sequence の続きを N本 sample して、完結させる - generator を使って続きを生成する - Monte Carlo search:たくさんサンプルして、確率分布を推定する方法 - 今回は sequence の続きを確率変数とみなしている - 無理矢理完結させた N本の sequence に対する discriminator の評価の平均を生成途中の sequence の value とする - つまり生成途中の sequence からどんな sequence が最終的に得られるかをシミュレーションして、 途中 の sequence の価値を決める 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
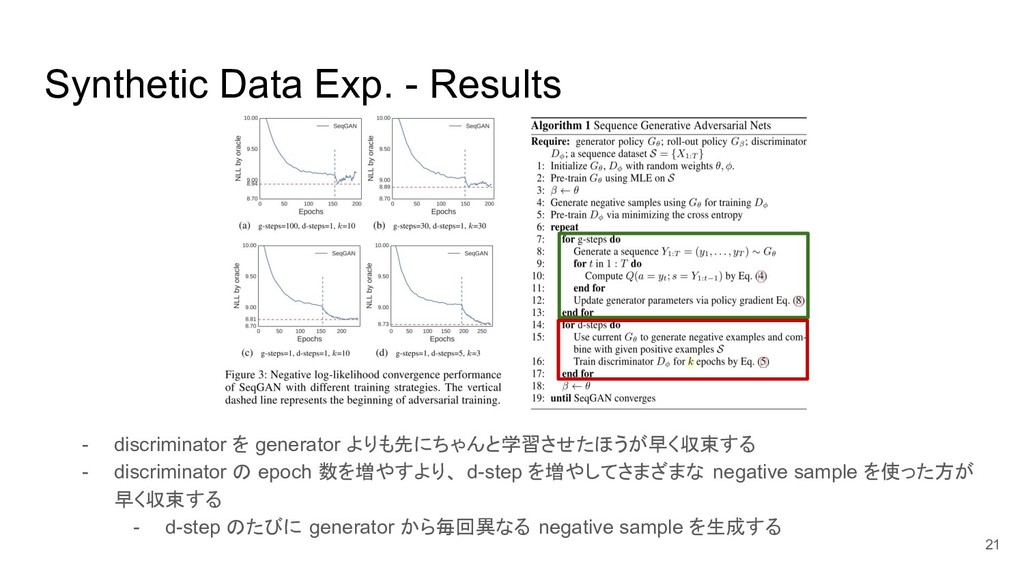{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}