Adopting a Big-Data mindset and establishing a capable data infrastructure to support it is a challenge. This session, hosted by iHeartRadio, will introduce current technologies (Hadoop/Hive/Impala/Parquet, Luigi, Kafka/Flume, ElasticSearch/Kibana), along with a few examples of data and machine learning projects that leverage them. We’ll leave the realm of theory and also go into operationalization strategies, discuss cluster configurations and automated deployment using Chef.
Presented by Pasha Katsev
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
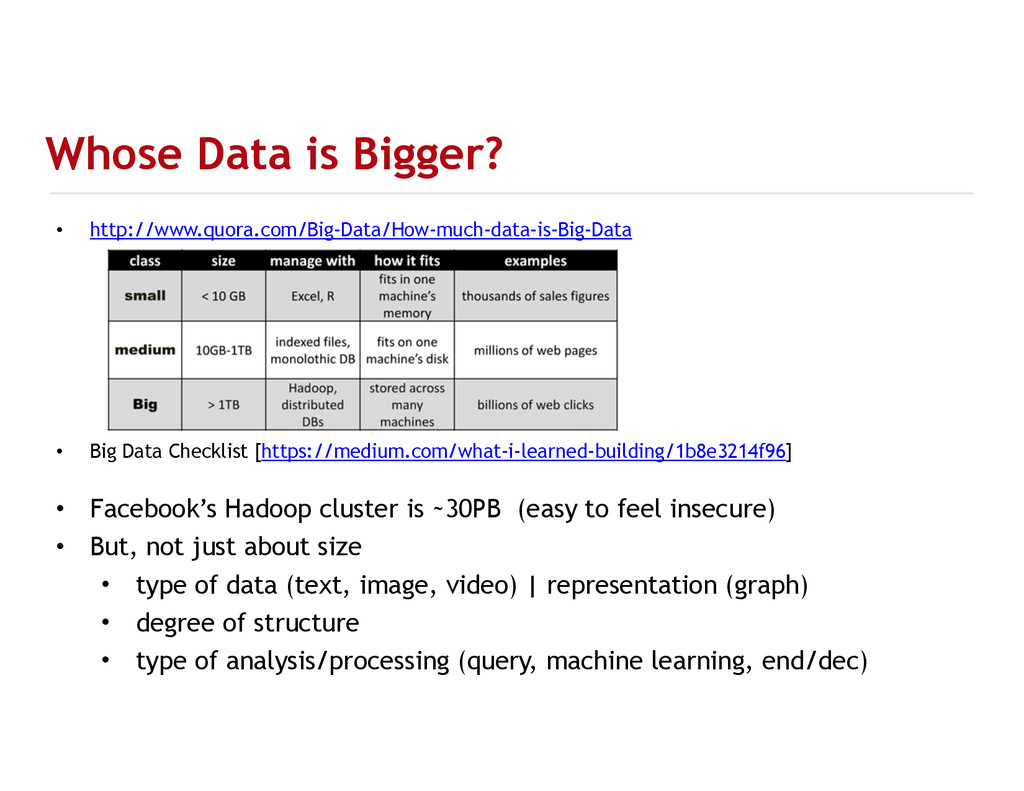{kind=link}
![• Logs: • Search • ~150 MB/day [web] + ~500](https://files.speakerdeck.com/presentations/47dd7af077160131d57e22a403f64e0b/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
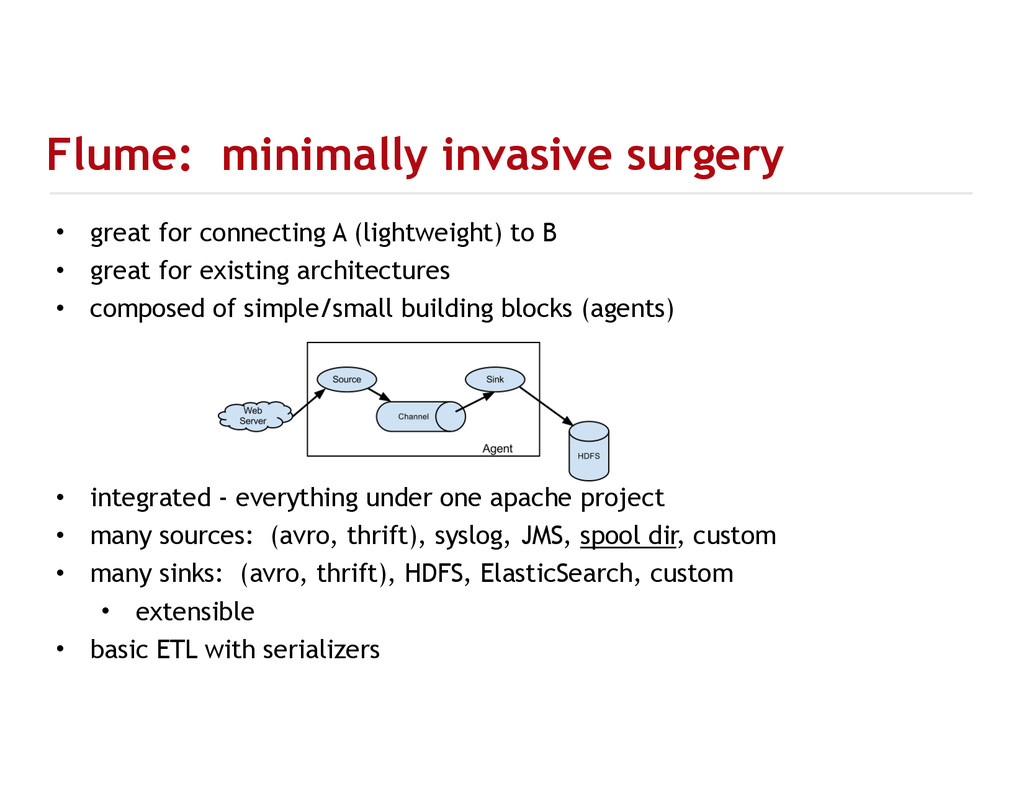{kind=link}
{kind=link}
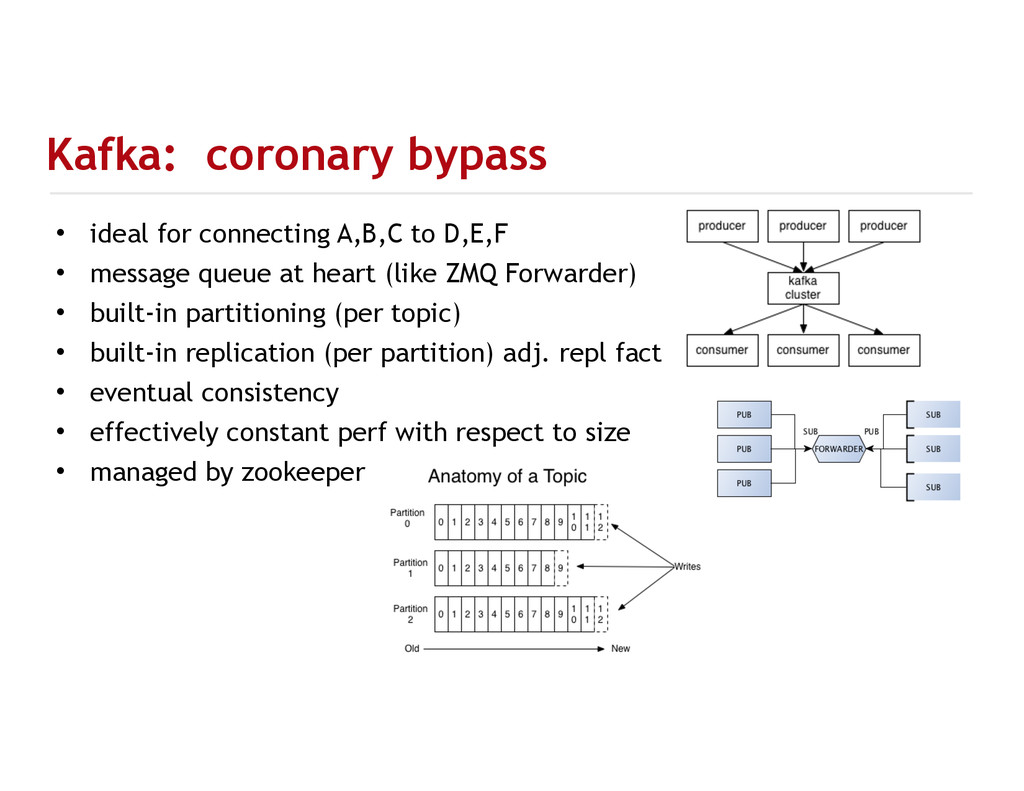{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
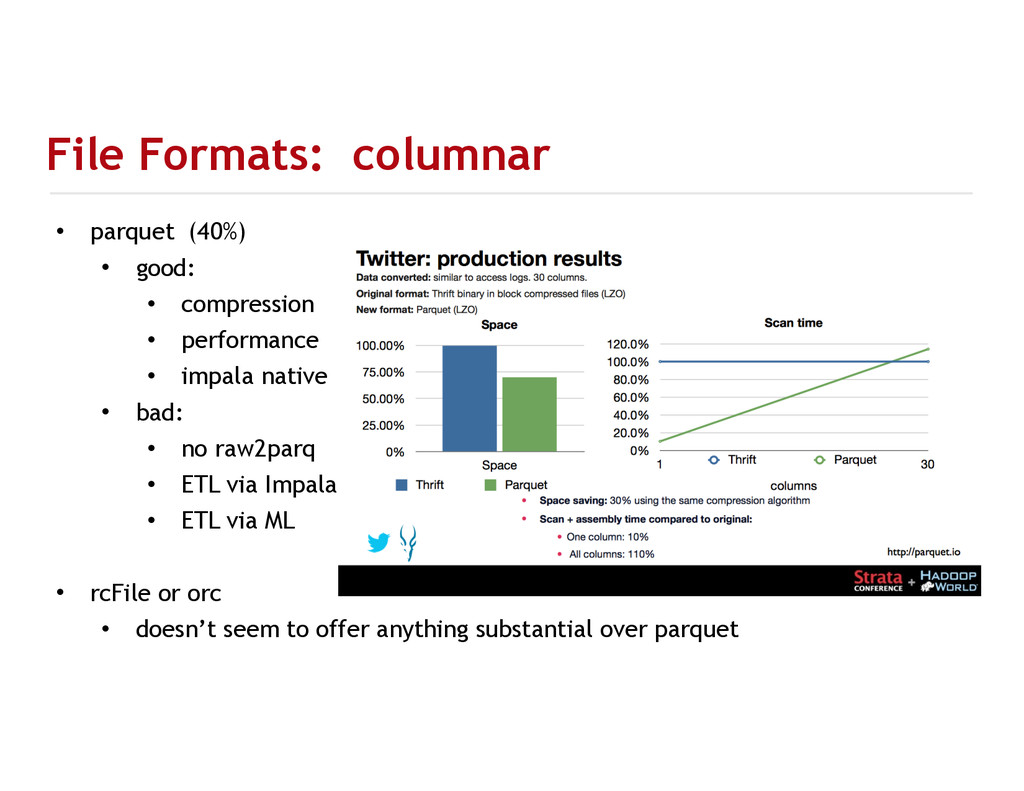{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
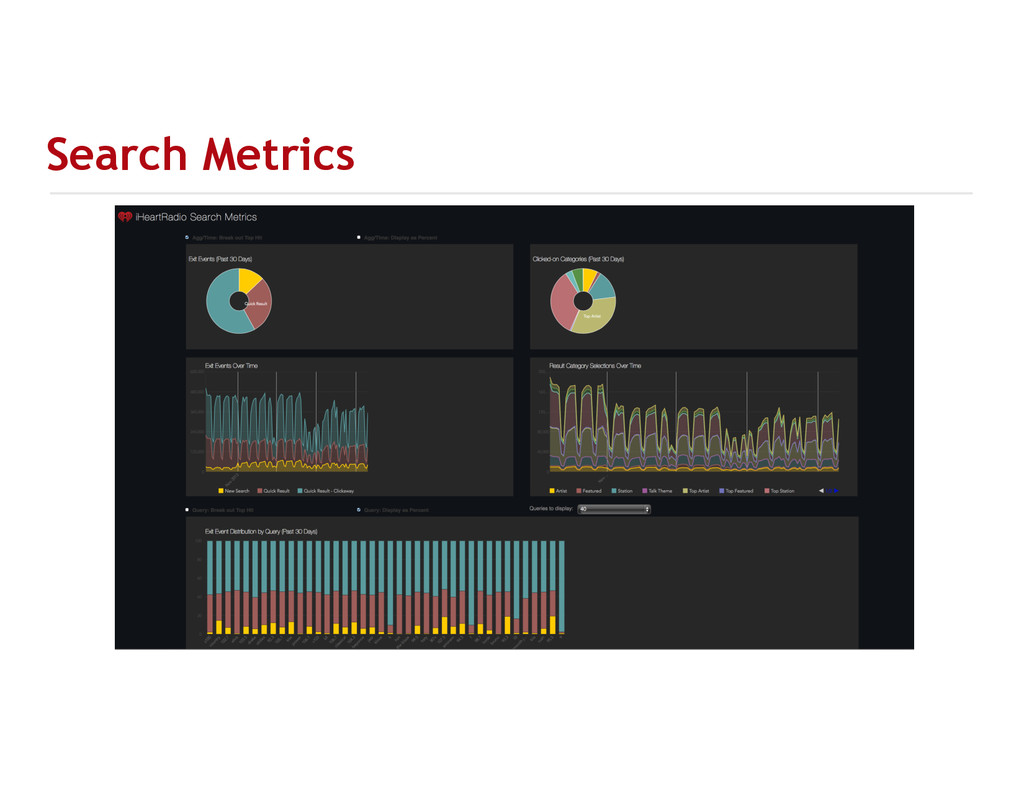{kind=link}
{kind=link}
{kind=link}
![questions? email: [email protected]](https://files.speakerdeck.com/presentations/47dd7af077160131d57e22a403f64e0b/slide_35.jpg){kind=link}