Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
KubeCon Recap -Platform migration at Scale-
Search
Kohei Ota
May 26, 2022
Technology
1.1k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
KubeCon Recap -Platform migration at Scale-
Kohei Ota
May 26, 2022
More Decks by Kohei Ota
See All by Kohei Ota
CloudNative Meets WebAssembly: Exploring Wasm's Potential to Replace Containers
inductor
4
3.6k
The Cloud Native Chronicles: 10 Years of Community Growth Inside and Outside Japan
inductor
0
190
Cracking the KubeCon CfP
inductor
2
920
コンテナビルド最新事情 2022年度版 / Container Build 2022
inductor
3
600
データベースとストレージのレプリケーション入門 / Intro-of-database-and-storage-replication
inductor
28
6.6k
KubeConのケーススタディから振り返る、Platform for Platforms のあり方と その実践 / Lessons from KubeCon case studies: Platform for Platforms and its practice
inductor
3
1k
オンラインの技術カンファレンスを安定稼働させるための取り組み / SRE activity for online conference platform
inductor
1
1.4k
Kubernetesネットワーキング初級者脱出ガイド / Kubernetes networking beginner's guide
inductor
22
7.7k
コンテナネイティブロードバランシングの話 / A story about container native load balancing
inductor
2
2.4k
Other Decks in Technology
See All in Technology
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
160
AI エージェント時代のデジタルアイデンティティ
fujie
0
160
WEBフロントエンド研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
490
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
1.4k
Azure Durable Functions で作った NL2SQL Agent の精度向上に取り組んだ話/aidevday2026
thara0402
0
110
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
460
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
20
18k
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
350
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
AI研修(Day2)【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
1k
Flutter研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
220
実践が先生だった— 新卒サーバーエンジニア1年目のリアル
mixi_engineers
PRO
0
150
Featured
See All Featured
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
190
First, design no harm
axbom
PRO
2
1.2k
Navigating Weather and Climate Data
rabernat
0
410
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Deep Space Network (abreviated)
tonyrice
0
230
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
190
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Navigating Team Friction
lara
192
16k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Transcript
KubeCon Recap -Platform migration at Scale- Kubernetes Meetup #51 Kohei
Ota, Architect at HPE/CNCF Ambassador
© 2022 Cloud Native Computing Foundation 2 自己紹介 Kohei Ota
(@inductor) •Architect at HPE •CNCF Ambassador •KubeCon EU 2022 Track co-chair (Operation) •Google Developer Expert (GCP) •CloudNative Days Tokyo organiser •Container Runtime Meetup organiser
© 2022 Cloud Native Computing Foundation 3 Session info of
this recap 1. Mercedes-Benzの事例 a. Keynote: 7 Years of Running Kubernetes for Mercedes-Benz b. How to Migrate 700 Kubernetes Clusters to Cluster API with Zero Downtime 2. 稼働中のコンテナランタイムを変更した事例 a. Keep Calm and Containerd On! by Intuit Inc
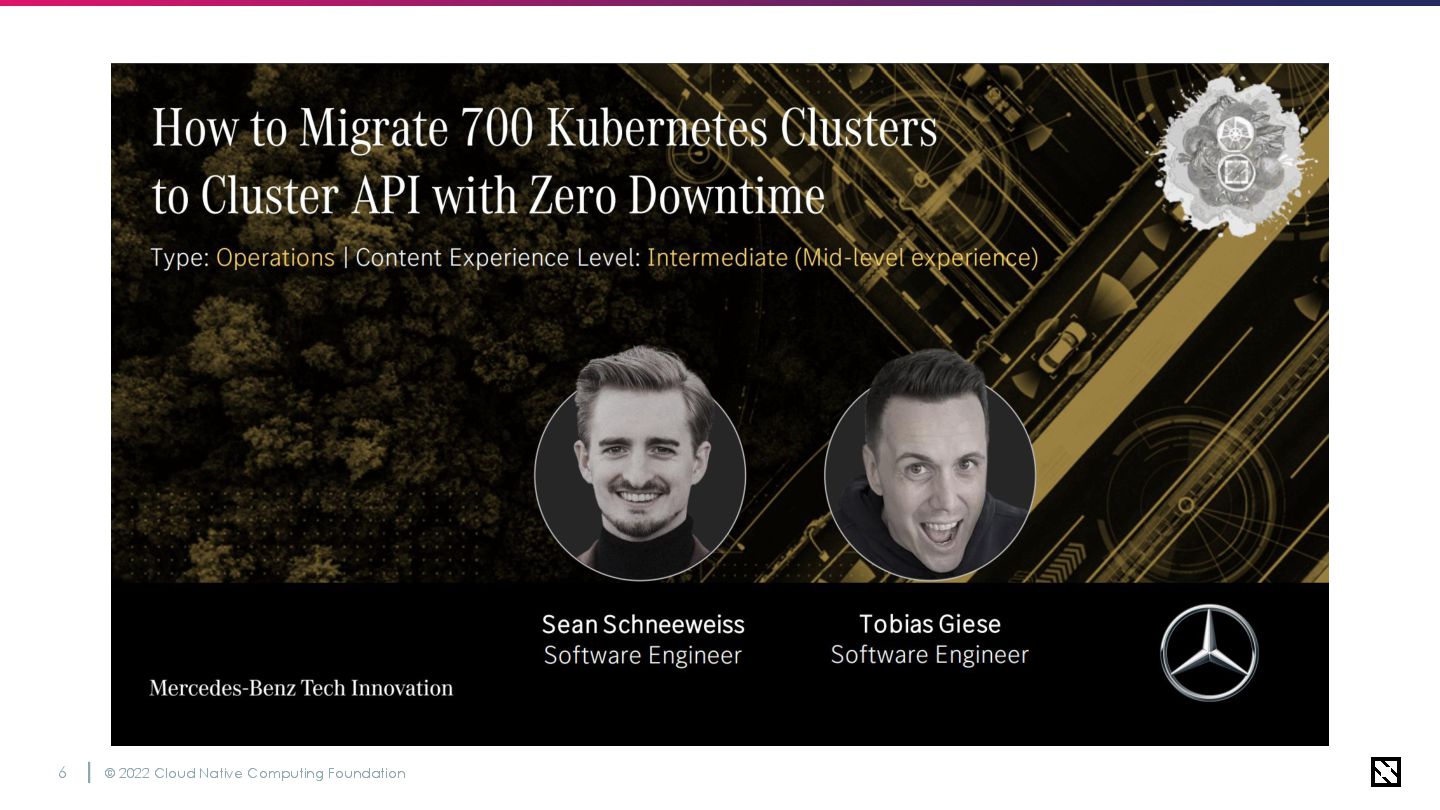
Migrating 700 Kubernetes Clusters to Cluster API with Zero Downtime
after 7 years operation at Mercedes-Benz
7年間稼働してきたメルセデスベンツの700に もわたるクラスターを、ダウンタイムなしで Cluster APIに移行した事例
© 2022 Cloud Native Computing Foundation 6
© 2022 Cloud Native Computing Foundation 7
© 2022 Cloud Native Computing Foundation 8
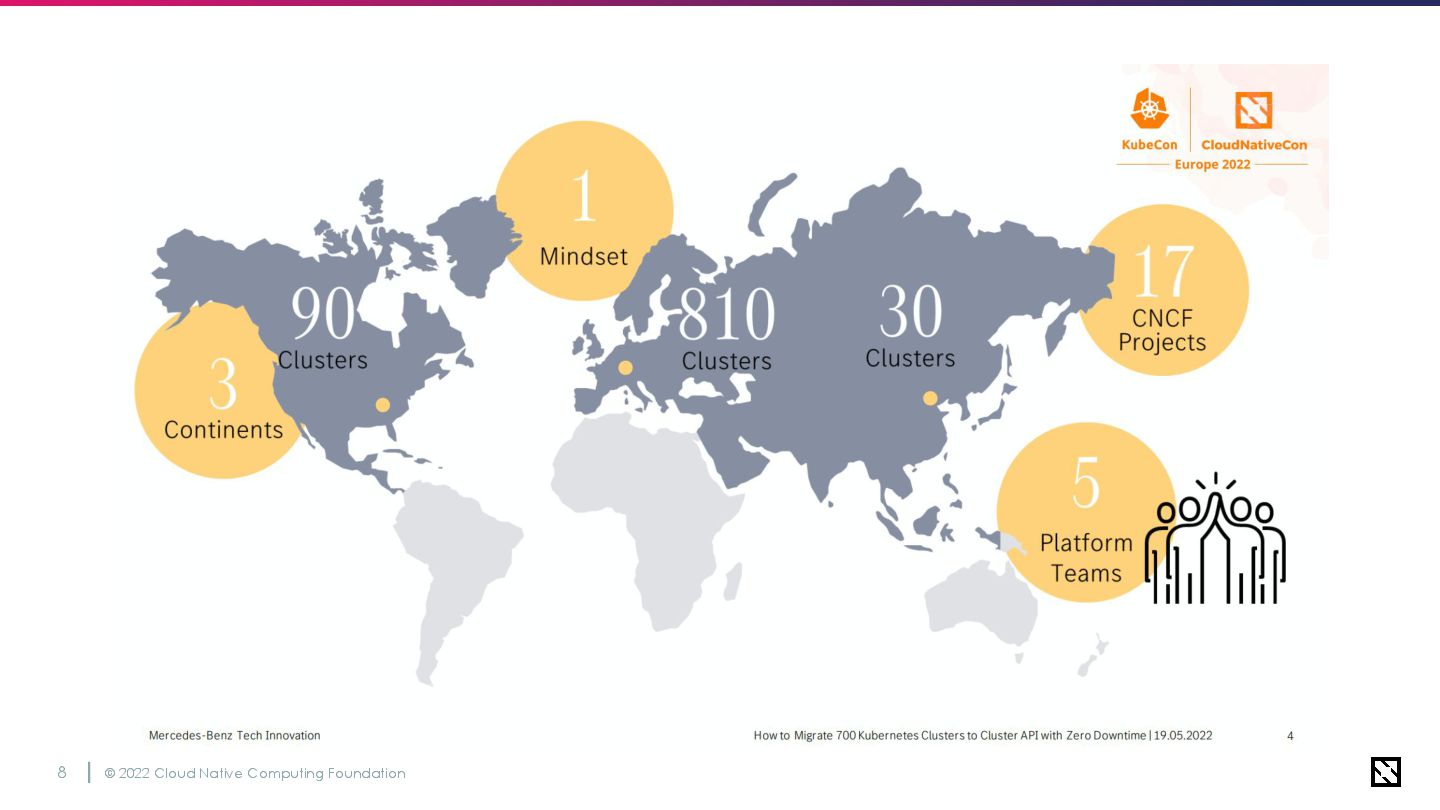
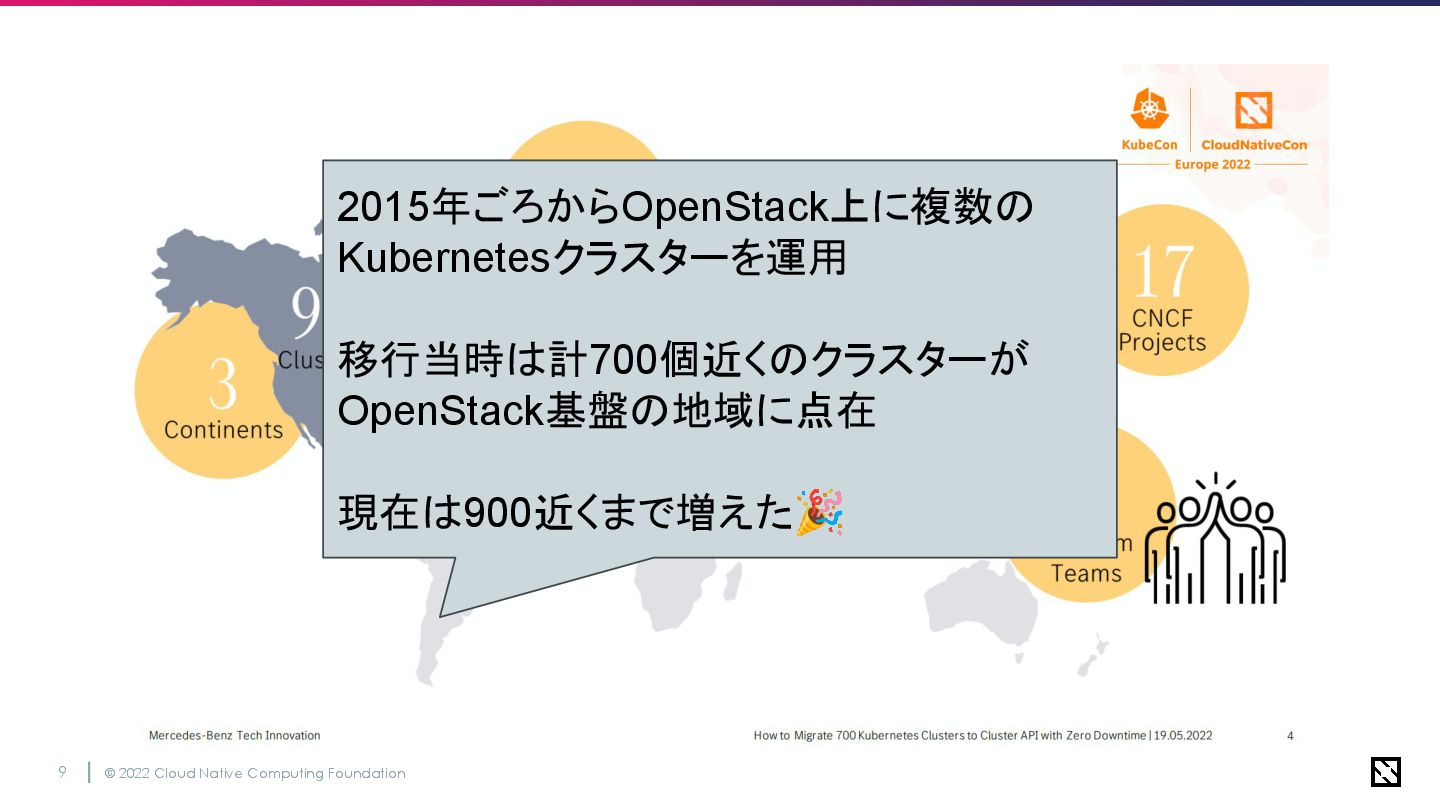
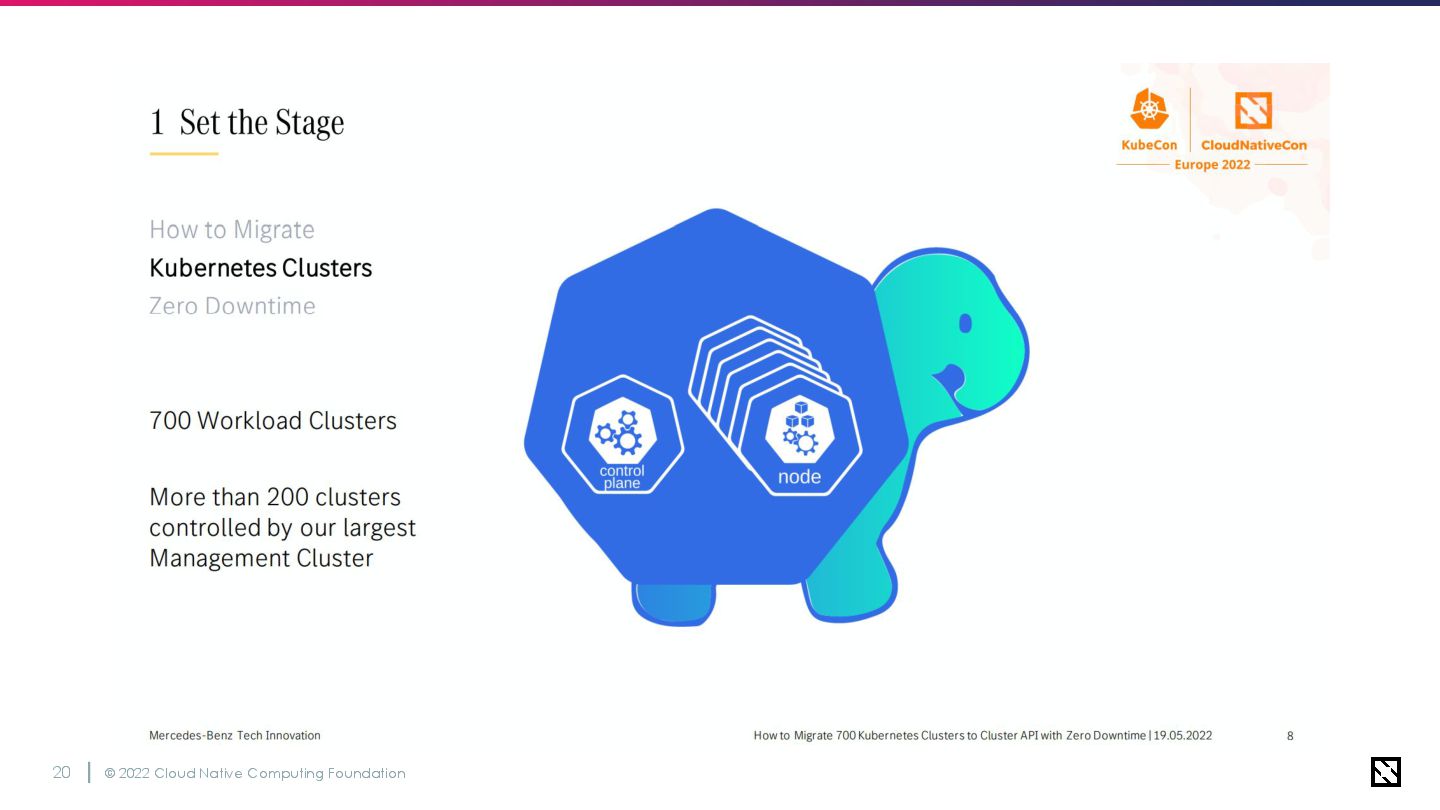
© 2022 Cloud Native Computing Foundation 9 2015年ごろからOpenStack上に複数の Kubernetesクラスターを運用 移行当時は計700個近くのクラスターが
OpenStack基盤の地域に点在 現在は900近くまで増えた🎉
© 2022 Cloud Native Computing Foundation 10 エンタープライズ規模でのFOSS(Fully Open Source)
• ダイムラーでもかつてはクローズドな技術スタックを使っていた • 2014年ごろから自動化を含めOSSをエンタープライズで使うための取り組みを Green field approachを用いて開始 • オープンソース利用のガイドラインを策定 ◦ https://opensource.mercedes-benz.com/manifesto/ • コミュニティへの貢献を怠らない
インフラ構成 (Before/After)
© 2022 Cloud Native Computing Foundation 12
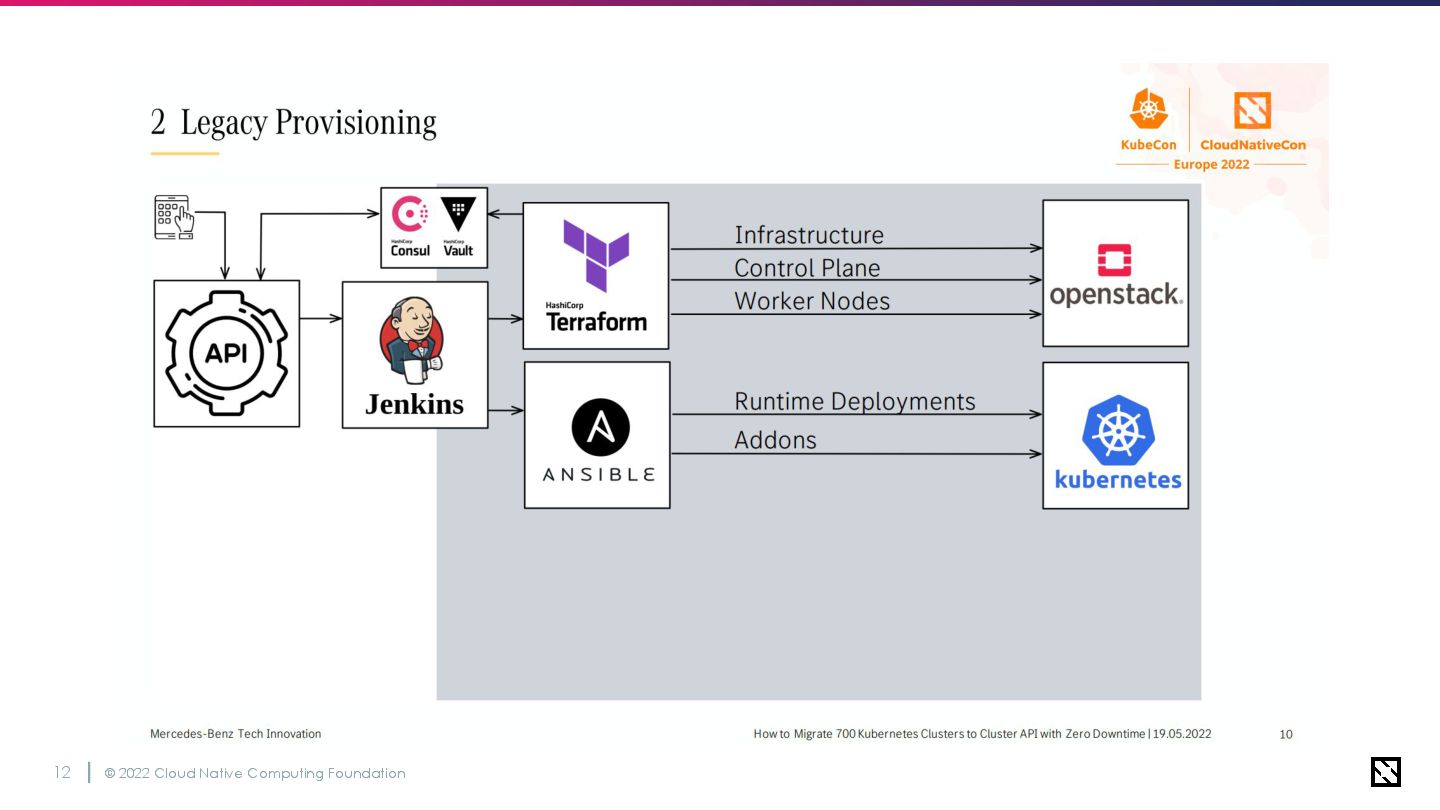
© 2022 Cloud Native Computing Foundation 13 OpenStack + Terraformで仮想マシンの管理
AnsibleでOS上のランタイムを展開 💡VM時代の典型的な管理方法
© 2022 Cloud Native Computing Foundation 14
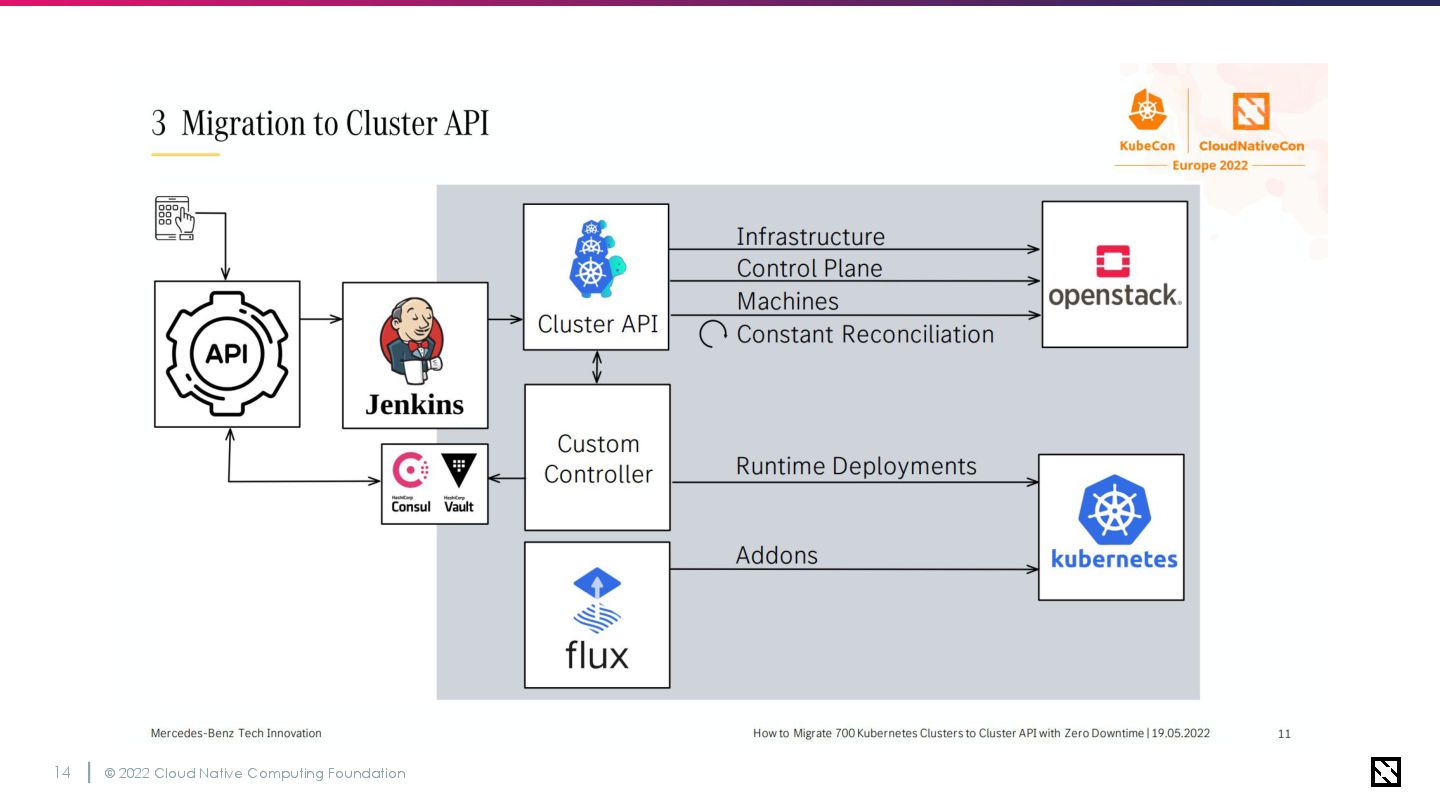
© 2022 Cloud Native Computing Foundation 15 Cluster APIでクラスターの管理 カスタムコントローラーとFluxCDの組合せ
💡GitOpsでKubernetesネイティブな管理方法
Why Cluster API?
© 2022 Cloud Native Computing Foundation 17
© 2022 Cloud Native Computing Foundation 18 Cluster APIを使うと... 1.
クラスターのライフサイクル 2. クラスターに参加するマシンの管理 3. 構成設定(kubeadm config) これらがすべてKubernetesのCRDで管理できる
© 2022 Cloud Native Computing Foundation 19 Cluster APIを使うと... 1.
クラスターのライフサイクル 2. クラスターに参加するマシンの管理 3. 構成設定(kubeadm config) これらがすべてKubernetesのCRDで管理できる Cluster API Providerの存在が大きい AWS/GCP/Azure/OpenStack vSphere/Docker など、APIのあるIaaSで ノードをセットアップできる仕組み https://cluster-api.sigs.k8s.io/reference/providers.html
© 2022 Cloud Native Computing Foundation 20
© 2022 Cloud Native Computing Foundation 21 管理用クラスターの亀 (Cluster API)の
力を使って、全ゾーンの中で最大 200 近くのワークロードクラスターを集約し て管理するようになった
© 2022 Cloud Native Computing Foundation 22 管理用クラスターの亀 (Cluster API)の
力を使って、全ゾーンの中で最大 200 近くのワークロードクラスターを集約し て管理するようになった 200ものクラスターを既存の Terraform + Ansibleで管理するくらいだったら Cluster APIでシュッてやりたい気持ちは本当にそう だねという感じ
ゼロダウンタイムに関する考慮事項
© 2022 Cloud Native Computing Foundation 24 ゼロダウンタイムの要件と実現方法 • 要件
◦ ユーザー(クラスター利用者/開発者)はワークロードのデプロイが不要 ◦ コントロールプレーン・ワーカーどちらも無停止で実施 • Why? ◦ 基盤の根本技術を変えるというインフラの理由でワークロードを停止させるべきでない ◦ 開発環境やバッチ処理など様々なワークロードが世界中にある • 実現方法 ◦ OpenStackで管理されているKubernetesクラスターのVM、ルーター、 LBaaSなどのオブジェクトをTerraformによる管理からCluster API管理に置換 ◦ クラスターの構成管理はAnsible + kubeadmだが、そこも全部Cluster API管理に置換
© 2022 Cloud Native Computing Foundation 25 ゼロダウンタイムの要件と実現方法 • 要件
◦ ユーザー(クラスター利用者/開発者)はワークロードのデプロイが不要 ◦ コントロールプレーン・ワーカーどちらも無停止で実施 • Why? ◦ 基盤の根本技術を変えるというインフラの理由でワークロードを停止させるべきでない ◦ 開発環境やバッチ処理など様々なワークロードが世界中にある • 実現方法 ◦ OpenStackで管理されているKubernetesクラスターのVM、ルーター、 LBaaSなどのオブジェクトをTerraformによる管理からCluster API管理に置換 ◦ クラスターの構成管理はAnsible + kubeadmだが、そこも全部Cluster API管理に置換 💡`terraform import` みたいなやつで メタデータを取り込めば実現できそう
© 2022 Cloud Native Computing Foundation 26 メタデータの移行 • すべてのOpenStackリソースはTerraformで管理されている
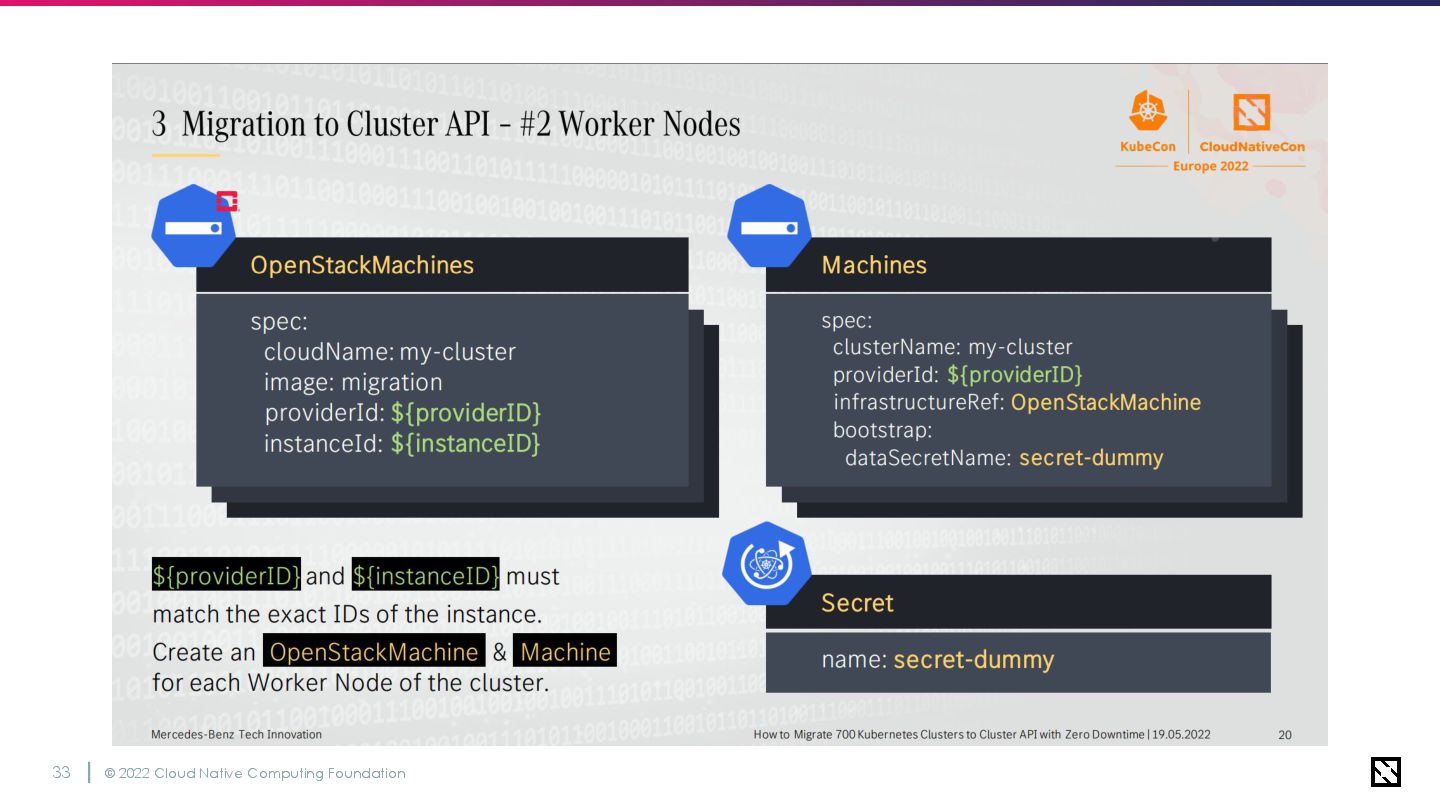
• OpenStack上にはAnsible + kubeadmで作られたクラスターが既にある • Cluster APIはInfra Providerによるインフラリソースのカスタムリソース管理と、クラ スター自体の管理をkubeadmの力で実現している → Terraform stateにあるマシンのメタデータをCluster API Provider OpenStackに食 わせて、kubeadm configをKubeadmControlPlaneに食わせればええやん!!!
クラスター移行のステップ
© 2022 Cloud Native Computing Foundation 28
© 2022 Cloud Native Computing Foundation 29 1. OpenStack側のメタデータをCluster APIのオ
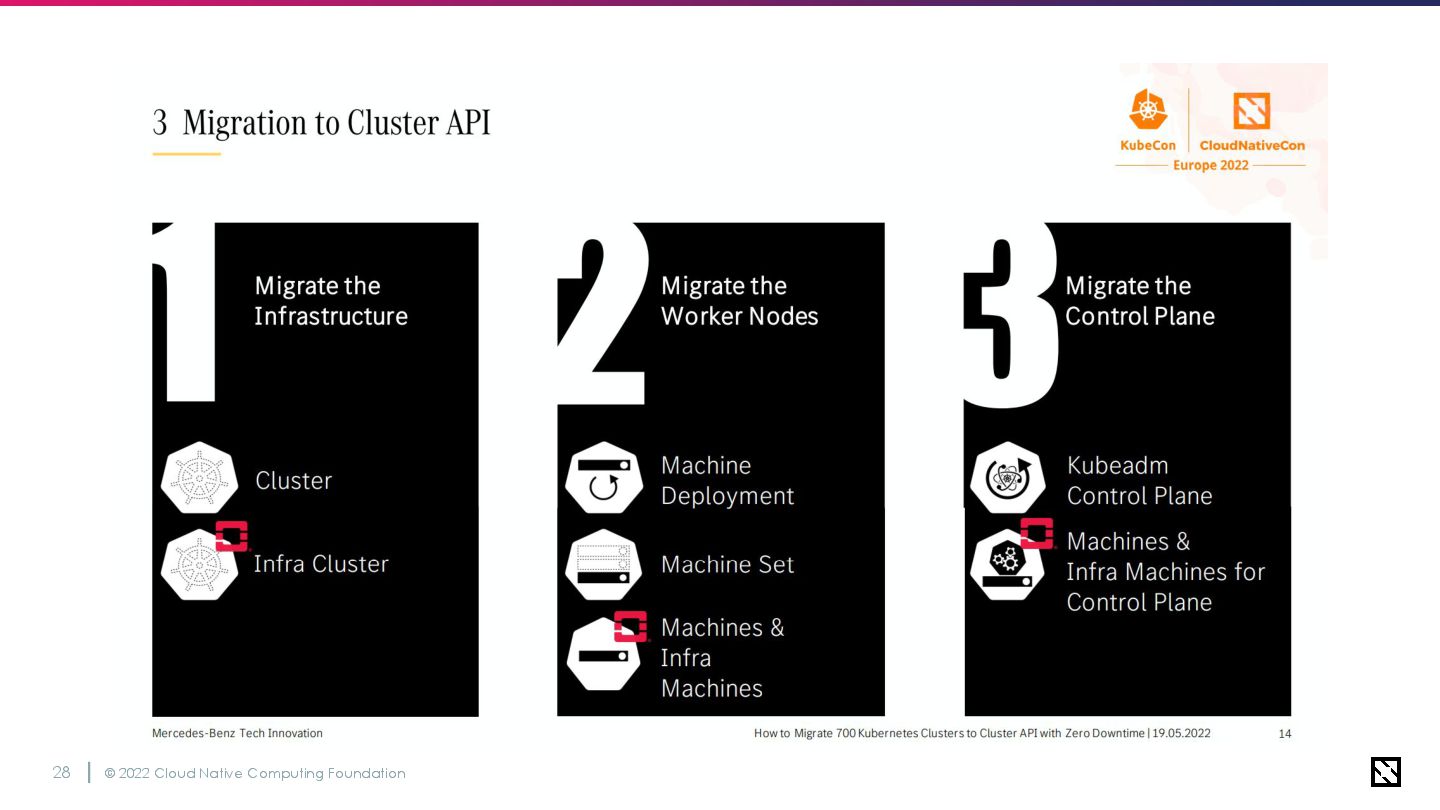
ブジェクトに置換 2. ワーカーノード及びマシンセットをCluster API のオブジェクトに置換 3. コントロールプレーンとKubeadmの構成情報 をCluster APIのオブジェクトに置換
© 2022 Cloud Native Computing Foundation 30
© 2022 Cloud Native Computing Foundation 31
© 2022 Cloud Native Computing Foundation 32
© 2022 Cloud Native Computing Foundation 33
© 2022 Cloud Native Computing Foundation 34
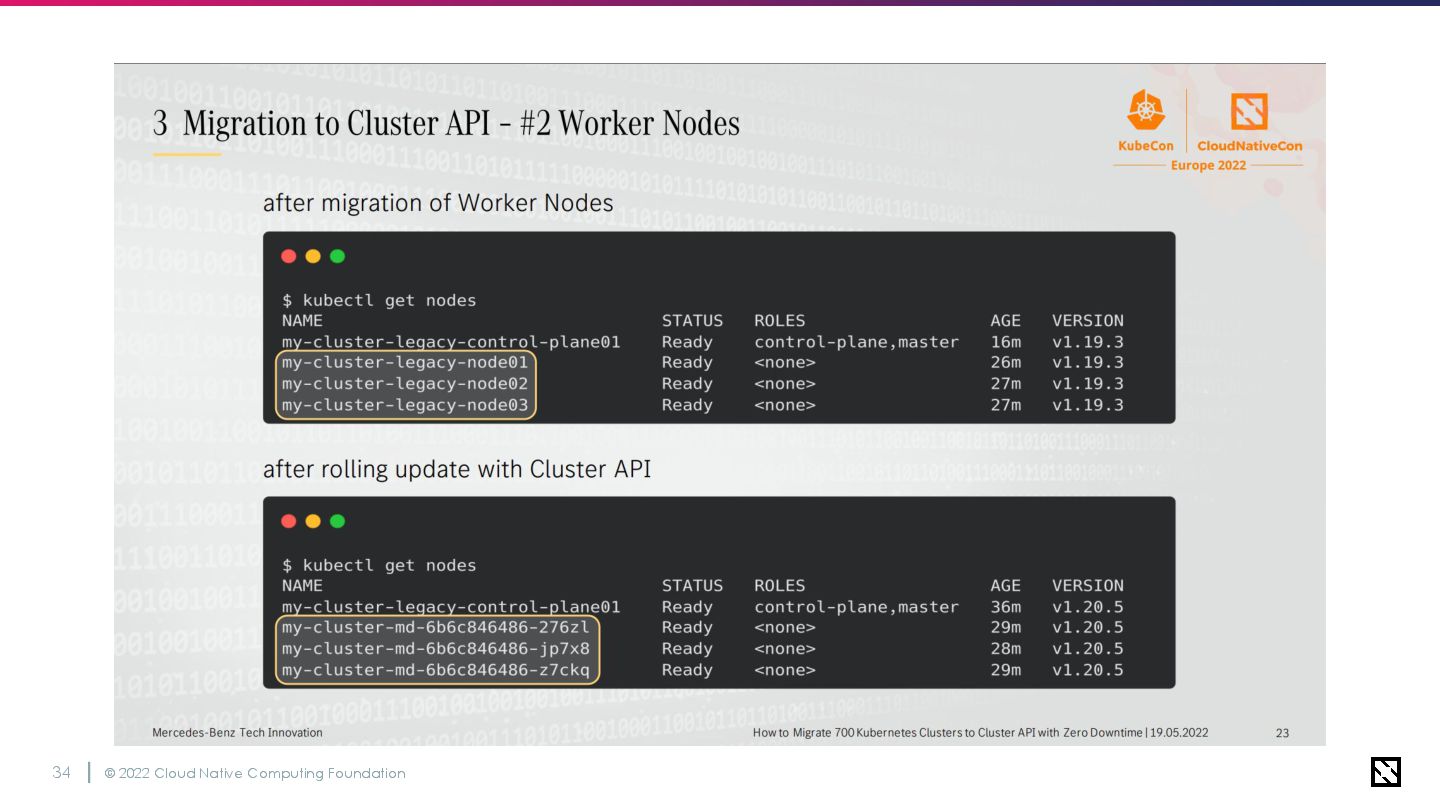
© 2022 Cloud Native Computing Foundation 35 そんなこんなでクラスターの移行自体は完了 ・OpenStack上のリソース ・Kubernetesの構成設定
の両方がKubernetesのカスタムリソースで 管理できるようになった🥳🥳
学びと今後の予定
© 2022 Cloud Native Computing Foundation 37 移行作業時の学び • ちゃんとゼロダウンタイムだったのか?
◦ クラスター: Yes ◦ ワークロード: No • なんで? ◦ Pod Disruption Budgets(PDB)などの、利用者側で仕込んでおくべき設定が入っていないワー クロードが存在 ◦ クラスターのバージョンアップ時などに停止時間が発生(Node drain処理) ◦ Cluster API側でできること ▪ Pre-Drain/Pre-Terminateアノテーションの付与 ▪ Cluster APIのカスタムコントローラー側で、クラスター構成変更に伴って発生する drainやボ リュームデタッチなどの処理について考慮してくれるようになる • クラスター移行はちゃんと演習しておきましょう ◦ 完全自動化された日常的なビルドテスト ▪ レガシー構成からCluster APIへの移行 ▪ Cluster APIを用いた新規クラスターの作成やバージョンアップなど
© 2022 Cloud Native Computing Foundation 38 今後の展望 • AnsibleからFluxへの完全な移行
• Cluster API 新機能の導入 • Cluster API Metrics Exporterへの貢献 • 既存基盤と同じ利用ができるような仕組みを備えた上で パブリッククラウド利用も視野に
Migrating Running Docker to Containerd at Scale
そこそこの規模で稼働中のDockerを Containrdに置き換える話
© 2022 Cloud Native Computing Foundation 41 Intuitのインフラについて • 財務関係のSaaS・ソフトウェアを展開するテックカンパニー
• 200以上のクラスター • 16000以上のノード • 5000人以上の開発者が利用
© 2022 Cloud Native Computing Foundation 42
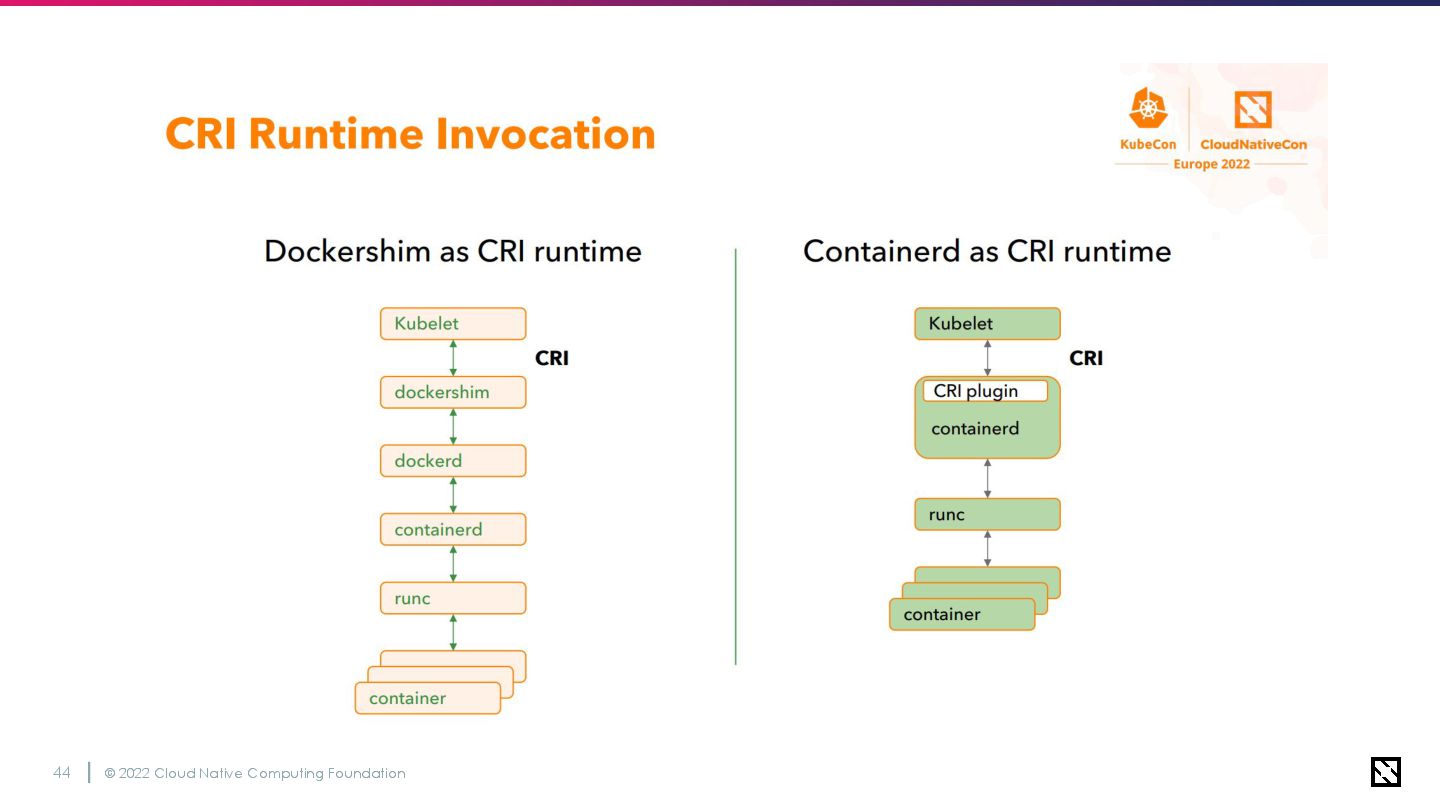
© 2022 Cloud Native Computing Foundation 43 Kubernetes 1.24で削除されるDockershim •
DockershimはKubernetes上でDockerを動作させるためのブリッジインターフェー ス(Docker API <-> CRI) • CRIで標準化されたランタイム規格はDocker自体とは関連がない(そもそもDocker はKubernetesよりも昔から存在するため) • CRIネイティブなContainerdやCRI-Oが十分枯れてきたため、メンテナンスコストが 高いDockershimをKubernetesのメインストリームから排除することでコード量が大 幅に削減される ◦ https://qiita.com/y1r96/items/37483ffd17e21f060331
© 2022 Cloud Native Computing Foundation 44
インフラ構成 (Before/After)
© 2022 Cloud Native Computing Foundation 46
© 2022 Cloud Native Computing Foundation 47
© 2022 Cloud Native Computing Foundation 48 主な影響範囲 • Logging
(JSON -> TEXT format) • Docker CLI (CLIが変わるだけなので割愛) • kubelet config (設定変更だけなので割愛) • CNI(時間があれば後で詳しく説明します)
Logging
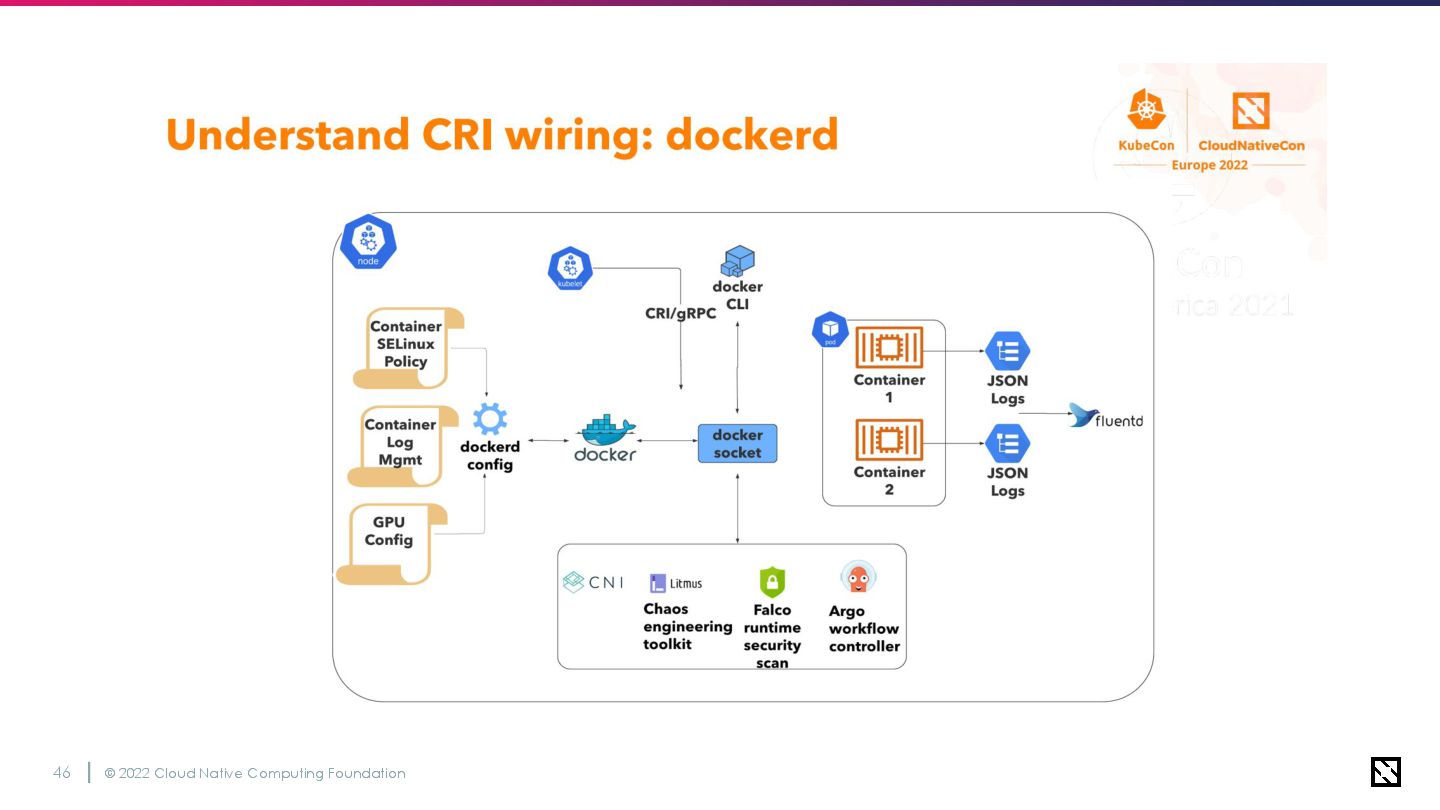
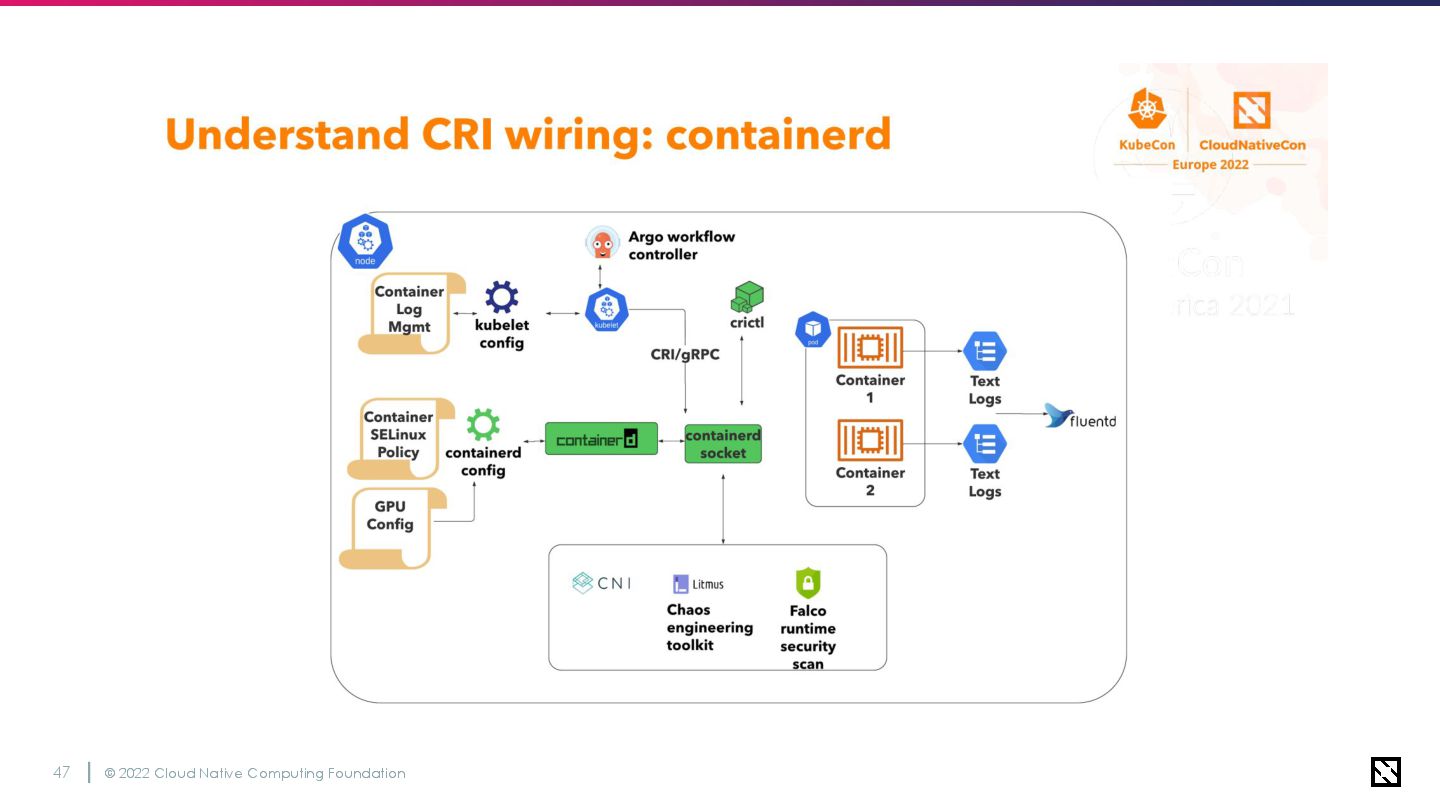
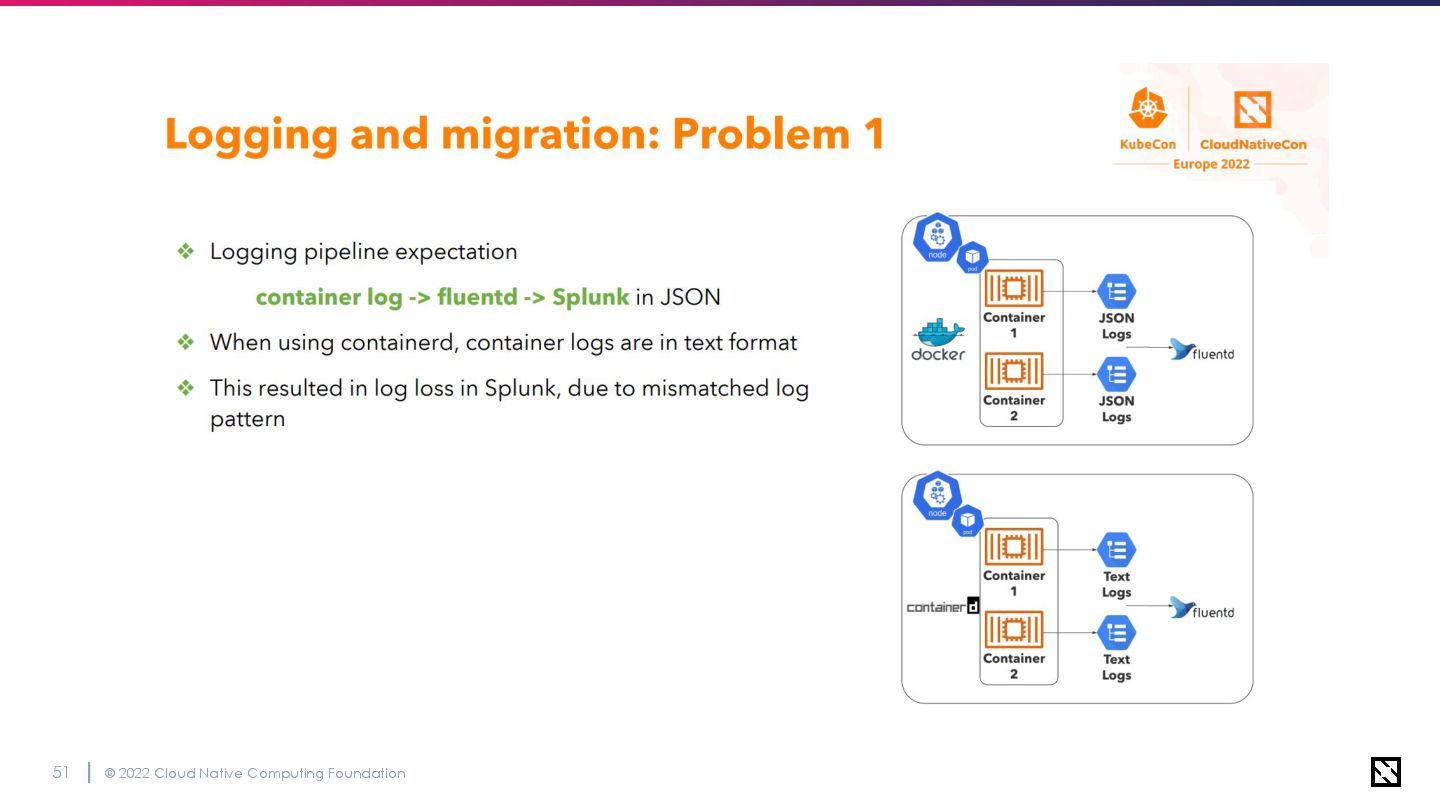
© 2022 Cloud Native Computing Foundation 50 Docker logging vs
CRI logging • Fluentd DaemonSetsをクラスターアドオンとしてデプロイ ◦ ログの収集、パース、アグリゲーターへの転送を担当 • Fluentdで収集するログの中でもコンテナログが最も重要度が高い ◦ Docker -> Containerdでロギングフォーマットが変更された
© 2022 Cloud Native Computing Foundation 51
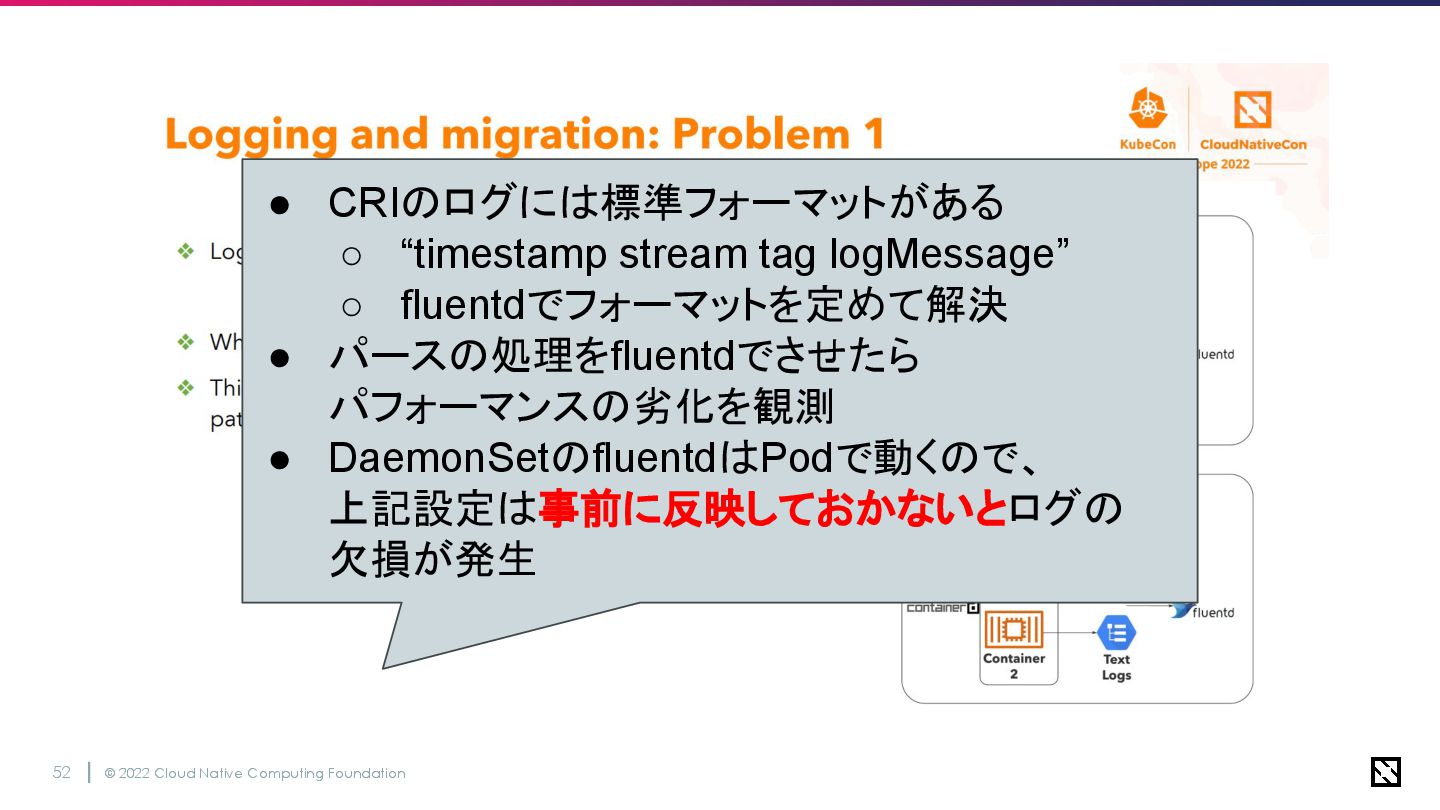
© 2022 Cloud Native Computing Foundation 52 • CRIのログには標準フォーマットがある ◦
“timestamp stream tag logMessage” ◦ fluentdでフォーマットを定めて解決 • パースの処理をfluentdでさせたら パフォーマンスの劣化を観測 • DaemonSetのfluentdはPodで動くので、 上記設定は事前に反映しておかないとログの 欠損が発生
CNIに関する考慮
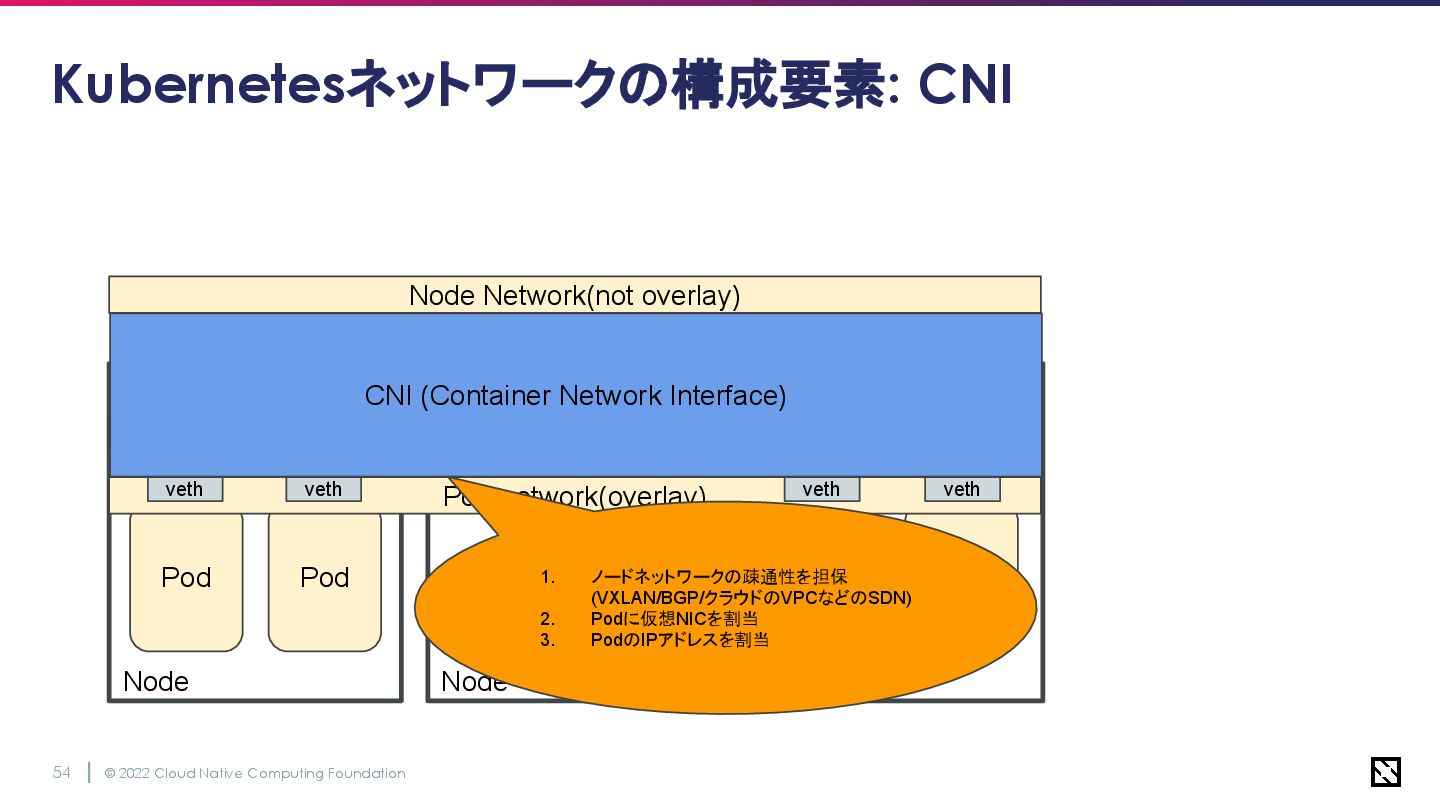
© 2022 Cloud Native Computing Foundation 54 Node Node Node
Pod Pod Pod Pod Kubernetesネットワークの構成要素: CNI Pod network(overlay) Service Network(overlay) Node Network(not overlay) veth veth veth veth eth0 eth0 eth0 CNI (Container Network Interface) 1. ノードネットワークの疎通性を担保 (VXLAN/BGP/クラウドのVPCなどのSDN) 2. Podに仮想NICを割当 3. PodのIPアドレスを割当
© 2022 Cloud Native Computing Foundation 55 CNIについて • 外の世界のネットワークとKubernetesのネットワークをつなげる役割
◦ クラウドのVPCやノードの制御に使うBGP、あるいはVXLANなどのホストレベルの ネットワークを認識できる • 各Podに割り当てる仮想NICの管理 ◦ コンテナ作成時にランタイムが作ったNW namespaceに対してvNICをアタッチ • 各PodのIPアドレス管理(要するにIPAM) ◦ コンテナは揮発性が高いので、CNIがIPAMのデーモンを管理してIPアドレスを管理し、Service のエンドポイント情報を書き換える
© 2022 Cloud Native Computing Foundation 56 CNIについて • 外の世界のネットワークとKubernetesのネットワークをつなげる役割
◦ クラウドのVPCやノードの制御に使うBGP、あるいはVXLANなどのホストレベルの ネットワークを認識できる • 各Podに割り当てる仮想NICの管理 ◦ コンテナ作成時にランタイムが作ったNW namespaceに対してvNICをアタッチ • 各PodのIPアドレス管理(要するにIPAM) ◦ コンテナは揮発性が高いので、CNIがIPAMのデーモンを管理してIPアドレスを管理し、Service のエンドポイント情報を書き換える 今回のポイント
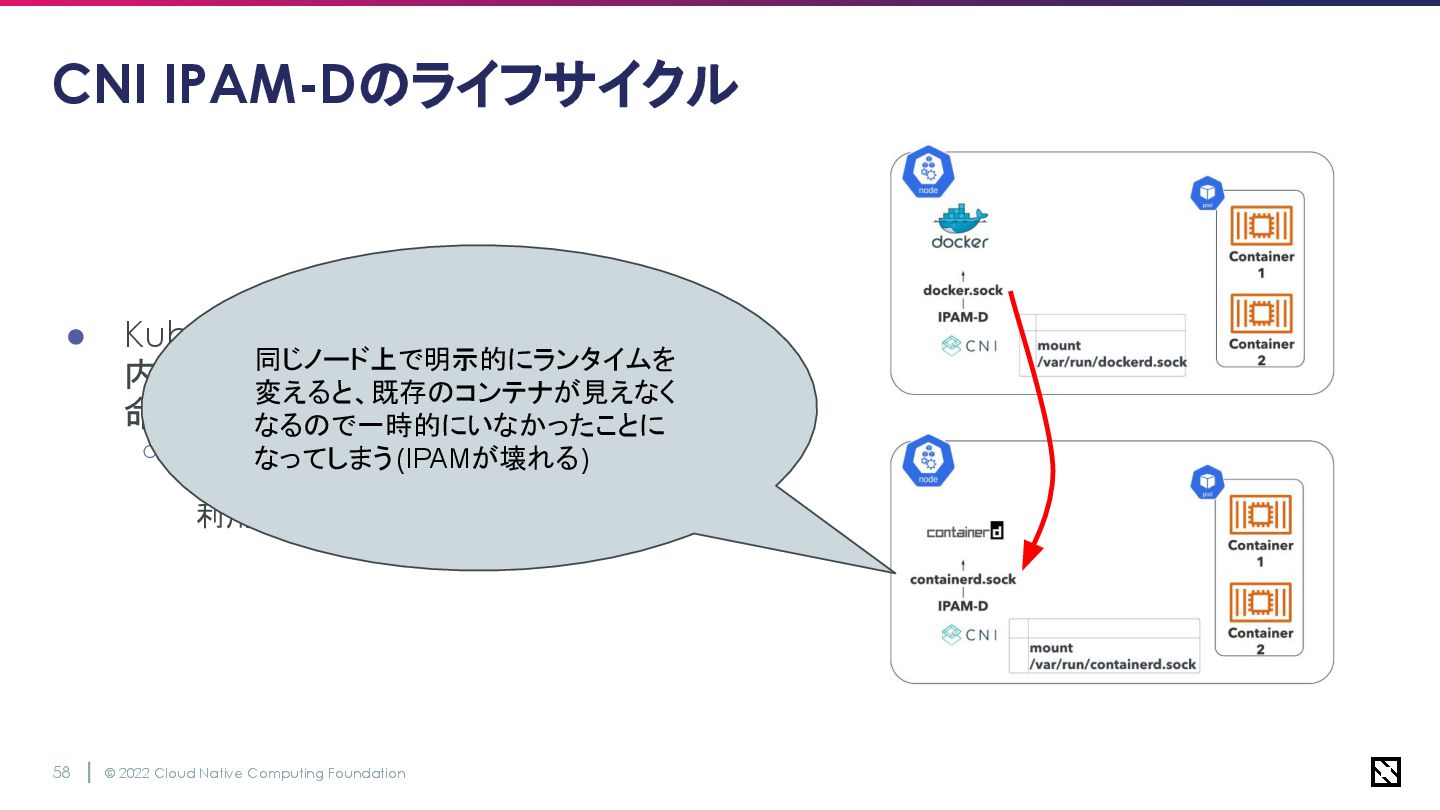
© 2022 Cloud Native Computing Foundation 57 CNI IPAM-Dのライフサイクル •
KubernetesでPodを作成するとき、 内部的にはkubeletがCRIランタイムに 命令を発行 ◦ CRIランタイムでは、コンテナ作成時に namespaceを作成し、CNIのIPAMが 利用可能なアドレスをそこに割り当てる
© 2022 Cloud Native Computing Foundation 58 CNI IPAM-Dのライフサイクル •
KubernetesでPodを作成するとき、 内部的にはkubeletがCRIランタイムに 命令を発行 ◦ CRIランタイムでは、コンテナ作成時に namespaceを作成し、CNIのIPAMが 利用可能なアドレスをそこに割り当てる 同じノード上で明示的にランタイムを 変えると、既存のコンテナが見えなく なるので一時的にいなかったことに なってしまう(IPAMが壊れる)
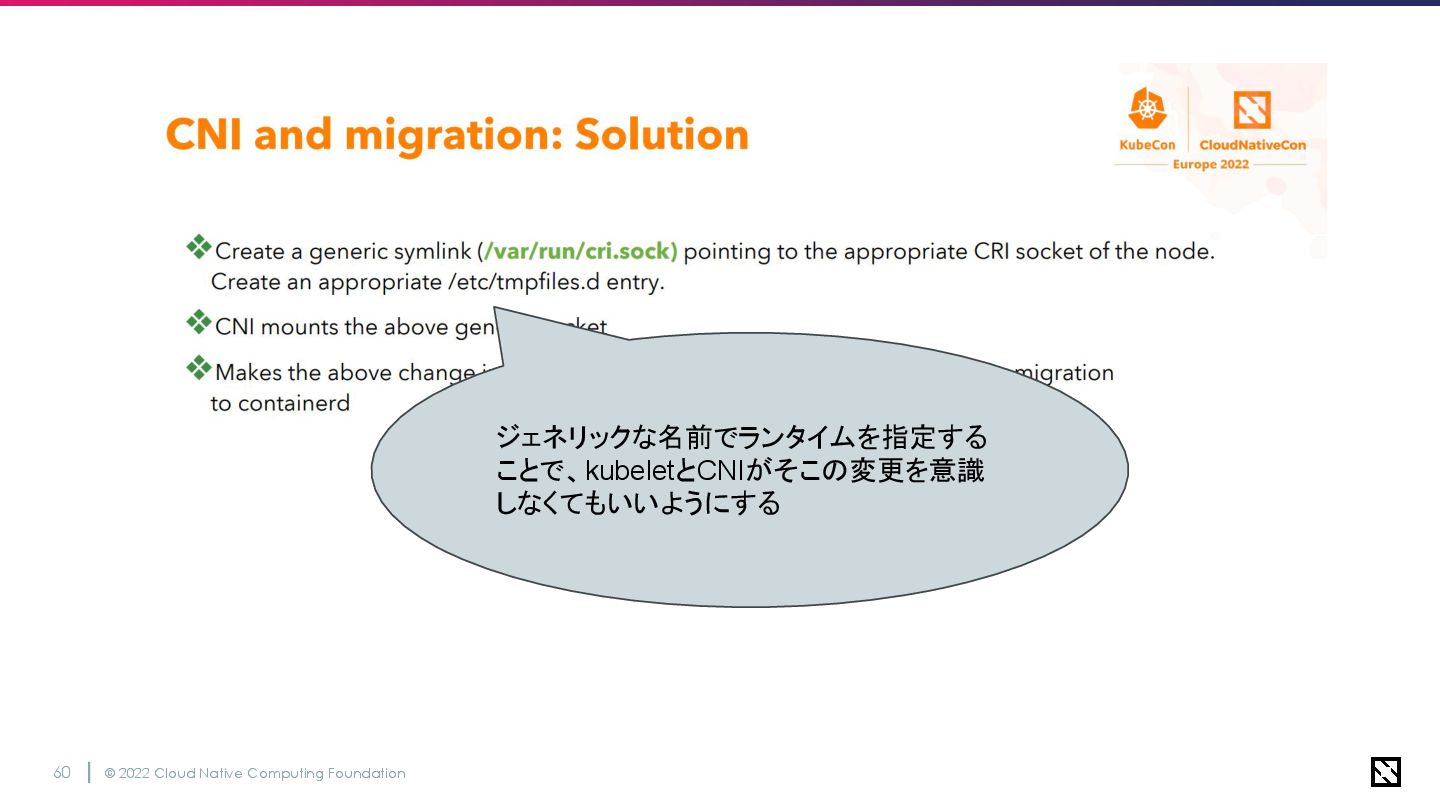
© 2022 Cloud Native Computing Foundation 59
© 2022 Cloud Native Computing Foundation 60 ジェネリックな名前でランタイムを指定する ことで、kubeletとCNIがそこの変更を意識 しなくてもいいようにする
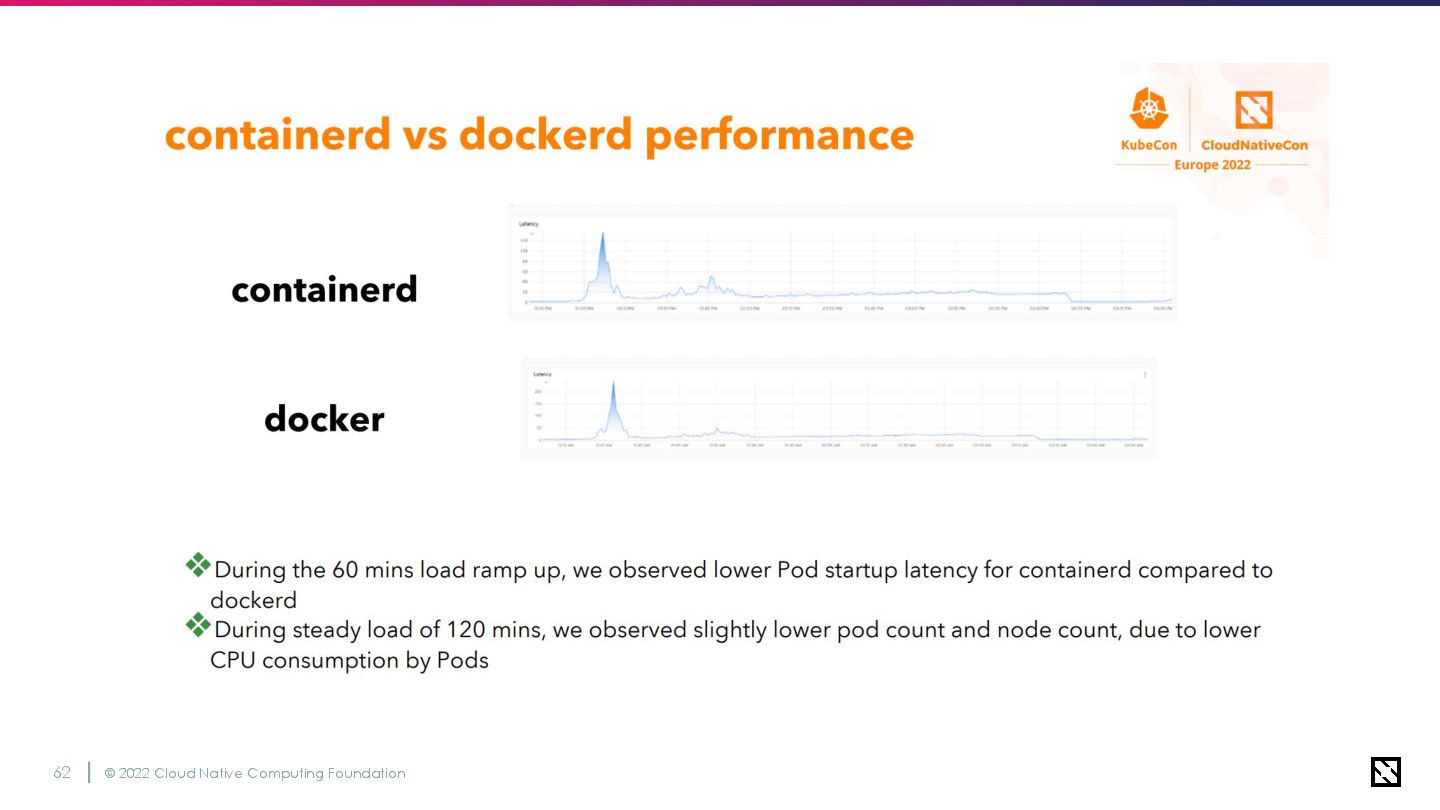
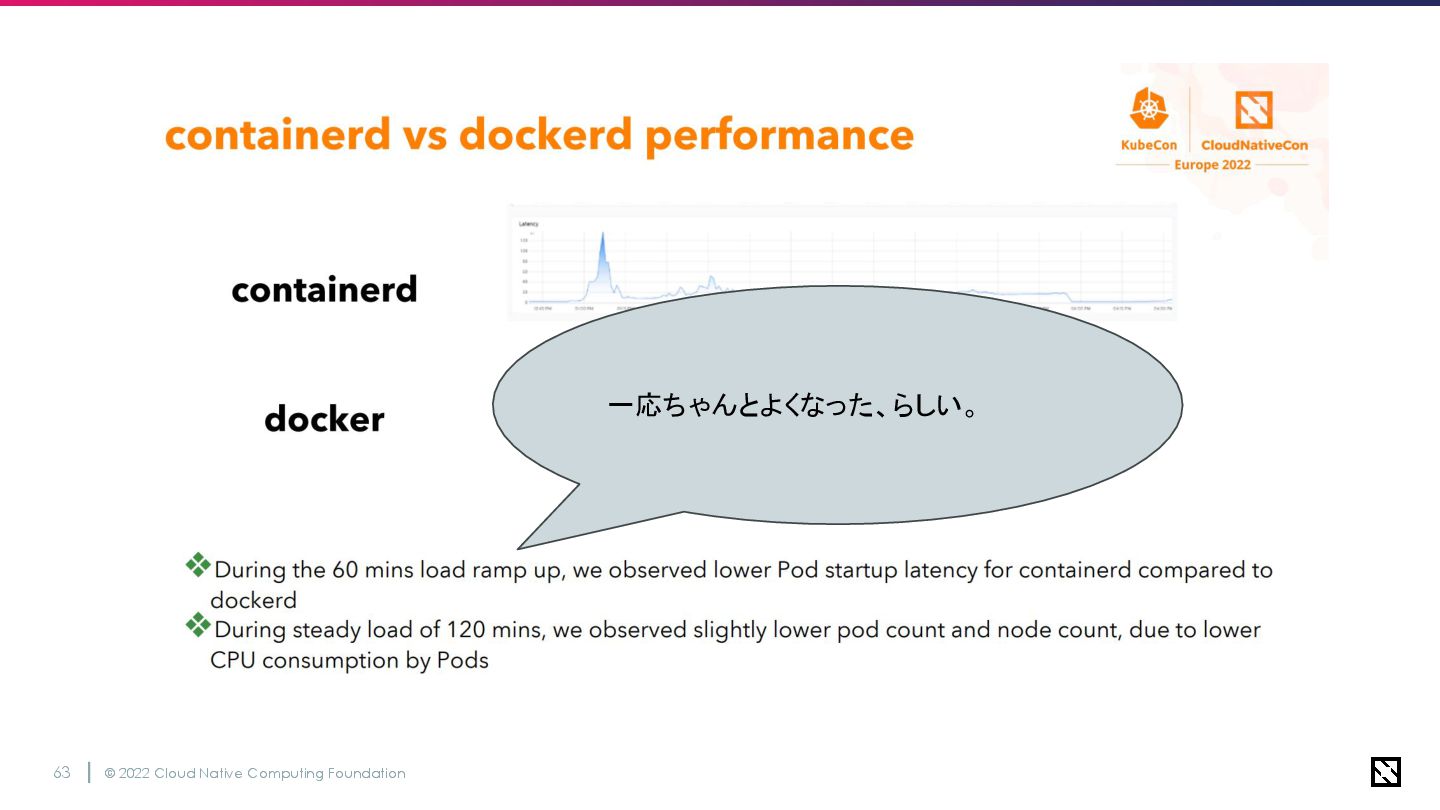
性能変化
© 2022 Cloud Native Computing Foundation 62
© 2022 Cloud Native Computing Foundation 63 一応ちゃんとよくなった、らしい。
まとめ
© 2022 Cloud Native Computing Foundation 65 所感 • 今回はBlue
GreenやCanaryではなくin-placeで全部を移行する事例を紹介 • Cluster APIに移行する方法はかなり知恵を絞った感じがして面白い • ランタイム移行のアプローチも王道といえば王道だが、ノードを作成して入れ替えて もよさそうなのにin-placeでやったのはかなり頑張ったなと思った ◦ 実際に確認したわけではなく想像だが、ノード数・クラスタ数ともに規模が大きいのでインフラコ ストも新規作成の管理コストもかさむことを懸念したのかなと思う
© 2022 Cloud Native Computing Foundation 66 参考資料 • 前半事例(Cluster
API)の資料 ◦ https://static.sched.com/hosted_files/kccnceu2022/10/KubeConEU22_MBTI_Clust erAPI_Migrate_700_Clusters.pdf • 前半事例(ランタイム)の資料 ◦ https://static.sched.com/hosted_files/kccnceu2022/2a/Containerd_KubeCon_EU _2022.pdf ◦ 動画リンクは現時点ではまだ上がっていないので割愛
Thank you for your attention! The CNCF aims to help
end users connect with other end users, recruit talent, and adopt cloud native successfully in a vendor neutral environment.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}