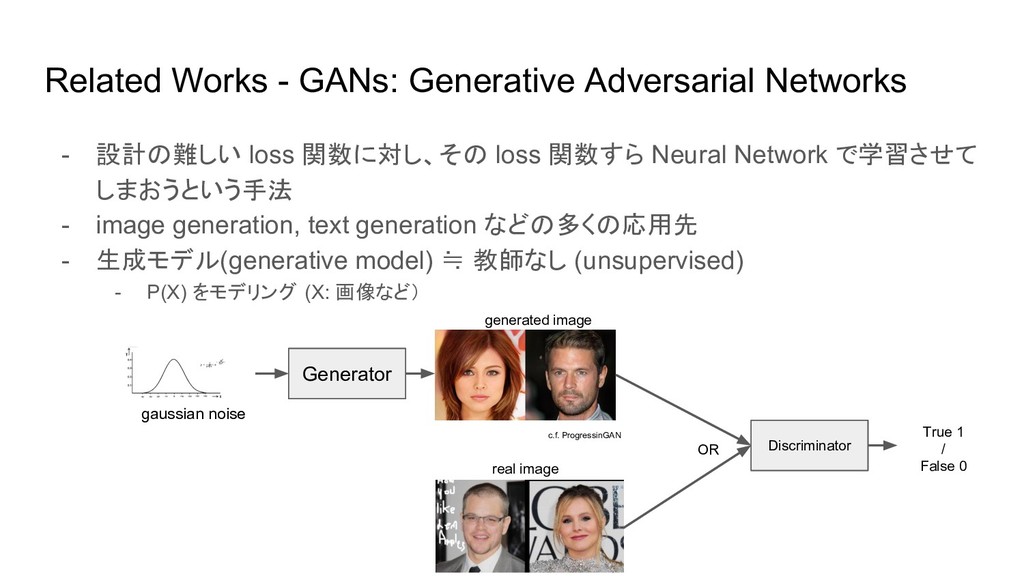
関数に対し、その loss 関数すら Neural Network で学習させて しまおうという手法 - image generation, text generation などの多くの応用先 - 生成モデル(generative model) ≒ 教師なし (unsupervised) - P(X) をモデリング (X: 画像など) Generator c.f. ProgressinGAN gaussian noise generated image OR Discriminator real image True 1 / False 0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
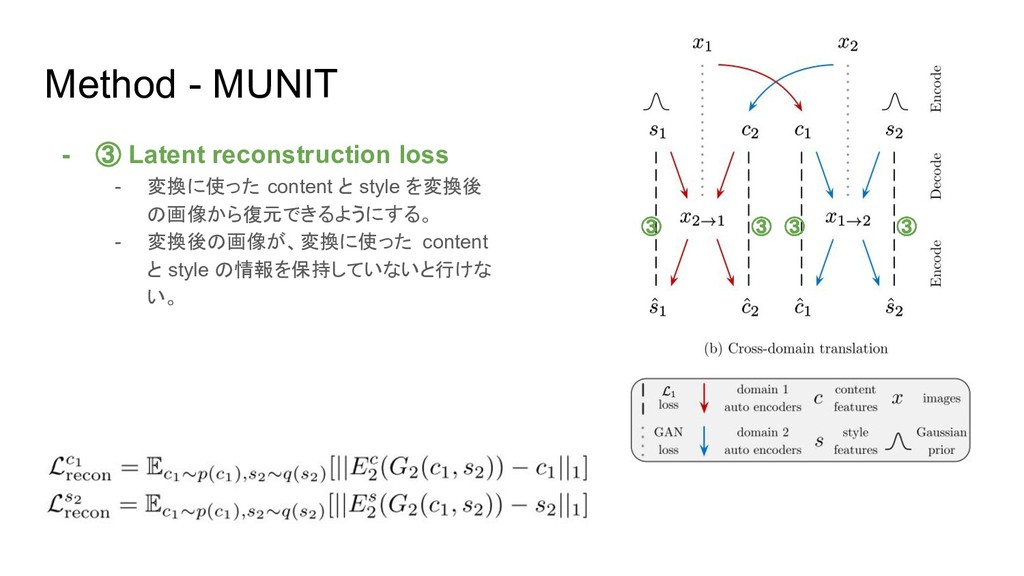{kind=link}
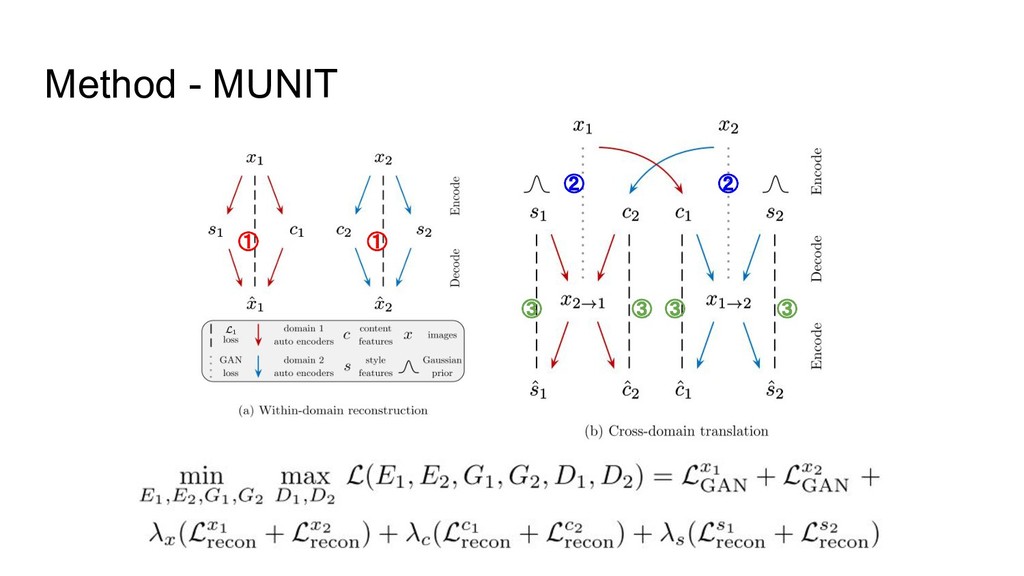{kind=link}
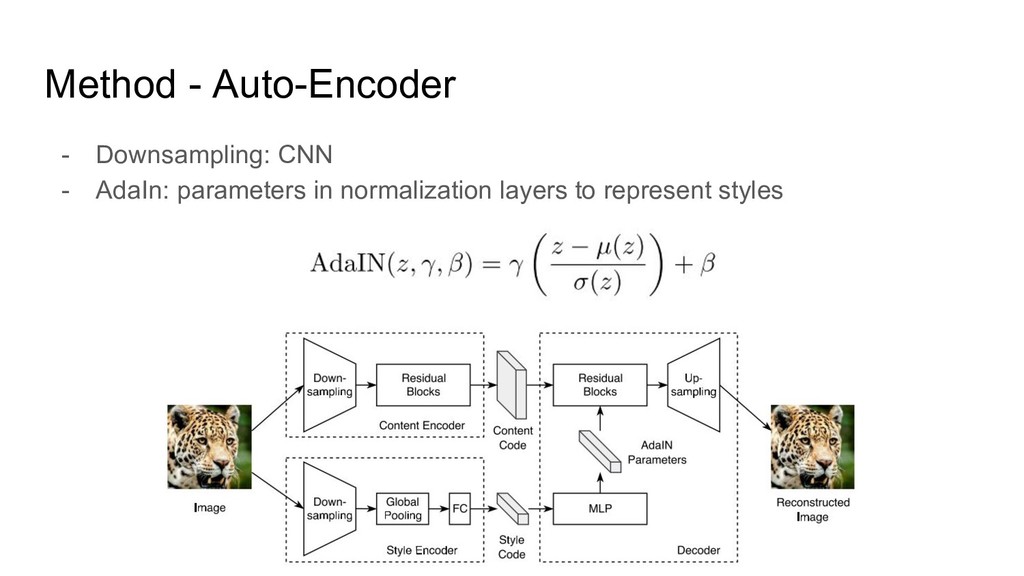{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
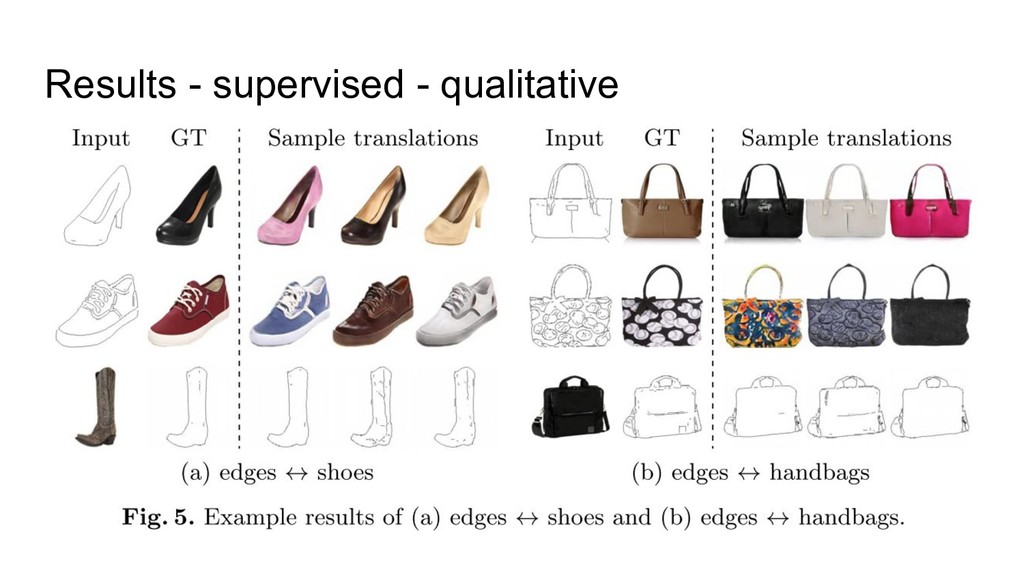{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}