような表現 ▪ 例) R U
still with me or what? ▪ R → are , U → you ▪ 省略 ▪ 例) idk! , smh ▪ Idk → I don’t know, smh → shaking my head ▪ これらは機械翻訳などで問題となる ▪ それらに対応するためのデータが必要
導入 ▪ マイクロブログから自然発生したこれらの見つけ、抽出し、 それらに活用する ▪ ツイートが複数の言語を持っているか、それらが複数言語 感で対応が取れているかをチェックする手法の提案
理論 ▪ 一つ一つの文章に対して処理を行いスコアリング ▪ 以下の様なタプルを考える ▪ [p,q] , [u,v] は文字のインデックス
▪ l,r はそれぞれの言語 ▪ a は左と右のセグメントの単語アライメント
理論 ▪ モデルを3つに大雑把に分けて考える
理論 ▪ スパンスコア Ss ▪ セグメントが大きければ大きいほど大きな値を返す ▪ 変なところで区切る場合は Φ=0 とする
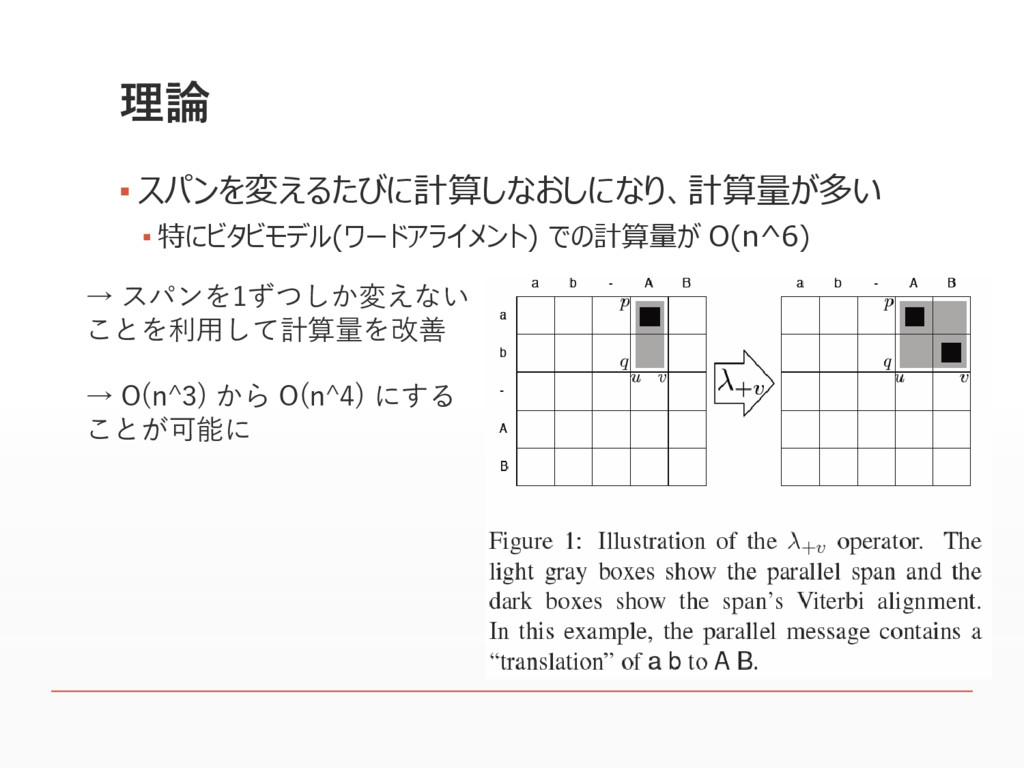
理論 ▪ スパンを変えるたびに計算しなおしになり、計算量が多い ▪ 特にビタビモデル(ワードアライメント) での計算量が O(n^6) → スパンを1ずつしか変えない ことを利用して計算量を改善
→ O(n^3) から O(n^4) にする ことが可能に
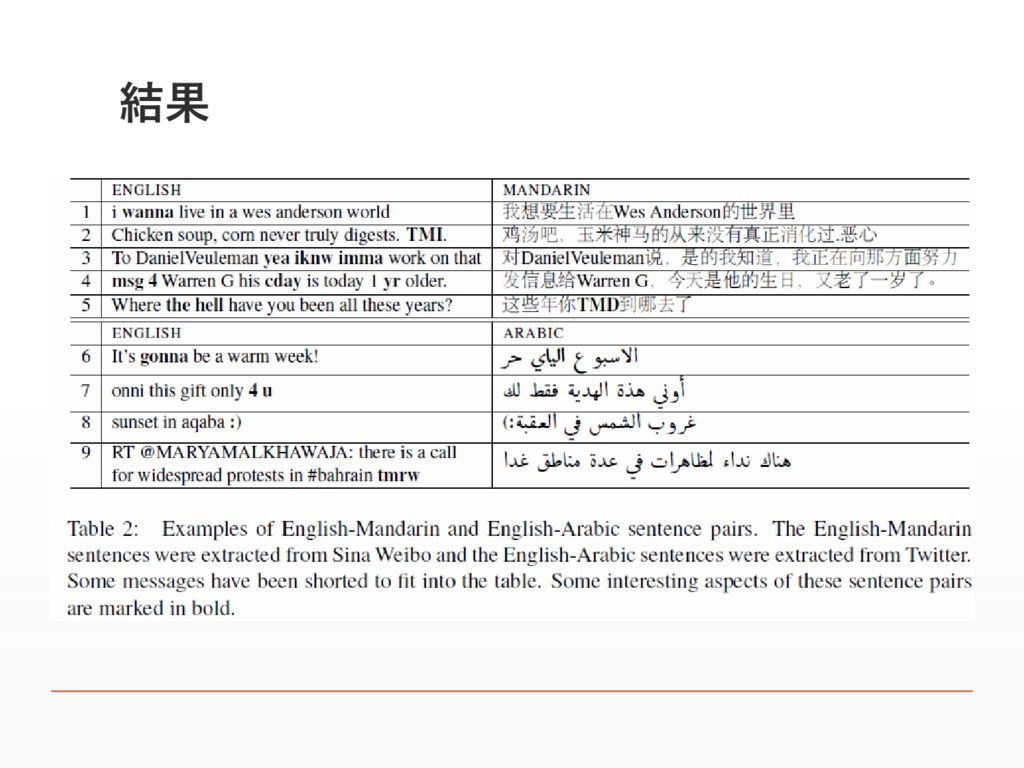
準備 ▪ TwitterとSinaWeibo(中国版Twitter)からツイートを 抽出 ▪ Twitterでは16億ツイート取得 ▪ SinaWeiboでは直近100ツイート中10ツイートが2種の言語を持つ ツイートをしているユーザーに関して6500万ツイートを取得 ▪
どちらの場合もユニコードの数字を用いて予めフィルタリング ▪ 例) ツイート中に3文字以上ラテン文字が含まれ、3文字以上中国語が 含まれる場合抽出
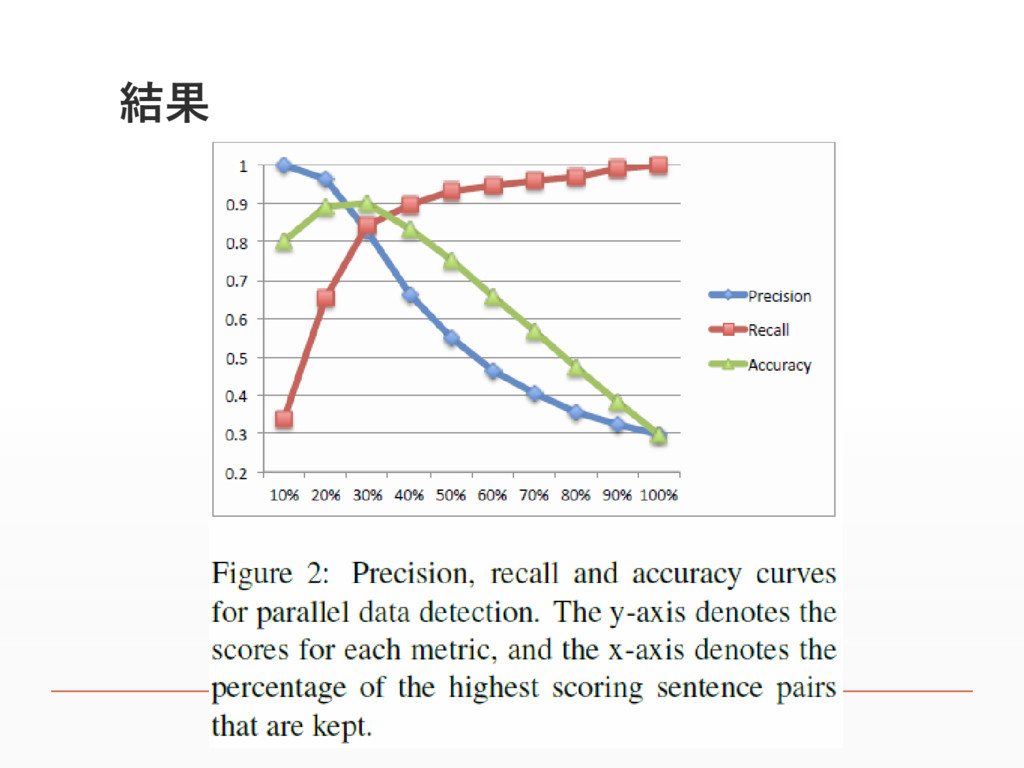
実験 ▪ 提案手法によってどれくらいのパラレルコーパスを取得でき るか ▪ フィルタリングしたSinaWeiboのツイートをランダムで2000 件抽出、スコアを計算する。 ▪ 上位n%を取った時の適合率、再現率、精度をグラフ化
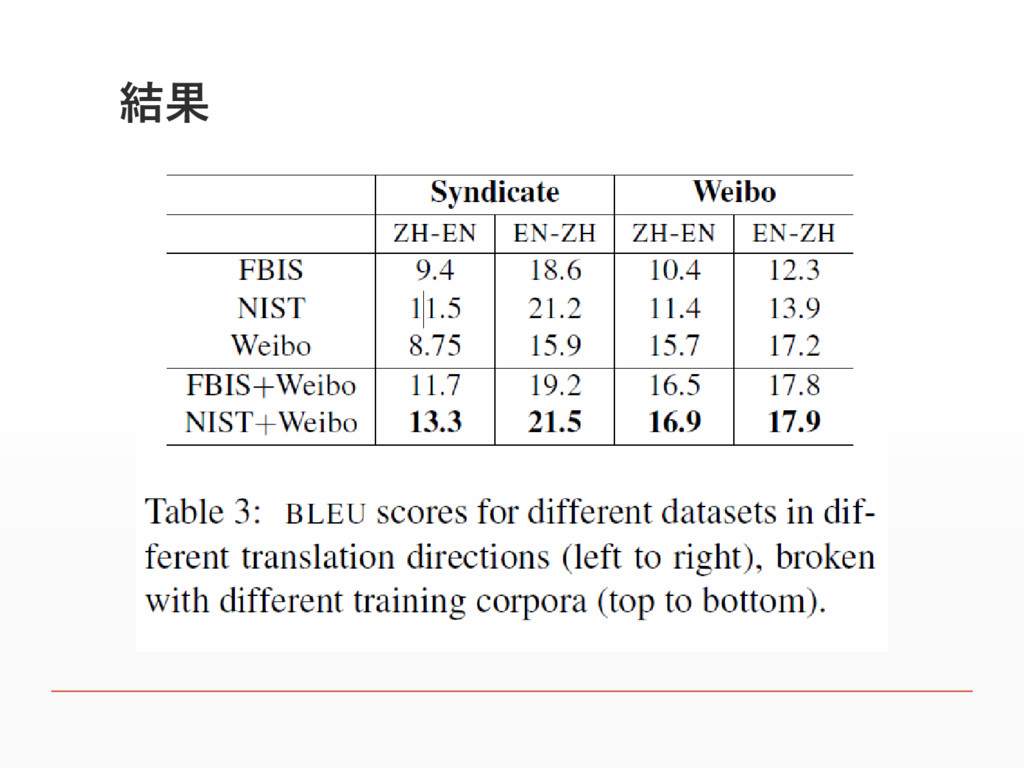
結果
結果
実験 ▪ 抽出したパラレルコーパスがどのくらい機械翻訳の性能向 上に寄与するか ▪ Project Syndicateから新たに作成したテストセットと Weiboから抽出したツイートをテストセットとして使用 ▪ ベースラインとしてNIST,FBISのデータセットを使用
▪ 抽出したデータセット単体と、それぞれを組み合わせて実験 ▪ BLEU値で比較
結果
まとめ ▪ 一文章から複数言語になっている部分を見つけ、抽出す る手法を提案した ▪ 機械翻訳のタスクに於いて既存のものにプラスして使用す ることで翻訳の性能向上できることを確認した。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![理論 ▪ 一つ一つの文章に対して処理を行いスコアリング ▪ 以下の様なタプルを考える ▪ [p,q] , [u,v] は文字のインデックス](https://files.speakerdeck.com/presentations/e3e12f8cbf124cc4b5e75cbb211b9e6d/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}