In these slides I talk briefly about how we build a secondary education platform at Studyflow, using Clojure / ClojureScript and Event Sourcing and CQRS
• We provide two courses (Rekenen and Taal) • We serve over 100 schools, 50 000+ students, who answered correctly more than 10 million questions. 4 / 25
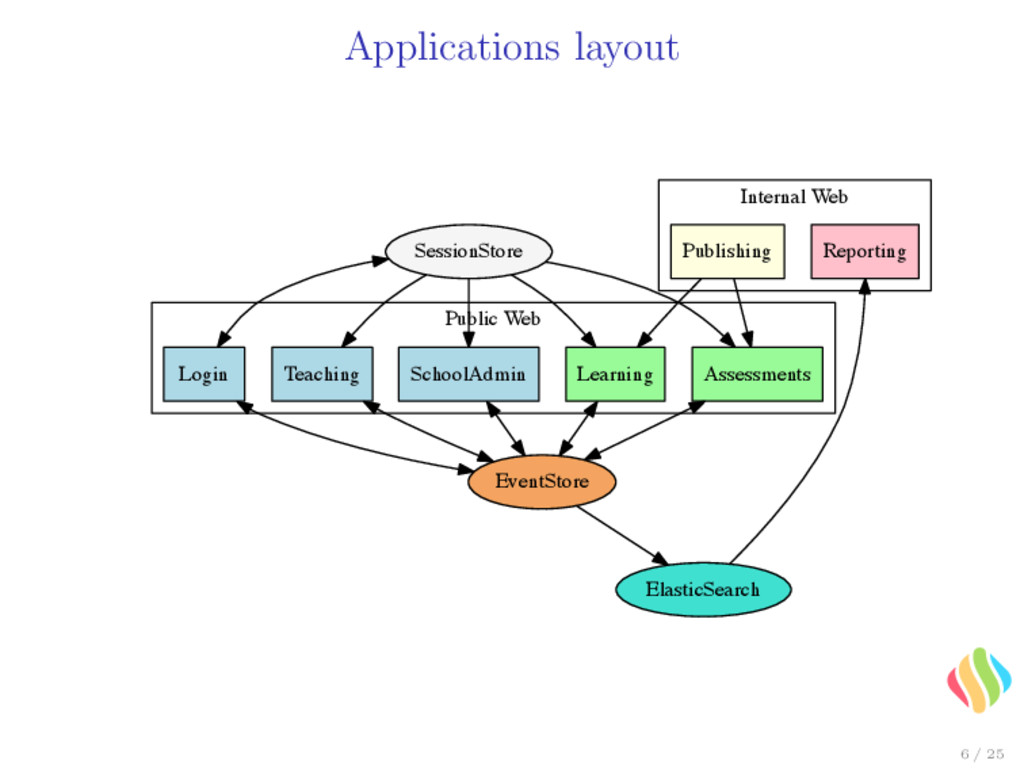
2 stacks (to provide rolling updates) • 1 VM for publishing app (internal and only 2-3 users at the same time) • 1 VM per each Clojure application per stack • 1 VM for the Event Store Performance is great, we just take a bit of memory... 7 / 25
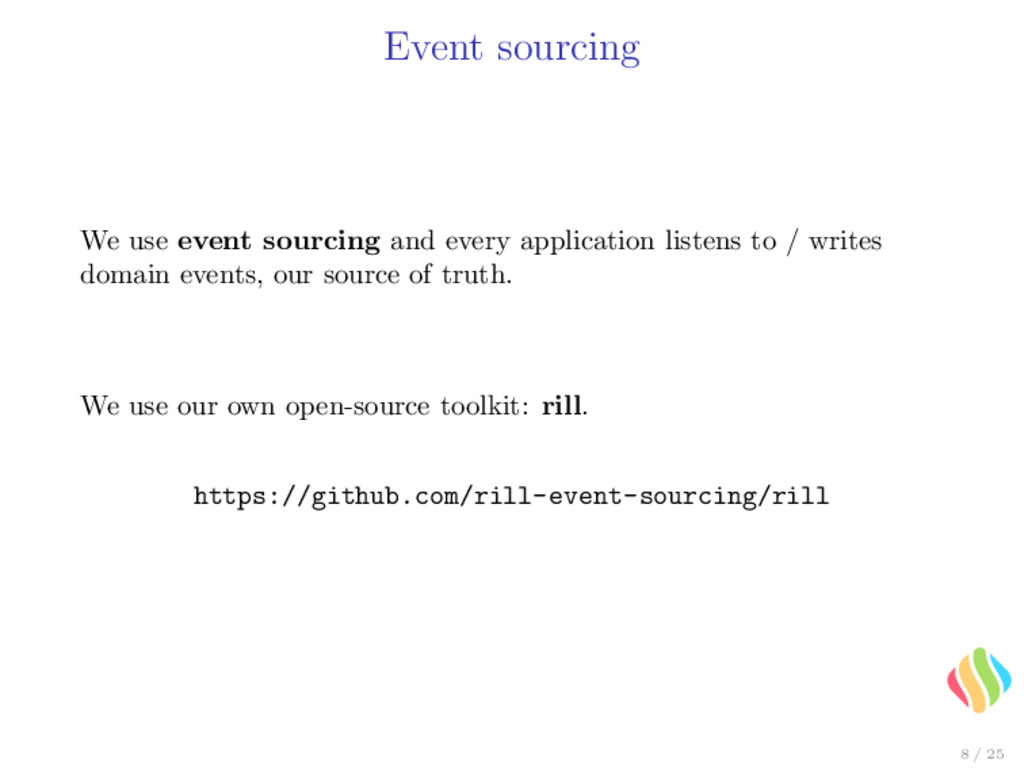
• has a meaning in the domain; • encodes the intent of change; • immutable. • Event store is an append-only system. • The application state is simply reconstructed from these events, in chronological order. 9 / 25
"2015-02-11T11:46:55.014-00:00", :rill.message/id #uuid "276de24f-d7df-478c-a82a-fd97c24a7232", :answer "My Answer", :question-id 442, :user-id 23} • Right now, we have more than 55 million events • ∼ 11M new events per month 10 / 25
answer questions like: • Which questions are difficult? • How different are quick learners vs slow ones? • What kind of mistake is the most common for a particular question? • Do the students that read again the explanation (theory) immediately after answering incorrectly get it right? • Some stuff that we don’t know yet! 11 / 25
side Read side • Read side and write side of the applications have different needs (CQRS) • Each application read-model is generated / updated asynchronously from the published events 12 / 25
listens for events about credentials, updating the current state of the application, a “credentials database”. • It is just a (continuous) reduction on the list of events, applying one at a time. 13 / 25
their sha. • Upon commit, if all tests pass, we build automatically the jar of each application and store it S3 with format $application-$sha.jar 1 Each server gets the appropriate sha version from S3 and it starts it up 2 All the applications catch up with previous events building the read-model 3 Every application listens for new events and updates the read-model accordingly 15 / 25
Very straightfoward to implement but non-durable. • What happens if the server suddenly malfunctions and reboots? • What happens on deploy? Building the read-model is fast with a small number of events, but at 50M it takes a lot (in our teaching application, ∼ 4 hours). 16 / 25
Changes to frontend code • Changes to graphical design • Simple restart of the machine do not require a different read-model. Saving the read-model to disk and loading it on startup seems a good strategy. 17 / 25
1 Good separation of code that writes to read-model 2 Computation a shasum of the files related to such code to generate a read-model version 3 In-memory map gets periodically serialized and saved to disk, also with the index i of the last-seen event. 4 If the sha is the same, the read-model must be the same, therefore we can load it from disk upon application start. 18 / 25
just a shortcut for applying the events 0, . . . , i. • From i + 1 onwards the events have to be handled normally. • Luckily, these are very few (generated during downtime or re-deploy). This brings the deploy time of new versions of the application without changes to the read-model down to 5 minutes (mostly other stuff not related to read-model) 19 / 25
events has changed? 1 Write a migration 2 Rebuild the entire read-model Migrations are annoying and we still need to build a version of the read-model anyway, so we chose 2. 20 / 25
between a commit and the time we decide to put it live: • Code review • Tests (automated and manual, on a variety of devices) • Decision It seems useful to use this time to build the read-model. 21 / 25
and build read-models up front. • A dedicated build server, with a single jar with all the applications combined (similar to our development environment), plugged to the production event store • Compression and upload of the read-model to S3 • Upon deploy, get the appropriate read-model from S3. Having a centralized place for read-models on S3 is very convenient. 22 / 25
bug in the read-model? The updated version cannot be live before a few hours. Depending on the nature of the change, we can still 1 download the read-model in our development machine 2 Run a manual migration 3 Save it and upload it to the appropriate place on S3. Upon deploy, there’s virtually no difference from an automatic build. 23 / 25
way to bring down the deployment time. • Splitting of applications (and their read-models) in smaller pieces (code-wise): reduces the likelihood that a change impacts the read-model version. • Sharding of event stores. Due to our natural domain, we could have one separate database per region, province, city or even each school. The number of events to be read is then small enough that the construction of the read-model is done at most in a few minutes. 24 / 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Info and contact Rill https://github.com/rill-event-sourcing/rill Previous talk http://joost.zeekat.nl/wp-content/es-at-sf.pdf Studyflow [email protected]](https://files.speakerdeck.com/presentations/cccb21dd7d66408e8d91a079dadc68c4/slide_24.jpg){kind=link}