本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
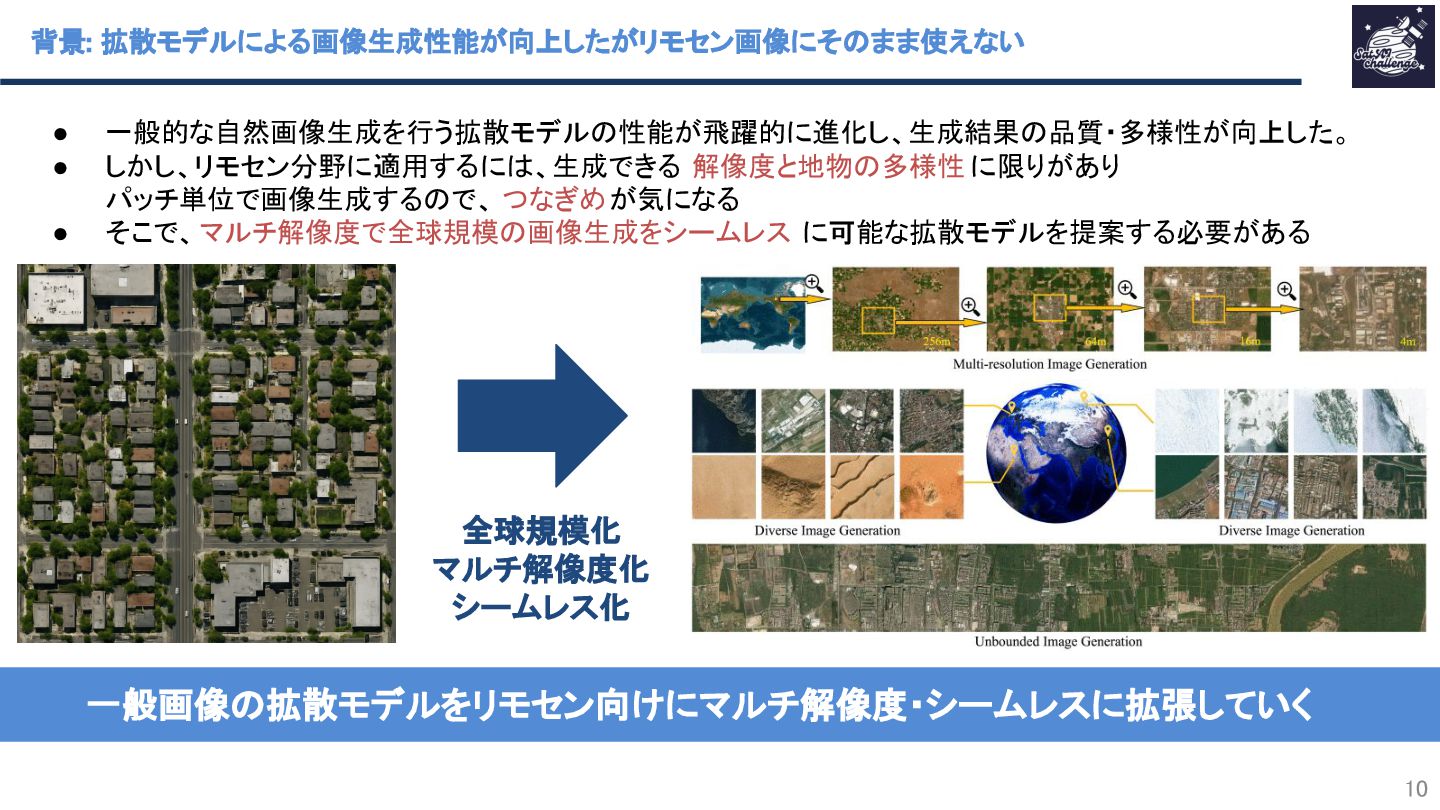
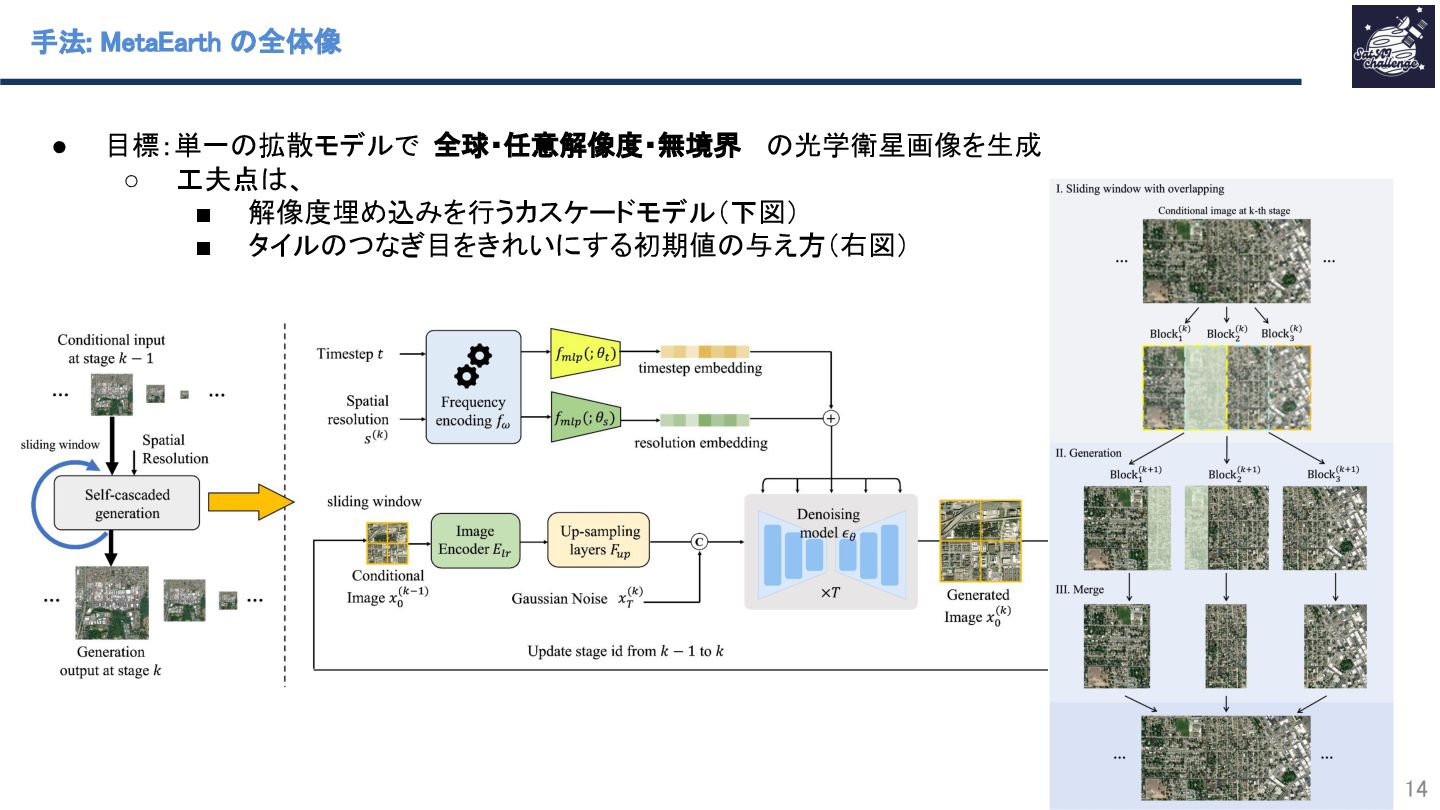
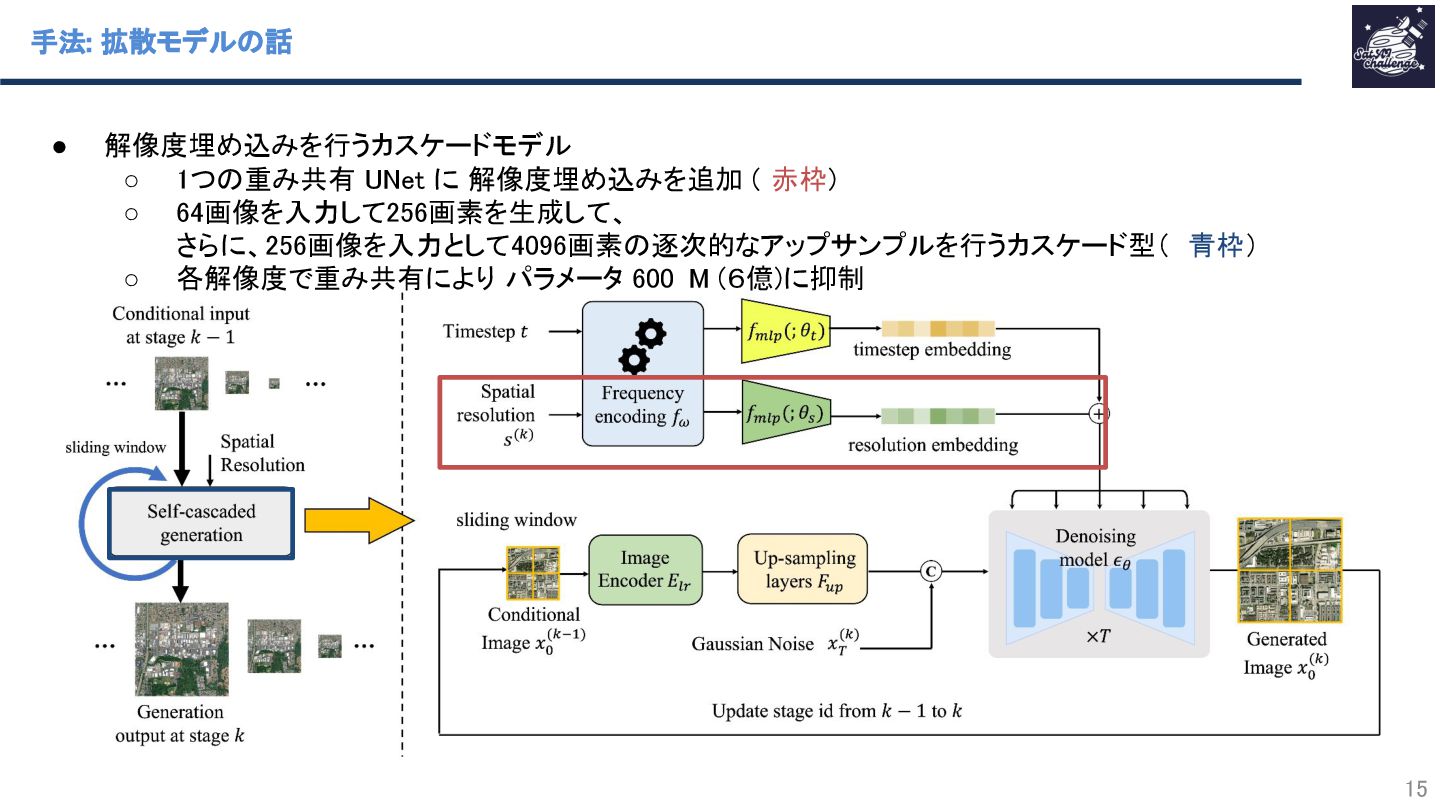
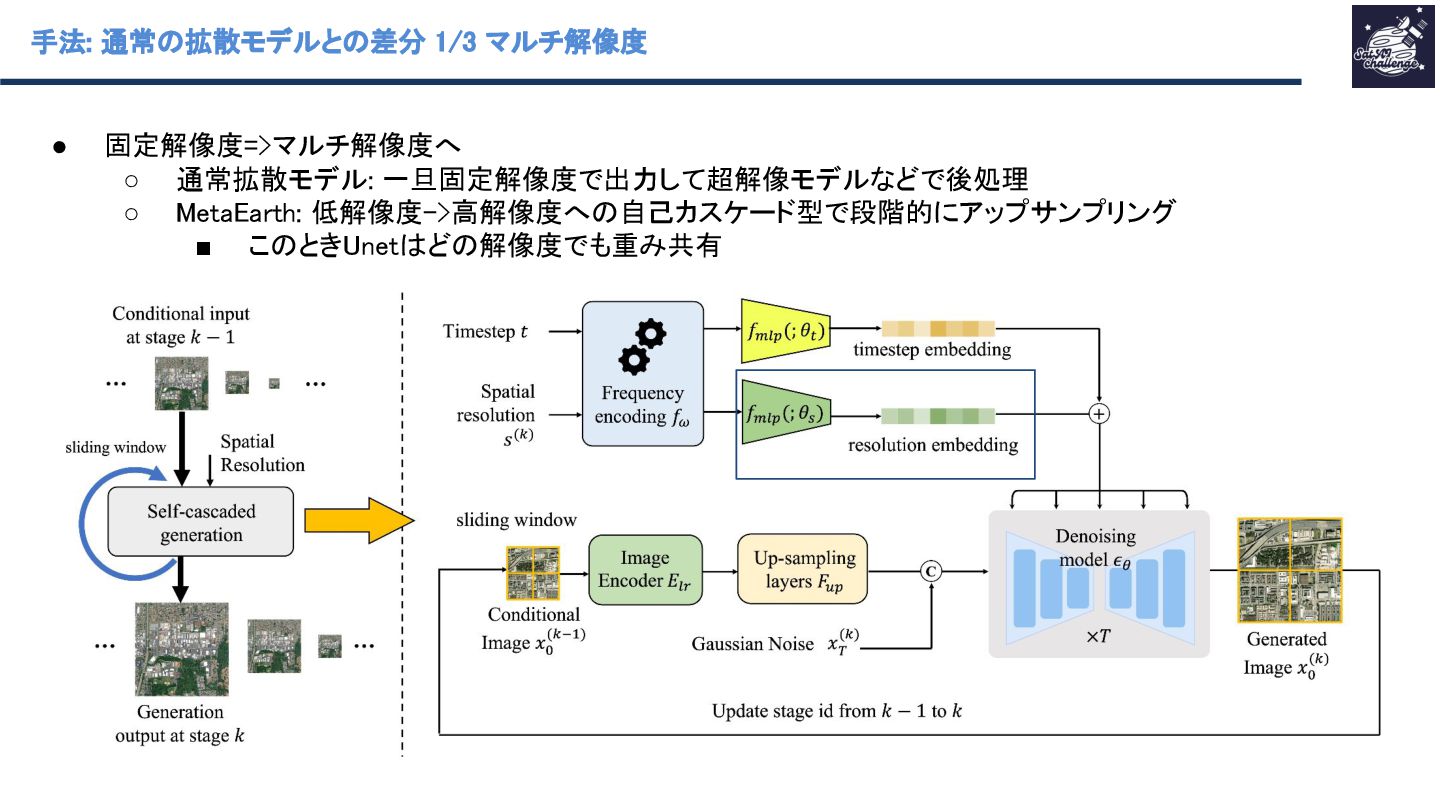
紹介する論文は 「MetaEarth: A Generative Foundation Model for Global-Scale Remote Sensing Image Generation」 です。本研究では、拡散モデルで画像生成した衛星画像を水増しとして使って下流タスクの性能向上を試みた。この拡散モデルを衛星画像生成エンジンとして、世界モデルと定義している。なお、拡散モデルは、既存の一般画像向けの手法から、「マルチ解像度対応のためのカスケード化」「タイル間の整合性を取るためのガウスノイズ付与の工夫」を行った。画像生成結果は高品質を示し、さらに衛星画像の分類タスクにおいて、データを水増しをした分類モデルの方が高い精度を示し、提案手法の効果を示した。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
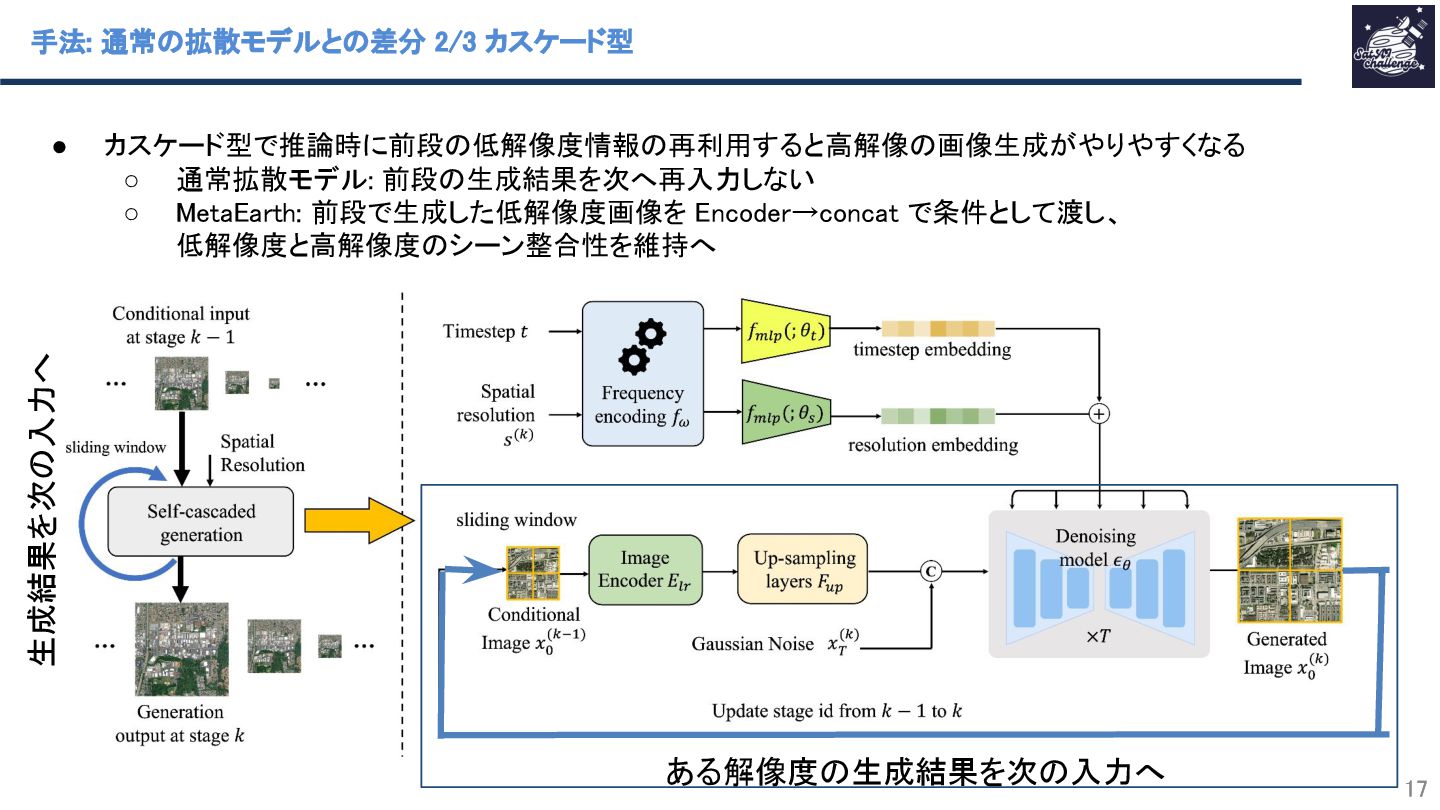{kind=link}
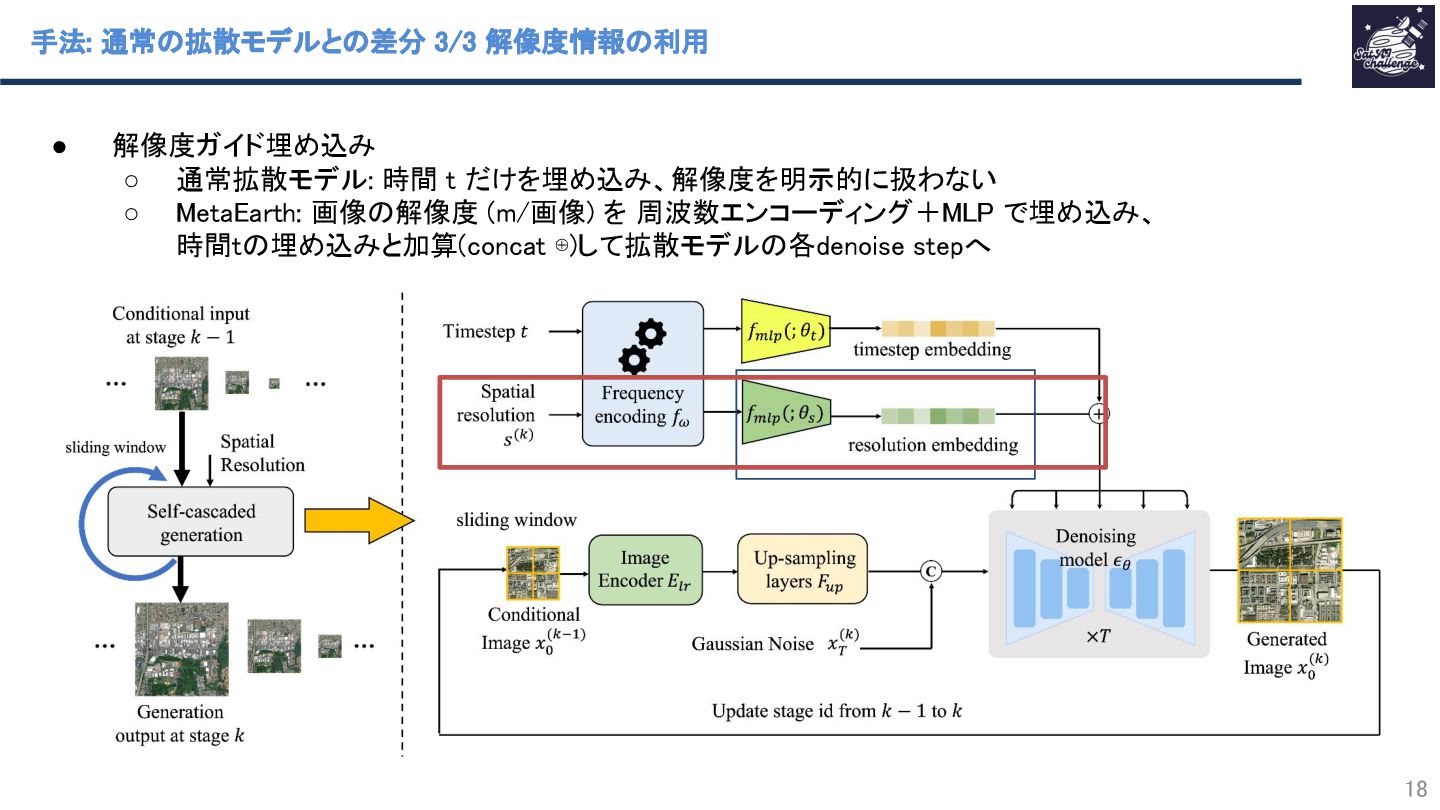{kind=link}
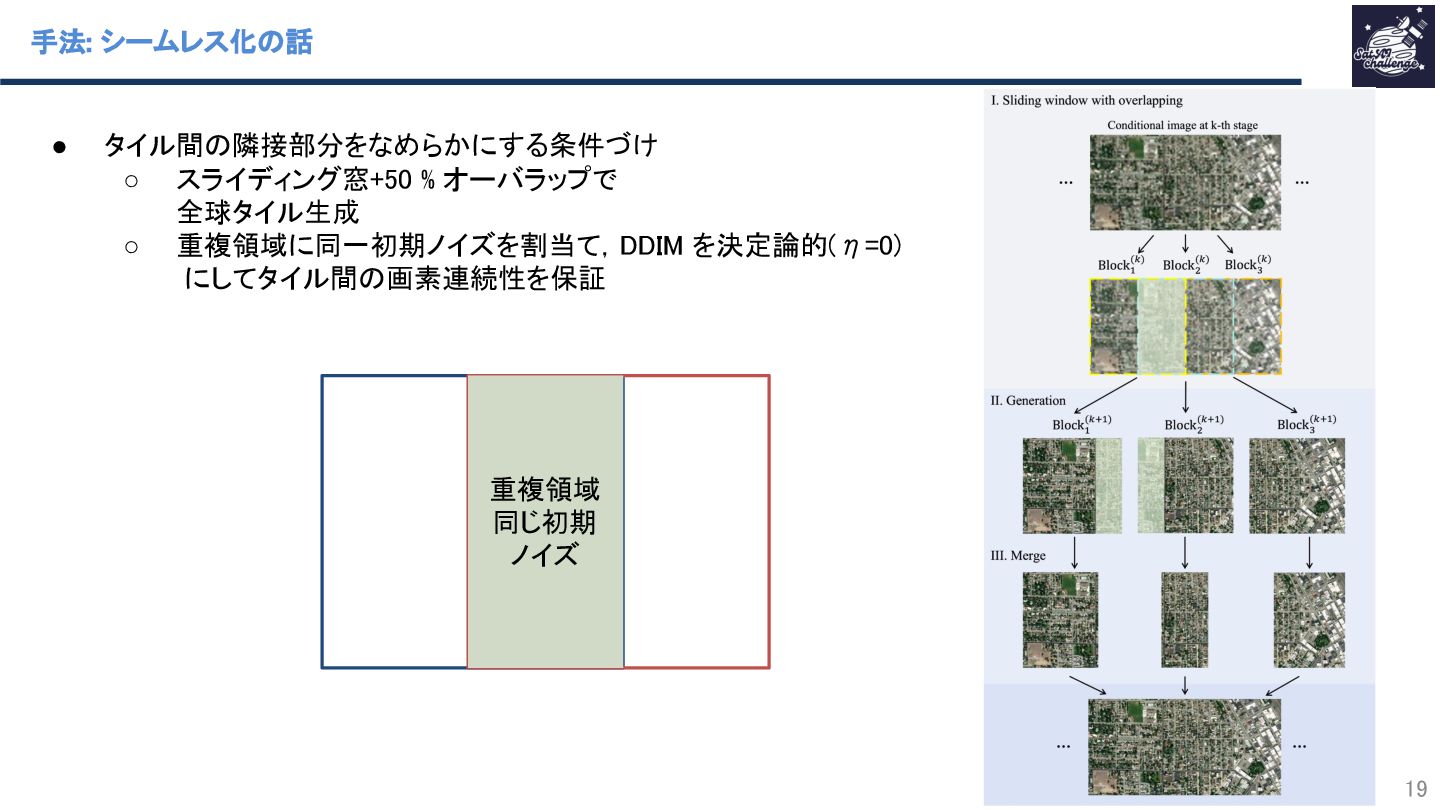{kind=link}
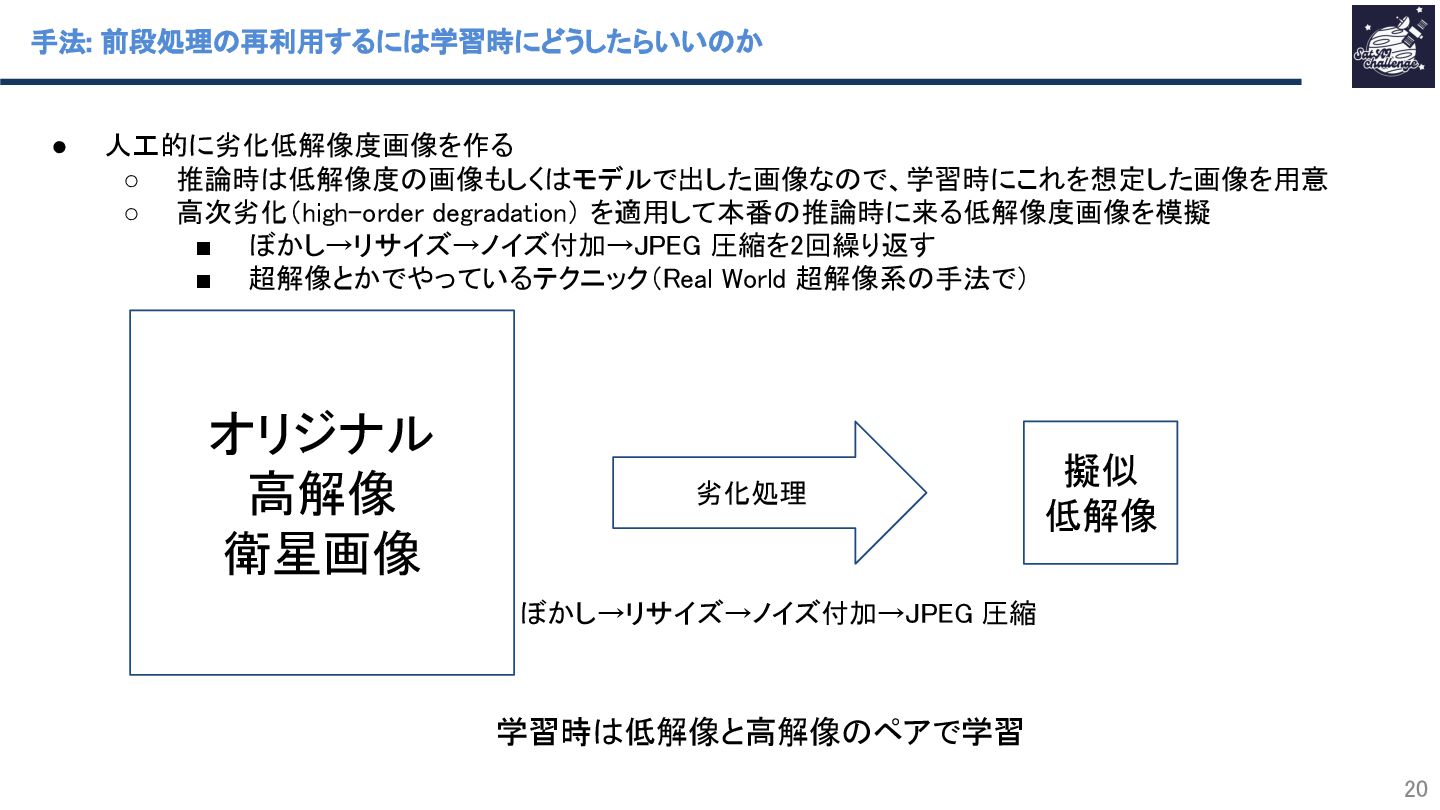{kind=link}
{kind=link}
{kind=link}
{kind=link}
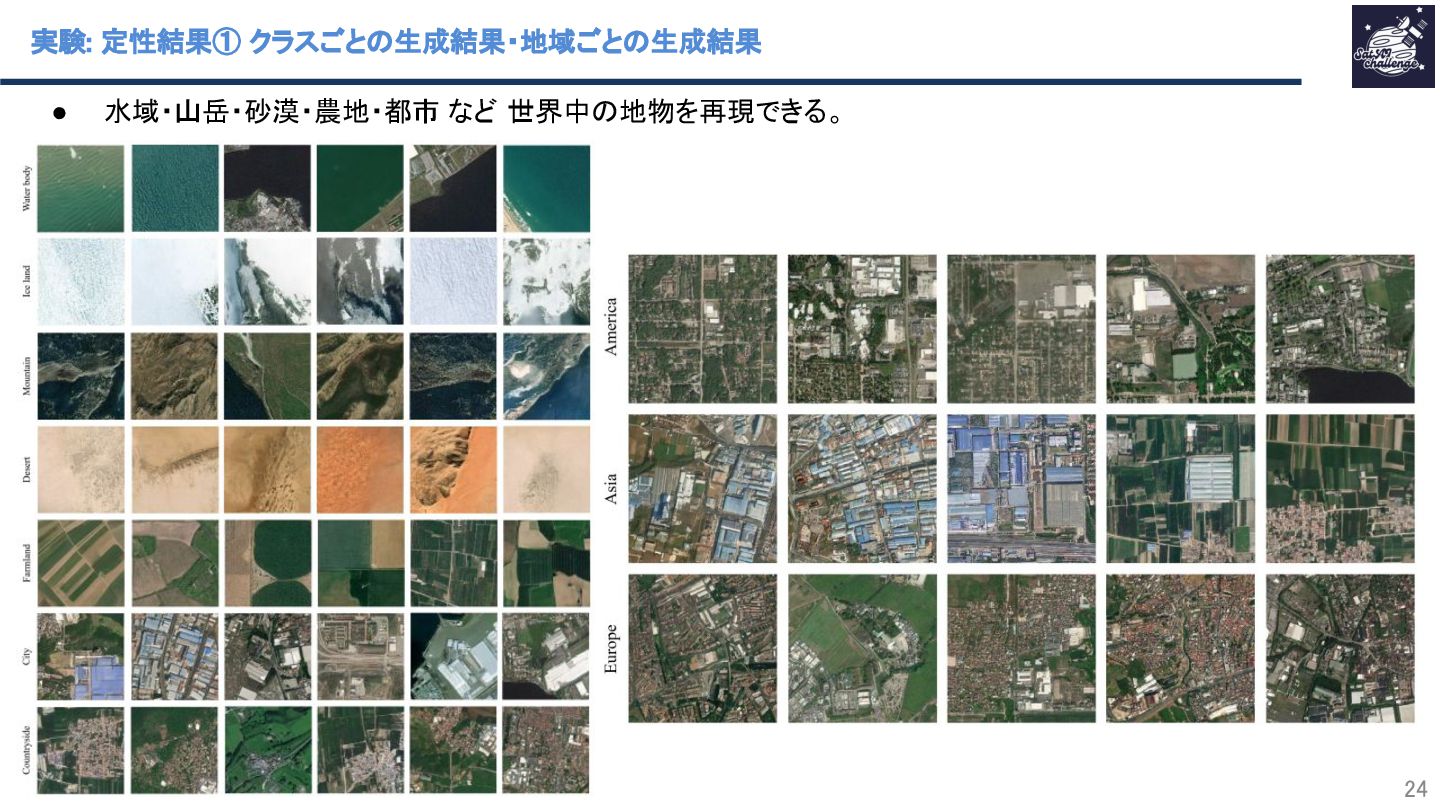{kind=link}
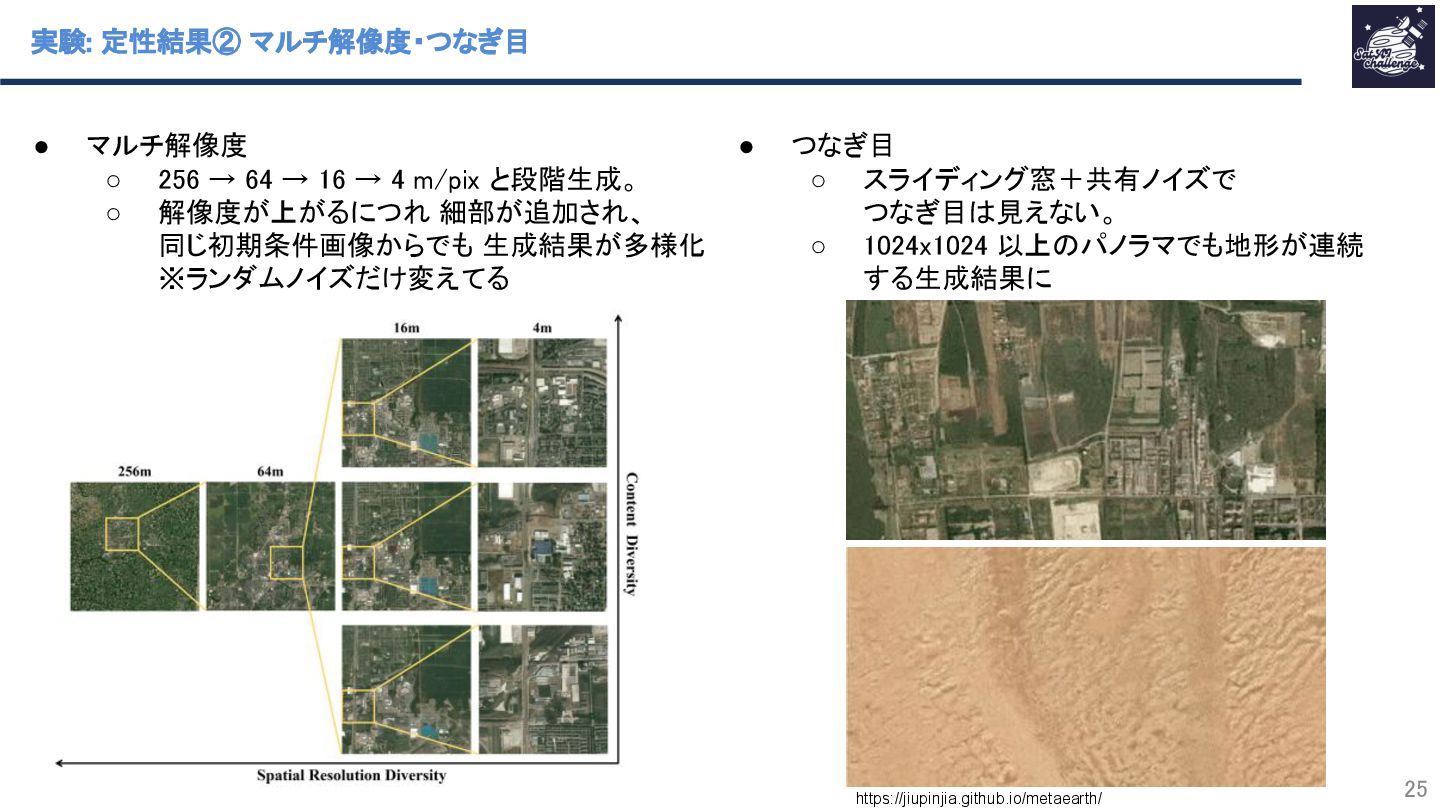{kind=link}
{kind=link}
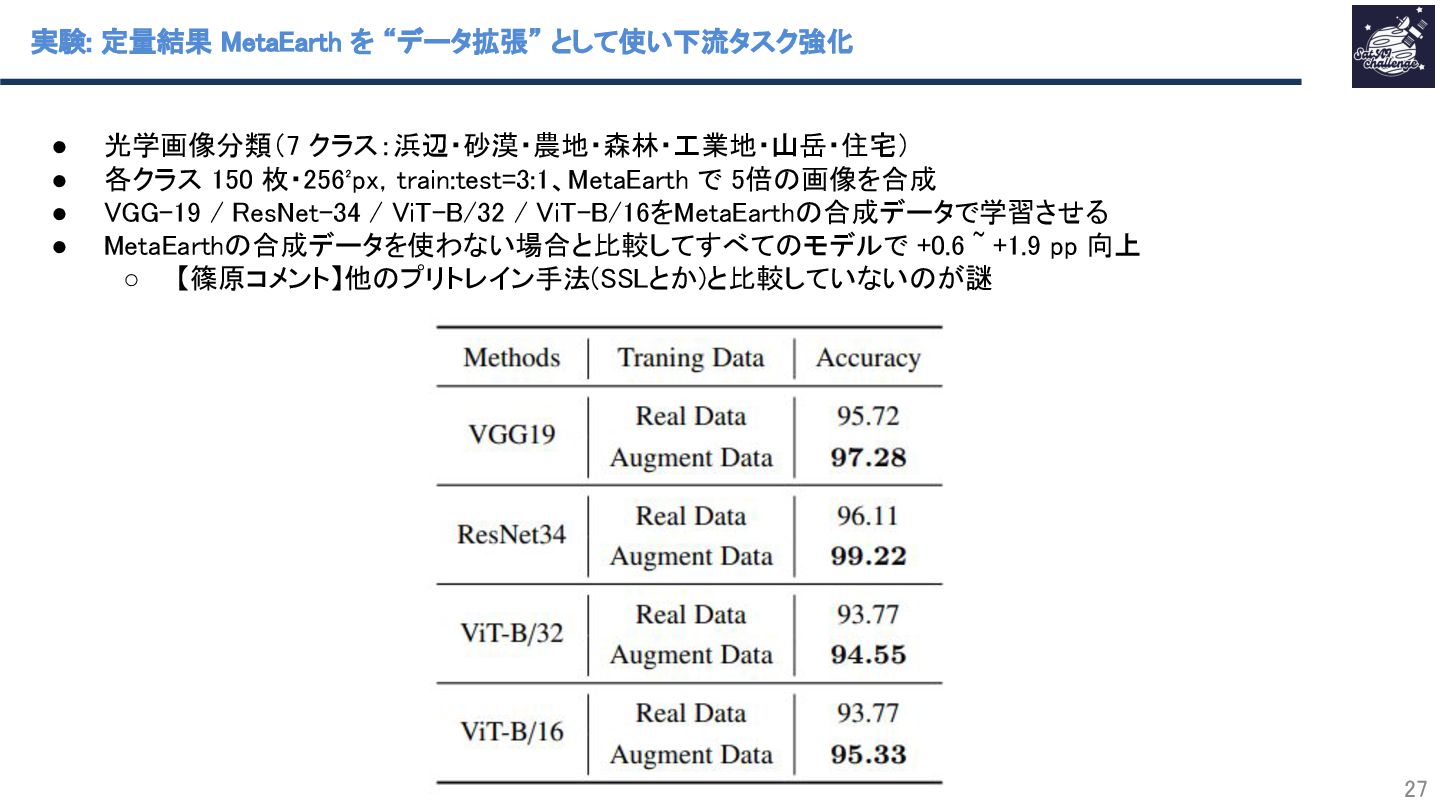{kind=link}
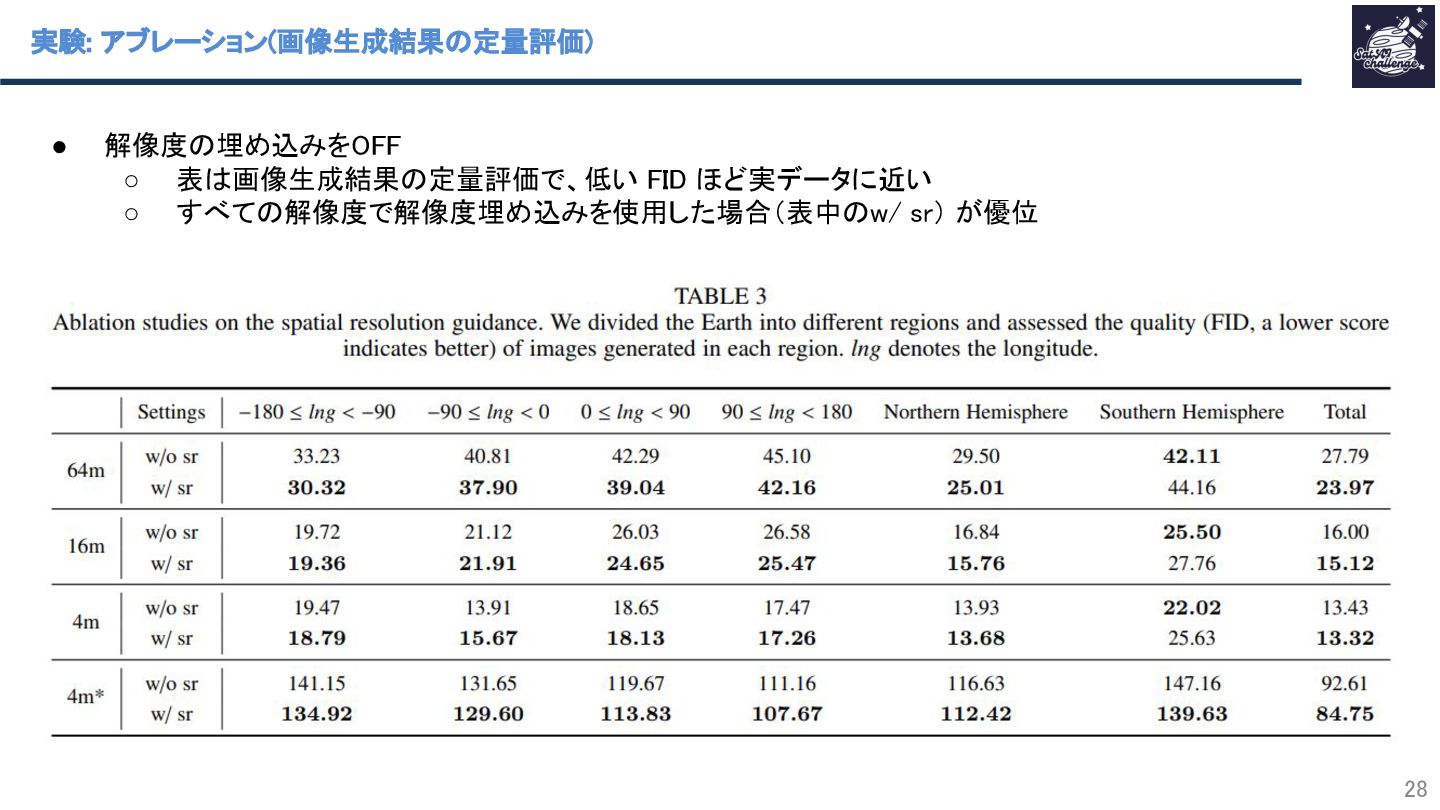{kind=link}
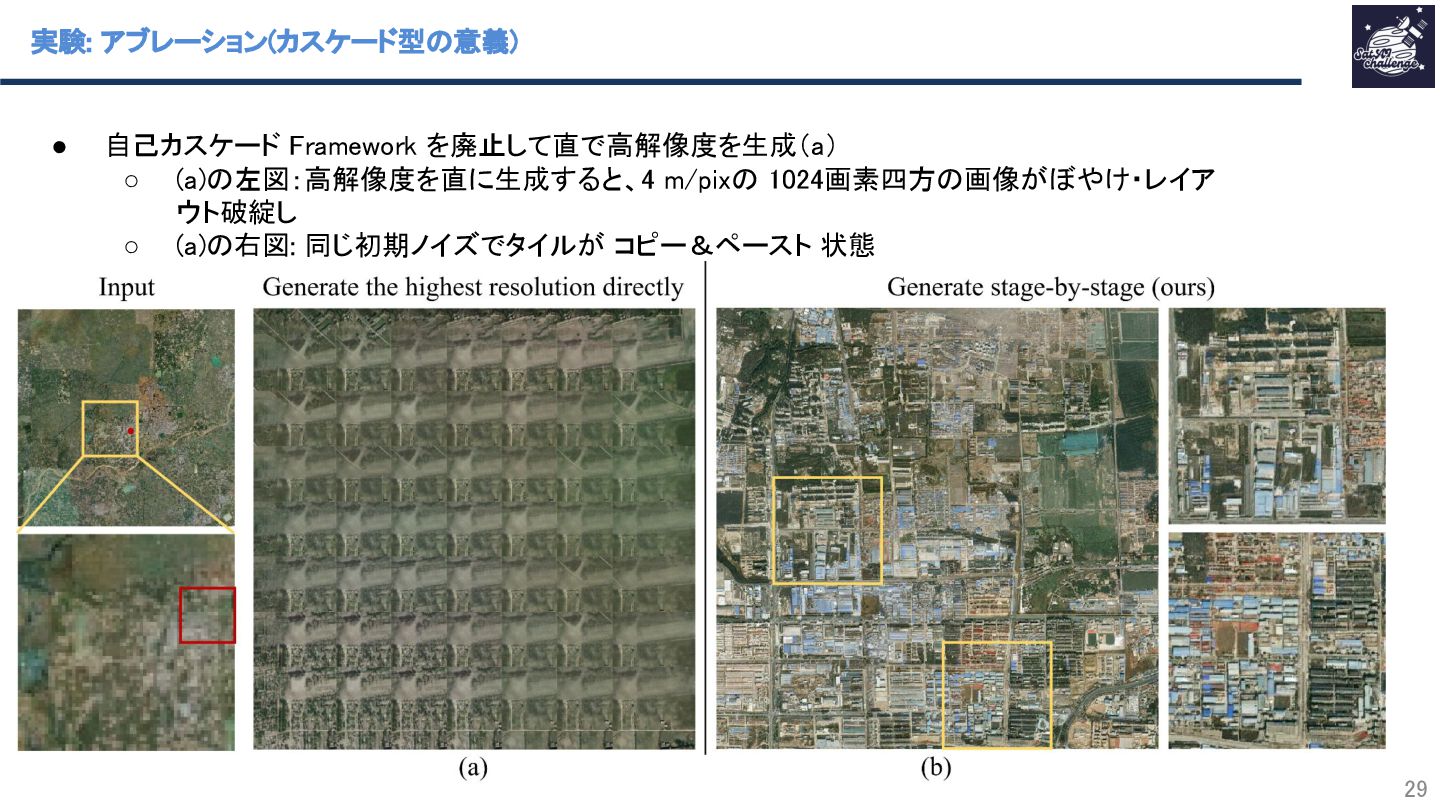{kind=link}
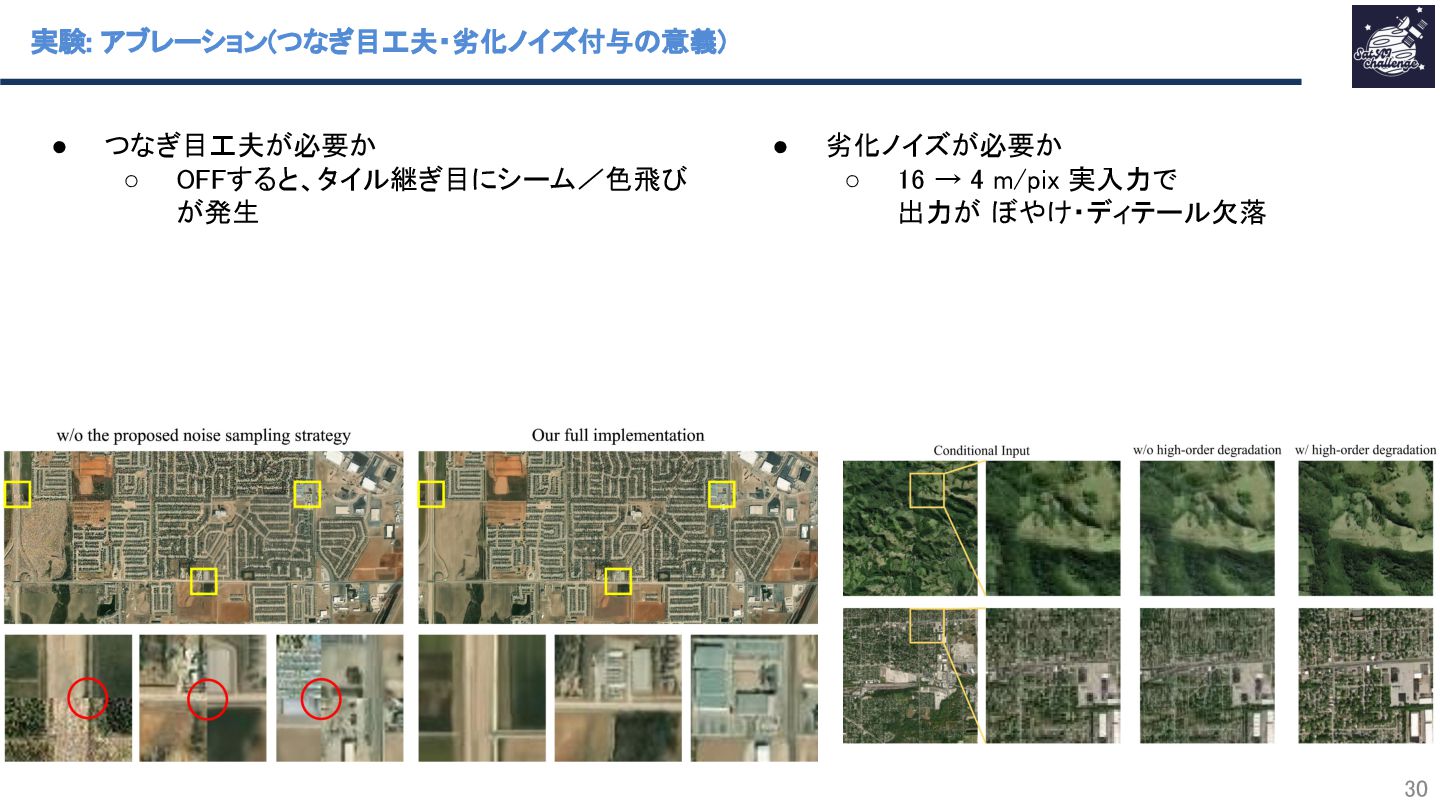{kind=link}
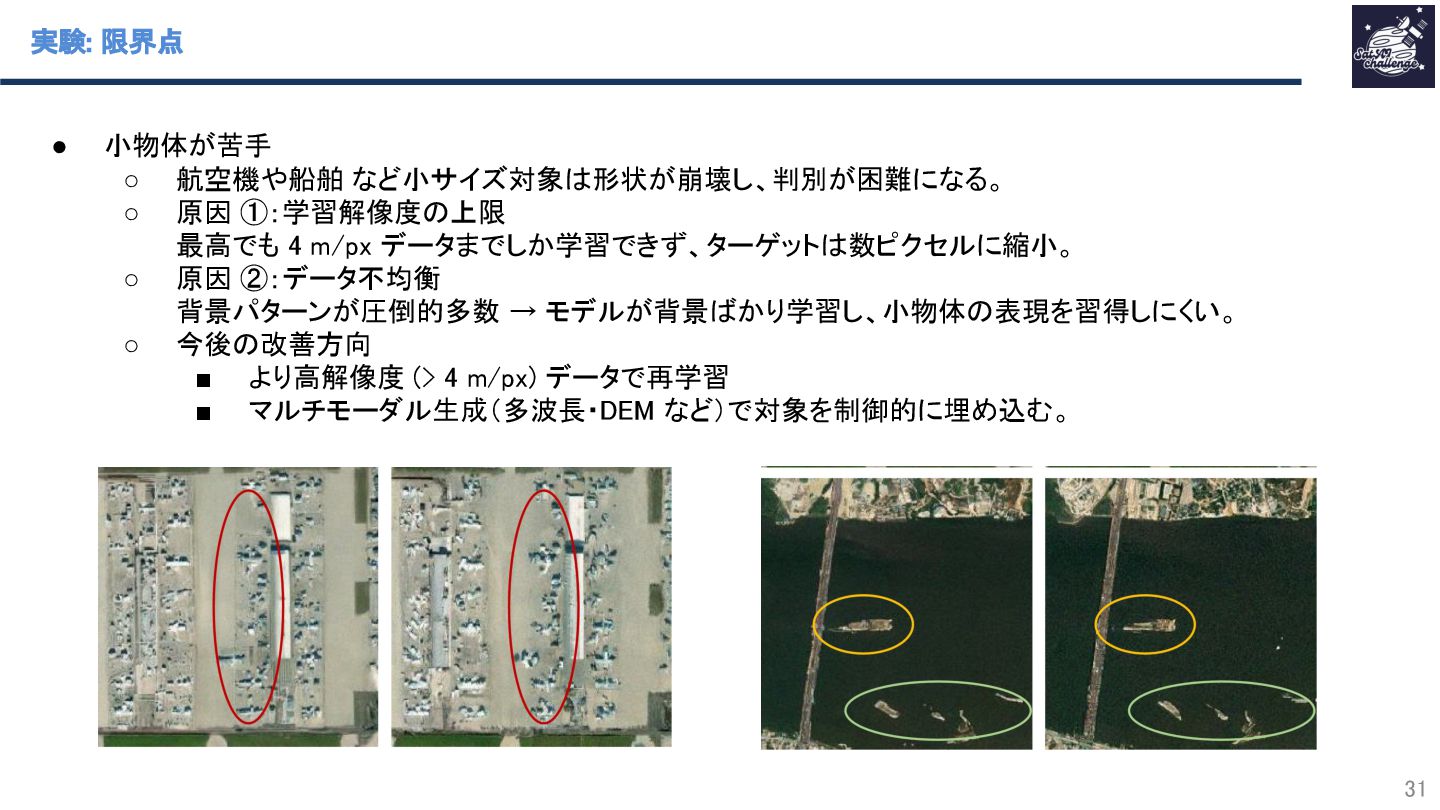{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}