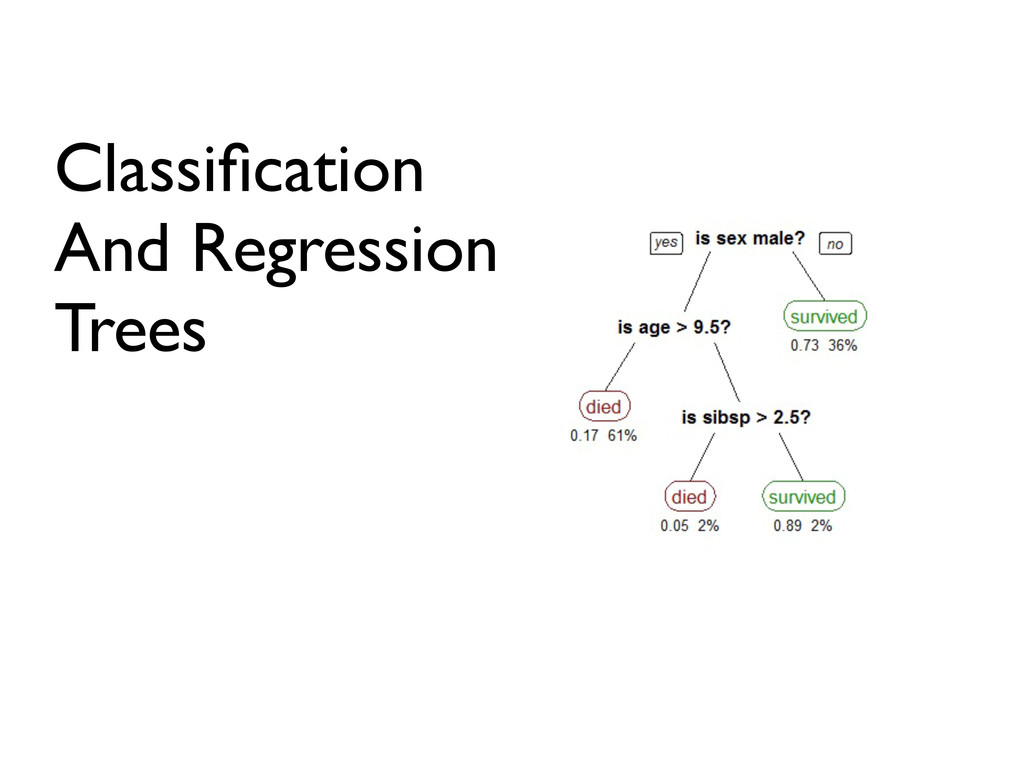
the data in groups and subgroups • Make multiple trees this way • Use rest of data (not subset) to determine best classification • Tree with most predictive power wins
permuted_snp_errors = sum of missed classifications inside of tree by each variable • oob_size (out of bag size) means all the data points not used • generalization_error = sum of errors for entire forest
a training." "Really? On the way home will you do a driving?" • Sophthewiseone: TIL: Hitler was a micromanager. "Hitler was constantly interfering in the decisions of his subordinates." Explains a lot...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
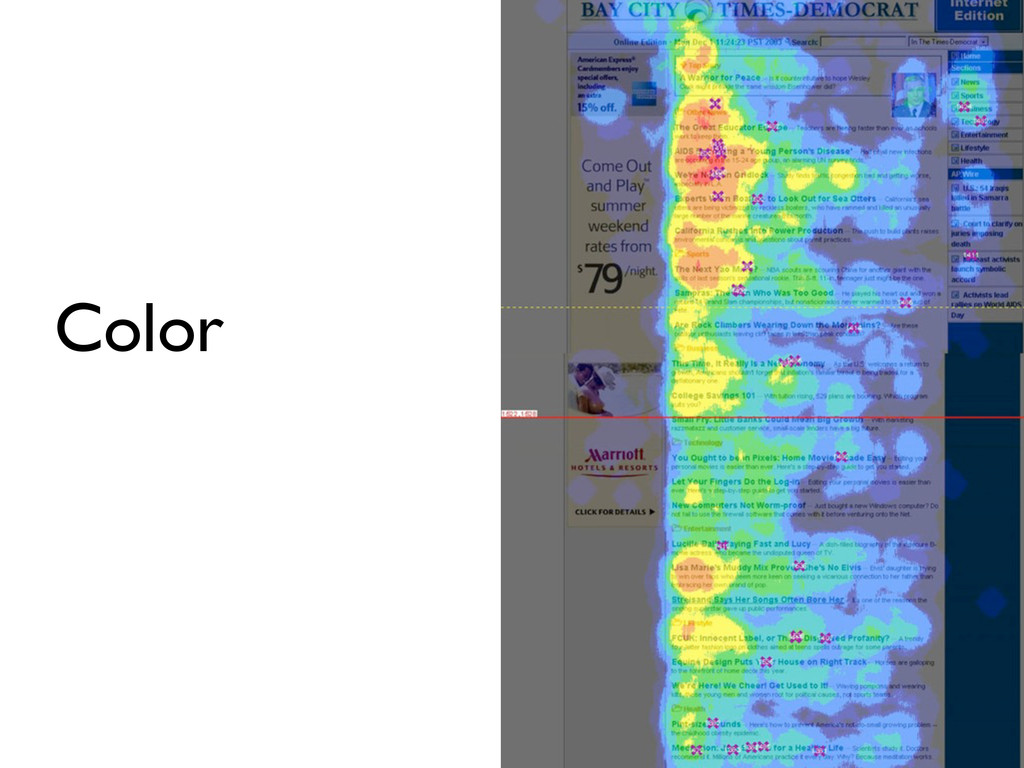{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}