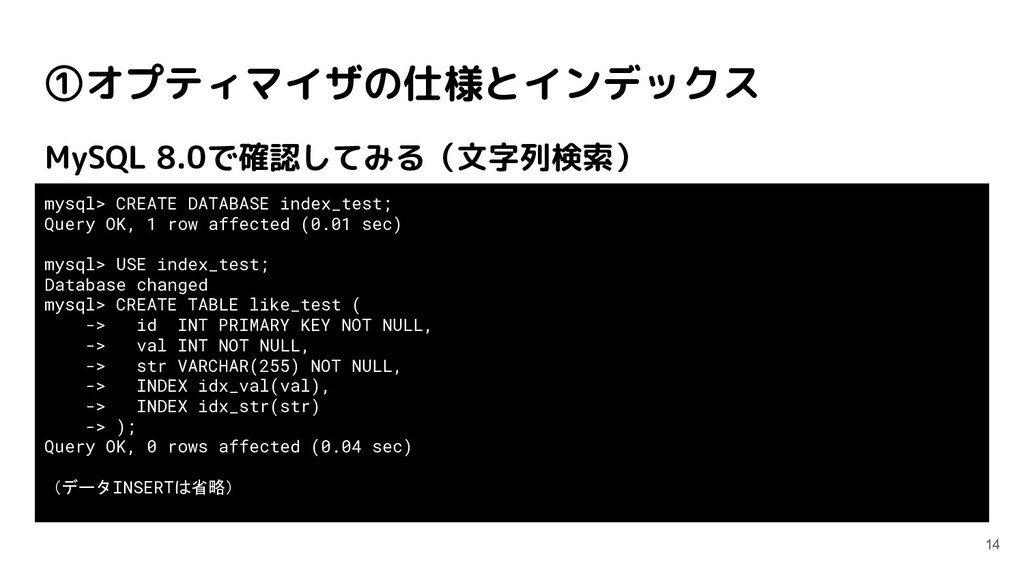
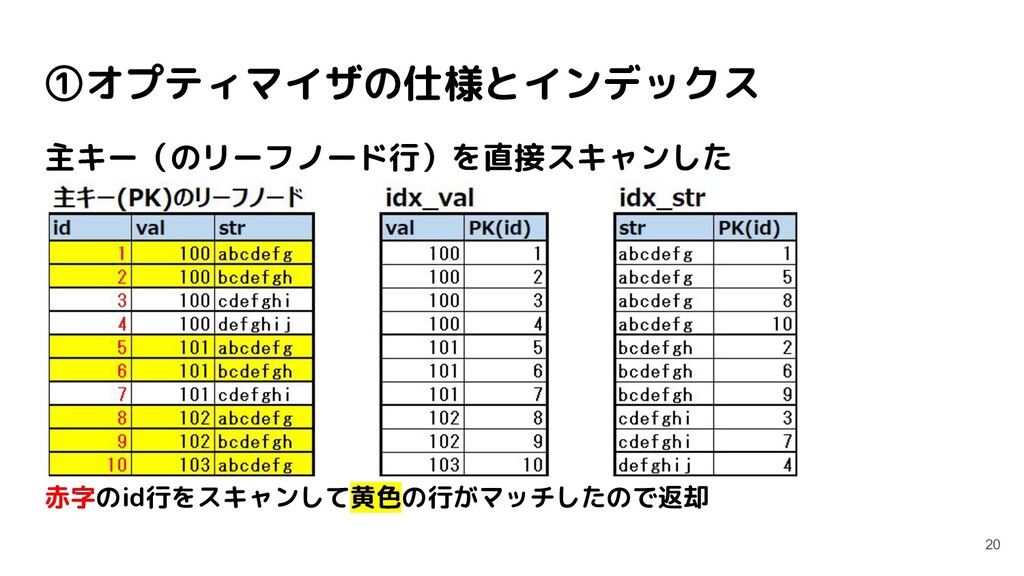
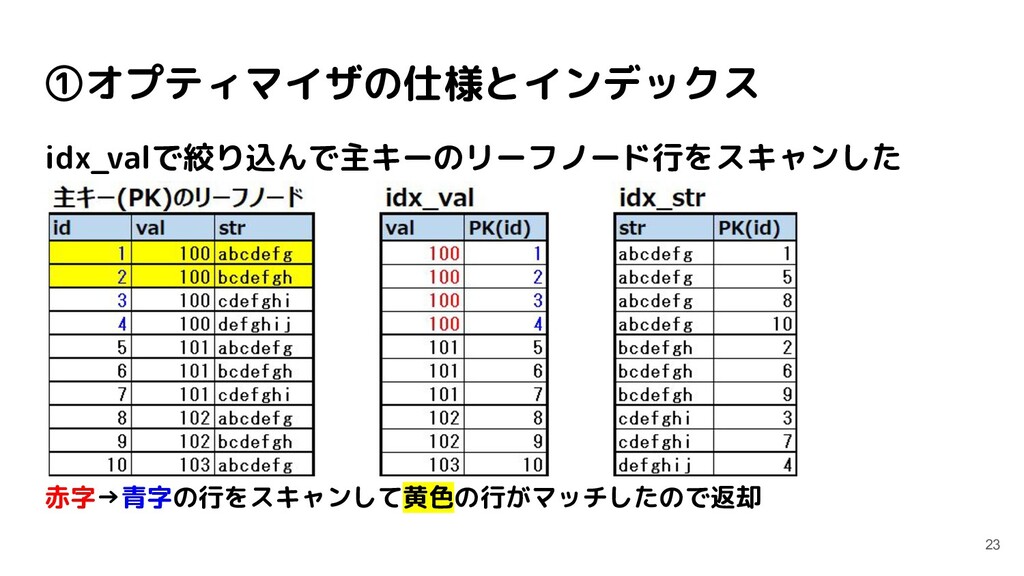
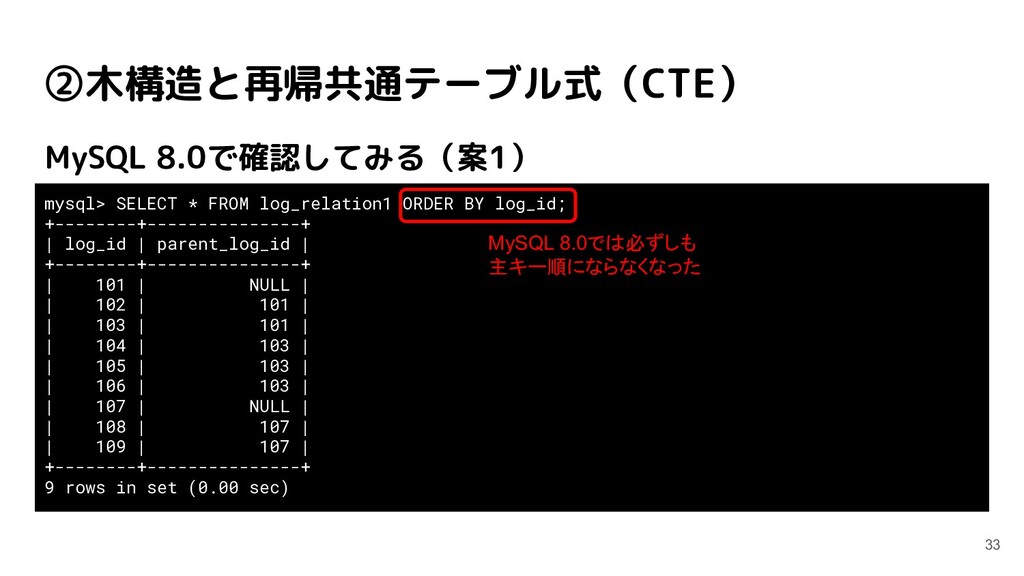
1 row affected (0.01 sec) mysql> USE index_test; Database changed mysql> CREATE TABLE like_test ( -> id INT PRIMARY KEY NOT NULL, -> val INT NOT NULL, -> str VARCHAR(255) NOT NULL, -> INDEX idx_val(val), -> INDEX idx_str(str) -> ); Query OK, 0 rows affected (0.04 sec) (データINSERTは省略)
( index_test(# id INT PRIMARY KEY NOT NULL, index_test(# val INT NOT NULL, index_test(# str VARCHAR(255) NOT NULL index_test(#); CREATE TABLE index_test=# CREATE INDEX ON like_test (val); CREATE INDEX index_test=# CREATE INDEX ON like_test (str); CREATE INDEX
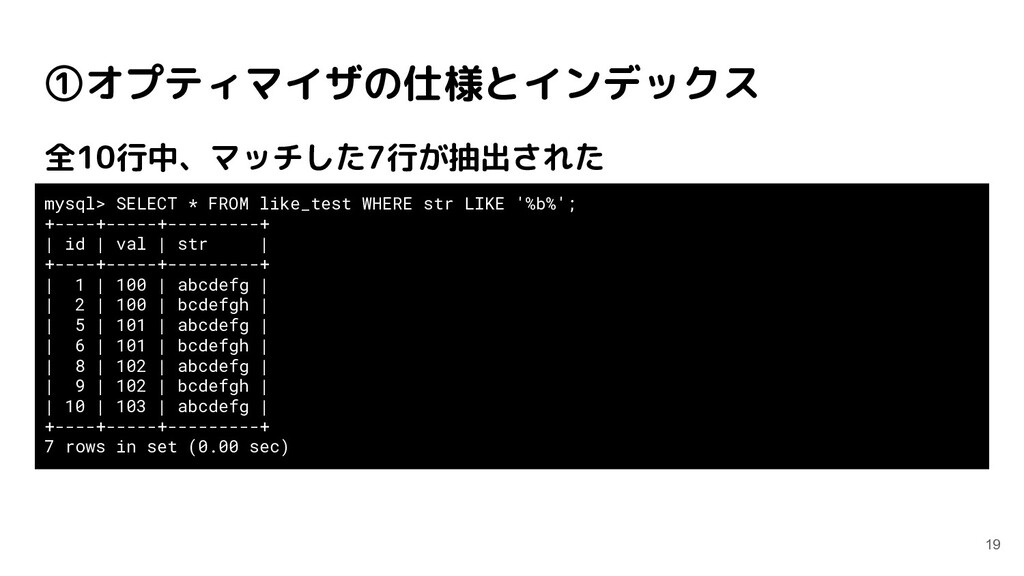
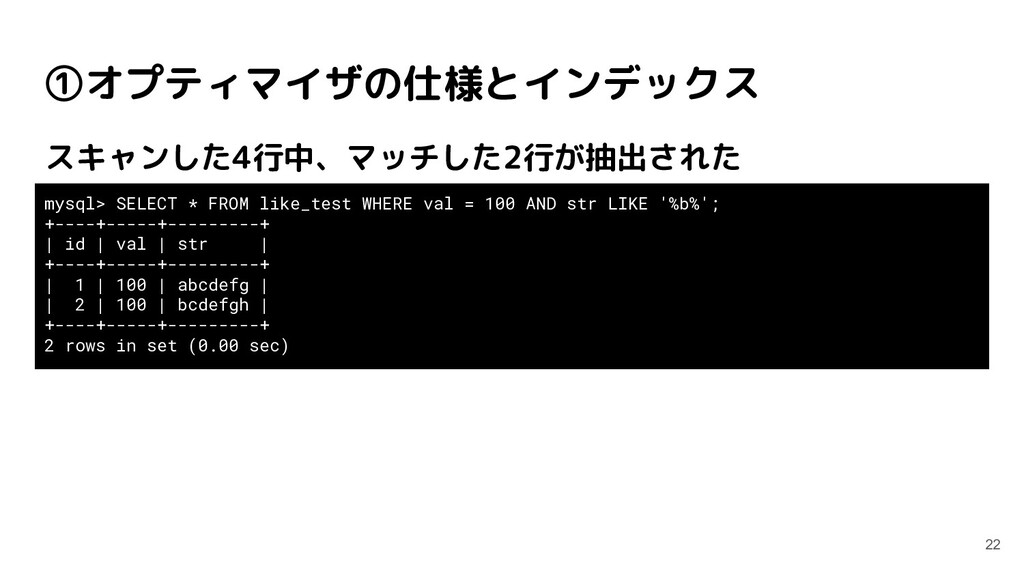
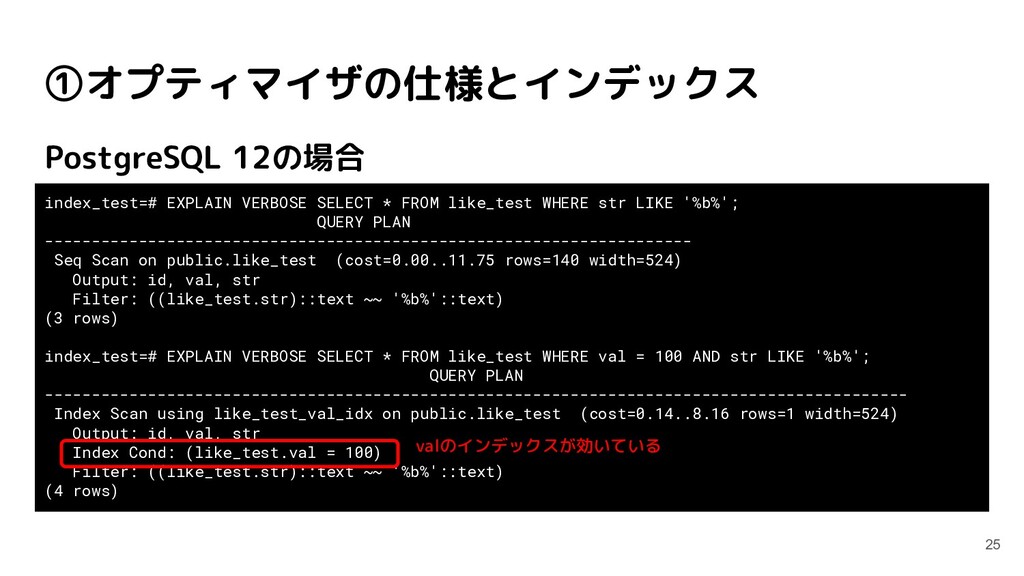
like_test WHERE str LIKE '%b%'; QUERY PLAN --------------------------------------------------------------------- Seq Scan on public.like_test (cost=0.00..11.75 rows=140 width=524) Output: id, val, str Filter: ((like_test.str)::text ~~ '%b%'::text) (3 rows) index_test=# EXPLAIN VERBOSE SELECT * FROM like_test WHERE val = 100 AND str LIKE '%b%'; QUERY PLAN -------------------------------------------------------------------------------------------- Index Scan using like_test_val_idx on public.like_test (cost=0.14..8.16 rows=1 width=524) Output: id, val, str Index Cond: (like_test.val = 100) Filter: ((like_test.str)::text ~~ '%b%'::text) (4 rows) valのインデックスが効いている
(SELECT log_id FROM log_relation1 WHERE log_id = 101 tree_test(# UNION ALL tree_test(# SELECT a.log_id FROM log_relation1 a, temp b tree_test(# WHERE a.parent_log_id = b.log_id) tree_test-# SELECT log_id FROM temp; log_id -------- 101 102 103 104 105 106 (6 rows)
(SELECT log_id FROM log_relation1 WHERE log_id = 101 UNION ALL SELECT a.log_id FROM log_relation1 a, temp b WHERE a.parent_log_id = b.log_id) SELECT log_id FROM temp; QUERY PLAN ----------------------------------------------------------------------------------------------------------- CTE Scan on temp (cost=456.09..478.71 rows=1131 width=4) CTE temp -> Recursive Union (cost=0.15..456.09 rows=1131 width=4) -> Index Only Scan using log_relation1_pkey on log_relation1 (cost=0.15..8.17 rows=1 width=4) Index Cond: (log_id = 101) -> Hash Join (cost=0.33..42.53 rows=113 width=4) Hash Cond: (a.parent_log_id = b.log_id) -> Seq Scan on log_relation1 a (cost=0.00..32.60 rows=2260 width=8) -> Hash (cost=0.20..0.20 rows=10 width=4) -> WorkTable Scan on temp b (cost=0.00..0.20 rows=10 width=4) (10 rows) ハッシュ結合
-> (SELECT log_id, parent_log_id FROM log_relation1 WHERE log_id = 105 -> UNION ALL -> SELECT a.log_id, a.parent_log_id FROM log_relation1 a, temp b -> WHERE a.log_id = b.parent_log_id) -> SELECT log_id FROM temp; +--------+ | log_id | +--------+ | 105 | | 103 | | 101 | +--------+ 3 rows in set (0.00 sec)
log_relation2 a, log_relation2 b WHERE a.log_id = 105 AND POSITION(b.path IN a.path) = 1; QUERY PLAN -------------------------------------------------------------------------------------------------- Nested Loop (cost=0.14..21.66 rows=1 width=4) Join Filter: ("position"((a.path)::text, (b.path)::text) = 1) -> Index Scan using log_relation2_pkey on log_relation2 a (cost=0.14..8.16 rows=1 width=516) Index Cond: (log_id = 105) -> Seq Scan on log_relation2 b (cost=0.00..11.40 rows=140 width=520) (5 rows)
mysql> SELECT -> RANK() OVER (PARTITION BY municipality_type ORDER BY population DESC) AS pop_rank, -> name, -> population, -> municipality_type -> FROM population;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![②木構造と再帰共通テーブル式(CTE) MySQL 8.0で確認してみる(案1問合せ[A]) 34 mysql> WITH RECURSIVE temp(log_id) AS ->](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_33.jpg){kind=link}
![②木構造と再帰共通テーブル式(CTE) MySQL 8.0で確認してみる(案1問合せ[A]) 35](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_34.jpg){kind=link}
{kind=link}
![②木構造と再帰共通テーブル式(CTE) PostgreSQL 12でも同じように行ける(案1問合せ[A]) 37 tree_test=# WITH RECURSIVE temp(log_id) AS tree_test-#](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_36.jpg){kind=link}
![②木構造と再帰共通テーブル式(CTE) EXPLAINするとCTE Scanになる(案1問合せ[A]) 38 tree_test=# EXPLAIN WITH RECURSIVE temp(log_id) AS](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_37.jpg){kind=link}
![②木構造と再帰共通テーブル式(CTE) MySQL 8.0で確認してみる(案1問合せ[B]) 39 mysql> WITH RECURSIVE temp(log_id, parent_log_id) AS](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_38.jpg){kind=link}
![②木構造と再帰共通テーブル式(CTE) MySQL 8.0で確認してみる(案1問合せ[B]) 40](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_39.jpg){kind=link}
{kind=link}
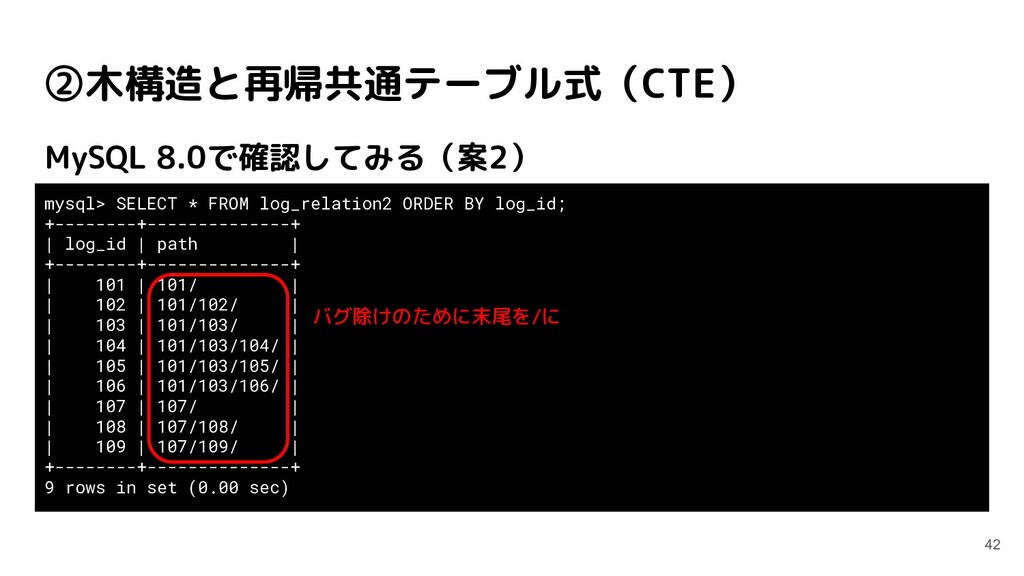{kind=link}
![②木構造と再帰共通テーブル式(CTE) MySQL 8.0で確認してみる(案2問合せ[A]) 43 mysql> SELECT log_id FROM log_relation2 WHERE](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_42.jpg){kind=link}
![②木構造と再帰共通テーブル式(CTE) MySQL 8.0で確認してみる(案2問合せ[A]) 試験問題と同様にインデックス検索になる 44 mysql> EXPLAIN -> SELECT log_id](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_43.jpg){kind=link}
![②木構造と再帰共通テーブル式(CTE) MySQL 8.0で確認してみる(案2問合せ[B]) 45 mysql> SELECT b.log_id FROM log_relation2 a,](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_44.jpg){kind=link}
![②木構造と再帰共通テーブル式(CTE) MySQL 8.0で確認してみる(案2問合せ[B]) 試験問題とは違ってINDEX(主キー)が使われる • 経路(path)側はINDEXフルスキャンに 46 mysql> EXPLAIN ->](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_45.jpg){kind=link}
![②木構造と再帰共通テーブル式(CTE) PostgreSQL 12でEXPLAINを確認(案2問合せ[B]) こちらも試験問題とは違ってINDEX(主キー)が使われる 47 tree_test=# EXPLAIN SELECT b.log_id FROM](https://files.speakerdeck.com/presentations/78aaf0b6ea8249f2a3b0008f312e51a0/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}