'order_id': random.randint(1000, 9999), 'amount': order_data.get('amount', 0), 'customer': order_data.get('customer', 'unknown') }) logger.error("Order creation failed", extra={ 'reason': 'payment_declined', 'amount': order_data.get('amount', 0) }) Query in Grafana: # All errors {service="flaskcon-demo-app"} |= "ERROR" # Errors with high amounts {service="flaskcon-demo-app"} | json | amount > 100 | level="ERROR"
{kind=link}
{kind=link}
{kind=link}
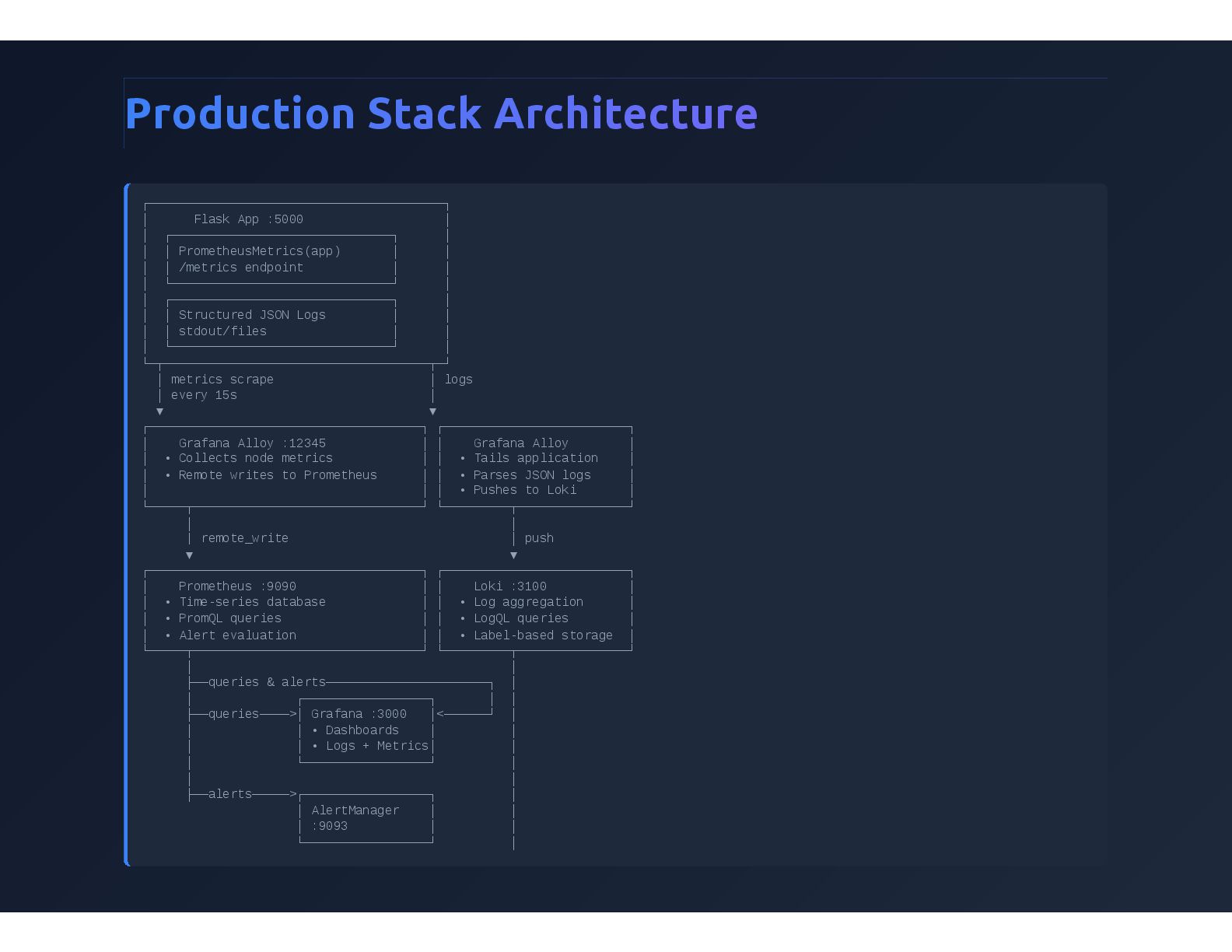{kind=link}
{kind=link}
{kind=link}
![Tracking Business Metrics @app.route('/api/orders', methods=['POST']) def create_order(): """Simulate order creation](https://files.speakerdeck.com/presentations/1b548c2b0397438581a24f2035f892be/slide_6.jpg){kind=link}
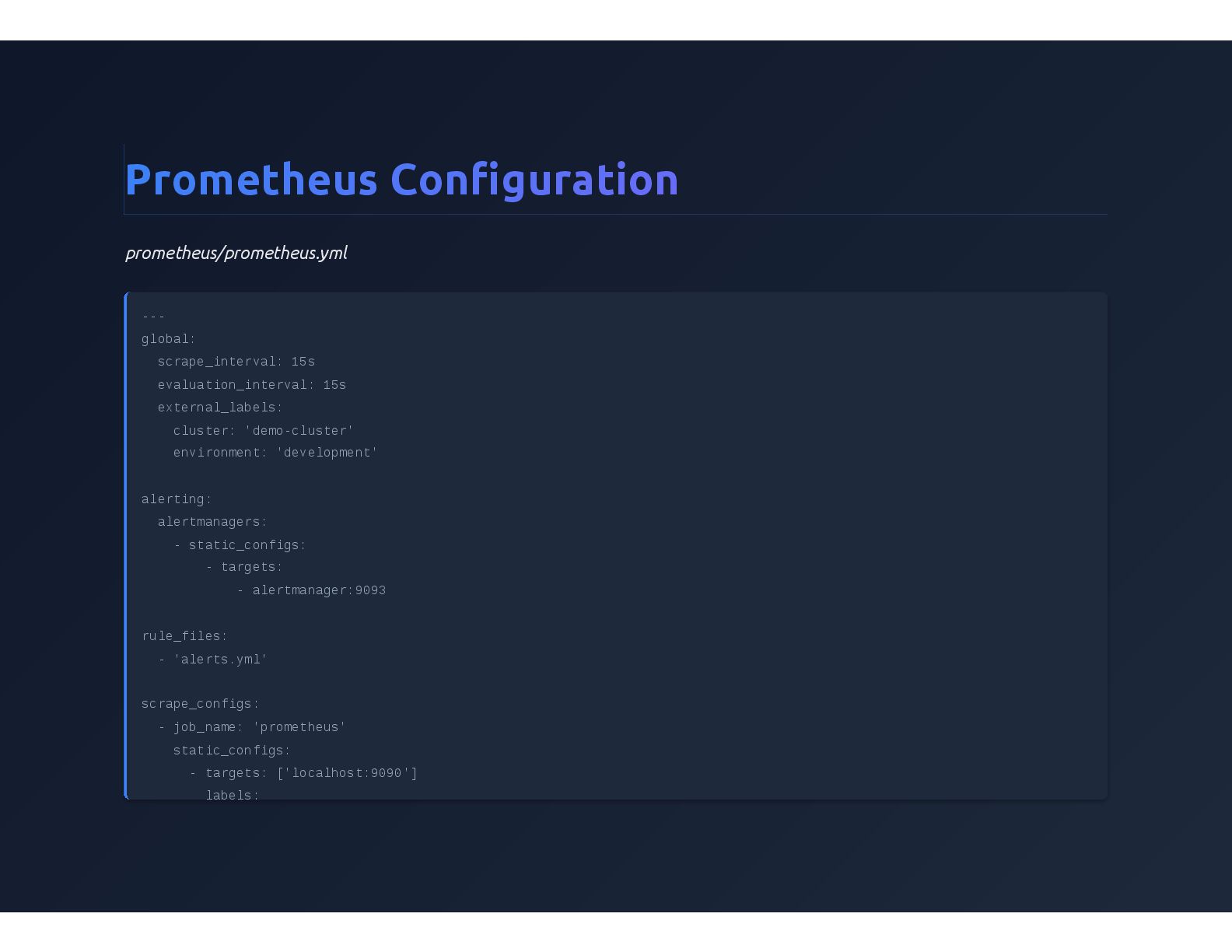{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
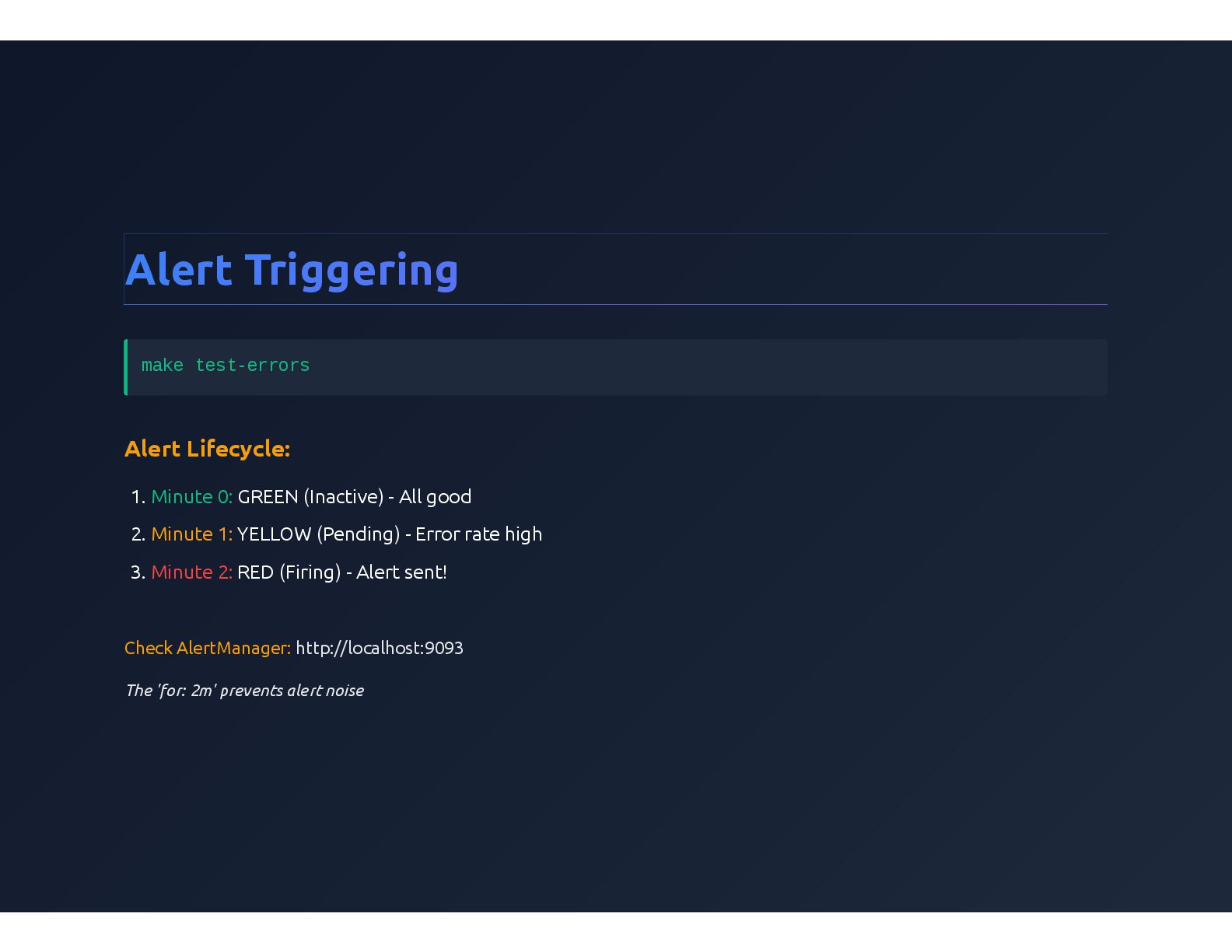{kind=link}
![Prometheus Queries Request Rate per Endpoint: sum(rate(flask_http_request_total[5m])) by (path) Error](https://files.speakerdeck.com/presentations/1b548c2b0397438581a24f2035f892be/slide_13.jpg){kind=link}
![Performance Analysis Slowest Endpoints (Top 5): topk(5, histogram_quantile(0.95, sum(rate(flask_http_request_duration_seconds_bucket[5m])) by](https://files.speakerdeck.com/presentations/1b548c2b0397438581a24f2035f892be/slide_14.jpg){kind=link}
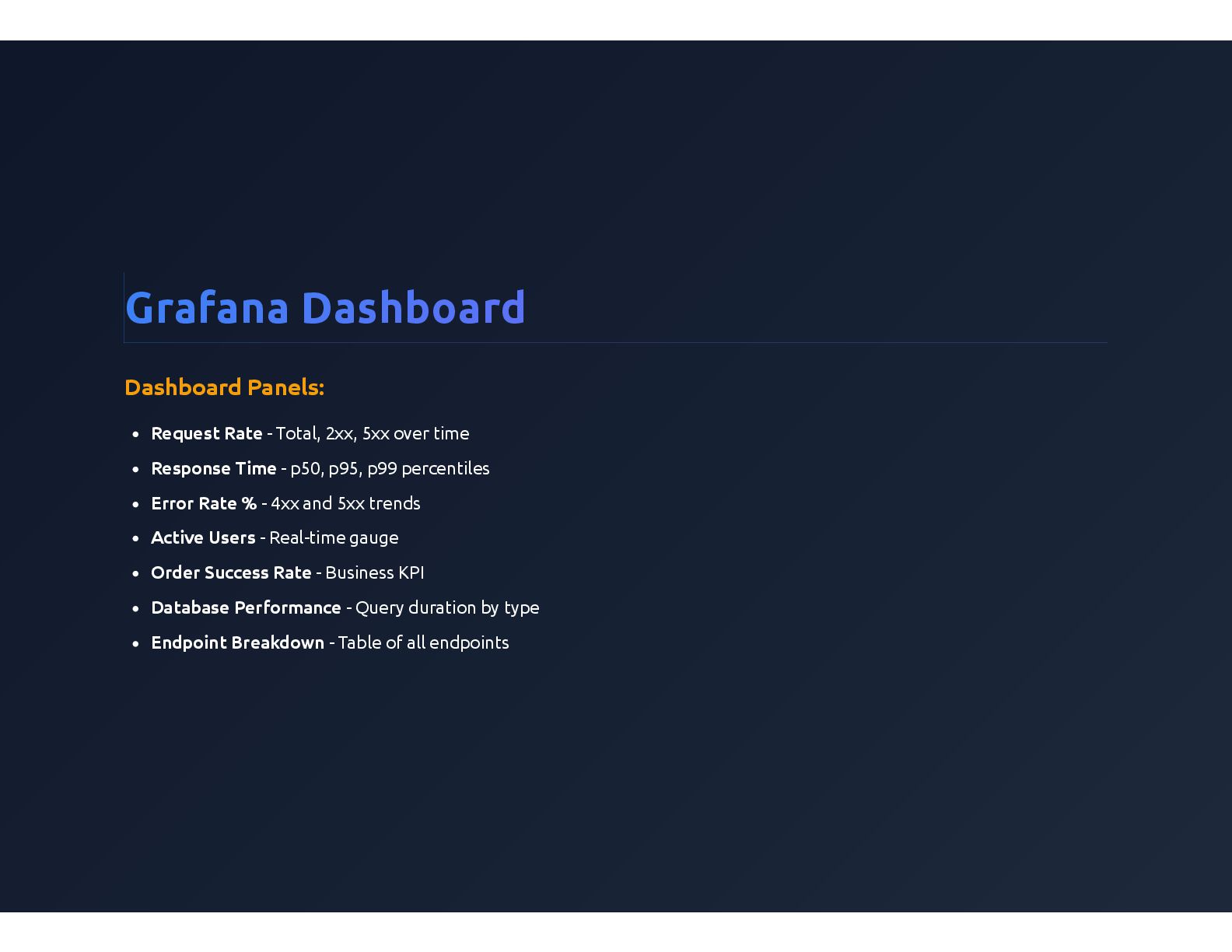{kind=link}
{kind=link}
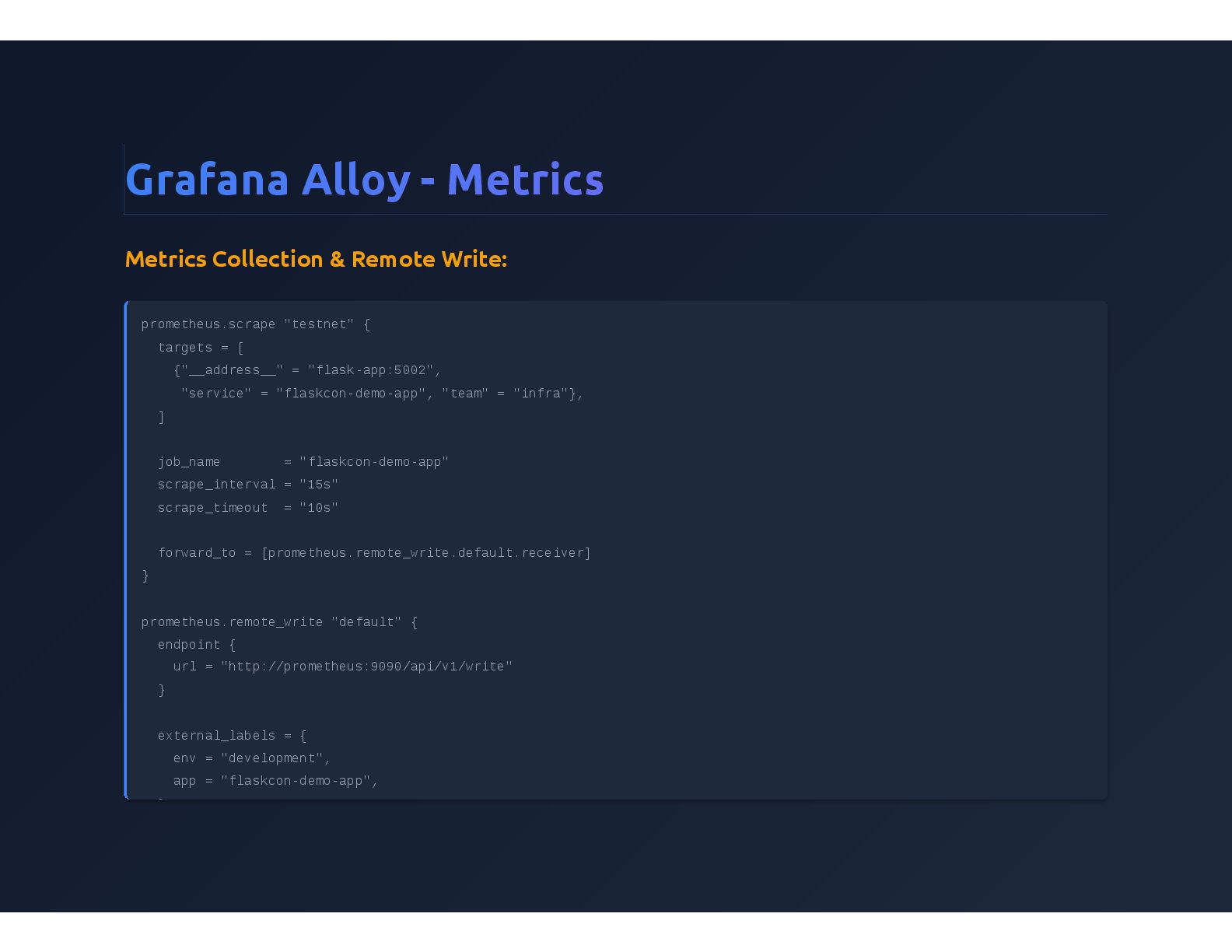{kind=link}
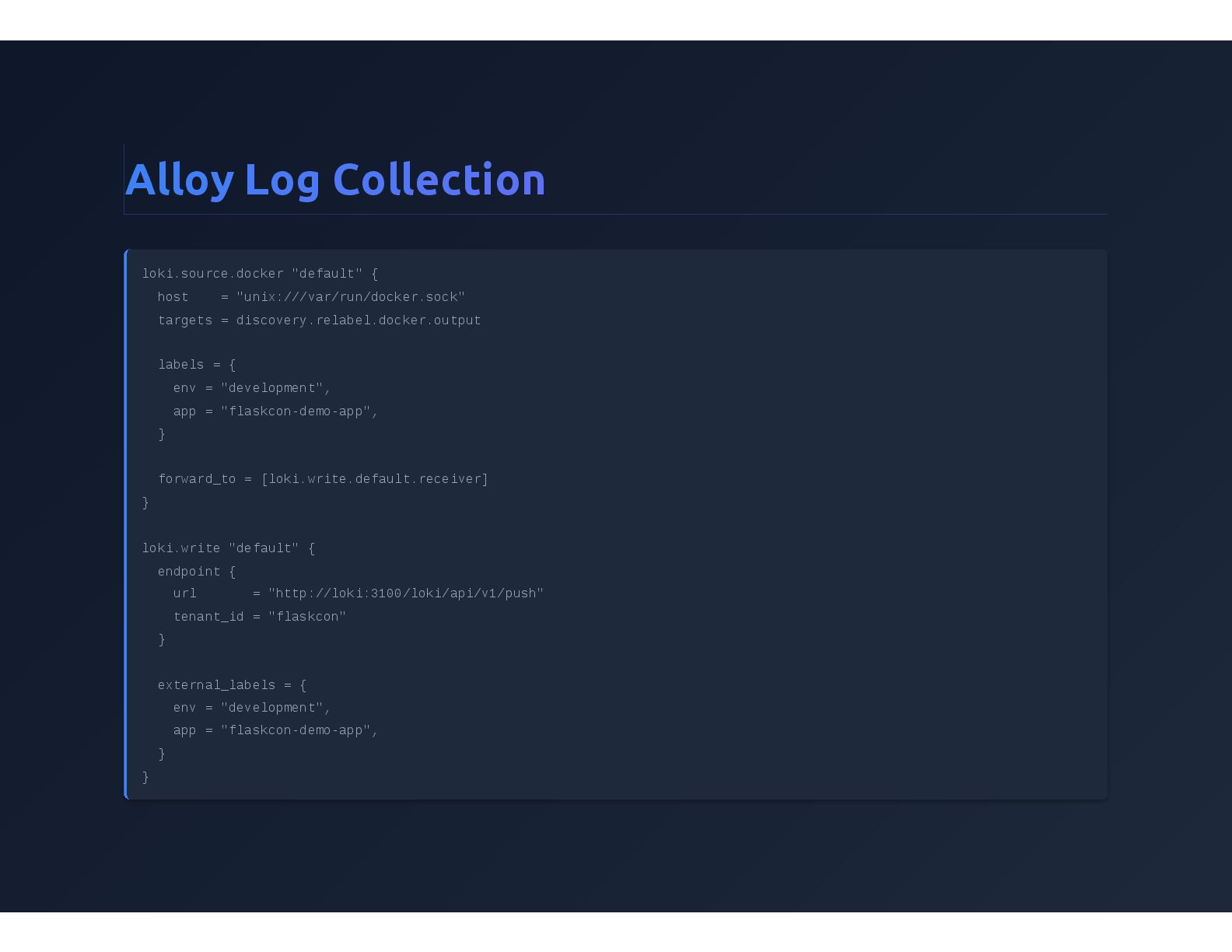{kind=link}
{kind=link}
{kind=link}
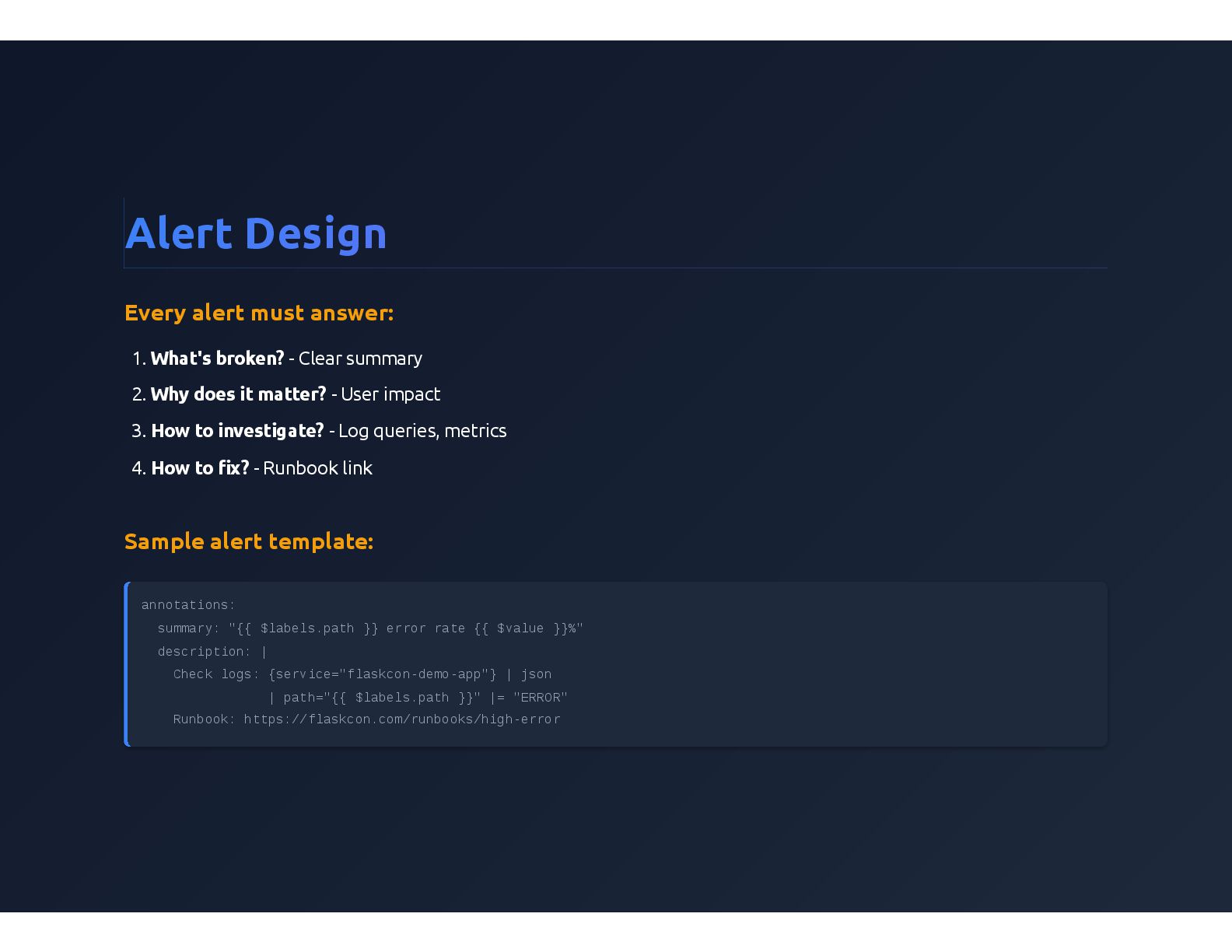{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! Questions? github.com/birozuru/flaskcon-demo [email protected] @birozuru The complete code is](https://files.speakerdeck.com/presentations/1b548c2b0397438581a24f2035f892be/slide_25.jpg){kind=link}