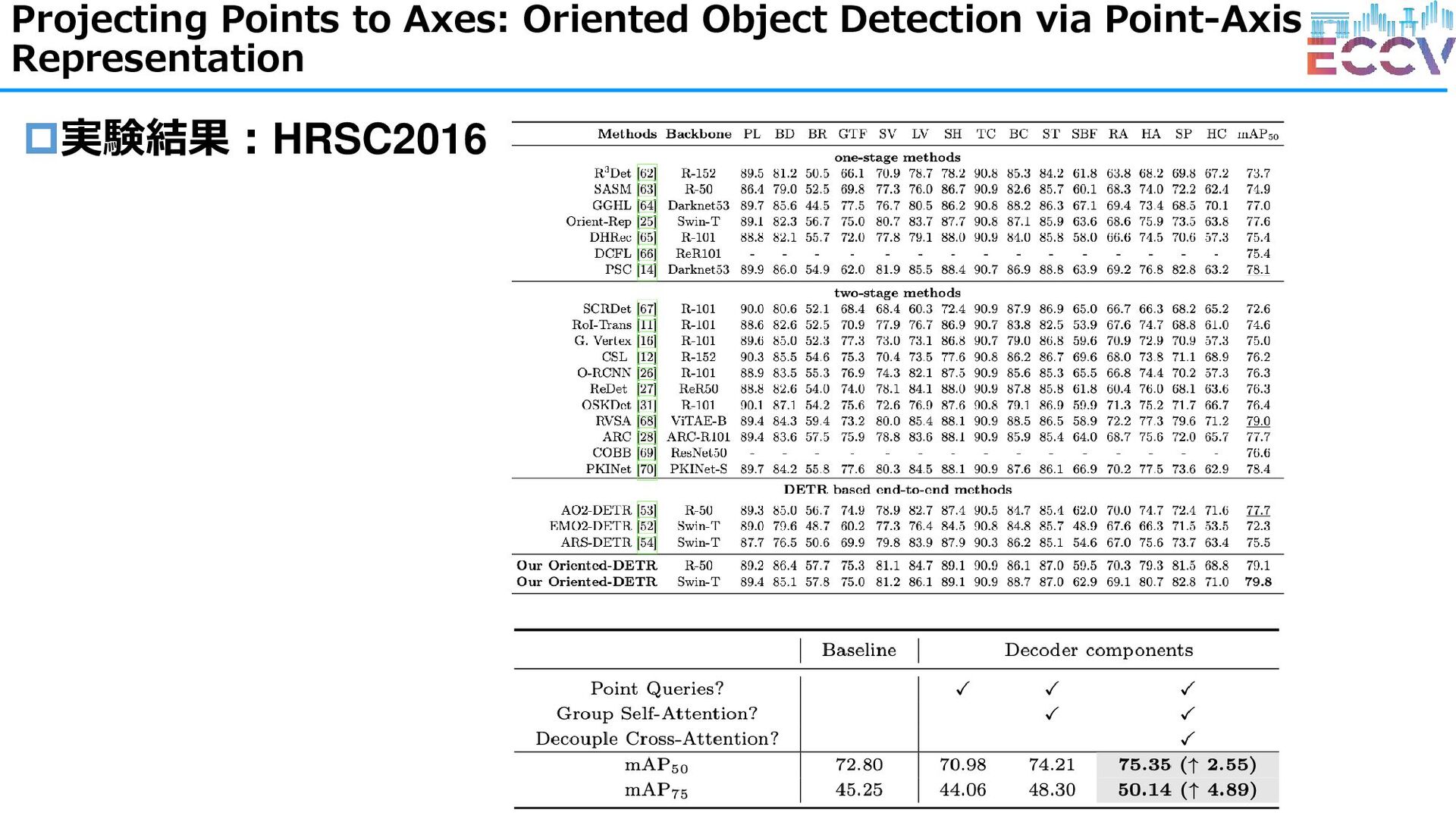
for High-performance and Energy-efficient Object Detection (ECCV2024 Best Paper Award Candidate) ・Projecting Points to Axes: Oriented Object Detection via Point-Axis Representation ・DQ-DETR: DETR with Dynamic Query for Tiny Object Detection ・Relation DETR: Exploring Explicit Position Relation Prior for Object Detection ※DETRに関する論文:14件 / 78件
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}