Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_20180518_Pixel-Level Domain Transfer
Search
hrsma2i
May 18, 2018
Research
65
0
Share
文献紹介_20180518_Pixel-Level Domain Transfer
文献紹介
hrsma2i
May 18, 2018
More Decks by hrsma2i
See All by hrsma2i
文献紹介_20181123_SeqGAN_ Sequence Generative Adversarial Nets with Policy Gradient
hrsma2i
0
83
文献紹介_20180622_MUNIT _ Multimodal Unsupervised Image-to-Image Translation
hrsma2i
0
100
文献紹介_20180420_CSN _ Learning Type-Aware Embeddings for Fashion Compatibility
hrsma2i
0
190
文献紹介_20171110_QRNN _ Quasi-Recurrent Neural Networks
hrsma2i
0
53
Other Decks in Research
See All in Research
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
0
230
NLP colloquium: AI Safety Survey
kanekomasahiro
0
460
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
220
ペットのかわいい瞬間を撮影する オートシャッターAIアプリへの スマートラベリングの適用
mssmkmr
0
500
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
160
台湾モデルに学ぶ詐欺広告対策:市民参加の必要性
dd2030
0
340
明日から使える!研究効率化ツール入門
matsui_528
13
7.1k
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
110
Ankylosing Spondylitis
ankh2054
0
170
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
120
「車1割削減、渋滞半減、公共交通2倍」を 熊本から岡山へ@RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
1
1.1k
都市交通マスタープランとその後への期待@熊本商工会議所・熊本経済同友会
trafficbrain
0
210
Featured
See All Featured
Producing Creativity
orderedlist
PRO
348
40k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Google's AI Overviews - The New Search
badams
0
1k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Mind Mapping
helmedeiros
PRO
1
210
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
210
Being A Developer After 40
akosma
91
590k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
230
Transcript
文献紹介 Pixel-Level Domain Transfer author: Yoo, Donggeun
abstract - street outfit image から shop per-garment image の生成
Table of Contents - Introduction - Domain adaptation - GANs
- Method - Results - manual evaluation - automated evaluation
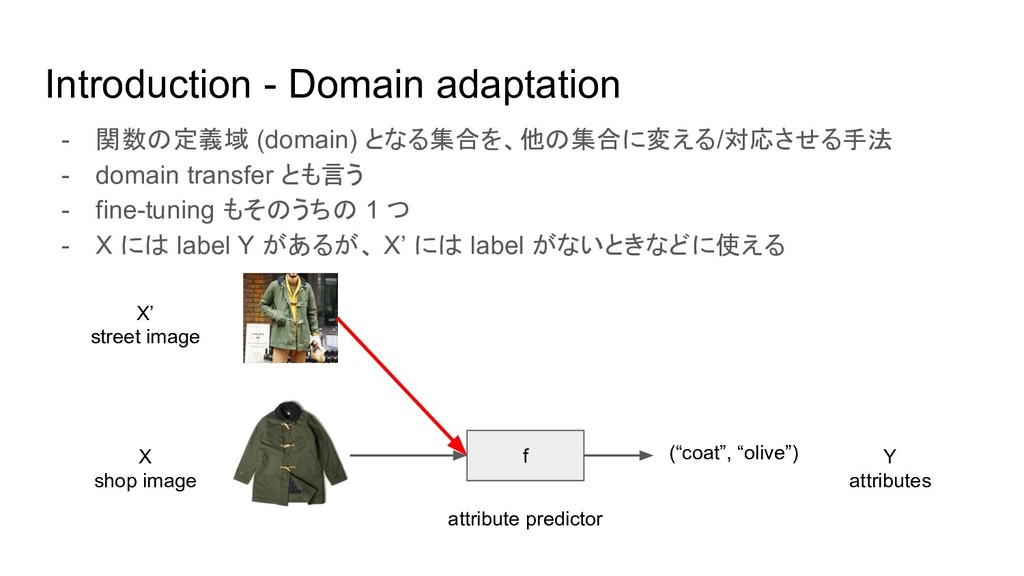
Introduction - Domain adaptation - 関数の定義域 (domain) となる集合を、他の集合に変える/対応させる手法 - domain
transfer とも言う - fine-tuning もそのうちの 1 つ - X には label Y があるが、 X’ には label がないときなどに使える f X shop image Y attributes (“coat”, “olive”) X’ street image attribute predictor
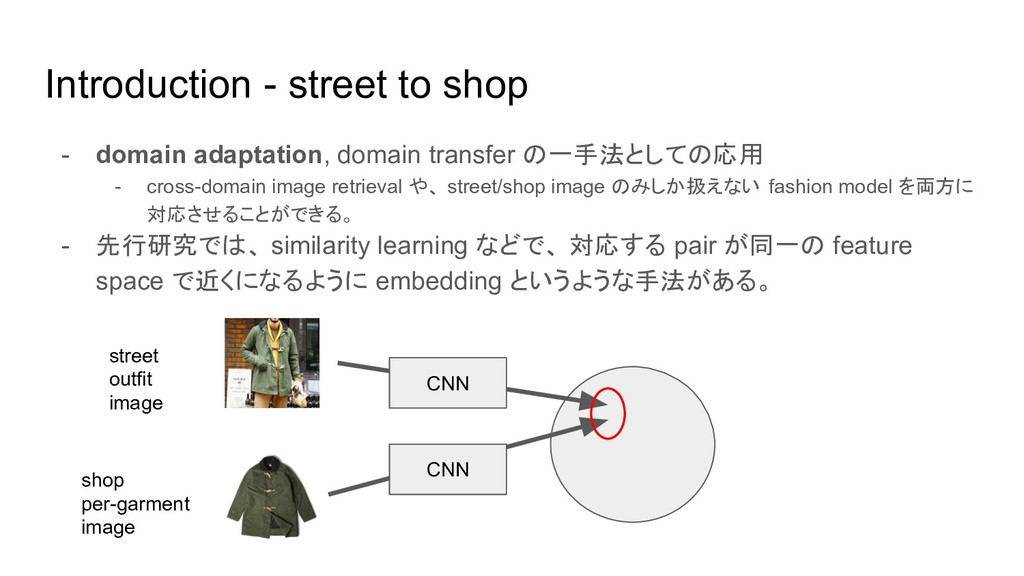
Introduction - street to shop - domain adaptation, domain transfer
の一手法としての応用 - cross-domain image retrieval や、 street/shop image のみしか扱えない fashion model を両方に 対応させることができる。 - 先行研究では、 similarity learning などで、 対応する pair が同一の feature space で近くになるように embedding というような手法がある。 CNN CNN street outfit image shop per-garment image
Introduction - our work - 今回は、 street image から shop
image を生成するモデル - street image を撮るだけで、 shop image を撮らなくて済む。
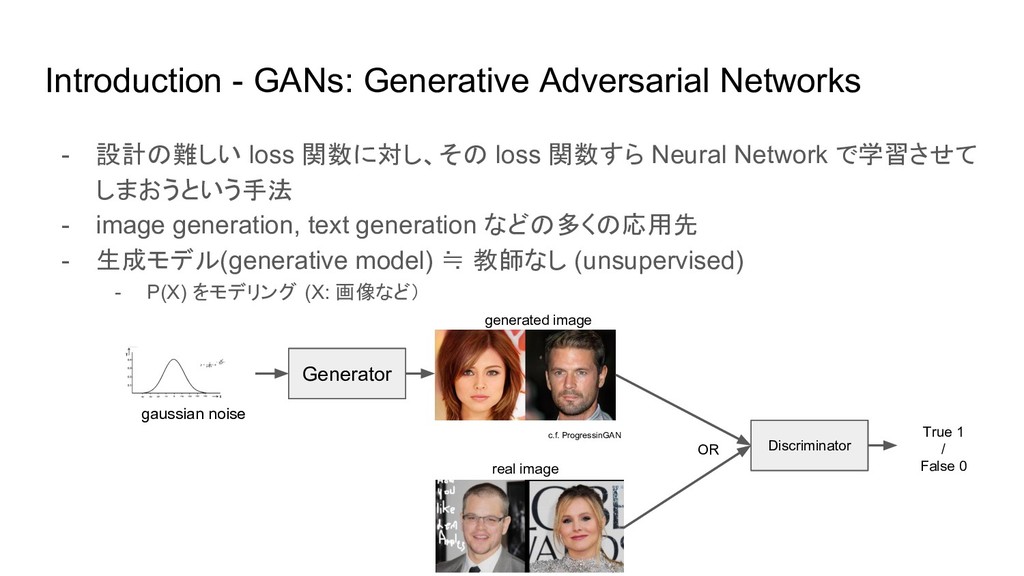
Introduction - GANs: Generative Adversarial Networks - 設計の難しい loss 関数に対し、その
loss 関数すら Neural Network で学習させて しまおうという手法 - image generation, text generation などの多くの応用先 - 生成モデル(generative model) ≒ 教師なし (unsupervised) - P(X) をモデリング (X: 画像など) Generator c.f. ProgressinGAN gaussian noise generated image OR Discriminator real image True 1 / False 0
Introduction - GANs: Generative Adversarial Networks - Generator, Discriminator を交互に学習させる。
- Discriminator は Generator が生成した画像か本物かを識別できるよう学習。 - Generator は Discriminator を騙すような画像を生成するよう学習。 Generator c.f. ProgressinGAN gaussian noise generated image OR Discriminator real image True 1 / False 0
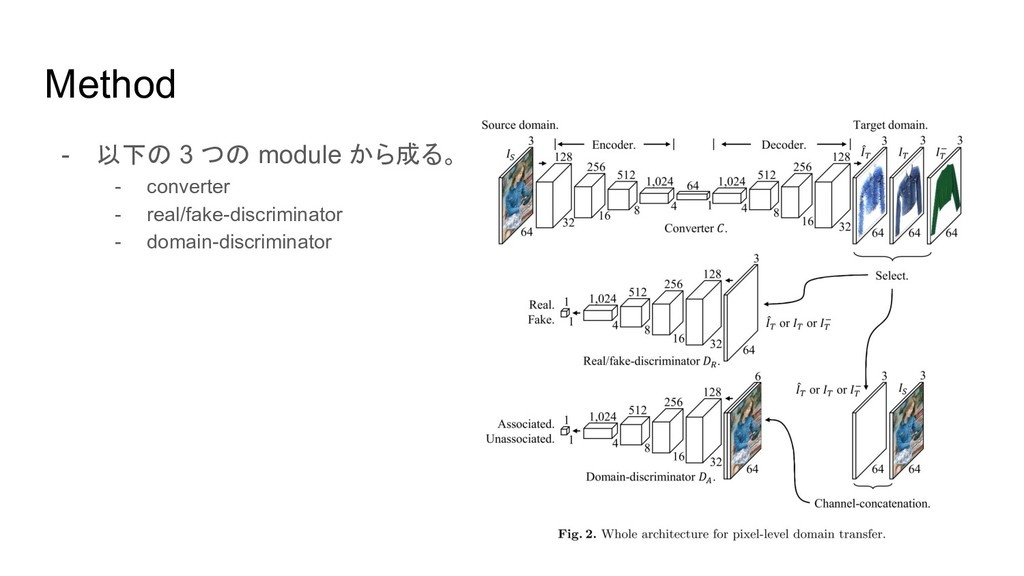
Method - 以下の 3 つの module から成る。 - converter -
real/fake-discriminator - domain-discriminator
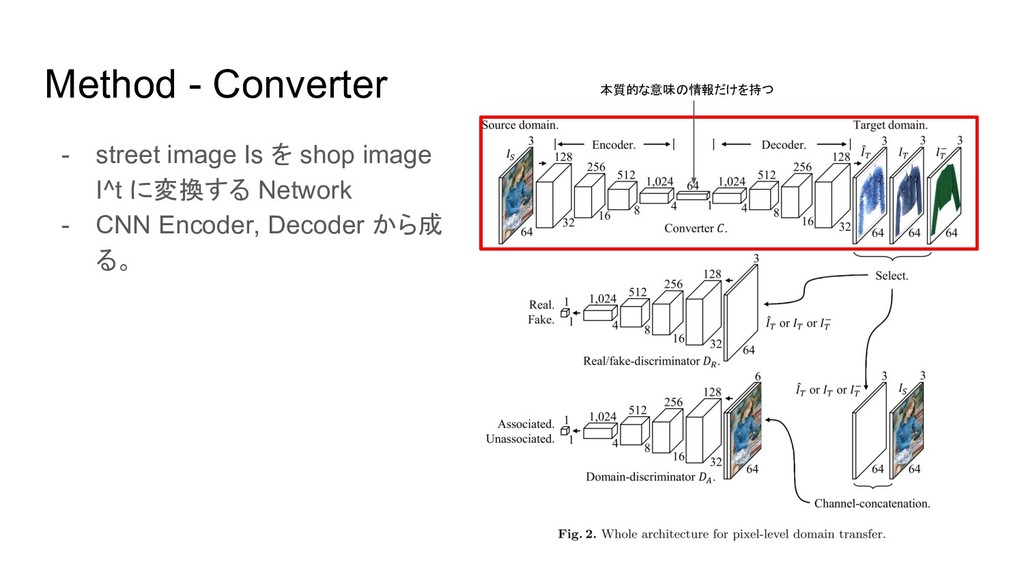
Method - Converter - street image Is を shop image
I^t に変換する Network - CNN Encoder, Decoder から成 る。 本質的な意味の情報だけを持つ
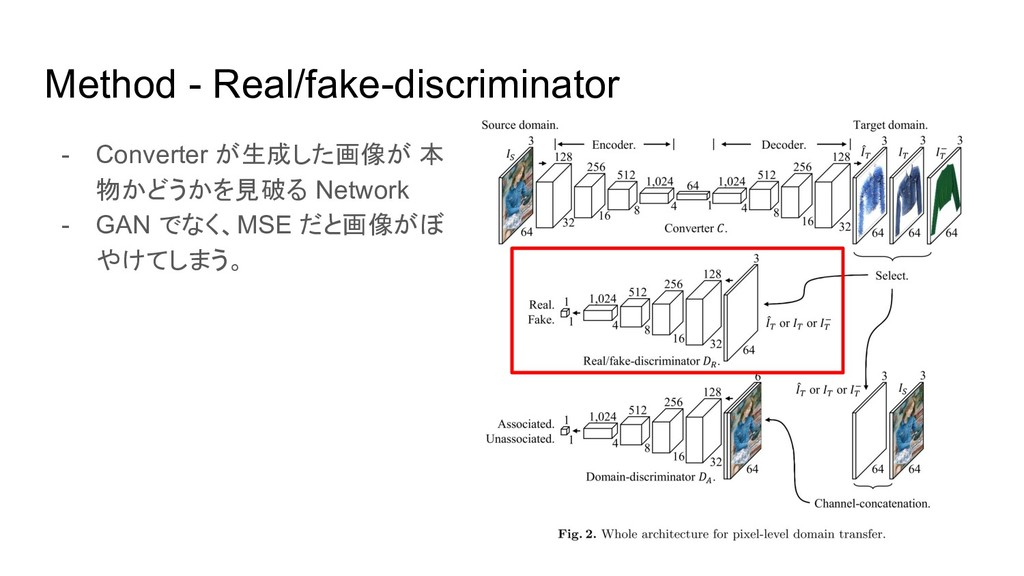
Method - Real/fake-discriminator - Converter が生成した画像が 本 物かどうかを見破る Network -
GAN でなく、MSE だと画像がぼ やけてしまう。
Method - GAN を用いる理由 - target domain の shop image
の正解は複数あり、正解を一意に定められない。 - source と target 集合の画像の性質がかなり異なる。 - e.g. 動画の frame 予測などは frame ごとに画像の性質は近いので、 MSE などでも大丈夫らし い。
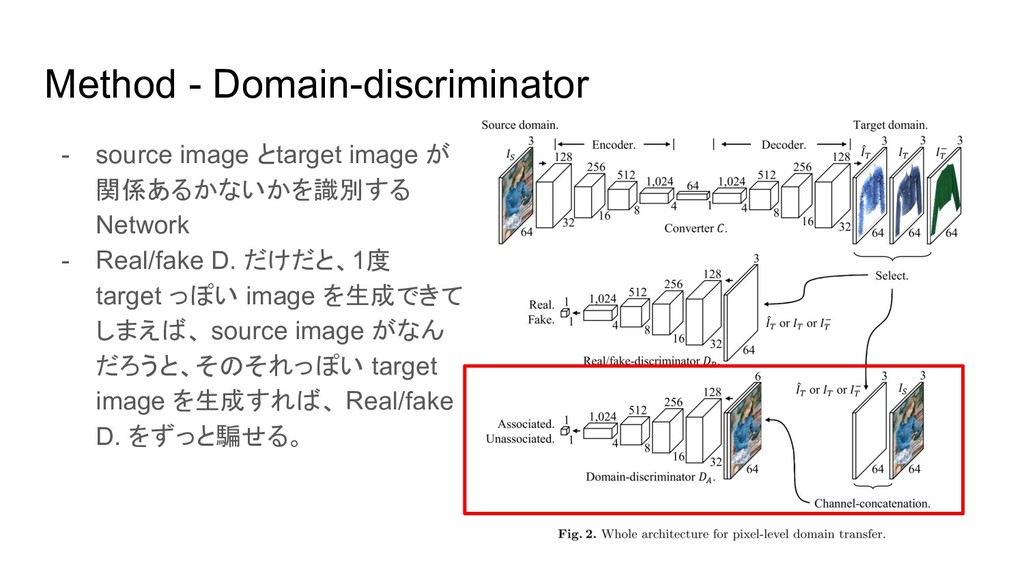
Method - Domain-discriminator - source image とtarget image が 関係あるかないかを識別する
Network - Real/fake D. だけだと、1度 target っぽい image を生成できて しまえば、 source image がなん だろうと、そのそれっぽい target image を生成すれば、 Real/fake D. をずっと騙せる。
Dataset - LookBook - 新しく提案 - 複数の street image と対応する
1 枚の shop image の集合。 - category は tops のみ。
Results - Quantitative evaluation - evaluation metrics - user study
score: manual - RMSE, C-SSIM: automated
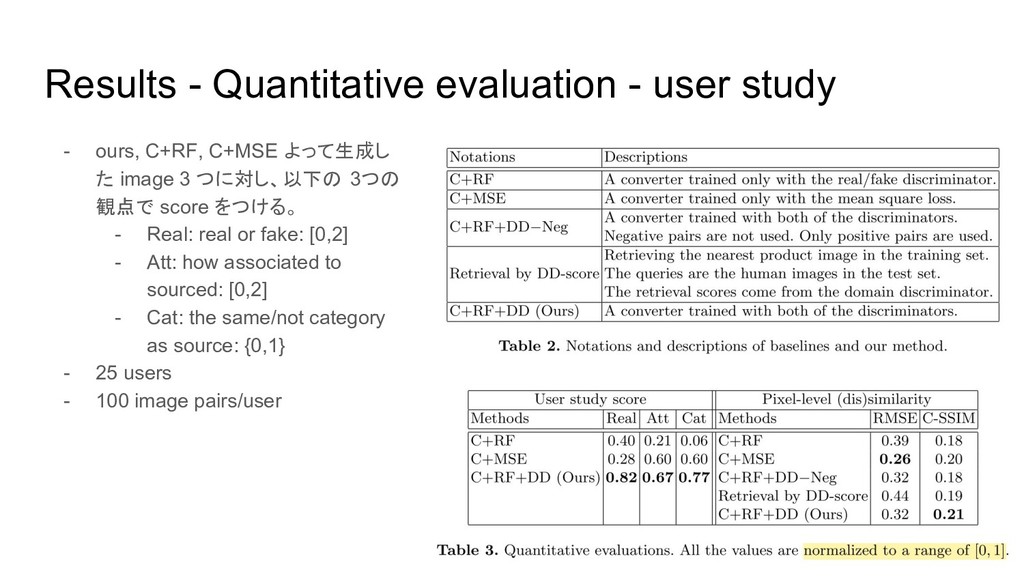
Results - Quantitative evaluation - user study - ours, C+RF,
C+MSE よって生成し た image 3 つに対し、以下の 3つの 観点で score をつける。 - Real: real or fake: [0,2] - Att: how associated to sourced: [0,2] - Cat: the same/not category as source: {0,1} - 25 users - 100 image pairs/user
Results - Quantitative evaluation - user study - C+MSE: Att
を反映してるが、 本 物っぽくない - C+RF: MSE に比べ、本物っぽい が、 source と関係ないものを生成 してるので、AttはMSEより低い。 - Ours: Sourceのattribute, category などを保ちつつ、本物っぽい画像を 生成できてる。
Results - Qualitative evaluation
Results - Qualitative evaluation - 同じ item で異なる street image
でも大体 同じような shop image を生成できている。
Results - Quantitative evaluation - C-SSIM - Channel-wise Structured SIMilarity
- real shop image と generated shop image の 差異を測る - a manual metric which is consistent with human perception - Ours が他の全ての baselines に優った。
Results - Quantitative evaluation - C-SSIM - C+RF+DD-Neg: Negative なし。
- Negativeもあったがほうが、 DDがより効く
Results - Quantitative evaluation - C-SSIM - Retrieval by DD-score: sourceと
同じ item の generative shop image か、 source と似てる (DD-score 低い) item の real shop image とどっちが 本物の real shop image と似てるかを検証 - Ours の汎化性を検証するため。(汎 化できてなければ、未知の item に 弱く、検索した similar item image に負ける)
Results - Virtual Try On - shop image to street
image と いう逆の task も、データを入れ 替えれば同じ model でできる。 - コンピュータを用いた仮想的な試 着などの応用が考えられる。他 の論文も結構ある。
Conclusion - street2shop image generation で pixel-level での domain trasfer
の手法を初め て提案した。 - Domain-discriminator により、 Source の意味情報を保ったまま、本物っぽい画像 の生成ができるようになった。 - street-shop image の novel dataset を提案。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}