Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
オンラインの技術カンファレンスを安定稼働させるための取り組み / SRE activity f...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Kohei Ota
November 09, 2021
Technology
1.4k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
オンラインの技術カンファレンスを安定稼働させるための取り組み / SRE activity for online conference platform
Kohei Ota
November 09, 2021
More Decks by Kohei Ota
See All by Kohei Ota
CloudNative Meets WebAssembly: Exploring Wasm's Potential to Replace Containers
inductor
4
3.6k
The Cloud Native Chronicles: 10 Years of Community Growth Inside and Outside Japan
inductor
0
190
Cracking the KubeCon CfP
inductor
2
920
KubeCon Recap -Platform migration at Scale-
inductor
1
1.1k
コンテナビルド最新事情 2022年度版 / Container Build 2022
inductor
3
600
データベースとストレージのレプリケーション入門 / Intro-of-database-and-storage-replication
inductor
28
6.6k
KubeConのケーススタディから振り返る、Platform for Platforms のあり方と その実践 / Lessons from KubeCon case studies: Platform for Platforms and its practice
inductor
3
1k
Kubernetesネットワーキング初級者脱出ガイド / Kubernetes networking beginner's guide
inductor
22
7.7k
コンテナネイティブロードバランシングの話 / A story about container native load balancing
inductor
2
2.4k
Other Decks in Technology
See All in Technology
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
210
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
230
コンポーネント名には何を含めるべきなのか? / what-should-be-included-in-component-names
airrnot1106
0
140
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
250
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
240
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
6
540
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
1.4k
データエンジニアこそ組織のオントロジーに向き合うべき — 問いに答えるAIから、事業を動かすAIへ
gappy50
4
940
オートマトンと字句解析でRoslynを読む
tomokusaba
0
100
『モンスターストライク』 の運営に伴走する! データ民主化への 解析グループの3つのアプローチ
mixi_engineers
PRO
0
130
文字起こし基盤の信頼性
abnoumaru
0
150
「休む」重要さ
smt7174
7
1.7k
Featured
See All Featured
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
Scaling GitHub
holman
464
140k
Everyday Curiosity
cassininazir
0
260
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
How to Talk to Developers About Accessibility
jct
2
440
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Believing is Seeing
oripsolob
1
170
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
230
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Docker and Python
trallard
47
4k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
360
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
390
Transcript
オンラインの技術カンファレンスを 安定稼働させるための取り組み Presented by @inductor
自己紹介 Kohei Ota (@inductor) •アーキテクト@HPE •CNCF Ambassador •Google Developer Expert
(GCP) •CloudNative Days Tokyo 運営 •Container Runtime Meetup 運営 •Kubernetes SIG-Docs Japanese owner •Docker Meetup Tokyo 運営
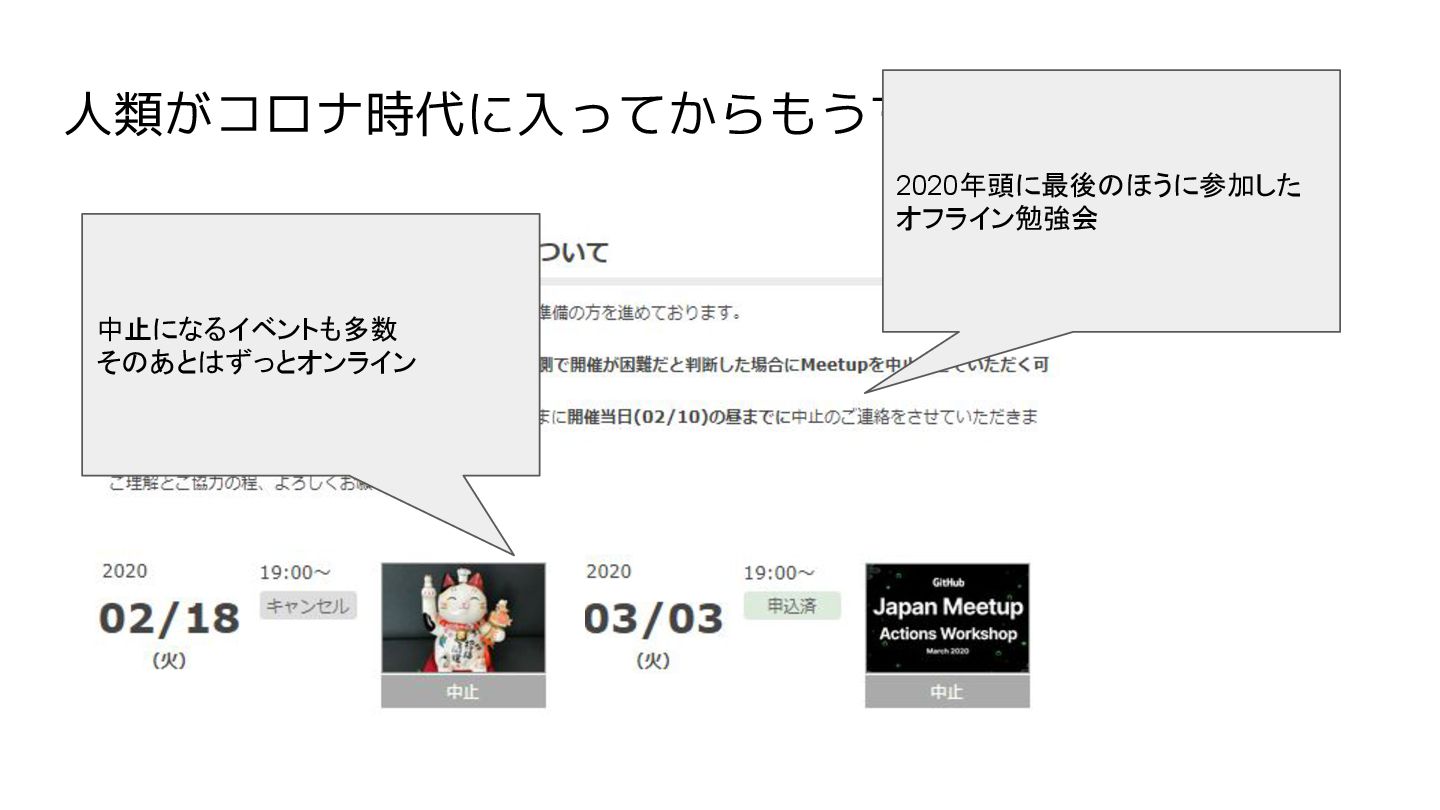
人類がコロナ時代に入ってからもうすぐ2年...
人類がコロナ時代に入ってからもうすぐ2年... 2020年頭に最後のほうに参加した オフライン勉強会 中止になるイベントも多数 そのあとはずっとオンライン
ミートアップでの取り組み • ZOOMの配信機能がかなり便利だった ◦ ほぼゼロコンフィグでYouTube Liveとの連携が終わる ◦ ただし細かいことはいじれないのでレールに乗っかるしかない • 配信機材調達や環境の準備が面倒
◦ 家で配信することになるので人によって音質・画質・回線品質がまちまち • 懇親会や質問による人間のやりとりがやりづらい ◦ Sli.doやTwitterなどのみでは質問内容や回答できる範囲に限界が・・・ → 大変になった部分もあったけど、やればやれないことはないレベル
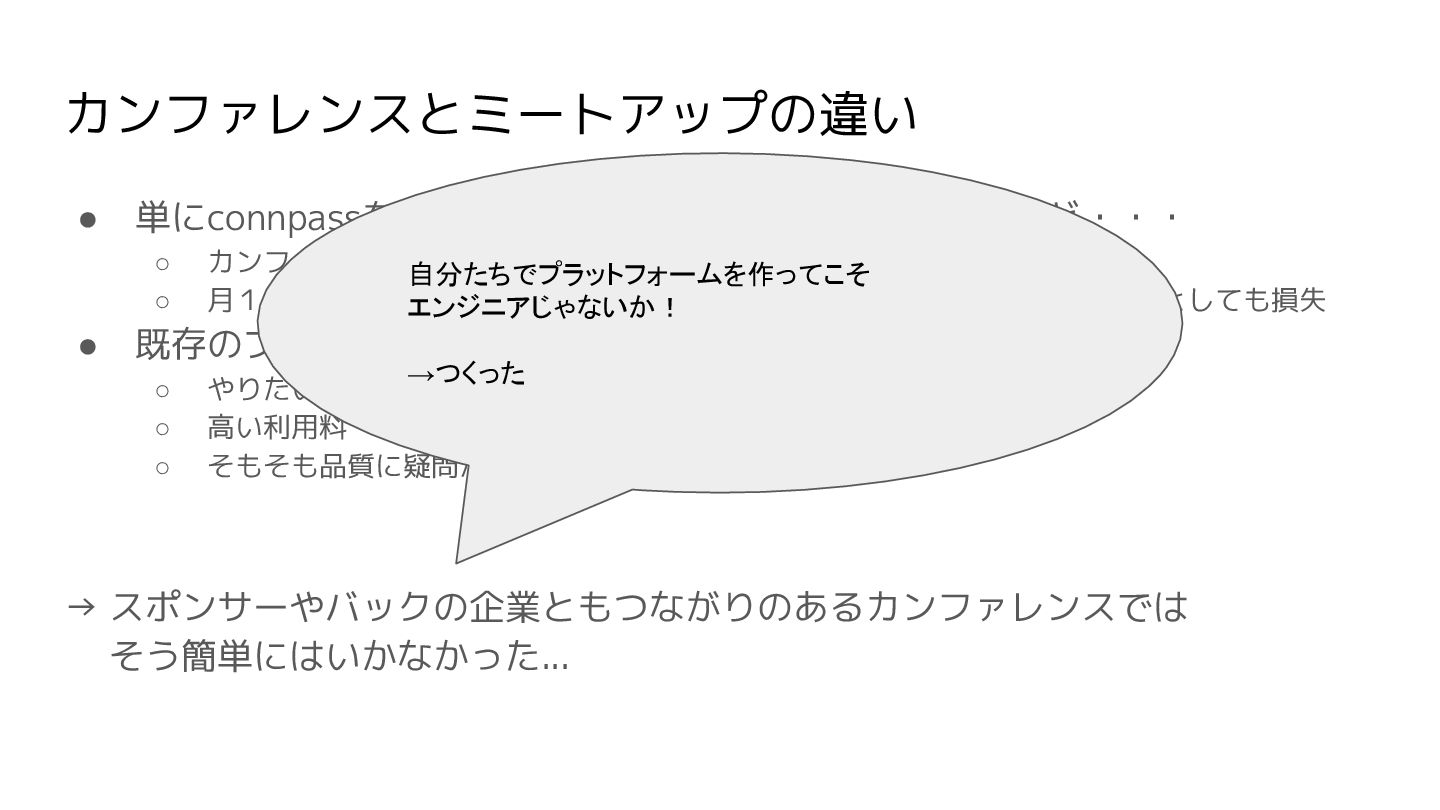
カンファレンスとミートアップの違い • 単にconnpassを用意して配信環境を用意するでもいいけど・・・ ◦ カンファレンスたるもの、提供できる形をもっと練るべき ◦ 月1とかじゃなくて年に数回のお祭りの体験が損なわれるのはコミュニティとしても損失 • 既存のプラットフォームを検討するも ◦
やりたい形に沿わないプラットフォームのSaaS ◦ 高い利用料 ◦ そもそも品質に疑問があることも → スポンサーやバックの企業ともつながりのあるカンファレンスでは そう簡単にはいかなかった...
カンファレンスとミートアップの違い • 単にconnpassを用意して配信環境を用意するでもいいけど・・・ ◦ カンファレンスたるもの、提供できる形をもっと練るべき ◦ 月1とかじゃなくて年に数回のお祭りの体験が損なわれるのはコミュニティとしても損失 • 既存のプラットフォームを検討するも ◦
やりたい形に沿わないプラットフォームのSaaS ◦ 高い利用料 ◦ そもそも品質に疑問があることも → スポンサーやバックの企業ともつながりのあるカンファレンスでは そう簡単にはいかなかった... 自分たちでプラットフォームを作ってこそ エンジニアじゃないか! →つくった
None
CloudNative Days Tokyo 2021 • 日付 2021年11月4日(木)-5日(金) • 会場 オンライン開催
• 主催 CloudNative Days Tokyo Committee • 参加費 無料(事前登録制) • 想定人数 2,000名〜3,000名 • 想定来場者インフラエンジニア SRE, アプリエンジニアなど8割以上が開発者、その他 CTO/CIO, システムインテグレーターなど • キーワードCloudNative, Kubernetes, Container, Microservices, CI/CD, DevOps, Edge/NFV, AI/Machine Learning, GPU/HPC • URL https://event.cloudnativedays.jp/cndt2021 Overview 9
CNDT2021 実行委員会メンバー Co-Chair Operation Platform Promotion Contents Broadcast Co-Chair
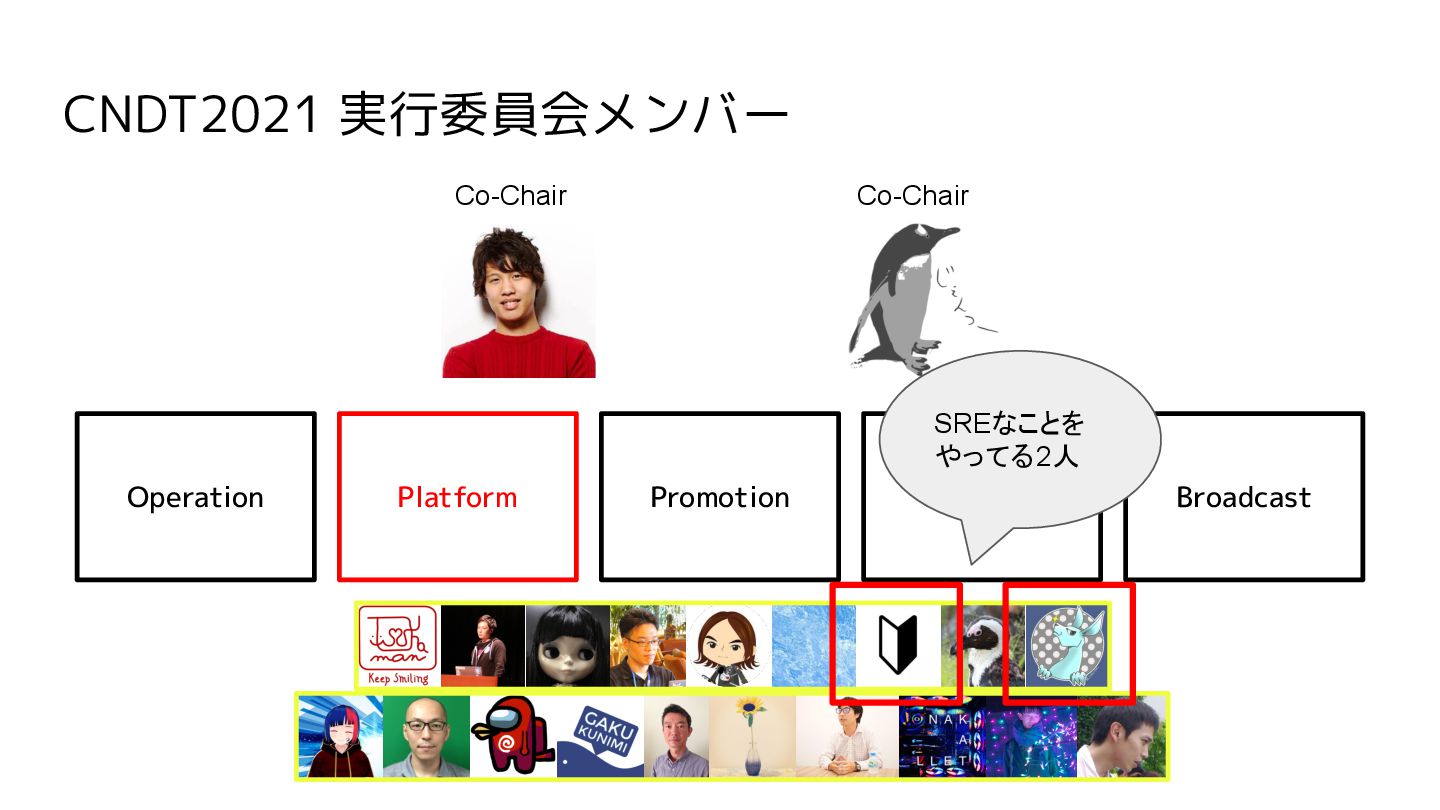
CNDT2021 実行委員会メンバー Co-Chair Operation Platform Promotion Contents Broadcast Co-Chair SREなことを
やってる2人
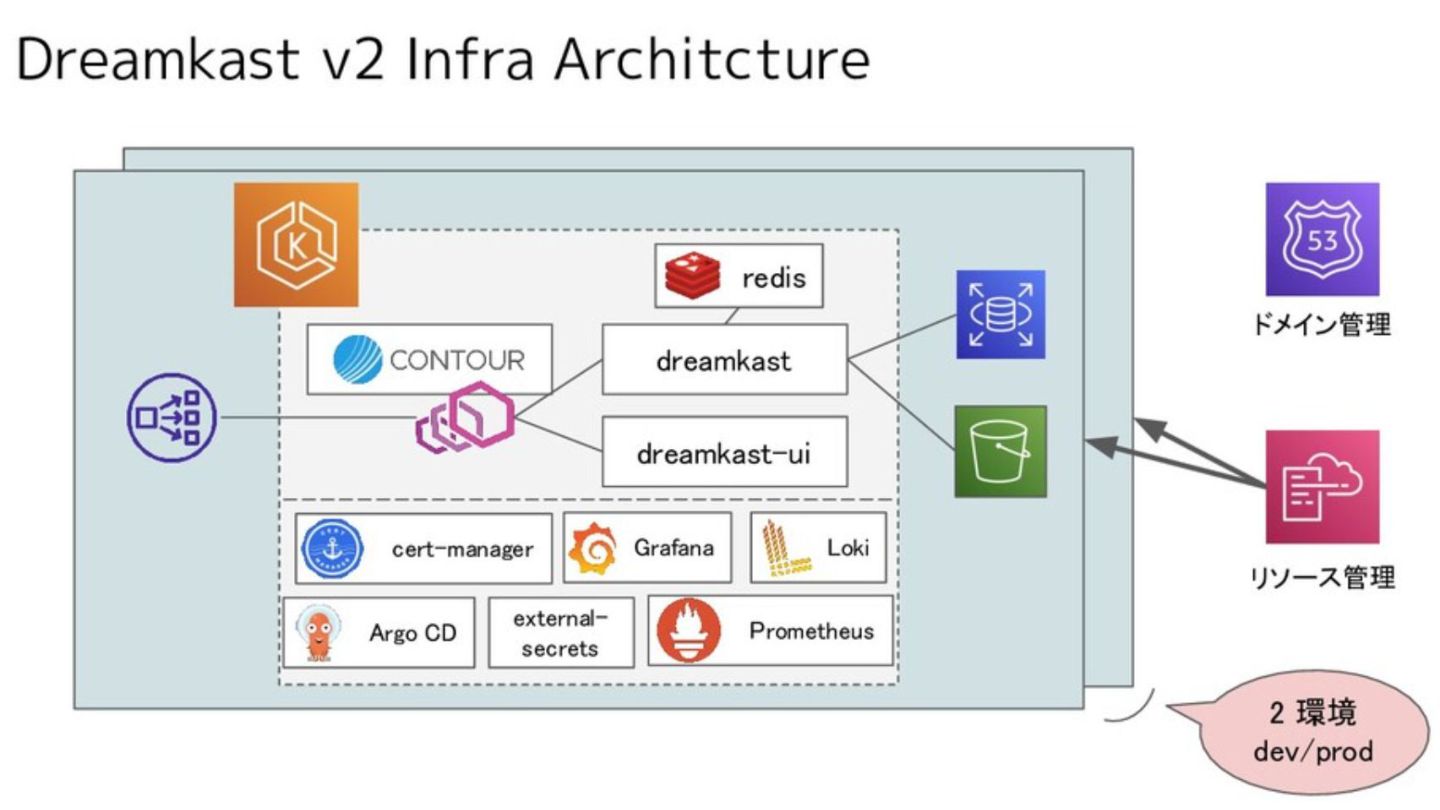
Dreamkast: オンライン配信プラットフォーム • https://github.com/cloudnativedaysjp/dreamkast • https://github.com/cloudnativedaysjp/dreamkast-infra • RailsのWebアプリ + Next.jsの配信ダッシュボード(視聴者画面)
• EKS + IVS + MediaLive で組まれたインフラ ◦ EKSでRailsを動かしてIVSとMediaLiveで配信を受ける構成
CNDT2021 実行委員会メンバー Co-Chair Operation Platform Promotion Contents Broadcast Co-Chair SREなことを
やってる2人 プラットフォームとしての改善の話はこの スライドを見てください
None
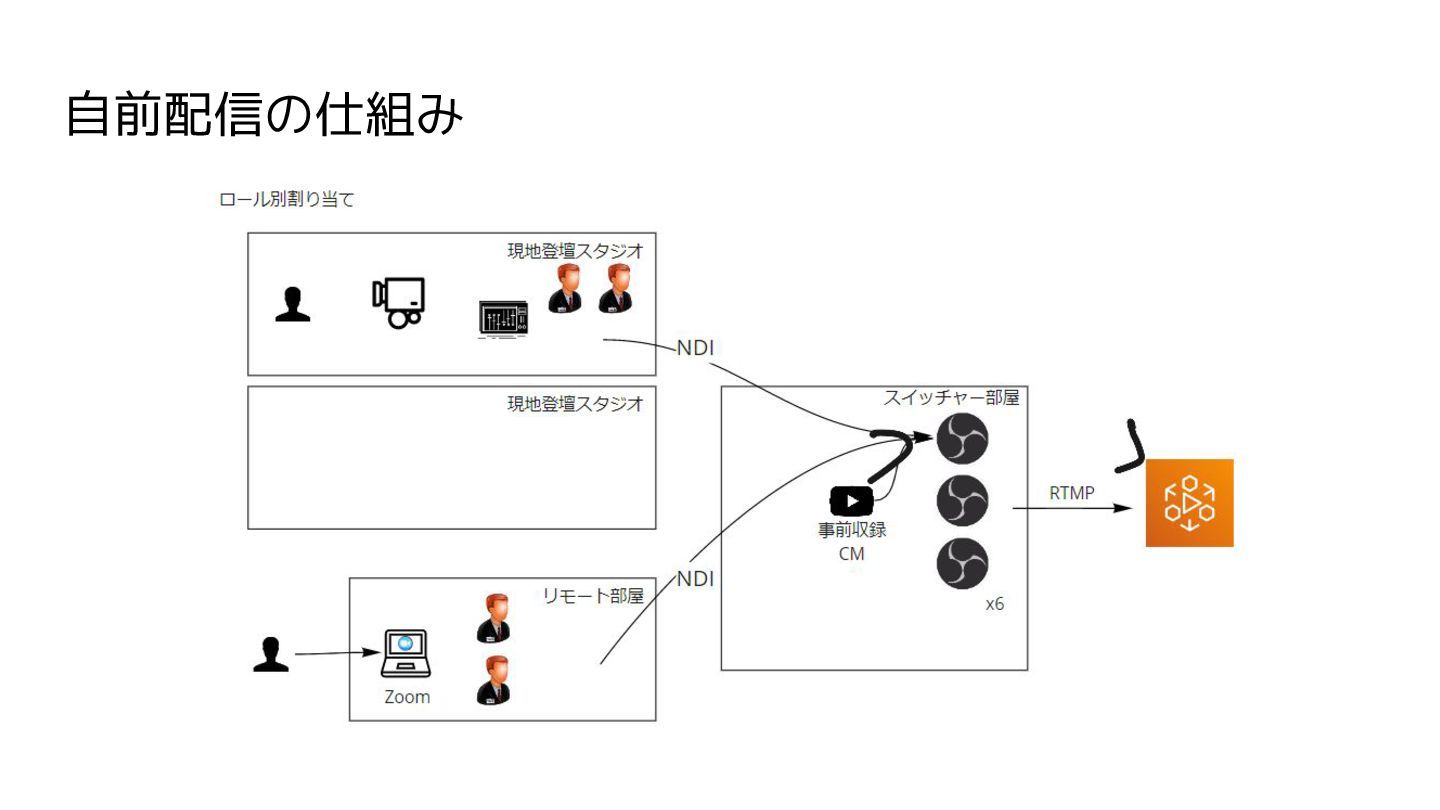
自前配信の仕組み
これまでの変遷 • v1はHerokuで作って公開した ◦ 便利だし楽、使い慣れてもいる ◦ レイテンシが大きい+開発体制としても今後どんどん大きくなっていった時に取り回しが 効かなくなってくる ◦ ECSかEKSか迷ってEKSにした(使い慣れてるし)
• まともにAWSで大きなものを作ると高い ◦ RedisにElastiCache最初は使ってたけどやめた ▪ 高い上にそこまで使いきれなかった→自前でRedisを動かすことに ◦ 全部Spotインスタンスで動かす強気の運用 ▪ めちゃめちゃ安い ◦ 仕事じゃないので使えるものは使う ▪ マネージドノードグループ、Cluster Autoscaler、Bottlerocket(最近入れた)
改善してきたこと • 運用のために使っているKubernetesマニフェストとCloudFormationの YAMLファイルはかなり成長してきた ◦ それなりの規模で動かしても大丈夫なくらいにはまともなコードになりつつあると思う • 相方のSREがPull requestベースでステージング上に検証用のPodが立ち上 がってLBに登録されるみたいなやつをオペレーター実装してくれた
• AWS自体で取り組まれている改善は極力リアルタイムに入れている ◦ 運用周りのオペレーターとか、新機能の追加検証とか、好きに実験してる ◦ さっきのページの「仕事じゃないので使えるものは使う」に同じ ◦ Fargateは最初入れたけどスケールが遅いのでやめた
今まで起こったプラットフォーム周りのあれこれ • イベント開始直後に500エラーが頻発(EKSにしてから最初のイベント) ◦ アクセス過多でスケールが間に合わなくて捌ききれなかった ◦ 手動でスケールしてどうにかしたけど次からはちゃんと負荷試験かけるようにした ◦ 本番ではなくプレイベントでよかった・・・(これ以外にもプレイベントでは本番で困らない ようにたくさんのことを実験しています)
• ArgoCDが重くて動かなくなった ◦ リポジトリ登録数が増えて負荷が高くなった ◦ デフォルトで設定されていたCPU Limitsを引き上げて解決 • 激アツ!Redis再起動 ◦ ログインセッションがブチッと切れる→こまる ◦ 実はまだ改善しないといけないポイント
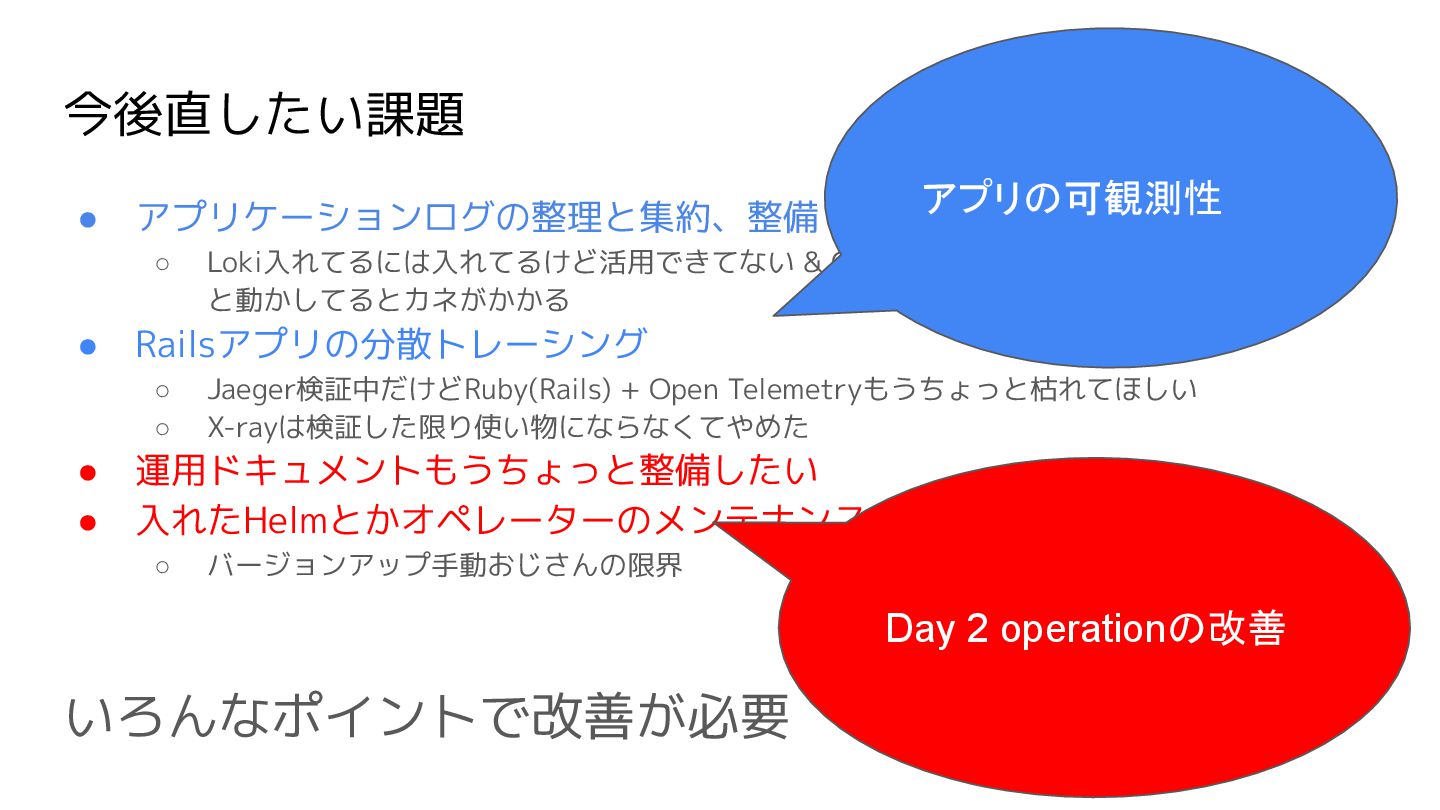
今後直したい課題 • アプリケーションログの整理と集約、整備 ◦ Loki入れてるには入れてるけど活用できてない & CloudWatchのContainer Insightsはずっ と動かしてるとカネがかかる •
Railsアプリの分散トレーシング ◦ Jaeger検証中だけどRuby(Rails) + Open Telemetryもうちょっと枯れてほしい ◦ X-rayは検証した限り使い物にならなくてやめた • 運用ドキュメントもうちょっと整備したい • 入れたHelmとかオペレーターのメンテナンスどうするか ◦ バージョンアップ手動おじさんの限界
今後直したい課題 • アプリケーションログの整理と集約、整備 ◦ Loki入れてるには入れてるけど活用できてない & CloudWatchのContainer Insightsはずっ と動かしてるとカネがかかる •
Railsアプリの分散トレーシング ◦ Jaeger検証中だけどRuby(Rails) + Open Telemetryもうちょっと枯れてほしい ◦ X-rayは検証した限り使い物にならなくてやめた • 運用ドキュメントもうちょっと整備したい • 入れたHelmとかオペレーターのメンテナンスどうするか ◦ バージョンアップ手動おじさんの限界 いろんなポイントで改善が必要 アプリの可観測性 Day 2 operationの改善
まとめ • 1からSREを実践できる環境は少ない ◦ スケールしながら育てていくもの • サービスのフェーズに合わせてできることから取り組む • 多様性を大事にする ◦
メンバーごとに得意なことが違って良い。それが大きなSREになってゆく • SREチームを作って満足しない ◦ 本質はサービスが重要なタイミングで正しく動き続けること ◦ 対話によって数字を決めましょう
We are hiring!! (運営メンバー)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}