Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ICCV2025論文紹介:FlowEdit
Search
hinako0123
December 14, 2025
170
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ICCV2025論文紹介:FlowEdit
hinako0123
December 14, 2025
More Decks by hinako0123
See All by hinako0123
CVPR2026現地参加報告
hinako0123
0
130
CVPR2026論文紹介:Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
hinako0123
0
130
ICCV2025現地参加報告
hinako0123
0
190
ICCV2025論文紹介:SAM2Long
hinako0123
0
200
ECCV2024現地参加報告
hinako0123
0
32
CVPR2025現地参加報告
hinako0123
0
160
CVPR2025論文紹介:動画像分類
hinako0123
0
110
CVPR2025論文紹介:Segmentation
hinako0123
0
200
ECCV2024論文紹介:Vision & Language
hinako0123
0
170
Featured
See All Featured
Accessibility Awareness
sabderemane
1
150
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
330
Documentation Writing (for coders)
carmenintech
77
5.4k
Unsuck your backbone
ammeep
672
58k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.6k
The SEO identity crisis: Don't let AI make you average
varn
0
510
It's Worth the Effort
3n
188
29k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
310
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Building AI with AI
inesmontani
PRO
1
1.1k
Transcript
ICCV2025 Best student paper FlowEdit: Inversion-Free Text-Based Editing Using Pre-Trained
Flow Models 中京大学 工学研究科 橋本研究室 村上 尚生 CV勉強会 Dec. 13, 2025 Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, Tomer Michaeli
テキストベースで画像を編集 やりたいこと
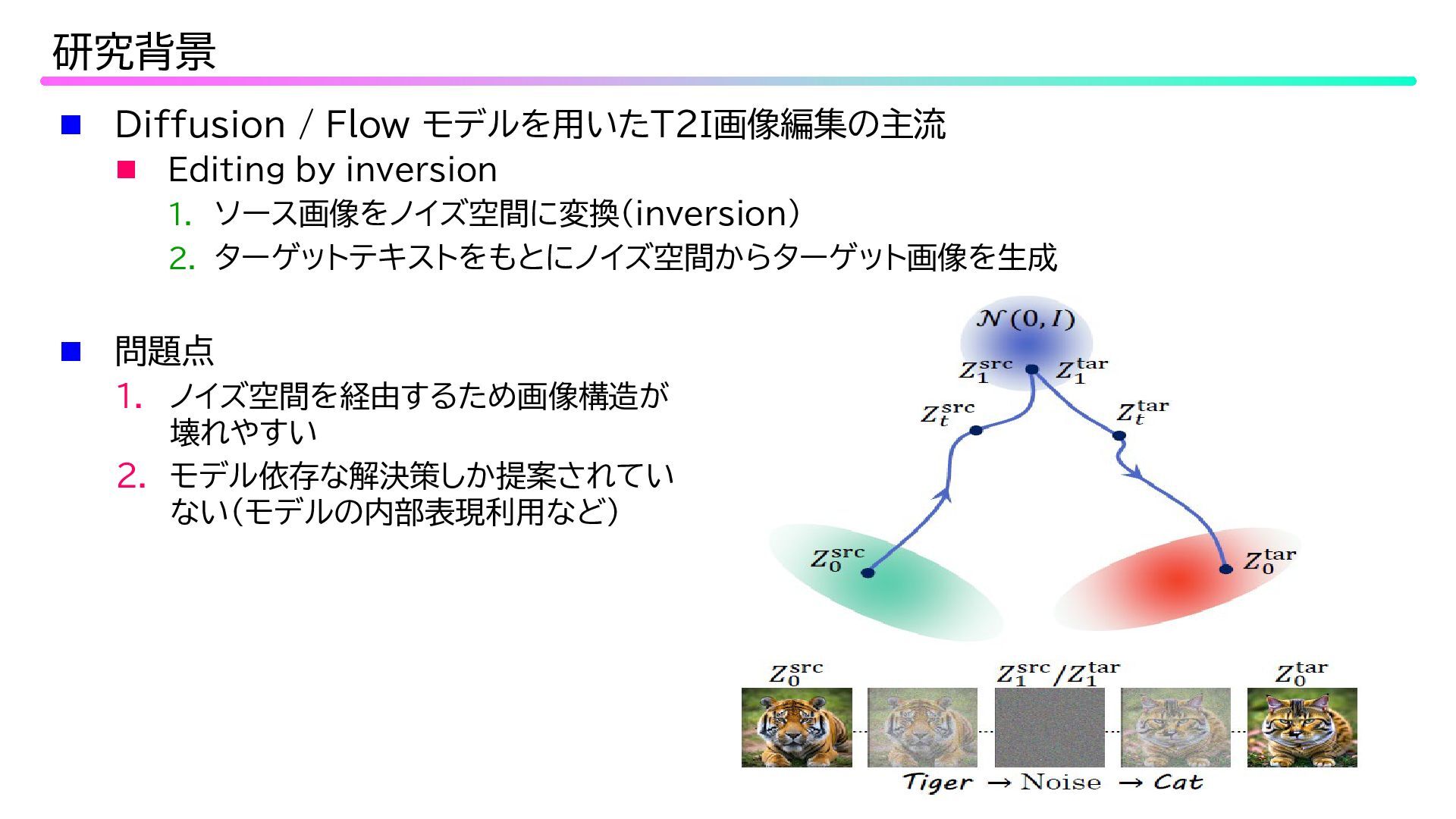
Diffusion / Flow モデルを用いたT2I画像編集の主流 Editing by inversion 1.
ソース画像をノイズ空間に変換(inversion) 2. ターゲットテキストをもとにノイズ空間からターゲット画像を生成 研究背景 問題点 1. ノイズ空間を経由するため画像構造が 壊れやすい 2. モデル依存な解決策しか提案されてい ない(モデルの内部表現利用など)
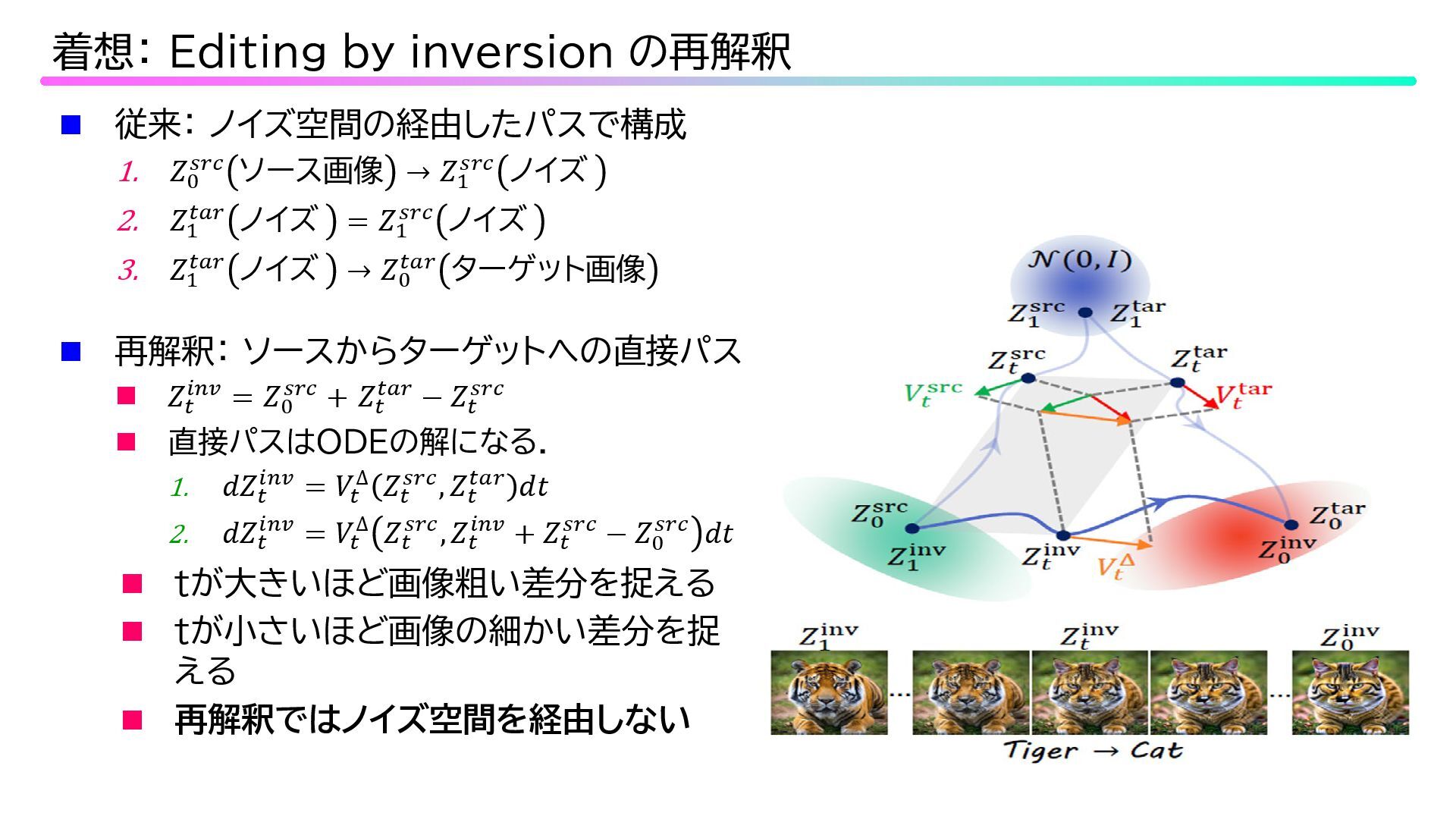
従来: ノイズ空間の経由したパスで構成 1. 𝑍𝑍0 𝑠𝑠𝑠𝑠𝑠𝑠 ソース画像 → 𝑍𝑍1 𝑠𝑠𝑠𝑠𝑠𝑠
ノイズ 2. 𝑍𝑍1 𝑡𝑡𝑡𝑡𝑡𝑡 ノイズ = 𝑍𝑍1 𝑠𝑠𝑠𝑠𝑠𝑠 ノイズ 3. 𝑍𝑍1 𝑡𝑡𝑡𝑡𝑡𝑡 ノイズ → 𝑍𝑍0 𝑡𝑡𝑡𝑡𝑡𝑡 ターゲット画像 着想: Editing by inversion の再解釈 再解釈: ソースからターゲットへの直接パス 𝑍𝑍𝑡𝑡 𝑖𝑖𝑖𝑖𝑖𝑖 = 𝑍𝑍0 𝑠𝑠𝑠𝑠𝑠𝑠 + 𝑍𝑍𝑡𝑡 𝑡𝑡𝑡𝑡𝑡𝑡 − 𝑍𝑍𝑡𝑡 𝑠𝑠𝑠𝑠𝑠𝑠 直接パスはODEの解になる. 1. 𝑑𝑑𝑍𝑍𝑡𝑡 𝑖𝑖𝑖𝑖𝑖𝑖 = 𝑉𝑉𝑡𝑡 ∆ 𝑍𝑍𝑡𝑡 𝑠𝑠𝑠𝑠𝑠𝑠, 𝑍𝑍𝑡𝑡 𝑡𝑡𝑡𝑡𝑡𝑡 𝑑𝑑𝑑𝑑 2. 𝑑𝑑𝑑𝑑𝑡𝑡 𝑖𝑖𝑖𝑖𝑖𝑖 = 𝑉𝑉𝑡𝑡 ∆ 𝑍𝑍𝑡𝑡 𝑠𝑠𝑠𝑠𝑠𝑠, 𝑍𝑍𝑡𝑡 𝑖𝑖𝑖𝑖𝑖𝑖 + 𝑍𝑍𝑡𝑡 𝑠𝑠𝑠𝑠𝑠𝑠 − 𝑍𝑍0 𝑠𝑠𝑠𝑠𝑠𝑠 𝑑𝑑𝑑𝑑 tが大きいほど画像粗い差分を捉える tが小さいほど画像の細かい差分を捉 える 再解釈ではノイズ空間を経由しない
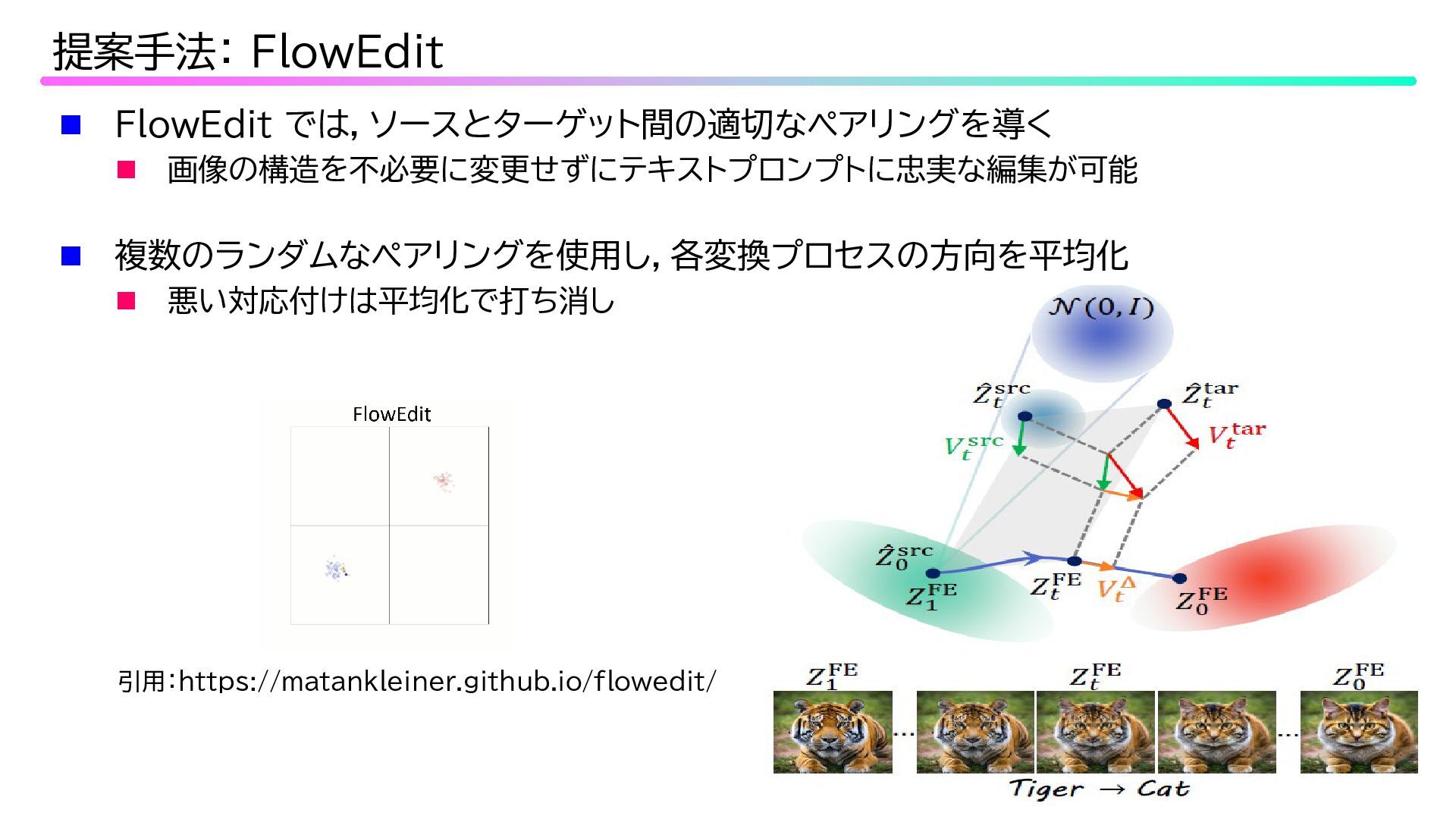
Inversion 利用の問題点 ソース分布の各モードがターゲット分布のモードに適切に対応付けされない 引用:https://matankleiner.github.io/flowedit/
FlowEdit では,ソースとターゲット間の適切なペアリングを導く 画像の構造を不必要に変更せずにテキストプロンプトに忠実な編集が可能 提案手法: FlowEdit 複数のランダムなペアリングを使用し,各変換プロセスの方向を平均化
悪い対応付けは平均化で打ち消し 引用:https://matankleiner.github.io/flowedit/
テキストで指定した領域のみ変更して,元の画像構造が維持されている. 実験結果①: FlowEditの結果
SD3とFLUXの両方で,FlowEditはターゲットプロンプトを忠実に反映している. 背景などの画像構造も最もよく維持されている. 実験結果②: その他の画像編集方法との比較
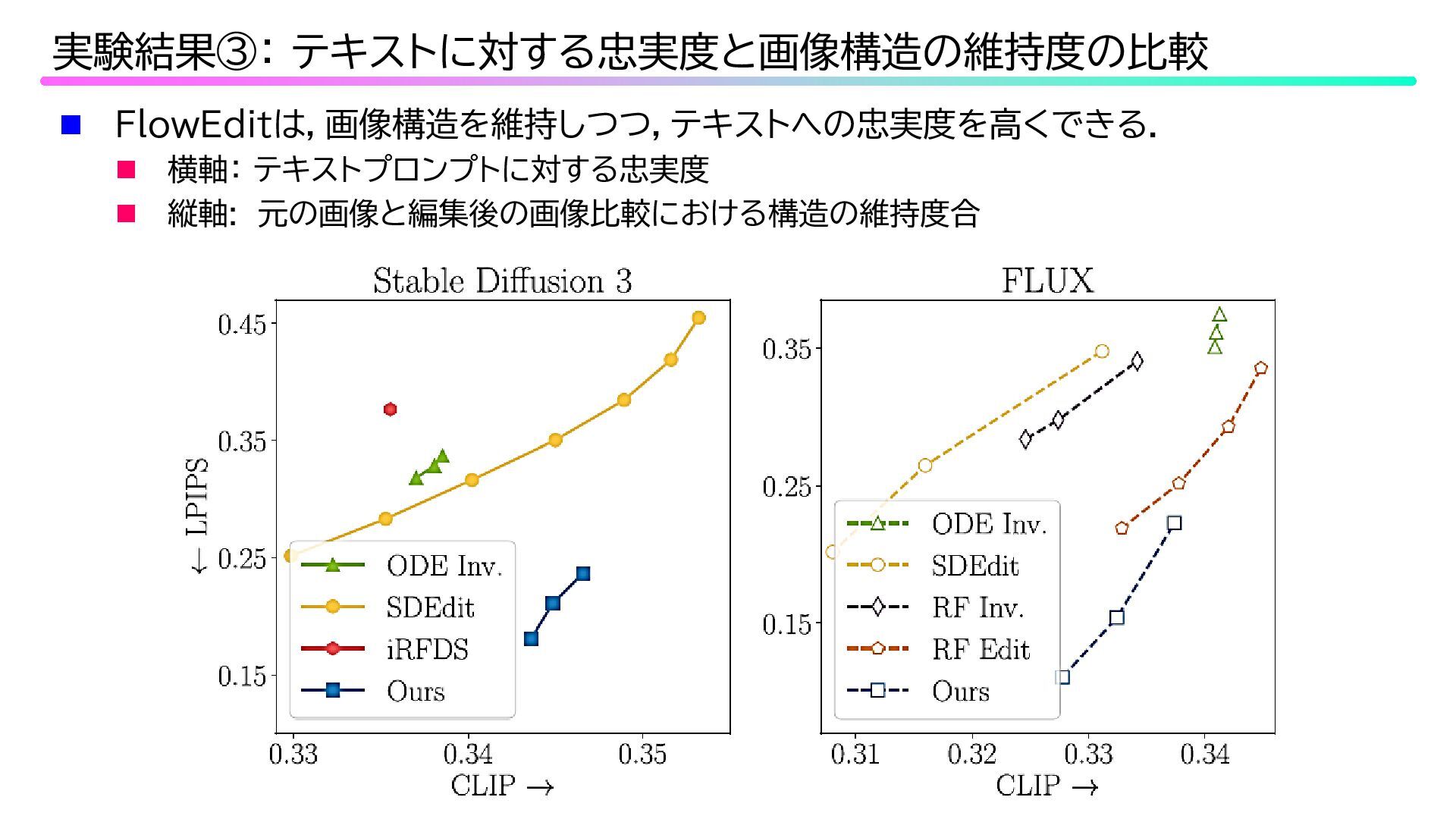
FlowEditは,画像構造を維持しつつ,テキストへの忠実度を高くできる. 横軸: テキストプロンプトに対する忠実度 縦軸: 元の画像と編集後の画像比較における構造の維持度合 実験結果③: テキストに対する忠実度と画像構造の維持度の比較
FlowEditとは Inversion-free / Model-agnosticな画像編集手法 Source→Target 分布を 直接ODEで輸送
ガウシアンノイズ分布を経由しないため,輸送コストが小さく,画像構造の保存性が高い Stable Diffusion 3 や FLUX に適用した場合,SoTA編集品質を達成 Limitation 画像構造を極力壊さないという設計思想のため大規模な画像編集が苦手 背景の全面変更(右図参照) 対象のポーズ変更 カメラ視点の大きな移動など 結論
Thank you for your attention!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}