Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
前処理と特徴量エンジニアリング
Search
hamage
May 28, 2020
Technology
360
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
前処理と特徴量エンジニアリング
1.前処理が作業の80%
2.データ量は足りてるか?
3.逆に特徴量が多い?
4.異常データが足りない!
5.標準化か?正規化か?
hamage
May 28, 2020
More Decks by hamage
See All by hamage
企業内スモールデータでのデータ解析
hamage9
0
1.8k
Other Decks in Technology
See All in Technology
新しい SLO が良い感じにハマっている話
z63d
4
1.8k
AI驚き屋発見器
yama3133
1
390
Data Hubグループ 紹介資料
sansan33
PRO
0
3.1k
ガバメントクラウドでのランサムウェア対策
techniczna
1
480
データ組織の転換期 一足飛びしない段階的戦略
leveragestech
PRO
0
140
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
270
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
330
オートマトンと字句解析でRoslynを読む
tomokusaba
0
130
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
160
初めてのGitHub Actions / GitHub Actions at First
tooppoo
0
120
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
180
AI エージェント時代のデジタルアイデンティティ
fujie
2
1.3k
Featured
See All Featured
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Optimising Largest Contentful Paint
csswizardry
37
3.9k
RailsConf 2023
tenderlove
30
1.5k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
940
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
410
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
WENDY [Excerpt]
tessaabrams
11
39k
Typedesign – Prime Four
hannesfritz
42
3.1k
Code Review Best Practice
trishagee
74
20k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
590
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Transcript
前処理と特徴量エンジニアリング 2020年5月28日 濱川 普紀
自己紹介 大阪在住 職業:某繊維メーカーで工場のスマート化に従事しています Python歴:2年 趣味:作曲 Name : 濱川普紀 Hamakawa Hirotoshi
@hamage9
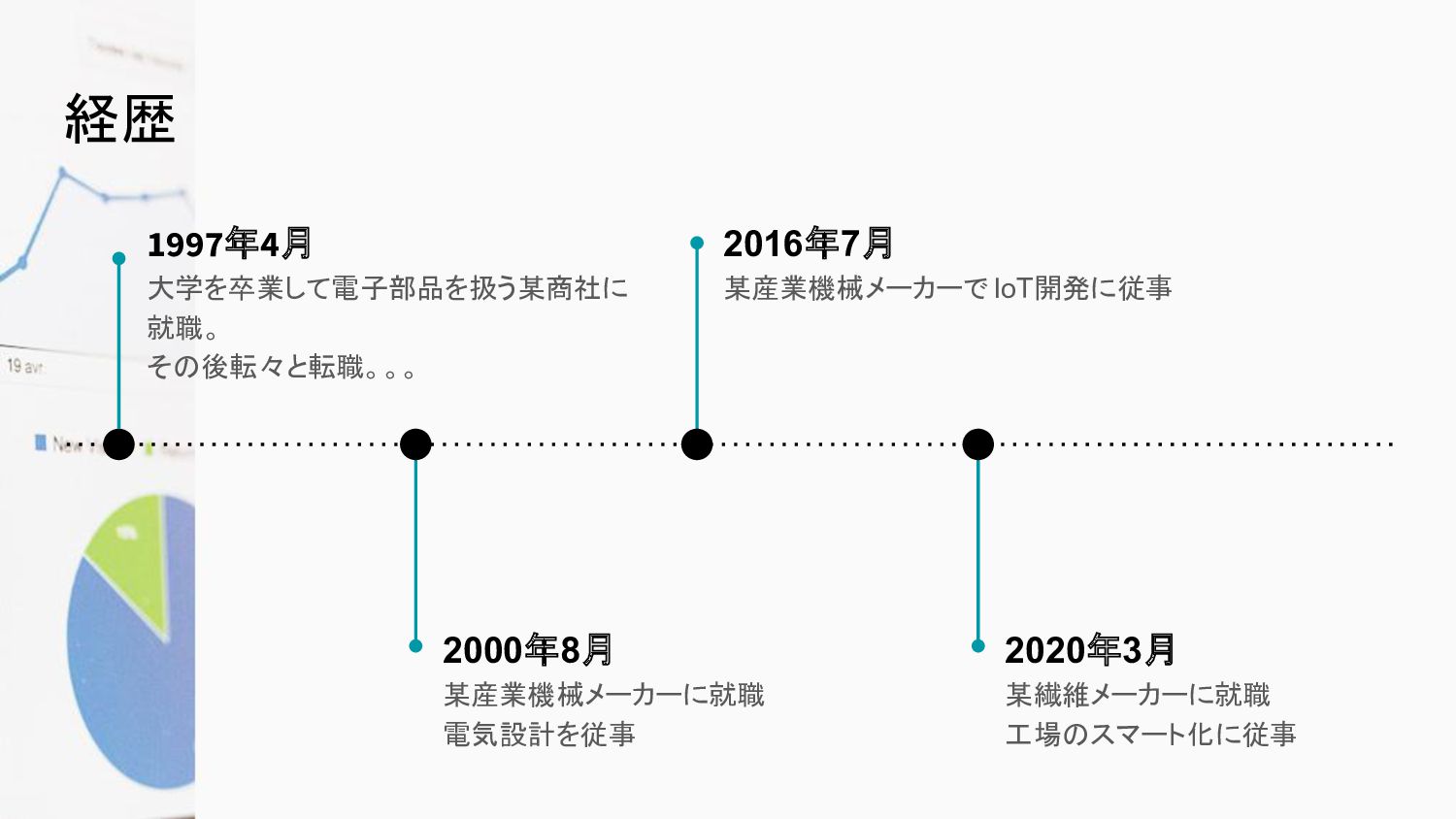
経歴 2000年8月 某産業機械メーカーに就職 電気設計を従事 2016年7月 某産業機械メーカーで IoT開発に従事 2020年3月 某繊維メーカーに就職 工場のスマート化に従事
1997年4月 大学を卒業して電子部品を扱う某商社に 就職。 その後転々と転職。。。
Agenda 1.前処理が作業の80% 2.データ量は足りてるか? 3.逆に特徴量が多い? 4.異常データが足りない! 5.標準化か?正規化か?
前処理が作業の80%
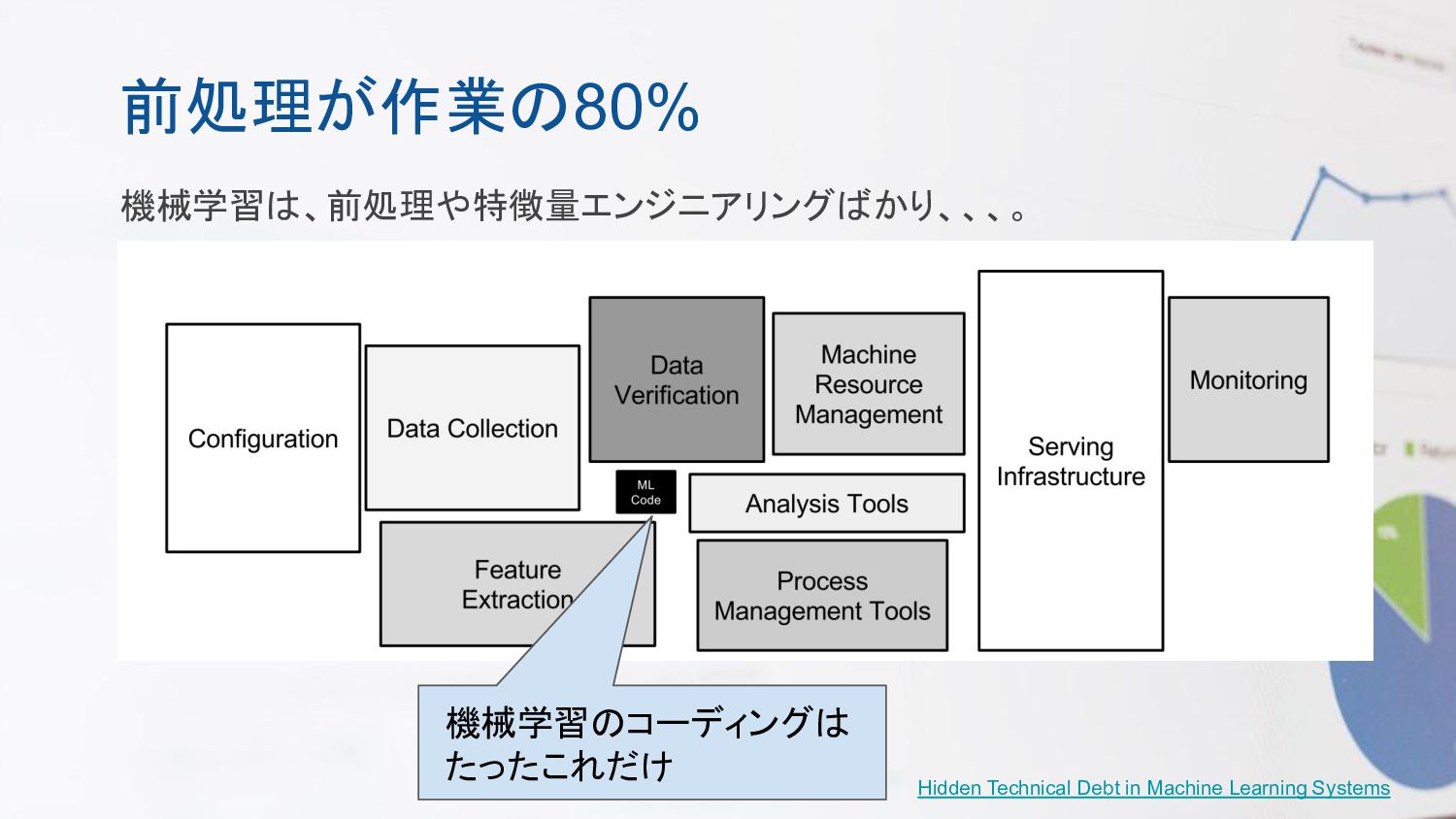
前処理が作業の80% 機械学習は、前処理や特徴量エンジニアリングばかり、、、。 機械学習のコーディングは たったこれだけ Hidden Technical Debt in Machine Learning
Systems
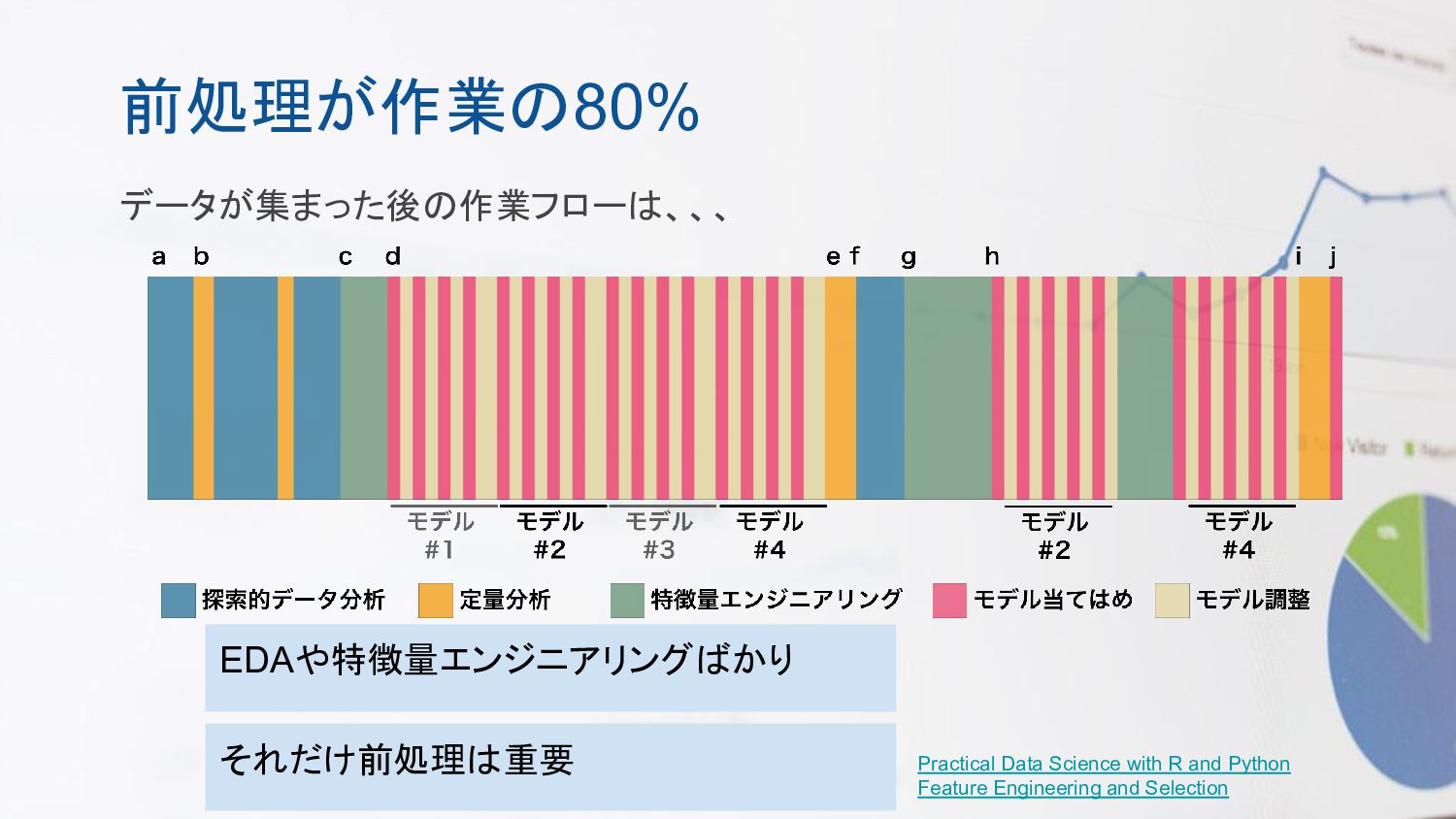
前処理が作業の80% データが集まった後の作業フローは、、、 EDAや特徴量エンジニアリングばかり Feature Engineering and Selection Practical Data Science
with R and Python それだけ前処理は重要
データ量は足りているか?
データ量は足りているか? 最低限必要なデータ量。例えば多変量関数で考えると。。。 変数の数だけ数式が必要。→特徴量の数以上のデータ量が必要 だけど、これじゃ少し足りない?
データ量は足りているか? バーニーおじさんの定理では10倍必要と言うが、、、 でもこんなにデータを集められない。 Generalization and Parameter Estimation in Feedforward Nets
「モデルのパラメータ数の10倍のデータ数が必要」
逆に特徴量が多い?
逆に特徴量が多い? 特徴量選択による次元削減 フィルタ法 ラッパー法 組み込み法 (埋め込み法) 閾値を使って有用でないと思われる特徴量を除去する手法 特徴量の一部を使って実際にモデルを学習し精度を調べる手法 モデルの学習プロセス自体に特徴量選択を組み込む手法 参考文献
Python機械学習クックブック 機械学習のための特徴量エンジニアリング Feature Engineering
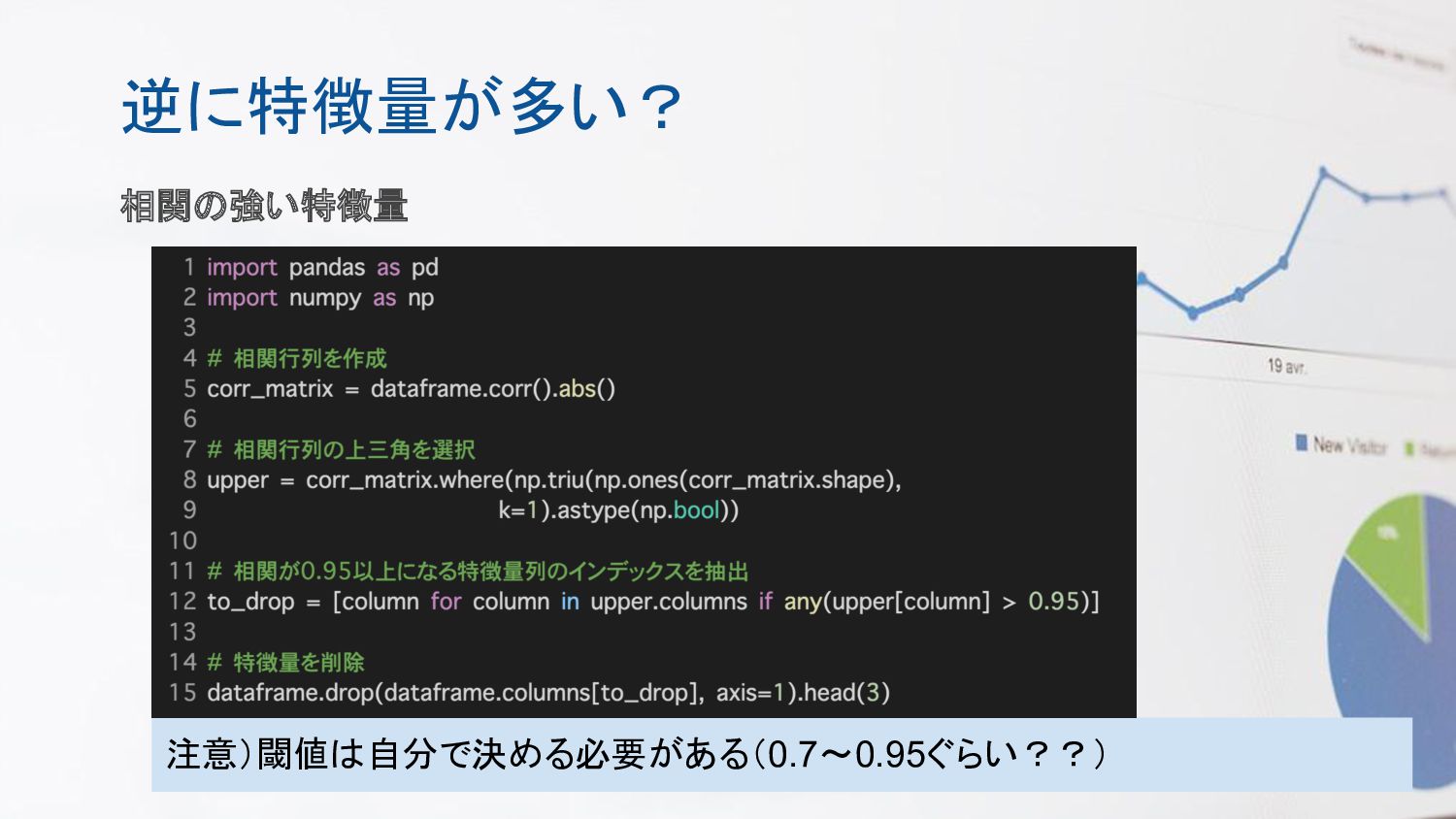
逆に特徴量が多い? フィルタ法 分散の小さい特徴量 分散が0に近い特徴量を削除 相関の強い特徴量 相関の強い特徴量の片方を削除 無関係な特徴量 クラス分類や回帰に無関係な特徴量を削除 注意)フィルタ法では、モデルにとって良い特徴量を選んでいるかどうかはわから ない
逆に特徴量が多い? 分散の小さい特徴量 →VarianceThresholdを使用 注意) 1.特徴量に単位の違うものが混じっているとうまく機能しない 2.閾値は自分で決める必要がある
逆に特徴量が多い? 相関の強い特徴量 注意)閾値は自分で決める必要がある(0.7〜0.95ぐらい??)
逆に特徴量が多い? クラス分類に無関係な特徴量(特徴量がカテゴリデータの場合) →カイ2乗統計量を使用
逆に特徴量が多い? クラス分類に無関係な特徴量(特徴量が数値データの場合) →F値を使用
逆に特徴量が多い? 回帰に無関係な特徴量 →引数をf_regressionにする
逆に特徴量が多い? ラッパー法(反復特徴量選択) →再帰的特徴量削減(recursive feature elimination:RFE)
逆に特徴量が多い? 組み込み法(埋め込み法) →モデルベース特徴量選択(SelectFromModel)使用
異常データが足りない!
異常データが足りない! 不均衡データ( Imbalanced Data)学習に用いられるアプローチ データレベル コスト考慮型学習 異常検知手法 正常と異常データの数量を均衡にするアプローチ 各クラスのデータ量に応じた重みを付けるアプローチ 異常検知手法を適用するアプローチ
参考サイト 【ML Tech RPT. 】第4回 不均衡データ学習 (Learning from Imbalanced Data) を学ぶ(1)
異常データが足りない! データレベルのアプローチ (imbalanced-learnを使用したオーバーサンプリング) 参考サイト Usage of the sampling_strategy parameter for
the different algorithms imblearn.over_sampling.SMOTE
異常データが足りない! データレベルのアプローチ (imbalanced-learnを使用したアンダーサンプリング) 参考サイト Usage of the sampling_strategy parameter for
the different algorithms ※アンダーサンプリングができるなら、ちょっと「異常データが足りない!」と言うタイトルとは相反しますが、不均衡データ の取り扱いという括りで紹介しておきます。
異常データが足りない! コスト考慮型学習のアプローチ →class_weight="balanced"と指定し、データ量に応じた重み付け 参考文献 Python機械学習クックブック
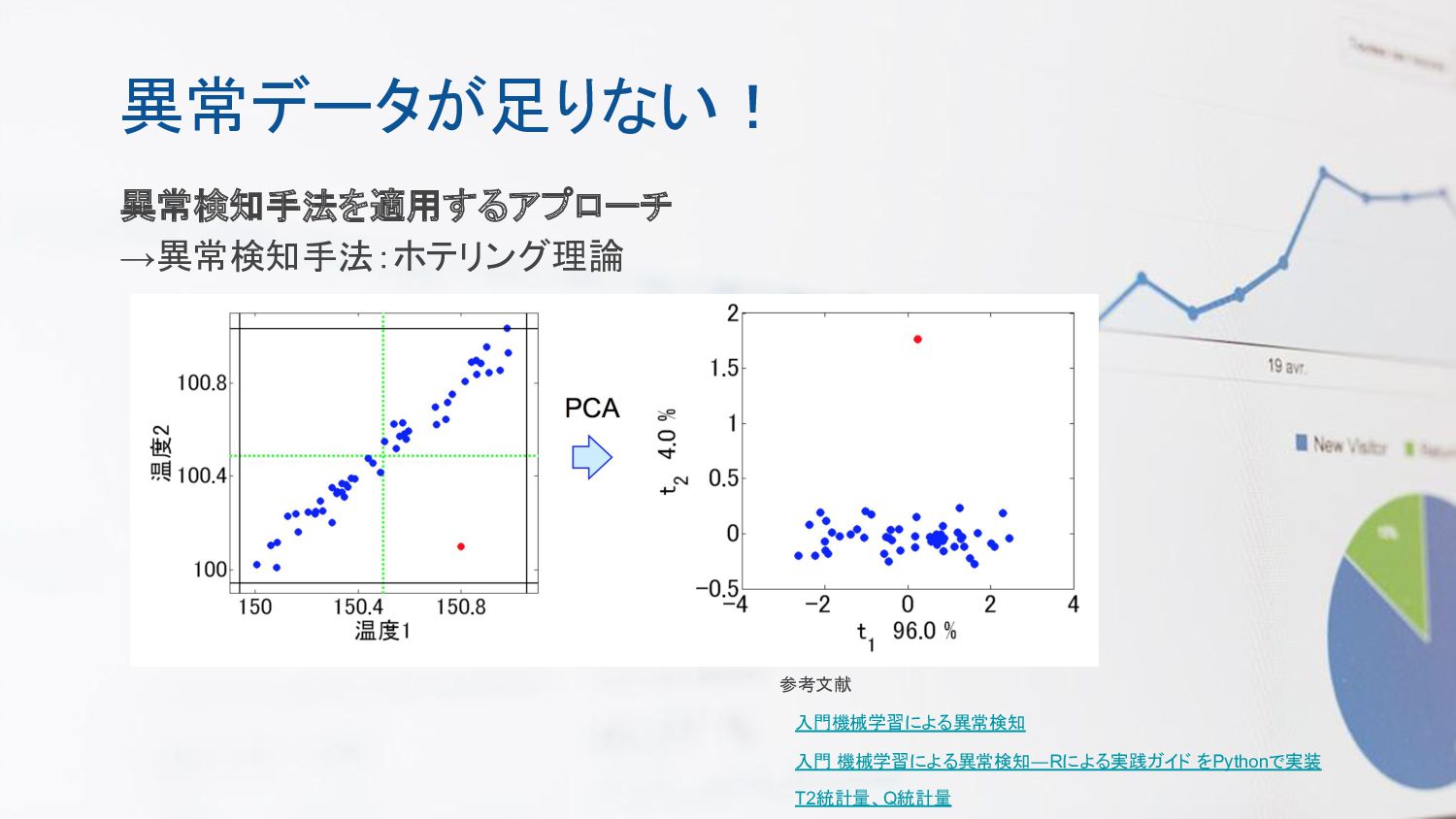
異常データが足りない! 異常検知手法を適用するアプローチ →異常検知手法:ホテリング理論 参考文献 入門機械学習による異常検知 入門 機械学習による異常検知―Rによる実践ガイド をPythonで実装 T2統計量、Q統計量
標準化か?正規化か?
標準化か?正規化か? 機械学習で行う主なスケーリング 標準化 データ全体を標準正規分布に 近似する手法 sklearn.preprocessing.StandardScaler 正規化 データ全体の最小値を最大値 を揃える手法 sklearn.preprocessing.MinMaxScaler
対数 変換 対数に変換する手法。金額や カウント表す変数に適用 numpy.log 外れ値 に頑健 四分位範囲が1になるよう変換 する手法 sklearn.preprocessing.RobustScaler 参考文献 Python機械学習クックブック Kaggleで勝つデータ分析の技術 上記以外にも多種多様な変換手法あり
標準化か?正規化か? 標準化と正規化のどちらを使えばいいの? 参考文献 Python機械学習クックブック 〜Python機械学習クックブックの抜粋〜 主成分分析には標準化が適しているが、ニューラルネットワークには min-maxスケール変換が適している。一般には、何か特別な理由がない 限り標準化を用いたほうがよい。
ご静聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}