Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
TAID: Temporally Adaptive Interpolated Distilla...
Search
ほき
March 22, 2025
Research
33
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
ほき
March 22, 2025
More Decks by ほき
See All by ほき
Expert-Level Detection of Epilepsy Markers in EEG on Short and Long Timescales
hokkey621
0
39
MMaDA: Multimodal Large Diffusion Language Models
hokkey621
0
32
脳波を用いた嗜好マッチングシステム
hokkey621
0
520
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
hokkey621
0
99
Learning to Model the World with Language
hokkey621
0
37
GeminiとUnityで実現するインタラクティブアート
hokkey621
0
1.7k
LT - Gemma Developer Time
hokkey621
0
25
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
hokkey621
0
42
イベントを主催してわかった運営のノウハウ
hokkey621
0
84
Other Decks in Research
See All in Research
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
R&Dチームを起ち上げる
shibuiwilliam
1
270
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
990
事後確率分布の共分散について
koide3
0
140
「AIとWhyを深堀る」をAIと深堀る
iflection
0
490
AIで最適化を解けるか?
mickey_kubo
0
120
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
290
定数整数除算・剰余算最適化再考
herumi
1
130
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
3.7k
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
2
300
コーディングエージェントとABNを再考
hf149
2
710
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
410
Featured
See All Featured
Marketing to machines
jonoalderson
1
5.5k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
730
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Git: the NoSQL Database
bkeepers
PRO
432
67k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
340
AI: The stuff that nobody shows you
jnunemaker
PRO
8
720
Test your architecture with Archunit
thirion
1
2.3k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
350
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
210
Transcript
https://www.academix.jp/ AcademiX 論文輪読会 TAID: Temporally Adaptive Interpolated Distillation for Efficient
Knowledge Transfer in Language Models ほき 2025/03/22
書誌情報 • TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge
Transfer in Language Models • Makoto Shing, Kou Misaki, Han Bao, Sho Yokoi, Takuya Akiba • ICLR 2025 • https://doi.org/10.48550/arXiv.2501.16937 ※本スライドの図は本論文またはSakana AIのテックブログより引用 2
LMsの活用と課題 • LMsは様々な分野で重要なツール • LMsは広く導入するには課題有り ◦ モデルサイズが大きすぎる ◦ デコード時間が長すぎる ◦
学習や推論に必要なエネルギー多すぎる • 大規模モデルを圧縮して小規模なモデルにしたい 3
知識蒸留 • 高性能なLLM(教師モデル)が自身の知識をSLM(生徒モデル)に移転 • 教師モデルの考え方も教示可能 4
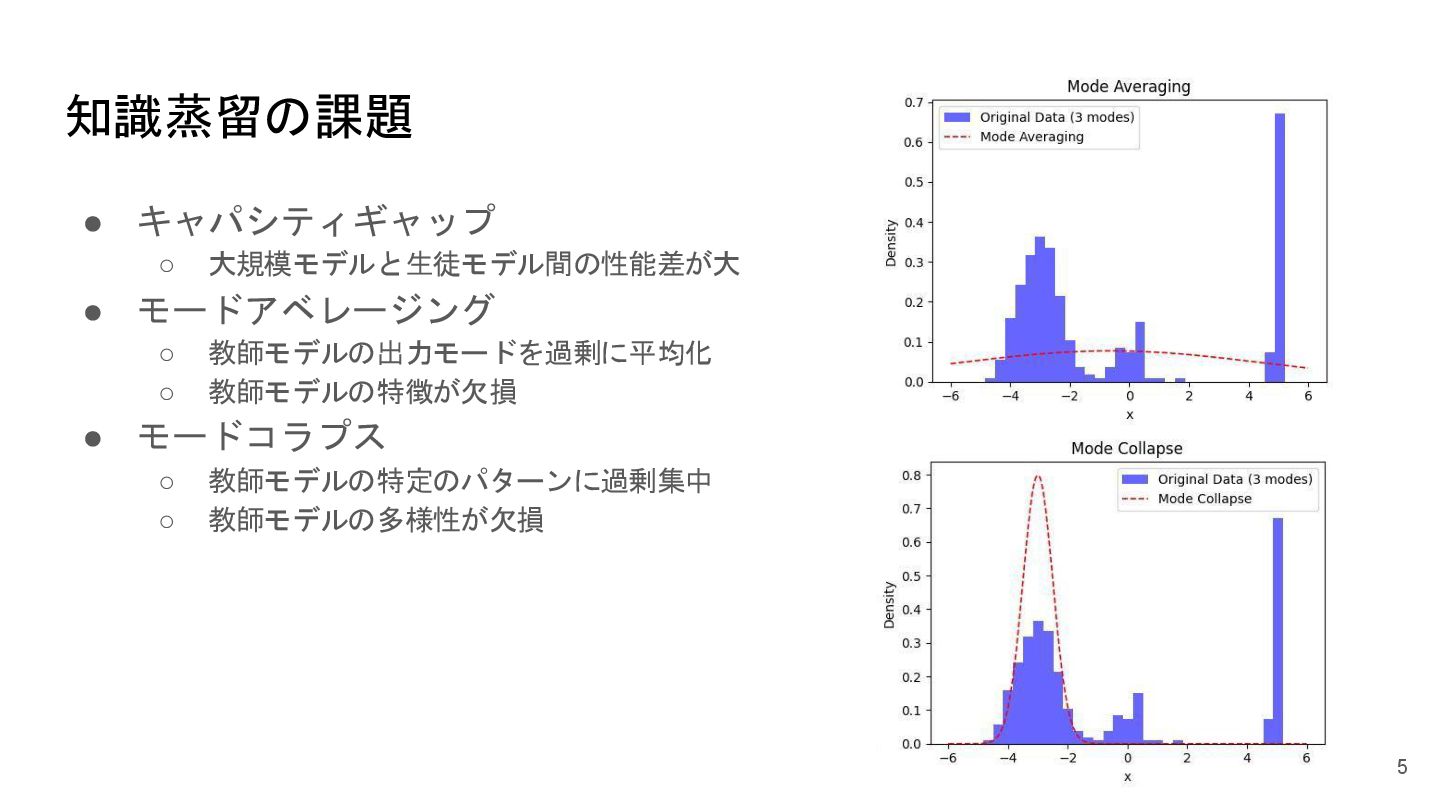
知識蒸留の課題 • キャパシティギャップ ◦ 大規模モデルと生徒モデル間の性能差が大 • モードアベレージング ◦ 教師モデルの出力モードを過剰に平均化 ◦
教師モデルの特徴が欠損 • モードコラプス ◦ 教師モデルの特定のパターンに過剰集中 ◦ 教師モデルの多様性が欠損 5
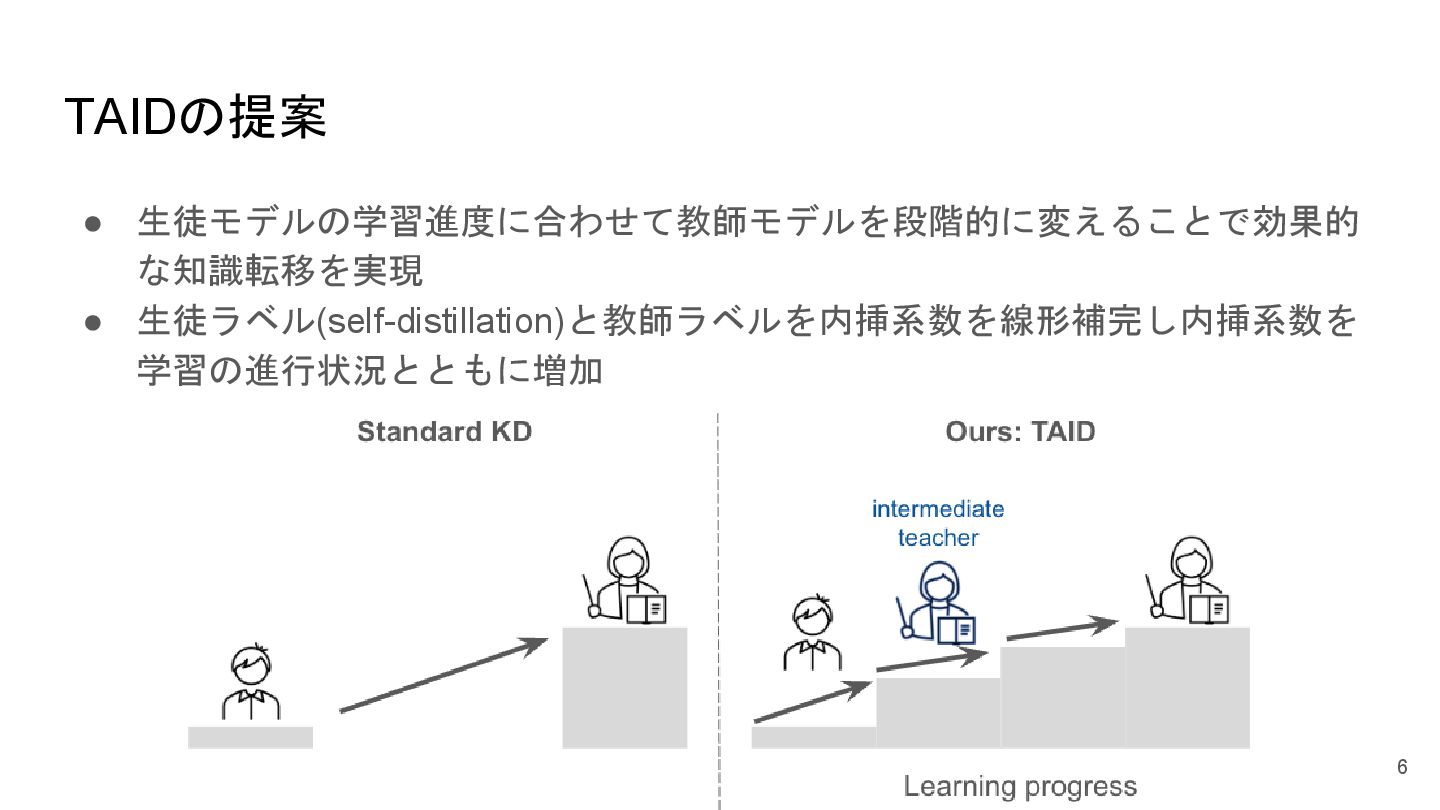
TAIDの提案 • 生徒モデルの学習進度に合わせて教師モデルを段階的に変えることで効果的 な知識転移を実現 • 生徒ラベル(self-distillation)と教師ラベルを内挿系数を線形補完し内挿系数を 学習の進行状況とともに増加 6
(前提)言語モデル蒸留の問題設定 • トークン列全体(𝑦)の確率は 7 • 各トークン(𝑦𝑠 )の条件付き確率は
(前提)従来の蒸留手法 • 十分に学習された教師モデル𝑝と𝑞𝜃 の出力分布間の差を最小化 8
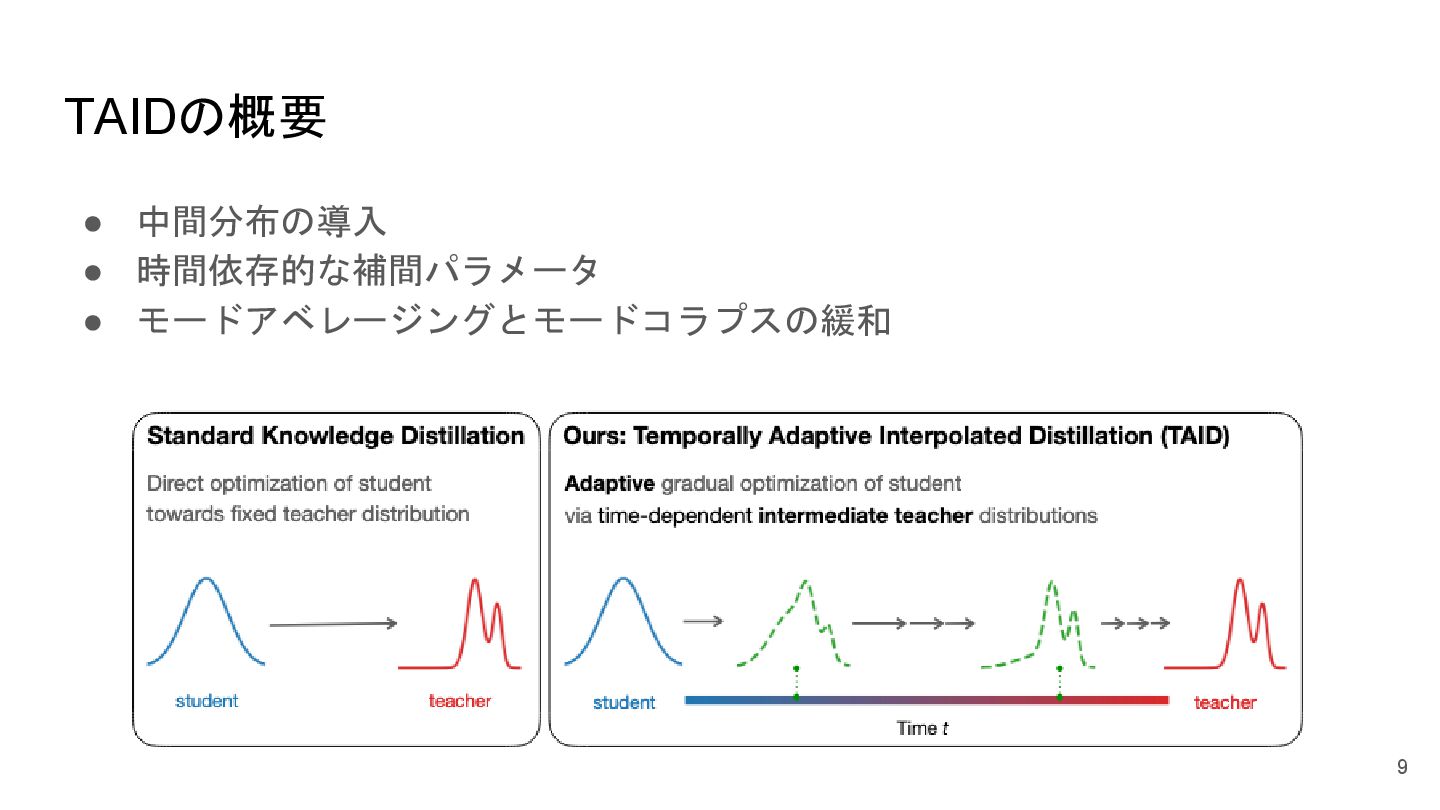
TAIDの概要 • 中間分布の導入 • 時間依存的な補間パラメータ • モードアベレージングとモードコラプスの緩和 9
TEMPORALLY INTERPOLATED DISTRIBUTION • 中間分布𝑝𝑡 と生徒分布𝑞𝜃 間のKL情報量を最小化 10 • 補完パラメータt
についてTAID補完分布𝑝𝑡 は次のように定義 • 初期学習(t≈0): 自身のモードを強調,自己蒸留に近い学習(効果:一般化能力の向上) • 中間学習(0<t<1): 生徒モデルの特徴と教師モデルの知識が融合(効果:安定した知識移転) • 最終学習(t≈1):教師モデルの知識を強く反映 (効果:高度な知識の獲得と性能向上)
ADAPTIVE INTERPOLATION PARAMETER UPDATE • より効率的な更新メカニズムを提案 • 目的関数を次の式で定義 11 •
𝛿𝑛 :目的関数の相対的な変化量(学習進捗を示す指標) ◦ 大きい場合(トレーニング初期段階) ▪ 学習が順調に進んでいるため、補完パラメータtを積極的に増加 ◦ 小さい場合(生徒モデルが教師モデルに近づいた段階) ▪ 学習が停滞しているため、慎重にtを調整し安定した学習を維持
TAIDの訓練アルゴリズム 12
モード崩壊についての理論的分析 • ごめんなさいよくわからなかったので論文を見てください 13
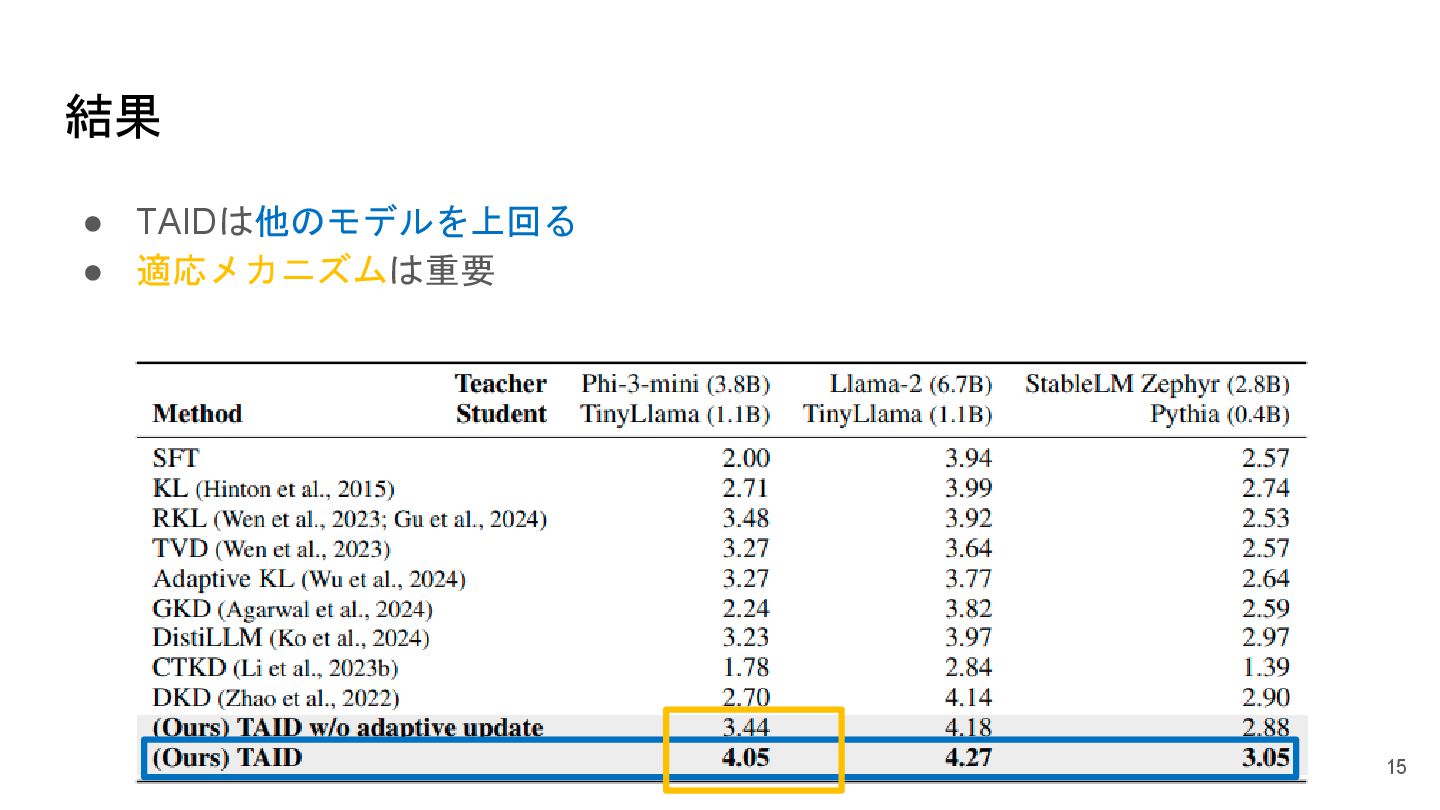
指示チューニングの実験 • 目的:モデルの性能を評価 • ベンチマーク:MT-Bench [Zheng, 2023] • 使用モデル 14
教師モデル 生徒モデル Phi-3-mini-4k-instruct TinyLlama Llama-2-7b-chat TinyLlama StableLM Zephyr 3B Pythia-410M
結果 • TAIDは他のモデルを上回る • 適応メカニズムは重要 15
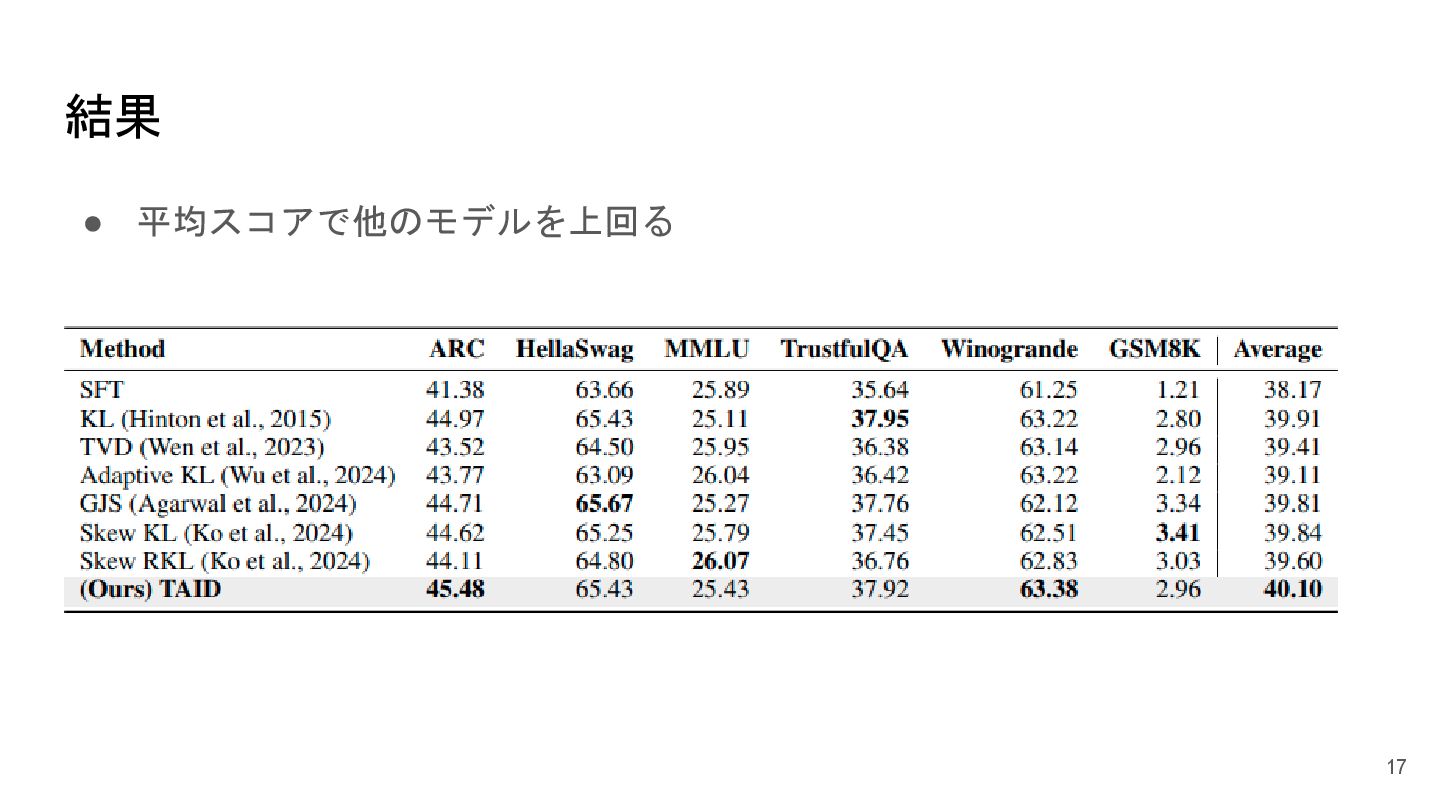
事前学習実験 • 目的:知識蒸留の効果を評価 • ベンチマーク:6つの異なるタスクを含む評価セット • 方法:Few-shot 評価に基づきモデルの基礎能力をテスト • 使用モデル
◦ 教師モデル:Phi-3-medium-4k-instruct ◦ 生徒モデル:TinyLlama 16
結果 • 平均スコアで他のモデルを上回る 17
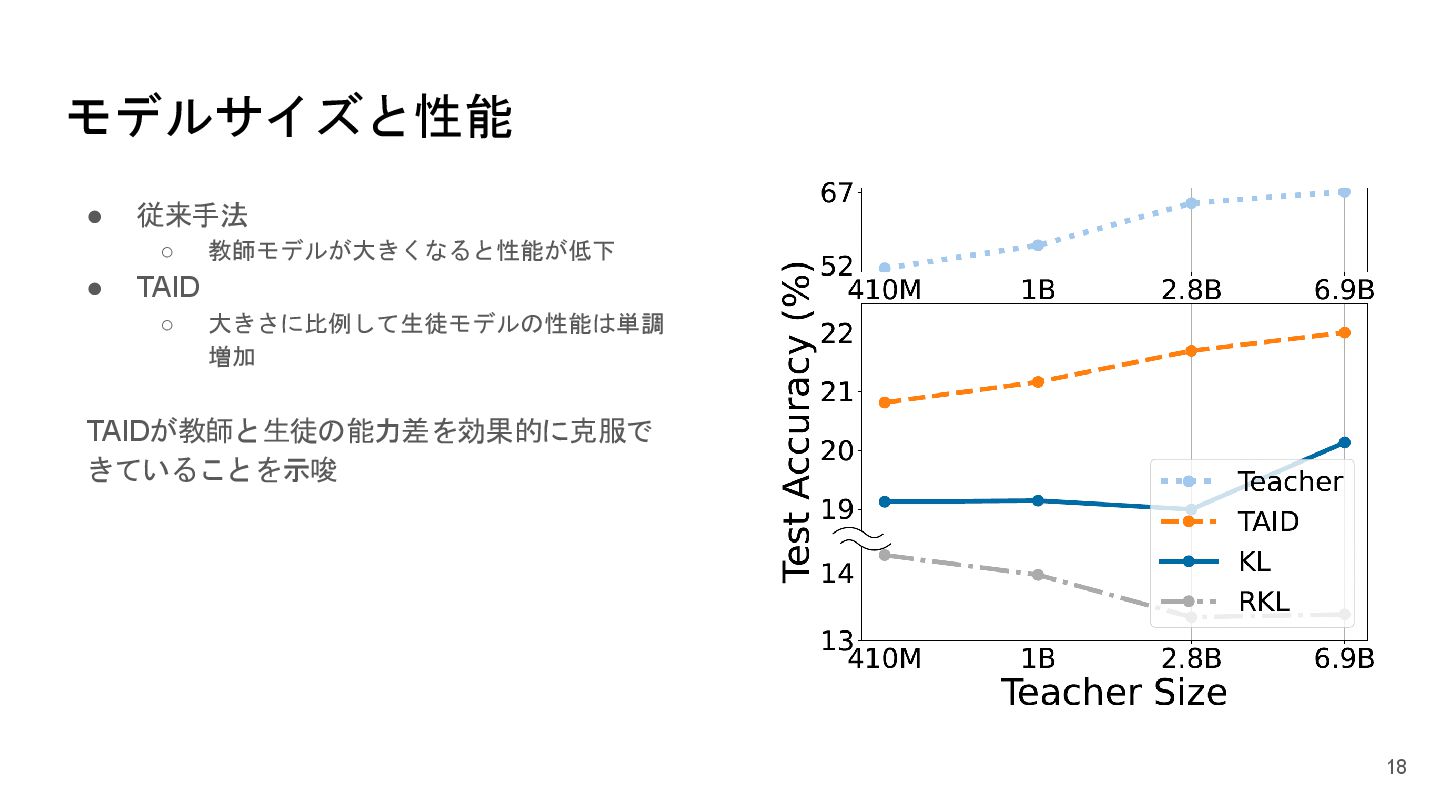
モデルサイズと性能 • 従来手法 ◦ 教師モデルが大きくなると性能が低下 • TAID ◦ 大きさに比例して生徒モデルの性能は単調 増加
TAIDが教師と生徒の能力差を効果的に克服で きていることを示唆 18
応用 • 日本語SLM「TinySwallow-1.5B」を開発 ◦ 320億パラメータのLLMから約1/20の大きさの15億パラメータのSLMへTAIDによる知識蒸留 を行うことで構築 • 日本語での言語モデルベンチマークにおいて、同規模のモデルの中で最高性 能を達成 19
まとめ • 大規模言語モデルの課題を知識蒸留を使って解決 • 中間分布を活用することによって蒸留の課題に対処 • ほかモデルを上回る結果を達成 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![指示チューニングの実験 • 目的:モデルの性能を評価 • ベンチマーク:MT-Bench [Zheng, 2023] • 使用モデル 14](https://files.speakerdeck.com/presentations/b2a613bc24174f7cb472940bd0a596f1/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}