Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ポストモーテムから振り返る
Search
Junnichi Kitta
July 09, 2021
Technology
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ポストモーテムから振り返る
Drecom SRE Sunday で話した内容のスライドです
https://www.youtube.com/watch?v=wua__TdBOtk
Junnichi Kitta
July 09, 2021
More Decks by Junnichi Kitta
See All by Junnichi Kitta
SREってなんだろう
hayabusa333
0
230
上から見るか下から見るか.pdf
hayabusa333
0
1.1k
Elixirでやってきたこと
hayabusa333
0
1.7k
APIサーバとしてのCowboy
hayabusa333
1
1.4k
CowboyとPhoenixの速度比較
hayabusa333
1
1.9k
E言語スタック
hayabusa333
0
570
Other Decks in Technology
See All in Technology
AICoEでAIネイティブ組織への進化
yukiogawa
0
170
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
公式ドキュメントの歩き方etc
coco_se
0
110
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
600
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
710
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
1
120
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.2k
世界、断片、モデル。そして理解
ardbeg1958
1
120
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
160
AI Driven AI Governance
pict3
0
440
知らん間に、回ってる
ming_ayami
0
600
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
250
Featured
See All Featured
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Building the Perfect Custom Keyboard
takai
2
810
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
The agentic SEO stack - context over prompts
schlessera
0
840
Paper Plane
katiecoart
PRO
2
52k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
The SEO identity crisis: Don't let AI make you average
varn
0
510
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Transcript
ポストモーテムから振り返る
自己紹介 TwitterID = hayabusa333 |> heart = [カーネル, GC, Erlang,
Elixir, SRE] |> jobs = 株式会社ドリコム |> position = [Joel教, Elixir雑魚勢, SRE初心者]
ポストモーテムとは - 発生した障害とその影響度、障害の緩和や解消の為に行わ れた対応、根本原因、再発防止の為のアクションを記録する 為のドキュメント
基本的な考え方 - 障害は必ず発生する - ポストモーテムは処罰ではなく学びの機会 - 学びを得る為には定式化されたプロセスが必要
なぜ書くか? - 障害をドキュメント化して、影響や根本原因の理解を深める為
いつ書くか? - ユーザーに影響するダウンタイムやデグレが一定の閾値を超えた時 - 20分以上 - データの損出が発生した時 - 種類を問わず、全てのデータが対象 -
障害解消の為に、エンジニアの介入が必要だった場合 - ロールバック、データパッチ、など - 障害解決までかかった時間が一定の閾値を超えた時 - 1時間以上 - モニタリングの障害 - 自動検知できなかった場合など
どう書くか? - 批判や非難はしない - 特定の個人やチームを糾弾せず、障害に影響する原因を特定する事に集 中 - 障害に関わりの持った全ての人が善意の下に正しい行動を取ったと考える - 建設的に書く
ポストモーテムのレビュー - 書きっぱなしではなく、必ずレビューを実施する - 関係者で定期的にポストモーテムをレビュー
書いたらどうなるか? - 報われなくてはならない - 目に見える報酬(チームレビュー完了と全体共有がコンバージョンポイント) - 賞賛されなくてはならない - 評価に反映される -
ソーシャルな方法で公的に共有される - チーム内だけでなく全体に共有されなくてはならない - N会 - 部会
書いたあとは? - フィードバックをもらう - ふりかえる
ポストモーテムのテンプレート - 作成日 - ポストモーテムを作成した日 - 障害発生期間 - ポストモーテムを記載する原因になった障害が発生した期間 -
作者 - ポストモーテムの記載者 - レビュワー - ポストモーテムのレビューをした人 - ステータス - 現状の障害の状況 - サマリ - 障害についての詳細 - インパクト - 障害が発生したことによる影響 - 根本原因 - 障害の原因となった事柄 - 発生原因 - 障害が発生した直接の要因
ポストモーテムのテンプレート - 対応 - 障害の回復のために行った作業 - 検出 - なぜ障害を発見することができたのか -
うまくいった事 - 障害復旧のために行った対応でうまくいった事 - うまくいかなかった事 - 障害復旧のために行った対応でうまくいかなかった事 - 幸運だった事 - 障害復旧のために行ったことで幸運だったこと - アクションアイテム - 再発防止のために行えること - タイムライン - 障害発生時の作業で行った作業の実施時間と内容 - 参考情報 - 作業の参考にした情報
ではポストモーテムを 見ていきましょう
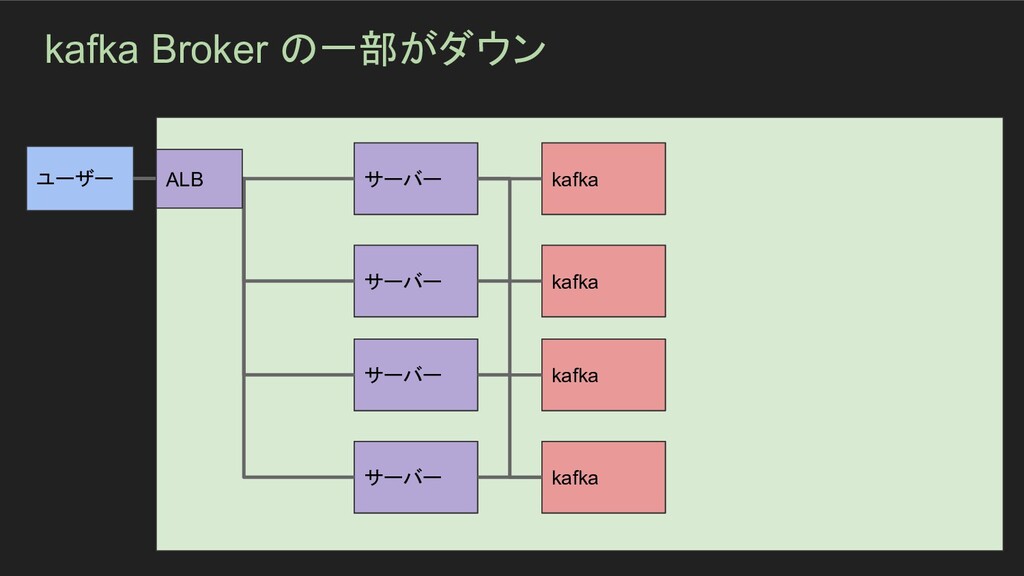
kafka Broker の一部がダウン ユーザー サーバー サーバー サーバー サーバー kafka kafka
kafka kafka ALB
kafka Broker の一部がダウン - 障害発生期間 - 年末の9日間ほど - サマリ -
とあるリアルタイムでの通信を管理するサーバーのバックエンドで使用していた Kafka Broker のうち2台ほどのBroker のノードダウンが発生していた。 冗長化構成を行っていたために動作上の問題は発生していないが、年末年始に問題が 悪化した場合にサービスに影響が出る可能性が出てくるためリバランスの実施を行い対 応 - インパクト - 冗長化構成を行なっていたためユーザーへのインパクトはなし - 根本原因 - 直接的な原因は不明 - 発生原因 - 直接的な原因は時間が経ってしまっていたために不明 AWS内部でのネットワークの一時的な遮断で発生したのではないかと推測
ポストモーテムのテンプレート - 対応 - Kafka Broker のプロセス自体は生きているようであったが、 ZooKeeperに認識されてい なかったため、クラスタから外れていた 2台の再起動を実施
再起動後、リバランスが自動で行われることを確認し、ログを監視して問題ないことを確 認 - 検出 - 年末の休みに入る前にCloudWatchでサーバーの状態を確認していたところ発覚 - うまくいった事 - 冗長化構成を行なっていたのでユーザーへのインパクトは発生しなかった - うまくいかなかった事 - サーバーの状態を丁寧に監視できていたら、もっと早めに検知ができて対応ができた - 幸運だった事 - 年末年始前にダウンしていることに気づけた - アクションアイテム - Grafanaに重要な情報を一覧できるページを作成する
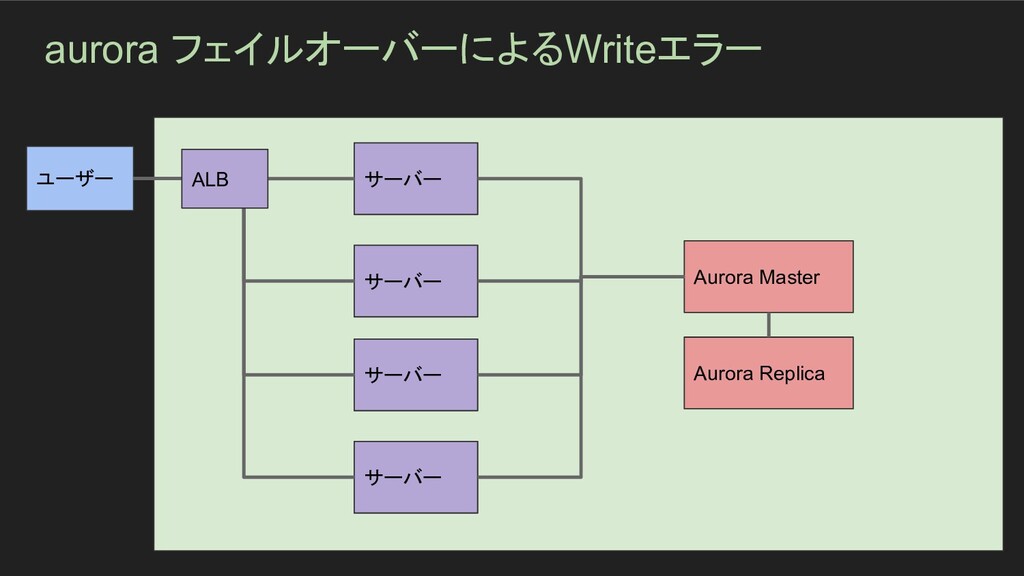
aurora フェイルオーバーによるWriteエラー ユーザー サーバー サーバー サーバー サーバー Aurora Master Aurora
Replica ALB
aurora フェイルオーバーによるWriteエラー - 障害発生期間 - 4時間 - サマリ - auroraのフェイルオーバーによって、Replicaインスタンスが昇格して、Masterになった。
Rails側でDBを参照する際は、クラスタのエンドポイントを利用して通信をかけていたが、 一部のプロセスのActiveRecordのConnectionPoolで、フェイルオーバー時にReplicaに 降格したインスタンスへのコネクションがキャッシュされた状態が続いた。 Unicornの再起動で、キャッシュをクリアして対応した - インパクト - 該当の期間中、一部のunicornプロセスで受け取ったリクエストのうち、 Writeを行うAPIが エラーとなっていた - 根本原因 - RailsのActiveRecordのコネクションプールは、DBのフェイルオーバーが発生した際、接 続先(IP/CNAME)を内部にキャッシュしてしまうケースがある。 この為、Writeをかけるインスタンスへのコネクションはフェイルオーバー後 ReadOnlyに 降格している為、Writeした際にエラーとなってしまう。
aurora フェイルオーバーによるWriteエラー - 発生原因 - Auroraクラスタのフェイルオーバー - 対応 - unicorn
プロセスの再起動 - 検出 - Sentryからのアラート通知 - うまくいった事 - 根本対応のアクションまで特定できた - https://matsukaz.hatenablog.com/entry/2017/07/31/125406 - うまくいかなかった事 - 検知から収束まで時間がかかってしまった - 幸運だった事 - 影響する unicornプロセスが一部であった - アクションアイテム - ActiveRecordにパッチを当てて対応
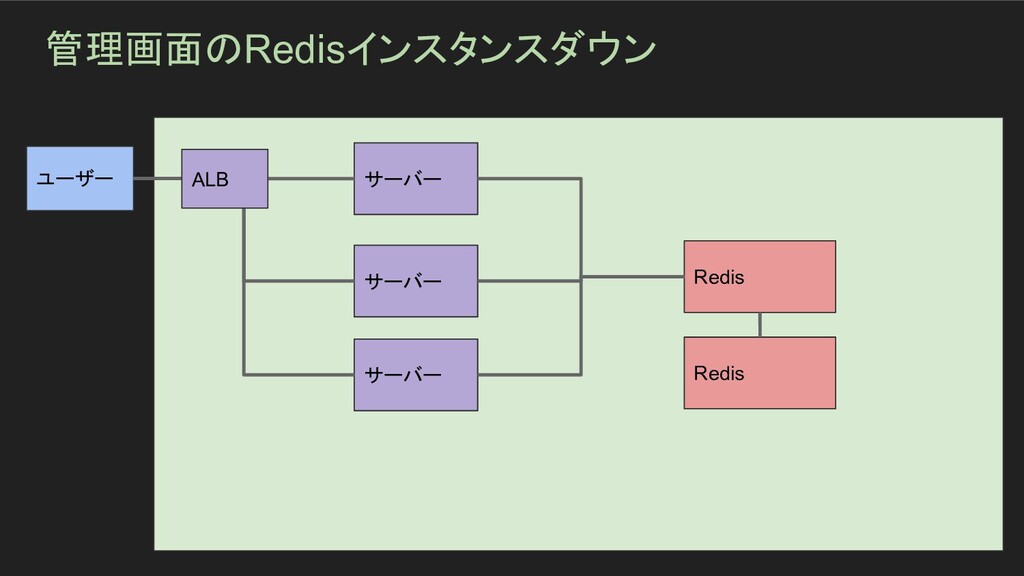
管理画面のRedisインスタンスダウン ユーザー サーバー サーバー サーバー Redis Redis ALB
管理画面のRedisインスタンスダウン - 障害発生期間 - 2時間 - サマリ - デベロッパー用の開発環境の管理画面で利用する Redis
インスタンスが通信不能にな り、デベロッパー用の開発環境の管理画面にアクセスできなくなっていた ElastiCache の Redis クラスタのフェイルオーバーは発火せず、強制的に Replica イン スタンスをフェイルオーバーさせることで対応 - インパクト - 障害期間中、デベロッパー用の開発環境の管理画面が 500エラーとなり、利用できなく なった。 データの欠損等は発生しなかった - 根本原因 - Redis インスタンスの突然死の検知が (現状の監視の仕組みでは)できていなかった - 発生原因 - Redis インスタンスの突然死による、Redisコネクション確率の失敗
管理画面のRedisインスタンスダウン - 対応 - アプリケーションログから、500エラーの原因特定 - Redis クラスタの正常化オペレーション - Redis
クラスタのマルチAZ設定の解除 - Replica インスタンスの昇格 - 新しいReplicaインスタンスの作成 - 検出 - 運用科メンバーからの指摘により発覚 - うまくいった事 - 運用科が使用している人への説明を行ってくれたことにより、開発チームがオペレーショ ンに集中できた - うまくいかなかった事 - SREメンバーで同じ調査やオペレーションを行ってしまい効率が悪かった - Redis クラスタの復旧処理で特定のAZでインスタンスが確保できないspecを利用してい ることを把握できていなかった - 幸運だった事 - デベロッパー用の開発環境の管理画面だったので影響度が比較的少なかった - アクションアイテム - Redis クラスタの特定(primary)のインスタンスが疎通不能になったことの検知
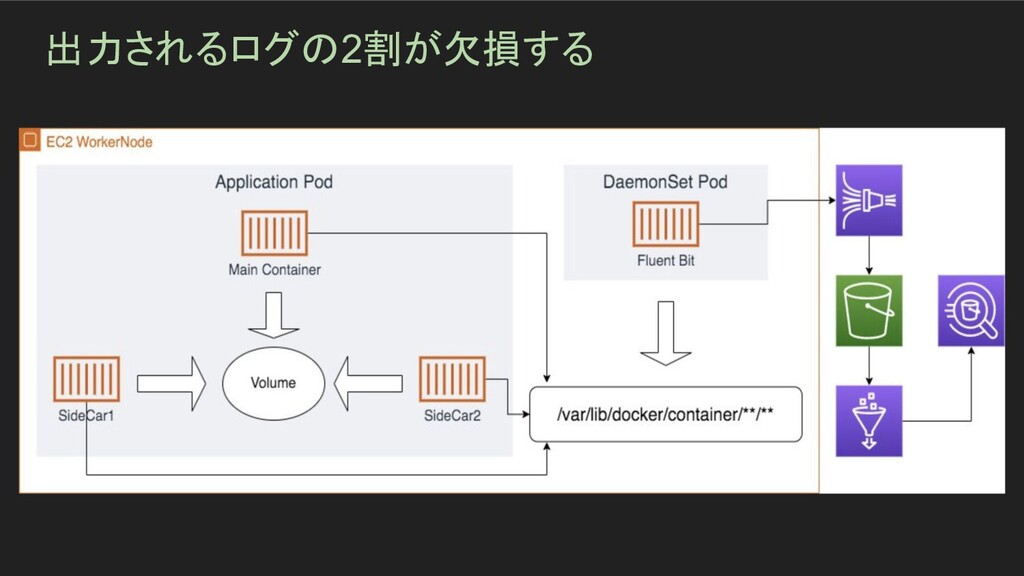
出力されるログの2割が欠損する
出力されるログの2割が欠損する - 障害発生期間 - 一週間ほど - サマリ - ログを2箇所に送信していたが、それぞれのログを比較して片方が約 20%ほど少なくなっ
ている問題が発生 原因としては、ログ情報をS3にアップロードする際にfluentbit の性能試験が実施できて おらず、またログ自体は欠損する可能性がある前提の作りとなっていた - インパクト - 関係者がその欠損しないもので見ていた - 一週間ほどのログ全般の約2割が欠損していた - 根本原因 - ログをS3にアップロードする fluentbit のインフラ性能試験が実施できておらず、どこまで 耐えれるかが把握できていなかった - ログの送信に関しては欠損する可能性がある前提の作りとなっていた - 発生原因 - ユーザー数が増えるタイミングでアクセスが増大したことにより限界性能を超えてしまった
出力されるログの2割が欠損する - 対応 - Mem_Buf_Sizeを増やし、ログ送信時のbufferを増やした - バッファをメモリバッファからファイルバッファに変更することによって再起動時の欠損を回 避 - 検出
- たまたま別部署から過去の欠損調査依頼を受けて調べていたところ発覚 - うまくいった事 - 原因が fluentbit であることの特定までがスムーズにできた - うまくいかなかった事 - 出力しているログのレベルが Error になっていたため、詳細な原因を把握できていなかっ た - fluentbit のメトリクスを確認していなかったため、 fluentbit 自体の問題を検知できなかっ た - 幸運だった事 - ユーザーの処理には影響が出なかった - アクションアイテム - fluentbit により大きな負荷がかかった場合でも安心して過ごせる方法の調査
まとめ - ポストモーテムを記載することによって次のアクションが明確 になってくる - 振り返りをすることで、こんなことがあったなっと学びが残せて いる - 共有していると他のチームもポストモーテムを共有してくれて、 経験してない気づきをもらえる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}