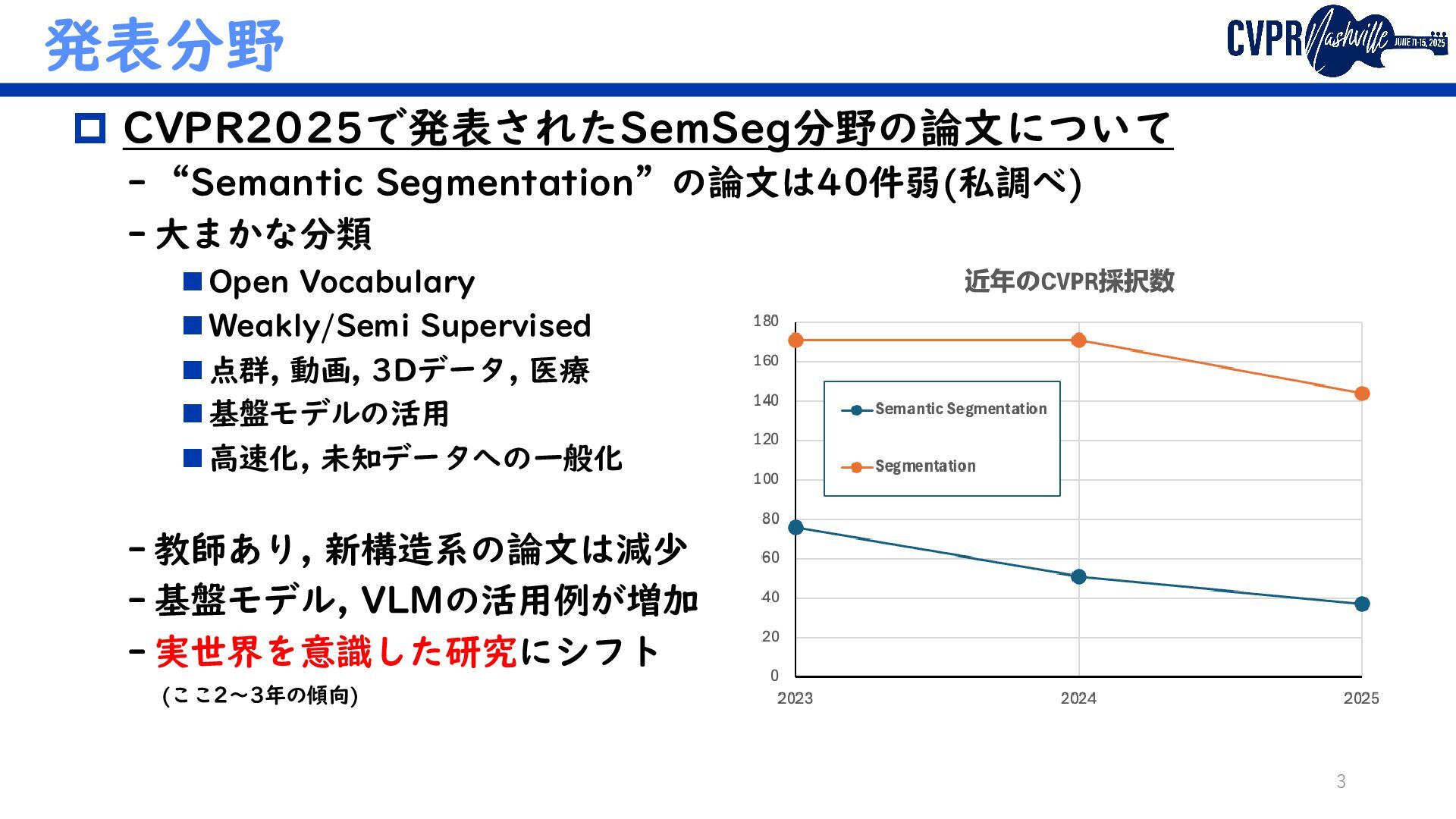
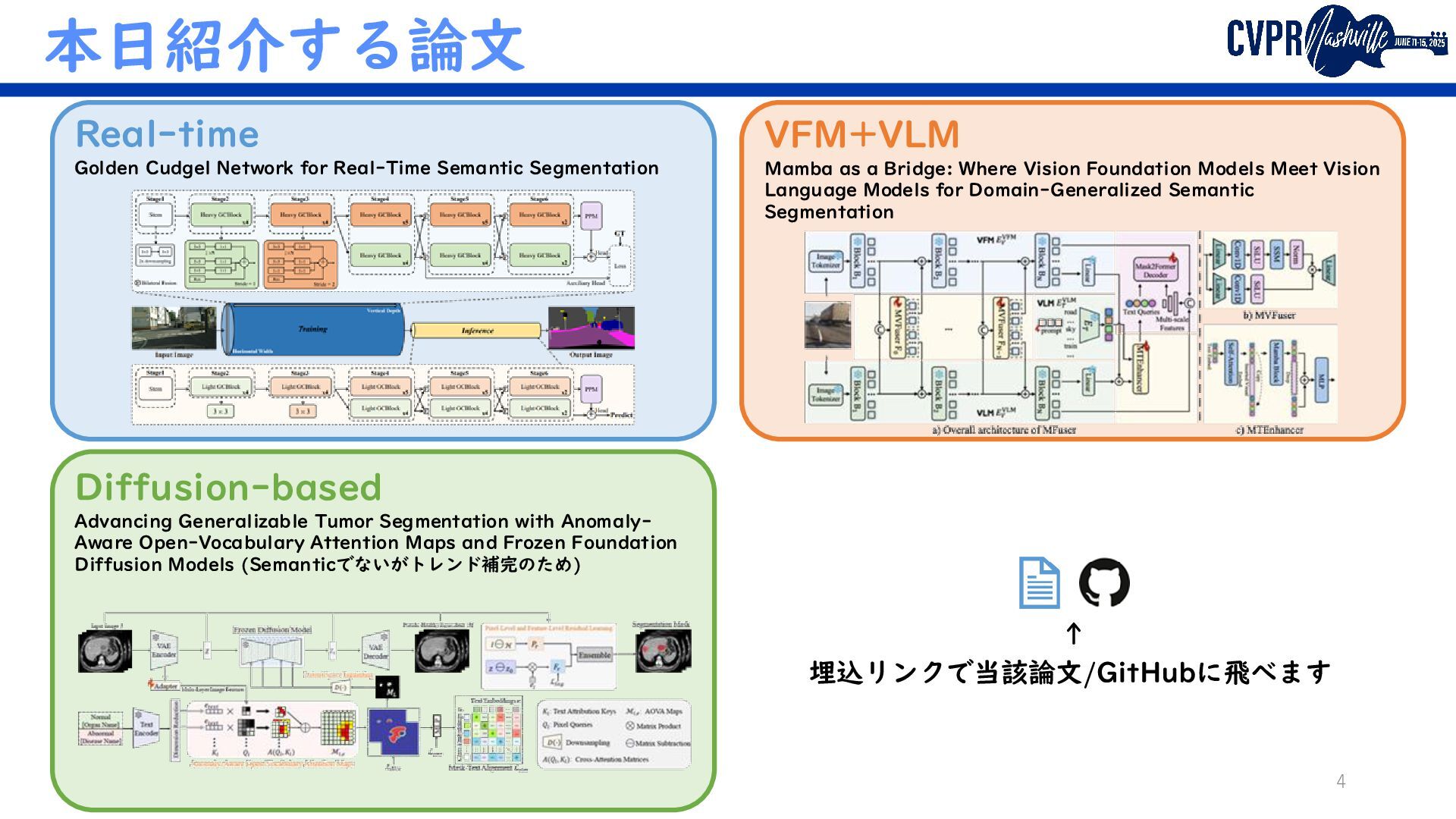
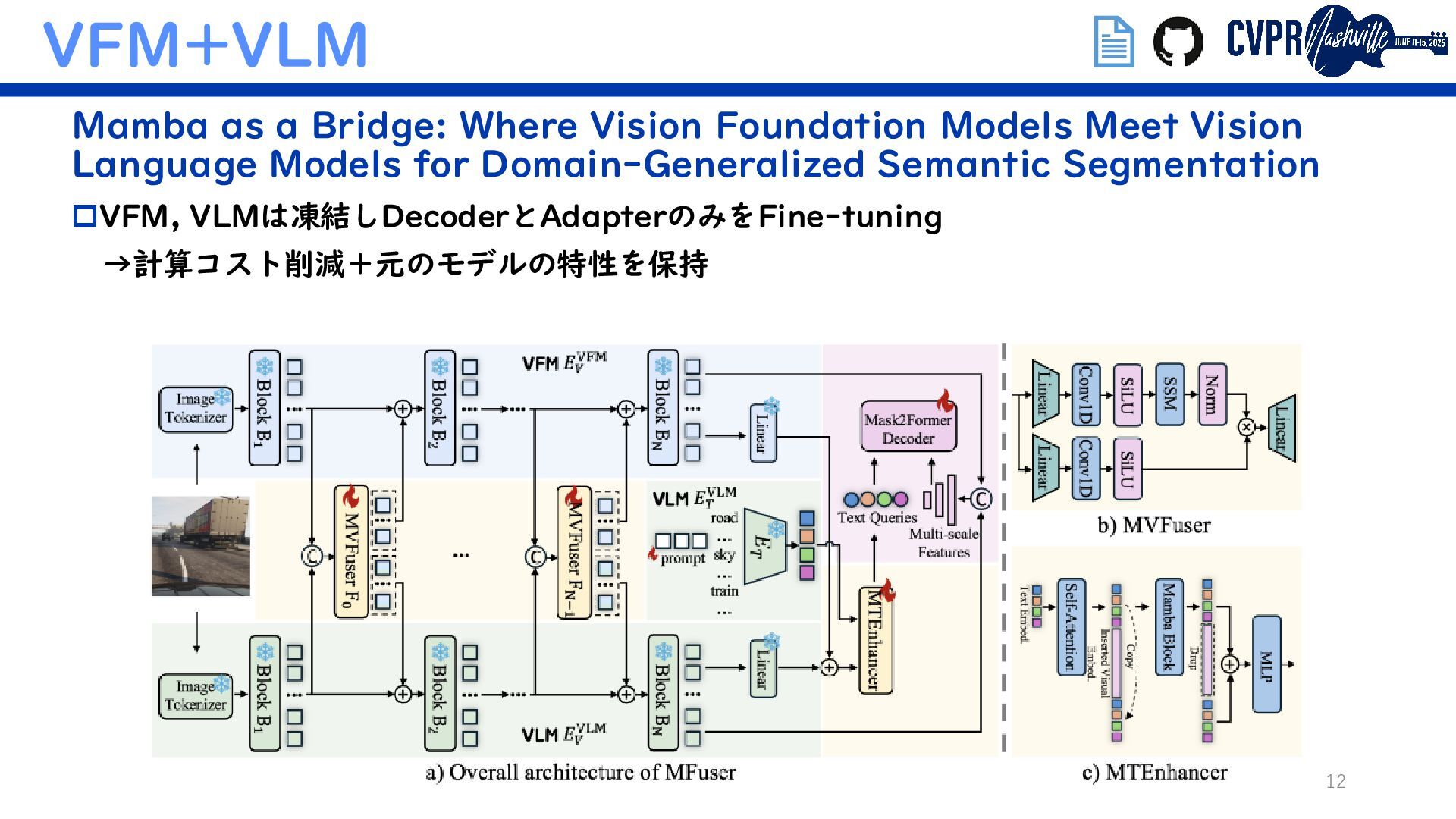
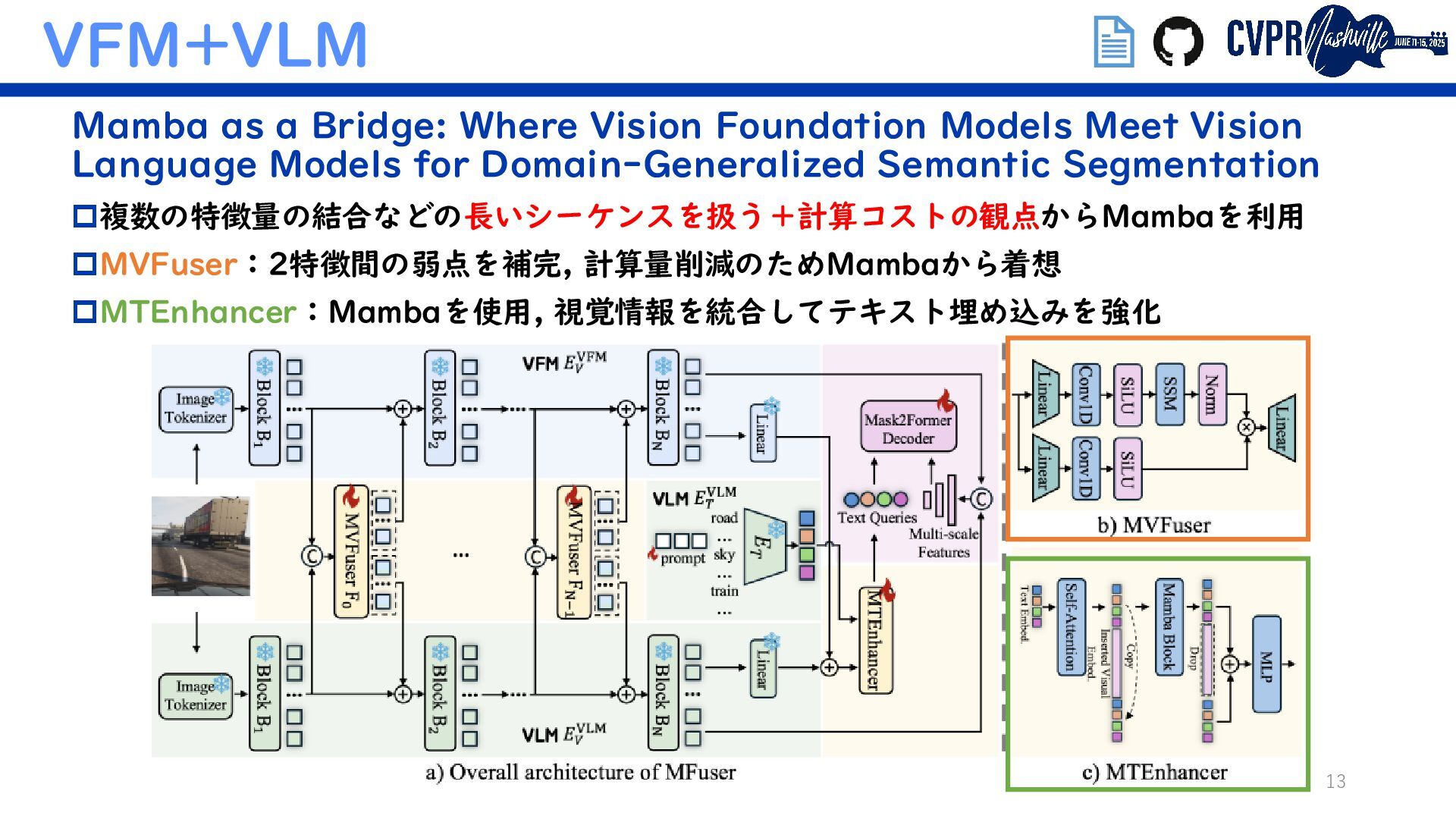
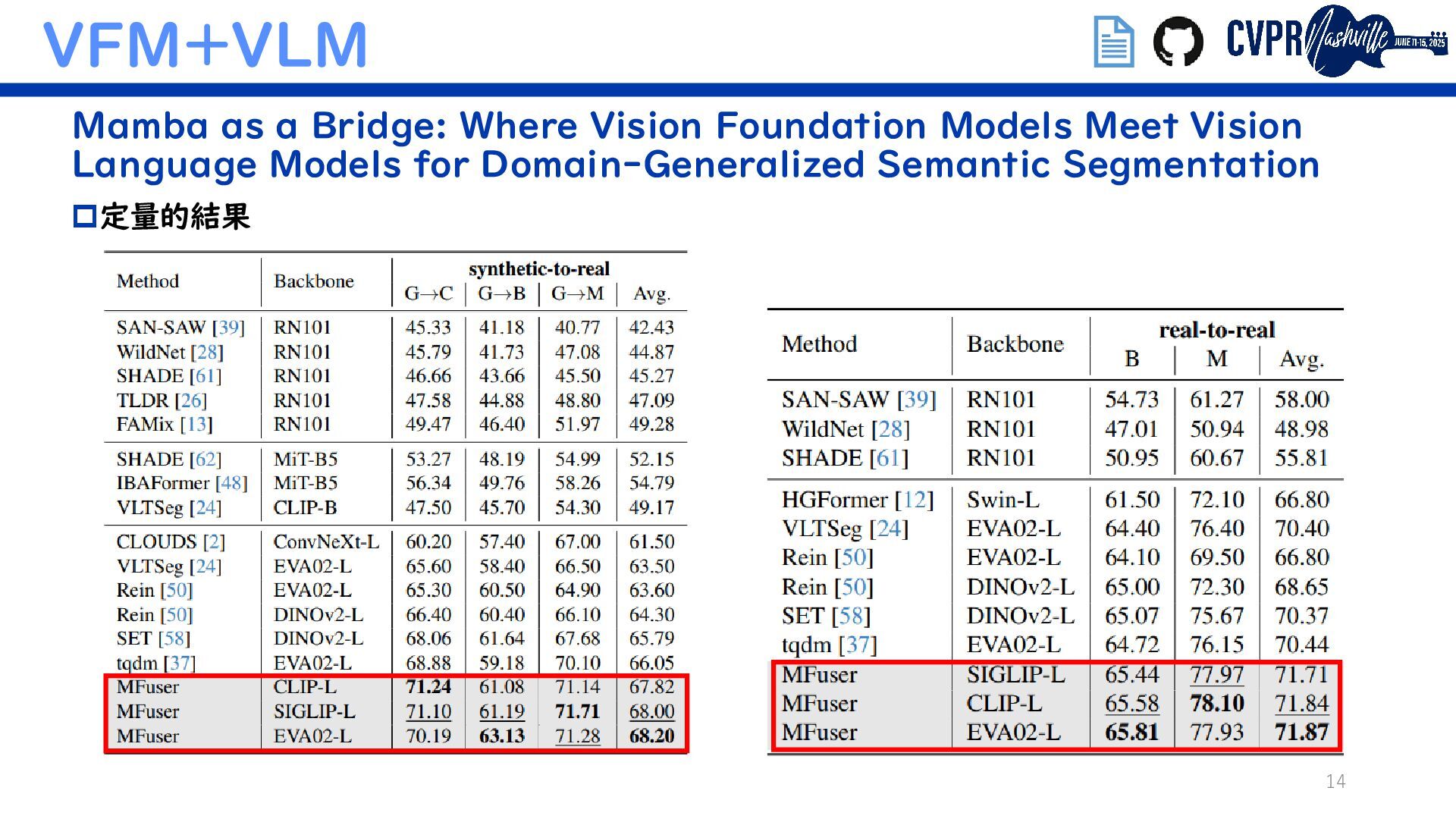
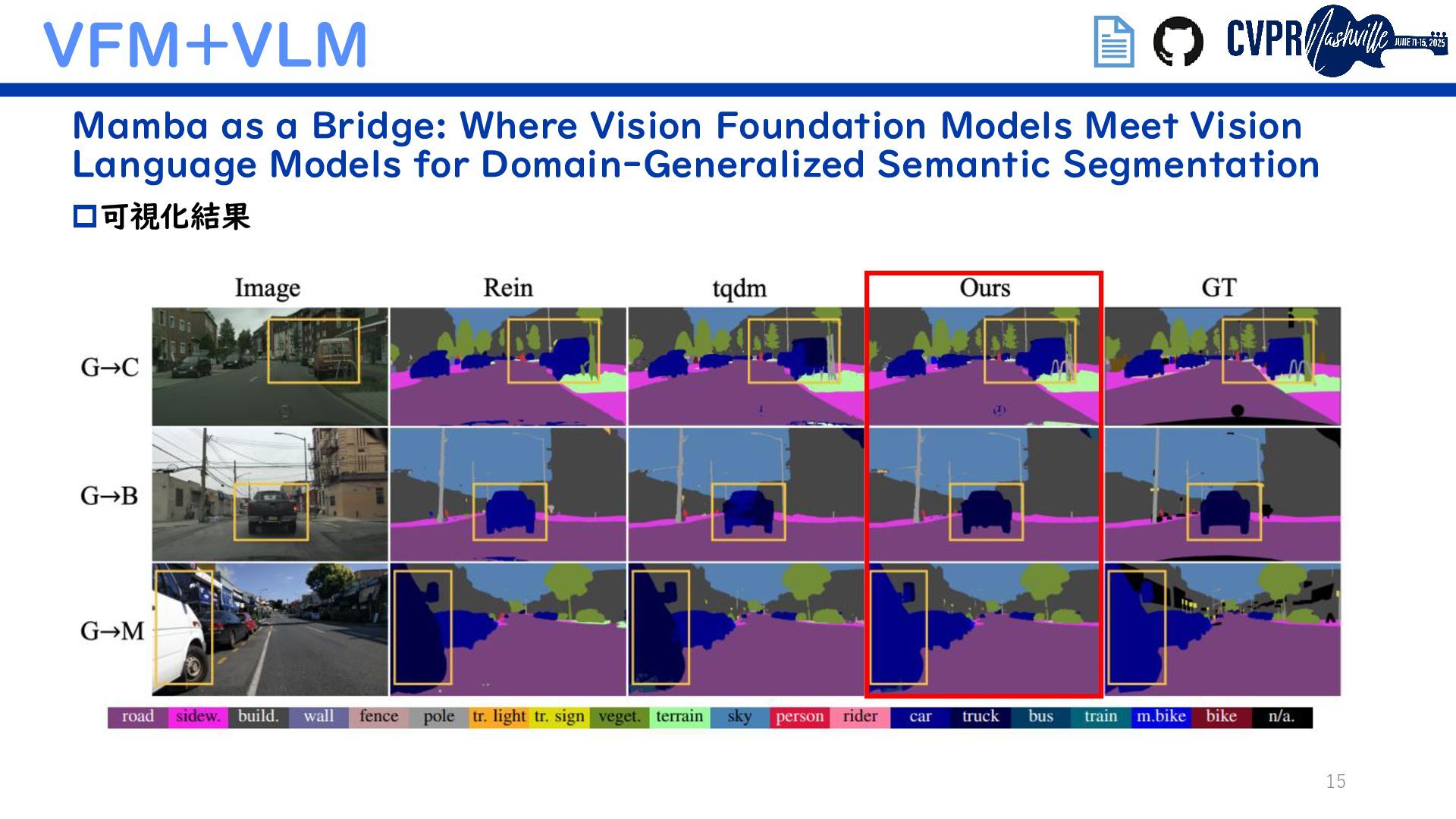
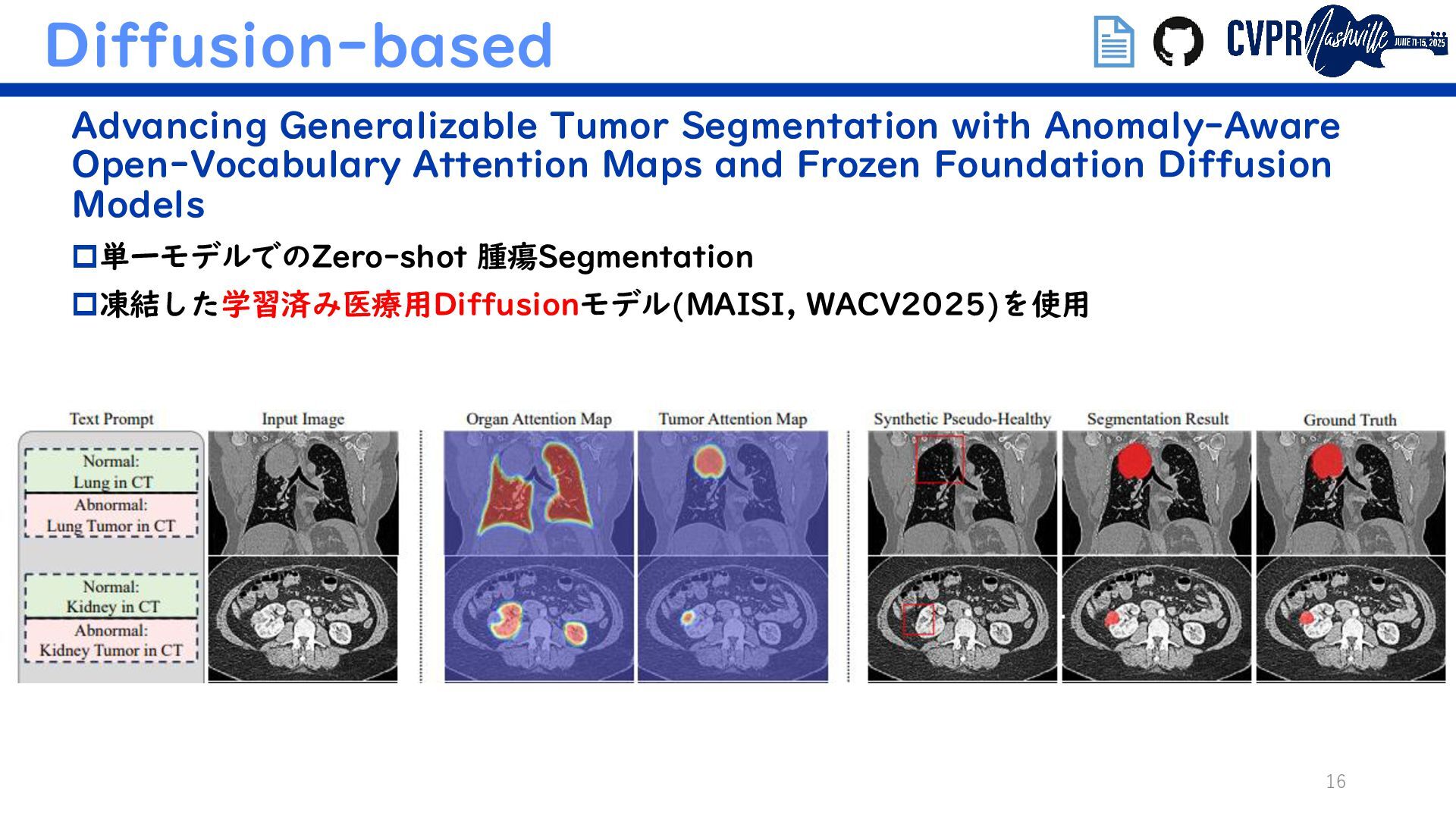
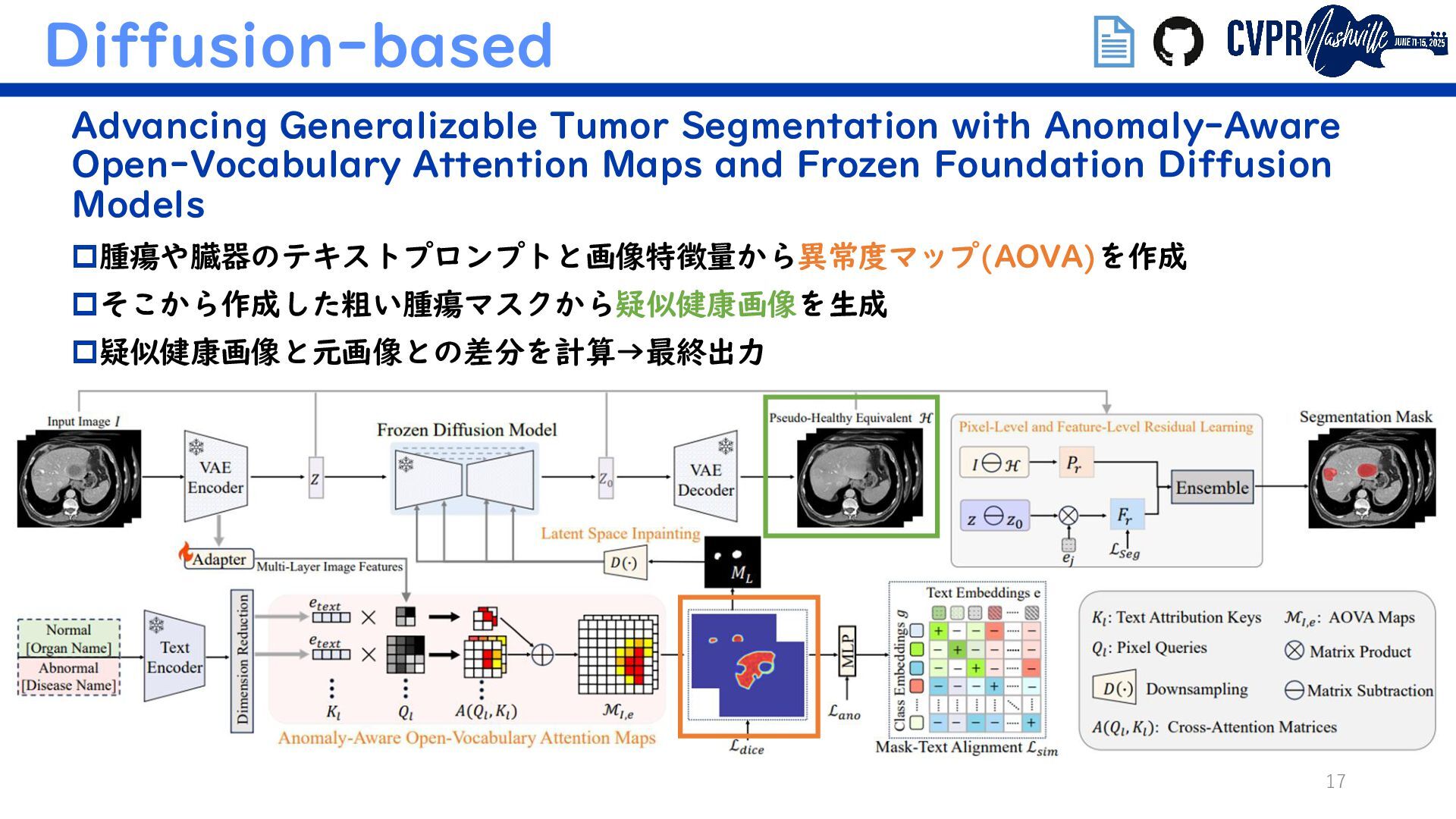
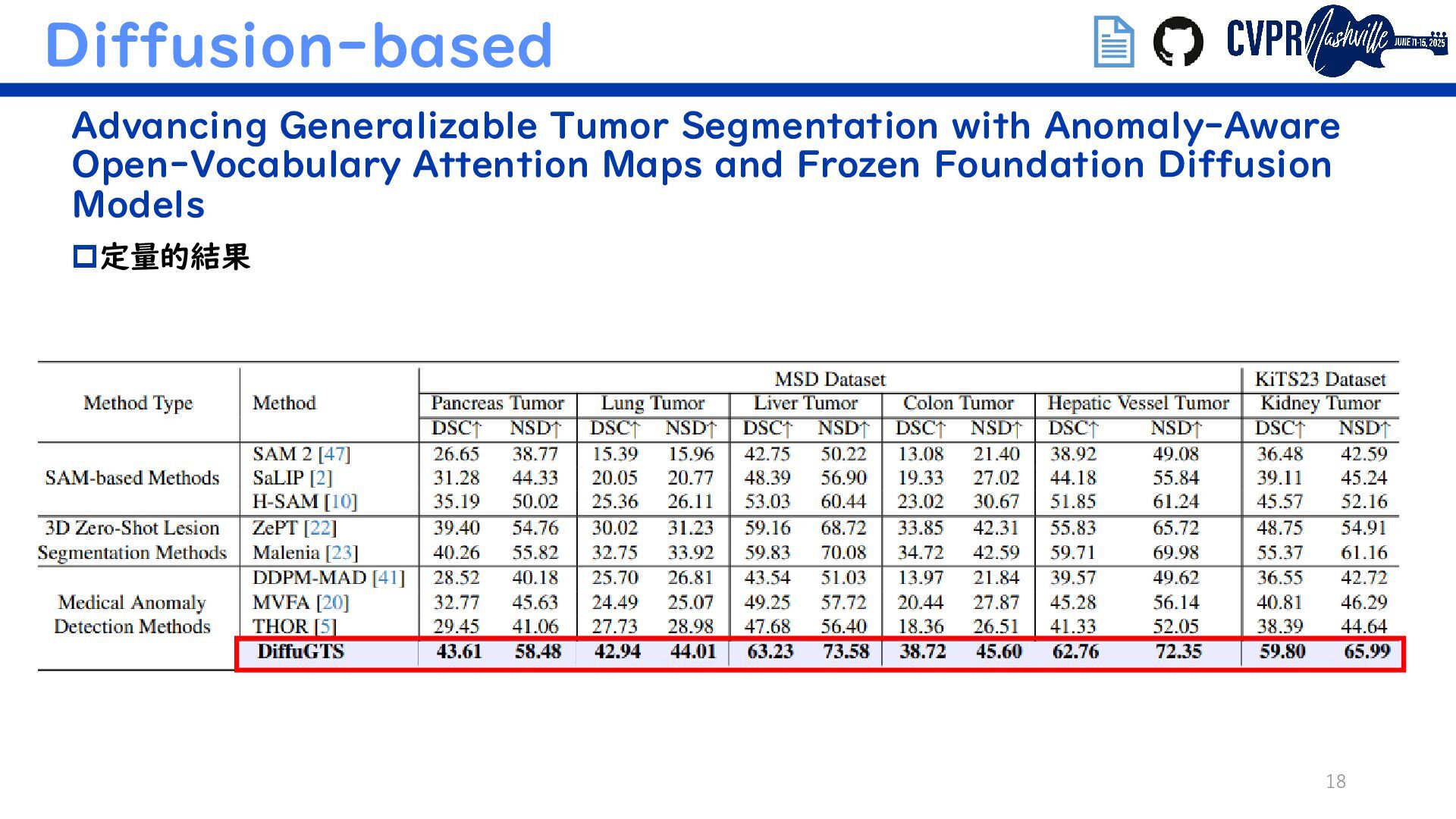
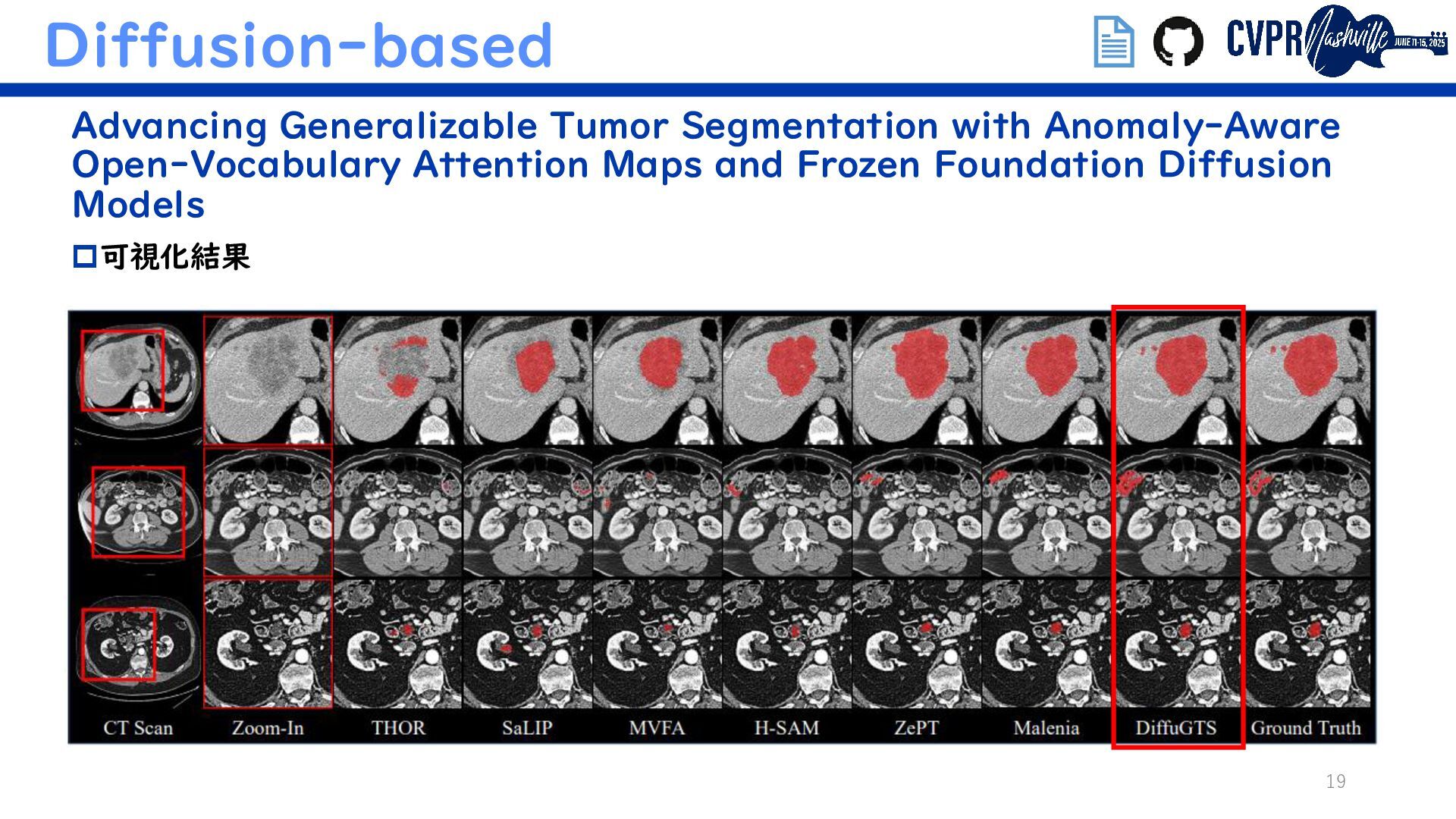
VFM+VLM Mamba as a Bridge: Where Vision Foundation Models Meet Vision Language Models for Domain-Generalized Semantic Segmentation Diffusion-based Advancing Generalizable Tumor Segmentation with Anomaly- Aware Open-Vocabulary Attention Maps and Frozen Foundation Diffusion Models (Semanticでないがトレンド補完のため) 埋込リンクで当該論文/GitHubに飛べます ↑
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
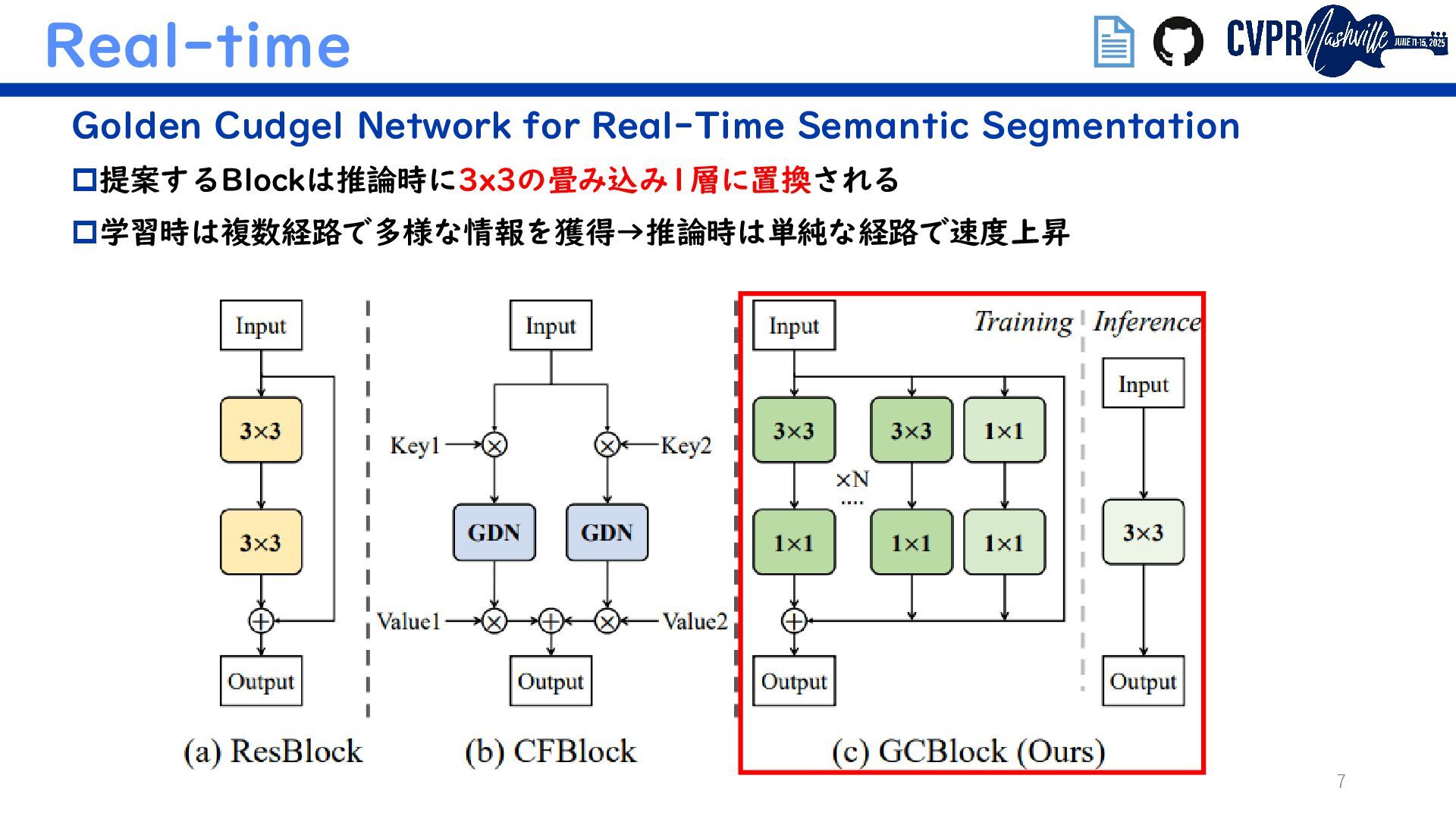{kind=link}
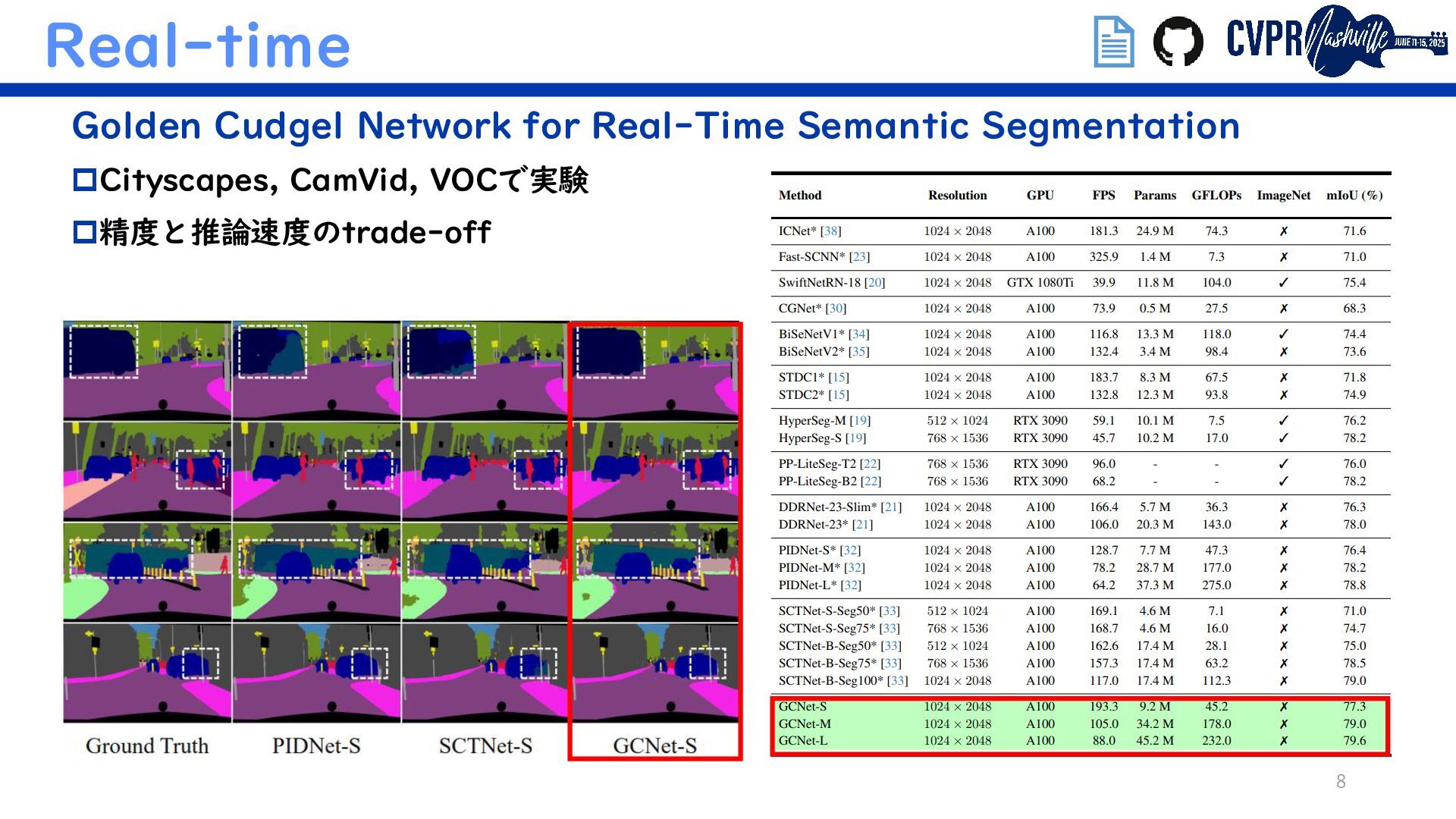{kind=link}
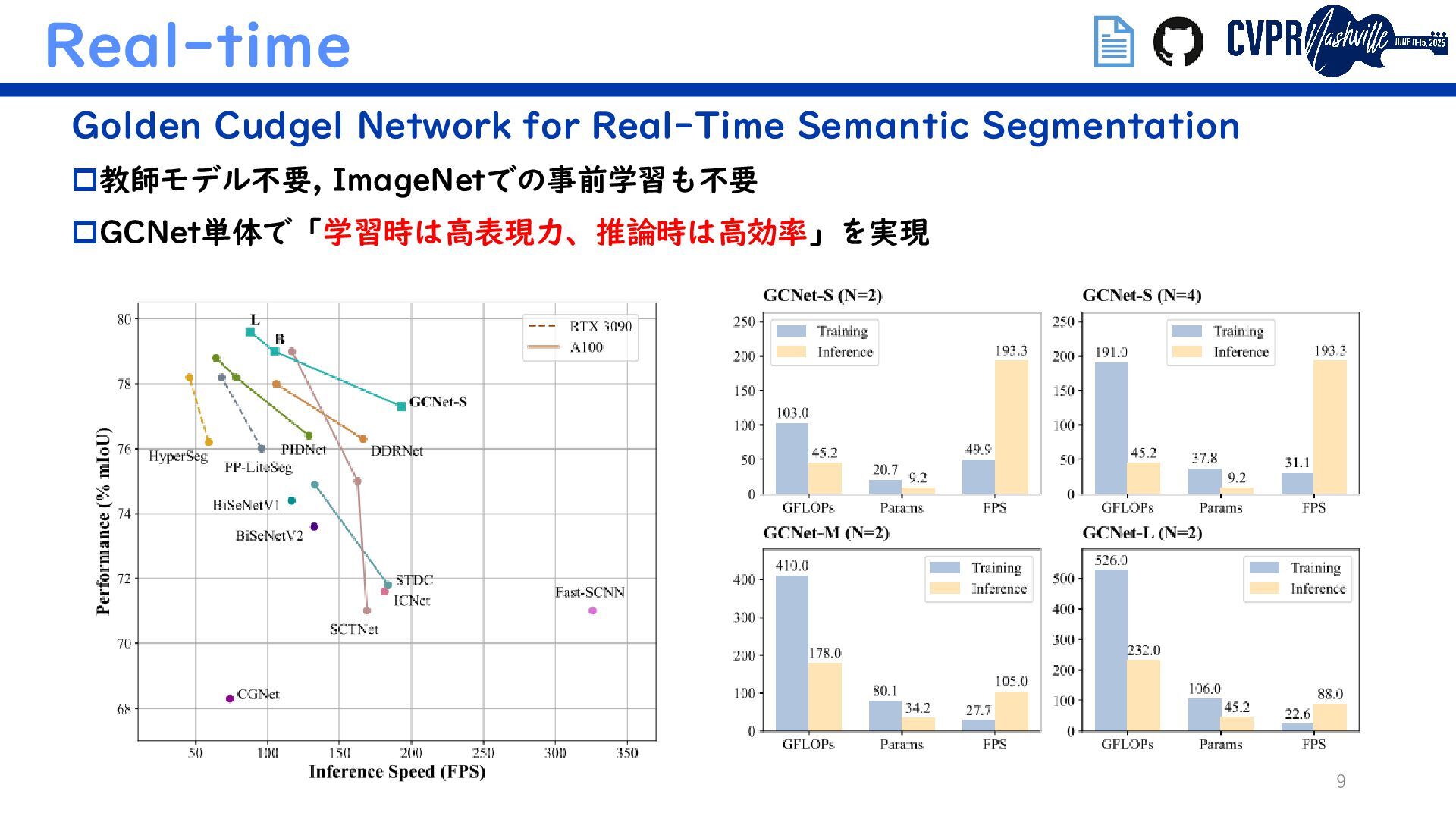{kind=link}
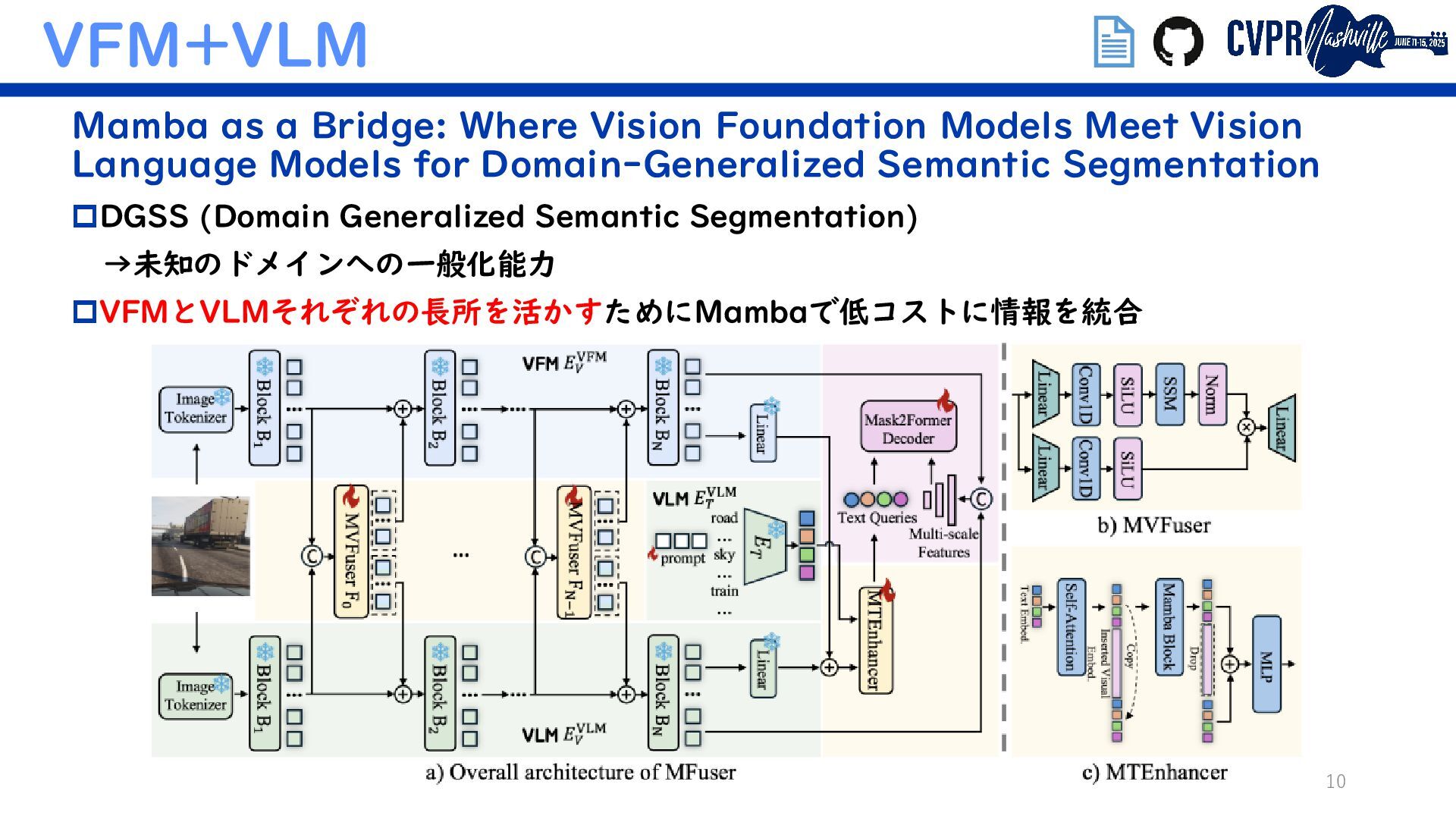{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}