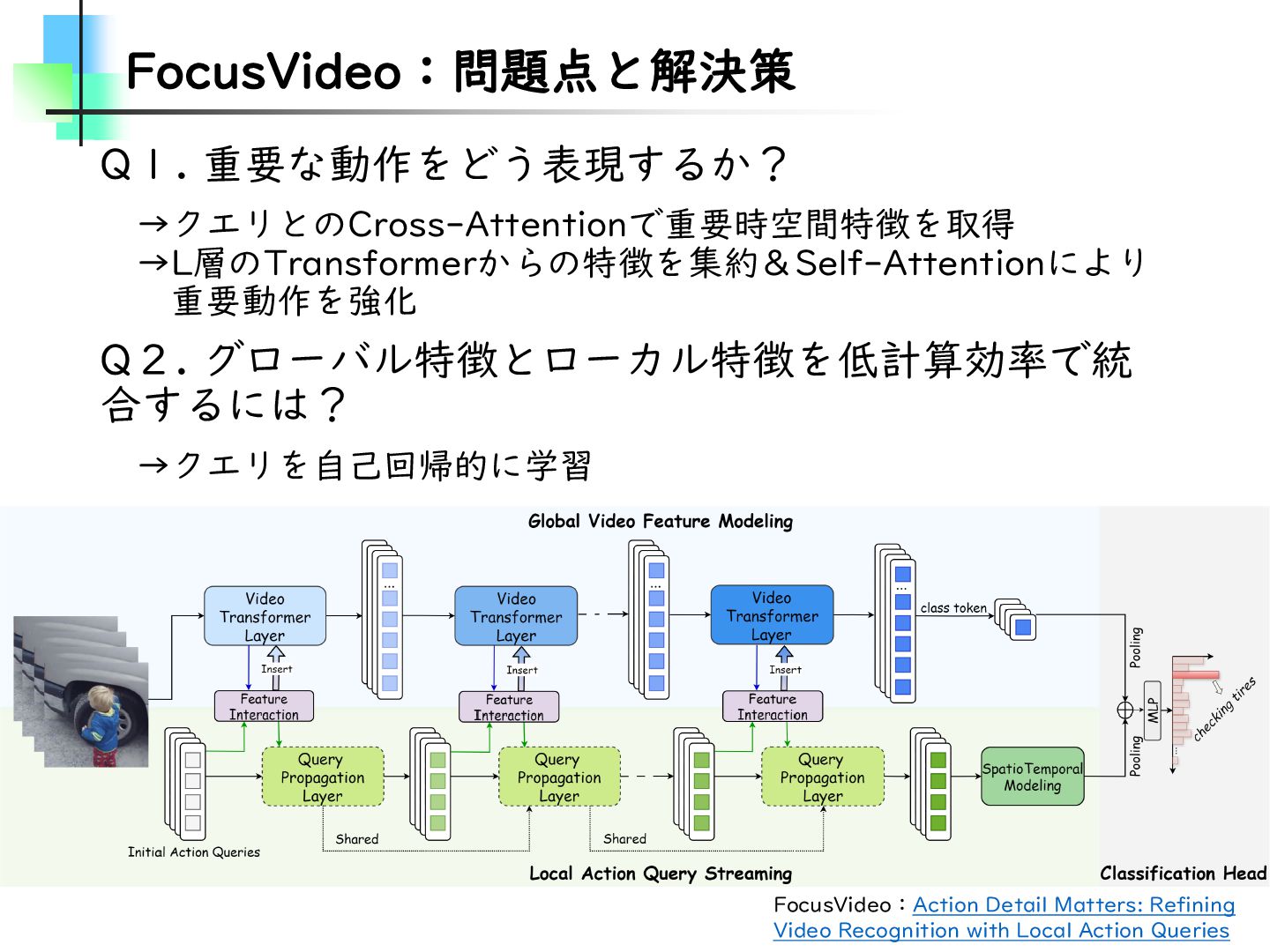
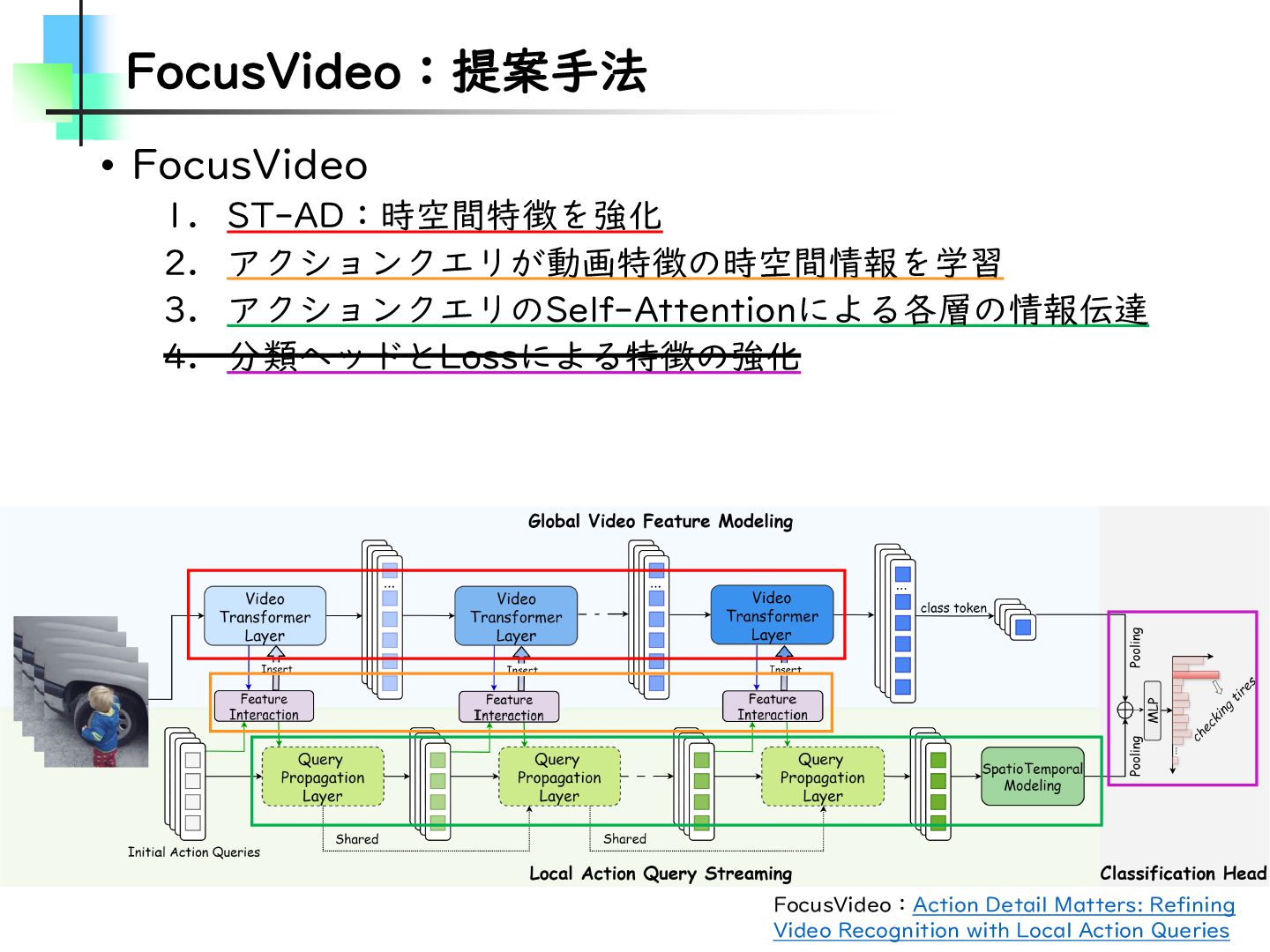
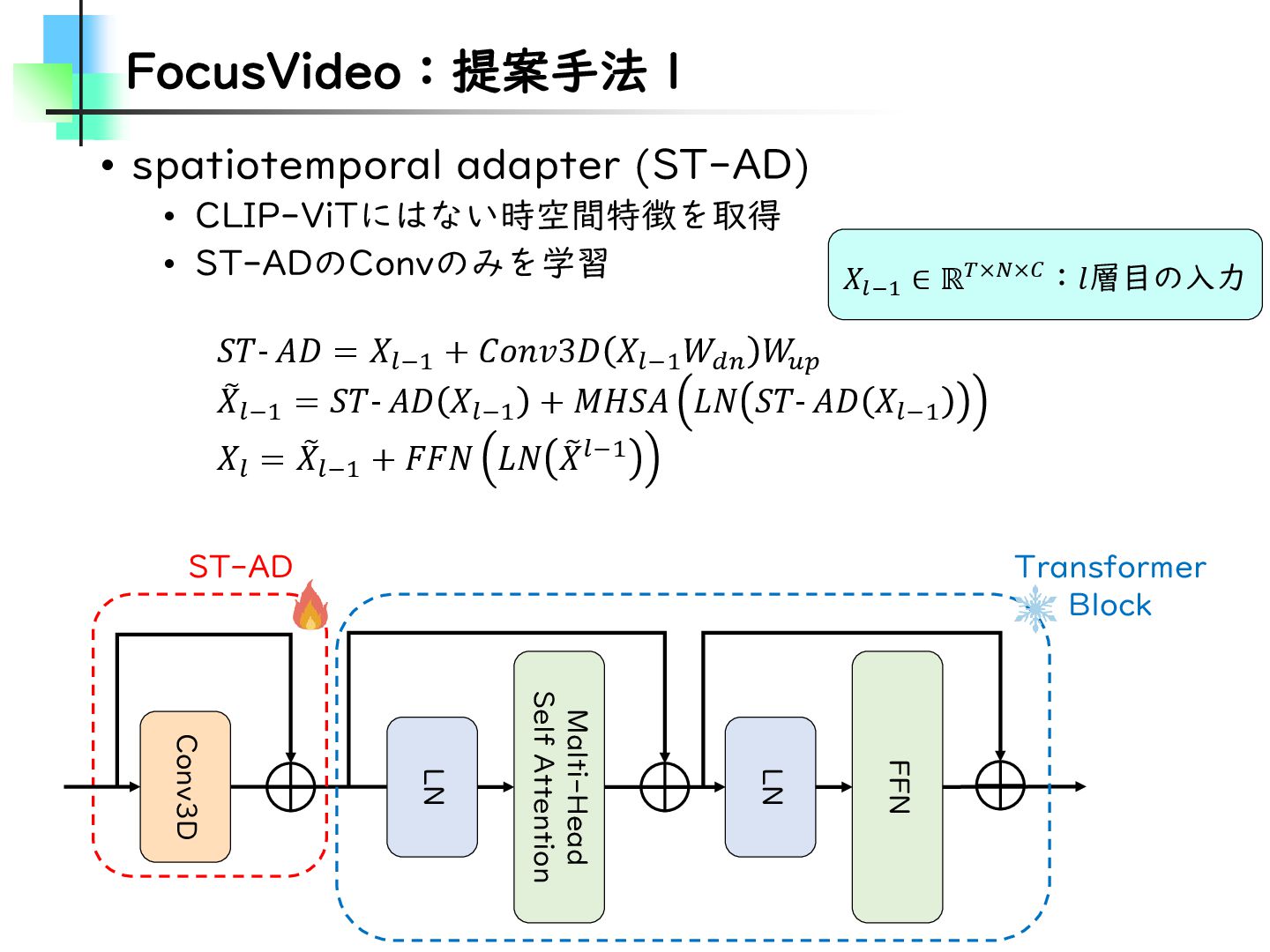
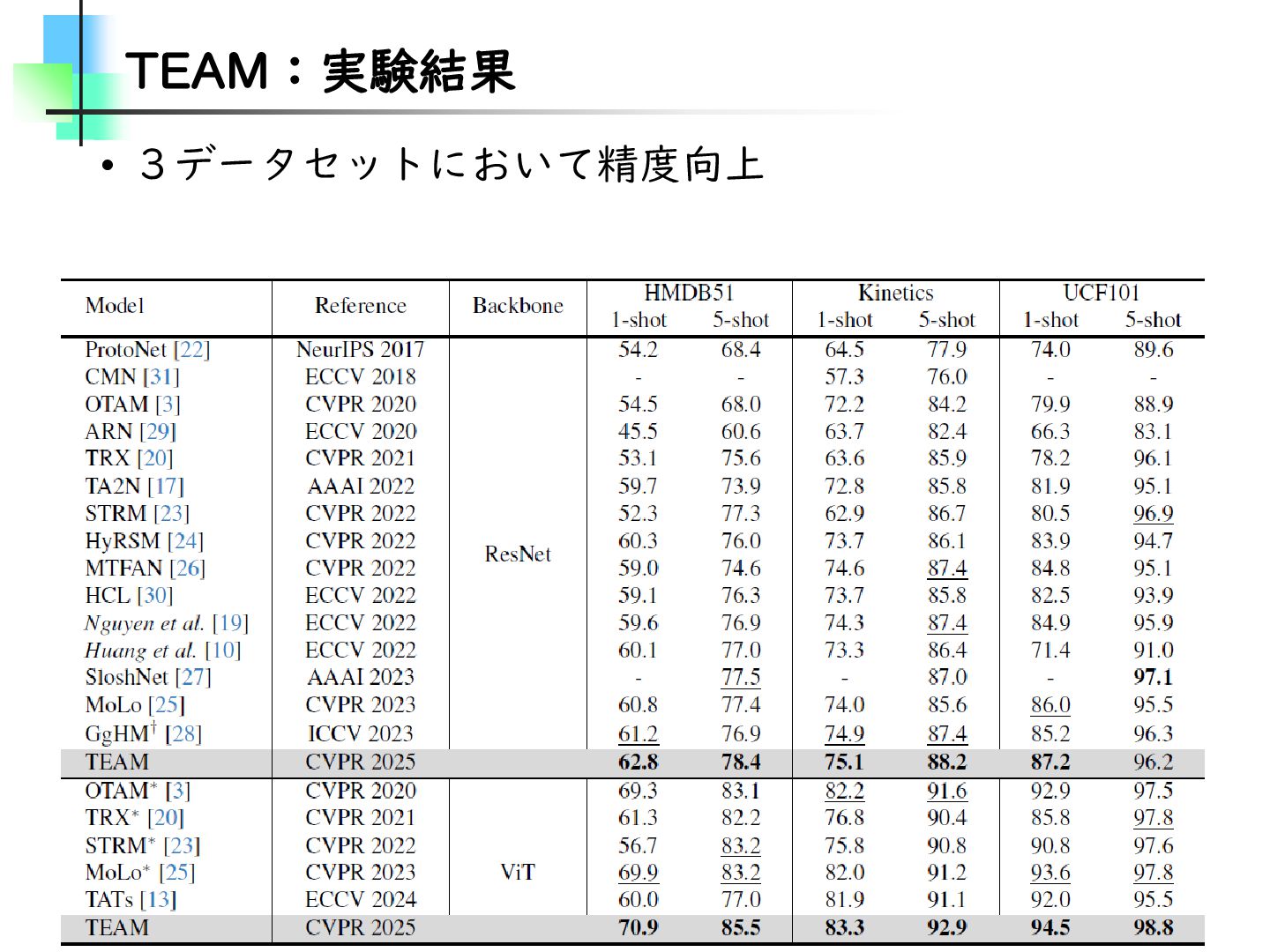
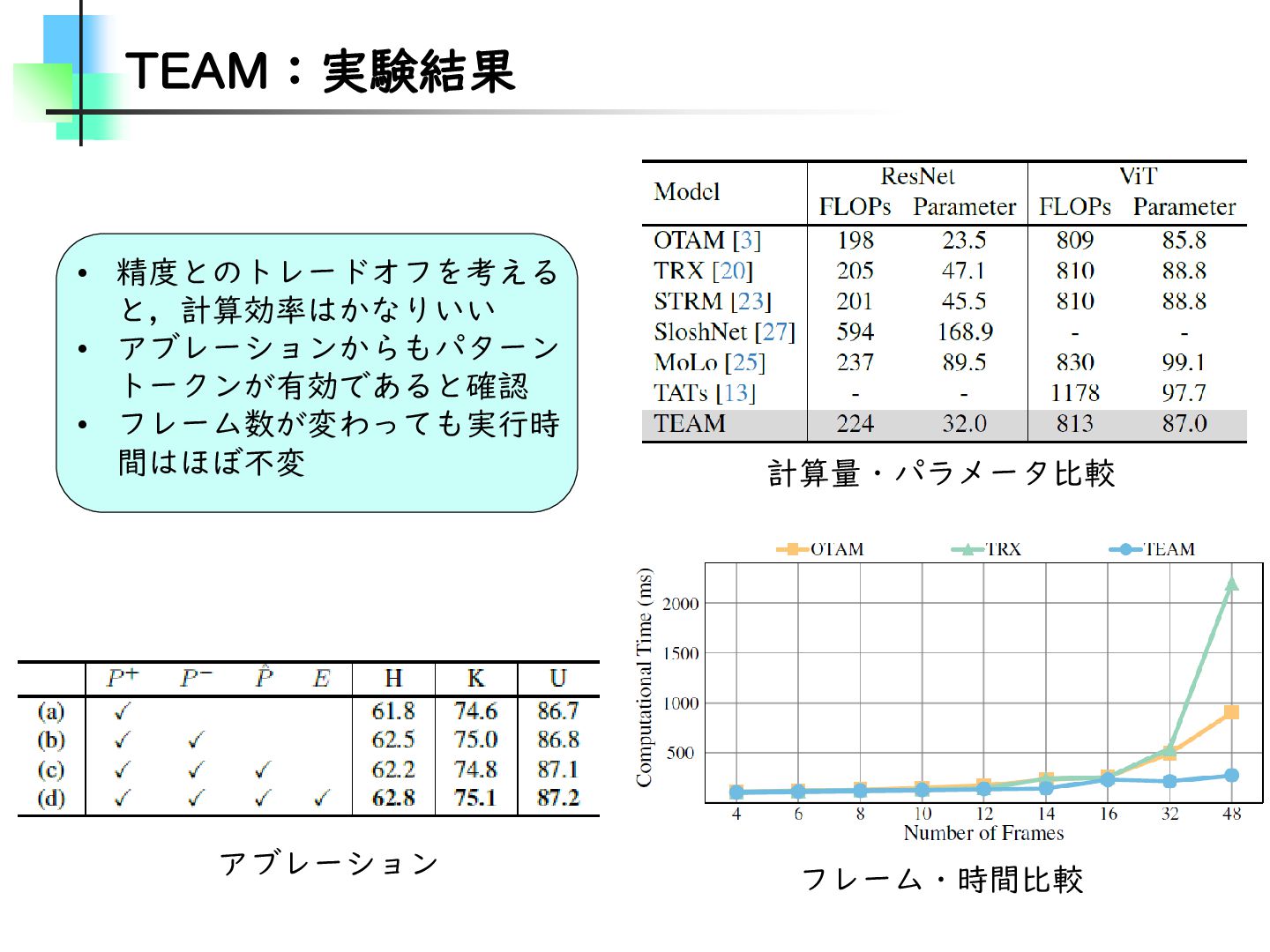
Refining Video Recognition with Local Action Queries • 以降、FocusVideo • Few-Shot Action Recognition • Temporal Alignment-Free Video Matching for Few-shot Action Recognition
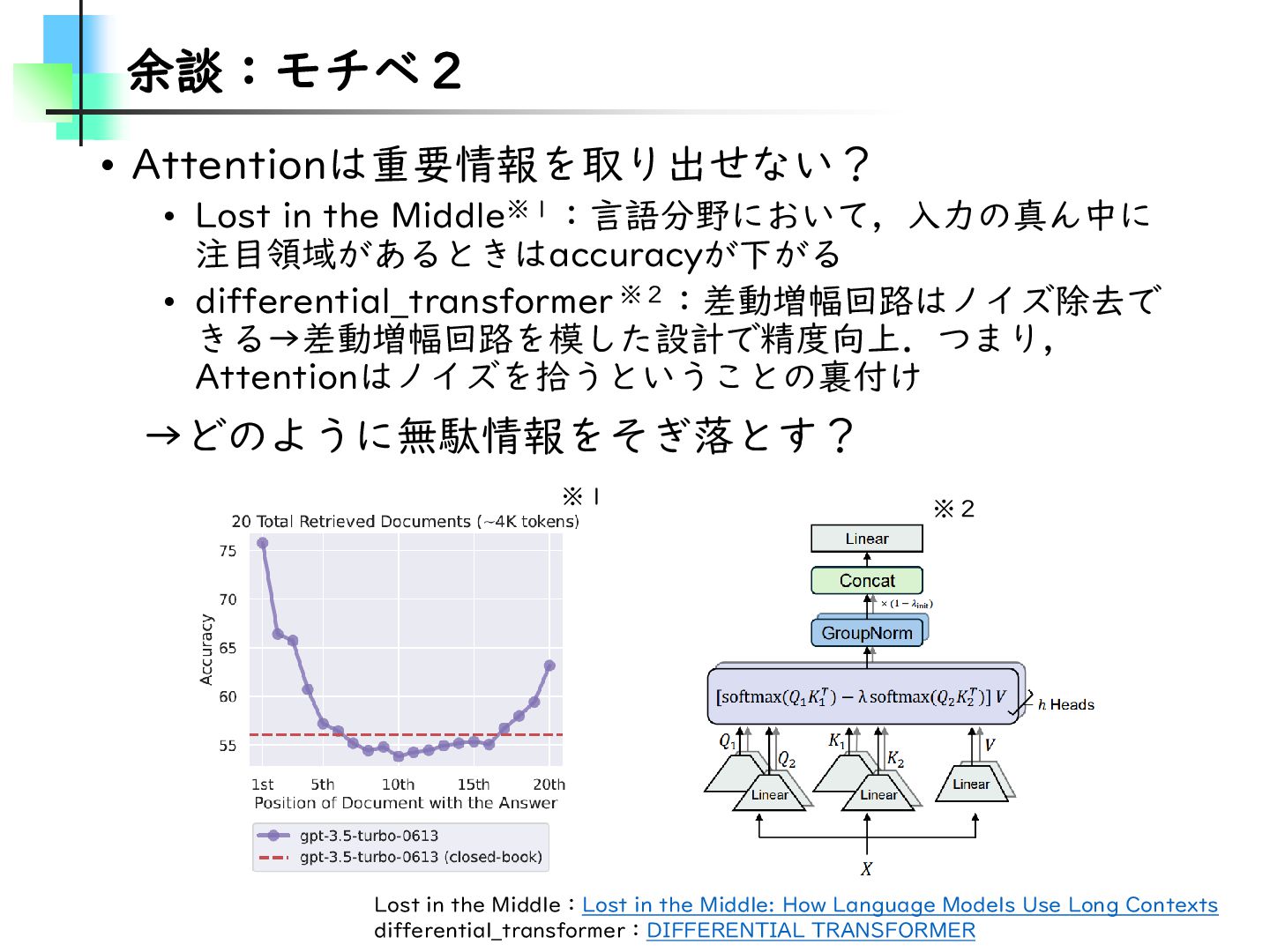
differential_transformer ※2:差動増幅回路はノイズ除去で きる→差動増幅回路を模した設計で精度向上.つまり, Attentionはノイズを拾うということの裏付け →どのように無駄情報をそぎ落とす? Lost in the Middle:Lost in the Middle: How Language Models Use Long Contexts differential_transformer:DIFFERENTIAL TRANSFORMER ※1 ※2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
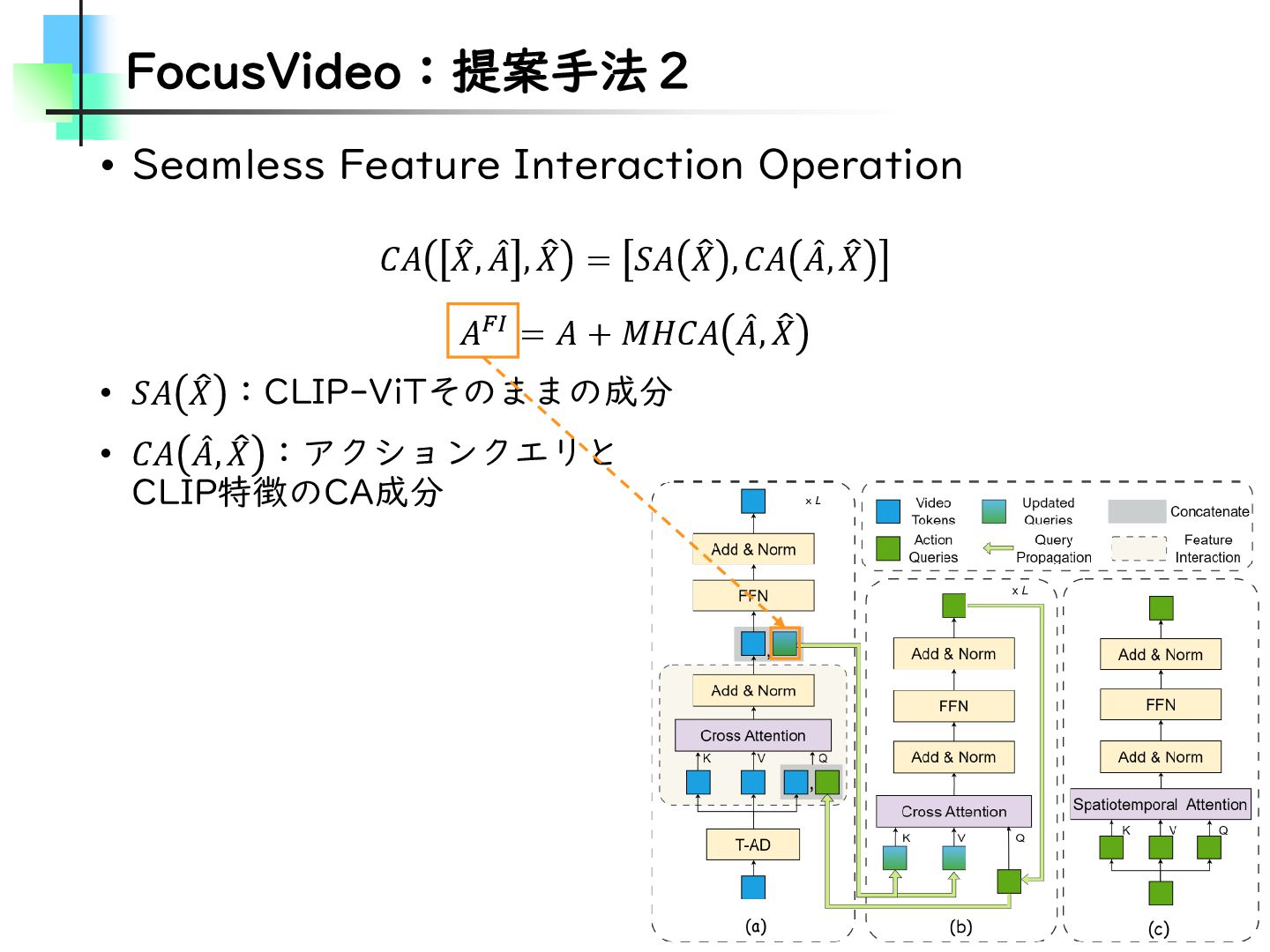{kind=link}
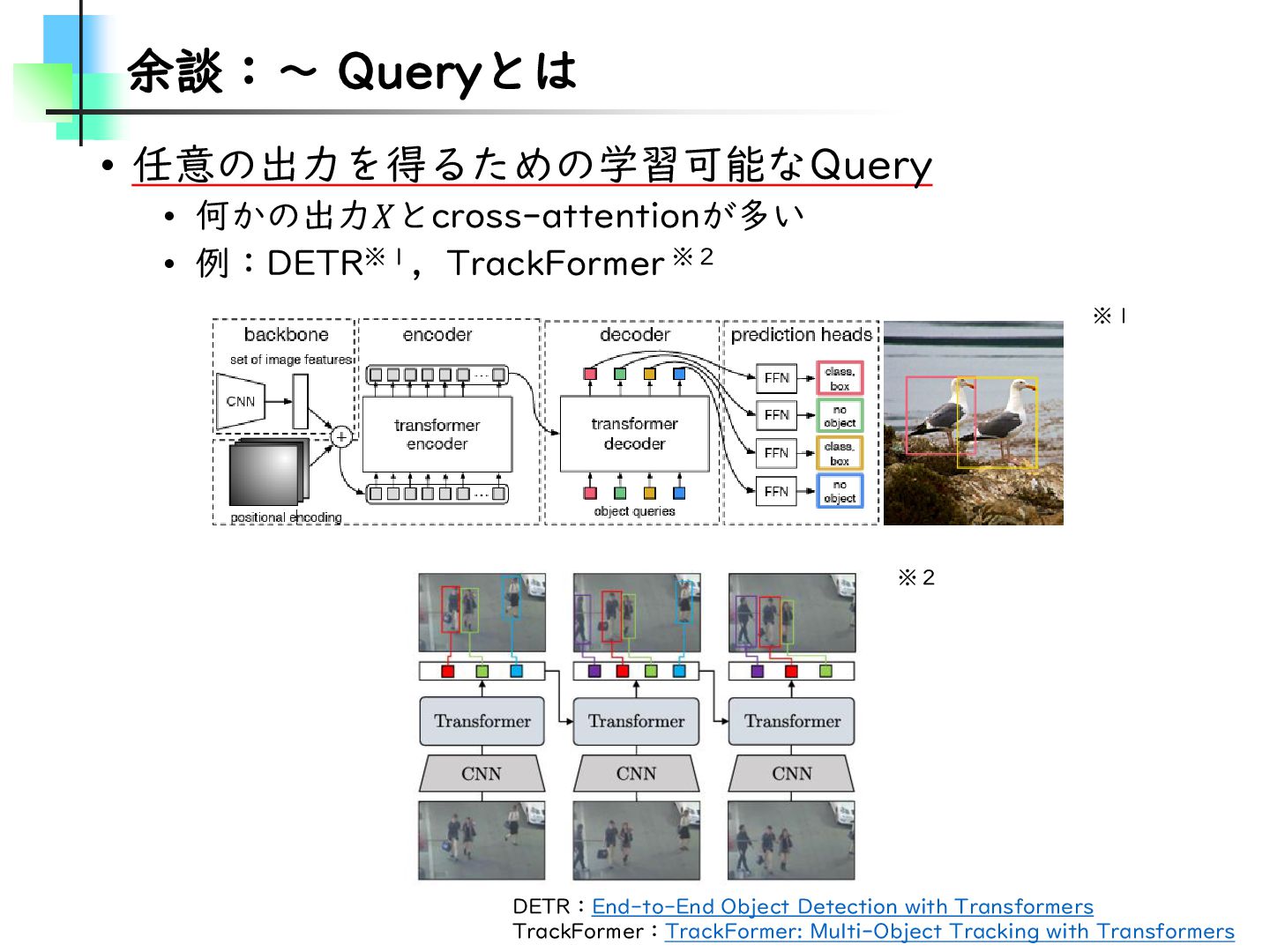{kind=link}
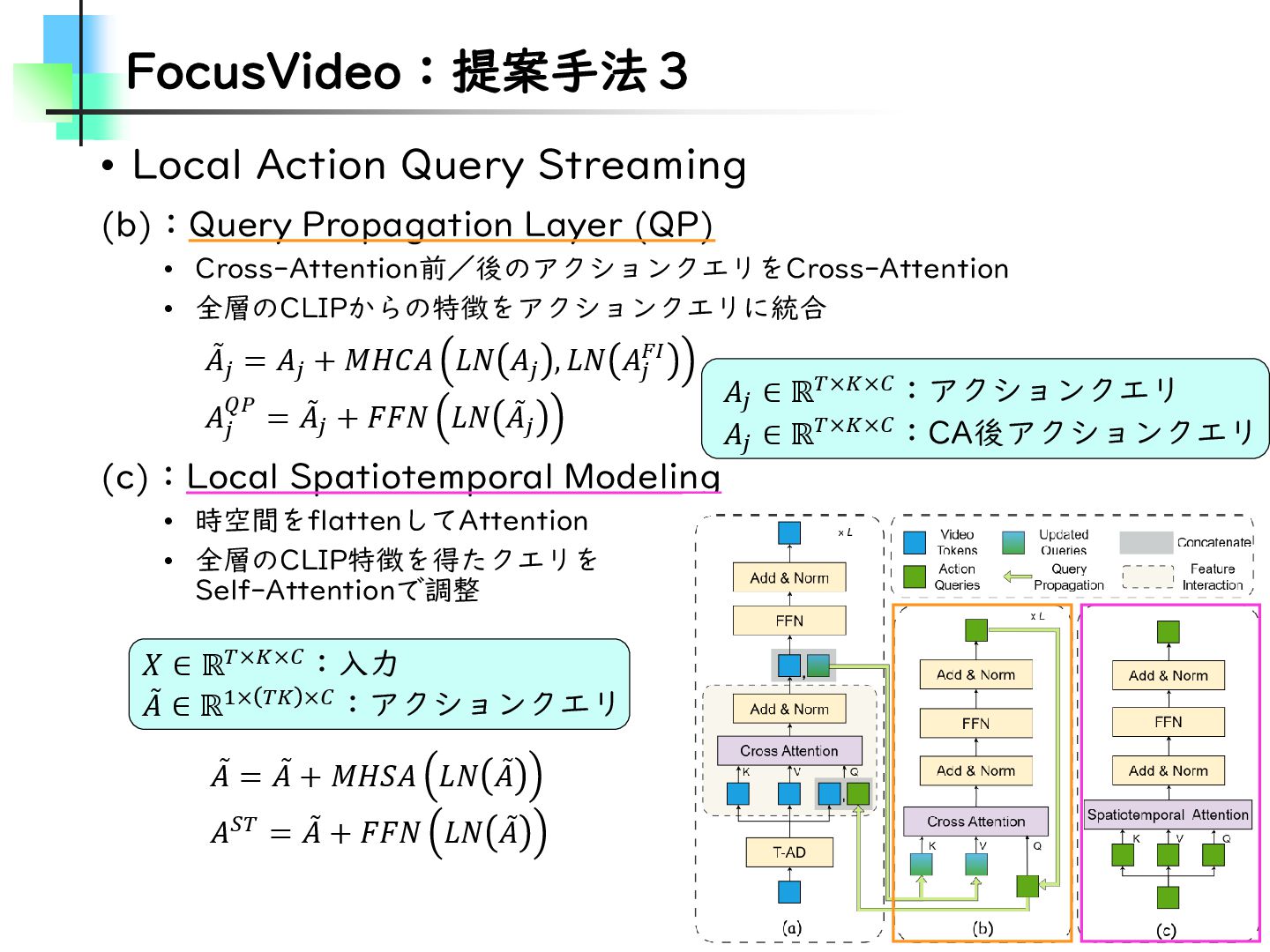{kind=link}
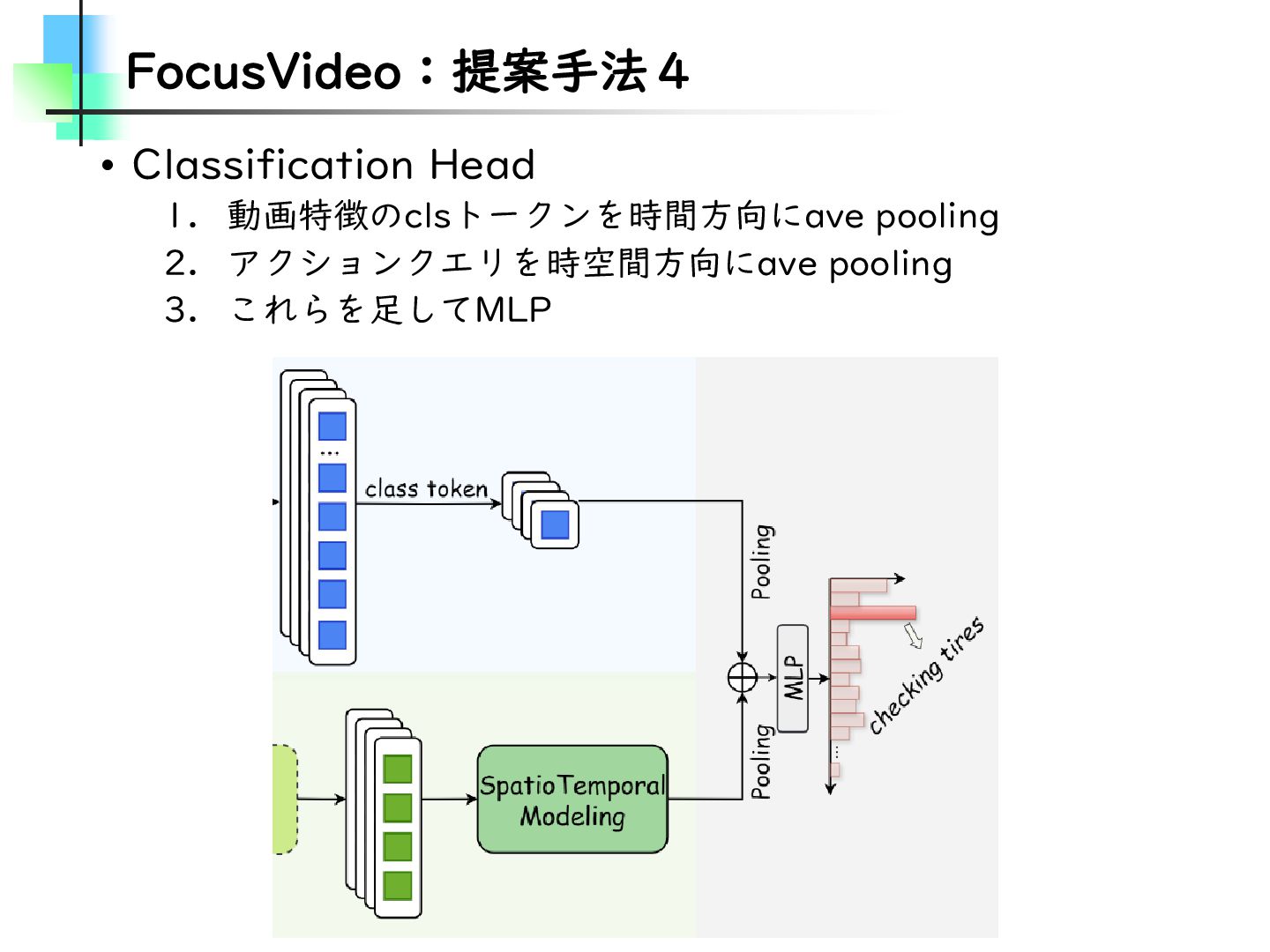{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}