rights reserved. 5 CAD (Computer-Aided Design, コンピュータ支援設計) 技術などの研究成果を公開している ※ 図表は元論文より引用 近年のコンピュータビジョンや機械学習分野でのPublications CLIP-Forge: Towards Zero-Shot Text-to-Shape Generation, CVPR2022 JoinABLe: Learning Bottom-up Assembly of Parametric CAD Joints, CVPR2022 BRepNet: A Topological Message Passing System for Solid Models, CVPR2021 RobustPointSet: A Dataset for Benchmarking Robustness of Point Cloud Classifiers, ICLR2021 workshop Fusion 360 Gallery: A Dataset and Environment for Programmatic CAD Construction from Human Design Sequences, SIGGRAPH 2021 Building-GAN: Graph-Conditioned Architectural Volumetric Design Generation, ICCV 2021 UV-Net: Learning from Boundary Representations, CVPR2021 UVStyle-Net: Unsupervised Few-shot Learning of 3D Style Similarity Measure for B-Reps, ICCV2021 Learning to Simulate and Design for Structural Engineering, ICML2020 PointMask: Towards Interpretable and Bias-Resilient Point Cloud Processing, ICML2020
rights reserved. 7 CAD (Computer-Aided Design, コンピュータ支援設計) 技術などの研究成果を公開している RobustPointSet: A Dataset for Benchmarking Robustness of Point Cloud Classifiers, ICLR2021 Workshop PointMask: Towards Interpretable and Bias-Resilient Point Cloud Processing, ICML2020 ※ 図表は元論文より引用 • 点群データ処理に関する研究 • データセットも公開している RobustPointSet は点群分類モデルのロバスト性を測るため に、複数の変換を適用したデータセット
{kind=link}
{kind=link}
{kind=link}
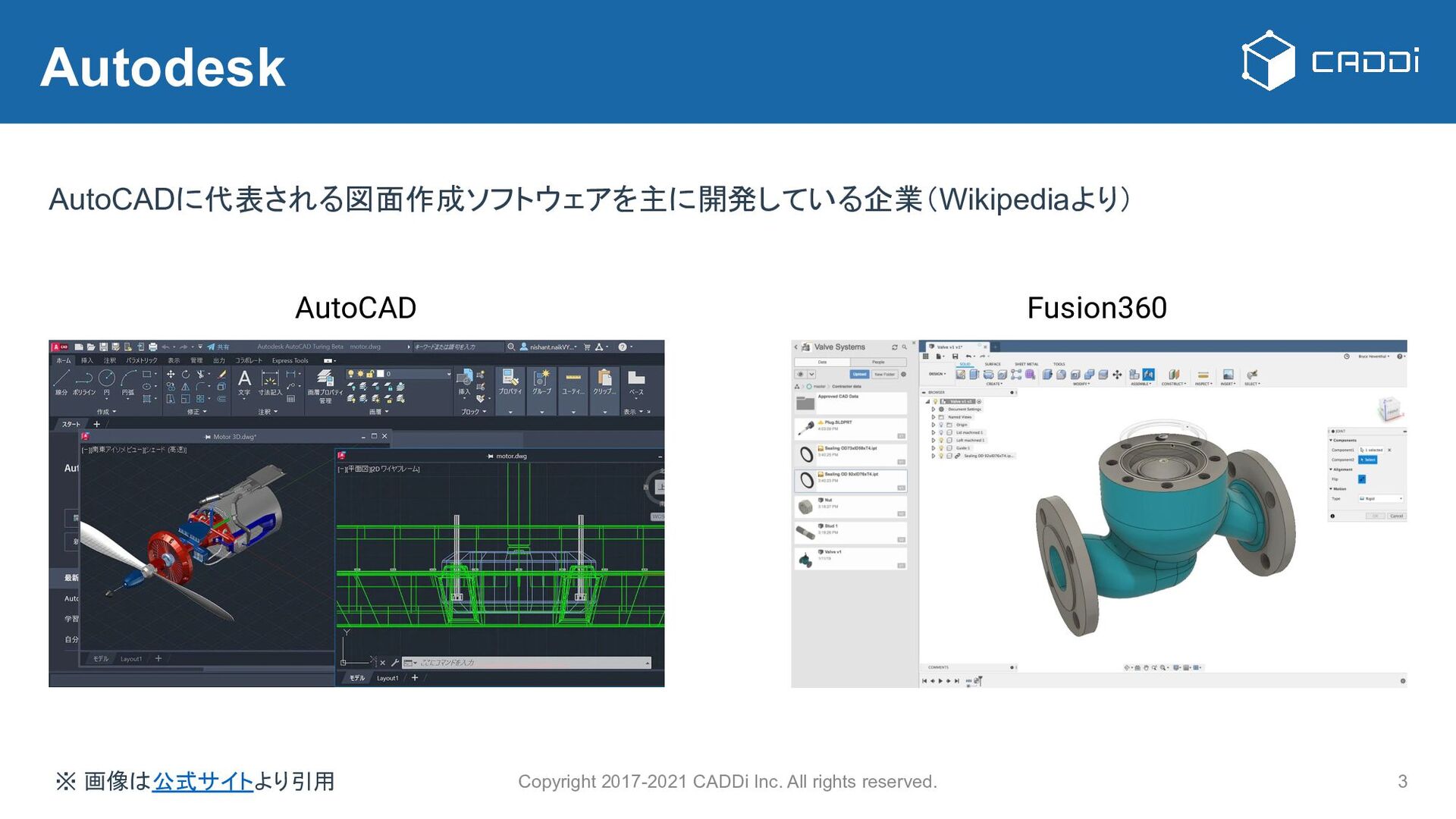{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
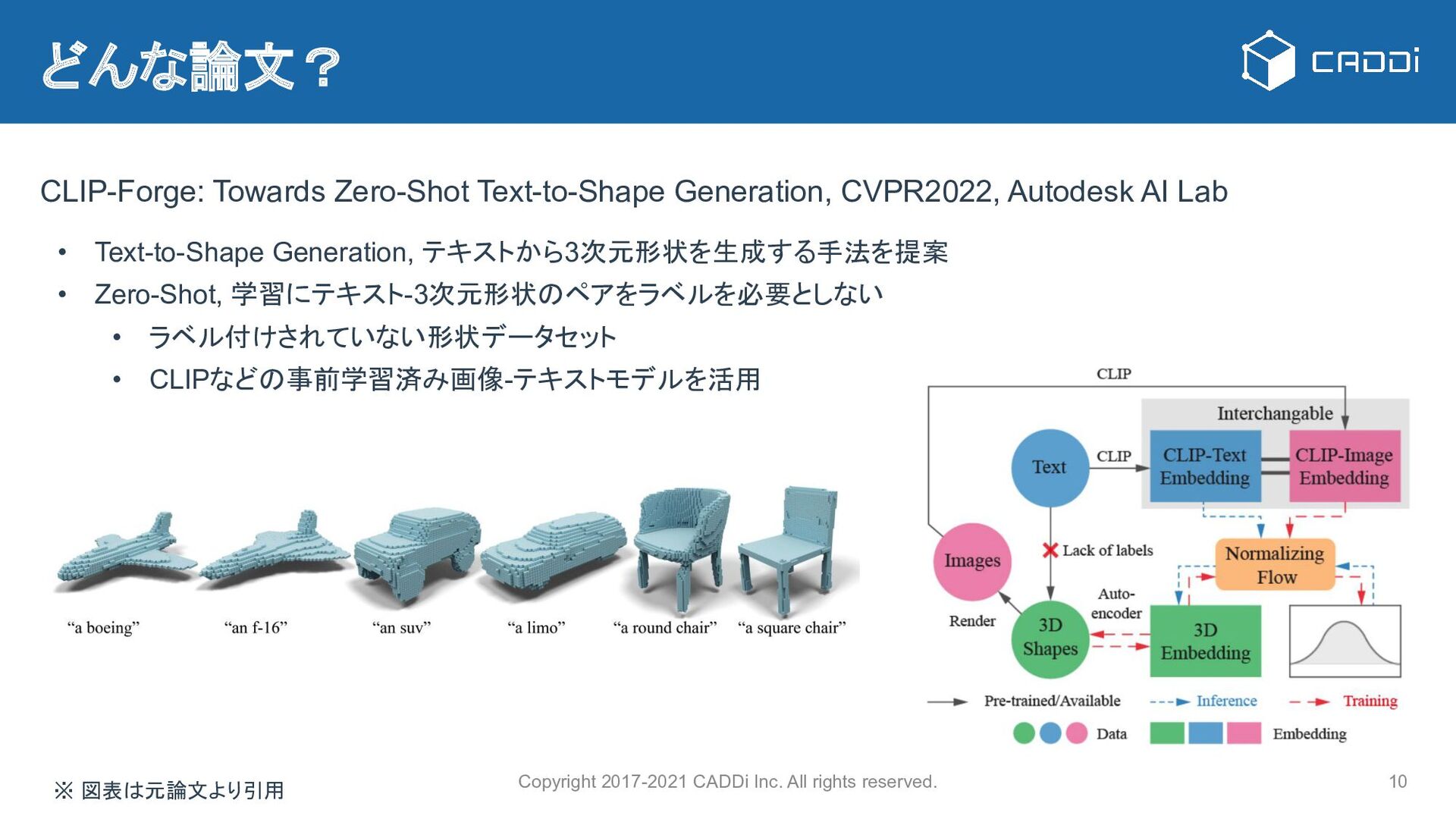{kind=link}
{kind=link}
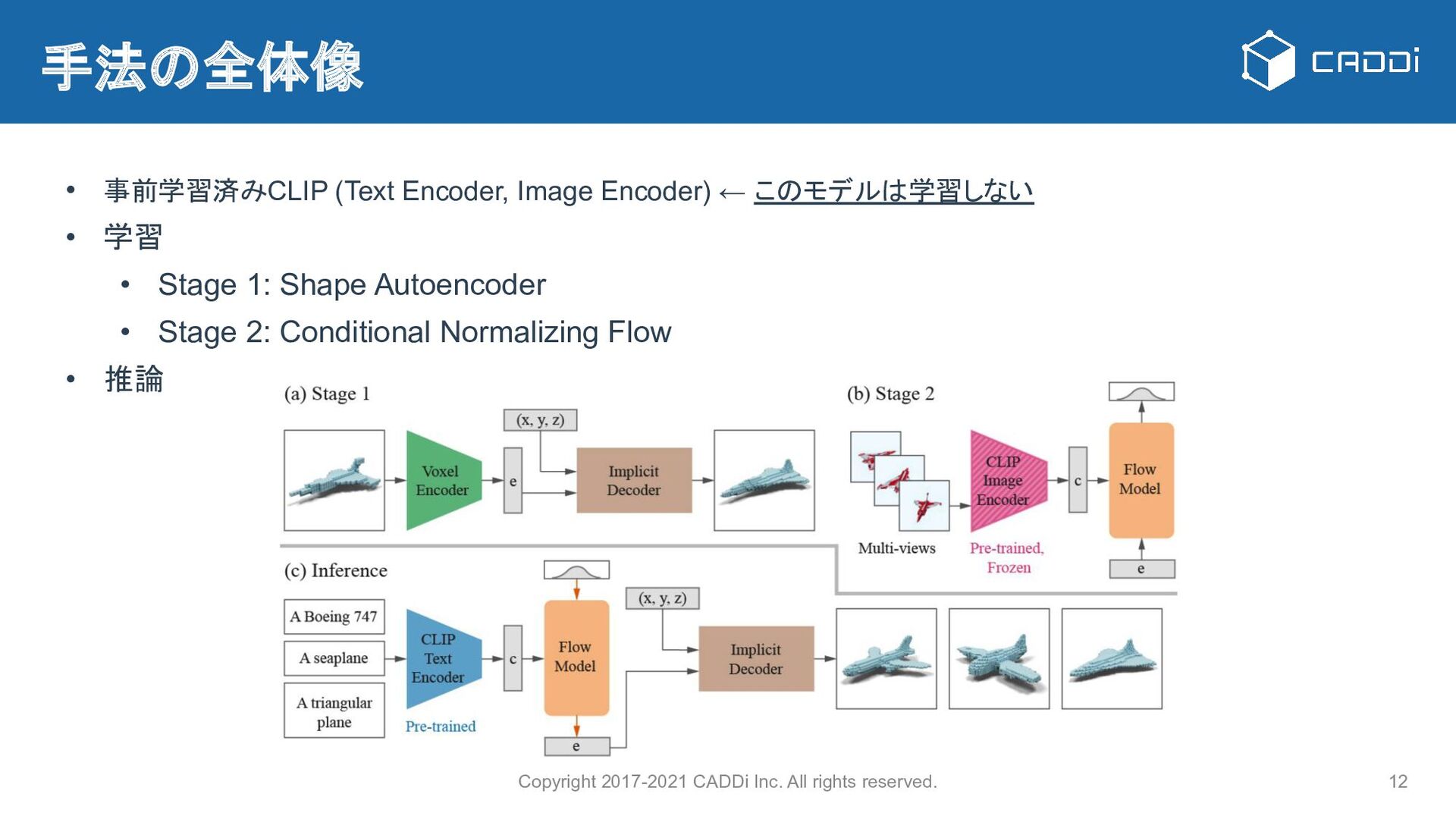{kind=link}
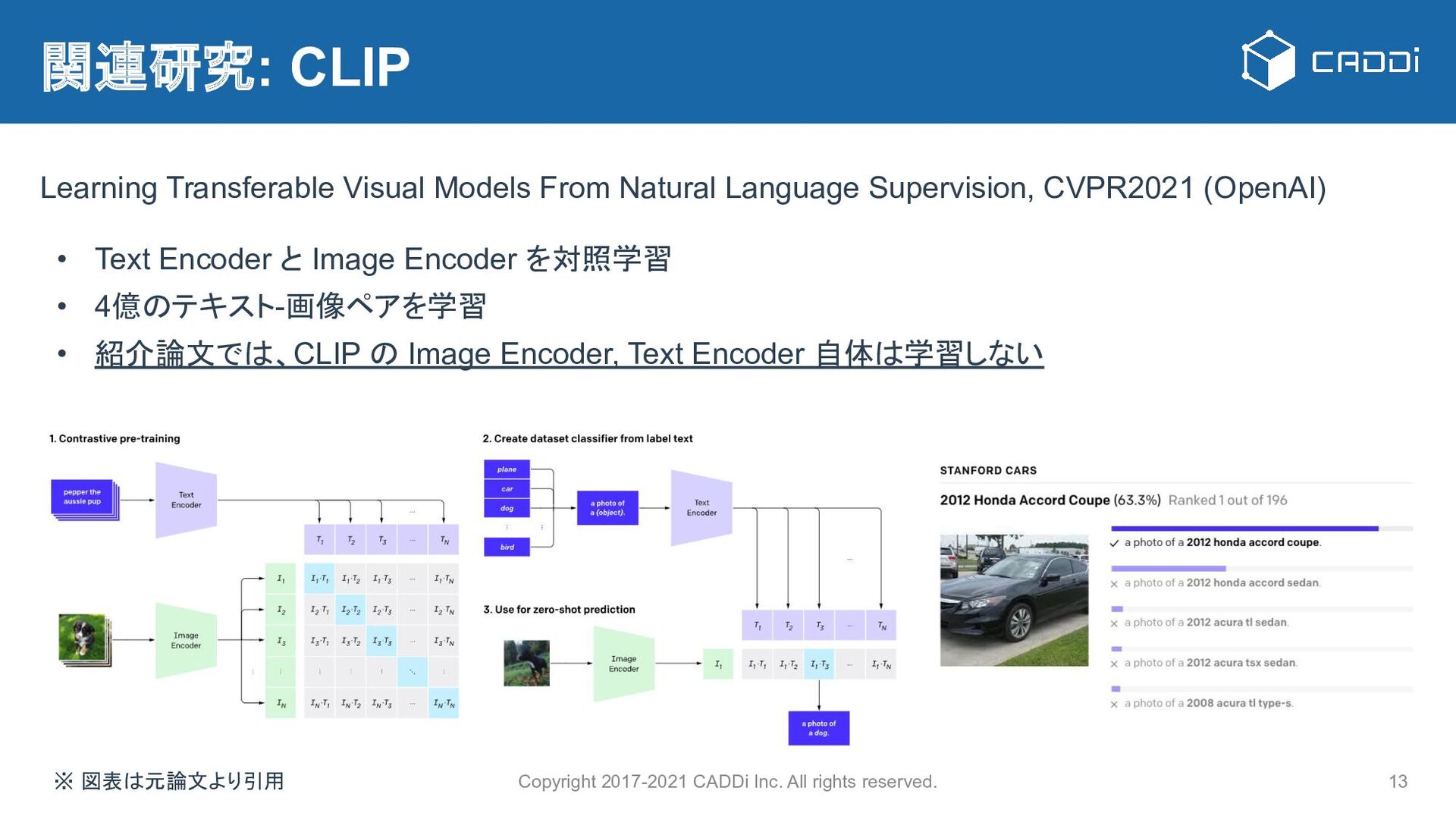{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}