Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
企業内スモールデータでのデータ解析
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
hamage
July 30, 2022
Programming
1.8k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
企業内スモールデータでのデータ解析
1.ビッグデータからスモールデータへ
2.ディープラーニングの弱点
3.企業内DX担当者の悩み
4.スモールデータ解析事例
・PLS
・MIC
hamage
July 30, 2022
More Decks by hamage
See All by hamage
前処理と特徴量エンジニアリング
hamage9
2
360
Other Decks in Programming
See All in Programming
Foundation Models frameworkで画像分析
ryodeveloper
1
250
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1.1k
TSX の <Hoge<Fuga>> という構文に驚いた話 / tsx-type-argument-syntax
kanaru0928
0
160
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
200
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
200
継続モナドとリアクティブプログラミング
yukikurage
3
670
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
3.3k
PostgreSQL 18で考えるUUID主キー
kazuhiro1982
0
450
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
290
その節約、円になってますか?
isamumumu
0
630
jsmini JavaScript Engine を作ってみた話
yosuke_furukawa
PRO
0
280
5分で問診!Composer セキュリティ健康診断
codmoninc
0
770
Featured
See All Featured
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
470
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Exploring anti-patterns in Rails
aemeredith
3
450
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
920
Speed Design
sergeychernyshev
33
2k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
232
55k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
4.1k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
400
Paper Plane (Part 1)
katiecoart
PRO
1
9.9k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
66
57k
A Soul's Torment
seathinner
6
3.1k
Transcript
企業内スモールデータでのデータ解析 2022-7-30 濱川 普紀
自己紹介 大阪在住 職業:某繊維メーカーで自社のスマートファクトリー化に従事しています Python歴:4年 趣味:電子音楽制作、ライブ活動 Name : 濱川普紀 Hamakawa Hirotoshi
@hamage9
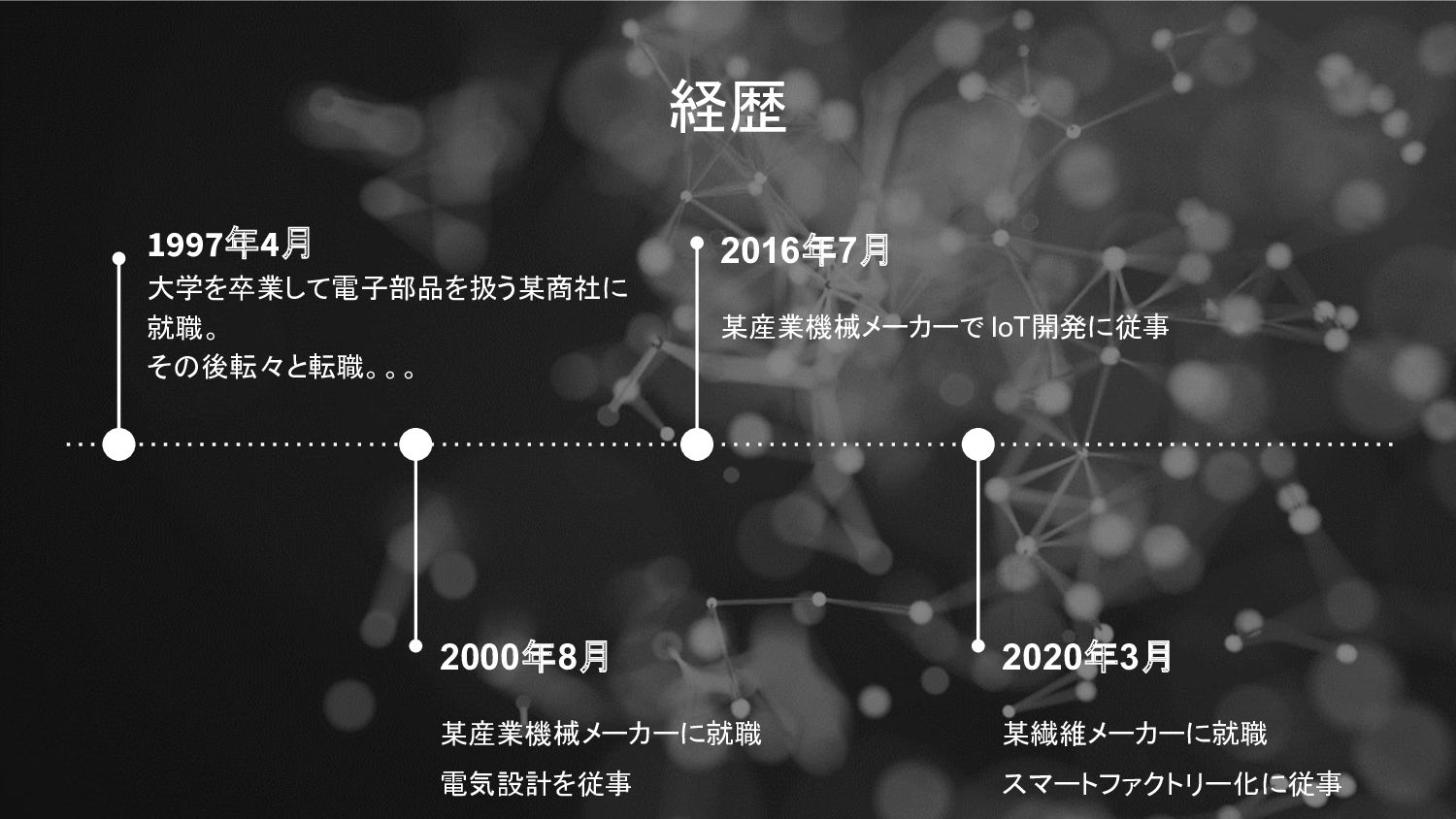
経歴 2000年8月 某産業機械メーカーに就職 電気設計を従事 2016年7月 某産業機械メーカーで IoT開発に従事 2020年3月 某繊維メーカーに就職 スマートファクトリー化に従事
1997年4月 大学を卒業して電子部品を扱う某商社に 就職。 その後転々と転職。。。
1.ビッグデータからスモールデータへ 2.ディープラーニングの弱点 3.企業内DX担当者の悩み 4.スモールデータ解析事例 Agenda
ビッグデータからスモールデータへ ビッグデータ解析の代表としてディープラーニングが注目されてきたが、その背景にはインターネッ トから大量のラベル付きデータが得られることが挙げられる。
ビッグデータからスモールデータへ しかし、企業にとって必要なデータもインターネットから得られるか? No!! 企業(特に製造業)にとって必要なデータは下記のようなスモールデータである • 装置故障などの異常データやメンテナンス記録 • 抜き取り検査の結果をプロセスデータと結合したデータ •
実験にて収集されたデータ • 顧客の購入履歴
ビッグデータからスモールデータへ スモールデータは最近、注目されている。
ディープラーニングの弱点 AIの代表的な手法であるディープラーニングにも、下記のような弱点がある。 1. 大量にデータが必要 →スモールデータだと解析できない。。。 2. 計算コストが高い →自社内のデータ解析の為にクラウドの GPU積んだVM使うの?? 3.
解釈性が低い →XAI分野は日々進歩しているが、工場の人たちを納得させるには物理化学的に辻褄が 合っていることが重要。 。。。じゃあ、どんな手法を使おうか??
企業内DX担当者の悩み ・A:定数 ・B:定数 ・z : 外生変数(exogenous variable) AIやIoT、DXのようなバズワードが流行り出すと、企業の偉いさんからは、、 • 当社もAIやディープラーニングを使ってDXをしてくれ!
→(ぼやき)いや、AIとかDLとかは手段だから、それを使って何をするのか、 どのような目的なのかが重要でしょ。。。 DLするにはデータが大量に必要ですけど。。。 • データが必要?ではIoT基盤を導入するぞ! →(ぼやき)いやいや、だから導入するのはいいけど、導入して何に使うの? それによって、どんなデータをどのような頻度で収集するのか決まら ないんですけど。。。 • 当社もIoT基盤を導入したので安泰だな! →(ぼやき)いやいやいや、そのデータ誰が解析するのよ。オレ一人じゃ 無理よ。。。社内教育を進めないといけないんですけど。。。
企業内DX担当者の悩み ・A:定数 ・B:定数 ・z : 外生変数(exogenous variable) • 前処理にどれだけ時間がかかってるんだ! →(ぼやき)いやいやいやいや、解析の
80%は前処理って言われてて、一番時間がかかる作業だし、 ここで間違ったことをするとちゃんと解析できないので、重要なんですけど。。。 • Auto MLというのがあるそうじゃないか、誰でも解析できるな! →(ぼやき)いやいやいやいやいや、例えば欠損処理でも何故欠損したかというような 背景を理解したり、他のデータも欠損しているかどうかなどを調査しない と、どう処理したらいいか決められないでしょ。。。
企業内DX担当者の悩み ・A:定数 ・B:定数 ・z : 外生変数(exogenous variable) 工場の担当者からは、、 • 異常データを検知したいんじゃなくて、異常を無くしたいんだよ
→ディープラーニングは不向き。決定木や線形回帰など解釈性が高い手法で解析必要。 • AIでちゃちゃっとできるんでしょ? →いや、皆さんのドメイン知識が重要になります。 • 要は相関が高いやつ見つければいいんでしょ? →相関が高いのは、あくまで線形的な関係性が高いというだけなんで、 必ずしもそのようなことはないですよね。。。
スモールデータ解析事例 PLS(部分的最小二乗法) 通常の線形回帰だと、、、 • 多重共線性の問題 • 説明変数と同じかそれ以上のデータが必要 (バーニーおじさんのルールだと 10倍必要?)
スモールデータ解析事例 PLS(部分的最小二乗法) 主成分回帰(PCR)だと、、、 • 多重共線性? →説明変数どうしが独立なので問題なし • 説明変数と同じかそれ以上のデータが必要? →線形回帰と同様に必要 •
次元削減したデータは目的変数との相関関係は考慮されていない
スモールデータ解析事例 PLS(部分的最小二乗法) PLSだと、、、 • 多重共線性? →説明変数どうしが独立なので問題なし • 説明変数と同じかそれ以上のデータが必要? →データの方が少なくても計算可能 •
次元削減したデータは目的変数との相関関係は考慮されていない? →次元削減の時に目的変数との相関関係も考慮されている!!
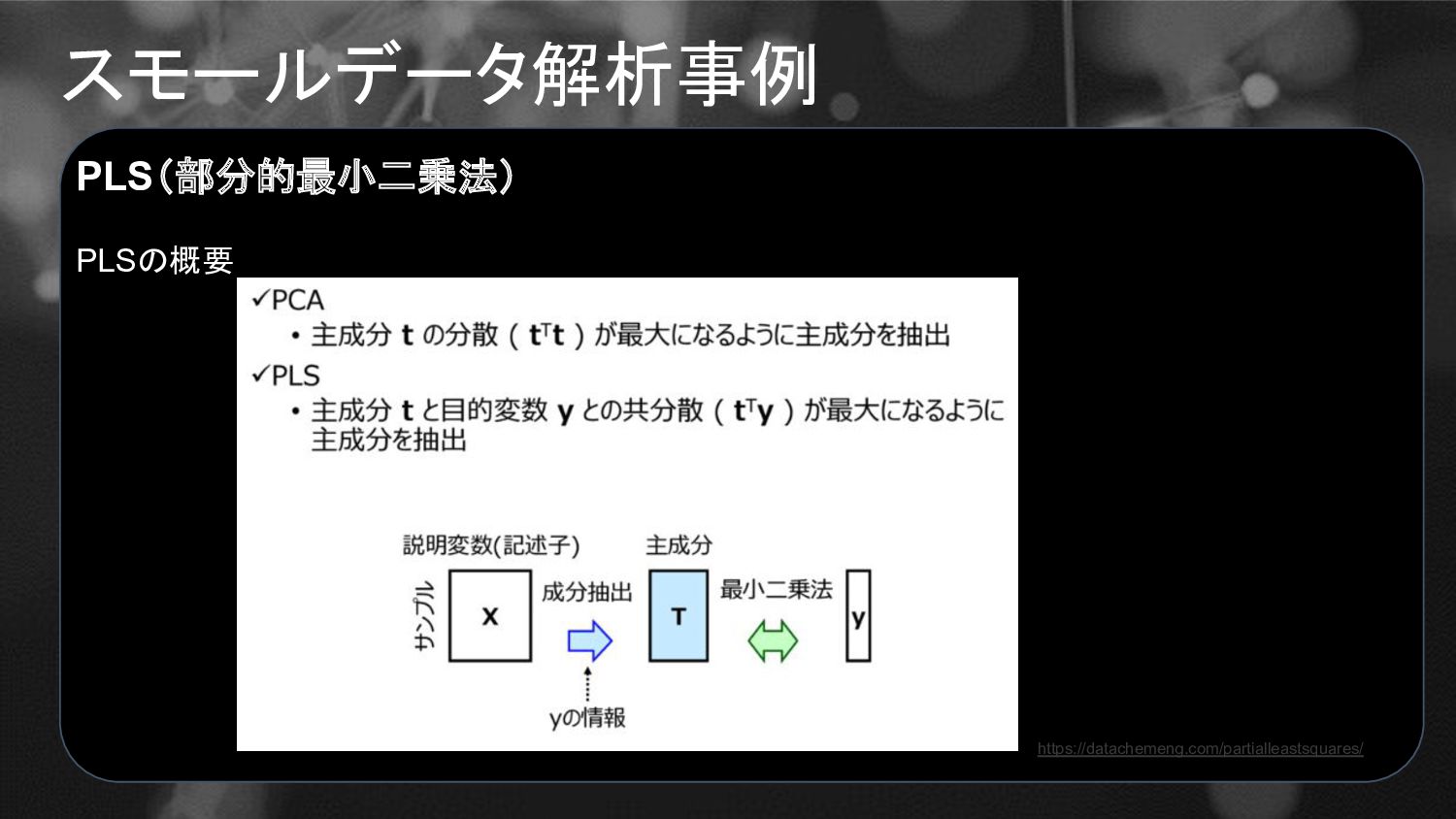
スモールデータ解析事例 PLS(部分的最小二乗法) PLSの概要 • 線形の回帰分析手法の1つ • 説明変数(記述子)の数がサンプルの数より多くても計算可能 • 回帰式を作るときにノイズの影響を受けにくい •
説明変数の間の相関が高くても対応可能 • 主成分分析をしたあとの主成分と目的変数との間で最小二乗法を行うのは主成分回帰 (PCR) であり、PLSとは異なるので注意 https://datachemeng.com/partialleastsquares/
スモールデータ解析事例 PLS(部分的最小二乗法) PLSの概要 https://datachemeng.com/partialleastsquares/
スモールデータ解析事例 PLS(部分的最小二乗法) PLSはいろんな書籍で紹介されています
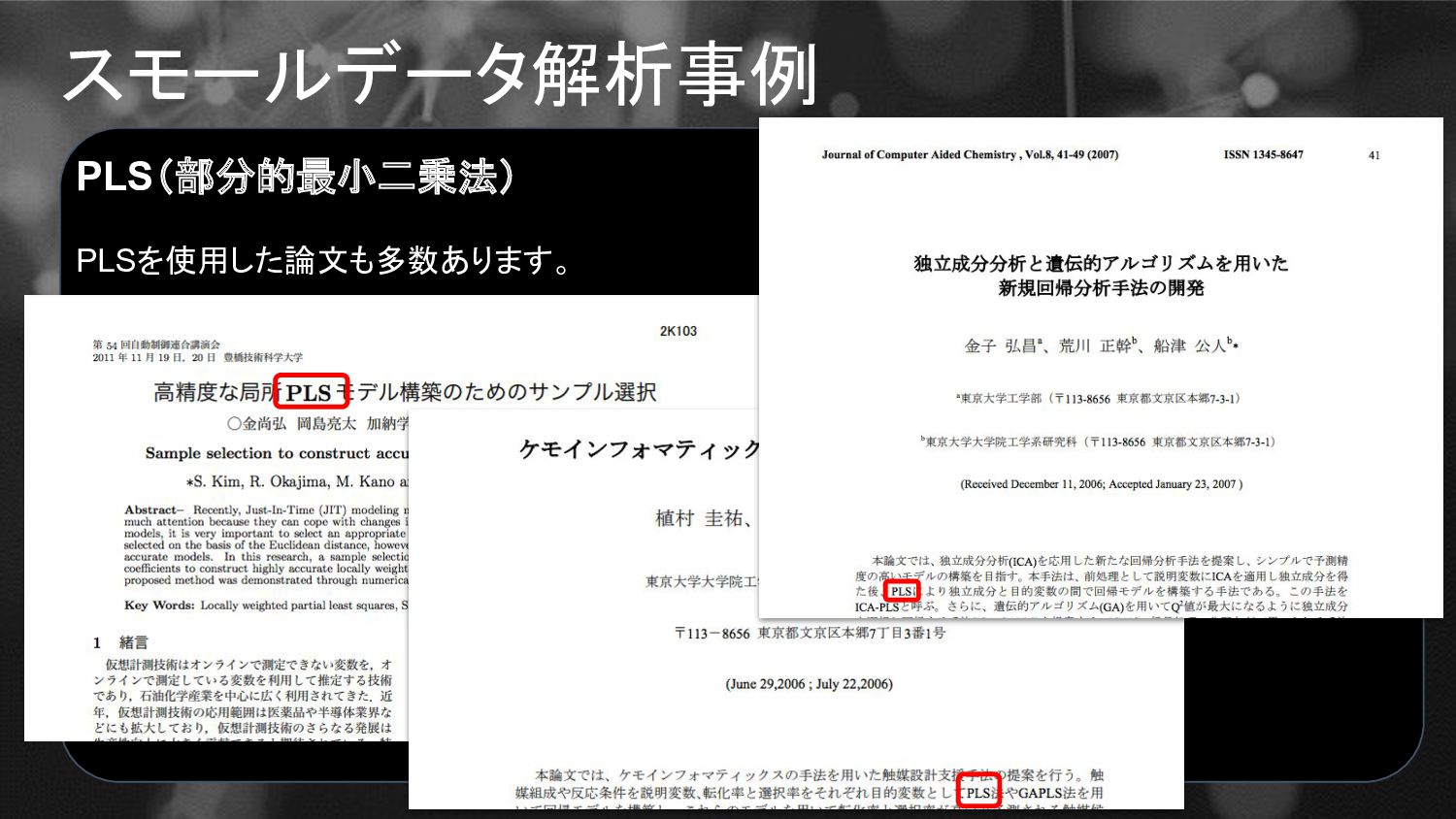
スモールデータ解析事例 PLS(部分的最小二乗法) PLSを使用した論文も多数あります。
スモールデータ解析事例 PLS(部分的最小二乗法) 詳しくは、先ほど紹介した書籍以外に、下記も参考になります。 部分的最小二乗回帰 (Partial Least Squares Regression, PLS)~回帰分析は最初にこれ! ~https://datachemeng.com/partialleastsquares/
【徹底解説】PLS(部分的最小二乗法)とは https://academ-aid.com/ml/pls 06. PLS(部分的最小二乗法) http://manabukano.brilliant-future.net/lecture/dataanalysis/doc06_PLS.pdf
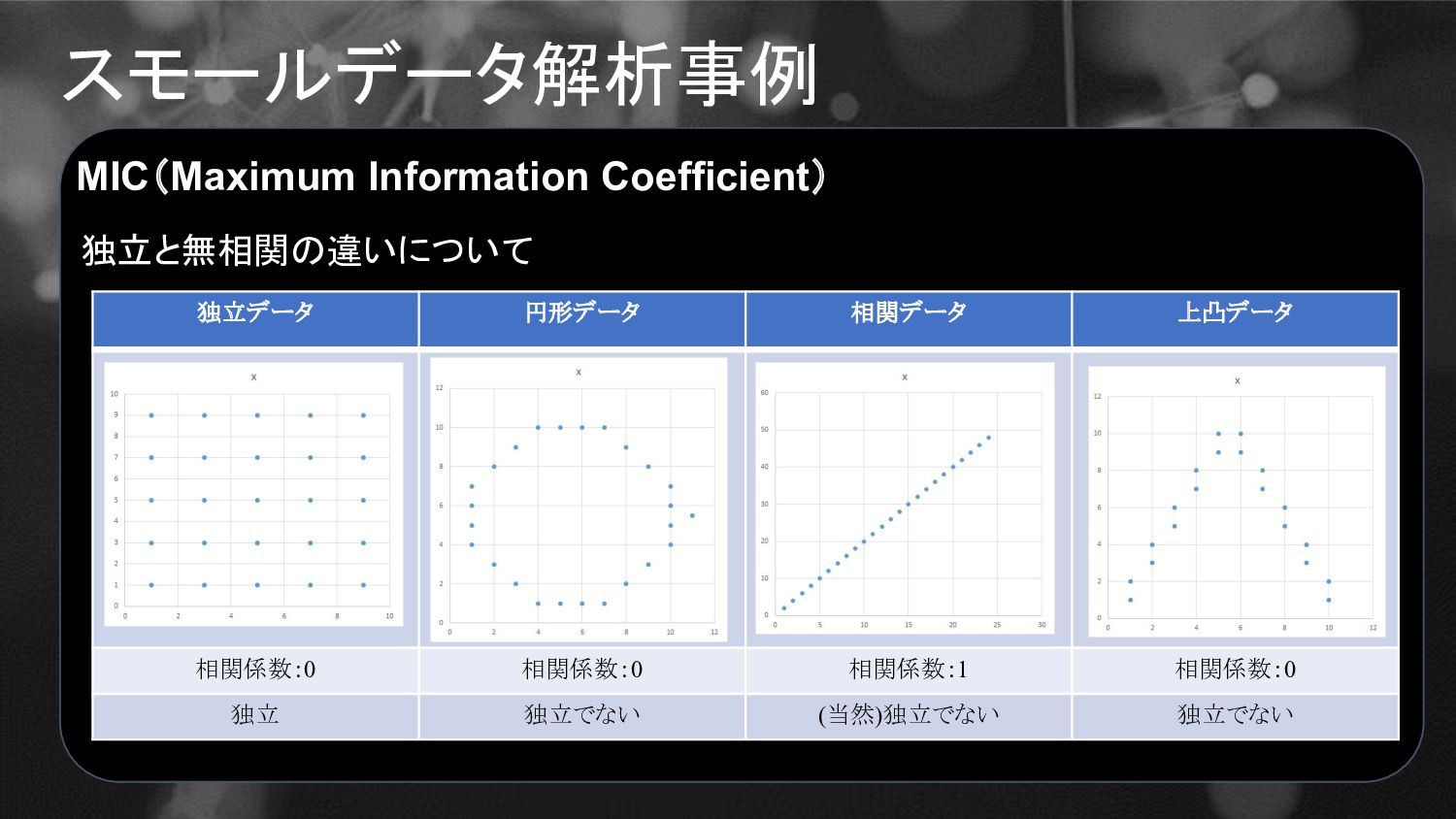
スモールデータ解析事例 MIC(Maximum Information Coefficient) 独立と無相関の違いについて 独立データ 円形データ 相関データ 上凸データ 相関係数:0
相関係数:0 相関係数:1 相関係数:0 独立 独立でない (当然)独立でない 独立でない
スモールデータ解析事例 MIC(Maximum Information Coefficient) 独立と無相関の違いについて 独立データ 円形データ 相関データ 上凸データ 相関係数:0
相関係数:0 相関係数:1 相関係数:0 独立 独立でない (当然)独立でない 独立でない 物性試験データとプロセスデー タの関係がこのようになることは 考えられませんか? 相関だけでは有用 なデータを見つけら れない
スモールデータ解析事例 MIC(Maximum Information Coefficient) 独立と無相関の違いについて 無相関 独立 直感的な意味合い 直線的な関係が無い 何の関係性も無い
イメージ 散布図を4つに分けた場合に右上及び 左下、もしくは右下及び左上にデータが 集まっていない 散布図をグリッドで分けた場合に、デー タが全体的に点在している 定義式 E[XY} = E[X]E[Y] P(x,y) = P(x)P(y) https://manabitimes.jp/math/934
スモールデータ解析事例 MIC(Maximum Information Coefficient) 独立と無相関の違いについて 無相関 独立 直感的な意味合い 直線的な関係が無い 何の関係性も無い
イメージ 散布図を4つに分けた場合に右上及び 左下、もしくは右下及び左上にデータが 集まっていない 散布図をグリッドで分けた場合に、デー タが全体的に点在している 定義式 E[XY} = E[X]E[Y] P(x,y) = P(x)P(y) https://manabitimes.jp/math/934 ・独立なら無相関 ・無相関でも独立とは限らない
スモールデータ解析事例 MIC(Maximum Information Coefficient) MIC→新しい相関係数 https://www.slideshare.net/logics-of-blue/mic-31810194
スモールデータ解析事例 MIC(Maximum Information Coefficient) MIC→新しい相関係数 相互情報量 MICは相互情報量を ・0~1にスケーリングし、 ・分割する数を最適化した もの
独立の定義式P(x,y) = P(x)P(y) より、独立の場合にlogの中身が1にな り、log1=0より、独立の場合にMICは0 になる。
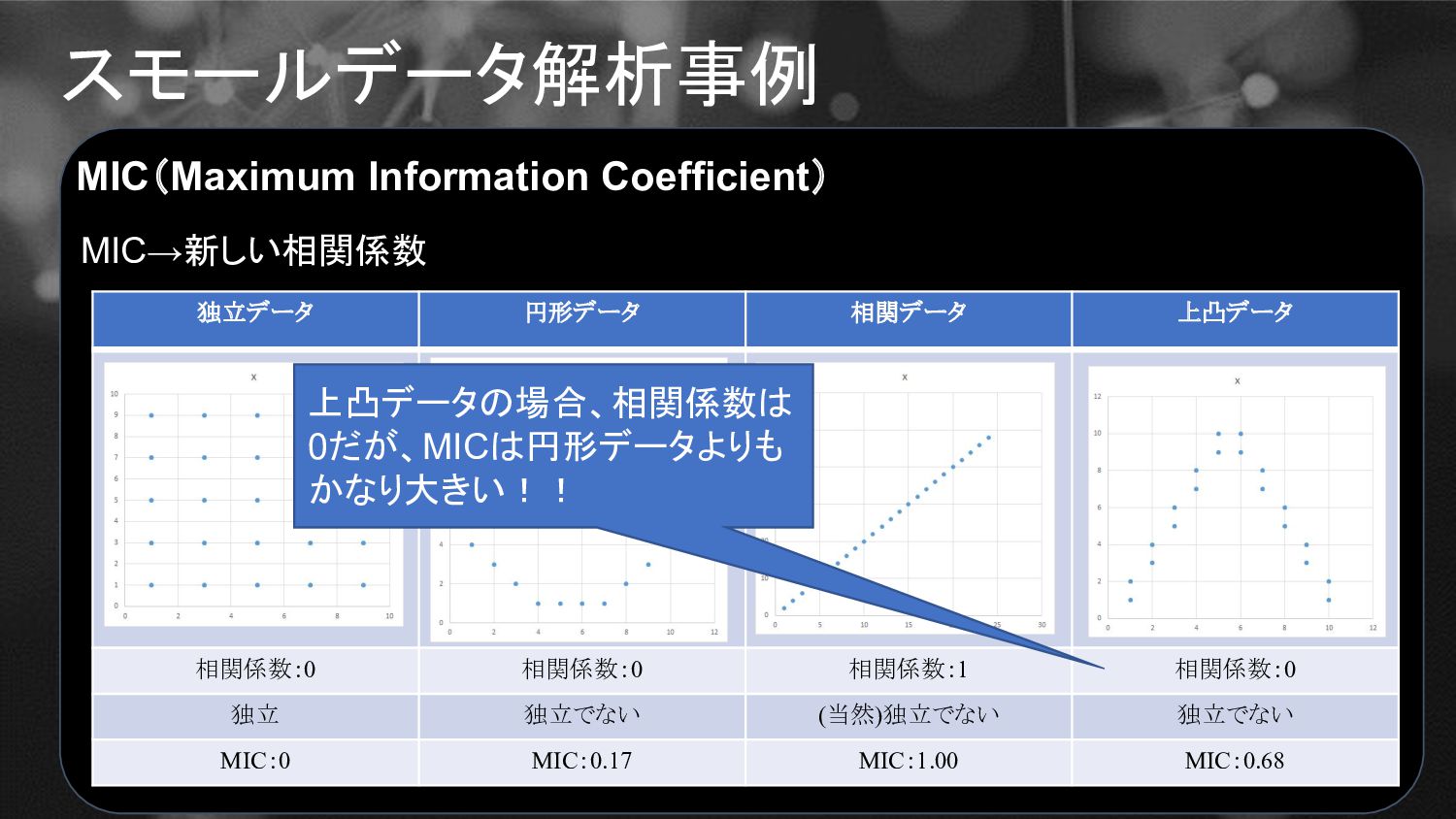
スモールデータ解析事例 MIC(Maximum Information Coefficient) MIC→新しい相関係数 独立データ 円形データ 相関データ 上凸データ 相関係数:0
相関係数:0 相関係数:1 相関係数:0 独立 独立でない (当然)独立でない 独立でない MIC:0 MIC:0.17 MIC:1.00 MIC:0.68
スモールデータ解析事例 MIC(Maximum Information Coefficient) MIC→新しい相関係数 独立データ 円形データ 相関データ 上凸データ 相関係数:0
相関係数:0 相関係数:1 相関係数:0 独立 独立でない (当然)独立でない 独立でない MIC:0 MIC:0.17 MIC:1.00 MIC:0.68 上凸データの場合、相関係数は 0だが、MICは円形データよりも かなり大きい!!
ご静聴ありがとうございました 濱川 普紀 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}