recognition. [S.l.]: Wiley, 1999. (Wiley series in microwave and optical engineering). [2] JAIN, L.; LAZZERINI, B. Knowledge-based intelligent techniques in character recognition. [S.l.]: CRC Press, 1999. (The CRC Press international series on computational intelligence). [3] PARKER, J. R. Algorithms for image processing and computer vision. [S.l.]: Wiley Computing, 2010. 504 p. [4] CHERIET, M.; KHARMA, N.; LIU, C. Character recognition systems: a guide for students and practitioners. [S.l.]: Wiley-Interscience, 2007. [5] BUNKE, H.; WANG, P. Handbook of character recognition and document image analysis. [S.l.]: World Scientific, 1997. [6] DAVIES, E. Computer and Machine Vision: Theory, algorithms, practicalities. [S.l.]: Elsevier Science, 2012. [7] TRIER Øivind D.; JAIN, A. K.; TAXT, T. Feature extraction methods for character recognition - a survey. Pattern Recognition, v. 29, n. 4, p. 641 – 662, 1996. ISSN 0031-3203. [8] BIGUN, J. Vision with direction: a systematic introduction to image processing and computer vision. [S.l.]: Springer, 2006.
{kind=link}
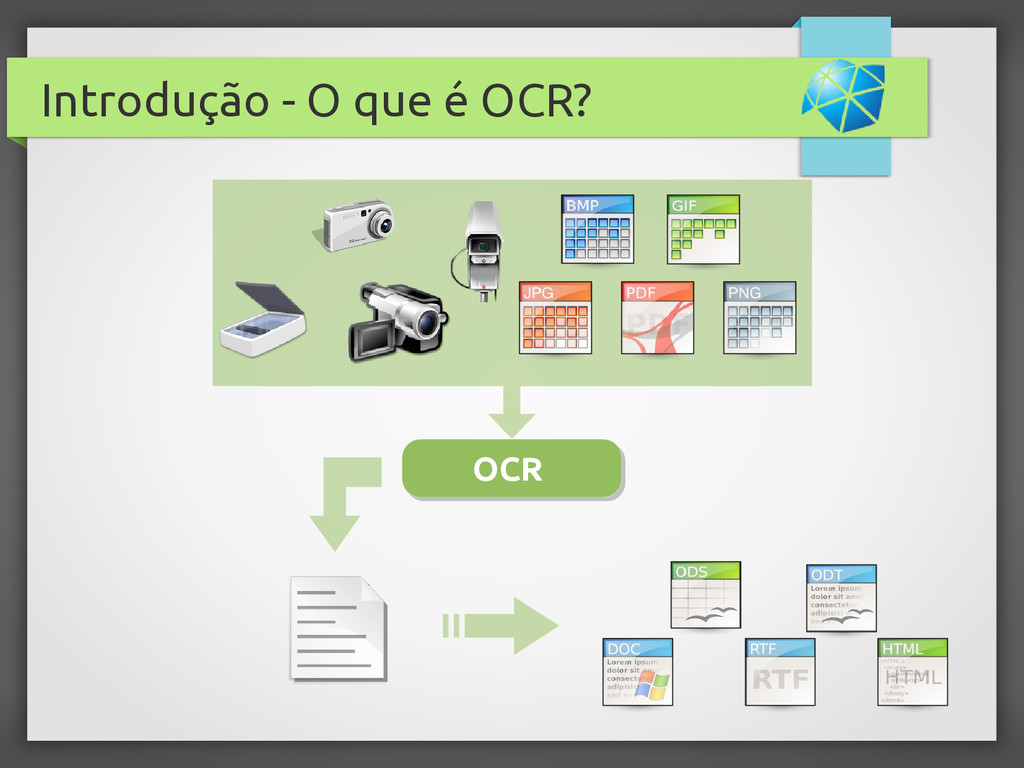
{kind=link}
{kind=link}
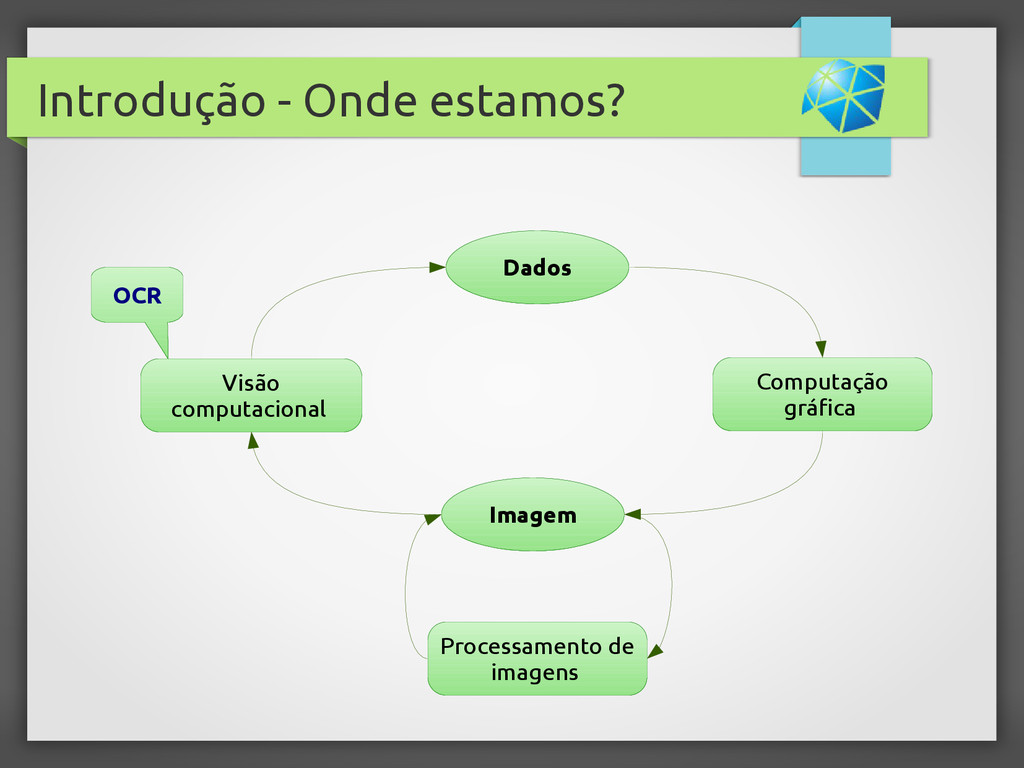
{kind=link}
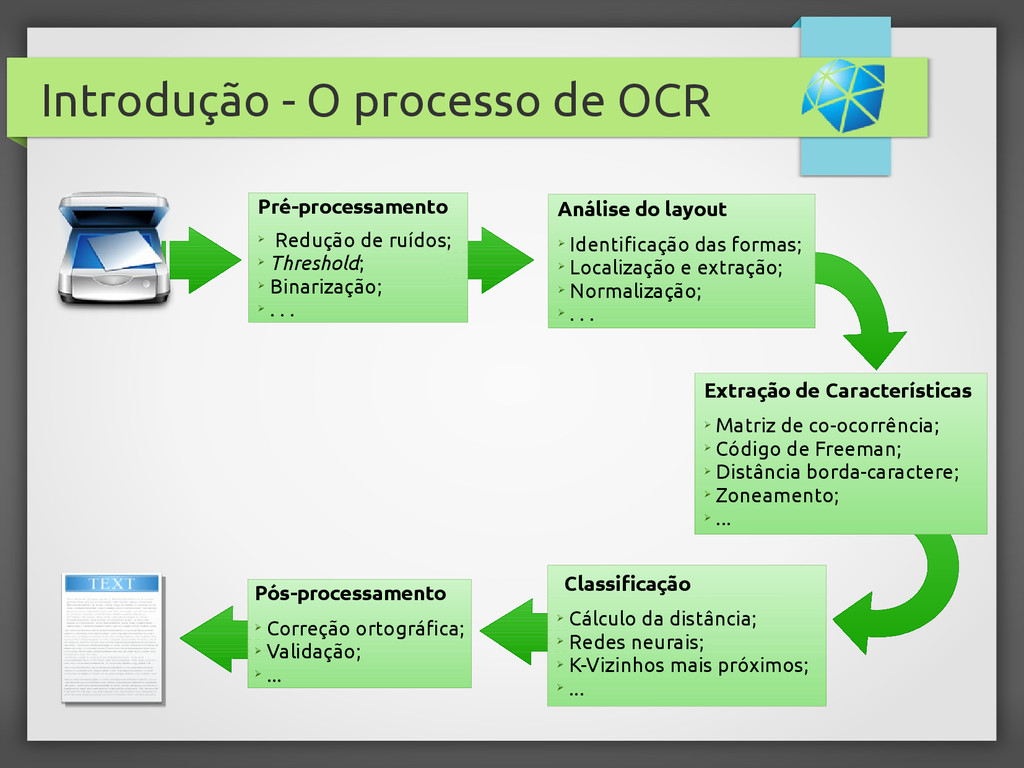
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fundamentação Teórica Uniformidade (Energia): Medida de Uniformidade entre [0, 1].](https://files.speakerdeck.com/presentations/80ee34a845ba46718ceb93019ea600b2/slide_19.jpg){kind=link}
{kind=link}
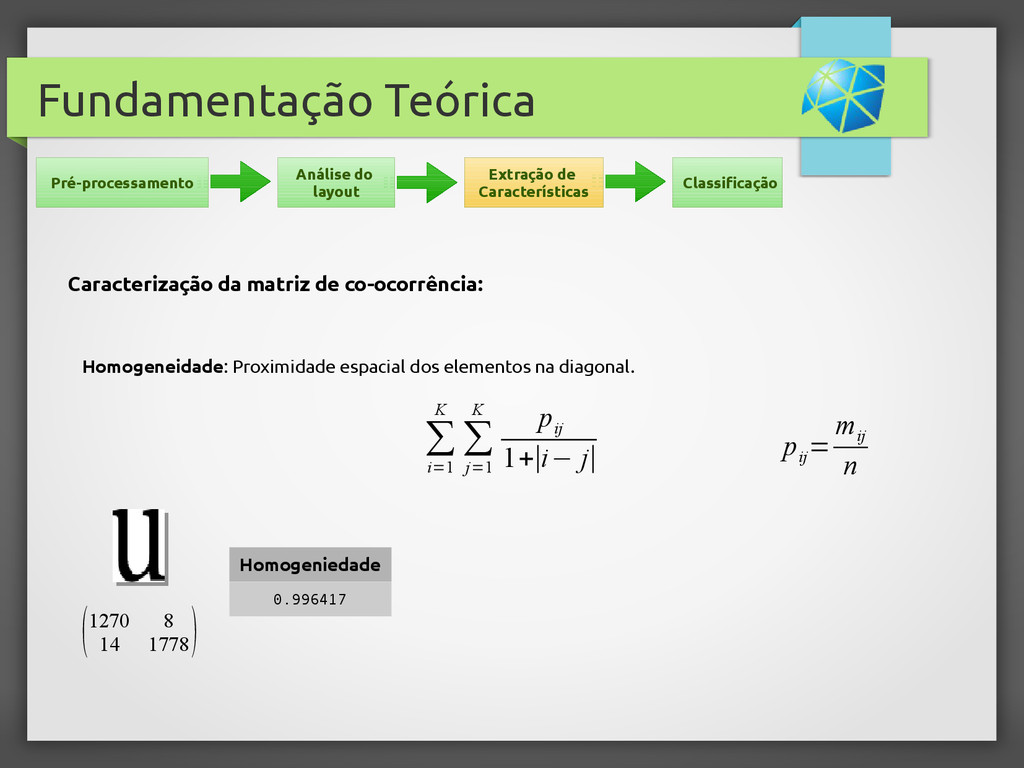{kind=link}
{kind=link}
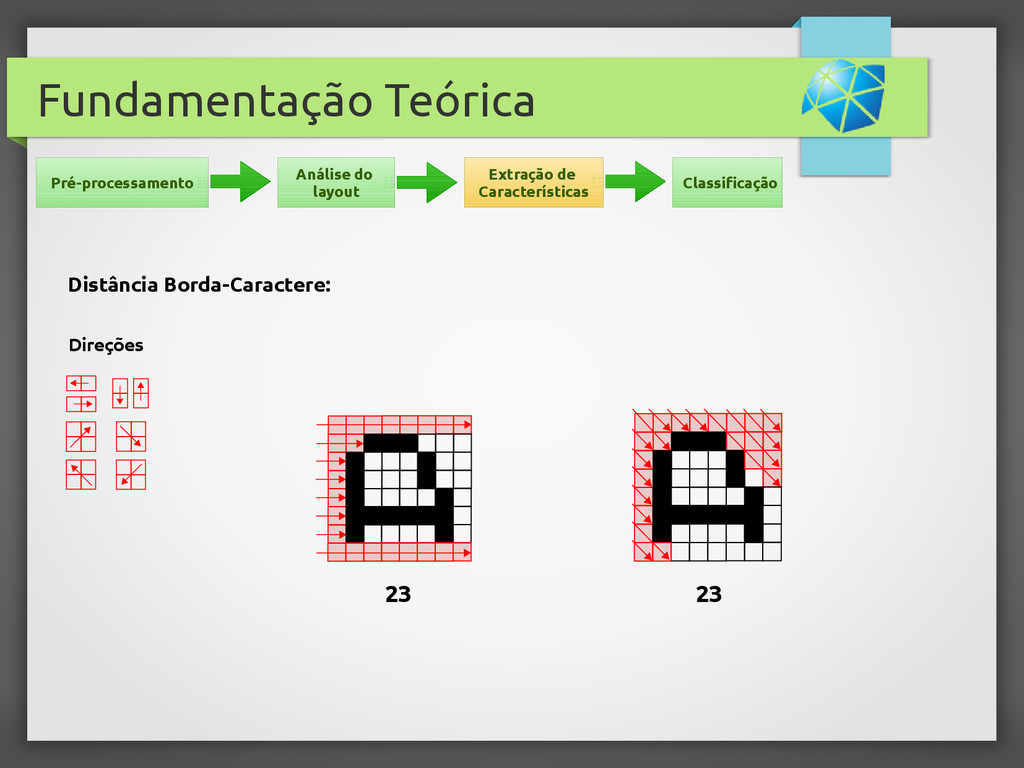{kind=link}
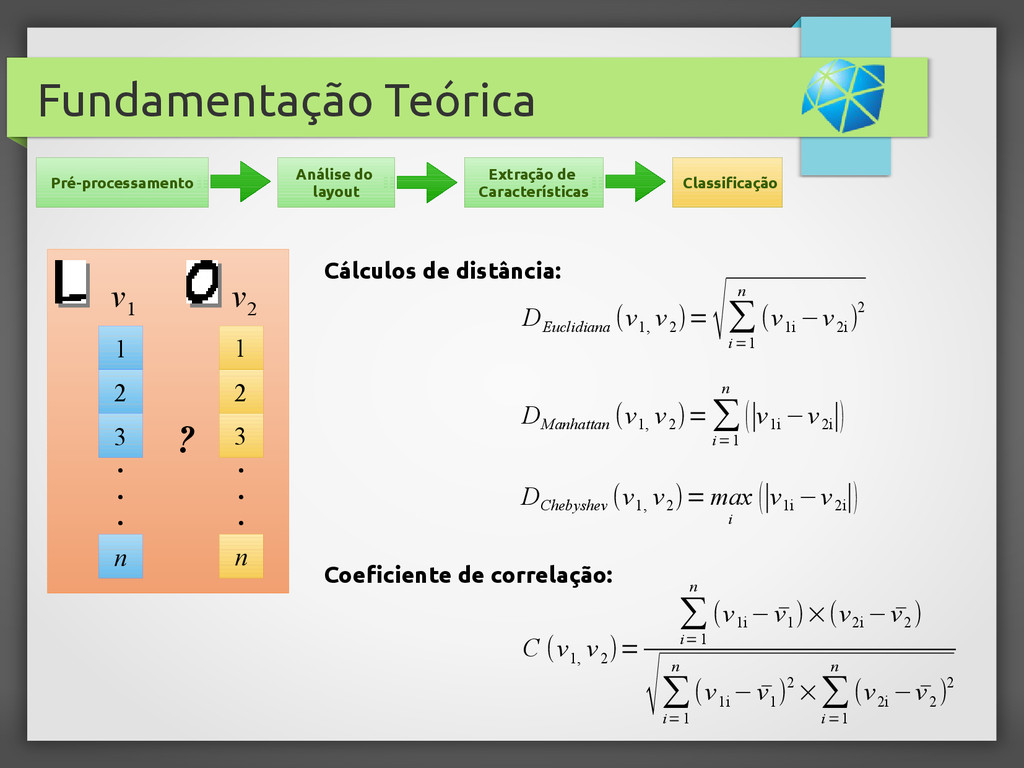{kind=link}
{kind=link}
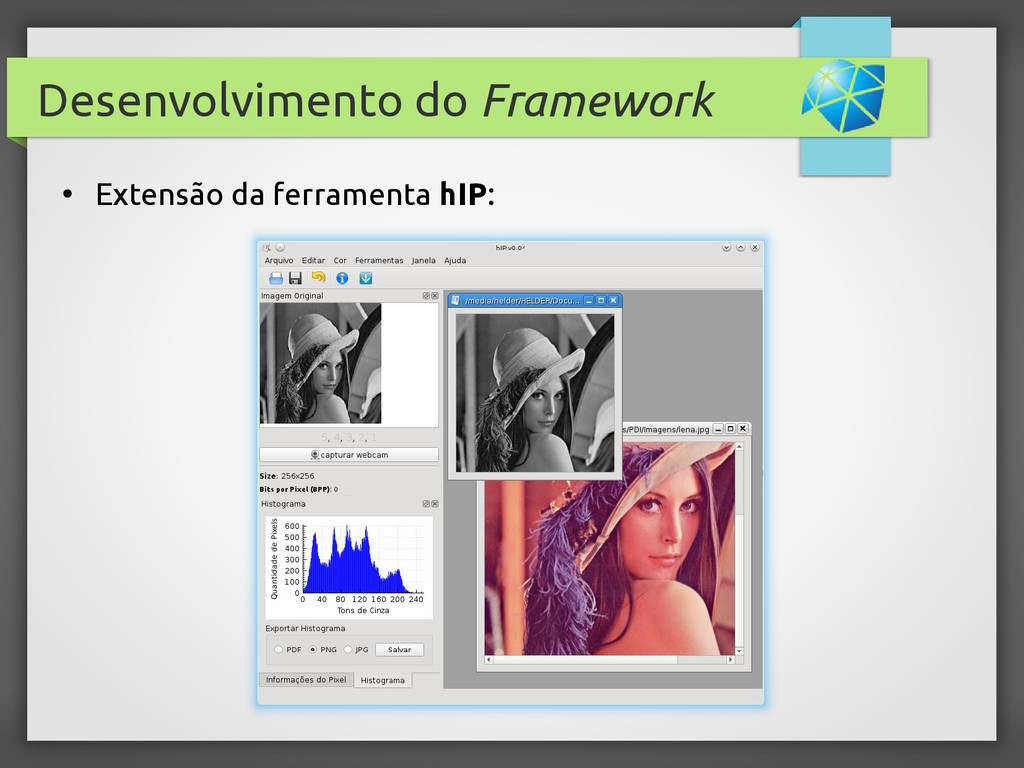{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Referências [1] MORI, S.; NISHIDA, H.; YAMADA, H. Optical character](https://files.speakerdeck.com/presentations/80ee34a845ba46718ceb93019ea600b2/slide_31.jpg){kind=link}
![Referências [9] UCHIDA, S. et al. Character image patterns as](https://files.speakerdeck.com/presentations/80ee34a845ba46718ceb93019ea600b2/slide_32.jpg){kind=link}
{kind=link}