Caches und Suchindizes aktualisieren, Daten zwischen Microservices synchronisieren, Lesemodelle in CQRS-Architekturen erstellen, Datentransfers vom operativen System zu Analytics-Tools - nur einige der Use Cases, die das Streaming von Änderungen aus Datenbanken ermöglicht.
Der Vortrag führt in das Konzept von Change Data Capture (CDC) ein und beleuchtet, wie dieses mit Debezium realisiert werden kann, einer auf Apache Kafka basierenden Open-Source-CDC-Lösung. Wir betrachten, wie Debezium Änderungen aus Datenbanken wie MySQL, PostgreSQL und MongoDB erfasst, wie man auf Change Data Events in Beinahe-Echtzeit reagieren kann und wie Debezium die Korrektheit und Vollständigkeit der Daten sicherstellt, auch falls einmal etwas schief geht, etwa weil der Message-Broker vorübergehend ausfällt.
{kind=link}
{kind=link}
{kind=link}
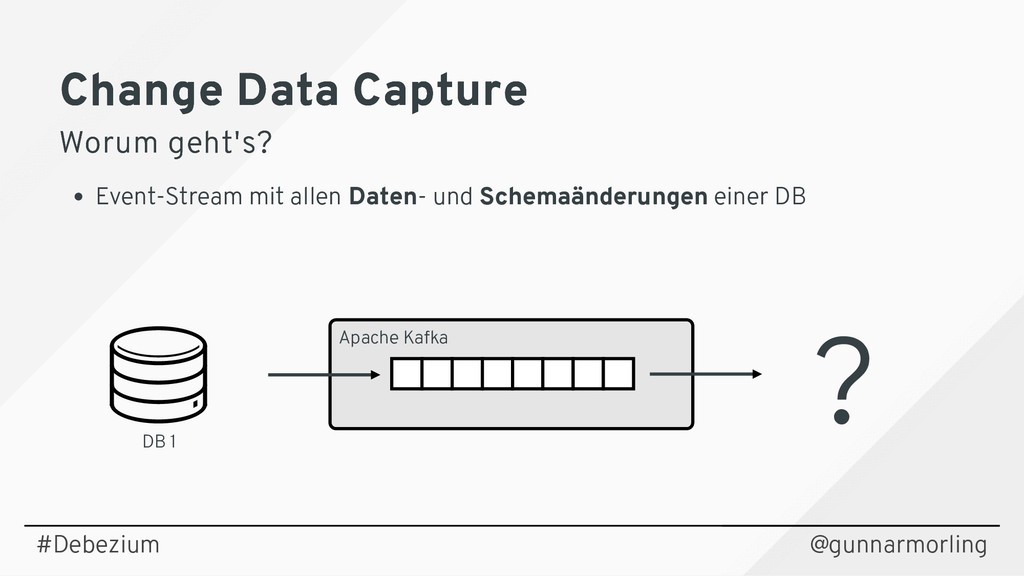{kind=link}
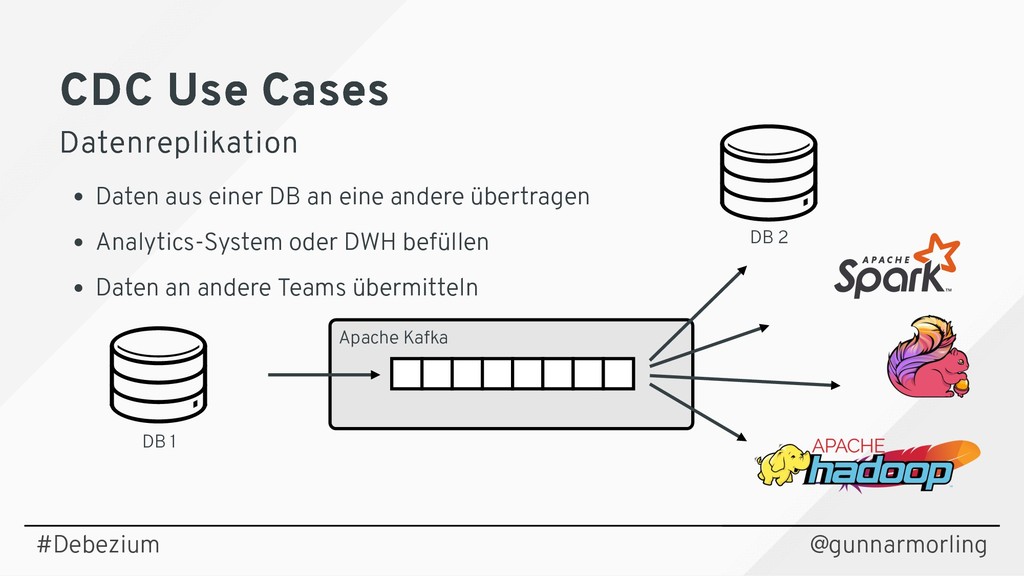{kind=link}
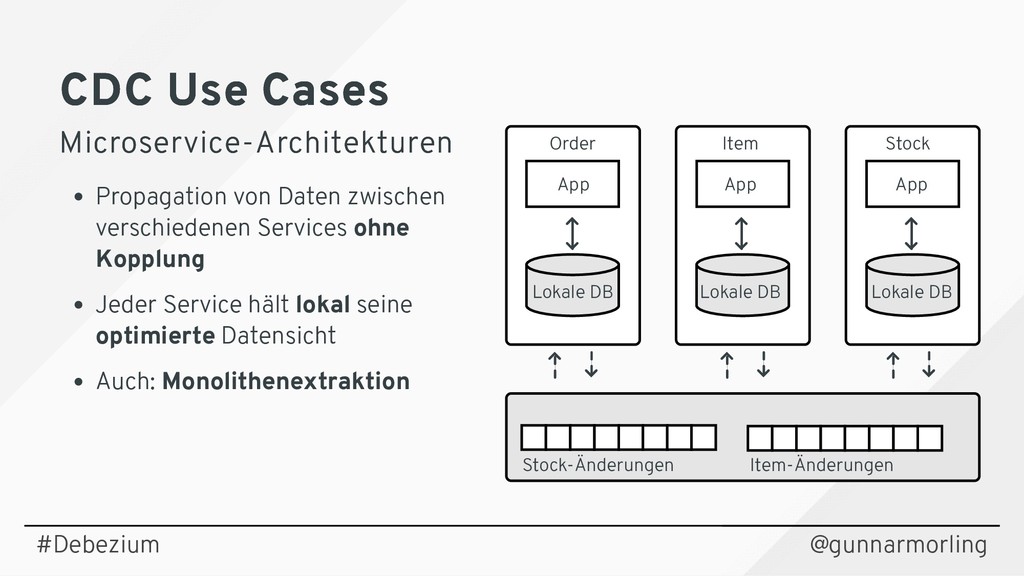{kind=link}
{kind=link}
{kind=link}
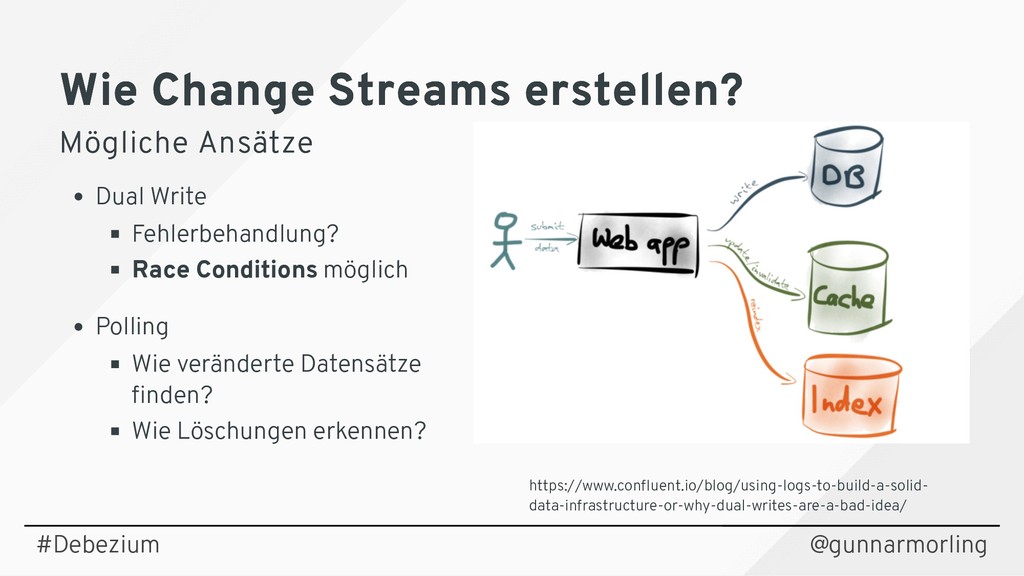{kind=link}
{kind=link}
{kind=link}
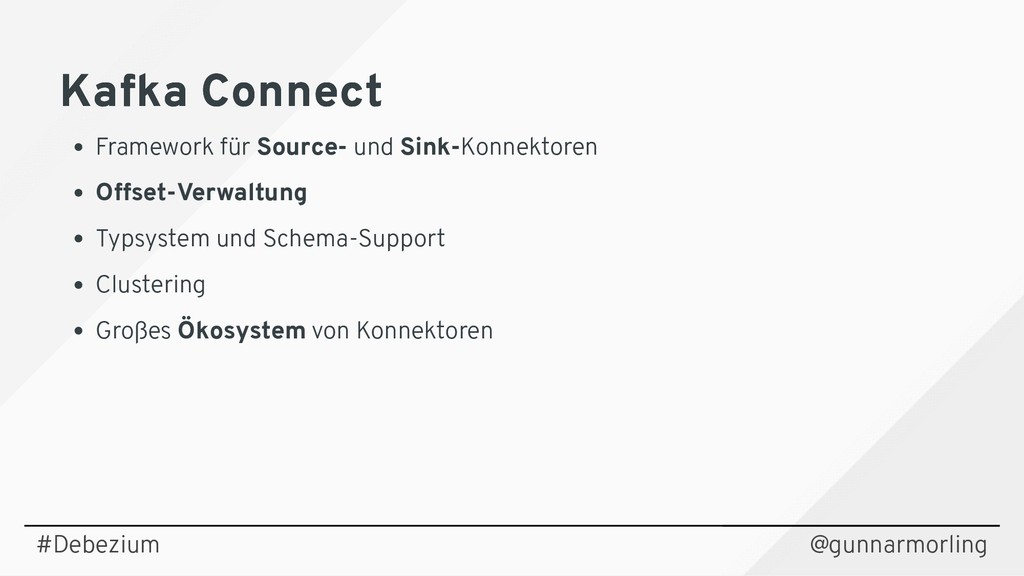{kind=link}
{kind=link}
{kind=link}
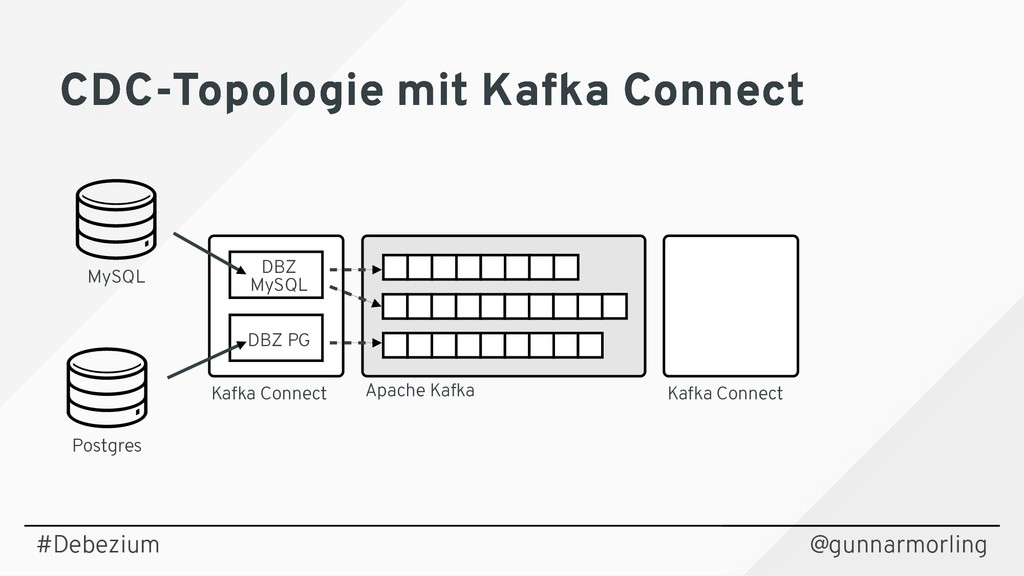{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
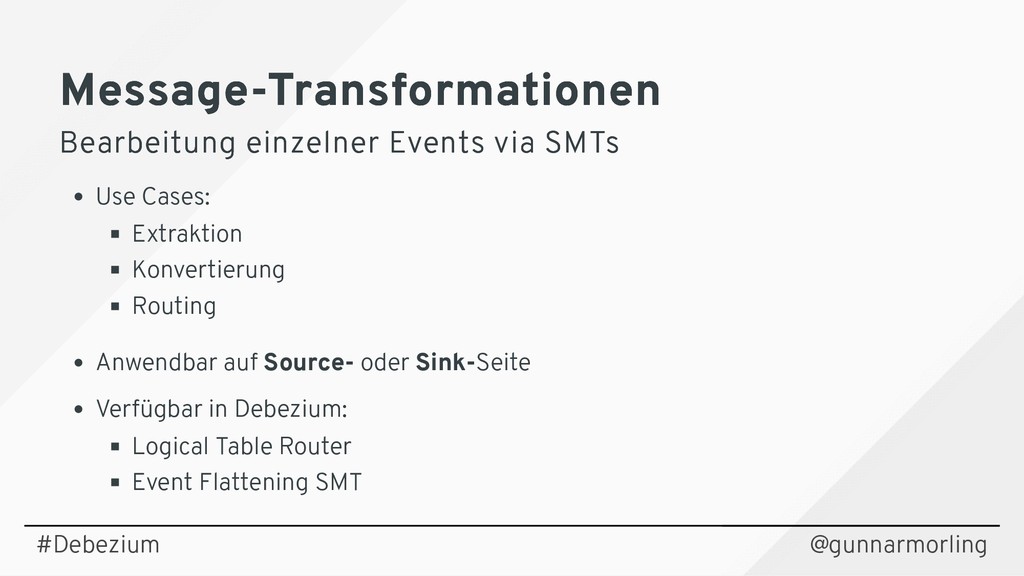{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}