I’m starvin’. I throw open my laptop, and search by what I've got in the house to minimize me running to the store. I'm craving a flavor, not necessarily a cuisine. Some southern food has its origins in West African food. How do recipe searches address this? How do we combine curation of good recipe content with better search to avoid having to build a recommendation engine? In this talk, we’ll take a look at the current state of web recipe discovery and how I naively tried to come up with an alternative with brute JavaScript force and graph-databasing(Neo4j); like baking a souffle for a dinner party and doing a no-fall dance before it comes out of the oven. Plan for the worst and be delighted when it doesn’t happen(or chuckle when it does)!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
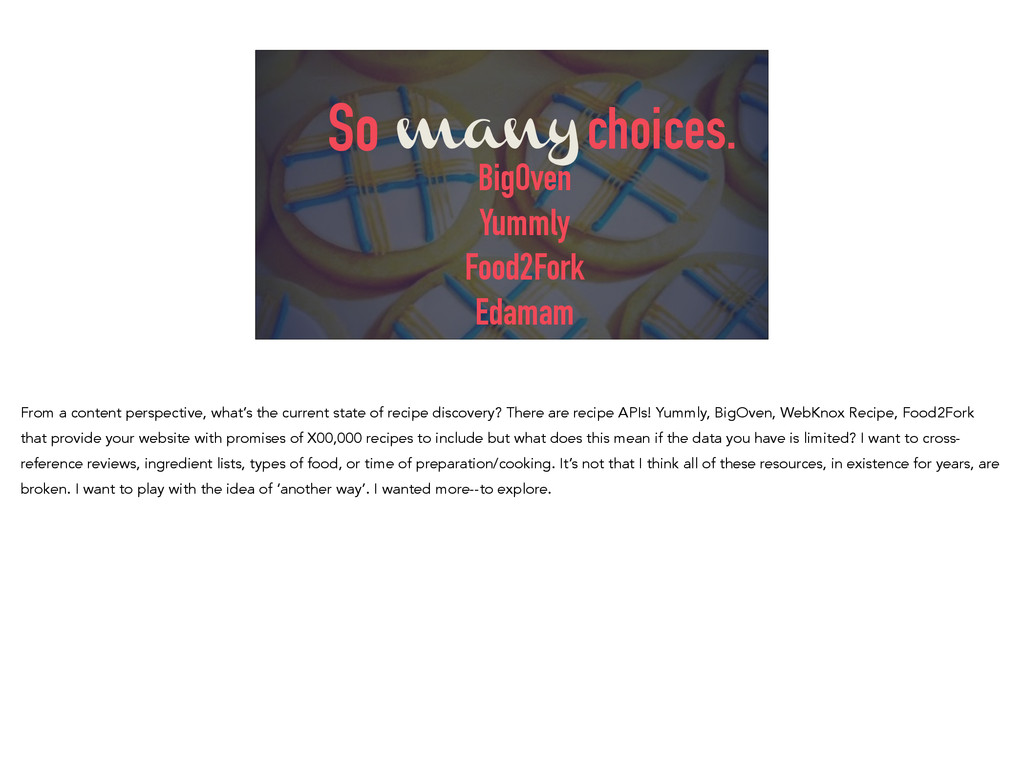{kind=link}
{kind=link}
{kind=link}
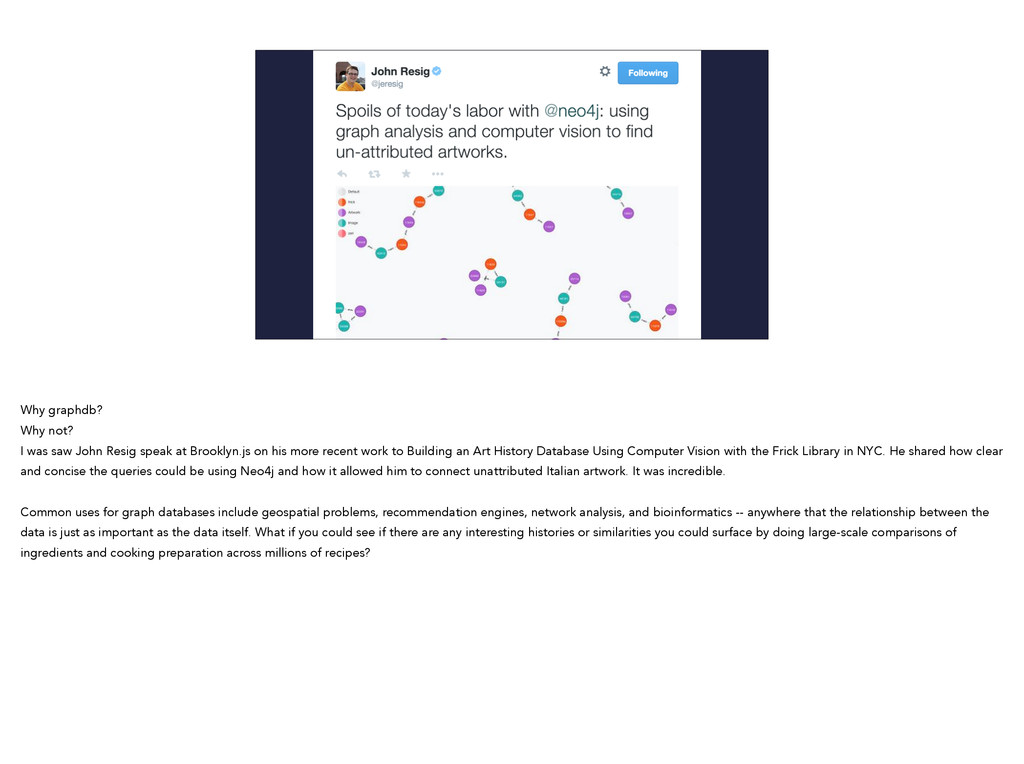{kind=link}
{kind=link}
![CYPHER is for ASCII lovers. (recipe) -[:CONTAINS]-> (ingredient) Node syntax](https://files.speakerdeck.com/presentations/3706fab9e1124587a36cca513b49869c/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}