M.F. Naeem, H. Li, B. Schiele, and L. Wang, "GiT: Towards Generalist Vision Transformer through Universal Language Interface," in European Conference on Computer Vision (ECCV), pp. 55–73, 2025. [Liu+ 2024] H. Liu, C. Li, Q. Wu, and Y.J. Lee, "Visual Instruction Tuning," in Advances in Neural Information Processing Systems (NeurIPS), vol. 36, 2024. [Wang+ 2024] Wenhai Wang, Z. Chen, X. Chen, J. Wu, X. Zhu, G. Zeng, P. Luo, T. Lu, J. Zhou, Y. Qiao, et al., "VisionLLM: Large Language Model is also an Open- Ended Decoder for Vision-Centric Tasks," in Advances in Neural Information Processing Systems (NeurIPS), vol. 36, 2024. [Kenton+ 2019] J.D.M.W.C. Kenton and L.K. Toutanova, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," in North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2019. [Wu+ 2016] Y. Wu, M. Schuster, Z. Chen, Q.V. Le, M. Norouzi, W. Macherey, M. Krikun, Y. Cao, Q. Gao, K. Macherey, et al., "Google’s Neural Machine Translation System: Bridging the Gap Between Human and Machine Translation," arXiv preprint, arXiv:1609.08144, 2016. [Lin+ 2014] T.Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C.L. Zitnick, "Microsoft COCO: Common Objects in Context," in European Conference on Computer Vision (ECCV), 2014. [Chen+ 2015] X. Chen, H. Fang, T.Y. Lin, R. Vedantam, S. Gupta, P. Dollár, and C.L. Zitnick, "Microsoft COCO Captions: Data Collection and Evaluation Server," arXiv preprint, arXiv:1504.00325, 2015. [Yu+ 2016] L. Yu, P. Poirson, S. Yang, A.C. Berg, and T.L. Berg, "Modeling Context in Referring Expressions," in European Conference on Computer Vision (ECCV), Springer, 2016. [Zhou+ 2017] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba, "Scene Parsing through ADE20K Dataset," in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. [Dosovitskiy+ 2021] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale," in International Conference on Learning Representations (ICLR), 2021. 参考文献
{kind=link}
{kind=link}
![紹介する論文 - 複数の視覚タスクを単一のVisionTransformerで解くフレームワークとして、 Generalist Vision Transformer (GiT) [Wang+ 2025] を提案](https://files.speakerdeck.com/presentations/f962fc1ed7794496b8c9e1c1d97fde0c/slide_2.jpg){kind=link}
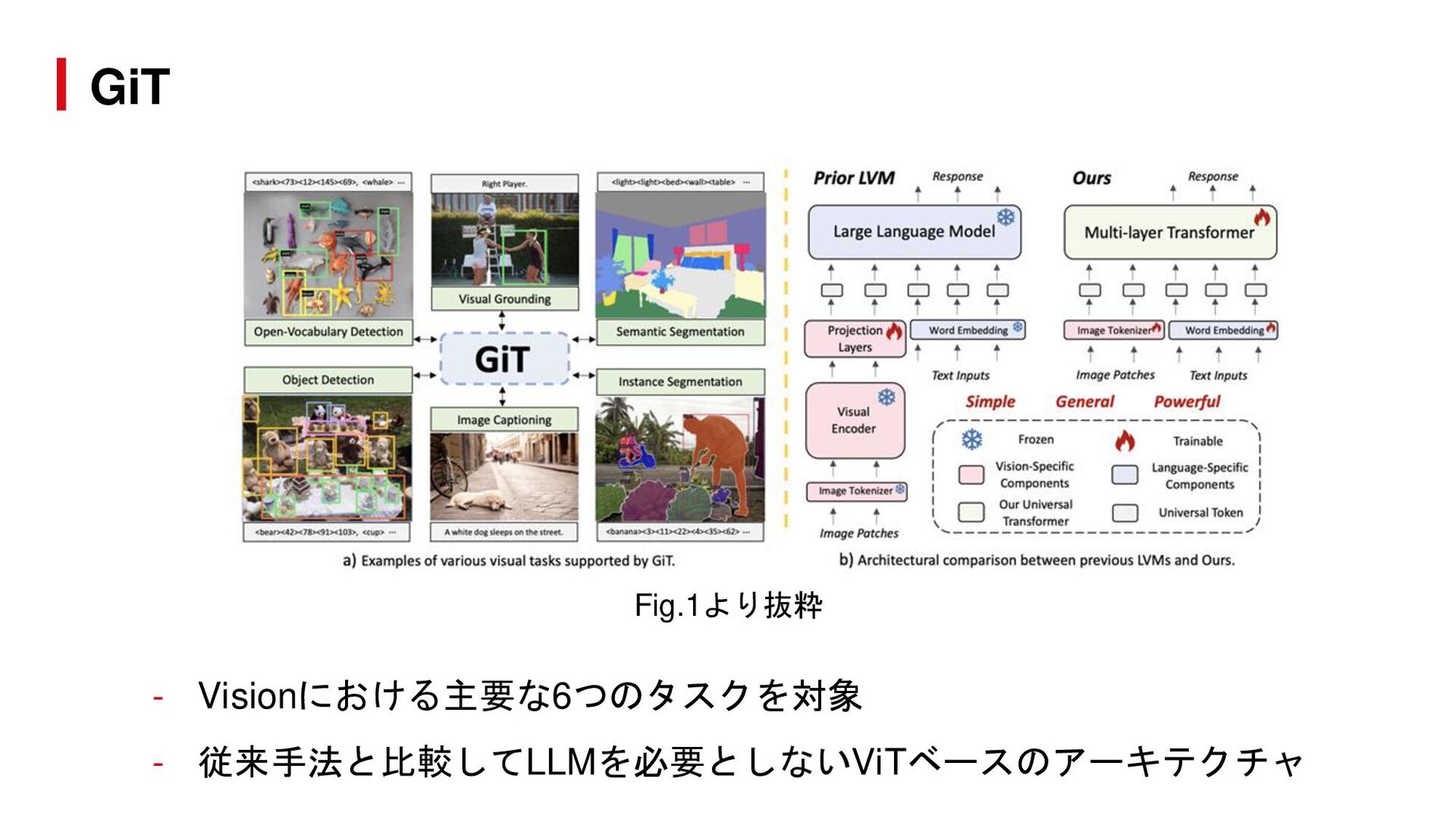{kind=link}
![課題 - 一般に複数のタスクを並行で扱うのは難しい - アーキテクチャ・学習の複雑化 手法 - ViT [Dosovitskiy+ 2021]](https://files.speakerdeck.com/presentations/f962fc1ed7794496b8c9e1c1d97fde0c/slide_4.jpg){kind=link}
{kind=link}
![LLaVA [Liu+ 2024] - 学習済みのVision EncoderとLanguage Model を活用 - 視覚特徴](https://files.speakerdeck.com/presentations/f962fc1ed7794496b8c9e1c1d97fde0c/slide_6.jpg){kind=link}
![Vision Generalist Modelに関する先行研究: VisionLLM VisionLLM*よりFigure 3を抜粋 VisionLLM [Wang+ 2024] -](https://files.speakerdeck.com/presentations/f962fc1ed7794496b8c9e1c1d97fde0c/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
![ViT [Dosovitskiy+ 2021] を基盤に自己回帰な機構で出力 - 画像をトークンと見なしてタスクプロンプトと結合 - 座標が必要なタスクではグリッド分割(N>1)したLocalパッチを入力 提案手法 Fig.2より抜粋](https://files.speakerdeck.com/presentations/f962fc1ed7794496b8c9e1c1d97fde0c/slide_10.jpg){kind=link}
![テキストトークンの作成 テキスト表現 - 複数の単語からなる単語をそれぞれトークンで表すのは冗長 - BERT [Kenton+ 2019] に倣い、WordPiece [Wu+](https://files.speakerdeck.com/presentations/f962fc1ed7794496b8c9e1c1d97fde0c/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
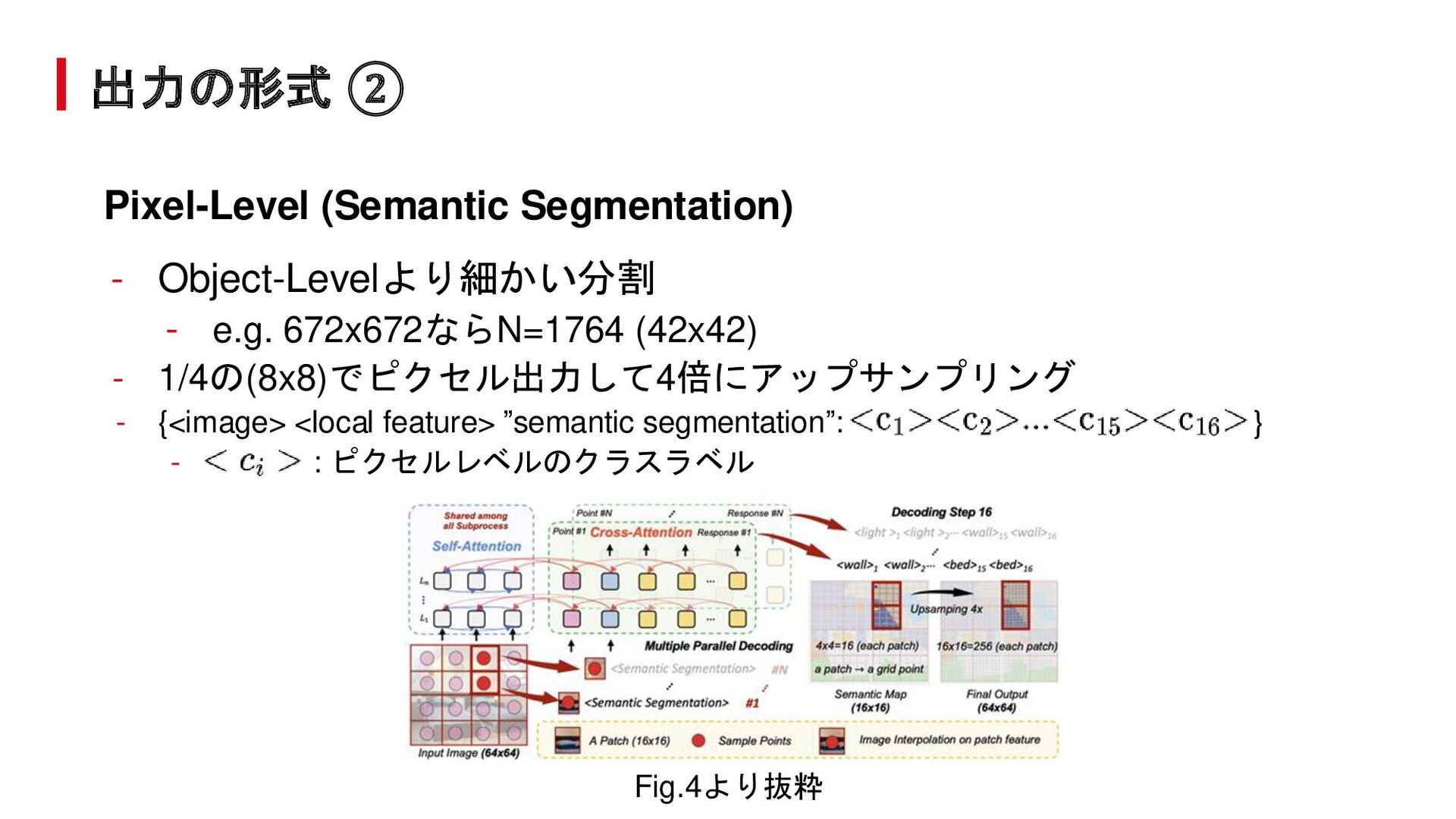{kind=link}
{kind=link}
{kind=link}
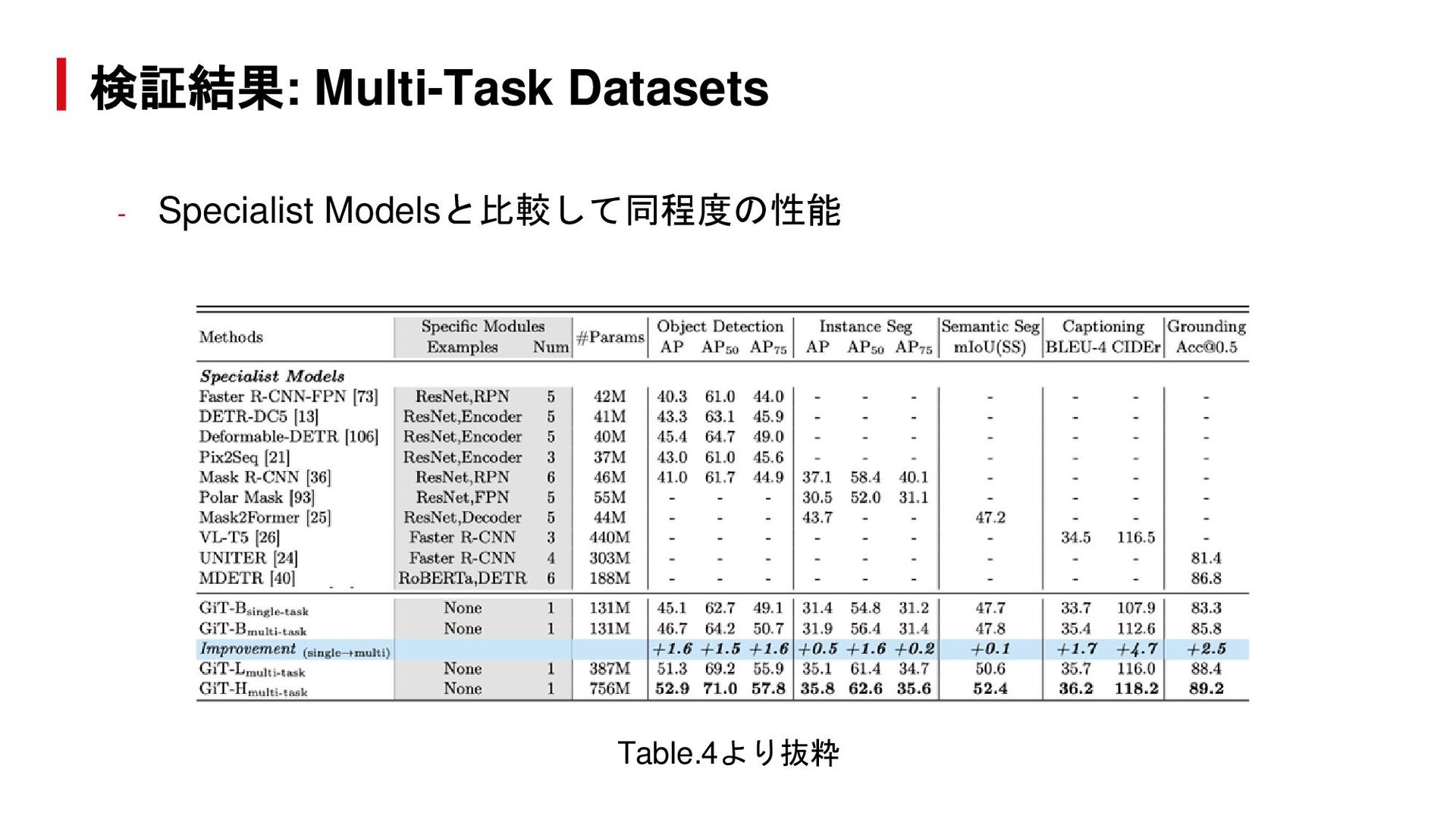{kind=link}
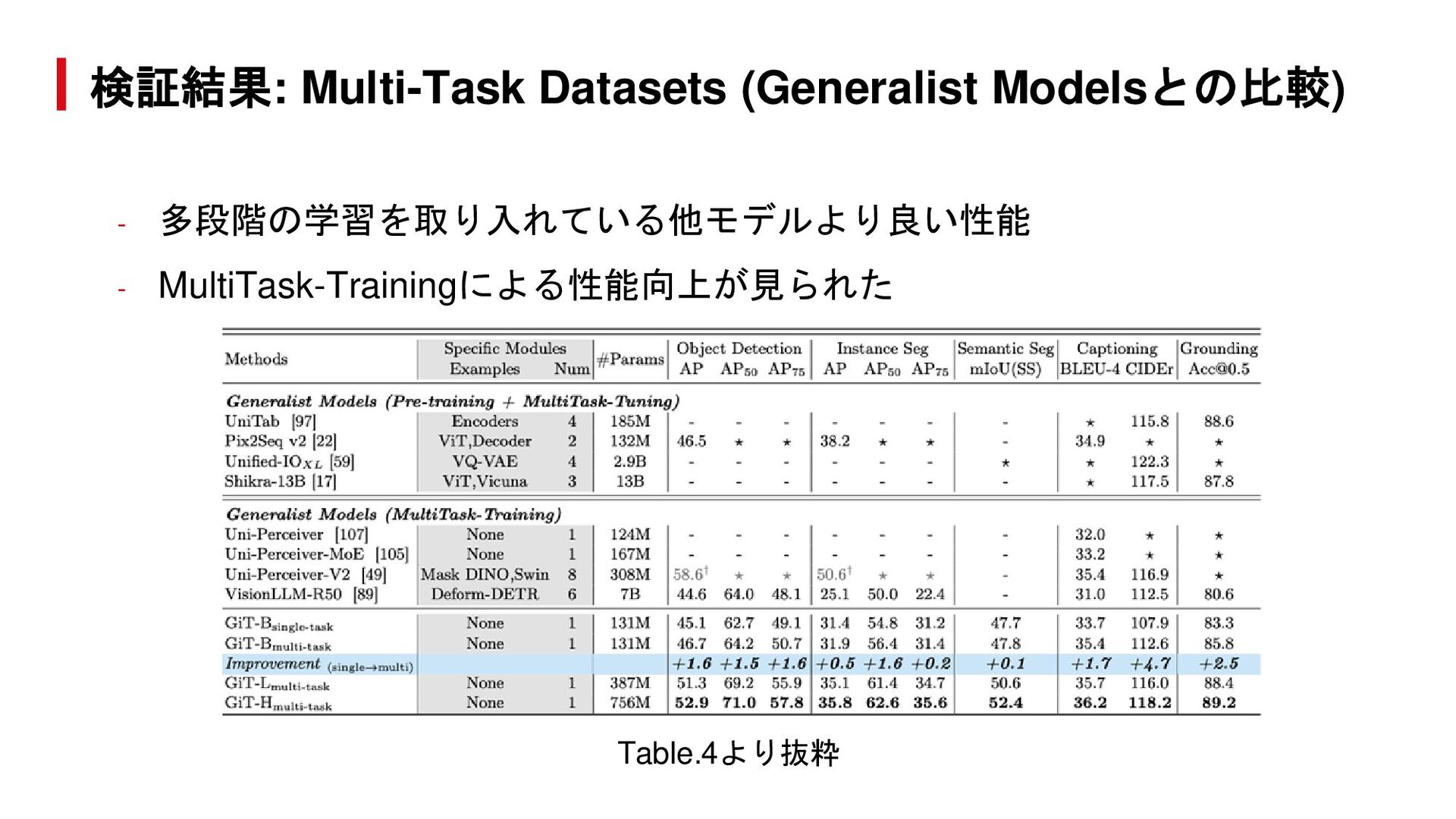{kind=link}
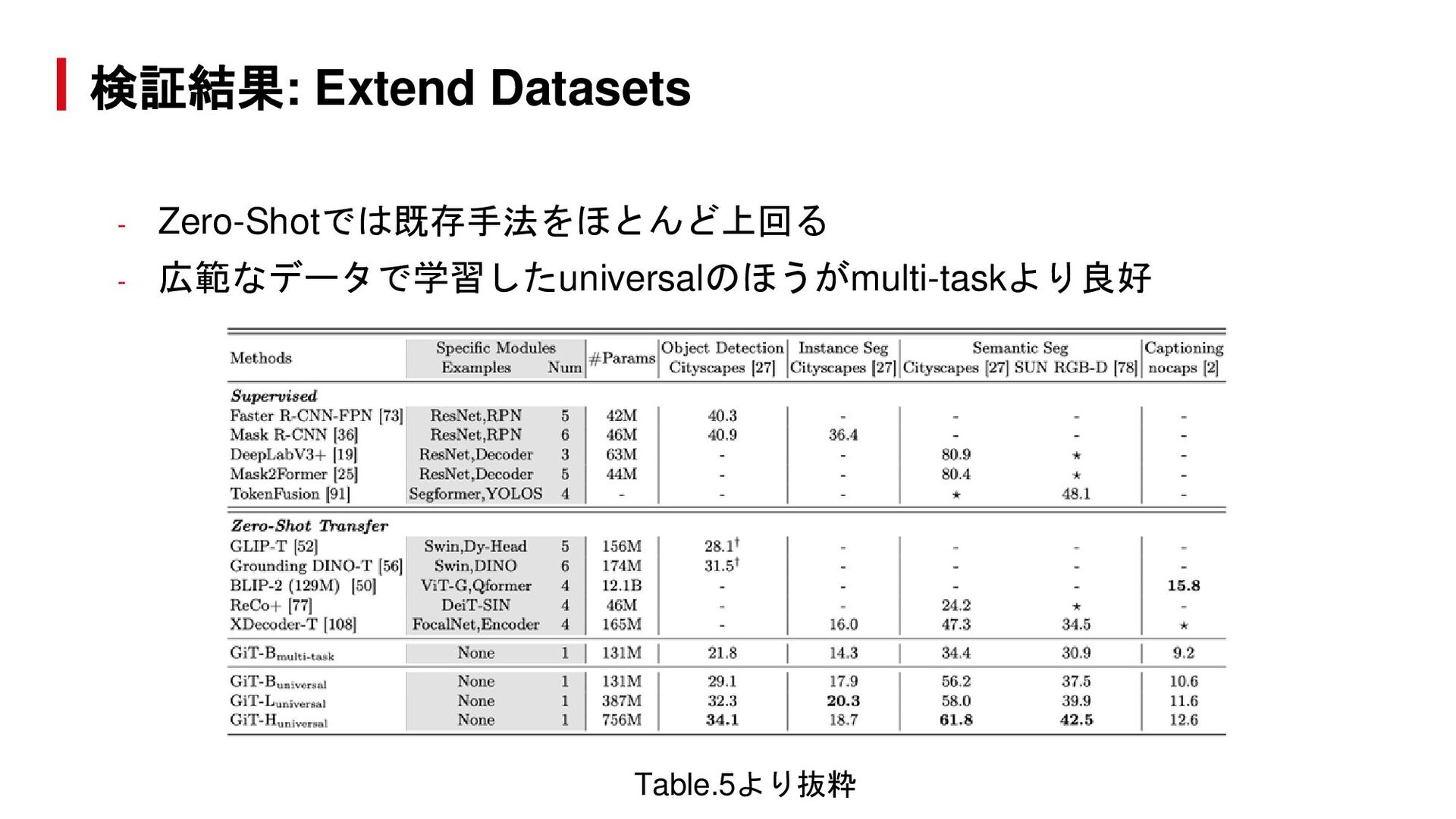{kind=link}
{kind=link}
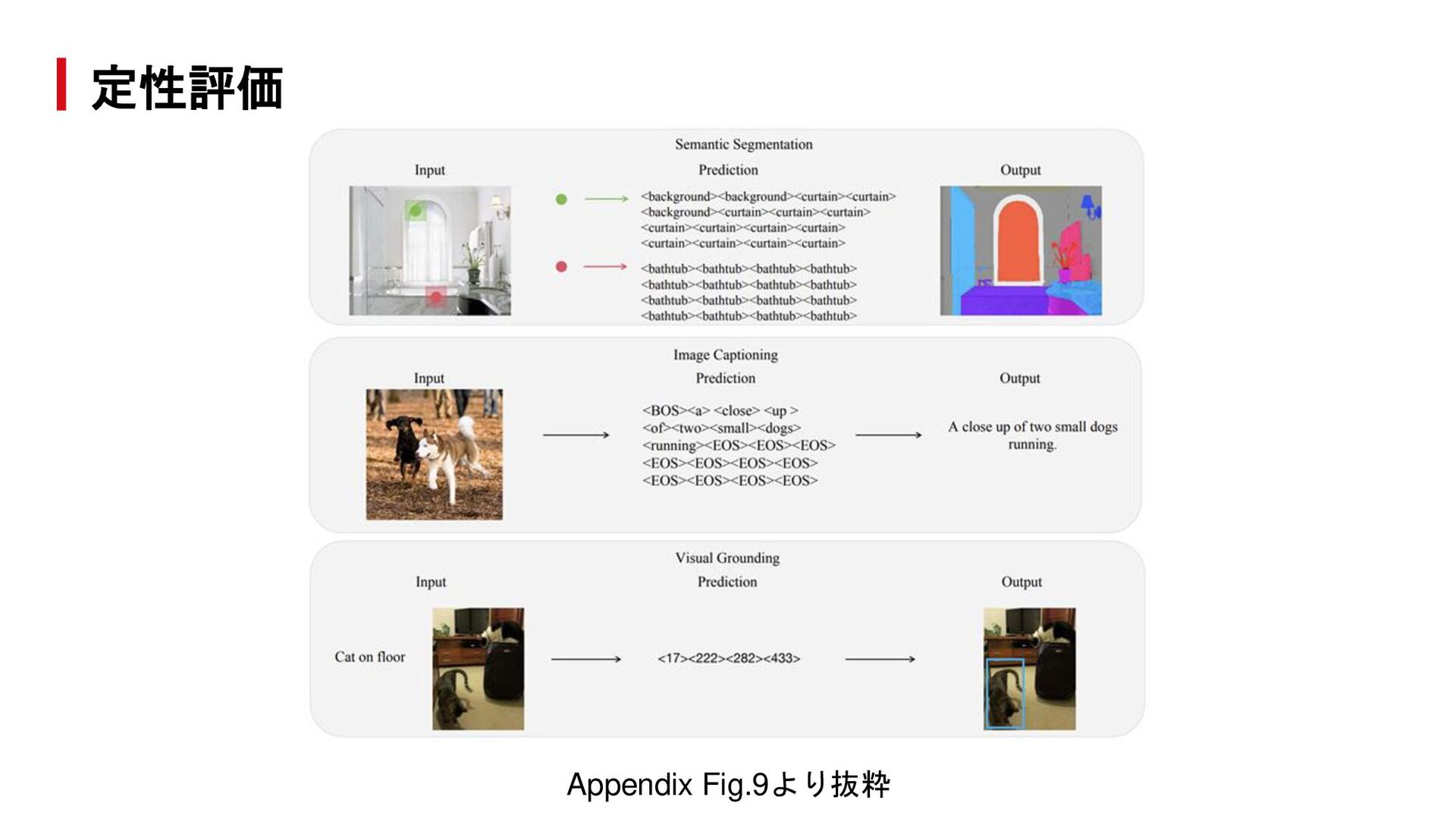{kind=link}
![課題 - 一般に複数のタスクを並行で扱うのは難しい - アーキテクチャ・学習の複雑化 手法 - ViT [Dosovitskiy+ 2021]](https://files.speakerdeck.com/presentations/f962fc1ed7794496b8c9e1c1d97fde0c/slide_23.jpg){kind=link}
![[Wang+ 2025] H. Wang, H. Tang, L. Jiang, S. Shi,](https://files.speakerdeck.com/presentations/f962fc1ed7794496b8c9e1c1d97fde0c/slide_24.jpg){kind=link}
{kind=link}