Anything ◼ Open-Vocabulary SAM: Segment and Recognize Twenty-thousand Classes Interactively ◼ Crowd-SAM:SAM as a smart annotator for object detection in crowded scenes ◼ PQ-SAM: Post-training Quantization for Segment Anything Model ◼ Pro2SAM: Mask Prompt to SAM with Grid Points for Weakly Supervised Object Localization ◼ CC-SAM: Enhancing SAM with Cross-feature Attention and Context for Ultrasound Image Segmentation ◼ CAT-SAM: Conditional Tuning for Few-Shot Adaptation of Segment Anything Model ◼ WPS-SAM: Towards Weakly-Supervised Part Segmentation with Foundation Models VP-SAM: Taming Segment Anything Model for Video Polyp Segmentation via Disentanglement and Spatio-temporal Side Network ◼ Domesticating SAM for Breast Ultrasound Image Segmentation via Spatial-frequency Fusion and Uncertainty Correction ◼ Segment and Recognize Anything at Any Granularity ◼ Better Call SAL: Towards Learning to Segment Anything in Lidar ◼ SAM-COD: SAM-guided Unified Framework for Weakly-Supervised Camouflaged Object Detection ◼ LiteSAM is Actually what you Need for segment Everything ◼ Learning to Adapt SAM for Segmenting Cross-domain Point Clouds ◼ SAM4MLLM: Enhance Multi-Modal Large Language Model for Referring Expression Segmentation •:今日発表します
Any Change ◼ Agent Skill Acquisition for Large Language Models via CycleQD (SAMのモデルマージを実施/Workshop/著者はSakanaAIの方) BMVC2024 ◼ SAM-EG: Segment Anything Model with Egde Guidance framework for efficient Polyp Segmentation ◼ SAM Helps SSL: Mask-guided Attention Bias for Self-supervised Learning SAM2ベース ◼ Segment Anything in Medical Images and Videos: Benchmark and Deployment ◼ SAM2-UNet: Segment Anything 2 Makes Strong Encoder for Natural and Medical Image Segmentation etc…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
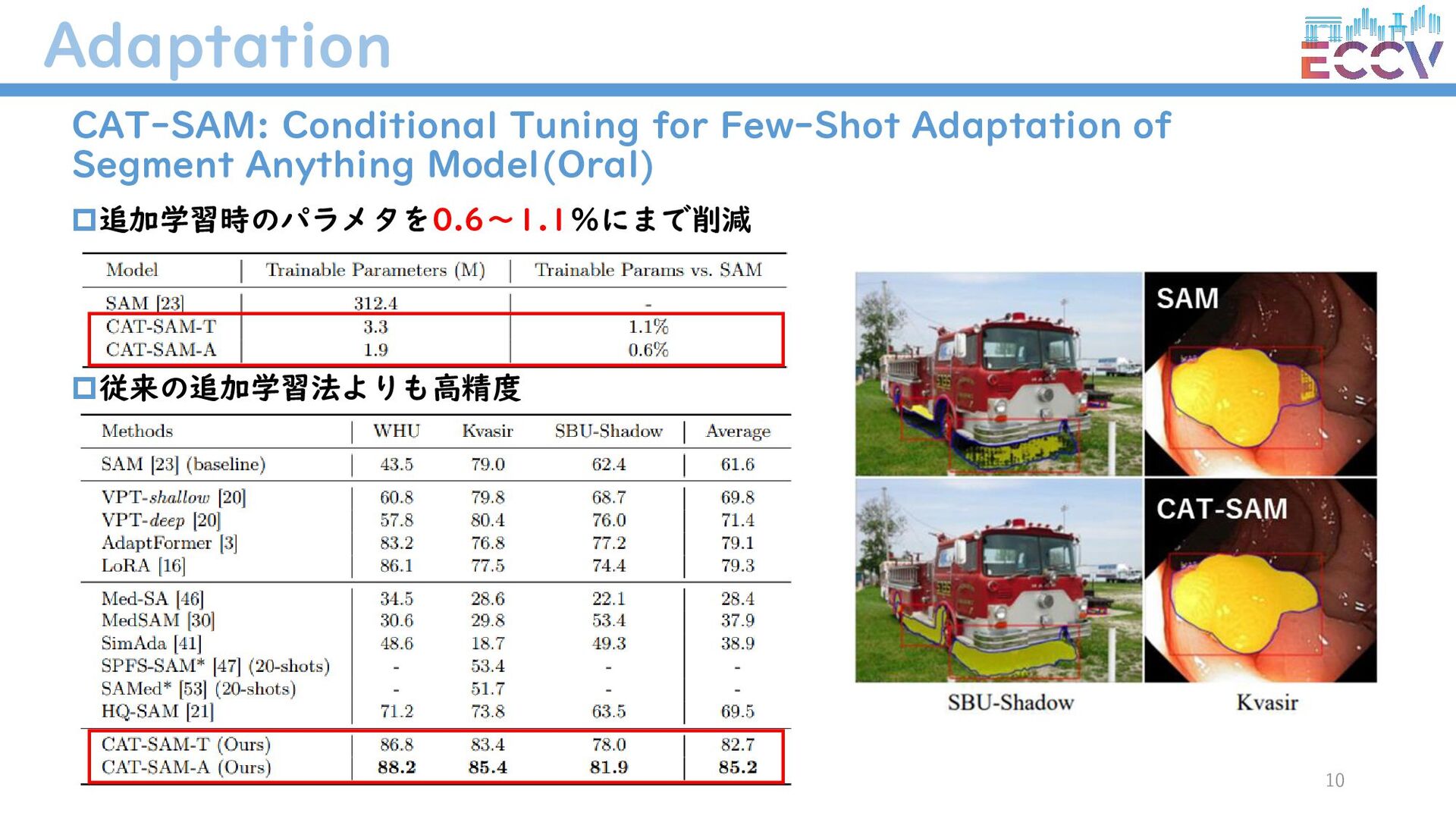{kind=link}
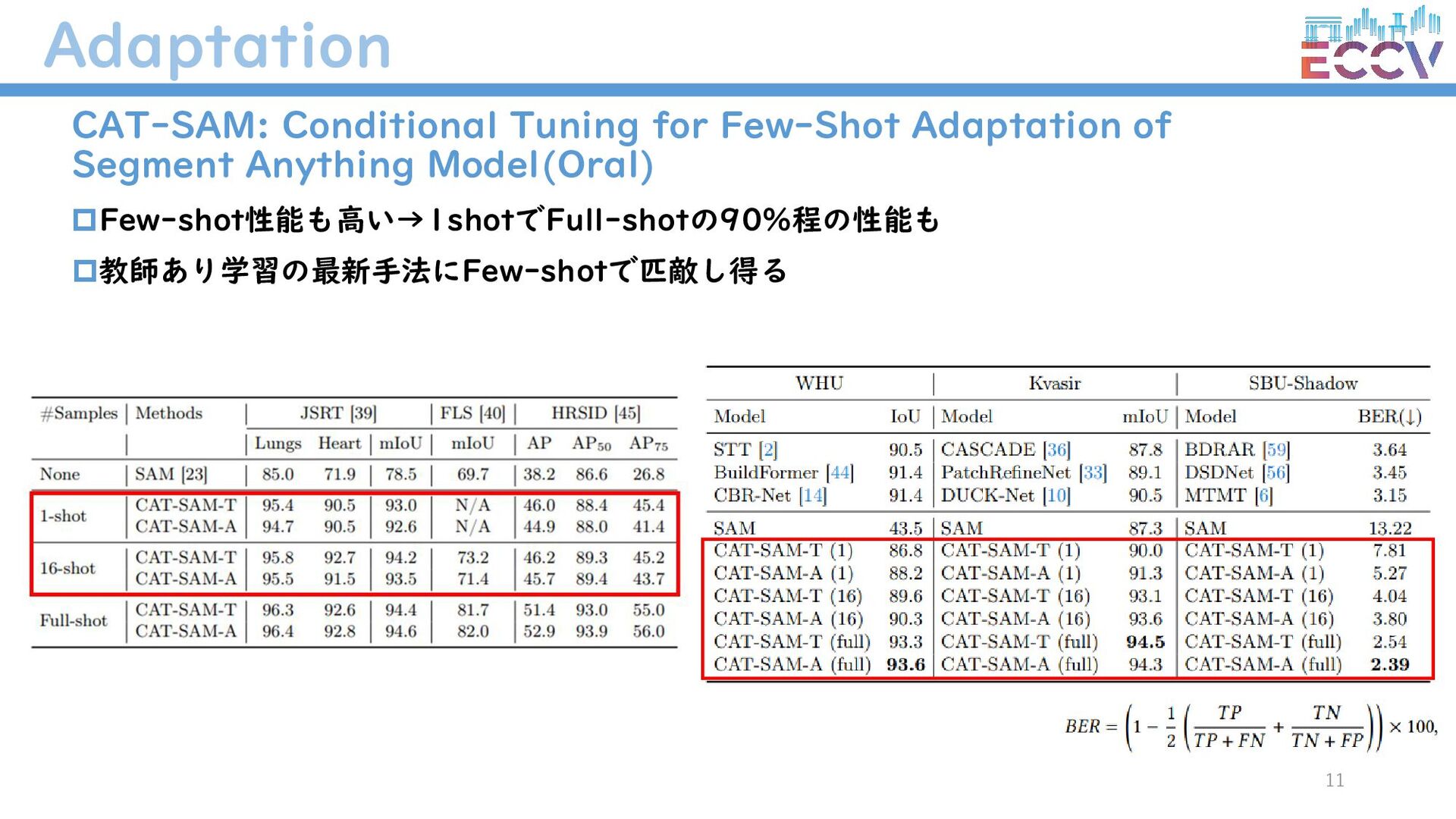{kind=link}
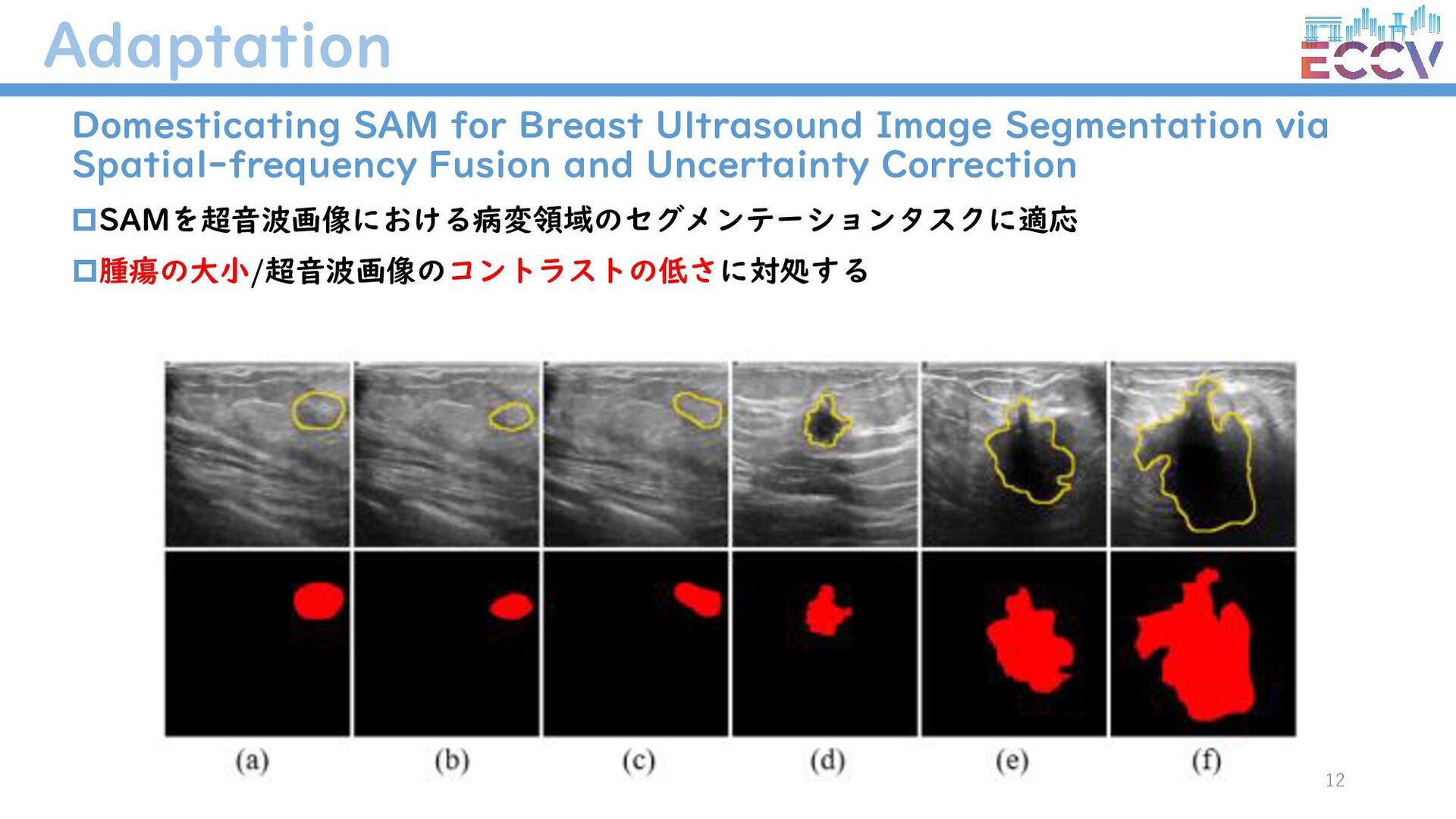{kind=link}
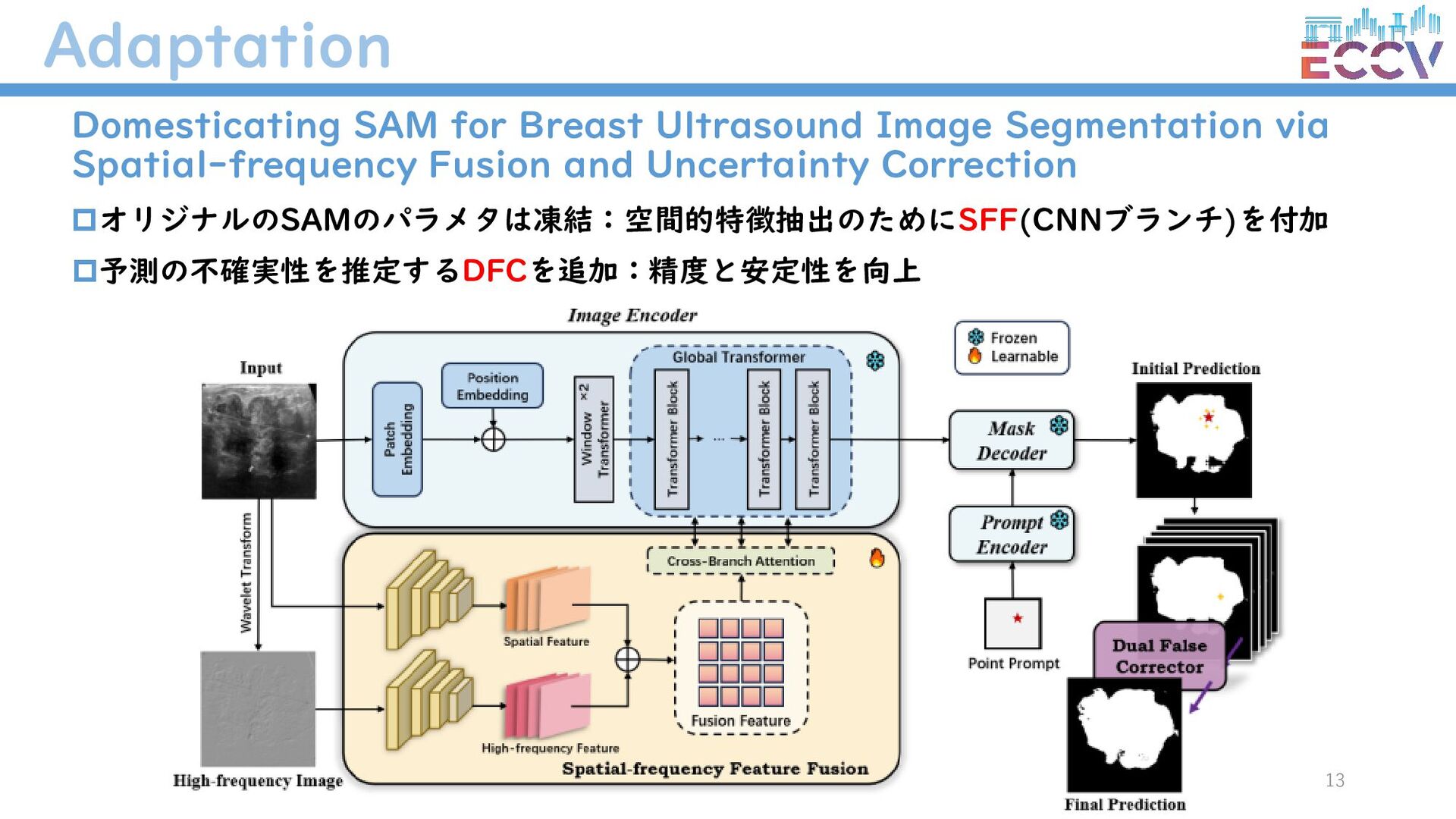{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
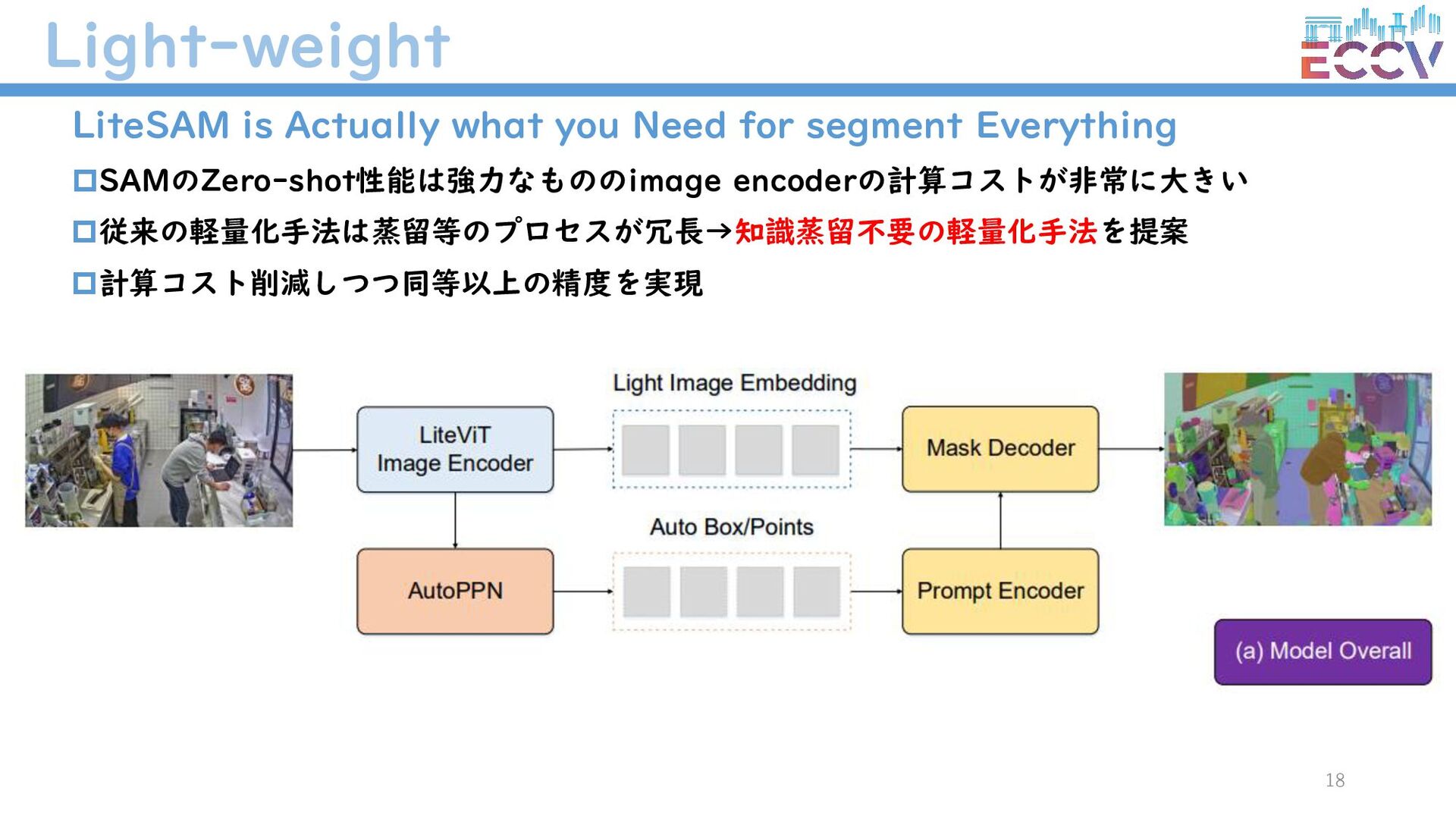{kind=link}
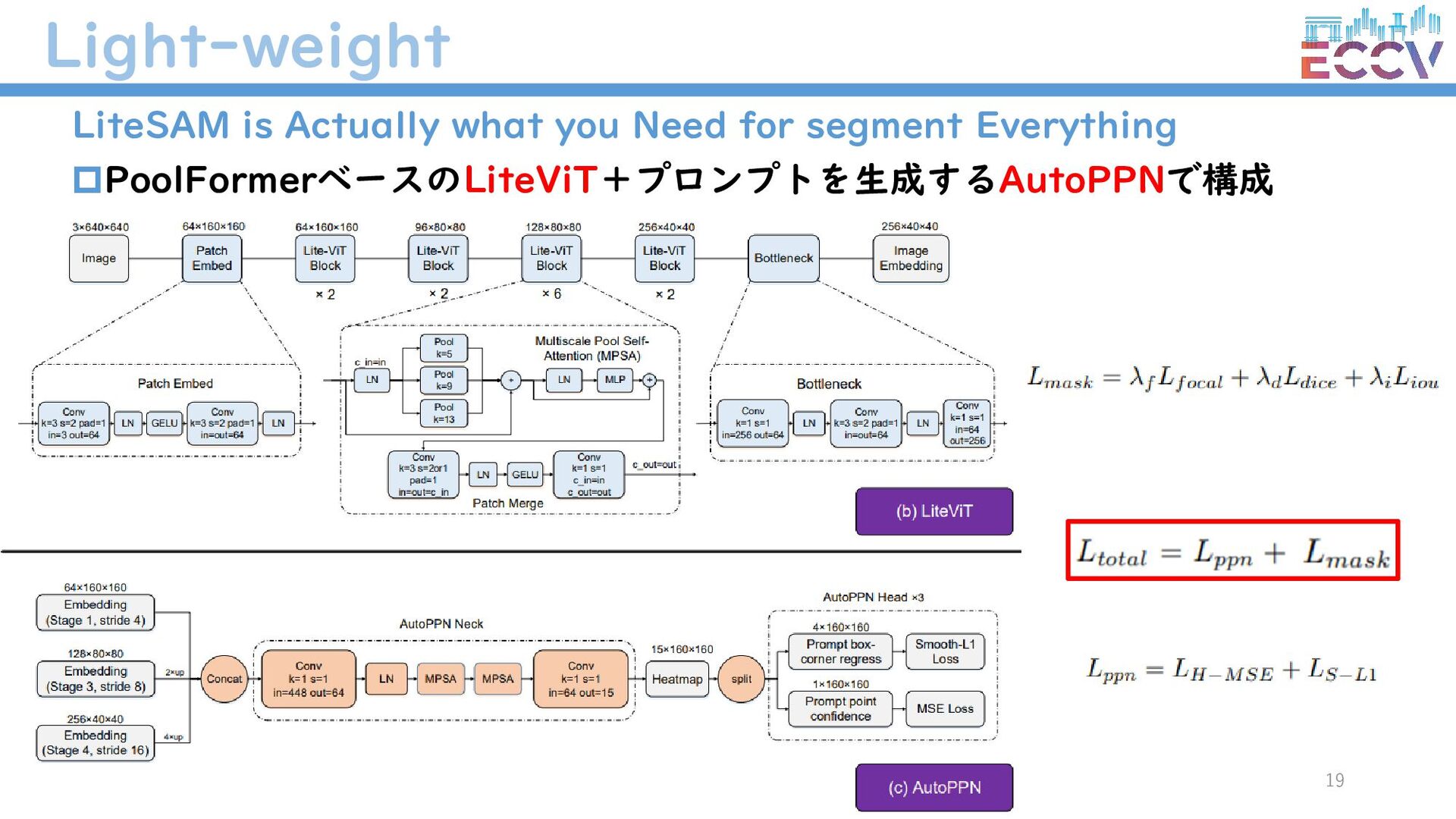{kind=link}
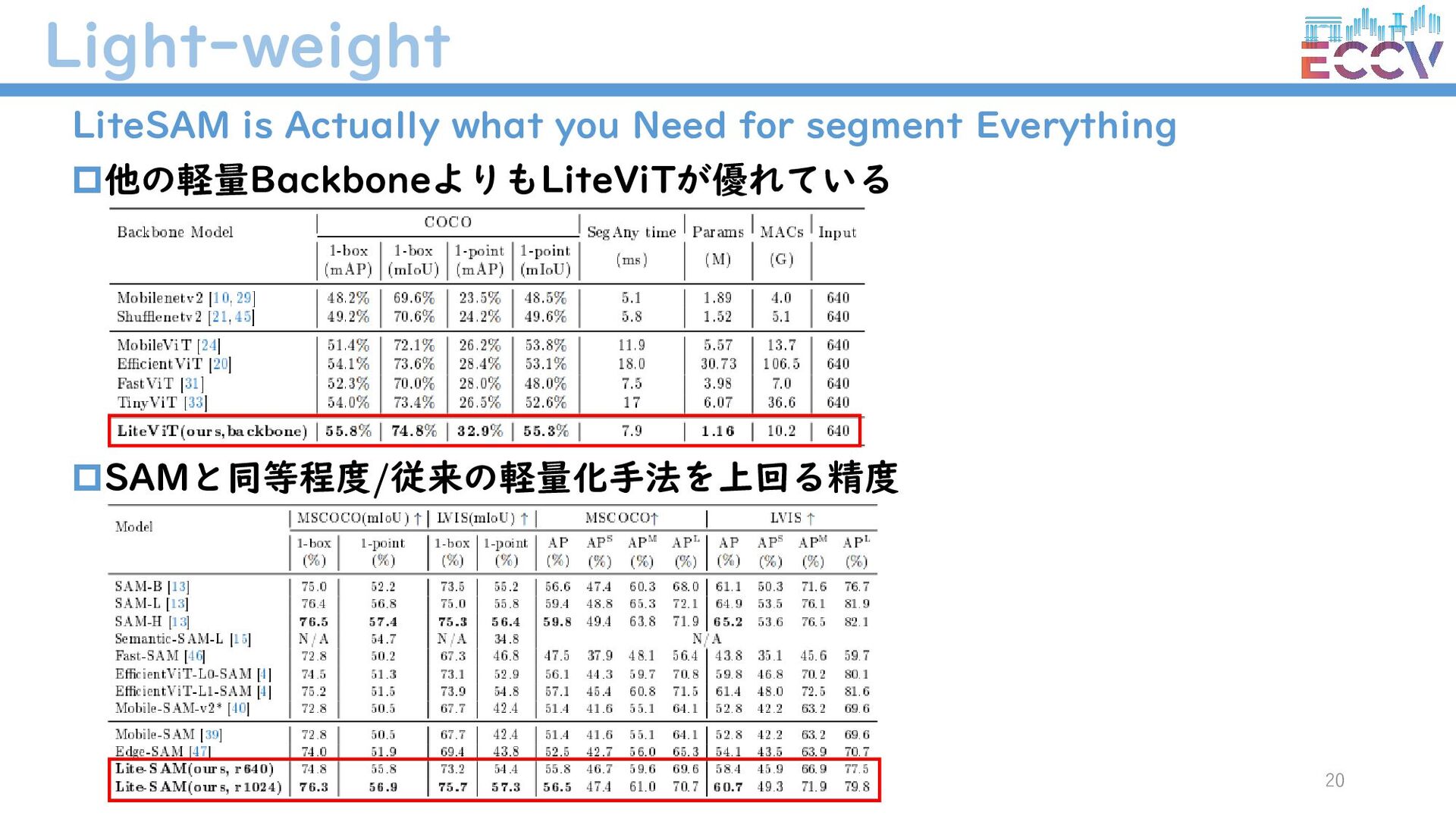{kind=link}
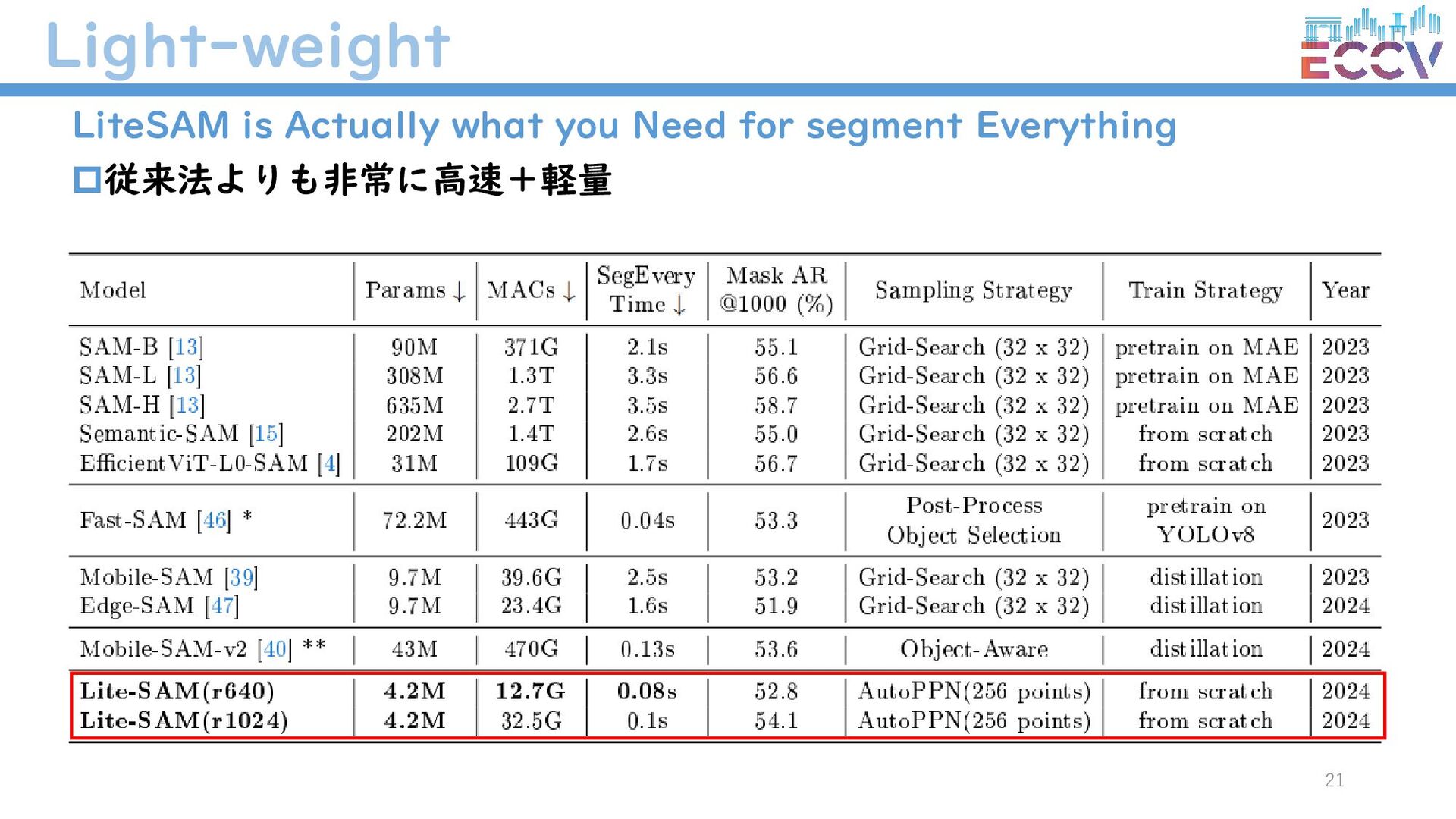{kind=link}
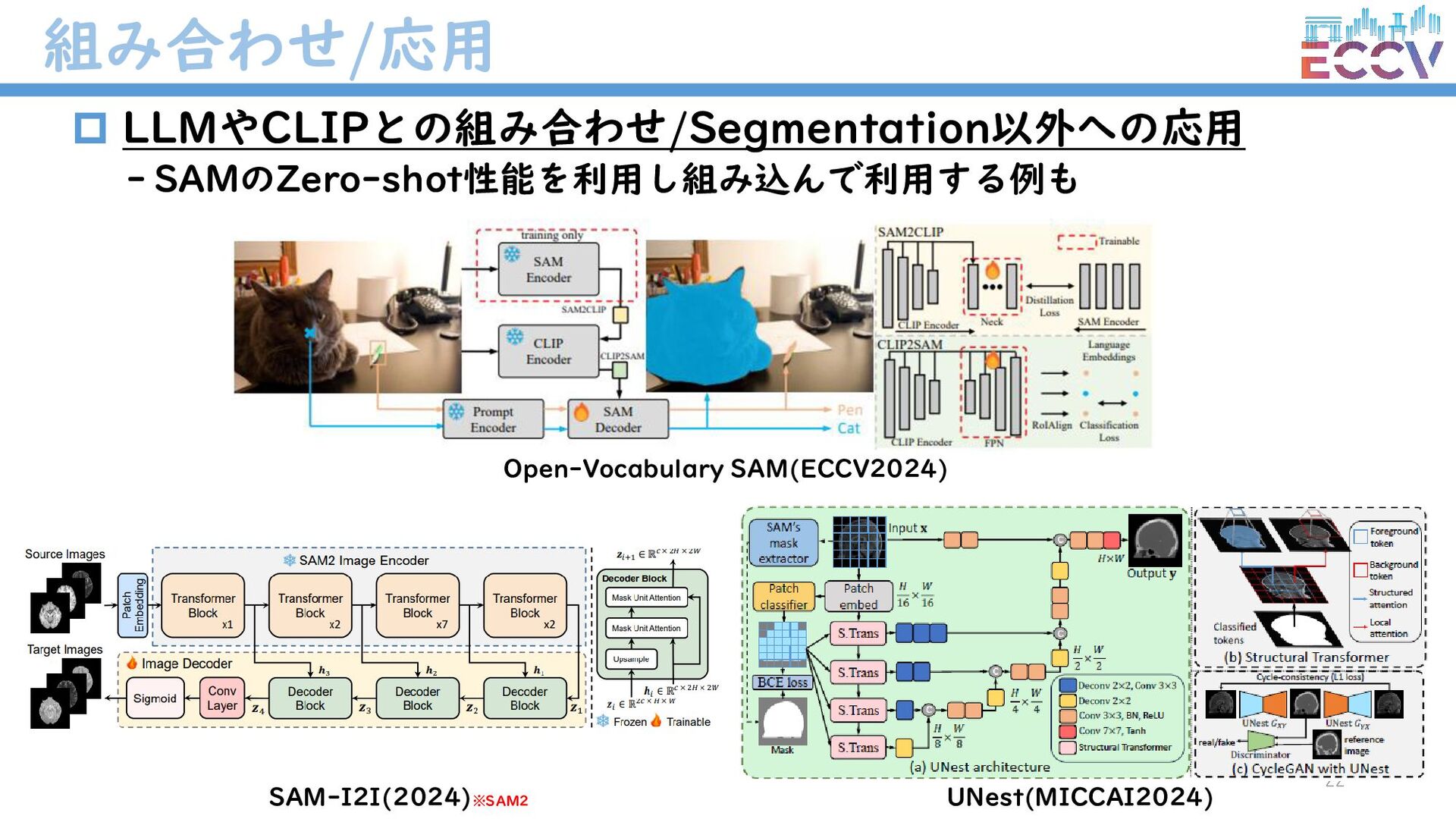{kind=link}
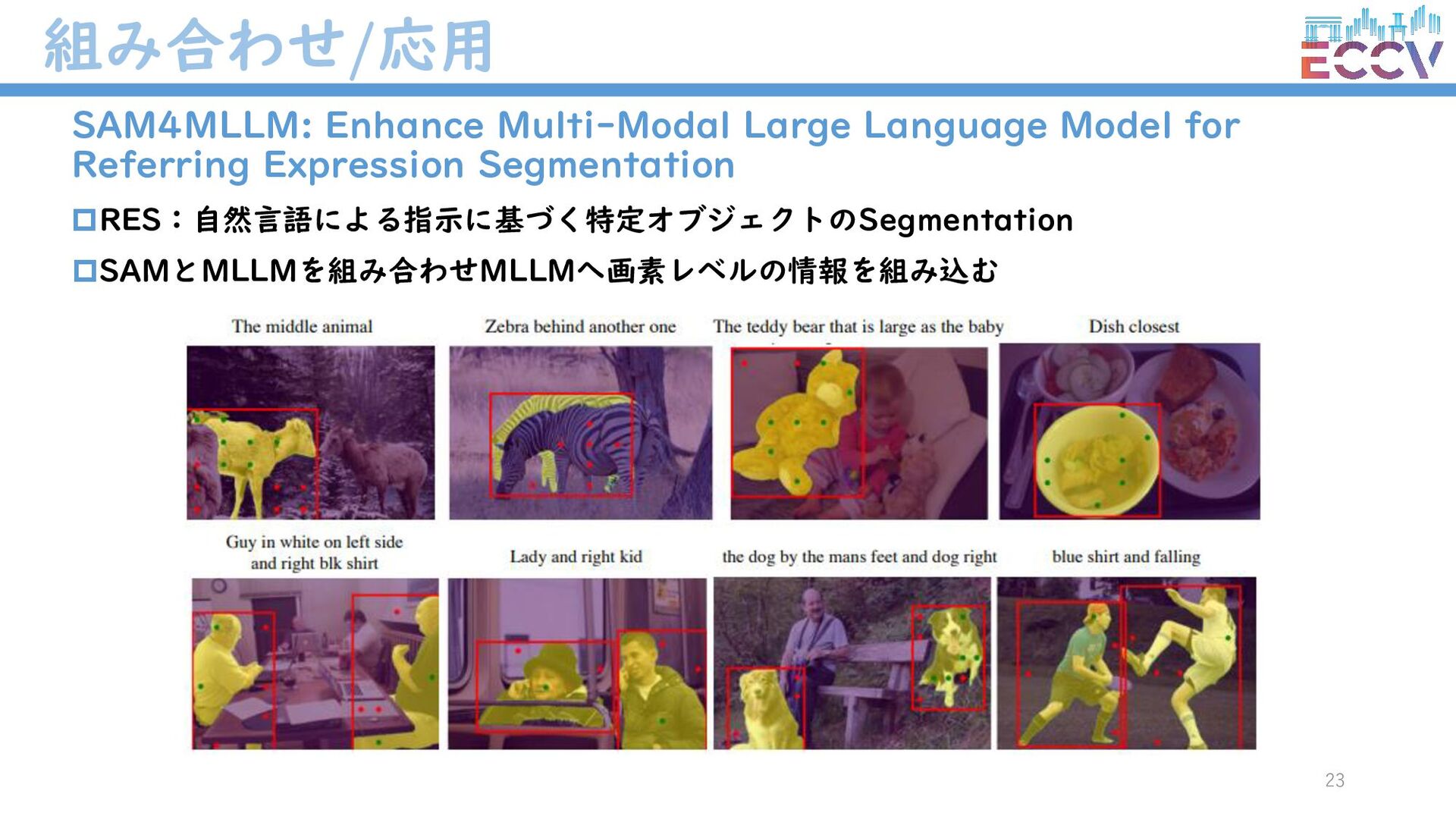{kind=link}
{kind=link}
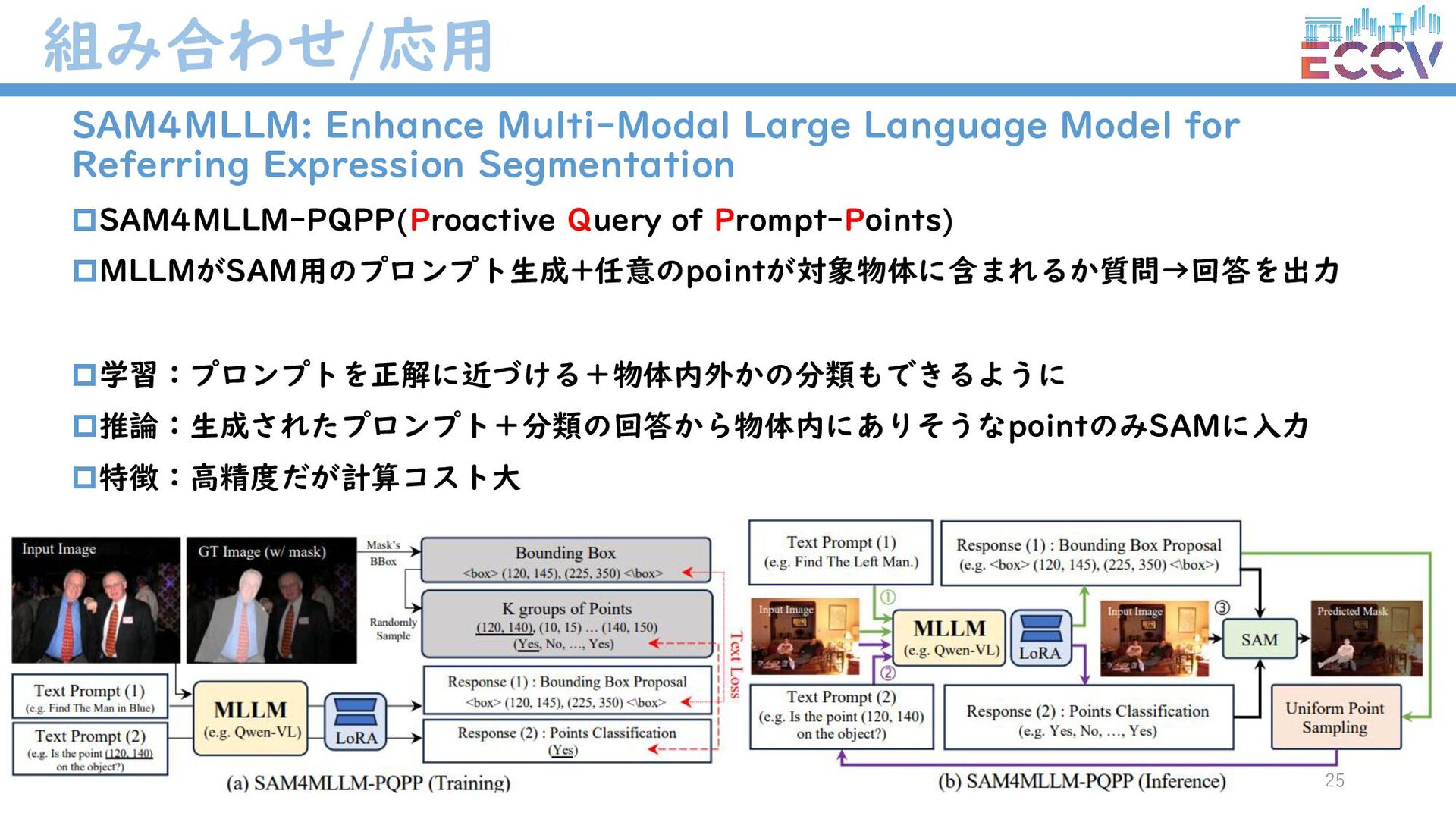{kind=link}
{kind=link}
{kind=link}
{kind=link}