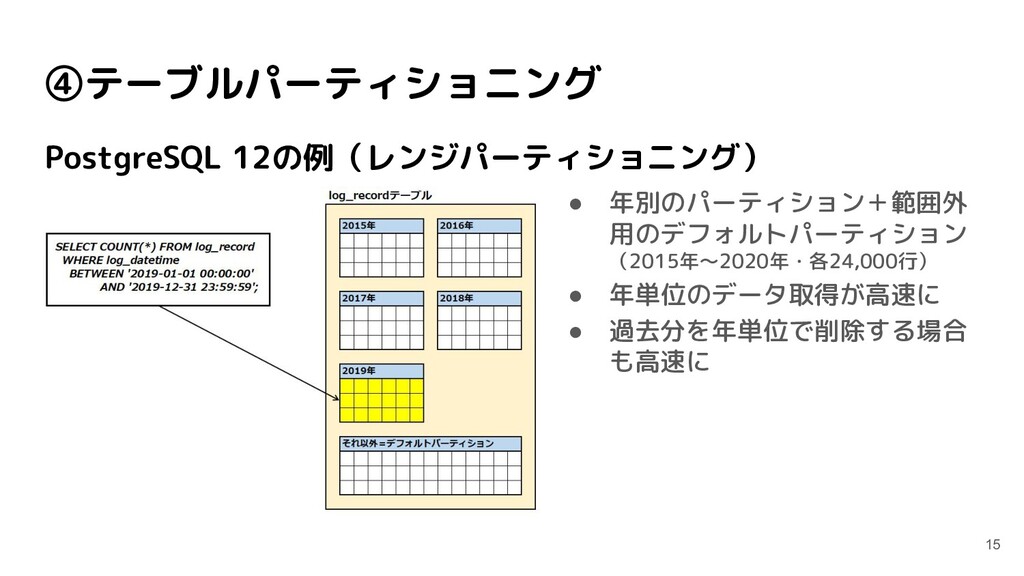
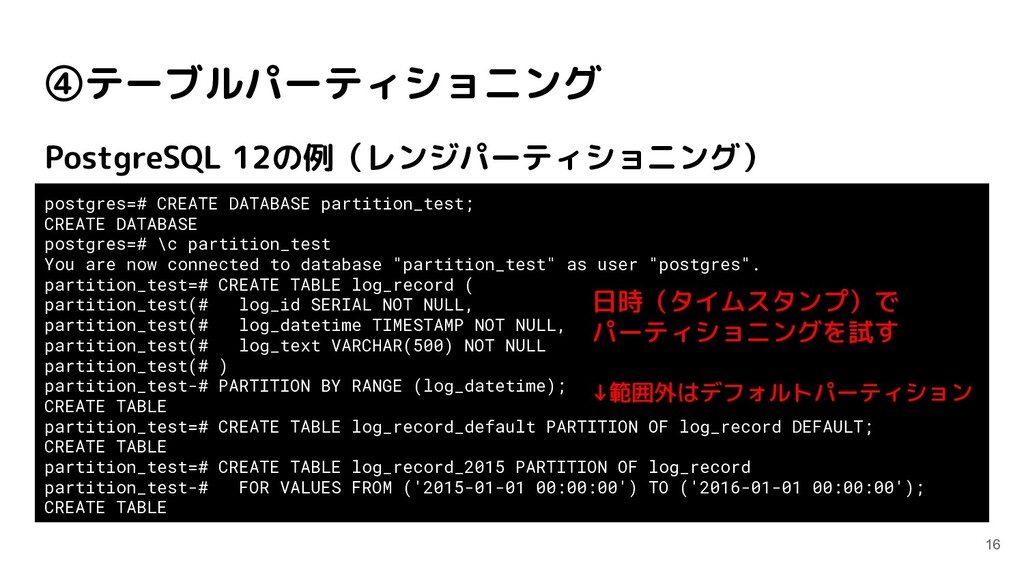
postgres=# \c partition_test You are now connected to database "partition_test" as user "postgres". partition_test=# CREATE TABLE log_record ( partition_test(# log_id SERIAL NOT NULL, partition_test(# log_datetime TIMESTAMP NOT NULL, partition_test(# log_text VARCHAR(500) NOT NULL partition_test(# ) partition_test-# PARTITION BY RANGE (log_datetime); CREATE TABLE partition_test=# CREATE TABLE log_record_default PARTITION OF log_record DEFAULT; CREATE TABLE partition_test=# CREATE TABLE log_record_2015 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2015-01-01 00:00:00') TO ('2016-01-01 00:00:00'); CREATE TABLE 日時(タイムスタンプ)で パーティショニングを試す ↓範囲外はデフォルトパーティション
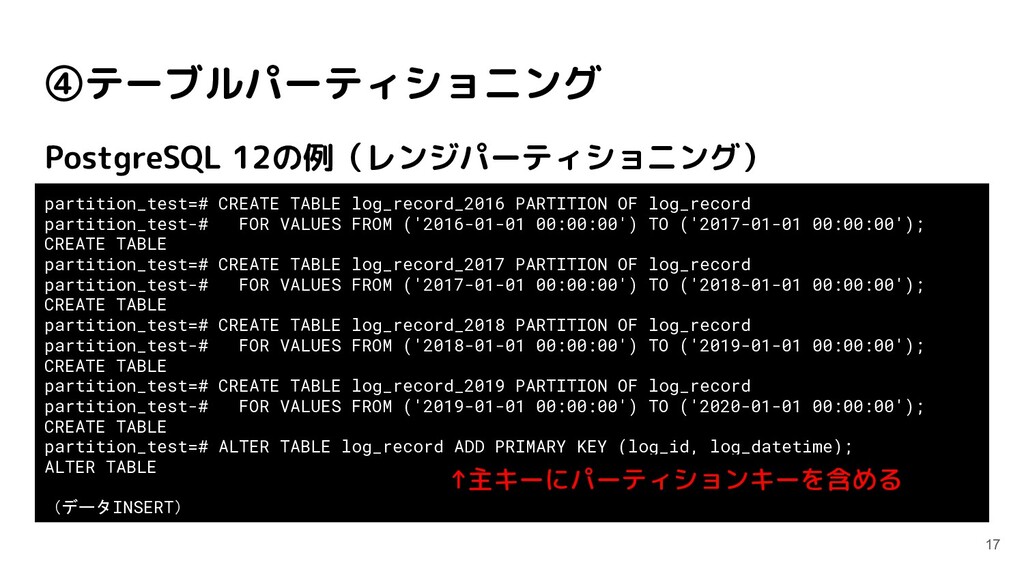
log_record partition_test-# FOR VALUES FROM ('2016-01-01 00:00:00') TO ('2017-01-01 00:00:00'); CREATE TABLE partition_test=# CREATE TABLE log_record_2017 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2017-01-01 00:00:00') TO ('2018-01-01 00:00:00'); CREATE TABLE partition_test=# CREATE TABLE log_record_2018 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2018-01-01 00:00:00') TO ('2019-01-01 00:00:00'); CREATE TABLE partition_test=# CREATE TABLE log_record_2019 PARTITION OF log_record partition_test-# FOR VALUES FROM ('2019-01-01 00:00:00') TO ('2020-01-01 00:00:00'); CREATE TABLE partition_test=# ALTER TABLE log_record ADD PRIMARY KEY (log_id, log_datetime); ALTER TABLE (データINSERT) ↑主キーにパーティションキーを含める
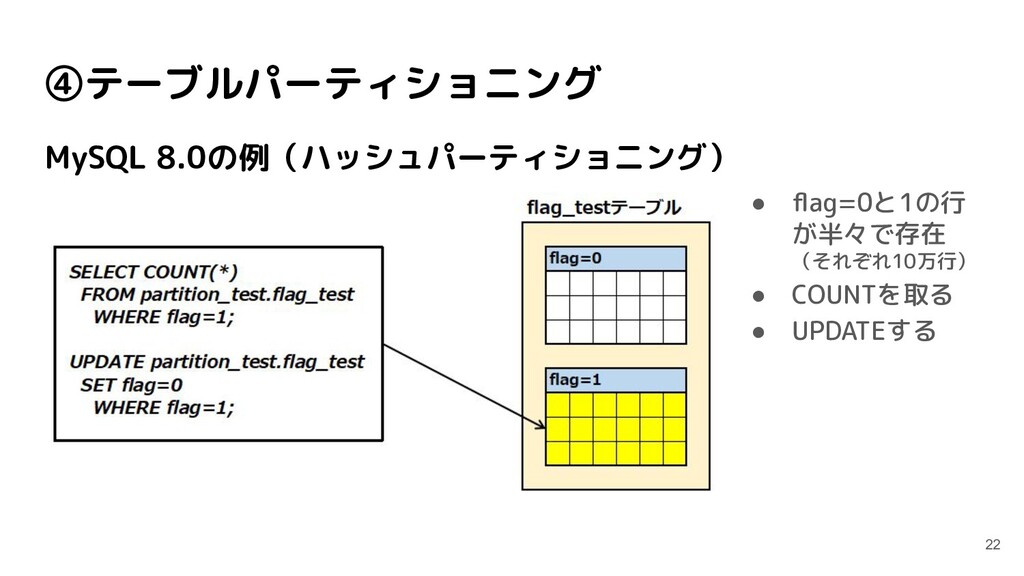
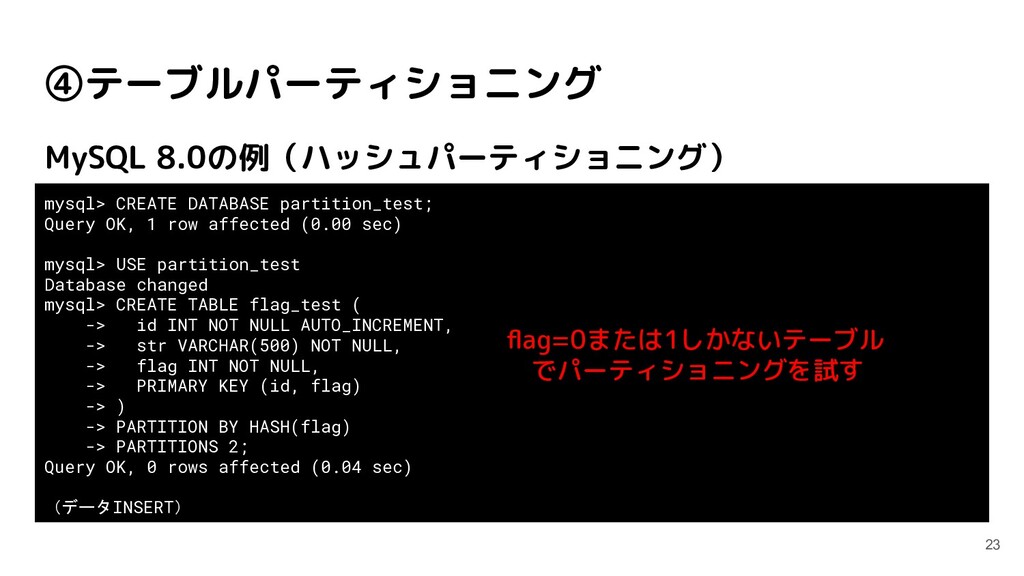
partition_test=# \c no_partition_test You are now connected to database "no_partition_test" as user "postgres". no_partition_test=# CREATE TABLE log_record ( no_partition_test(# log_id SERIAL NOT NULL, no_partition_test(# log_datetime TIMESTAMP NOT NULL, no_partition_test(# log_text VARCHAR(500) NOT NULL no_partition_test(# ); CREATE TABLE no_partition_test=# ALTER TABLE log_record ADD PRIMARY KEY (log_id); ALTER TABLE no_partition_test=# CREATE INDEX ON log_record (log_datetime); CREATE INDEX (データINSERT) 比較用に非パーティショニング のテーブルも用意する 全く同じデータをINSERTする
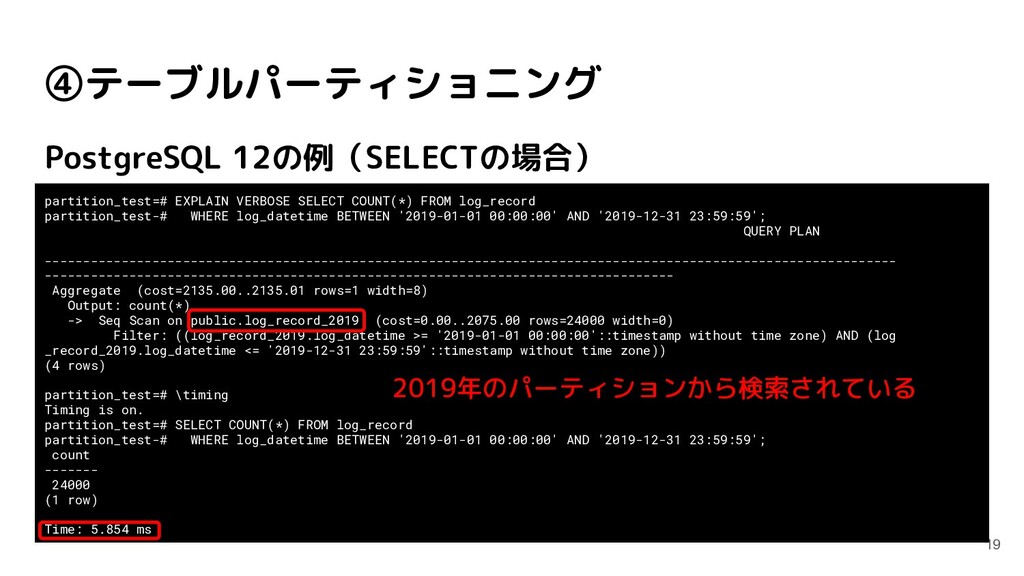
log_record partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; QUERY PLAN --------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------- Aggregate (cost=2135.00..2135.01 rows=1 width=8) Output: count(*) -> Seq Scan on public.log_record_2019 (cost=0.00..2075.00 rows=24000 width=0) Filter: ((log_record_2019.log_datetime >= '2019-01-01 00:00:00'::timestamp without time zone) AND (log _record_2019.log_datetime <= '2019-12-31 23:59:59'::timestamp without time zone)) (4 rows) partition_test=# \timing Timing is on. partition_test=# SELECT COUNT(*) FROM log_record partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; count ------- 24000 (1 row) Time: 5.854 ms 2019年のパーティションから検索されている
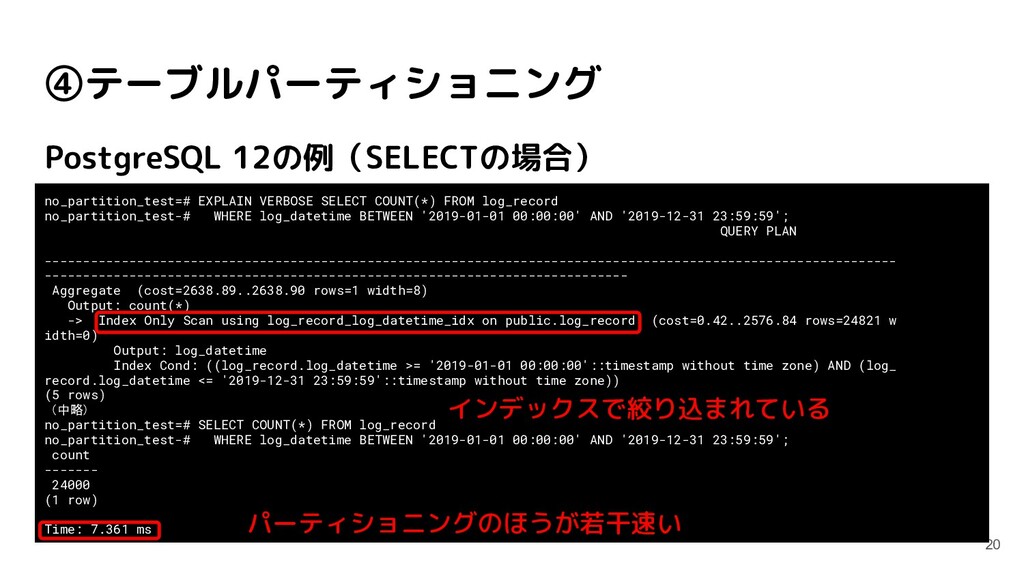
log_record no_partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; QUERY PLAN --------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------- Aggregate (cost=2638.89..2638.90 rows=1 width=8) Output: count(*) -> Index Only Scan using log_record_log_datetime_idx on public.log_record (cost=0.42..2576.84 rows=24821 w idth=0) Output: log_datetime Index Cond: ((log_record.log_datetime >= '2019-01-01 00:00:00'::timestamp without time zone) AND (log_ record.log_datetime <= '2019-12-31 23:59:59'::timestamp without time zone)) (5 rows) (中略) no_partition_test=# SELECT COUNT(*) FROM log_record no_partition_test-# WHERE log_datetime BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59'; count ------- 24000 (1 row) Time: 7.361 ms インデックスで絞り込まれている パーティショニングのほうが若干速い
Time: 7.023 ms partition_test=# SELECT COUNT(*) FROM log_record partition_test-# WHERE log_datetime BETWEEN '2015-01-01 00:00:00' AND '2015-12-31 23:59:59'; count ------- 0 (1 row) no_partition_test=# DELETE FROM log_record no_partition_test-# WHERE log_datetime BETWEEN '2015-01-01 00:00:00' AND '2015-12-31 23:59:59'; DELETE 24000 Time: 123.978 ms no_partition_test=# SELECT COUNT(*) FROM log_record no_partition_test-# WHERE log_datetime BETWEEN '2015-01-01 00:00:00' AND '2015-12-31 23:59:59'; count ------- 0 (1 row) パーティショニングの場合は子テーブルをDROPする パーティショニングを利用してDROPしたほうが速い 非パーティショニングの場合はDELETEする
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![④テーブルパーティショニング MySQL 8.0の場合 • パーティションの種類(区分方法)は4種類(バリエーション含め8種類) ◦ RANGE [COLUMNS] レンジ(範囲) ◦](https://files.speakerdeck.com/presentations/e80e5deafec14ed48fbccb4ddf752ae9/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
![④テーブルパーティショニング カーディナリティとは • カラム(列)値のばらつき(値が何種類あるか?) ◦ [例1] 0と1 : 2 ◦](https://files.speakerdeck.com/presentations/e80e5deafec14ed48fbccb4ddf752ae9/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}