モデルの適用範囲 (AD) とは?
どんな X の値でもモデルに入力してよいのか?
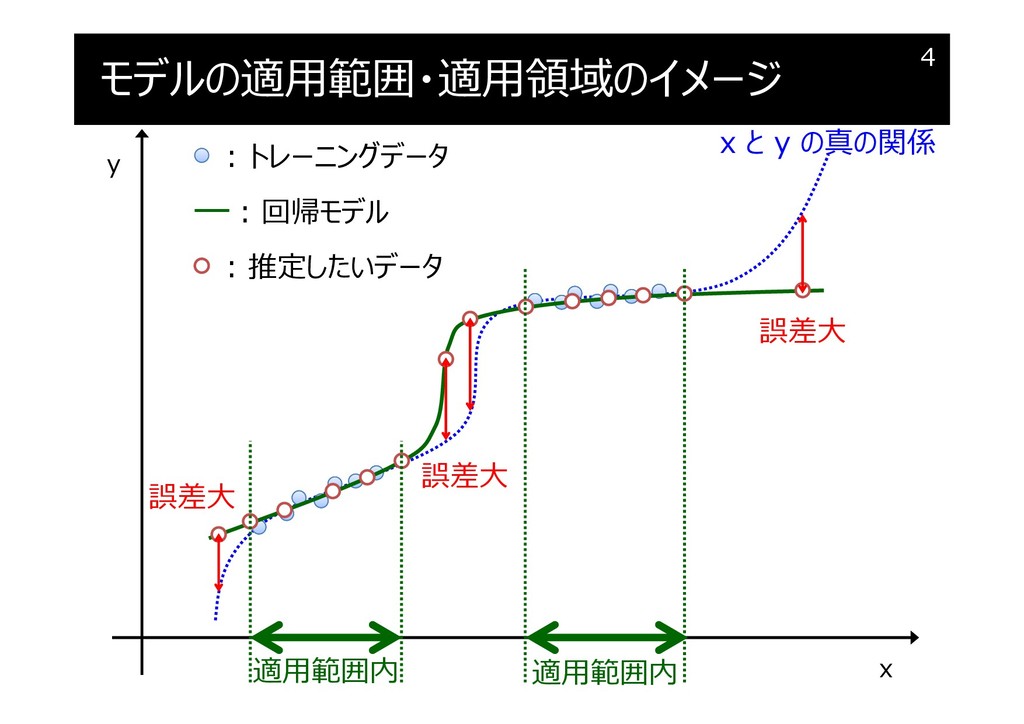
モデルの適用範囲・適用領域のイメージ
モデルの適用範囲・適用領域のイメージ
モデルの適用範囲・適用領域
AD の設定
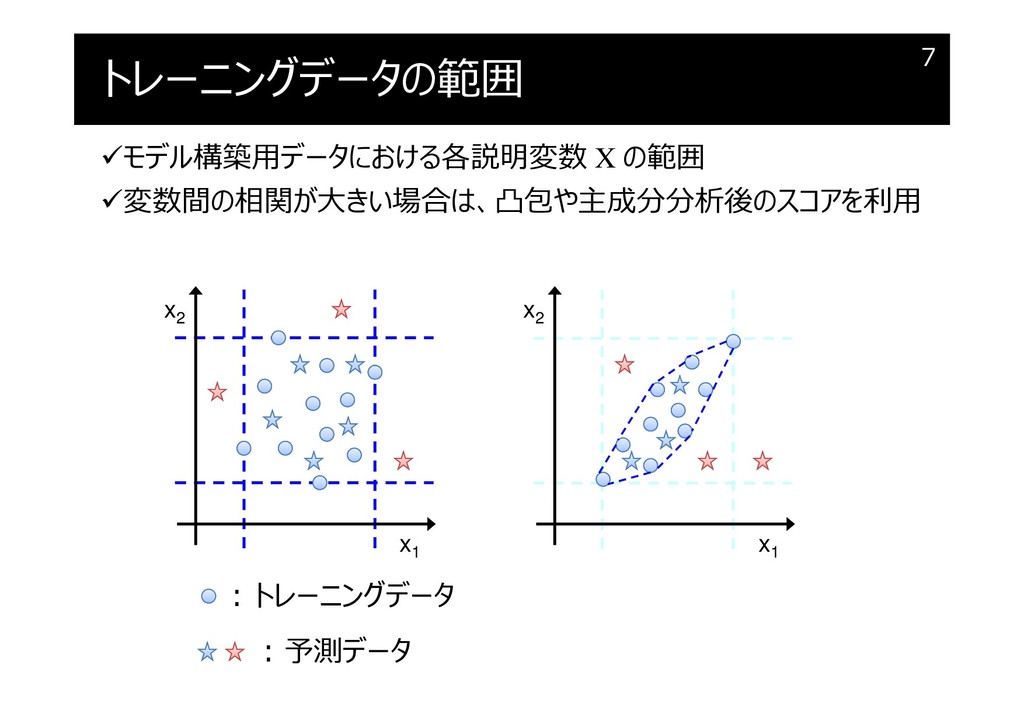
トレーニングデータの範囲
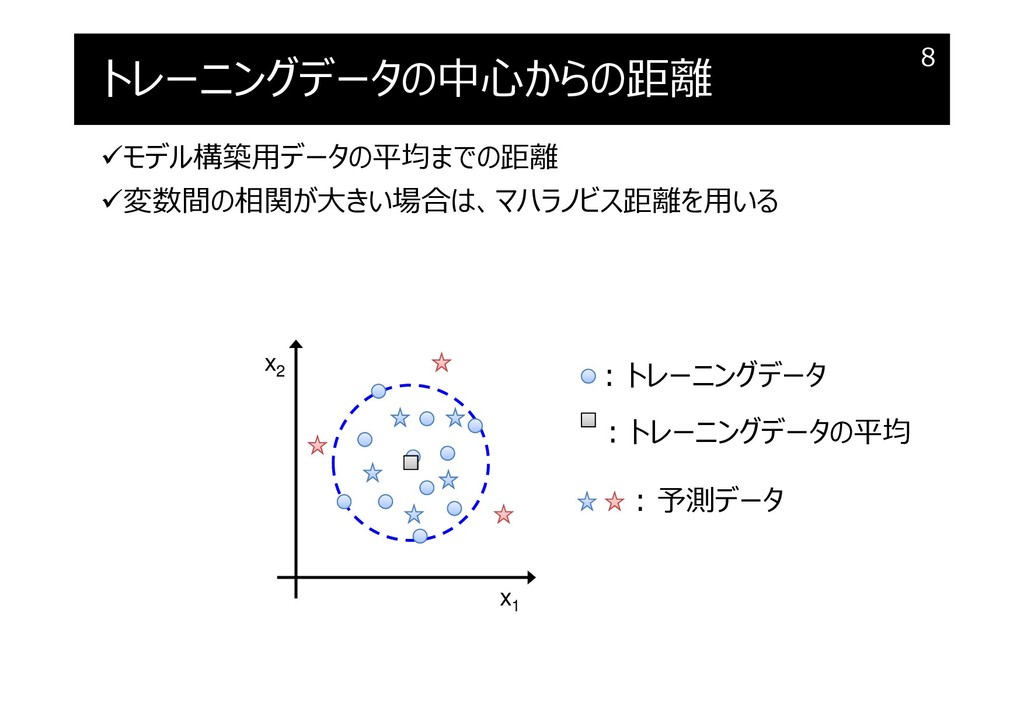
トレーニングデータの中心からの距離
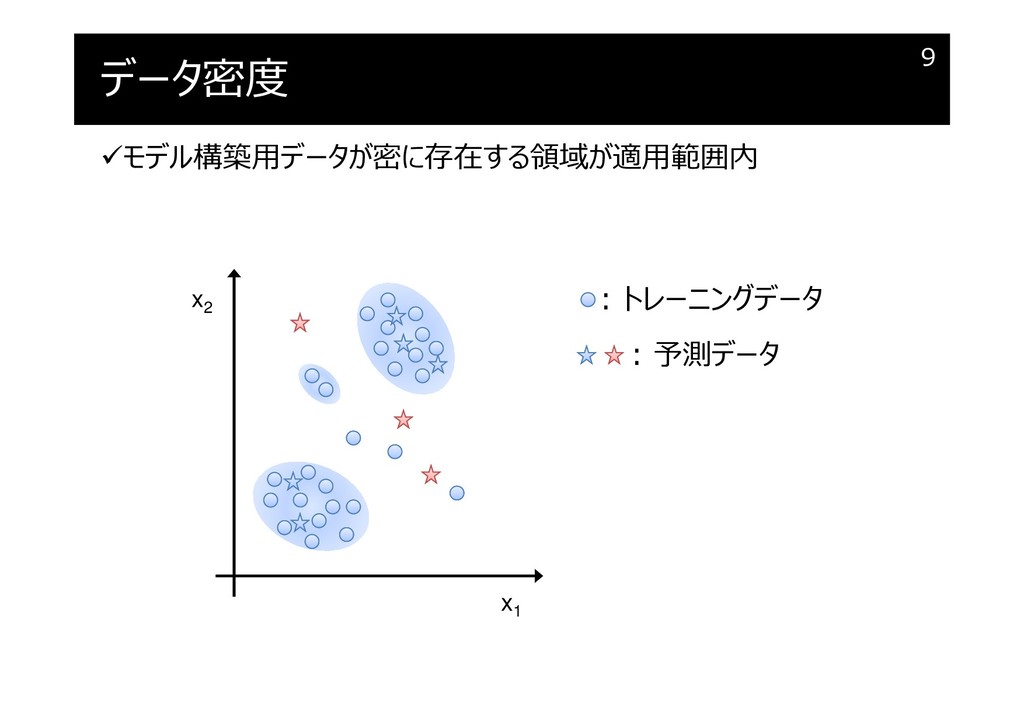
データ密度
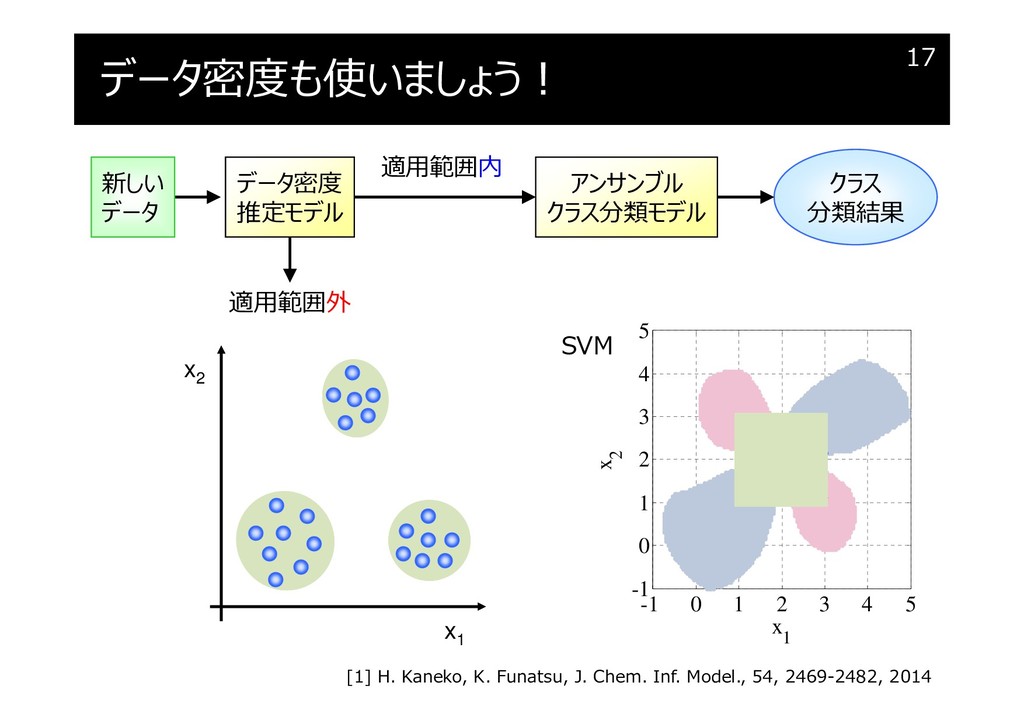
データ密度
アンサンブル学習
モデルとの距離 (Distance to Model)
回帰モデルの予測誤差(信頼性)の推定
注意!
数値シミュレーションデータで確認
すべてのサブモデルで分類結果が一致した領域
データ密度も使いましょう!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![モデルの適用範囲・適用領域 5 QSAR [1-3] QSPR [4-6] 『モデルが十分な性能を発揮できるデータ領域』 を定めよう︕ モデルの適用範囲・適用領域 (Applicability](https://files.speakerdeck.com/presentations/a2bb40e4603141ab869f5e5d84f6984d/slide_5.jpg){kind=link}
![AD の設定 トレーニングデータの範囲 [1] トレーニングデータの中心からの距離 [2,3] データ密度 [4,5] アンサンブル学習 [6]](https://files.speakerdeck.com/presentations/a2bb40e4603141ab869f5e5d84f6984d/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
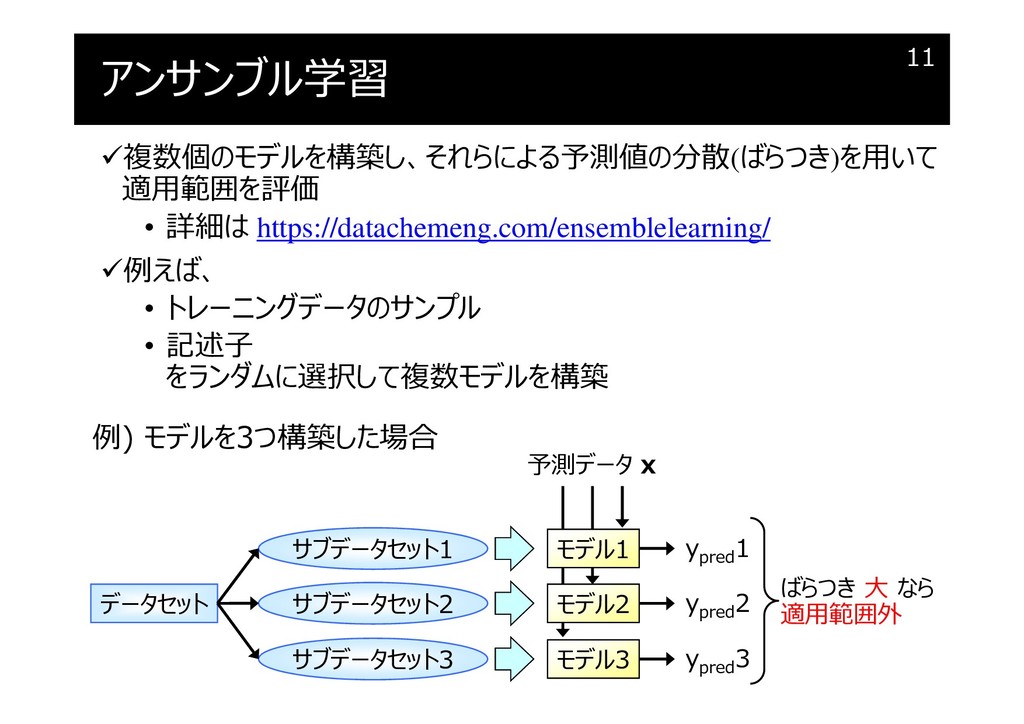{kind=link}
![モデルとの距離 (Distance to Model) 12 [1] Baskin II, Kireeva N,](https://files.speakerdeck.com/presentations/a2bb40e4603141ab869f5e5d84f6984d/slide_12.jpg){kind=link}
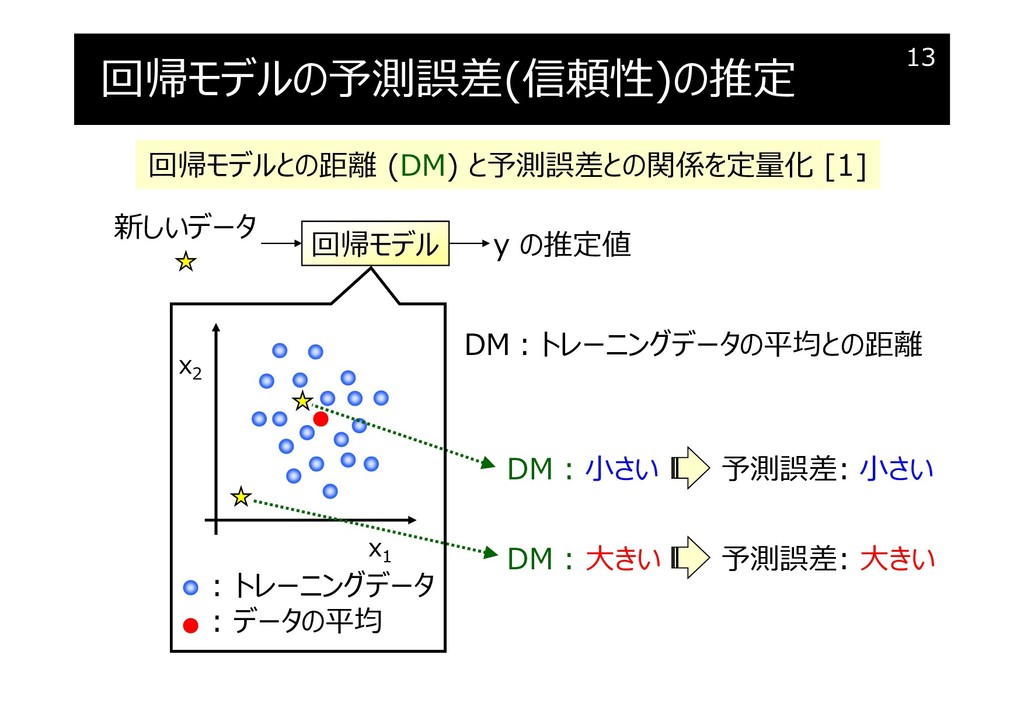{kind=link}
![注意︕ クラス分類のとき、アンサンブル学習だけでモデルの適用範囲を 設定すると、広くなりすぎてしまいます︕ 14 [1] H. Kaneko, K. Funatsu, J.](https://files.speakerdeck.com/presentations/a2bb40e4603141ab869f5e5d84f6984d/slide_14.jpg){kind=link}
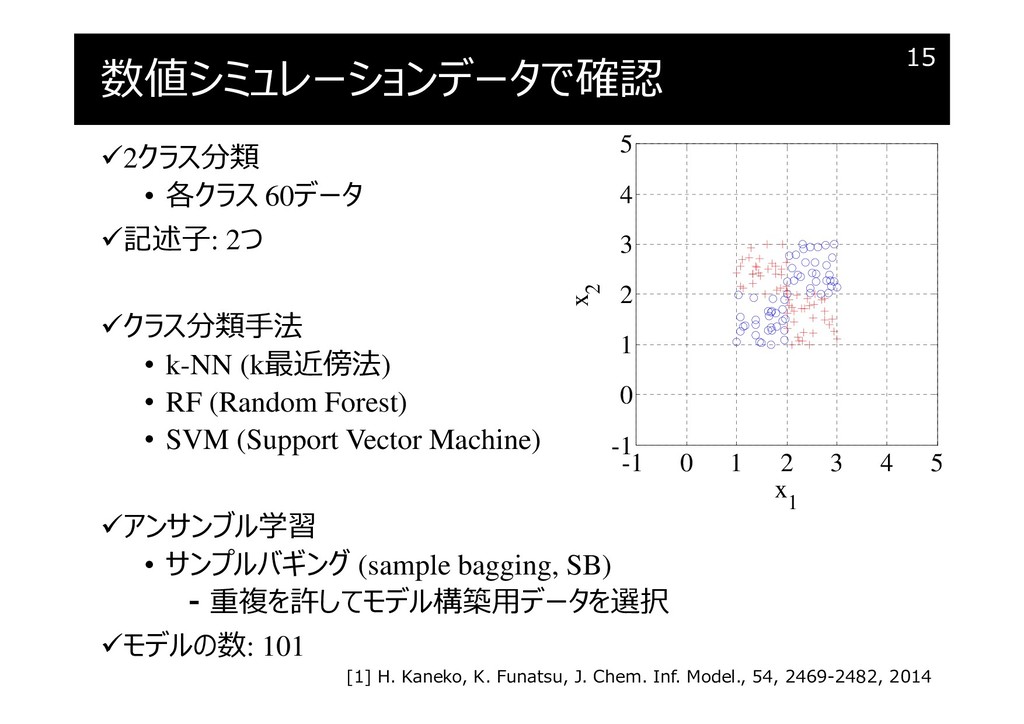{kind=link}
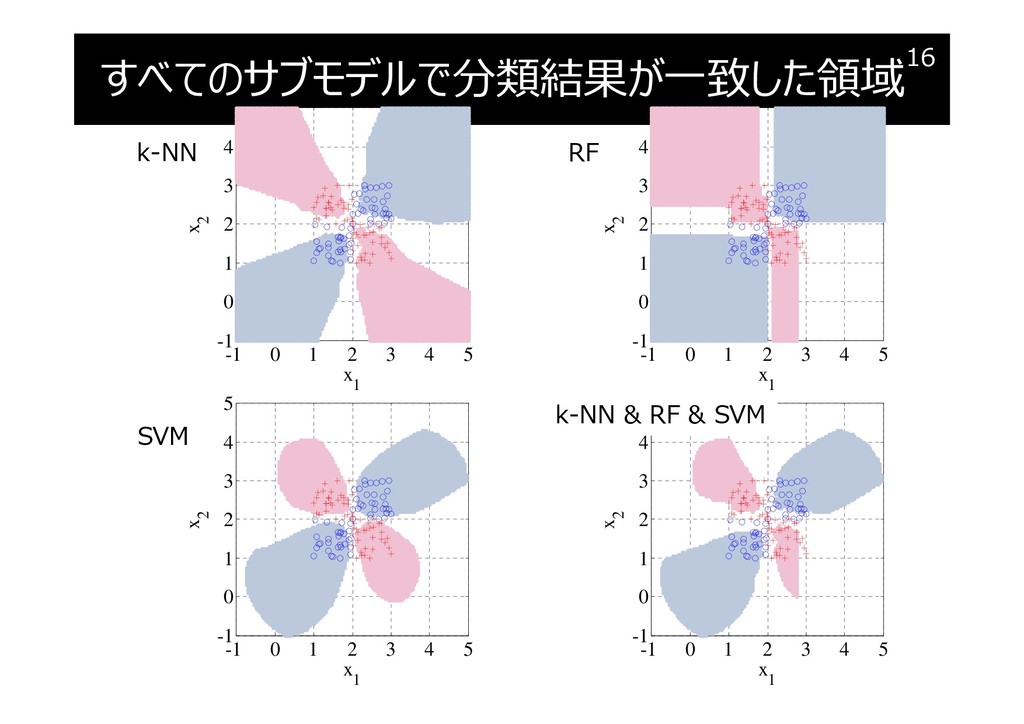{kind=link}
{kind=link}