we’re “getting rid of it”) • Clojure/ClojureScript stack (both SPA with reagent and request/response) • Use custom event sourcing library: rill • PostgreSQL for our EventStore • Analytics with ElasticSearch and Kibana
in our domain. Such events are: • meaningful within the domain • result of an explicit interaction • immutable Event sourcing Because of these properties, we consider them our only source of truth
important in our domain, maybe even more so than the final state (the journey vs the destination). Example: Recording info about questions answered incorrectly might be more important than just knowing that a student successfully completed a chapter. • Events are immutable, so our system is “append only”, making reasoning easier • Events as source of truth are very useful when investigating with Kibana: we can tell exactly what has happened
are quick learners from slow ones? • What kind of mistake is the most common for a particular question? • Is reading an explanation (theory) after a mistake useful? But, more importantly • A lot of things that we don’t know yet! From our business perspective, events can help us answer interesting questions
event 6 ….. event 331.999.997 event 331.999.998 event 331.999.999 event 332.000.000 Our event-store • A big log where all events are together, one after the other • We use PostgreSQL and we make use of a few additional columns stream-id Id of the aggregate the event refers to stream-order Local order within a stream insert-order Global order within all events
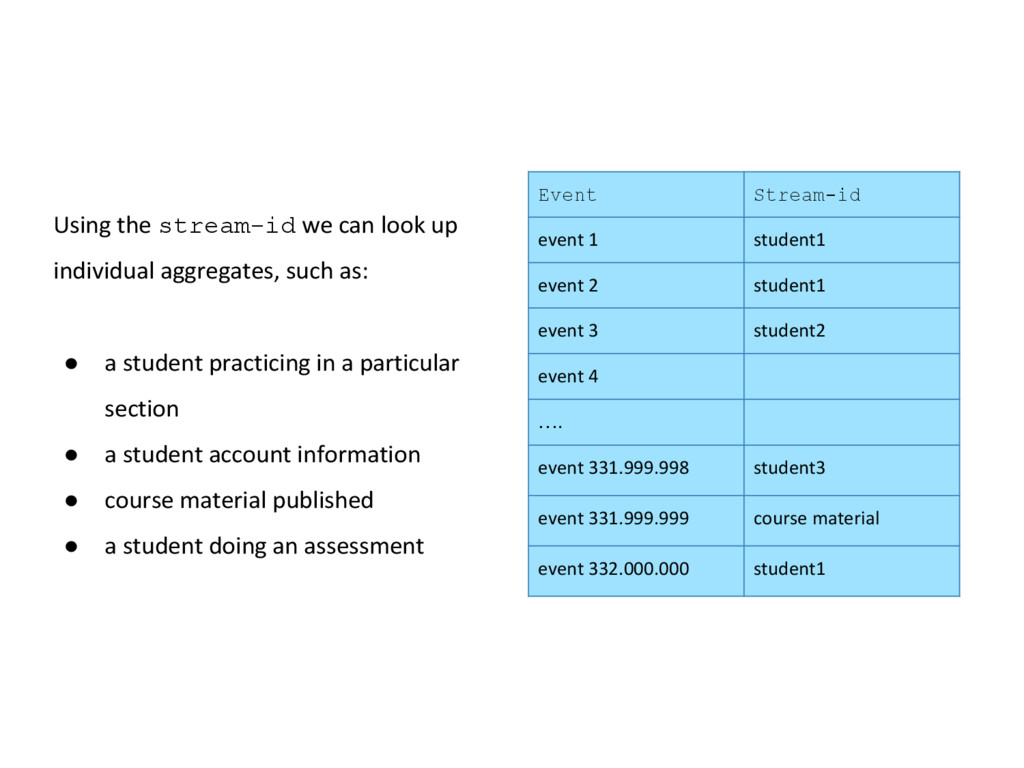
student2 event 4 …. event 331.999.998 student3 event 331.999.999 course material event 332.000.000 student1 Using the stream-id we can look up individual aggregates, such as: • a student practicing in a particular section • a student account information • course material published • a student doing an assessment
global view of everything 2. Selectively for one aggregate, to create a materialized view of it These events can then be “replayed” in 2 ways event 1 student 1 event 2 student 1 event 3 student 2 event 4 …. event 331.999.998 student 3 event 331.999.999 course material event 332.000.000 student 1 Why do we need these two ways?
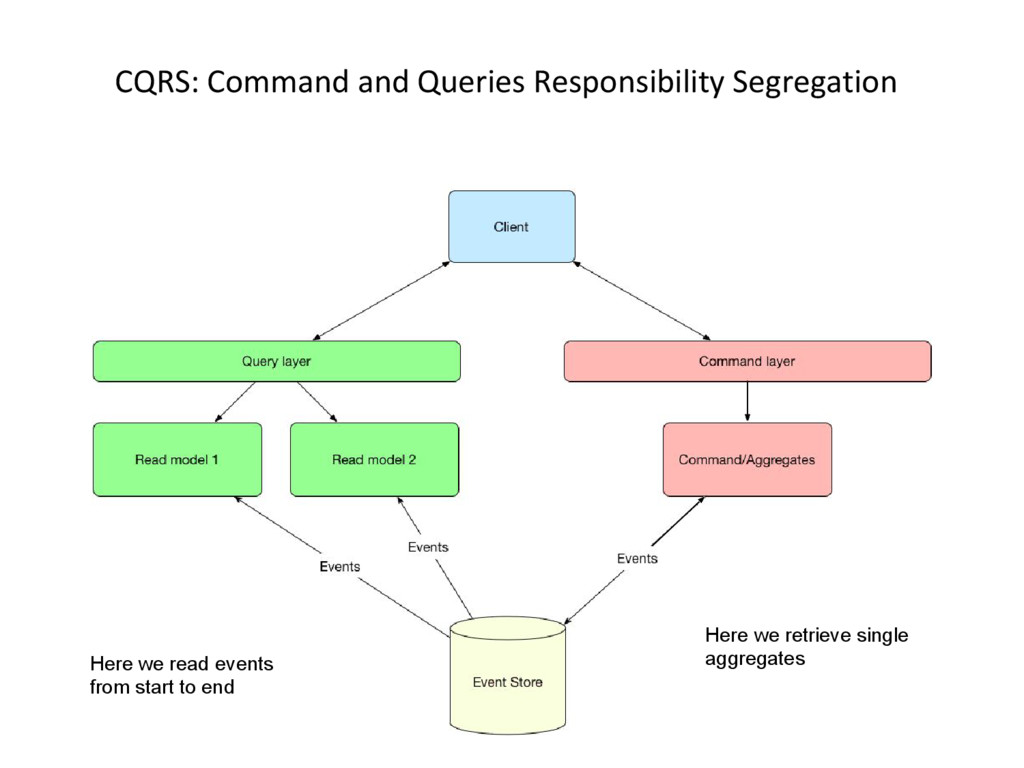
side (commands) and read sides have different needs • They can be scaled independently • Read side is asynchronously updated • Write side is synchronously updated when a command about that specific aggregate is fired
probably would look like if we did things traditionally. Just a big in-memory clojure map: • Memory is cheap (at least with bare metal) • Memory is fast We store in the read-model all the information that we need to display to the user, e.g. all the dashboarding.
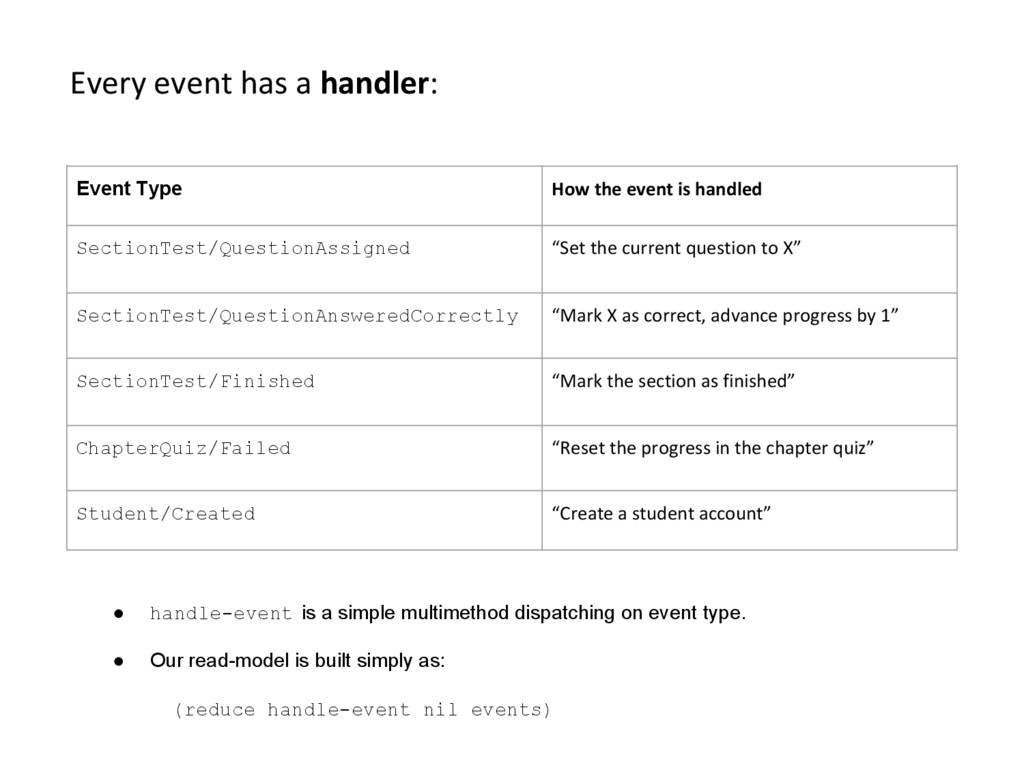
is handled SectionTest/QuestionAssigned “Set the current question to X” SectionTest/QuestionAnsweredCorrectly “Mark X as correct, advance progress by 1” SectionTest/Finished “Mark the section as finished” ChapterQuiz/Failed “Reset the progress in the chapter quiz” Student/Created “Create a student account” • handle-event is a simple multimethod dispatching on event type. • Our read-model is built simply as: (reduce handle-event nil events)
current question to X and track activity” SectionTest/QuestionAnsweredCorrectly “Mark X as correct, advance progress by 1, track activity” SectionTest/Finished “Mark the section as finished and track activity” ChapterQuiz/Failed “Reset the progress in the chapter quiz and track activity” Student/Created “Create a student account” Let’s assume we want to build a page which shows how much time the students spend practicing. We can change the event handlers:
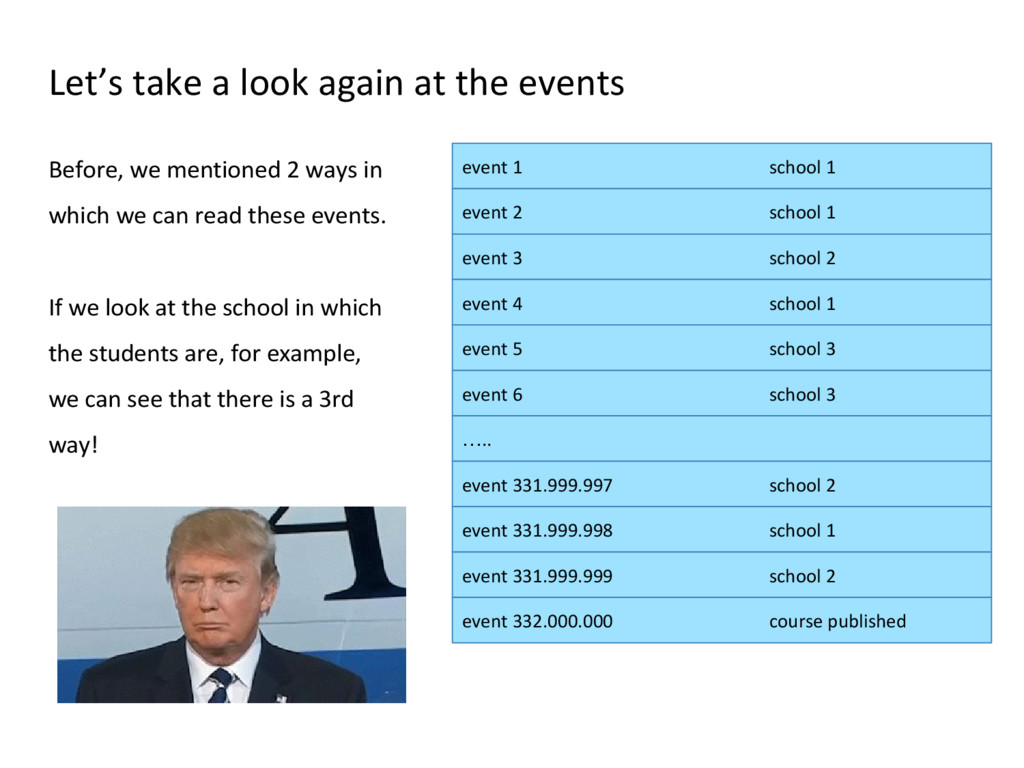
school 1 event 2 school 1 event 3 school 2 event 4 school 1 event 5 school 3 event 6 school 3 ….. event 331.999.997 school 2 event 331.999.998 school 1 event 331.999.999 school 2 event 332.000.000 course published Before, we mentioned 2 ways in which we can read these events. If we look at the school in which the students are, for example, we can see that there is a 3rd way!
school 2 event 4 school 1 event 5 school 3 event 6 school 3 event 7 school 2 Why don’t we separate the schools? • all the publishing stuff in the same place • all the administrative stuff (internal) in the same place • etc.
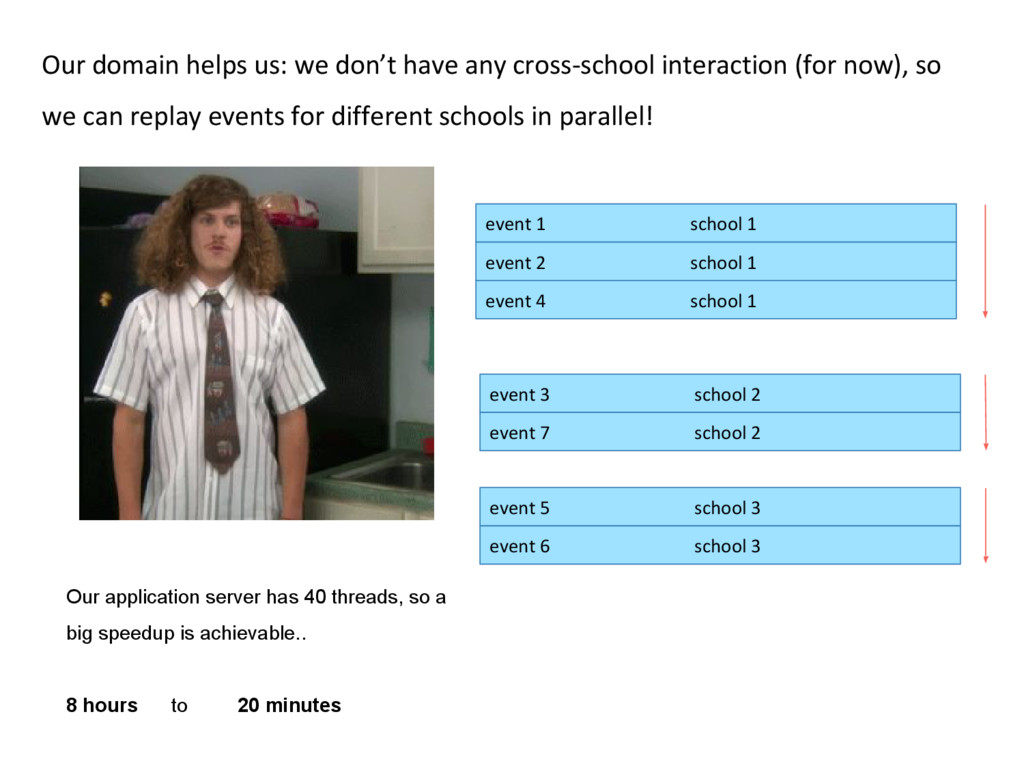
school 2 event 4 school 1 event 5 school 3 event 6 school 3 event 7 school 2 Our domain helps us: we don’t have any cross-school interaction (for now), so we can replay events for different schools in parallel! Our application server has 40 threads, so a big speedup is achievable.. 8 hours to 20 minutes
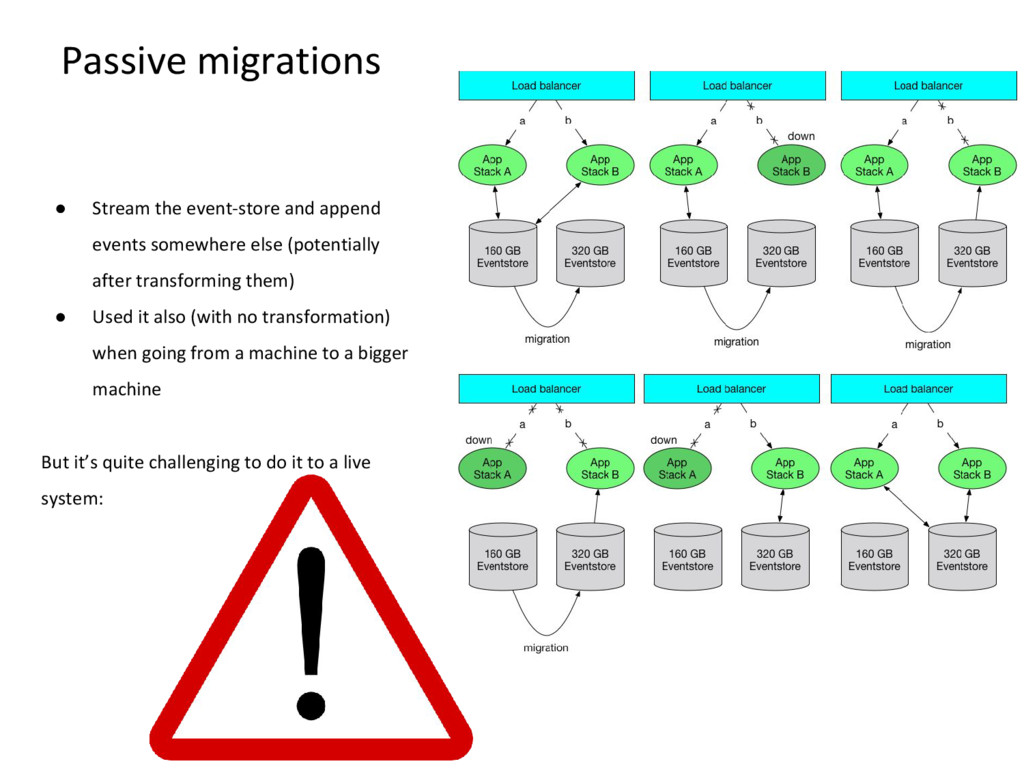
migrations Event sourcing says that events are immutable. Reality does not necessarily agree, so we sometimes cheat a bit. Spoiler alert: there is a reason why they tell you not to do it
retrieve events with some middleware 1 event goes in, 1 event goes out Example: UserAgreement/Accepted was fine when implemented. One year after, we revised the agreement and people needed to accept it again. We added to the event a revision field. Where do we put the logic that no revision field is actually revision 1? • Add another event type (and keep track of both old and new events) • Handler for the event (everywhere we handle that event) • In an active migration: (mostly)
else (potentially after transforming them) • Used it also (with no transformation) when going from a machine to a bigger machine But it’s quite challenging to do it to a live system:
in your repo) you can’t really go back from a passive migration. This has caused us a couple of headaches, just recently Protip: Have a bunch of consistency checks you can run before you do a definite switch
school 2 event 4 school 1 event 5 school 3 event 6 school 3 event 7 school 2 Even if the event-store is partitioned, we are still appending events 1 by 1, as of now event 8 school 1 event 9 school 2 event 10 school 1
matter how good is our infrastructure, appending events 1-by-1 does not scale • Current capacity is around 800 events/second • The more schools we have, the more users active at the same time, the more events we need to append every second, and so on...
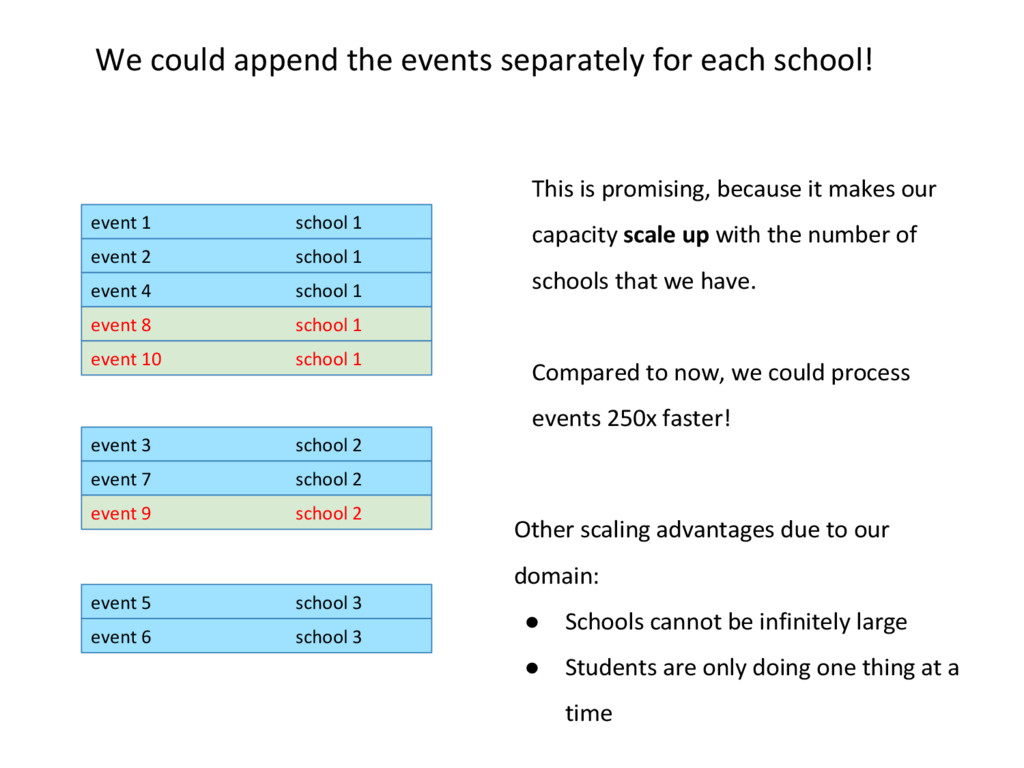
1 school 1 event 2 school 1 event 3 school 2 event 4 school 1 event 5 school 3 event 6 school 3 event 7 school 2 This is promising, because it makes our capacity scale up with the number of schools that we have. Compared to now, we could process events 250x faster! event 8 school 1 event 9 school 2 event 10 school 1 Other scaling advantages due to our domain: • Schools cannot be infinitely large • Students are only doing one thing at a time
partitions • Potentially hard / impossible to do stuff across schools, at least how we would do it now • One transactor per partition can complicate it a bit Drawbacks
of information from events, even retroactively Along with benefits, event sourcing also brings challenges (scaling reading and writing of events) We are partitioning the events by school, in order to do parallel read / writes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}