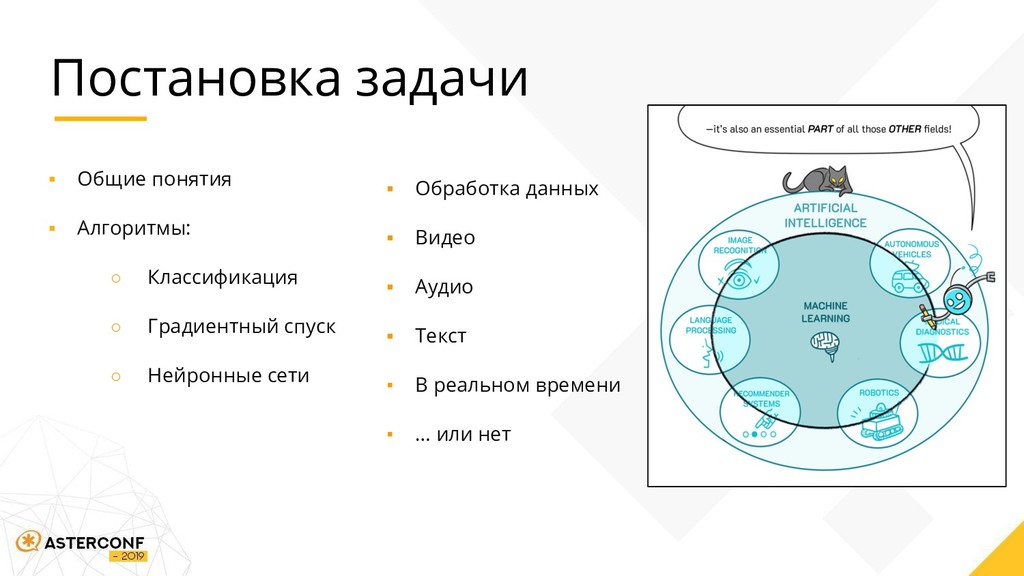
Области применения: ▪ Антифрод системы Анализ CDR и логов: ▪ Анализ изображения ▪ Определение эмоций ▪ Разделение аудио Области применения: ▪ HR-сервисы ▪ Валидация пользователя Анализ видео:
шум? ▪ Можно ли использовать в телефоне? ▪ Как распознать музыку? Возникающие вопросы и ответы ▪ Как распознать говорящего? ▪ Что насчет синтеза? ▪ Что насчет пунктуации?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![СПАСИБО ЗА ВНИМАНИЕ! +7 (929) 364 1441 [email protected] Гончаровский Игорь](https://files.speakerdeck.com/presentations/5de196fdf0414c64966d12ae9c15a477/slide_34.jpg){kind=link}