Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【IR Reading 2025春】Persona-SQ: A Personalized Su...
Search
hon-do
May 24, 2025
Research
17
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【IR Reading 2025春】Persona-SQ: A Personalized Suggested Question Generation Framework For Real-world Documents
hon-do
May 24, 2025
Other Decks in Research
See All in Research
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
220
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
200
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
440
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.6k
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
Data Visualization Tools in the Age of AI
flekschas
0
170
量子コンピュータの紹介
oqtopus
0
360
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.2k
Fukui Shibiten 39 - AI Art
butchi
0
150
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
550
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
Featured
See All Featured
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
920
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Designing Experiences People Love
moore
143
24k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
380
The Language of Interfaces
destraynor
162
27k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Being A Developer After 40
akosma
91
590k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
260
Transcript
Persona-SQ: A Personalized Suggested Question Generation Framework For Real-world Documents
Zihao Lin, Zichao Wang, Yuanting Pan, Varun Manjunatha Ryan Rossi, Angela Lau, Lifu Huang, Tong Sun (NAACL2025) 論文紹介する人 筑波大学 本藤祐大
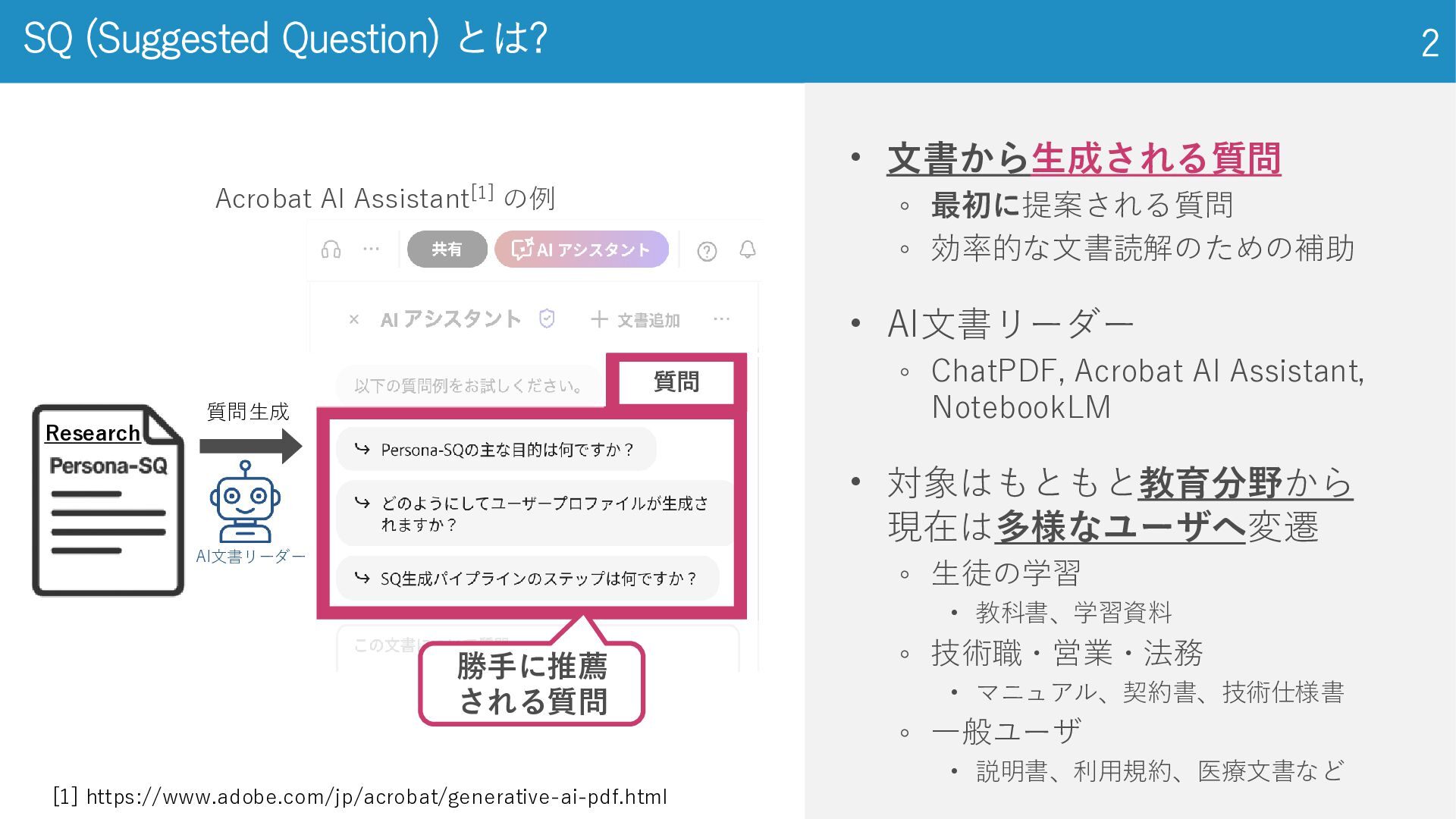
SQ (Suggested Question) とは? 2 • 文書から生成される質問 ◦ 最初に提案される質問 ◦
効率的な文書読解のための補助 • AI文書リーダー ◦ ChatPDF, Acrobat AI Assistant, NotebookLM • 対象はもともと教育分野から 現在は多様なユーザへ変遷 ◦ 生徒の学習 • 教科書、学習資料 ◦ 技術職・営業・法務 • マニュアル、契約書、技術仕様書 ◦ 一般ユーザ • 説明書、利用規約、医療文書など Research Acrobat AI Assistant[1] の例 [1] https://www.adobe.com/jp/acrobat/generative-ai-pdf.html 質問 質問生成 AI文書リーダー 勝手に推薦 される質問
Suggested Questionの課題 3 著作権 に関する 法律文書 現状のSQ生成:文書のみ → 質問化 •
文書は所有機関は? • いつ更新された? • どんな経緯で策定? リスク 経済効果 規制 法的責任 科学的根拠 メカニズム 「誰が読むか」を 無視して良いの? 経営者 弁護士 研究者 • 質問の同質化 ◦ 意図に沿わない不要な質問の量産 → 効果的ではない ◦ 情報要求を考慮できていない • どのくらい? ◦ ex. 法律ドメイン文書から質問生成 法律家のための質問ばかりで 法律家以外のユーザへの質問が少なく、 多様なユーザを考慮できない パーソナライズが必要 誰のための質問か? 偏りすぎてる..! 質問が 同質化
ユーザデータがない場合の 多様な情報要求を満たすアプローチが知りたい Whyこの論文? 4 • ユーザログがない場合の解決策 ◦ ログなしでもパーソナライズ実現がしたい ◦ 検索システム構築の際に、
多様なデータがいつも十分とは限らない • ペルソナ化の具体策 ◦ 仮想的ユーザ特性を用いる • パーソナライズの評価方法が知りたい • メタな気持ち: 文議論会で、毎回質問が浮かばないから、 質問を浮かべる方法が知りたい ・・・ パーソナライズは可能? ユーザ, ログデータなし… システムを誰がどう使うか不明 検索分野のログとか 使えばいいのに…
質問生成でパーソナライズはできる? 実用可能になる? 研究目的 • パーソナライズの実現 ◦ ユーザログのない条件下での 多様な情報要求を考慮した質問生成 • オンデバイス(ローカル)でも実現可能に
◦ パラメタの小さいモデルでも高精度に 5 プライバシー問題 とかね
ペルソナ考慮でSQはよくなる? 小型モデルでも可能? 研究課題 ユーザデータを使わずにパーソナライズ • ユーザ行動ログがない ◦ 既存のPDF-AI : 行動ログがないため、
分析に基づくアプローチが取れない → 逐次 ペルソナ(職業)×ゴールを合成し、質問生成 • 多様性や読者適合性の評価が難しい → 新指標「逆ランキング評価法」により 「意図したペルソナの視点を反映しているか」を定量化 ◦ 人手でも評価 • パラメタが大きくオンデバイスでは難しい → 小型モデルでFine-tuning 6
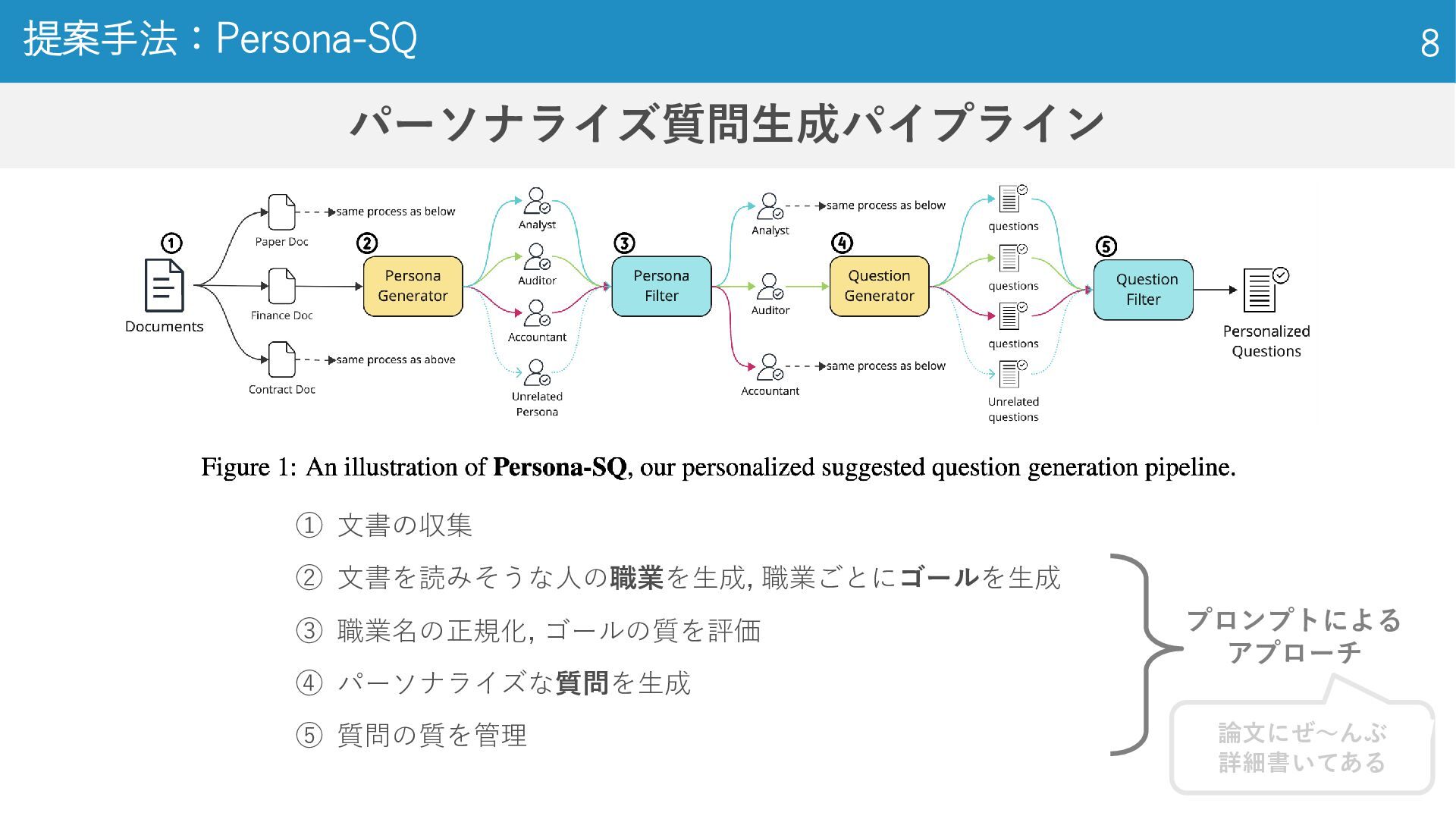
提案手法 Persona-SQ ぺ る そ な え す きゅ う
パーソナライズ質問生成パイプライン 提案手法:Persona-SQ 8 ① 文書の収集 ② 文書を読みそうな人の職業を生成, 職業ごとにゴールを生成 ③ 職業名の正規化,
ゴールの質を評価 ④ パーソナライズな質問を生成 ⑤ 質問の質を管理 プロンプトによる アプローチ 論文にぜ〜んぶ 詳細書いてある
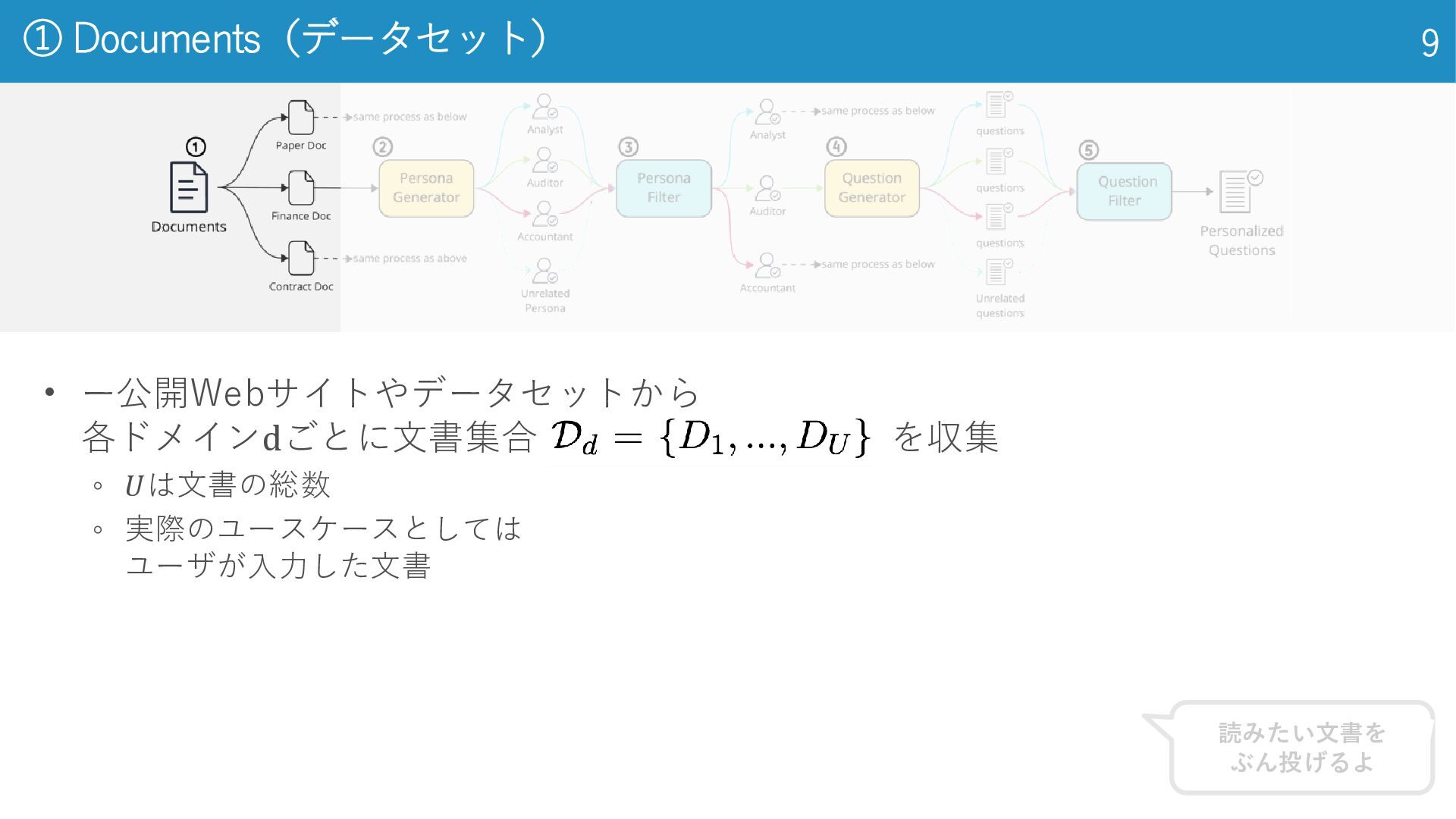
• ー公開Webサイトやデータセットから 各ドメインdごとに文書集合 を収集 ◦ 𝑈は文書の総数 ◦ 実際のユースケースとしては ユーザが入力した文書 ①
Documents(データセット) 9 読みたい文書を ぶん投げるよ
② Persona Generator 10 • LLMが職業とそのゴール5個を生成 ◦ {職業₁:[ゴール₁₁,…], …} ◦
多様で関連性のある 職業-ゴールのペアを大量生成 プロンプト • 目的:職業とゴールの予測(生成) • 前提:読者によって解釈・ゴールが異なる (domain > subdomain > profession > goals) • 条件:多様で職業に即したゴール、非専門職も可 職業とゴールを LLMのバイアスを元に 作っちゃうぞ
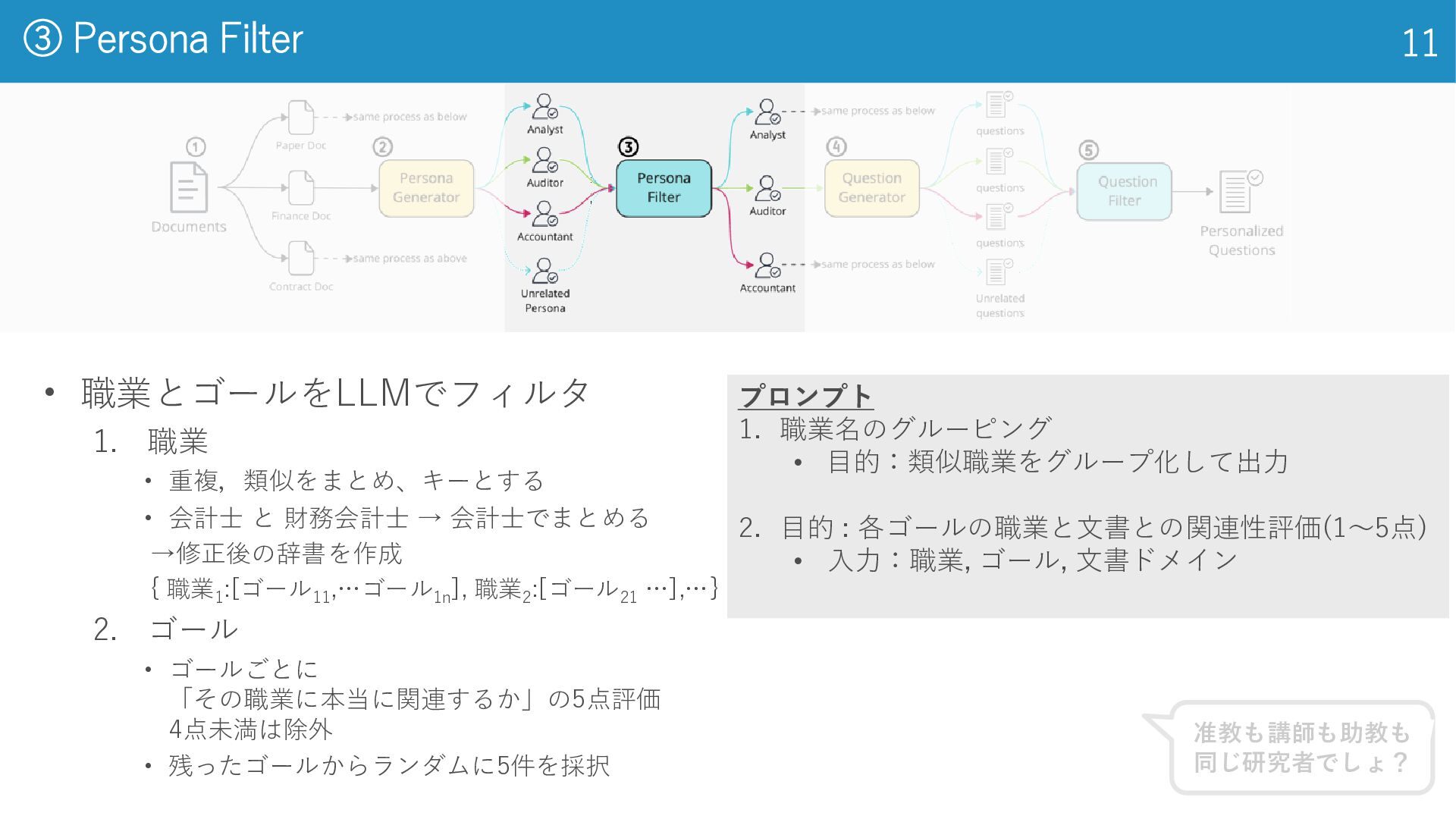
③ Persona Filter 11 • 職業とゴールをLLMでフィルタ 1. 職業 • 重複,類似をまとめ、キーとする
• 会計士 と 財務会計士 → 会計士でまとめる →修正後の辞書を作成 { 職業 1 :[ゴール 11 ,…ゴール 1n ], 職業 2 :[ゴール 21 …],…} 2. ゴール • ゴールごとに 「その職業に本当に関連するか」の5点評価 4点未満は除外 • 残ったゴールからランダムに5件を採択 プロンプト 1. 職業名のグルーピング • 目的:類似職業をグループ化して出力 2. 目的 : 各ゴールの職業と文書との関連性評価(1〜5点) • 入力:職業, ゴール, 文書ドメイン 准教も講師も助教も 同じ研究者でしょ?
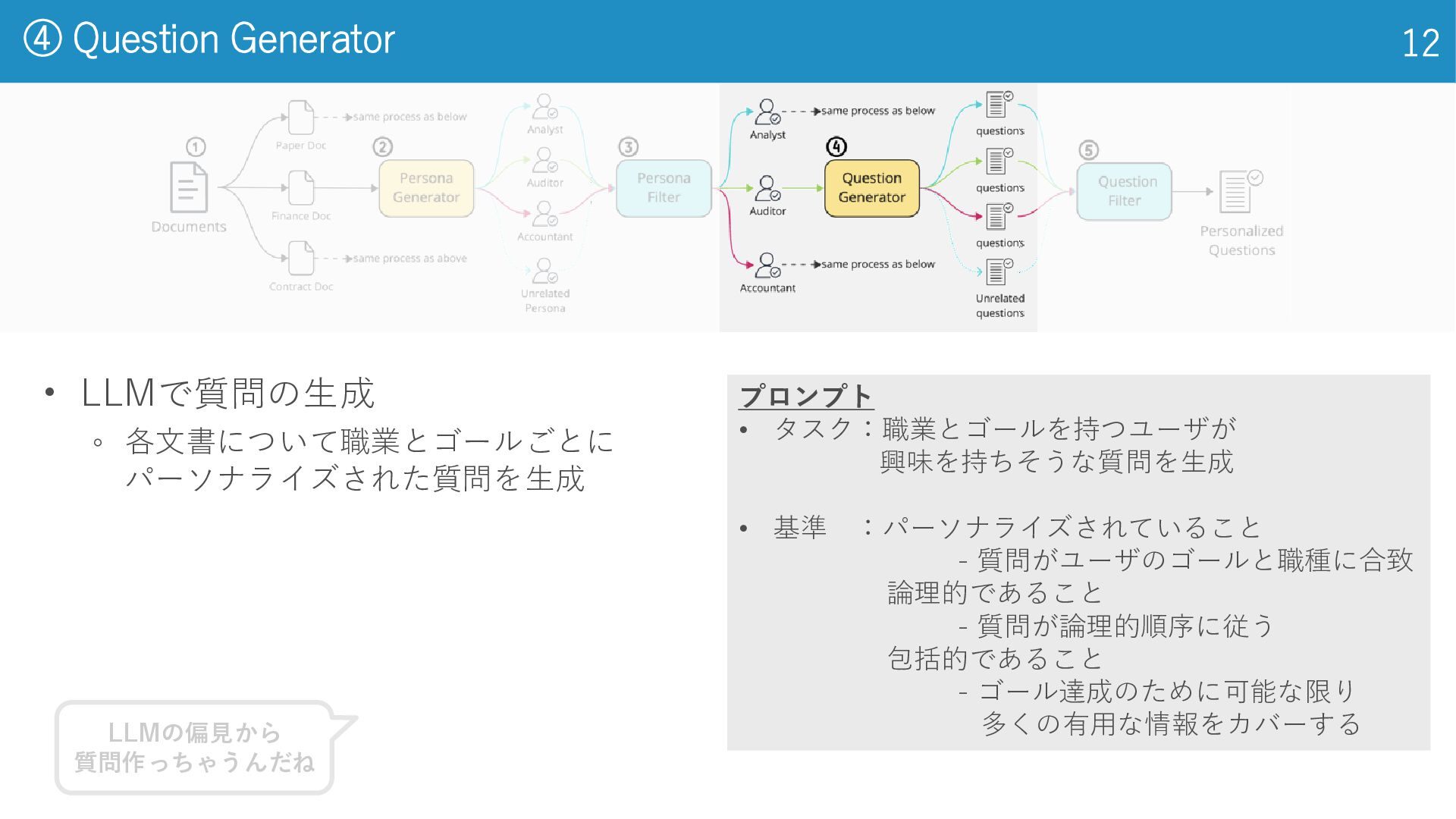
④ Question Generator 12 プロンプト • タスク:職業とゴールを持つユーザが 興味を持ちそうな質問を生成 • 基準
:パーソナライズされていること - 質問がユーザのゴールと職種に合致 論理的であること - 質問が論理的順序に従う 包括的であること - ゴール達成のために可能な限り 多くの有用な情報をカバーする LLMの偏見から 質問作っちゃうんだね • LLMで質問の生成 ◦ 各文書について職業とゴールごとに パーソナライズされた質問を生成
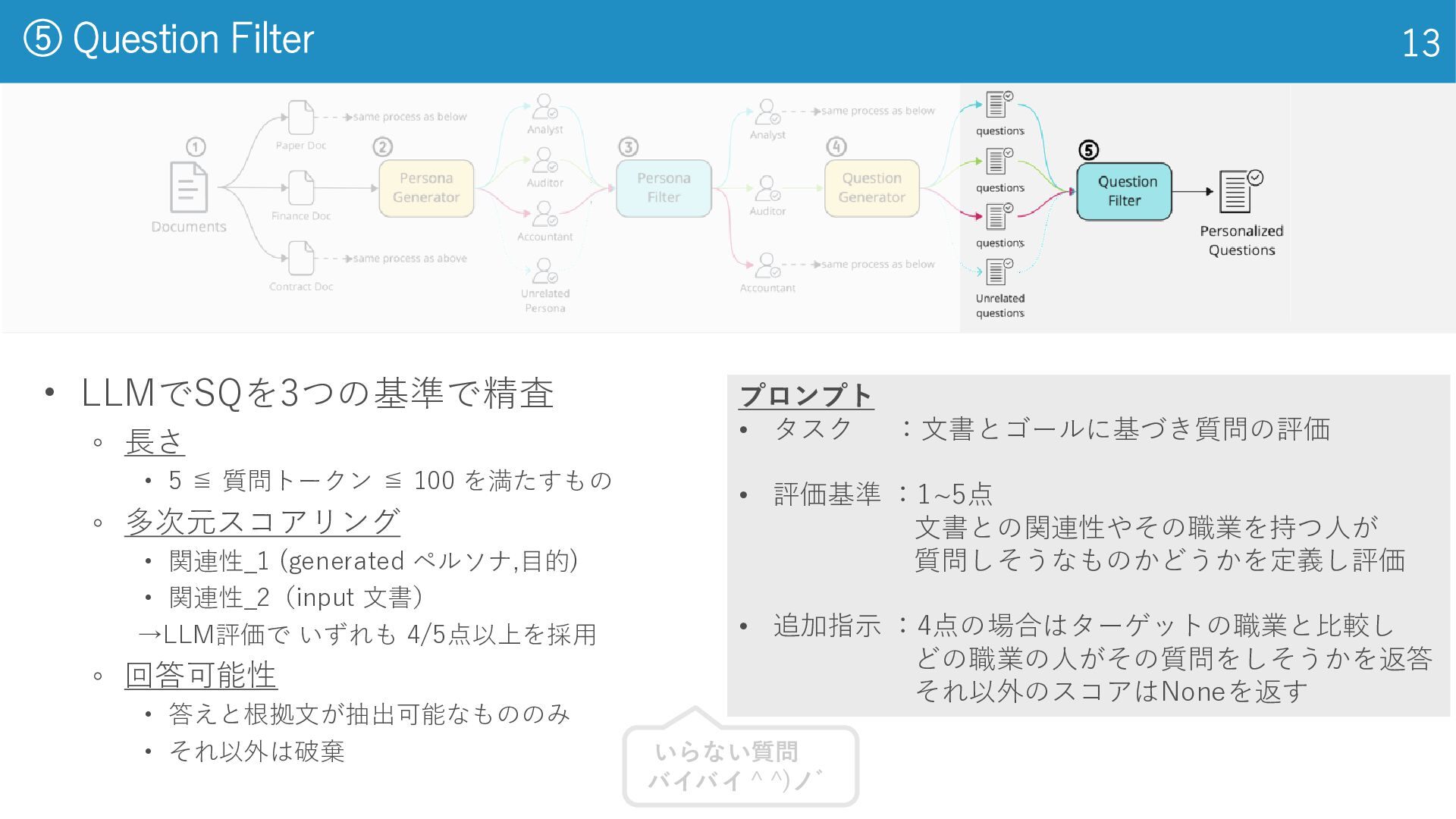
⑤ Question Filter 13 プロンプト • タスク :文書とゴールに基づき質問の評価 • 評価基準
:1~5点 文書との関連性やその職業を持つ人が 質問しそうなものかどうかを定義し評価 • 追加指示 :4点の場合はターゲットの職業と比較し どの職業の人がその質問をしそうかを返答 それ以外のスコアはNoneを返す いらない質問 バイバイ ^ ^)ノ゛ • LLMでSQを3つの基準で精査 ◦ 長さ • 5 ≦ 質問トークン ≦ 100 を満たすもの ◦ 多次元スコアリング • 関連性_1 (generated ペルソナ,目的) • 関連性_2(input 文書) →LLM評価で いずれも 4/5点以上を採用 ◦ 回答可能性 • 答えと根拠文が抽出可能なもののみ • それ以外は破棄
3ドメイン 公開データセットからランダムに 250文書 ◦ 金融 (Finance): Fns2020 (El-Haj et al.,
2020) • LSE上場企業の年次報告書 3,863件 (学習 3,000件, 検証 363件, テスト 500件) • 年次報告書全文 + 2–7 件のゴールド要約 ◦ 法律 (Legal): CUAD (Hendrycks et al., 2021) • アメリカの法律に関するデータセット • 契約書全文 510件 + 41 種類の条項スパン(開始・終了位置と抜粋)約1.3万箇所 ◦ 学術 (Academia): QASPER (Dasigi et al., 2021) • NLP系 研究論文 1,585本, 質問回答ペア 5,049件 • 論文全文(セクション‐段落構造付き)+ 複数のQAと根拠パラグラフ 金融、法律、学術の3ドメインで実験 データセット 14 El-Haj et al. (2020), FNS: Financial Narrative Summarisation, LREC-FNP 2020 Hendrycks et al. (2021), CUAD: Legal Contract Review Dataset, arXiv:2103.06268 Dasigi et al. (2021), QASPER: QA on Scientific Papers, EMNLP 2021 専門家による アノテーションされて るんだって。無給かな。
自動評価手法 5つの指標 逆ランキング法
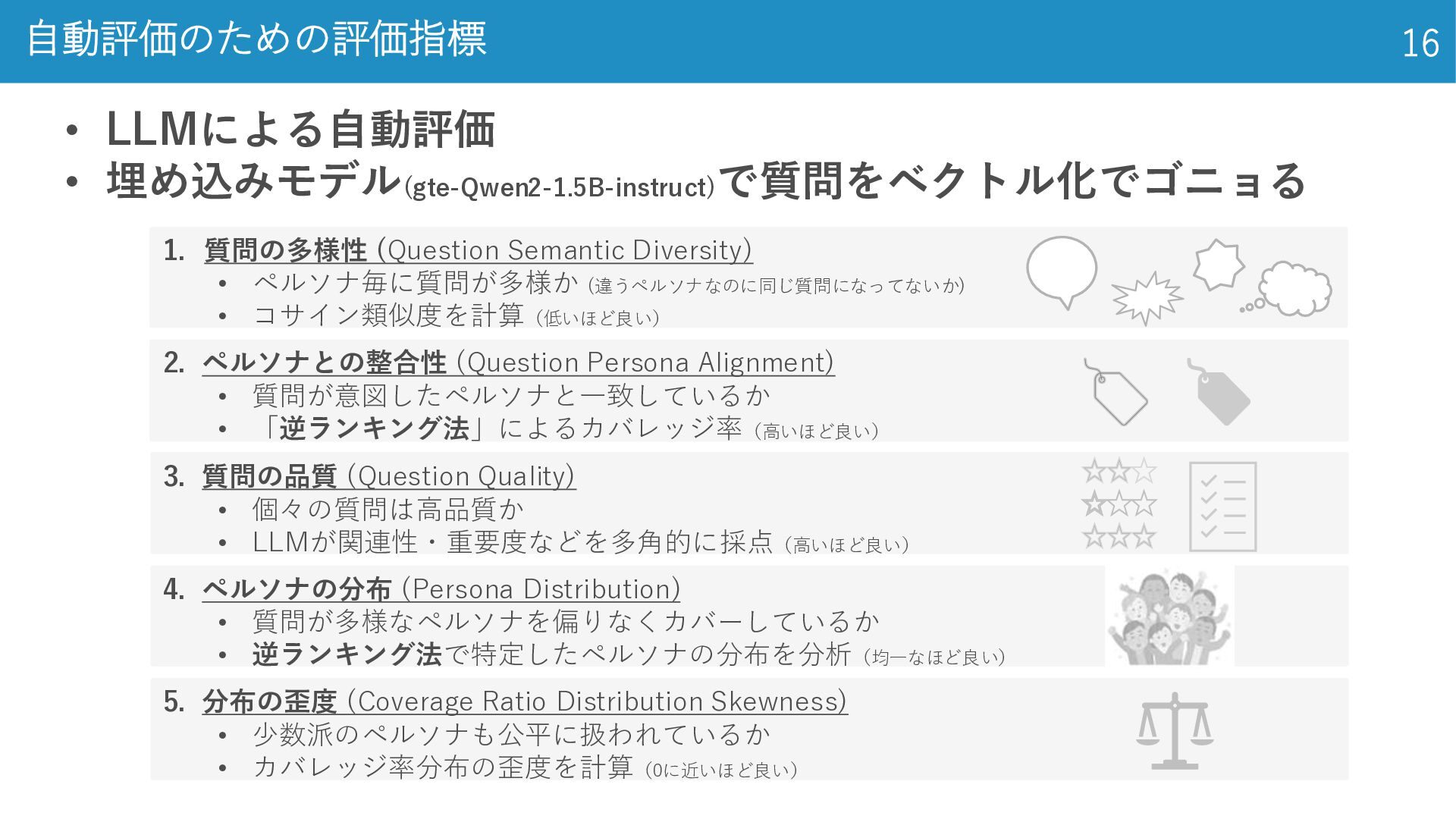
自動評価のための評価指標 16 1. 質問の多様性 (Question Semantic Diversity) • ペルソナ毎に質問が多様か (違うペルソナなのに同じ質問になってないか)
• コサイン類似度を計算(低いほど良い) 2. ペルソナとの整合性 (Question Persona Alignment) • 質問が意図したペルソナと一致しているか • 「逆ランキング法」によるカバレッジ率(高いほど良い) 3. 質問の品質 (Question Quality) • 個々の質問は高品質か • LLMが関連性・重要度などを多角的に採点(高いほど良い) 4. ペルソナの分布 (Persona Distribution) • 質問が多様なペルソナを偏りなくカバーしているか • 逆ランキング法で特定したペルソナの分布を分析(均一なほど良い) 5. 分布の歪度 (Coverage Ratio Distribution Skewness) • 少数派のペルソナも公平に扱われているか • カバレッジ率分布の歪度を計算(0に近いほど良い) • LLMによる自動評価 • 埋め込みモデル(gte-Qwen2-1.5B-instruct) で質問をベクトル化でゴニョる
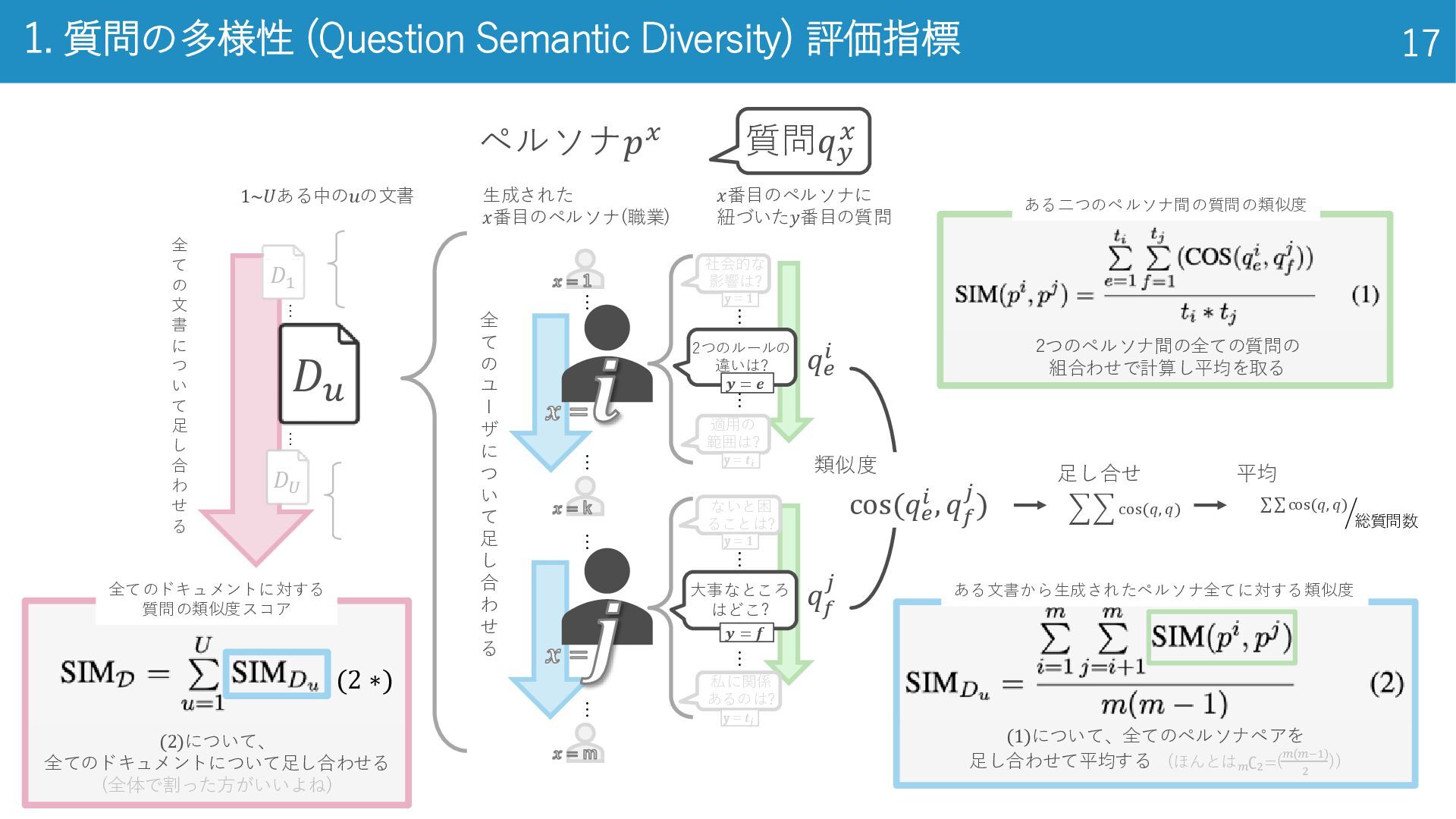
1. 質問の多様性 (Question Semantic Diversity) 評価指標 17 2つのペルソナ間の全ての質問の 組合わせで計算し平均を取る ある二つのペルソナ間の質問の類似度
全 て の 文 書 に つ い て 足 し 合 わ せ る … ペルソナ𝑝𝑥 質問𝑞𝑦 𝑥 𝑞𝑒 𝑖 𝒋 𝒙 = 𝑞 𝑓 𝑗 類似度 cos(𝑞𝑒 𝑖 , 𝑞 𝑓 𝑗) 足し合せ cos(𝑞, 𝑞) 平均 ൘ σσcos(𝑞, 𝑞) 総質問数 … … … 全 て の ユ l ザ に つ い て 足 し 合 わ せ る 生成された 𝑥番目のペルソナ(職業) 𝑥番目のペルソナに 紐づいた𝑦番目の質問 適用の 範囲は? 2つのルールの 違いは? … 社会的な 影響は? … 𝒚 = 𝒆 y = 𝒕𝒊 y = 𝟏 𝒙 = 𝒊 私に関係 あるのは? 大事なところ はどこ? … ないと困 ることは? … 𝒚 = 𝒇 y = 𝒕𝒋 y = 𝟏 𝒙 = 1 𝒙 = k 𝒙 = m 𝐷𝑢 … … 𝐷1 𝐷𝑈 (1)について、全てのペルソナペアを 足し合わせて平均する (ほんとは 𝑚 ∁2 =(𝑚(𝑚−1) 2 )) ある文書から生成されたペルソナ全てに対する類似度 (2 ∗) (2)について、 全てのドキュメントについて足し合わせる (全体で割った方がいいよね) 全てのドキュメントに対する 質問の類似度スコア 1~𝑈ある中の𝑢の文書
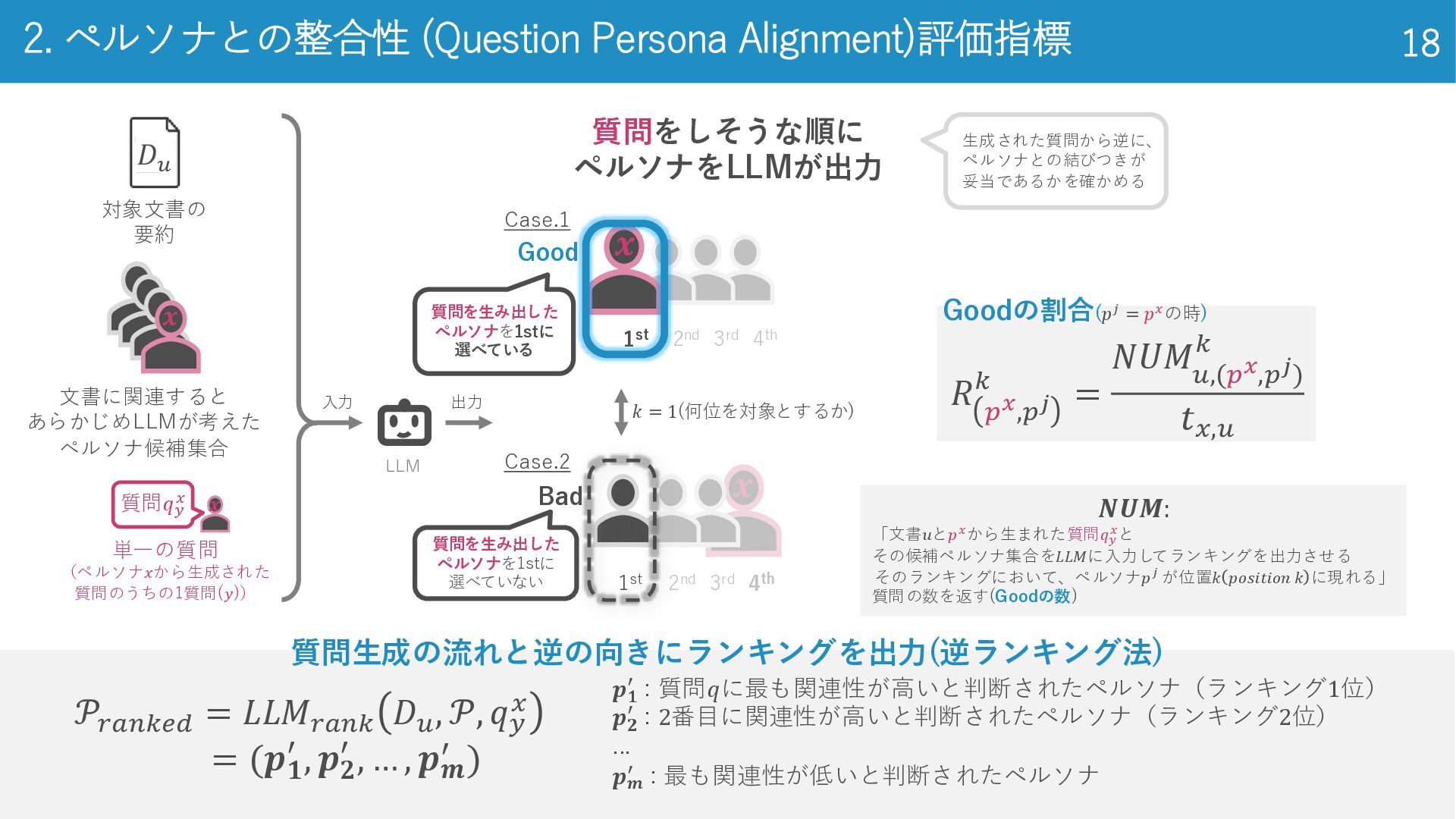
18 2. ペルソナとの整合性 (Question Persona Alignment)評価指標 18 𝐷𝑢 対象文書の 要約
質問𝑞𝑦 𝑥 単一の質問 (ペルソナ𝑥から生成された 質問のうちの1質問(𝑦)) 文書に関連すると あらかじめLLMが考えた ペルソナ候補集合 入力 出力 質問をしそうな順に ペルソナをLLMが出力 1st 2nd 3rd 4th 生成された質問から逆に、 ペルソナとの結びつきが 妥当であるかを確かめる 1st 2nd 3rd 4th Bad Good 質問を生み出した ペルソナを1stに 選べている 𝒙 𝒙 LLM 𝒙 質問生成の流れと逆の向きにランキングを出力(逆ランキング法) 𝒙 𝒫𝑟𝑎𝑛𝑘𝑒𝑑 = 𝐿𝐿𝑀𝑟𝑎𝑛𝑘 𝐷𝑢 , 𝒫, 𝑞𝑦 𝑥 = (𝒑𝟏 ′ , 𝒑𝟐 ′ , … , 𝒑𝒎 ′ ) 𝑵𝑼𝑴: 「文書𝑢と𝑝𝑥から生まれた質問𝑞𝑦 𝑥と その候補ペルソナ集合を𝐿𝐿𝑀に入力してランキングを出力させる そのランキングにおいて、ペルソナ𝑝𝑗 が位置𝑘 𝑝𝑜𝑠𝑖𝑡𝑖𝑜𝑛 𝑘 に現れる」 質問の数を返す(Goodの数) 𝑘 = 1(何位を対象とするか) 質問を生み出した ペルソナを1stに 選べていない Case.1 Case.2 𝒑𝟏 ′ : 質問𝑞に最も関連性が高いと判断されたペルソナ(ランキング1位) 𝒑𝟐 ′ : 2番目に関連性が高いと判断されたペルソナ(ランキング2位) ... 𝒑𝒎 ′ : 最も関連性が低いと判断されたペルソナ 𝑅 𝑝𝑥,𝑝𝑗 𝑘 = 𝑁𝑈𝑀 𝑢,(𝑝𝑥,𝑝𝑗) 𝑘 𝑡𝑥,𝑢 Goodの割合(𝑝𝑗 = 𝑝𝑥の時)
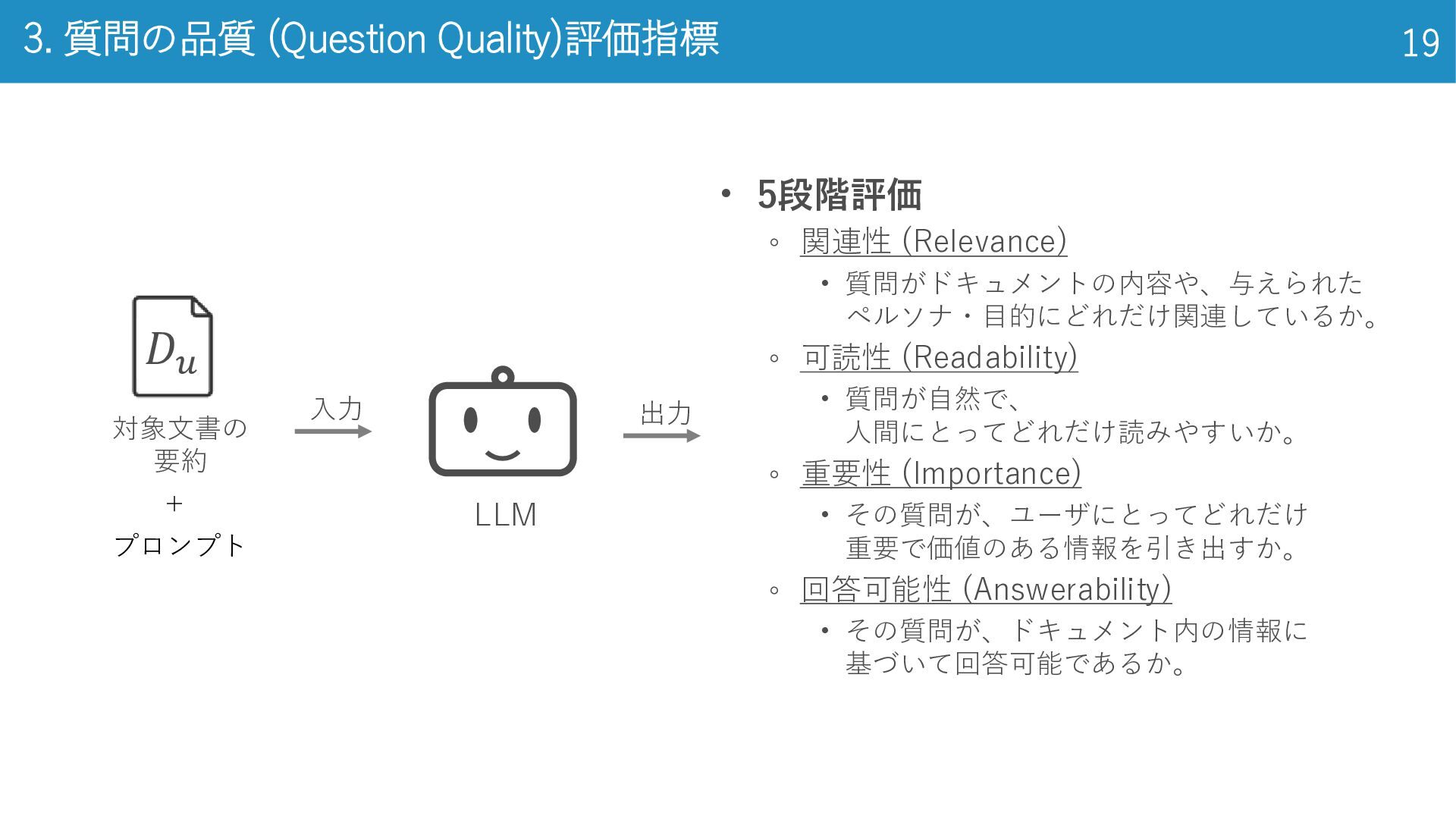
• 5段階評価 ◦ 関連性 (Relevance) • 質問がドキュメントの内容や、与えられた ペルソナ・目的にどれだけ関連しているか。 ◦ 可読性
(Readability) • 質問が自然で、 人間にとってどれだけ読みやすいか。 ◦ 重要性 (Importance) • その質問が、ユーザにとってどれだけ 重要で価値のある情報を引き出すか。 ◦ 回答可能性 (Answerability) • その質問が、ドキュメント内の情報に 基づいて回答可能であるか。 3. 質問の品質 (Question Quality)評価指標 19 LLM 𝐷𝑢 対象文書の 要約 プロンプト + 入力 出力
• 𝑫𝒊𝒔𝒕 𝒑𝒋 , 𝑫𝒖 = σ𝒉=𝟏 𝑵 𝕀 𝒇𝒓𝒂𝒏𝒌
𝒒𝒉 = 𝒑𝒋 𝑵 ∶ • 𝑸𝒖 = {𝒒𝟏 , 𝒒𝟐 , … , 𝒒𝑵 }: ◦ ドキュメント𝑫𝒖 に対して生成された𝑵個の質問の集合 • 𝑷 = {𝒑𝟏 , 𝒑𝟐 , … , 𝒑𝒎 }: ◦ システムが扱うことができる𝒎個のペルソナの全集合 • 𝒇𝒓𝒂𝒏𝒌 𝒒𝒉 : ◦ 質問𝒒𝒉 に対し、ペルソナの集合𝑷の中から 最も関連性が高いとLLMが判断(ランキング1位に選出)した ペルソナを返す関数「逆ランキング法」のこと。 • 𝕀 𝒙 : ◦ 指示関数。条件𝒙が真の場合は1、偽の場合は0を返す 4. ペルソナの分布 (Persona Distribution)評価指標 (論文中に詳細なし) 20 特定のドキュメント𝑫𝒖 における ペルソナ𝒑𝒋 ∈ 𝑷 の分布(出現率) 論文中には詳細が なかったので、 こうじゃないかな? という感じだよ
• 𝑺𝒌𝒆𝒘𝒏𝒆𝒔𝒔(𝑪) = 𝟏 𝒎 σ𝒊=𝟏 𝒎 𝑪𝒊 − μ𝒄
𝟑 (σ𝑪 )𝟑 : • 𝑪𝒊 : ◦ ペルソナ𝒑𝒊 に対するカバレッジ率 ・ペルソナ𝒑𝒊 のために生成された質問が、 逆ランキング法によって𝒑𝒊 自身と関連性が高いと判断された割合(𝑹 𝒅,(𝒑𝒊,𝒑𝒊) 𝒌 のこと) • 𝑪 = {𝑪𝟏 , 𝑪𝟐 , … , 𝑪𝒎 }: ◦ 全てのペルソナのカバレッジ率の集合 • 𝝁𝒄 : ◦ カバレッジ率の集合𝑪の平均値 • 𝝈𝒄 : ◦ カバレッジ率の集合𝑪の標準偏差 5. 分布の歪度 (Coverage Ratio Distribution Skewness)評価指標 (論文中に詳細なし) 21 一部のペルソナだけを優遇(or冷遇)していないか。 性能に「偏り」がないかを確認 論文中には詳細が なかったので、 こうじゃないかな? という感じだよ 𝑅 𝑝𝑖,𝑝𝑗 𝑘 = 𝑁𝑈𝑀 𝑢,(𝑝𝑖,𝑝𝑗) 𝑘 𝑡𝑖,𝑢
実験
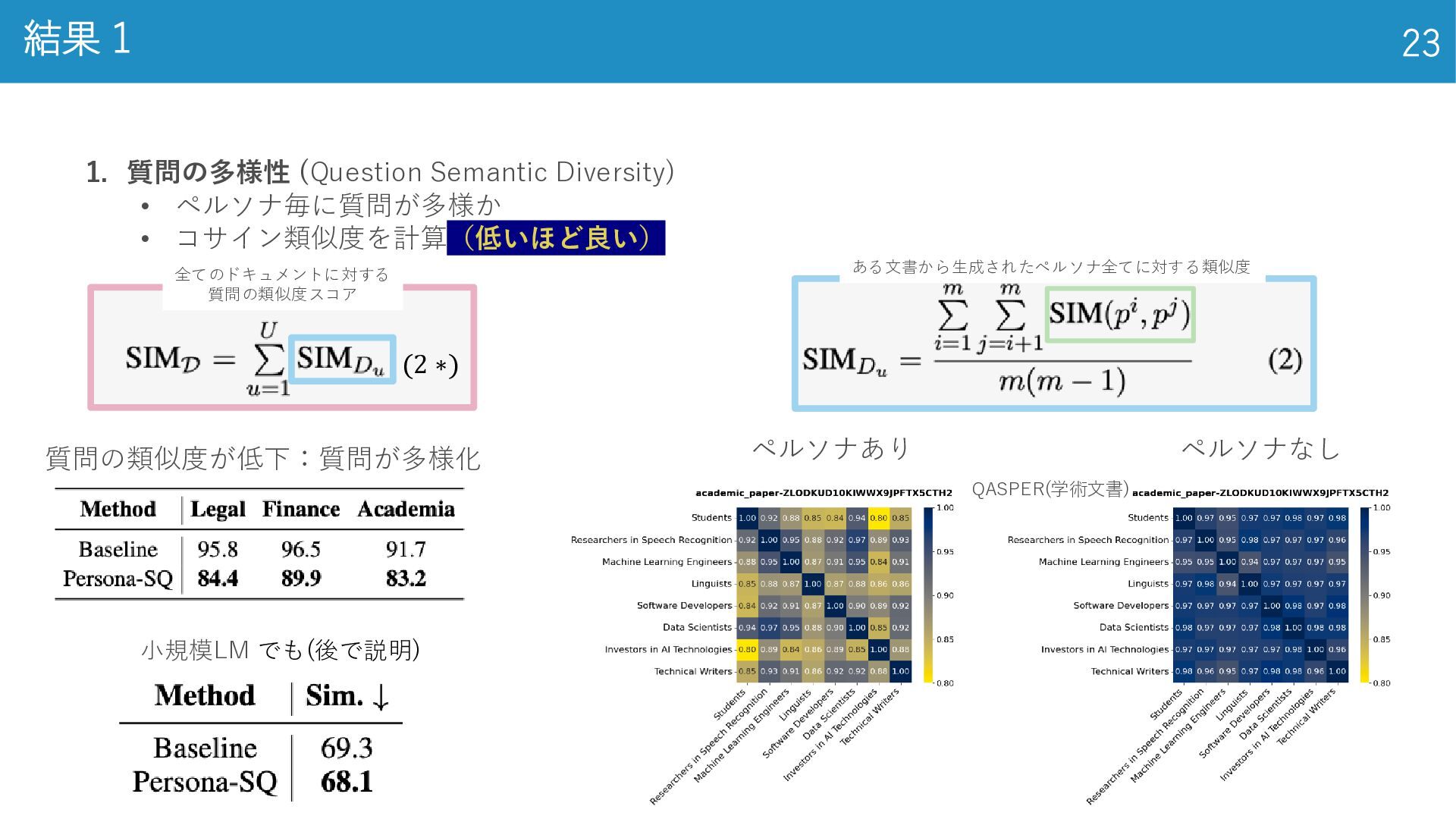
結果 1 23 1. 質問の多様性 (Question Semantic Diversity) • ペルソナ毎に質問が多様か
• コサイン類似度を計算(低いほど良い) ペルソナあり ペルソナなし 全文書で割った値 小規模LM でも(後で説明) 質問の類似度が低下:質問が多様化 QASPER(学術文書) ある文書から生成されたペルソナ全てに対する類似度 (2 ∗) 全てのドキュメントに対する 質問の類似度スコア
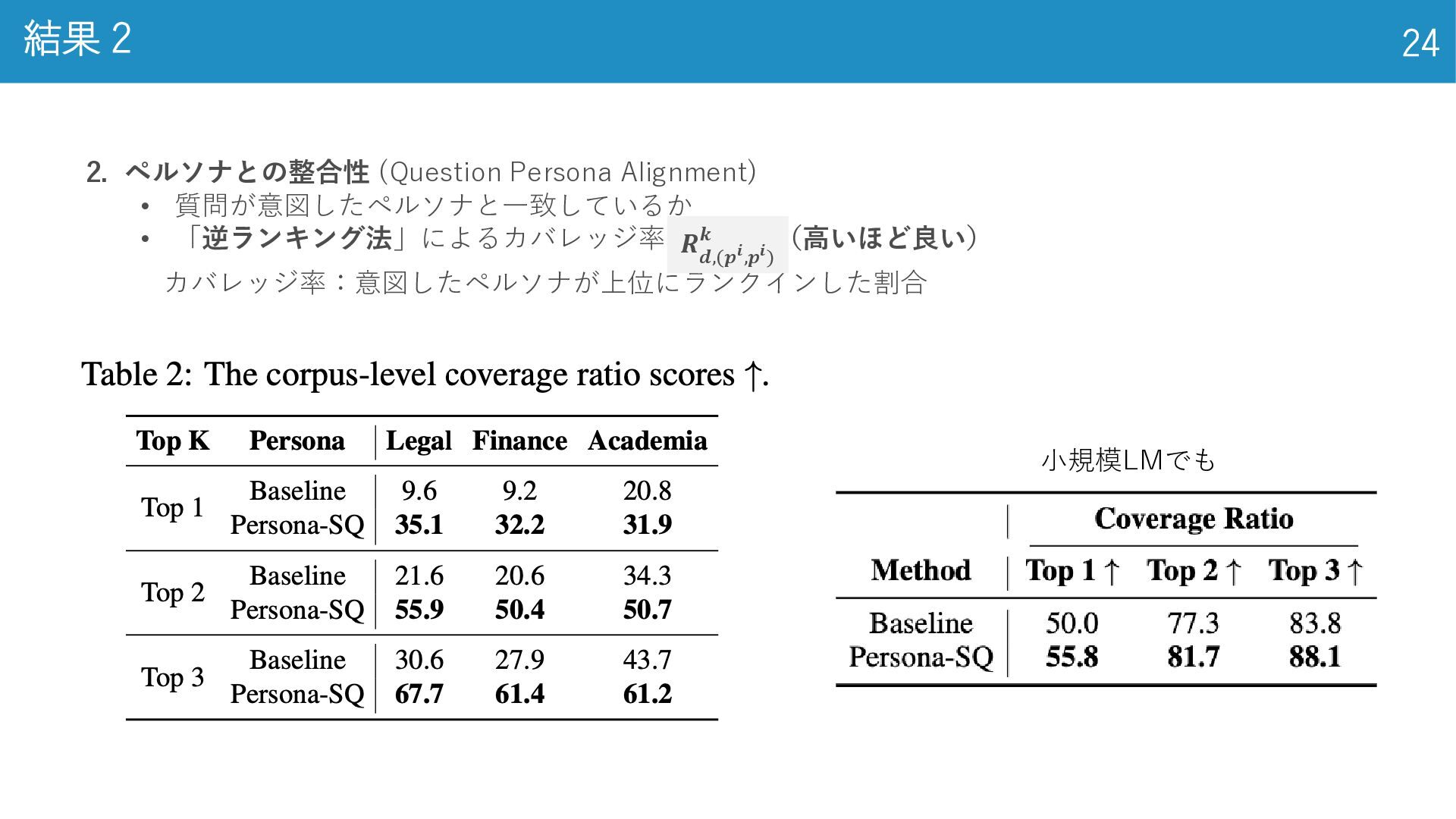
結果 2 24 2. ペルソナとの整合性 (Question Persona Alignment) • 質問が意図したペルソナと一致しているか
• 「逆ランキング法」によるカバレッジ率 (高いほど良い) カバレッジ率:意図したペルソナが上位にランクインした割合 𝑹 𝒅,(𝒑𝒊,𝒑𝒊) 𝒌 小規模LMでも
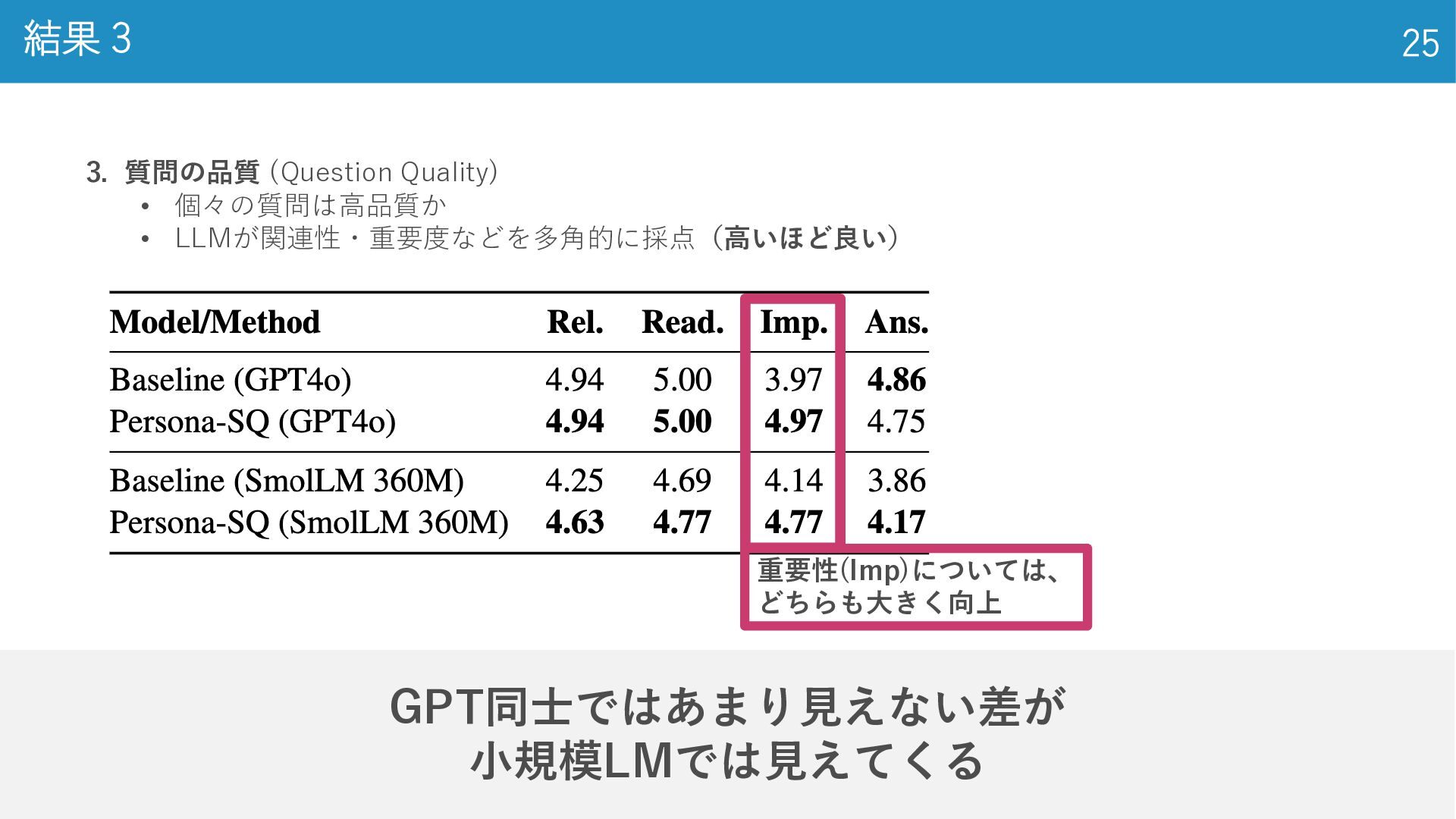
GPT同士ではあまり見えない差が 小規模LMでは見えてくる 25 結果 3 3. 質問の品質 (Question Quality) •
個々の質問は高品質か • LLMが関連性・重要度などを多角的に採点(高いほど良い) 重要性(Imp)については、 どちらも大きく向上
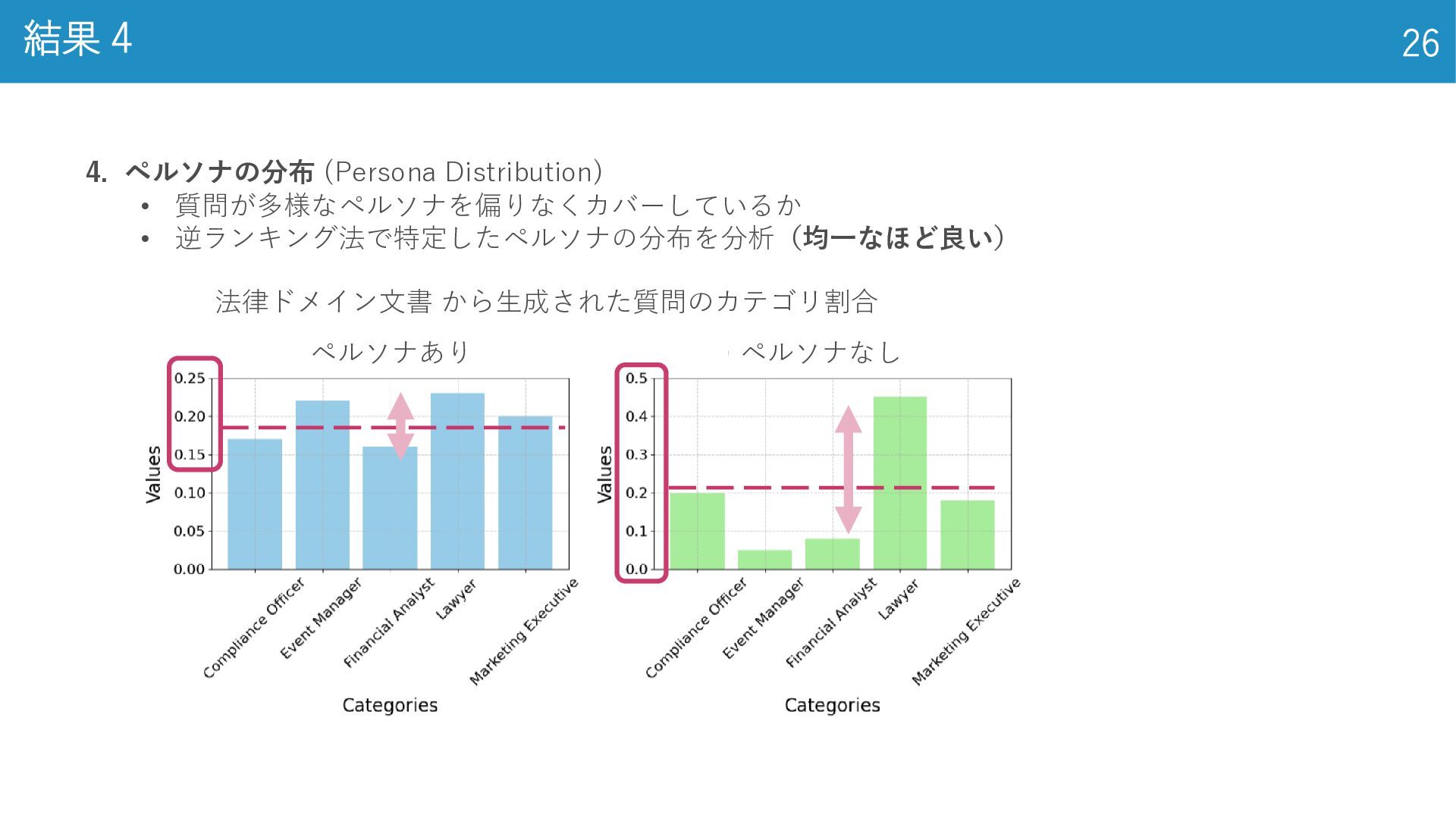
結果 4 26 4. ペルソナの分布 (Persona Distribution) • 質問が多様なペルソナを偏りなくカバーしているか •
逆ランキング法で特定したペルソナの分布を分析(均一なほど良い) 法律ドメイン文書 から生成された質問のカテゴリ割合 ペルソナあり ペルソナなし
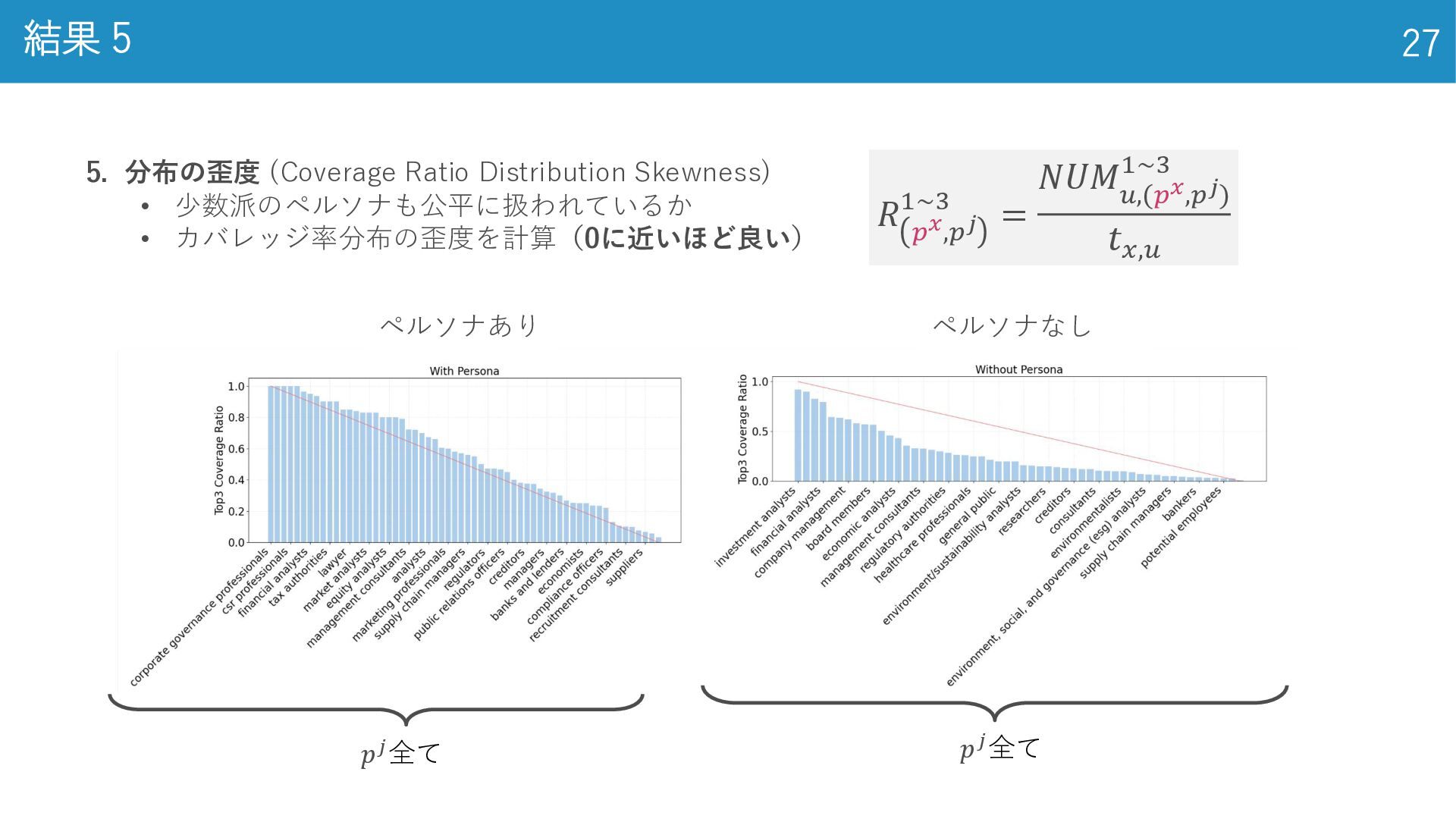
結果 5 27 5. 分布の歪度 (Coverage Ratio Distribution Skewness) •
少数派のペルソナも公平に扱われているか • カバレッジ率分布の歪度を計算(0に近いほど良い) ペルソナあり ペルソナなし 𝑅 𝑝𝑥,𝑝𝑗 1~3 = 𝑁𝑈𝑀 𝑢,(𝑝𝑥,𝑝𝑗) 1~3 𝑡𝑥,𝑢 𝑝𝑗全て 𝑝𝑗全て
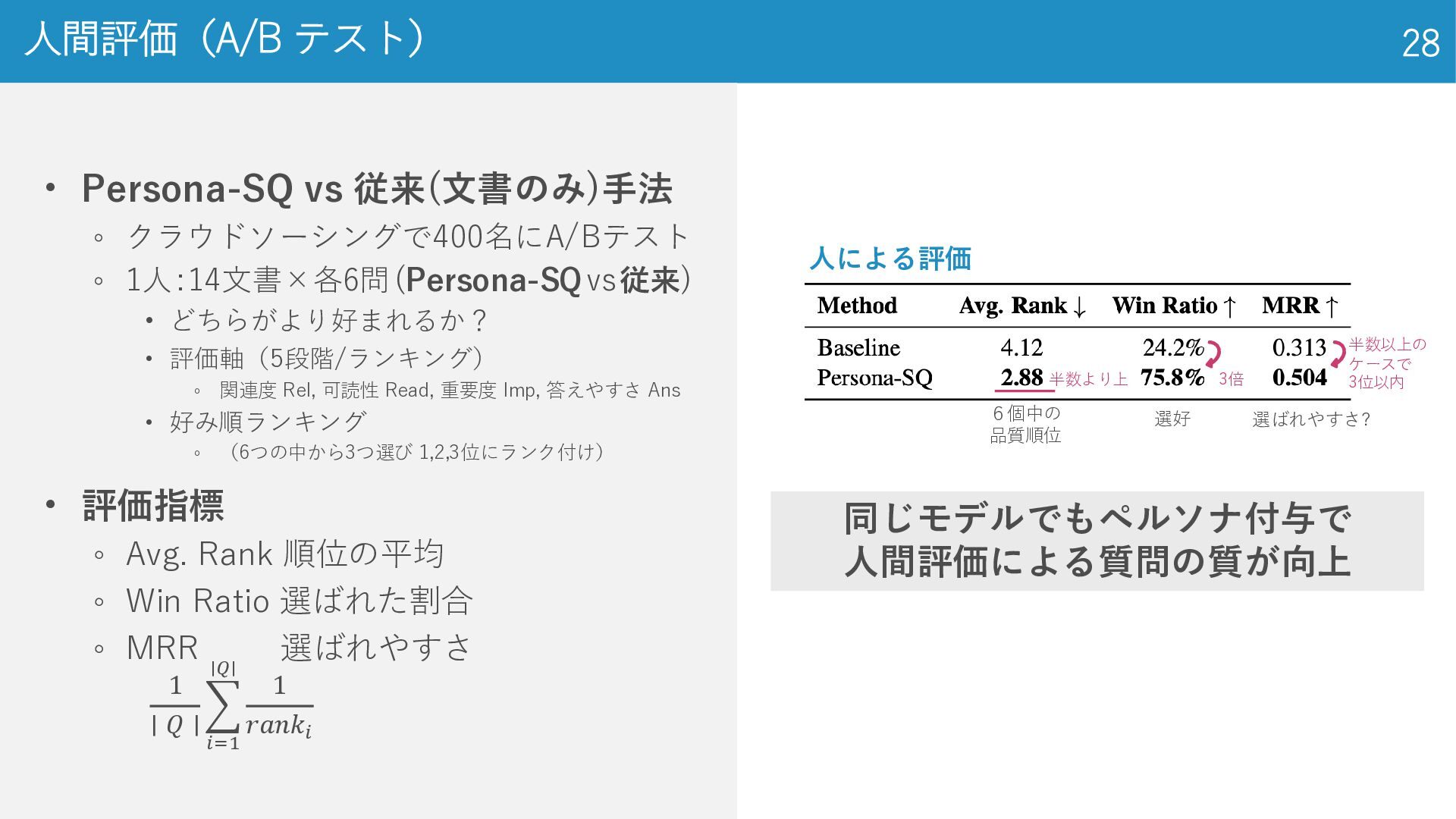
人間評価(A/B テスト) 28 • Persona-SQ vs 従来(文書のみ)手法 ◦ クラウドソーシングで400名にA/Bテスト ◦
1人:14文書×各6問(Persona-SQvs従来) • どちらがより好まれるか? • 評価軸(5段階/ランキング) ◦ 関連度 Rel, 可読性 Read, 重要度 Imp, 答えやすさ Ans • 好み順ランキング ◦ (6つの中から3つ選び 1,2,3位にランク付け) • 評価指標 ◦ Avg. Rank 順位の平均 ◦ Win Ratio 選ばれた割合 ◦ MRR 選ばれやすさ 6個中の 品質順位 選好 選ばれやすさ? 同じモデルでもペルソナ付与で 人間評価による質問の質が向上 半数より上 3倍 半数以上の ケースで 3位以内 人による評価 1 ∣ 𝑄 ∣ 𝑖=1 ∣𝑄∣ 1 𝑟𝑎𝑛𝑘𝑖
• オンデバイスでPersona-SQの実現 ◦ Persona-SQ×Llama-3.1-70Bで生成した 学習データを用いてfine-tuning • 学習データ: 8ドメインから1.6k文書, 2.3万質問を抽出 ◦
モデル:SmolLM 360M • サイズ ◦ fp16 重みで約 760 MB (比較Googleで380MB) ◦ 4-bit量子化で ≈ 200 MB まで圧縮可能 • 遅延 (MacBook M2 非最適化) ◦ モデル読み込み 0.5秒, ペルソナ推定+質問生成 ≈ 10秒/文書 • GPT4oに匹敵する性能 TinyDocLM-SQ:小型モデルへ展開 29 小規模モデルでも fine-tuning+ペルソナ付与で 大規模モデル(ペルソナ無し)を超える 半数以上の ケースで 3位以内 5倍 半数より上 GPTによる評価 人による評価 つよつよ 学習データ 覚醒 ヨワヨワ 小規模LM Persona-SQ プロンプト調味料 文書とプロンプト Llama 8ドメイン文書 モリッ ぐびっ 質問生成 つよつよLM 爆誕!! 体はこども 頭脳は大人
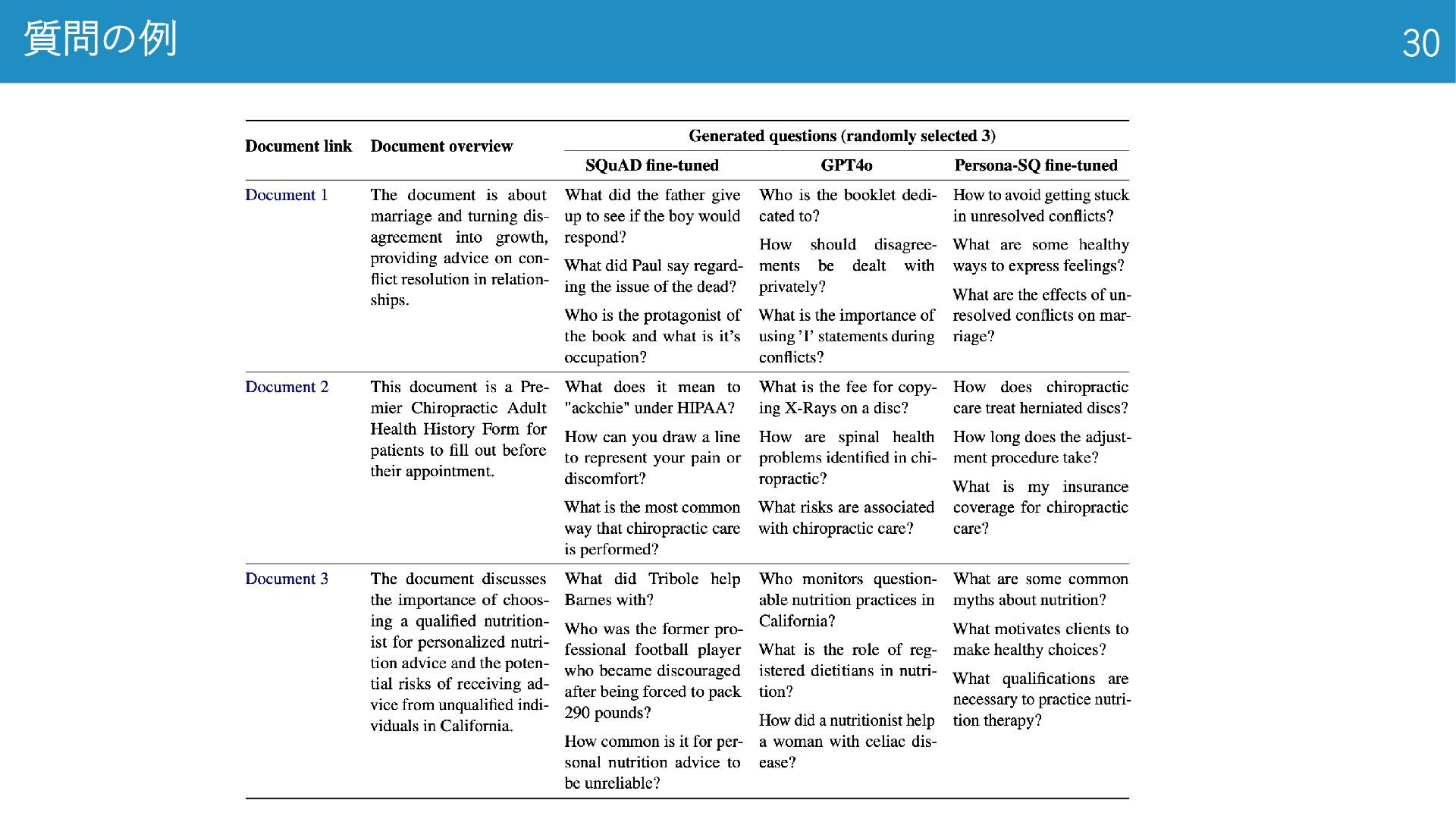
質問の例 30
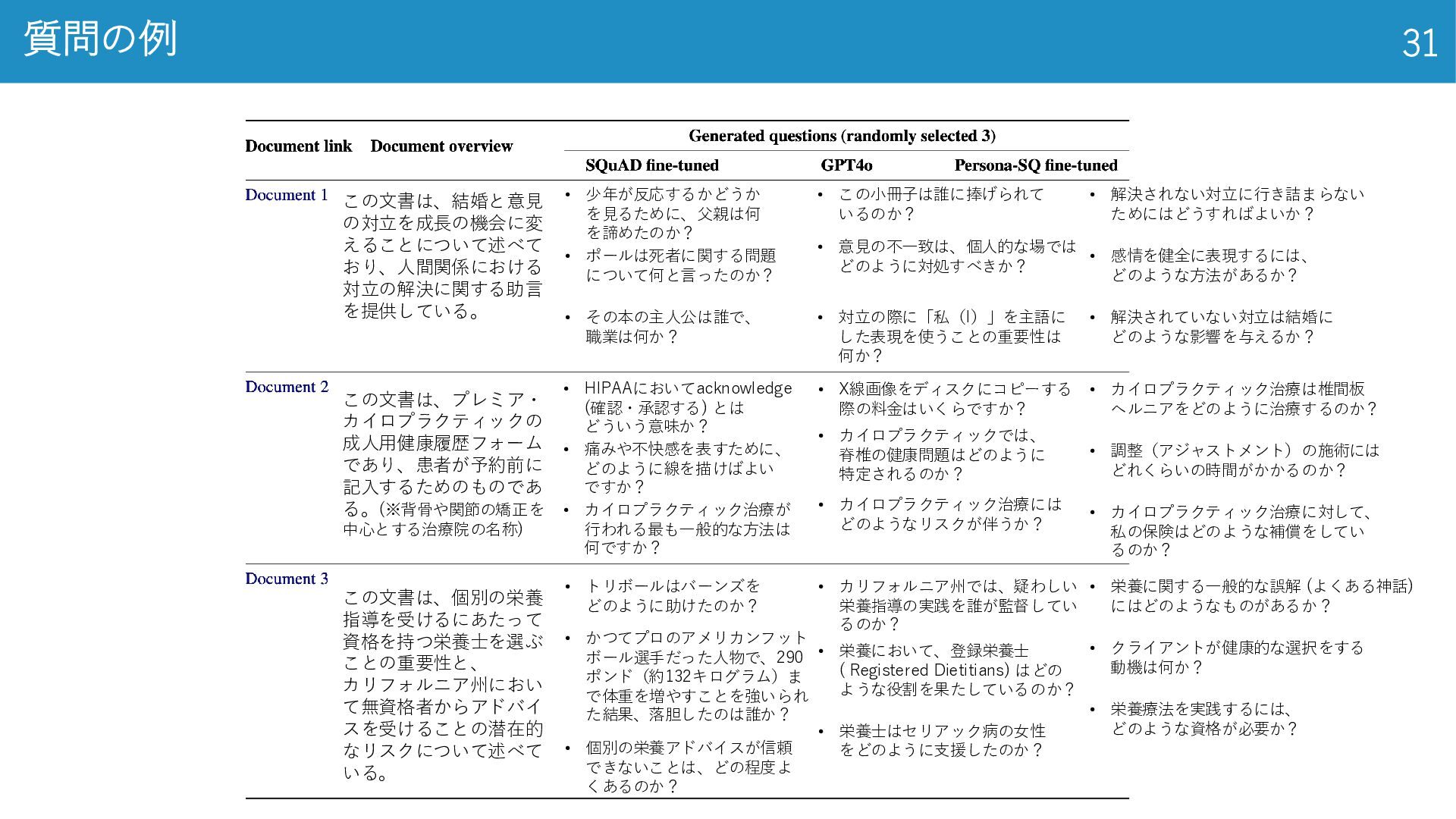
質問の例 31 • 少年が反応するかどうか を見るために、父親は何 を諦めたのか? • ポールは死者に関する問題 について何と言ったのか? •
その本の主人公は誰で、 職業は何か? • この小冊子は誰に捧げられて いるのか? • 意見の不一致は、個人的な場では どのように対処すべきか? • 対立の際に「私(I)」を主語に した表現を使うことの重要性は 何か? • 栄養に関する一般的な誤解 (よくある神話) にはどのようなものがあるか? • クライアントが健康的な選択をする 動機は何か? • 栄養療法を実践するには、 どのような資格が必要か? • カイロプラクティック治療は椎間板 ヘルニアをどのように治療するのか? • 調整(アジャストメント)の施術には どれくらいの時間がかかるのか? • カイロプラクティック治療に対して、 私の保険はどのような補償をしてい るのか? • HIPAAにおいてacknowledge (確認・承認する) とは どういう意味か? • 痛みや不快感を表すために、 どのように線を描けばよい ですか? • カイロプラクティック治療が 行われる最も一般的な方法は 何ですか? • X線画像をディスクにコピーする 際の料金はいくらですか? • カイロプラクティックでは、 脊椎の健康問題はどのように 特定されるのか? • カイロプラクティック治療には どのようなリスクが伴うか? • 解決されない対立に行き詰まらない ためにはどうすればよいか? • 感情を健全に表現するには、 どのような方法があるか? • 解決されていない対立は結婚に どのような影響を与えるか? • カリフォルニア州では、疑わしい 栄養指導の実践を誰が監督してい るのか? • 栄養において、登録栄養士 ( Registered Dietitians) はどの ような役割を果たしているのか? • 栄養士はセリアック病の女性 をどのように支援したのか? • トリボールはバーンズを どのように助けたのか? • かつてプロのアメリカンフット ボール選手だった人物で、290 ポンド(約132キログラム)ま で体重を増やすことを強いられ た結果、落胆したのは誰か? • 個別の栄養アドバイスが信頼 できないことは、どの程度よ くあるのか? この文書は、結婚と意見 の対立を成長の機会に変 えることについて述べて おり、人間関係における 対立の解決に関する助言 を提供している。 この文書は、プレミア・ カイロプラクティックの 成人用健康履歴フォーム であり、患者が予約前に 記入するためのものであ る。(※背骨や関節の矯正を 中心とする治療院の名称) この文書は、個別の栄養 指導を受けるにあたって 資格を持つ栄養士を選ぶ ことの重要性と、 カリフォルニア州におい て無資格者からアドバイ スを受けることの潜在的 なリスクについて述べて いる。
1. 実際のプロファイルではない ◦ 真にパーソナライズを実現しているかは不明 ◦ ランダム性が多く再現性が低い 2. 追加計算コスト ◦ システム遅延化の可能性
3. (自分の意見)参照文書以外に基づく回答 ◦ RAGまでやってほしい 4. ユーザデータ ◦ ユーザデータの無い歯痒さ ◦ 検索ではログデータがあるので十分に活用したい 5. ユーザスタディ ◦ 設定したペルソナ像と、実際の実験協力者のペルソナの一致が確認されていない ⇨ユーザー検証は、ペルソナの条件を満たす人物に依頼するべき ◦ そこまでやらないと、パイプラインの真の有効性(実際の人間への)は示されない 限界 課題 32
• データなしでもパーソナライズ ◦ ペルソナ(職業)×ゴールを合成し、質問生成 • 多様性や読者適合性の評価が難しさを解決 → 新指標「逆ランキング評価法」により 「意図したペルソナの視点を反映しているか」を定量化 ◦
人手評価でも質問の選好についての有効性があった • オンデバイス実現のために ◦ 小型モデルでFine-tuningした場合に 大規模モデルと同等の性能があり、有効性が示された まとめ 33 なんで 採択されたと思う?
補足 34
• LLM使い物になるの? ◦ GPT-4 : 人間の専門家の評価と8割以上の一致率らしい • Limitation ◦ Position
Bias • 回答される順番によって評価が左右される ◦ Verbosity Bias • 冗長な回答を好む傾向 ◦ Self-enhancement Bias • 自身or同系列モデルが生成した回答を高く評価する傾向 ◦ 推論能力 • 論理的推論が介入する評価が苦手 ◦ 問題を正しく解けないことによる 人間による評価からLLMによる評価へ 35 Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena によると
Coverage Ratio Distribution Skewness 36 金融ドメイン 法律ドメイン 学術ドメイン オレンジ:ペルソナあり 青
:ペルソナなし
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![② Persona Generator 10 • LLMが職業とそのゴール5個を生成 ◦ {職業₁:[ゴール₁₁,…], …} ◦](https://files.speakerdeck.com/presentations/d6ae8b606a6d479782ff8d5e9c9a6d44/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}