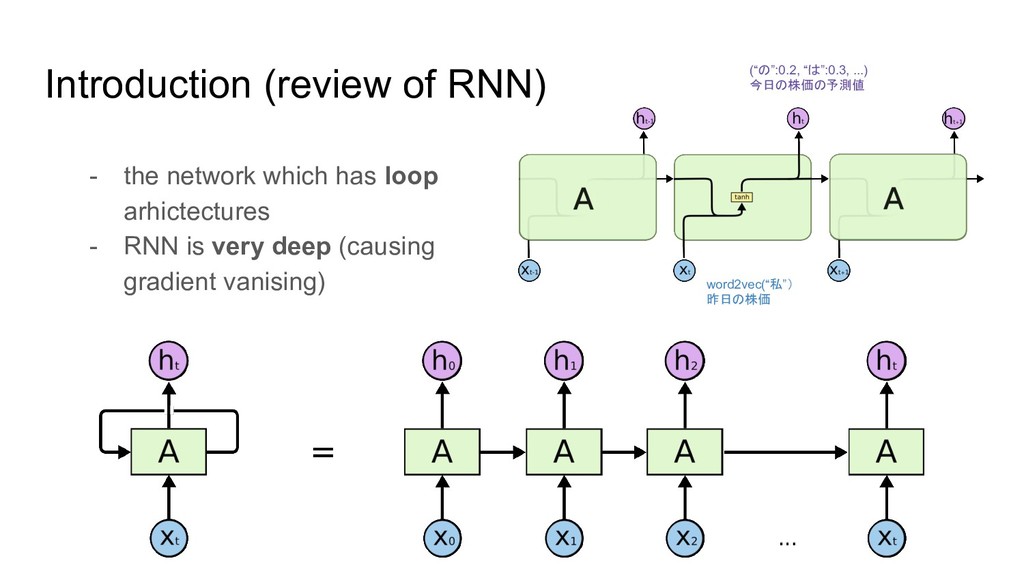
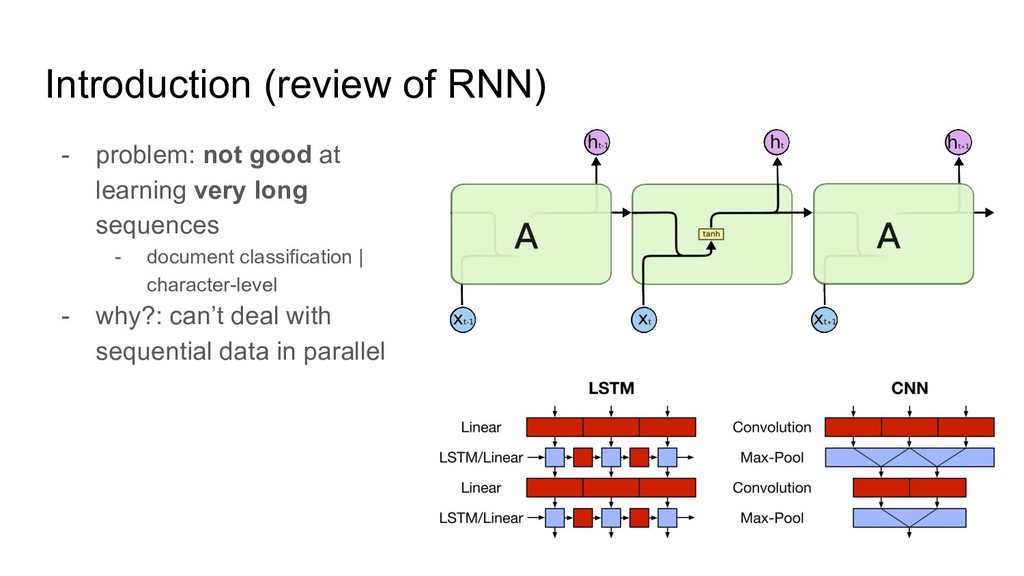
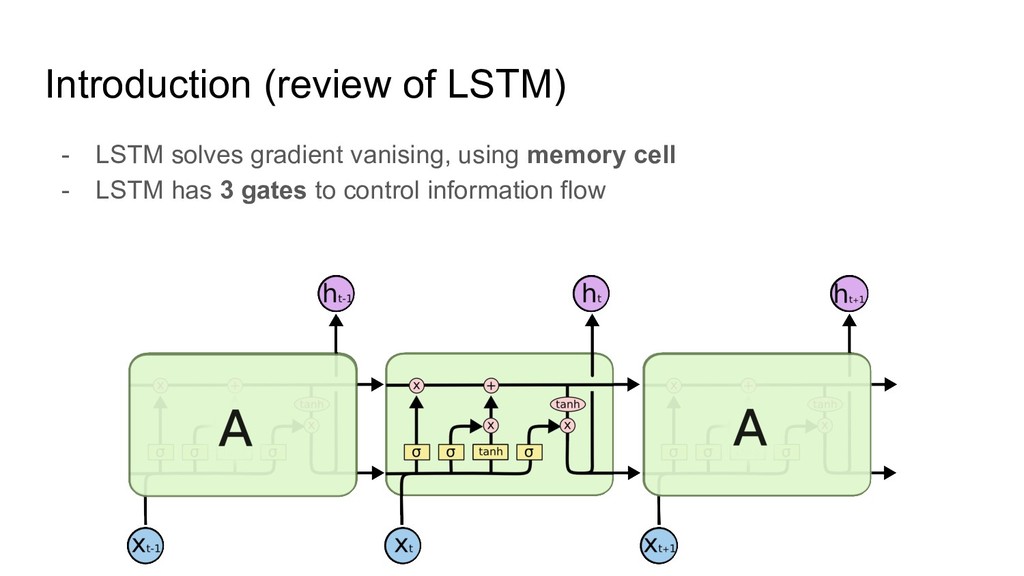
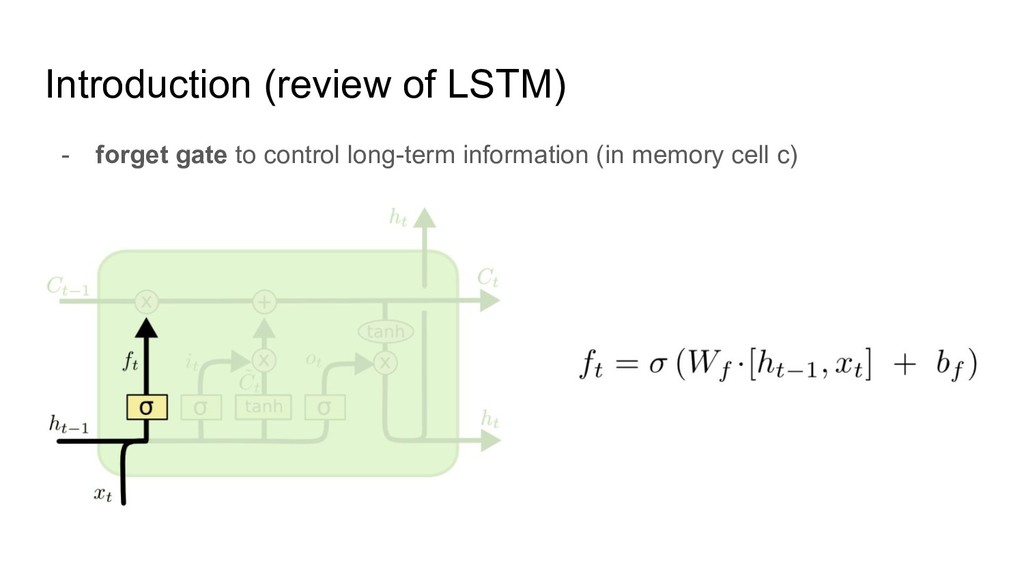
https://qiita.com/KojiOhki/items/89cd7b69a8a6239d67ca - ニューラルネットワーク勉強会 http://isw3.naist.jp/~neubig/student/2015/seitaro-s/161025neuralnet_study_LSTM.pdf - conv の 3D図作成 - thinkercad https://www.tinkercad.com/ - QRNN - LSTMを超える期待の新星、QRNN https://qiita.com/icoxfog417/items/d77912e10a7c60ae680e - slideshare https://www.slideshare.net/DeepLearningJP2016/dlquasirecurrent-neural-networks?qid=a4ead77d-d8dd-458b-965c-5e53723d7757 &v=&b=&from_search=1 - pytorchでの公式実装 https://github.com/salesforce/pytorch-qrnn/blob/master/torchqrnn/qrnn.py
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
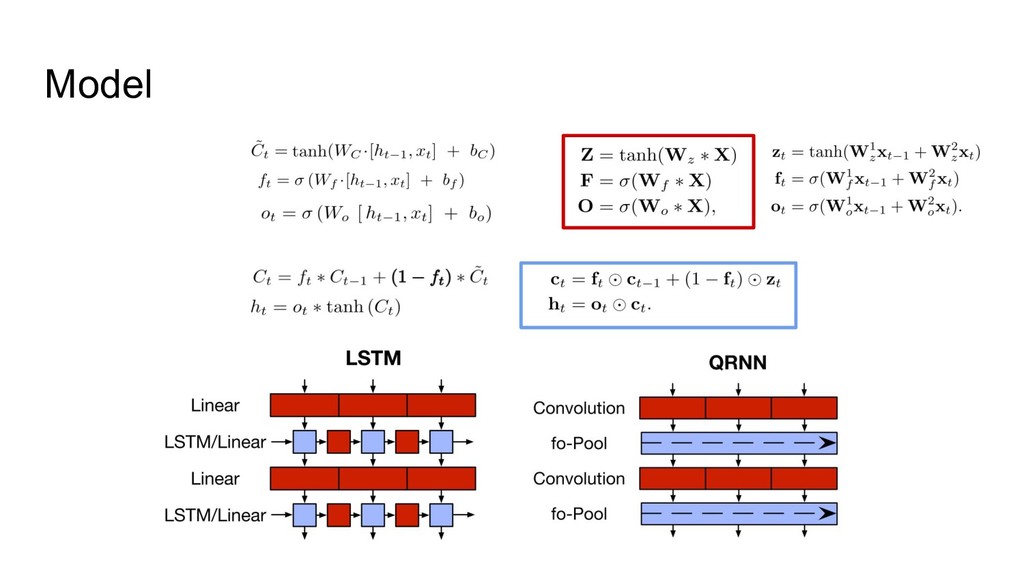
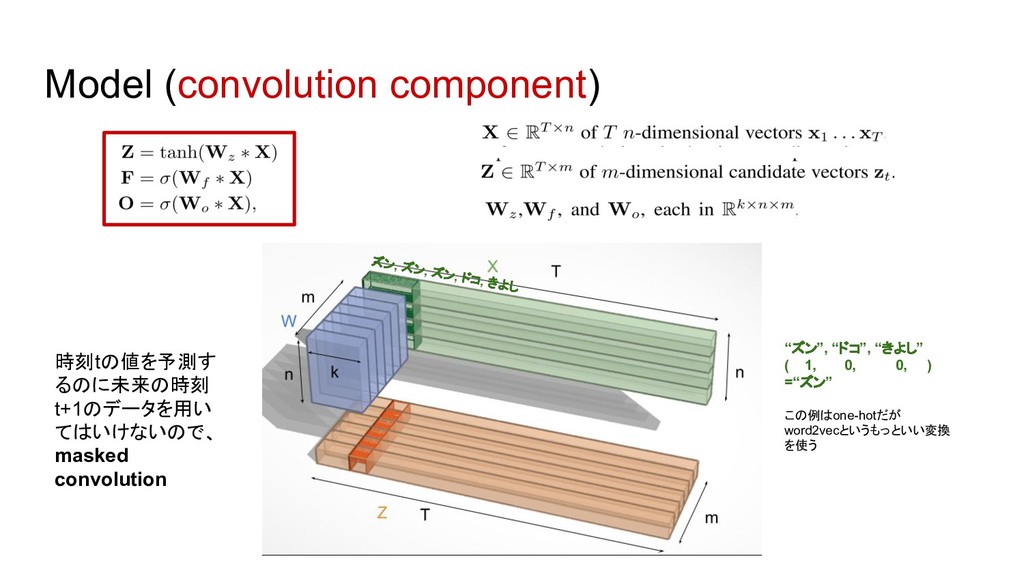
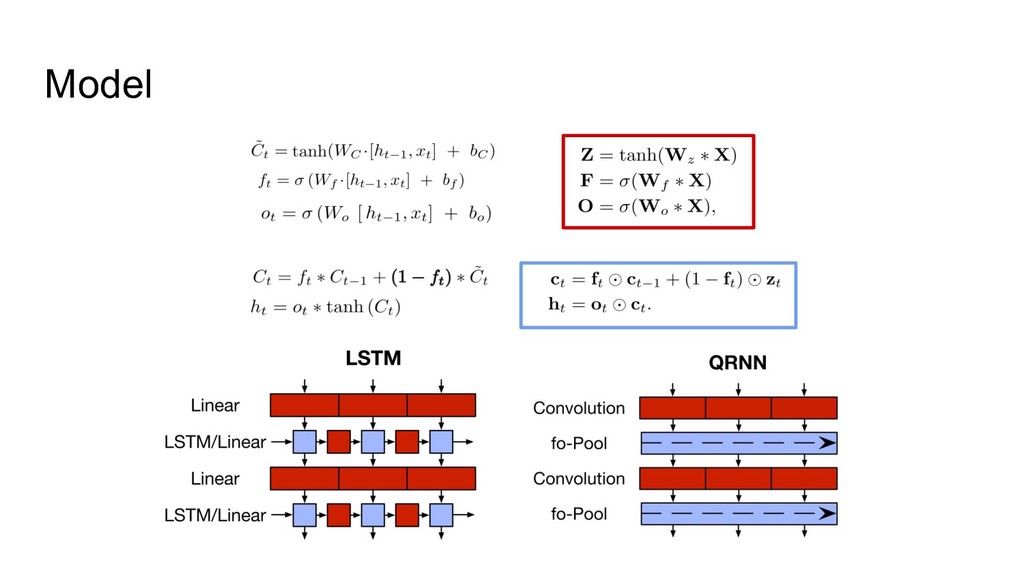
![bottle-neckになっていた前の層のhidden state h[t-1] を用いるのではなく、前の時刻 の入力x[t-1/2/...]を用いて並列処理を可能 にした。 Model (pooling component) LSTM](https://files.speakerdeck.com/presentations/de9daa37d8be4ed490d1c4e3527dae3a/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
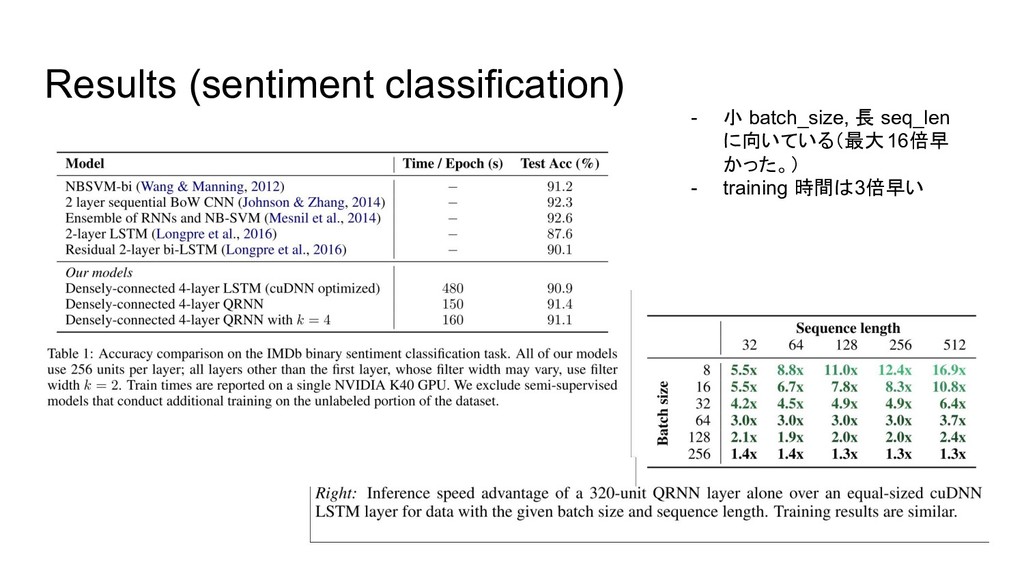{kind=link}
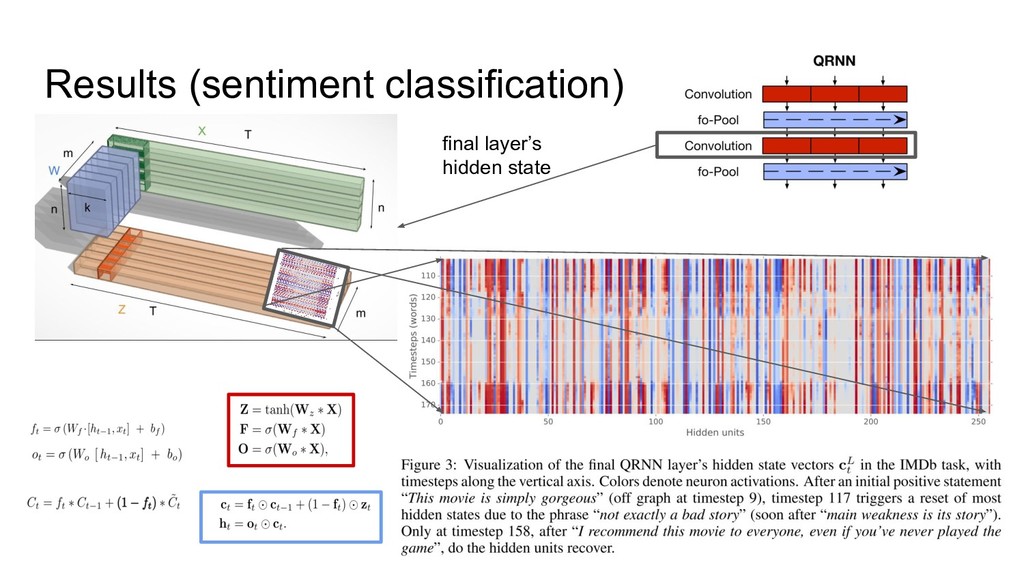{kind=link}
{kind=link}
{kind=link}
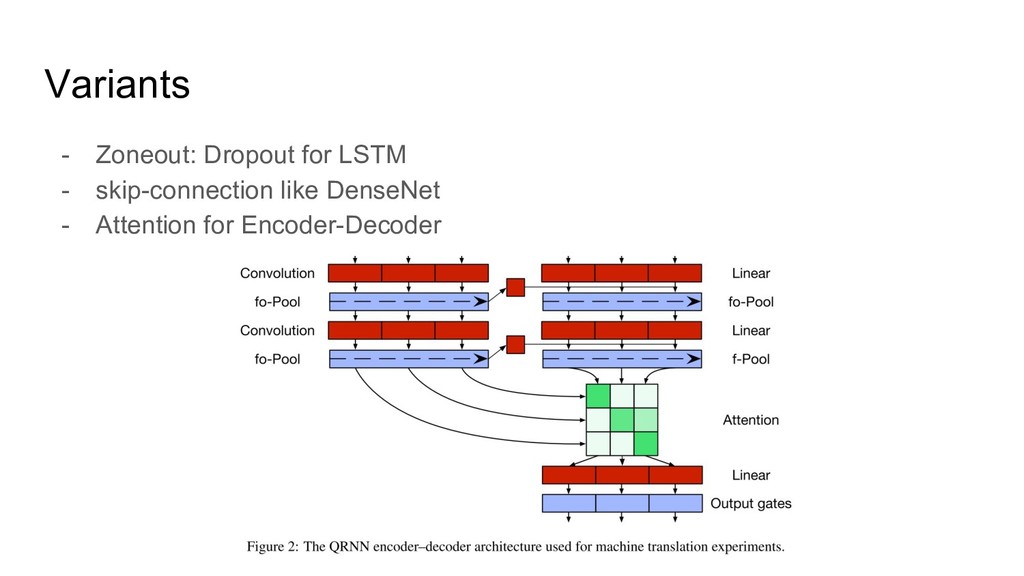
![考察 - LSTMに精度で少し負けてしまった理由は、隠れ層の状態 h[t-1] ではなく、直前の 入力 x[t-1|t-2|,...]を使って近似したからと考えられる。 - 入力で、隠れ層の状態を近似する場合、使う、前の時刻の filter](https://files.speakerdeck.com/presentations/de9daa37d8be4ed490d1c4e3527dae3a/slide_23.jpg){kind=link}
{kind=link}
{kind=link}