Data Volumes ranging from 100GB’s to PB’s Traditional RDBMS’s struggle to allow you effectively retrieve key information Varies depending on the Application / Company
volumes of data and aid in distributed processing Different types of NoSQL. Document, Graph, Column-Store Schema-less (to a degree) Loss of JOINS, loss of certain aggregation features common to RDBMS’s
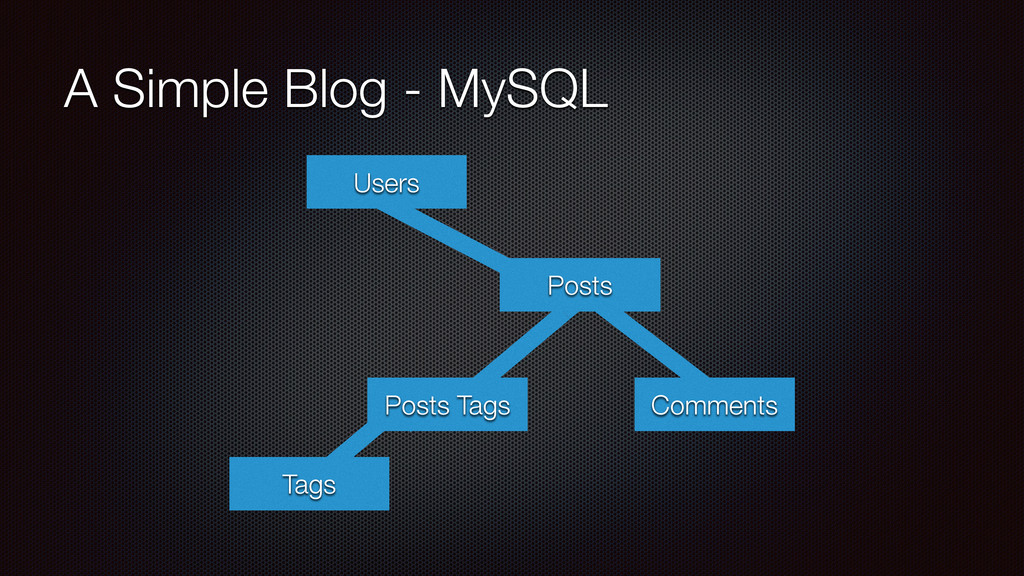
server running MSSQL storing almost 2TB of data 8GB RAM and 4 cores. (pathetic) Queries could take anywhere between 15 and 45 minutes 2 tables with 700 million and 300 million rows in (500GB and 300GB per table respectively) Other tables with 10s of millions of rows Lots of other tables! Some with 100s of columns
this much data from the get go but can handle an exponential increase Is a RDBMs really the right solution for this? How much time am I going to have spend ops-side?
Sharding <- Key Point Bound by Schemas and linear tables It has replication but how about transparent auto failover? Maintaining it could potentially be a full time job straight away… I need to be writing code though?
No. Need for other systems to allow for real time access and queries What about the learning curve? ! Potentially good for some aspects of our longer term goals though!
Store optimisations? What’s the learning curve like? Interop options with different technology stacks (PHP, C# specifically) Documentation and community support TTL? Hm….
aggregated queries to other tables = No extra query overhead Less overhead mapping the data layer to application layer - it’s already formed. Less time spent making the database because your application layer can be your schema.
of data With lots of daily data, aggregated into buckets. One query could retrieve lots of data with minimal overhead. Indexes on these sub-document objects 16MB document limit. Our biggest has 7000 objects inside which is ~4MB But you can effectively select which objects to return to make it even faster
hour These updates were effectively small chunks of data that needed to be associated with a day Push the small chunk to the bucket for the relevant day ! Documents began to grow at an alarming rate. Fault… Fault.Fault.FaFaFault
Prototype API mapped URL parameters to queries JSON API literally fell out of our computers in hours Getting to these data buckets was easy and our front end could consume and graph out the data with ease. Allowed to focus on processing and scaling
data and didn’t require babysitting constantly We needed to be able to get off the ground quickly and get to our data as fast as we were putting data in We needed to be able to adapt to an extremely volatile industry our metrics are based on We needed scaling and redundancy options One person needed to do all this in a matter of months.
Ensuring the indexes and collections are better suited to our data access patterns Dealing with page faults Mitigated by using SSDs Growing documents can actually have a negative impact on space efficiency
technologies Use them effectively by looking at how to structure your data to best suite your access and processing patterns. Schema’s are important still #sigh Knowing the technology you’re using at a core level is VERY useful for performance enhancements There’s more than one way to skin a cat
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}