This document provides an overview of visual speech recognition (VSR) and related research, with a particular focus on novel approaches using large language models (LLMs). Through demonstrations, we will introduce the specific performance and application examples of models such as VSP-LLM and Zero-AVSR, and discuss comparisons with conventional methods and challenges. We will also consider the current state of visual information recognition, including the difficulties in creating datasets and the reliance on conventional models.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
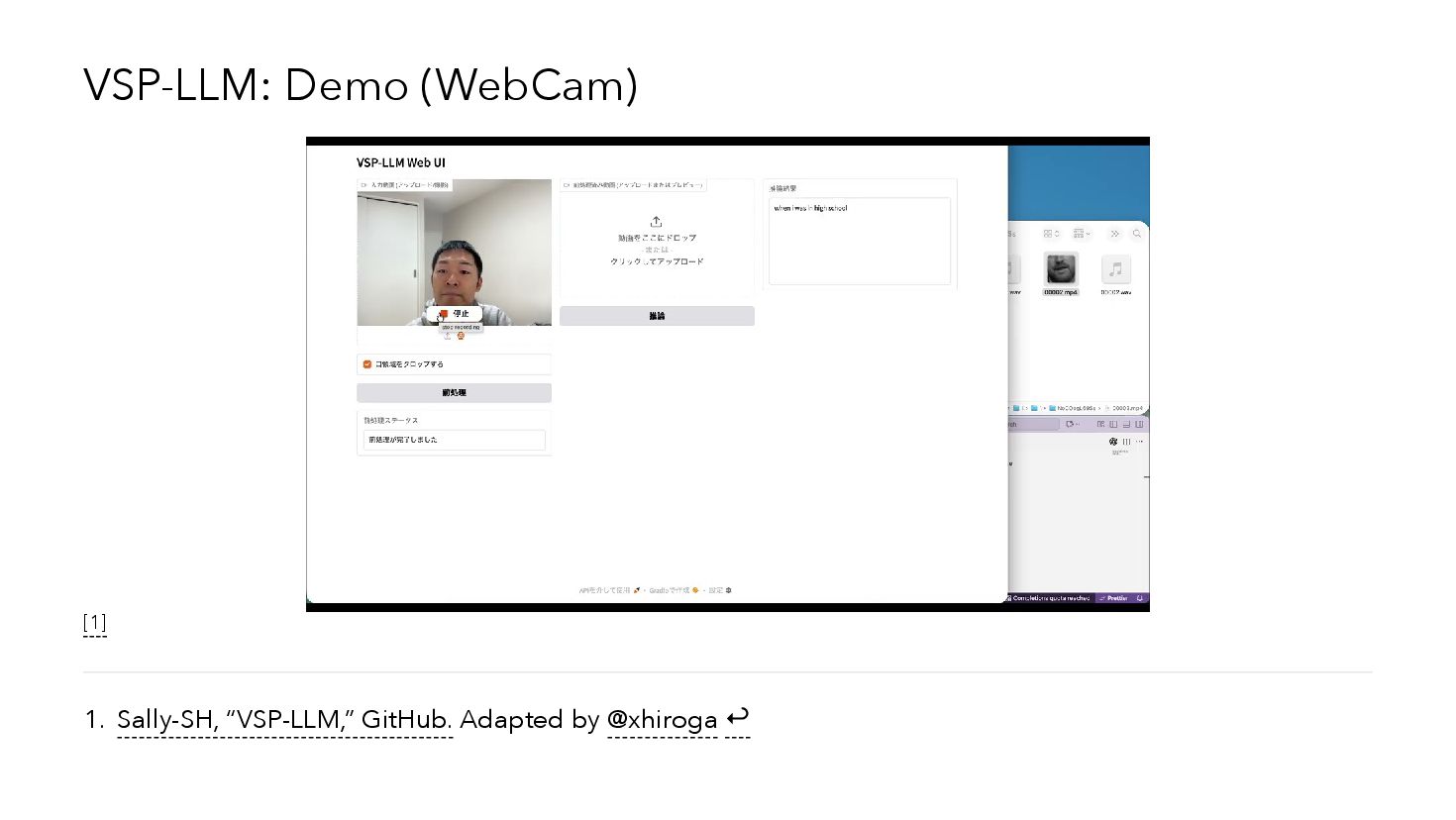{kind=link}
{kind=link}
{kind=link}
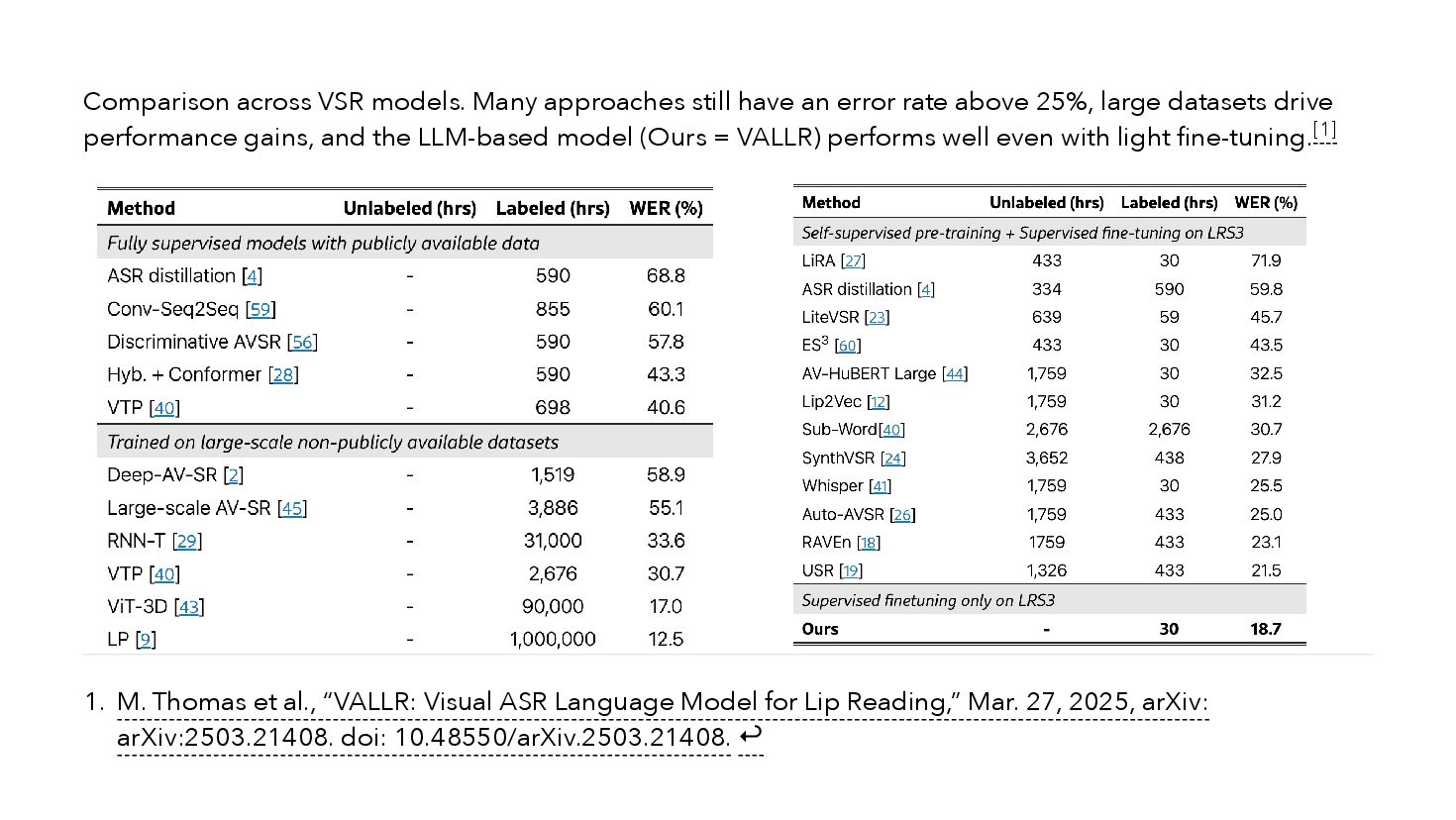{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
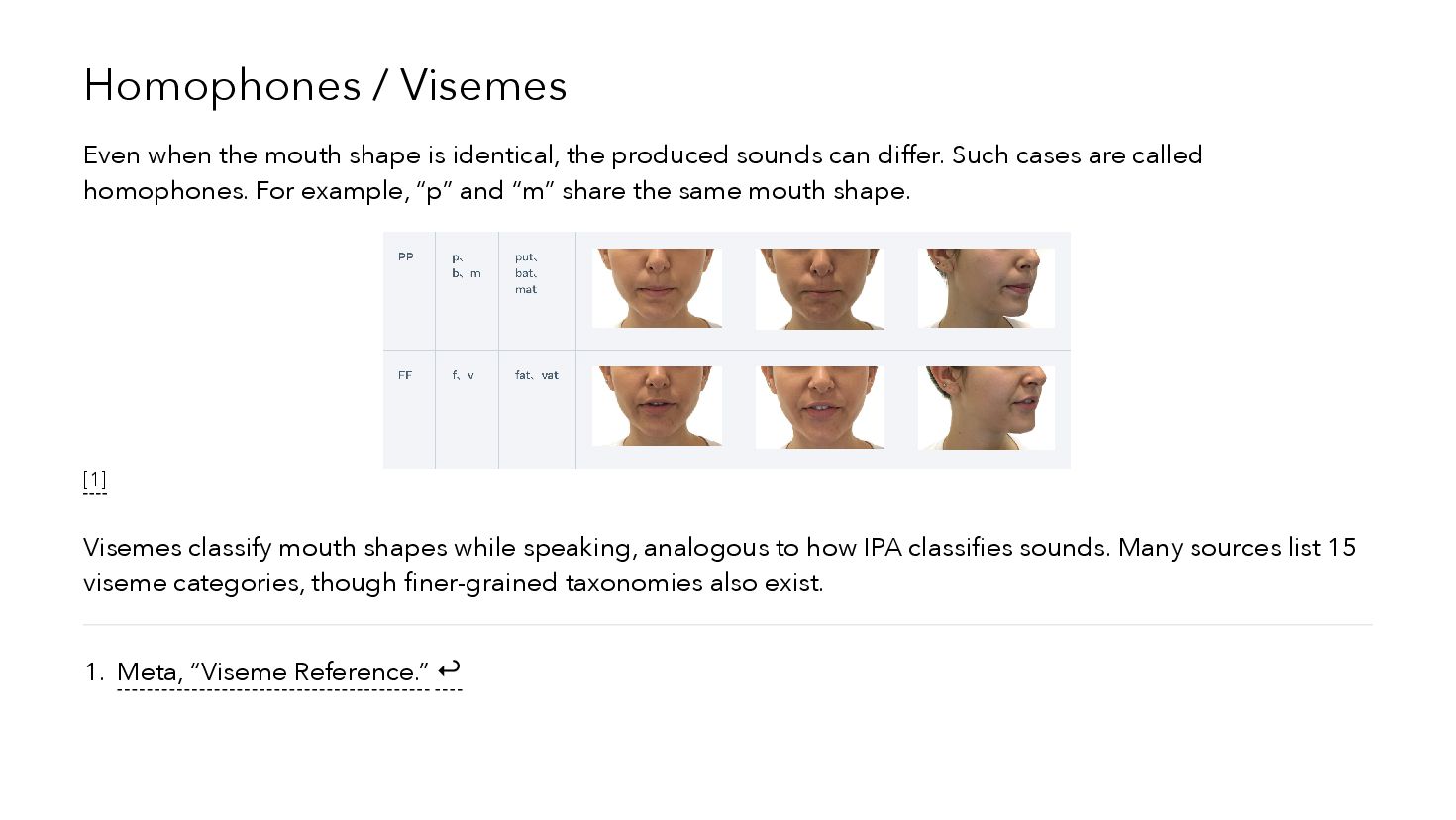{kind=link}
{kind=link}
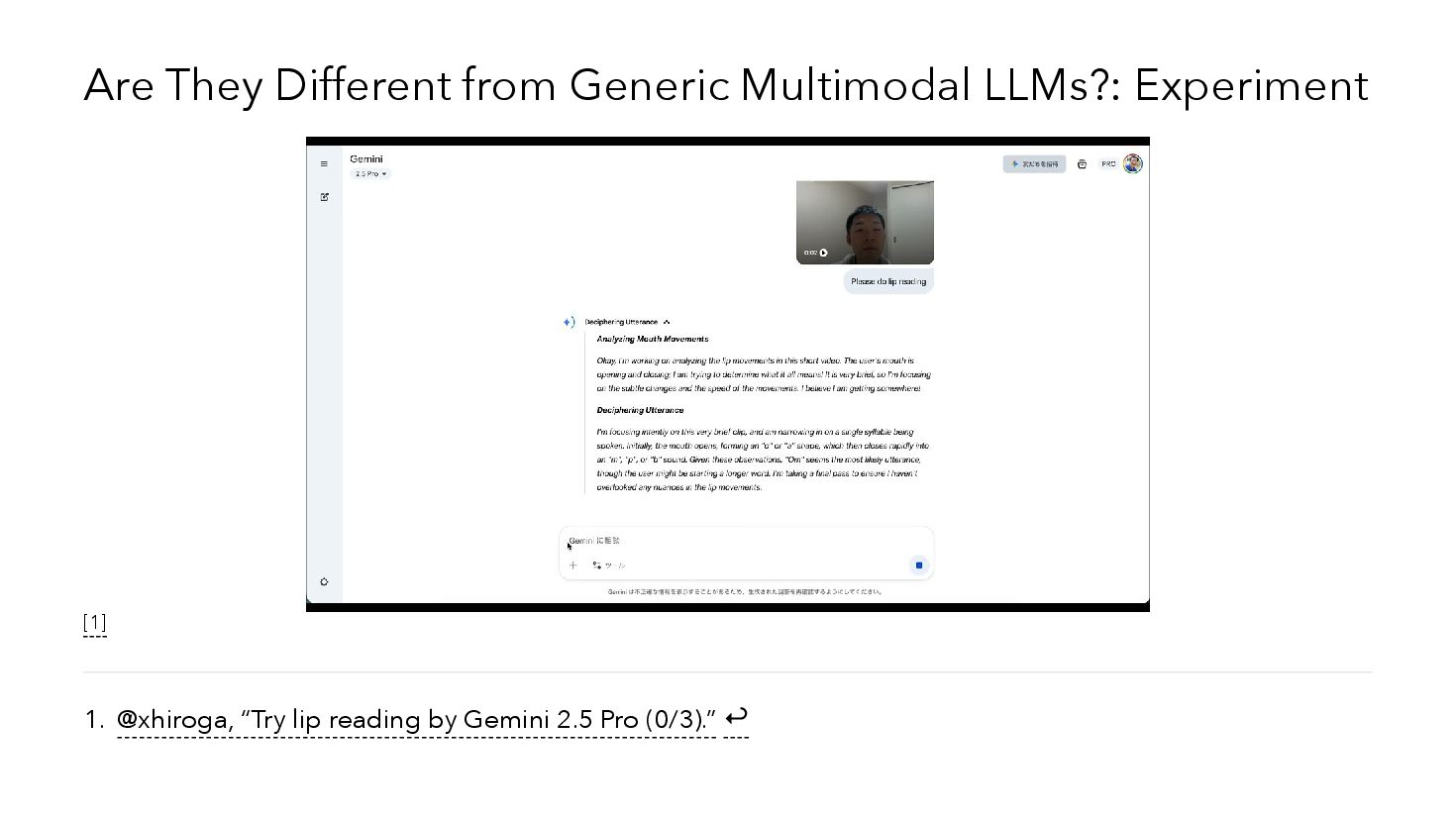{kind=link}
{kind=link}
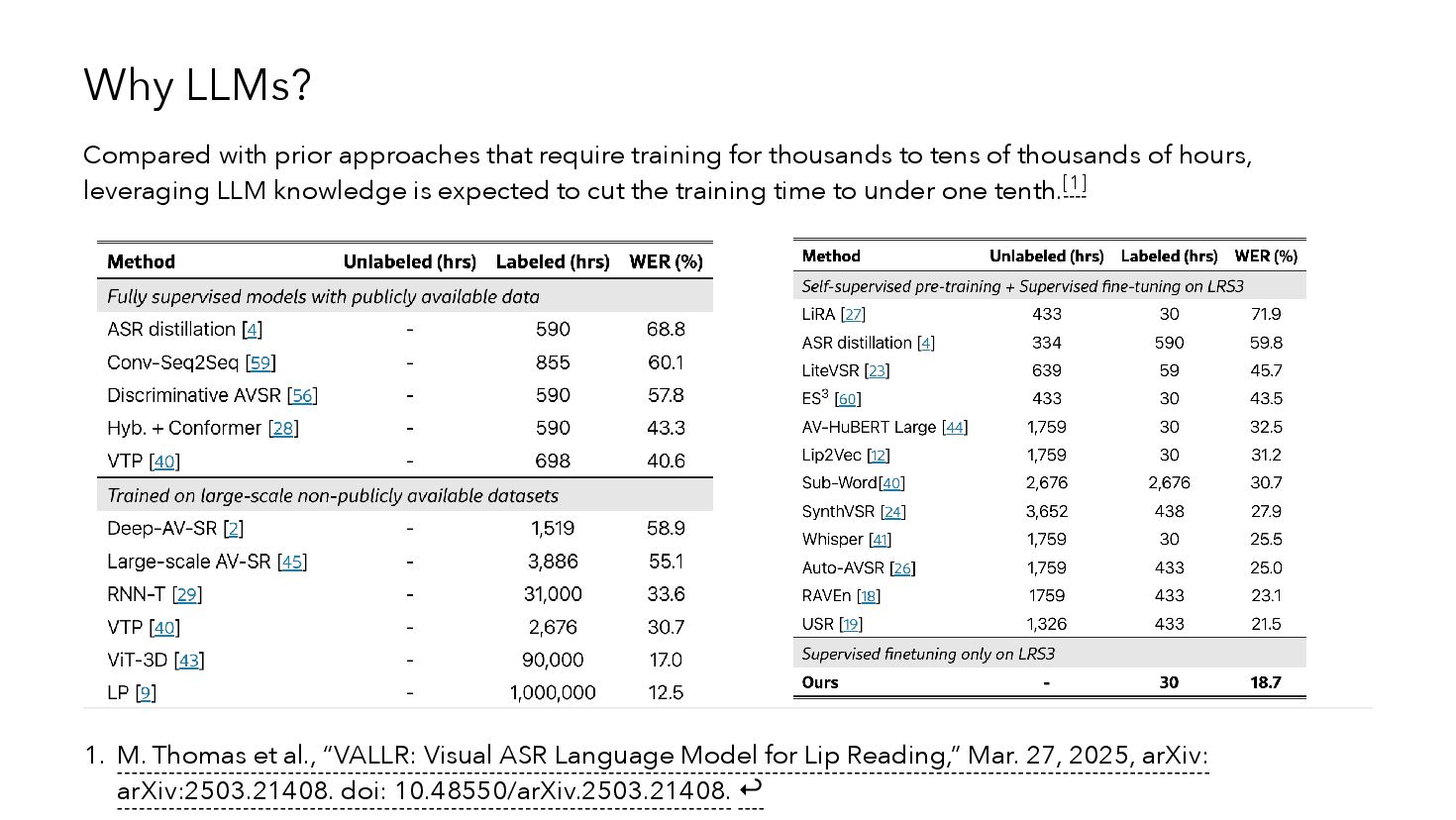{kind=link}
{kind=link}
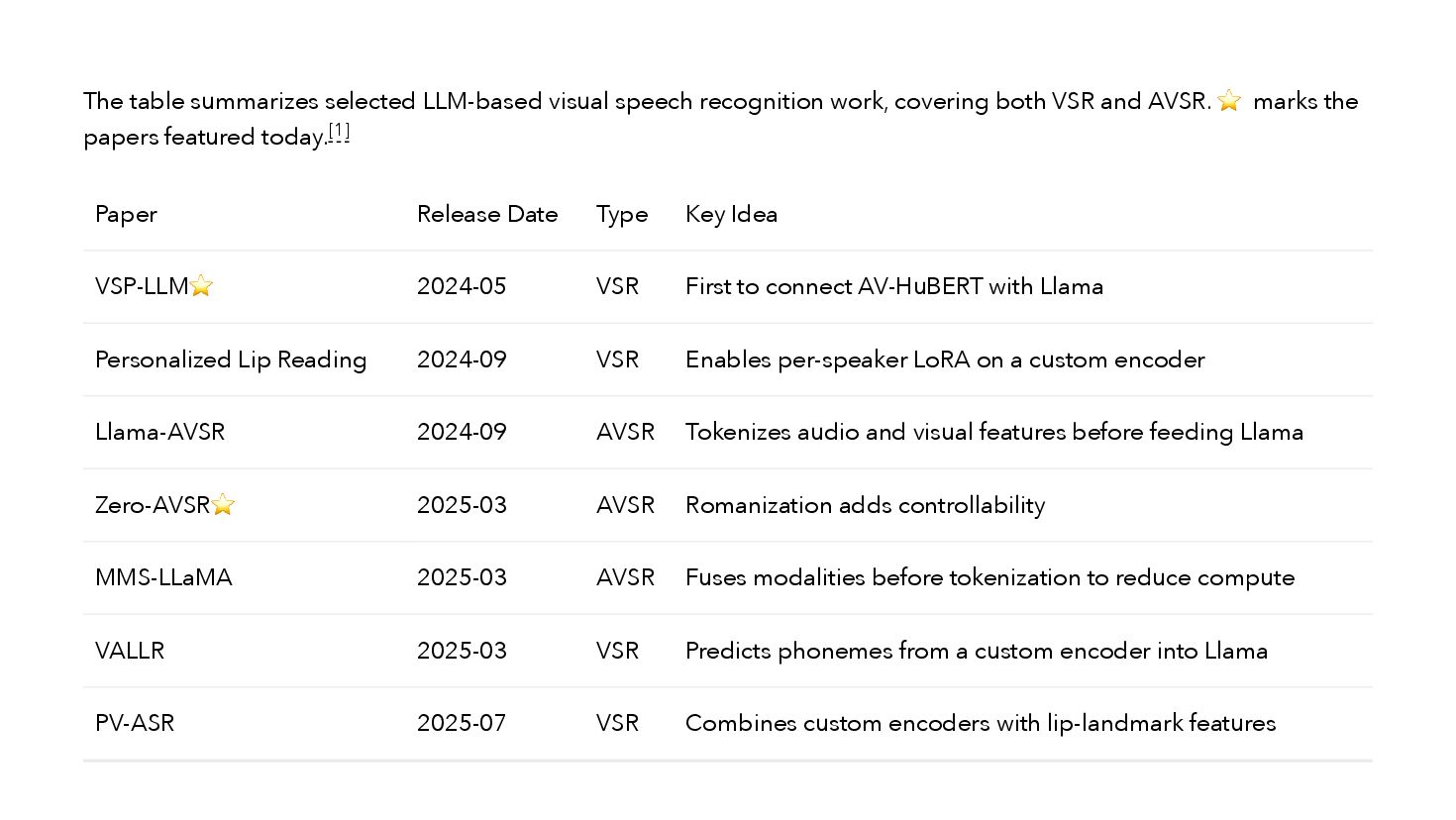{kind=link}
{kind=link}
{kind=link}
{kind=link}
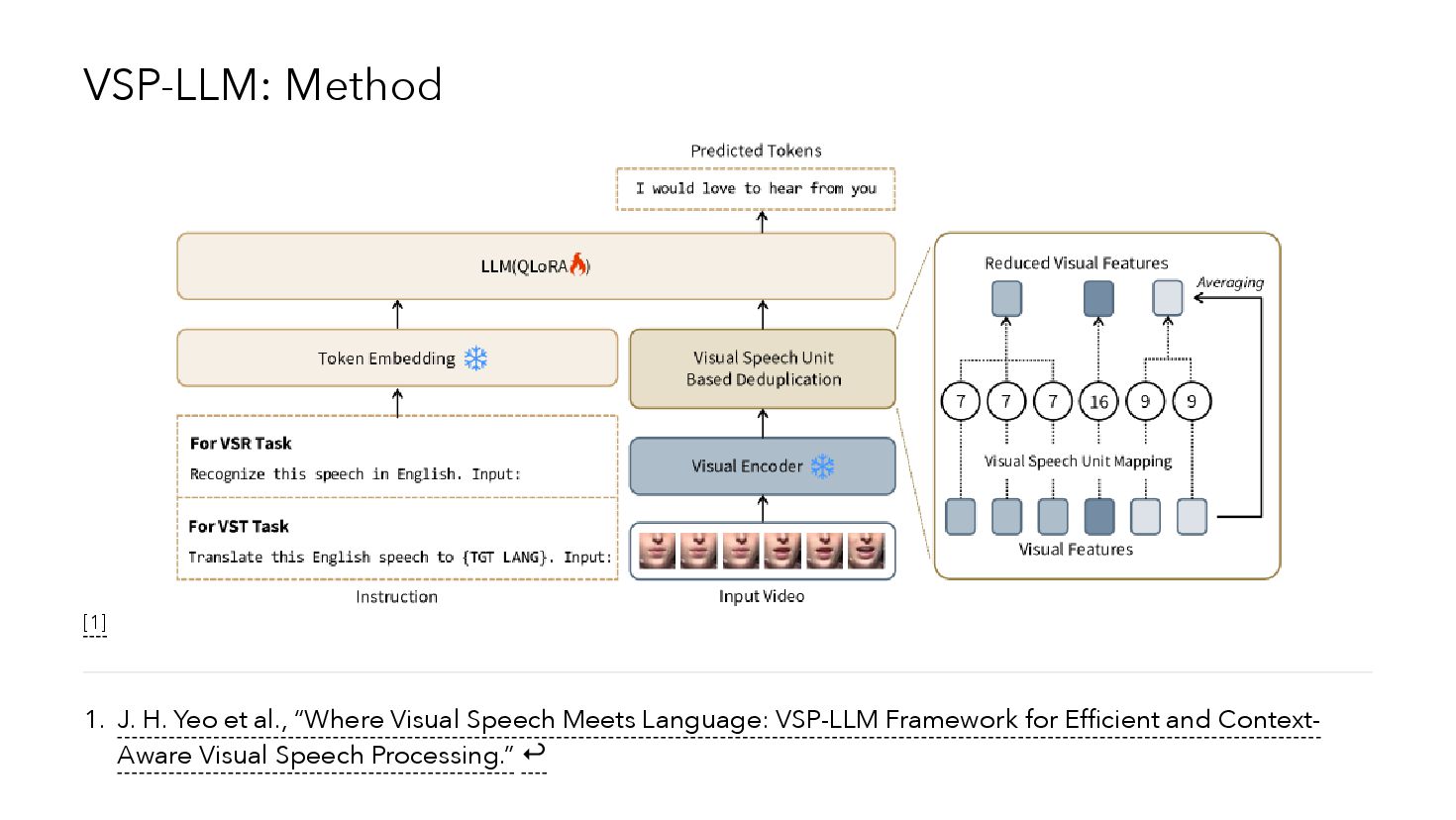{kind=link}
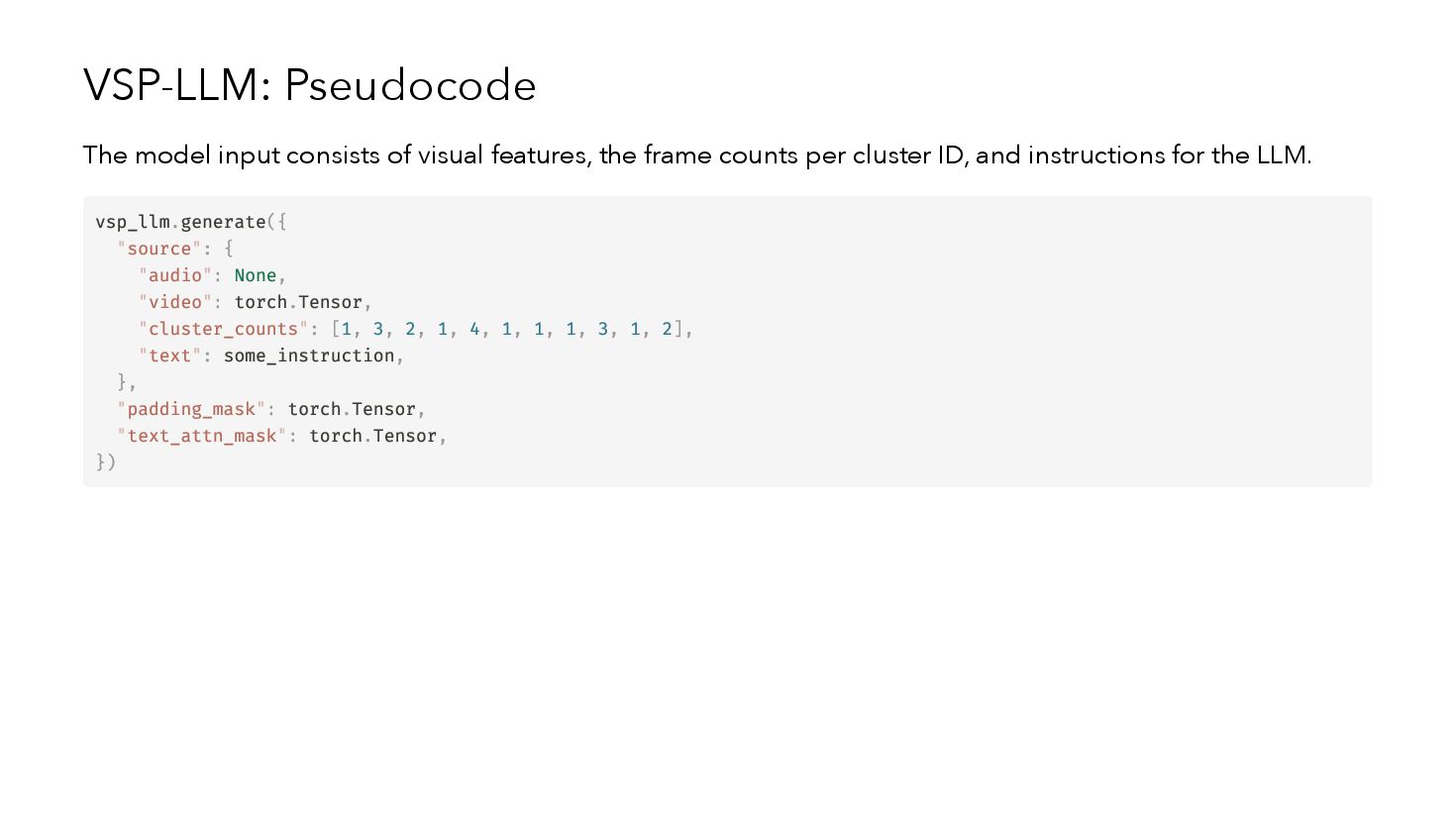{kind=link}
{kind=link}
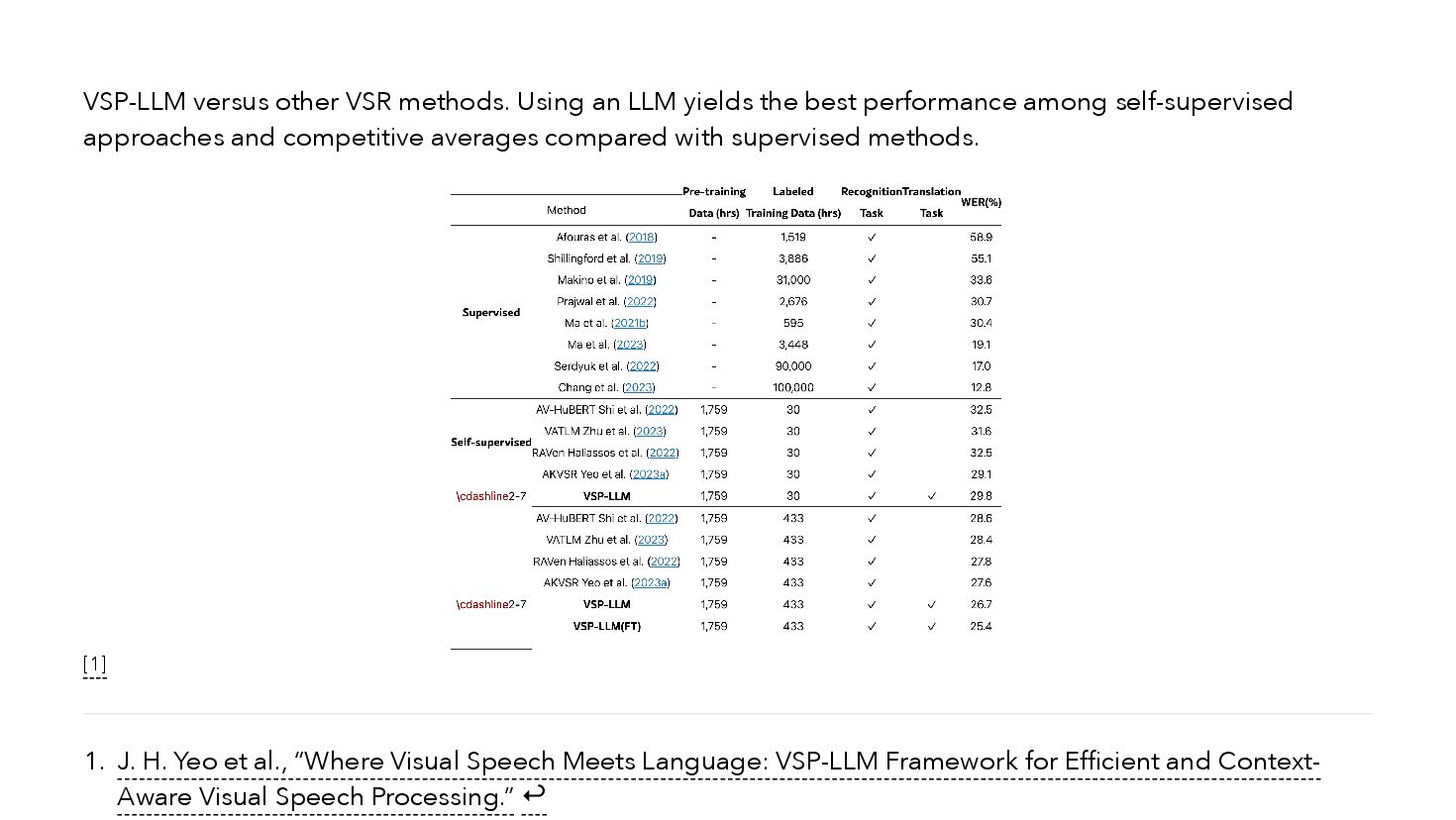{kind=link}
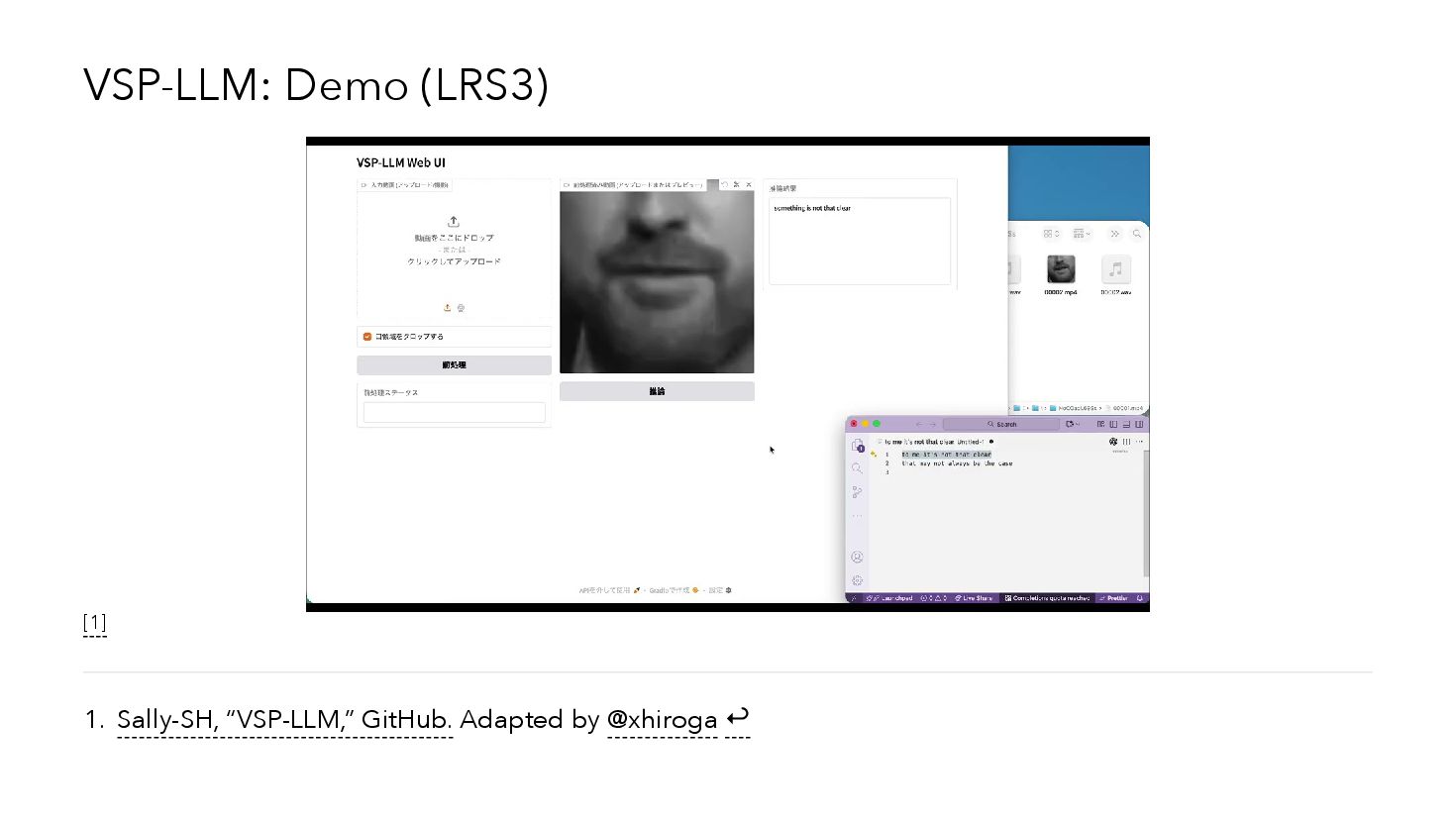{kind=link}
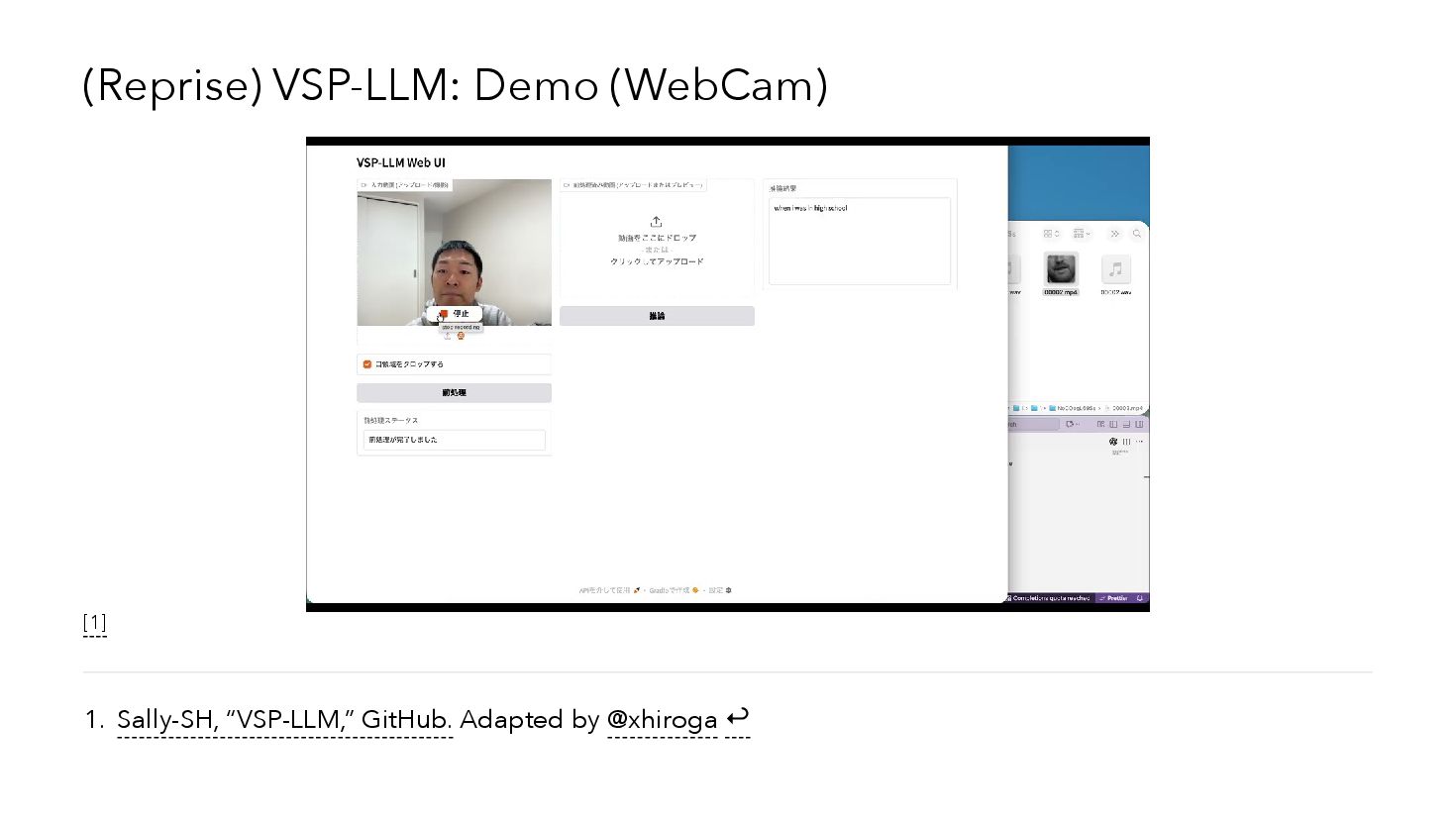{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
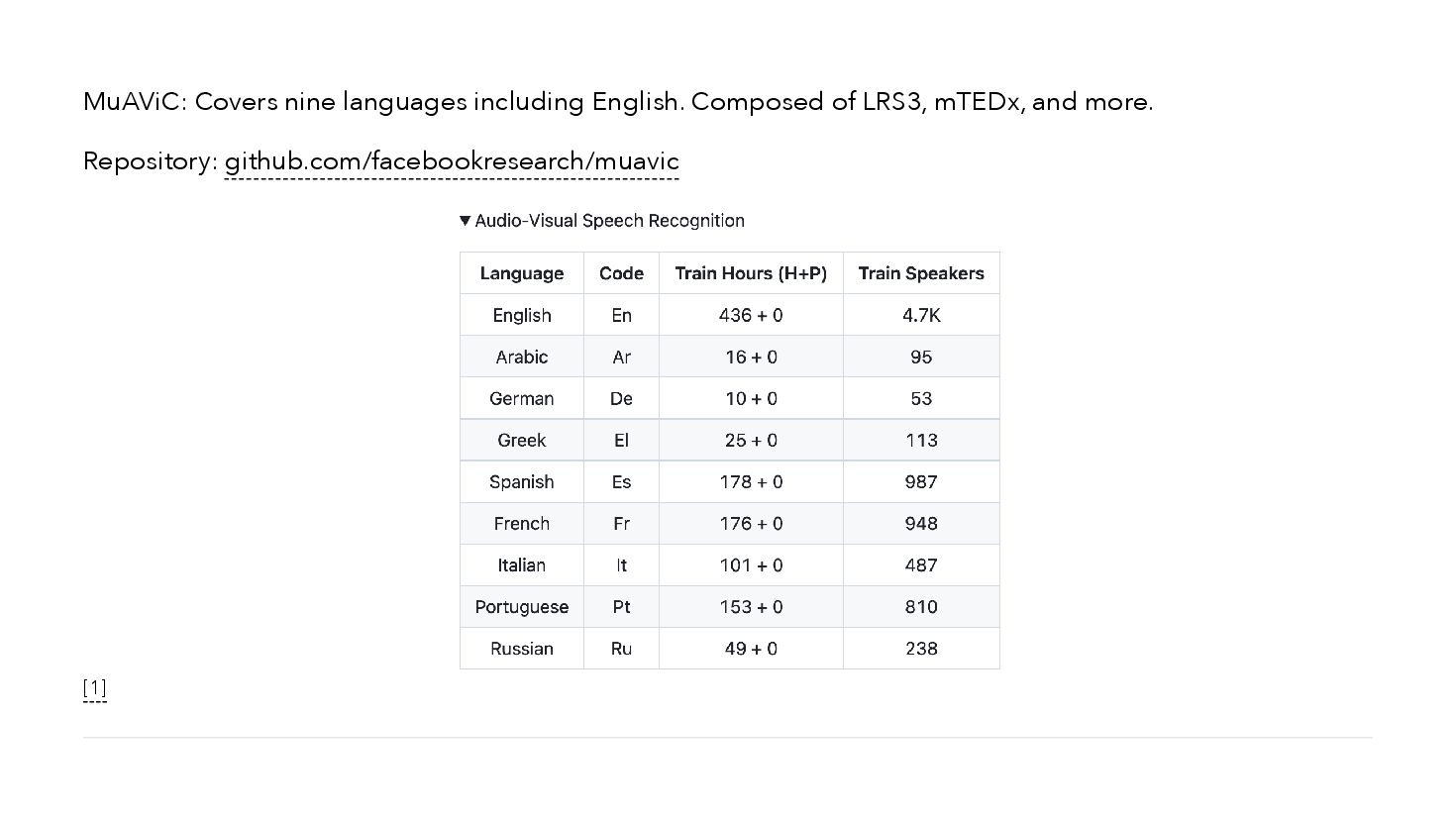{kind=link}
{kind=link}
{kind=link}
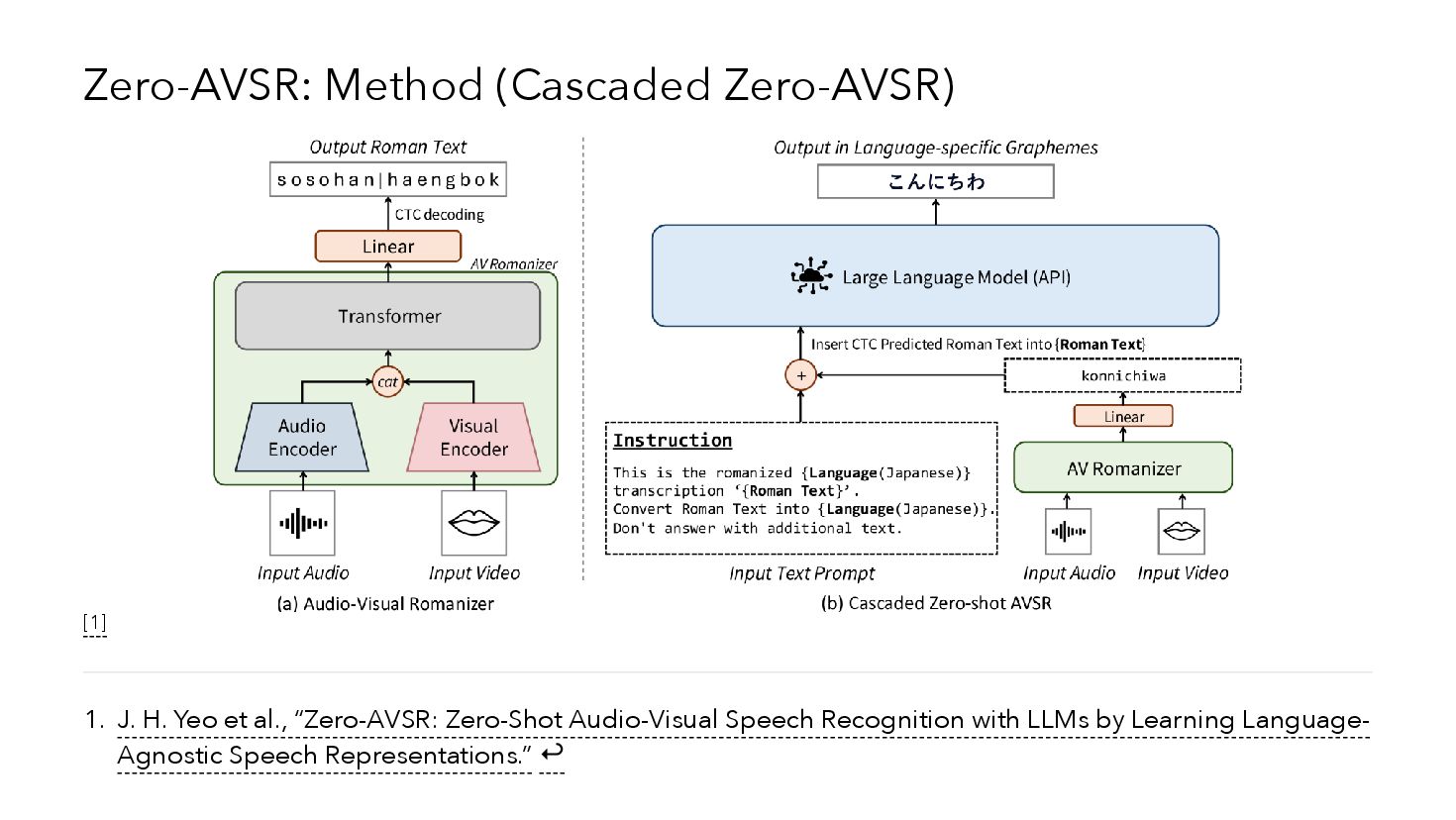{kind=link}
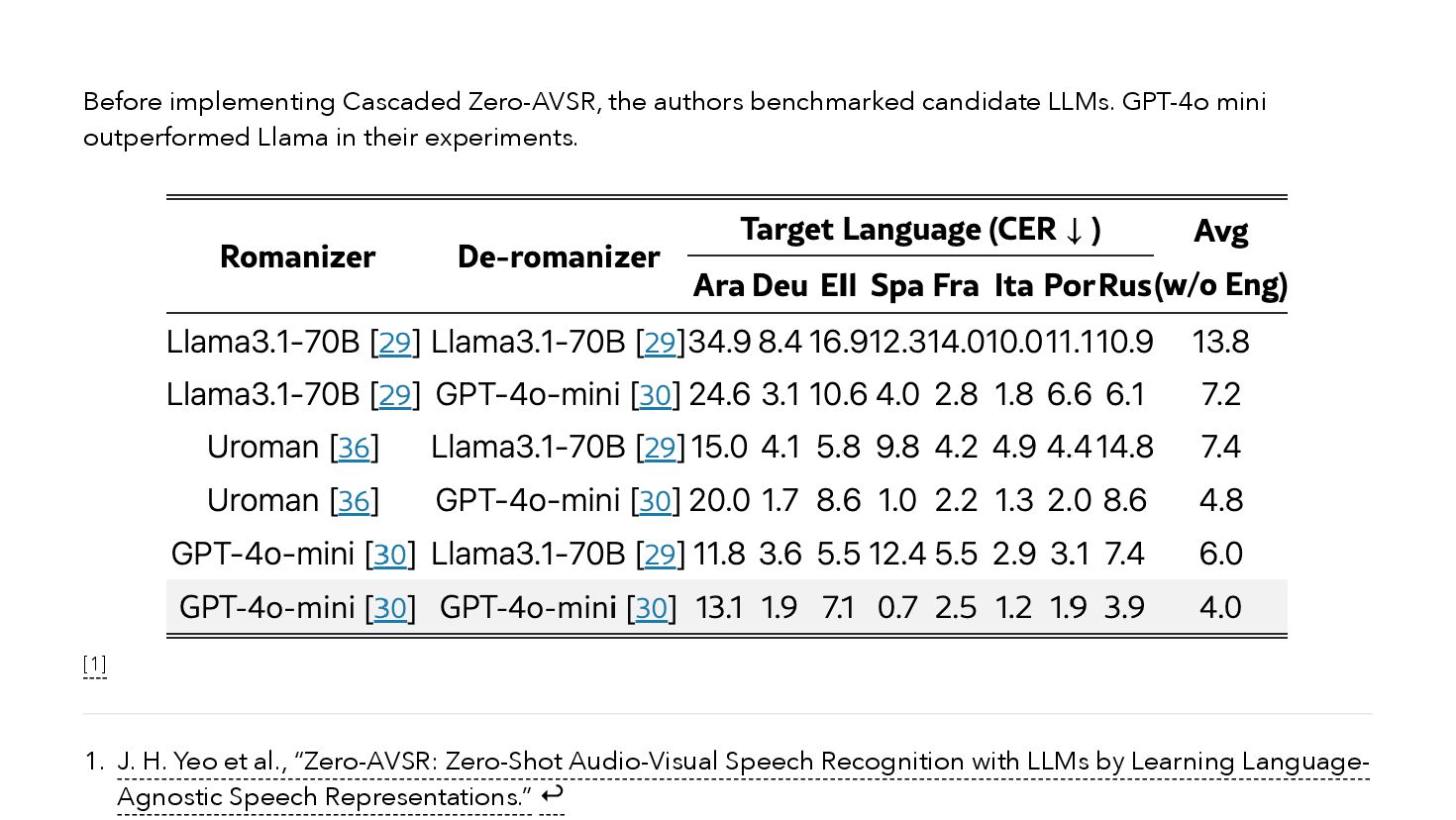{kind=link}
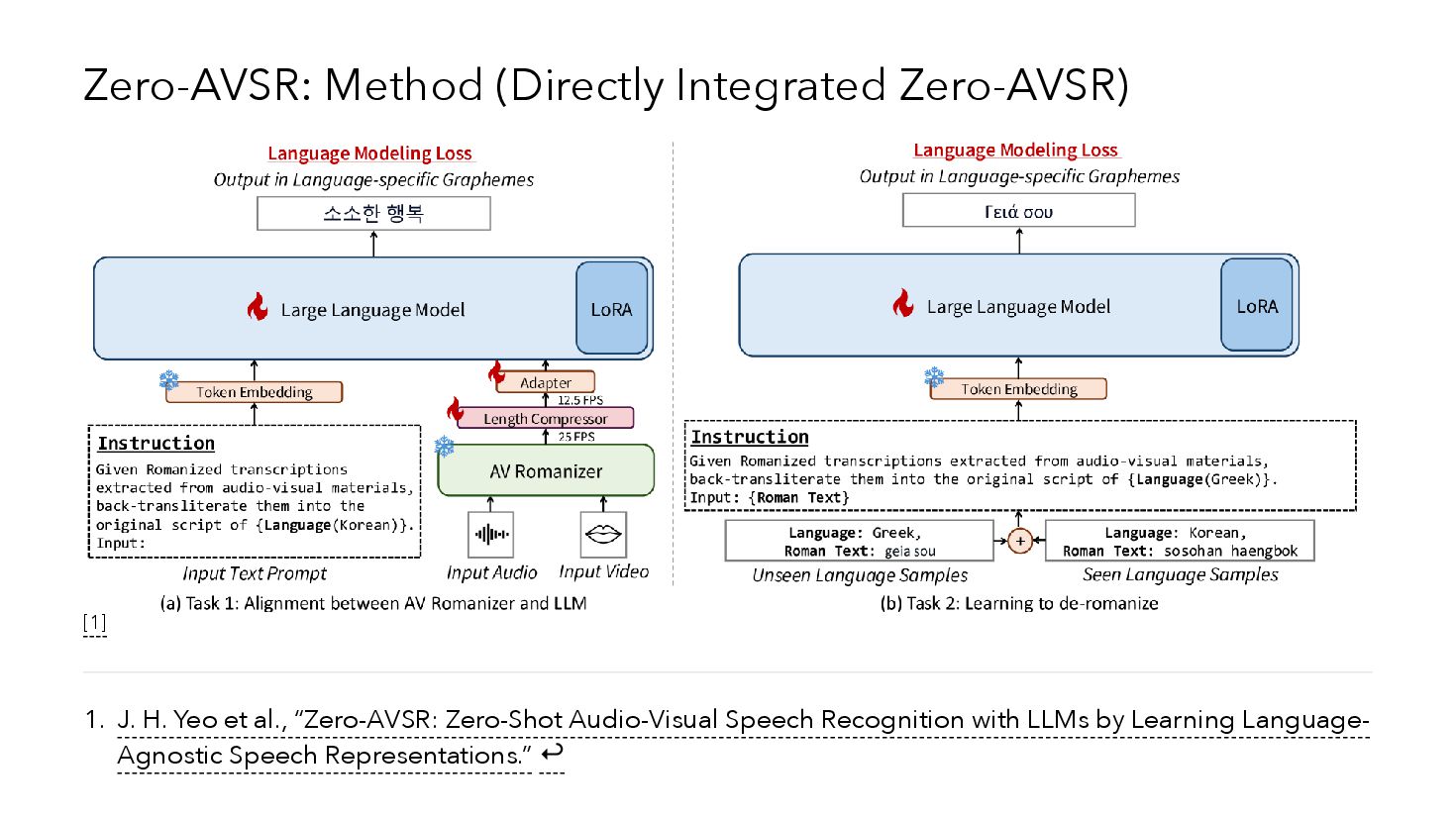{kind=link}
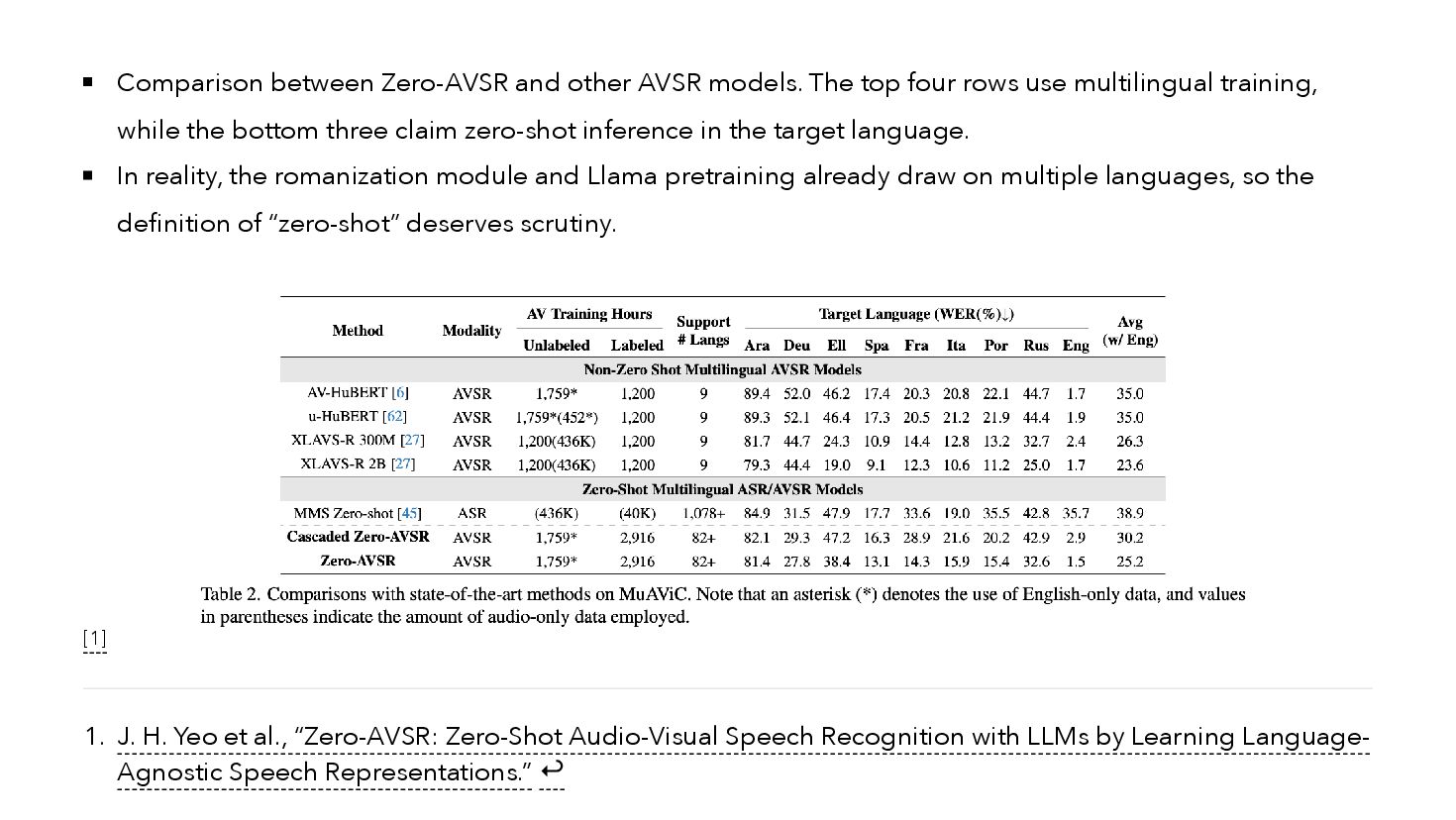{kind=link}
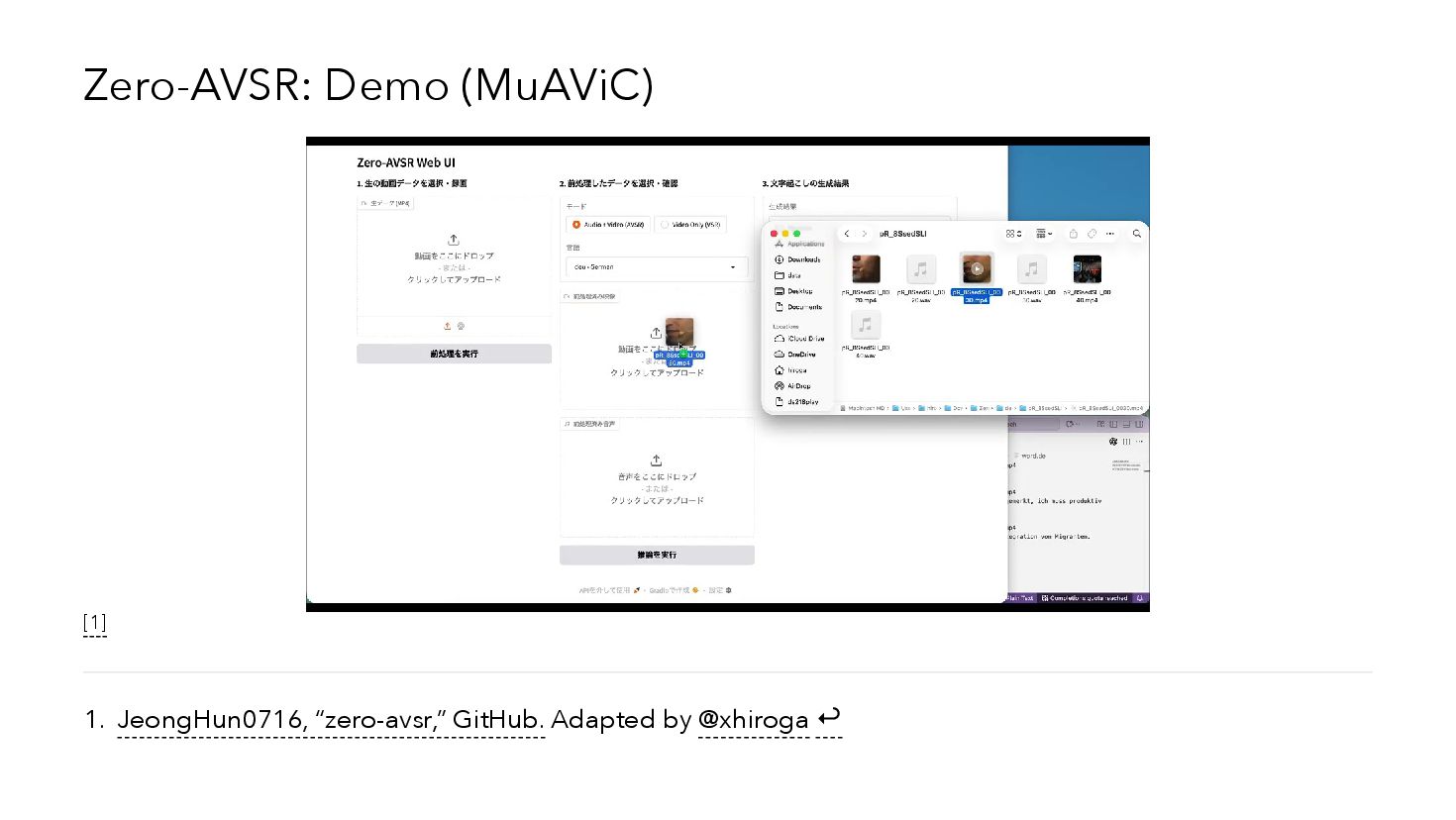{kind=link}
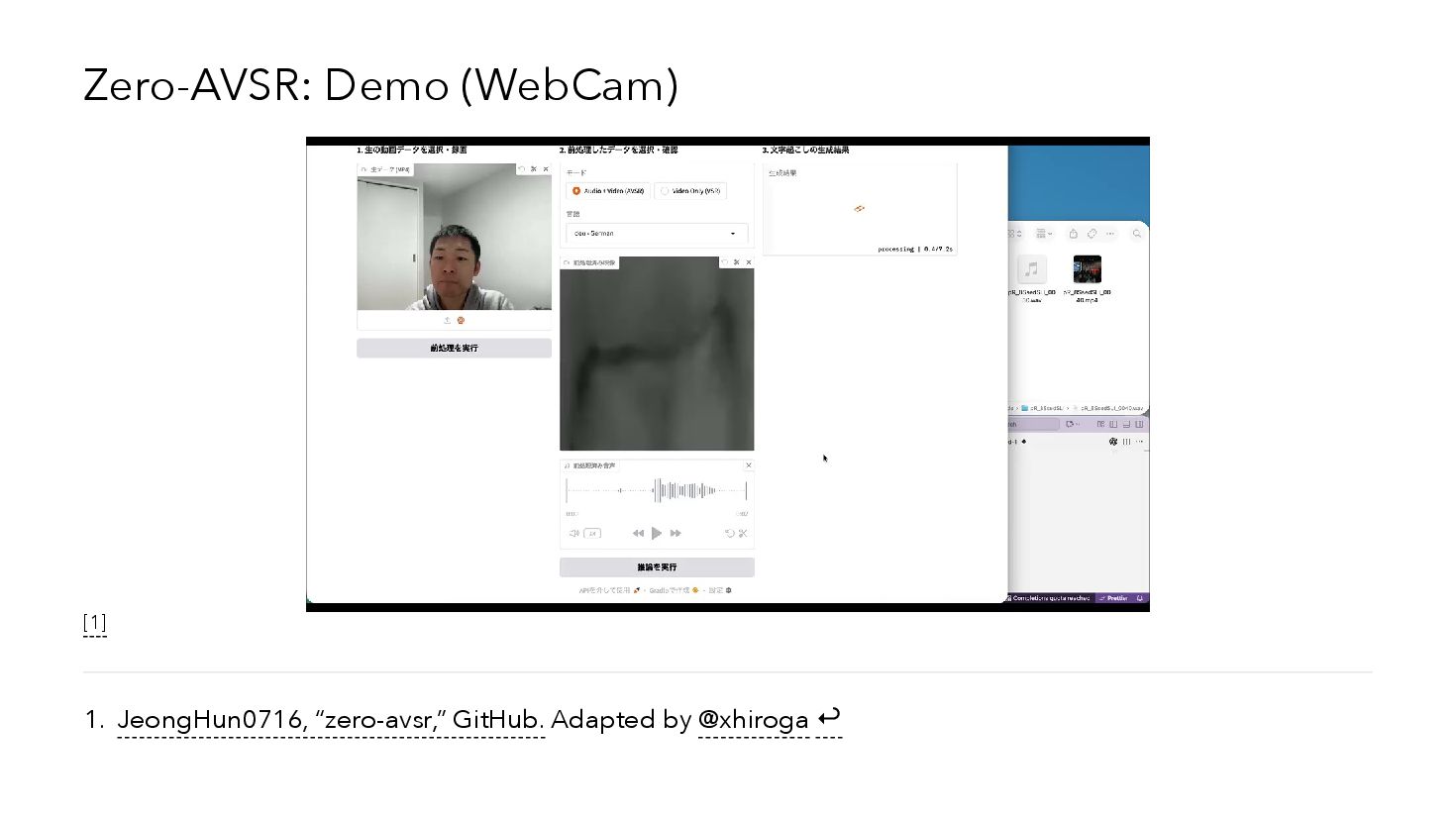{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}