Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
開発体験を左右するライブラリの API 設計 - GraphQL スキーマ構築ライブラリから考...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
izumin5210
May 22, 2026
Programming
1.9k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
開発体験を左右するライブラリの API 設計 - GraphQL スキーマ構築ライブラリから考える #tskaigi
izumin5210
May 22, 2026
More Decks by izumin5210
See All by izumin5210
izumin5210のプロポーザルのネタ探し #tskaigi_msup
izumin5210
2
950
AI Agent の開発と運用を支える Durable Execution #AgentsInProd
izumin5210
8
2.9k
AI Agent Tool のためのバックエンドアーキテクチャを考える #encraft
izumin5210
6
2.3k
Building AI Agents with TypeScript #TSKaigiHokuriku
izumin5210
6
1.8k
Web エンジニアが JavaScript で AI Agent を作る / JSConf JP 2025 sponsor session
izumin5210
4
3.5k
AI Coding Meetup #3 - 導入セッション / ai-coding-meetup-3
izumin5210
0
3.7k
Web フロントエンドエンジニアに開かれる AI Agent プロダクト開発 - Vercel AI SDK を観察して AI Agent と仲良くなろう! #FEC余熱NIGHT
izumin5210
3
1.3k
TypeScript を活かしてデザインシステム MCP を作る / #tskaigi_after_night
izumin5210
5
950
複雑なフォームを継続的に開発していくための技術選定・設計・実装 #tskaigi / #tskaigi2025
izumin5210
15
10k
Other Decks in Programming
See All in Programming
yield再入門 #phpcon
o0h
PRO
0
700
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
840
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
2
270
AI時代、エンジニアはどう育つのか -未経験エンジニアの成長を間近で見て考えたこと-
thasu0123
0
140
関数型プログラミングのメリットって何だろう?
wanko_it
0
190
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
160
jsmini JavaScript Engine を作ってみた話
yosuke_furukawa
PRO
0
160
はてなアカウント基盤 State of the Union
cockscomb
1
1.3k
型も通る、synthも通る、それでも危ない 〜AIのCDKの権限とコストを機械で検証する〜 / It Passes Type Checks, It Passes Synth Checks, but It’s Still Risky — Automatically Verifying Permissions and Costs in AI’s CDK —
seike460
PRO
1
410
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
190
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
170
共通化で考えるべきは、実装より公開する型だった
codeegg
0
270
Featured
See All Featured
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Mobile First: as difficult as doing things right
swwweet
225
10k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Building Applications with DynamoDB
mza
96
7.1k
KATA
mclloyd
PRO
35
15k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Amusing Abliteration
ianozsvald
1
240
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
230
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Transcript
TSKaigi 2026 / 2026-05-22 @izumin5210 GraphQL スキーマ構築ライブラリから考える 開発体験を左右するライブラリの API 設計
1
2 @izumin5210 LayerX バクラク事業部 (2022-09-) Platform Engineering 部 Enabling チーム
Staff Software Engineer Backend(Go, TypeScript), Web Frontend ISUCON14 4位 いま最も気になるディレクトリ microsoft/typescript-go _packages/native-preview/src/api
3 用語の定義 本発表で「API」は 2 つの意味で使い分けます。 通信 API: クライアント-サーバ間の通信インタフェース 例: GraphQL
/ tRPC / Connect / oRPC / hono rpc / TypeSpec で構築され るもの ライブラリ API: 通信 API を実装するためにライブラリが開発者に提供する API 例: graphql-codegen / Pothos / Nexus / TypeGraphQL などが公開する DSL / クラス / 関数
4 今日話すこと GraphQL に限らず、様々なライブラリの API を眺める ライブラリの API により変わる開発者の書き味・思考の単位・開発の進め方を比較・ 考察する
既存ライブラリにない特性を持つ新たなライブラリ API を考えて作ってみる おまけ: Agentic Coding 時代にライブラリ・フレームワークを作る
GraphQL と他の通信 API ライブラリを横並びで見てみる ライブラリ API を眺めよう
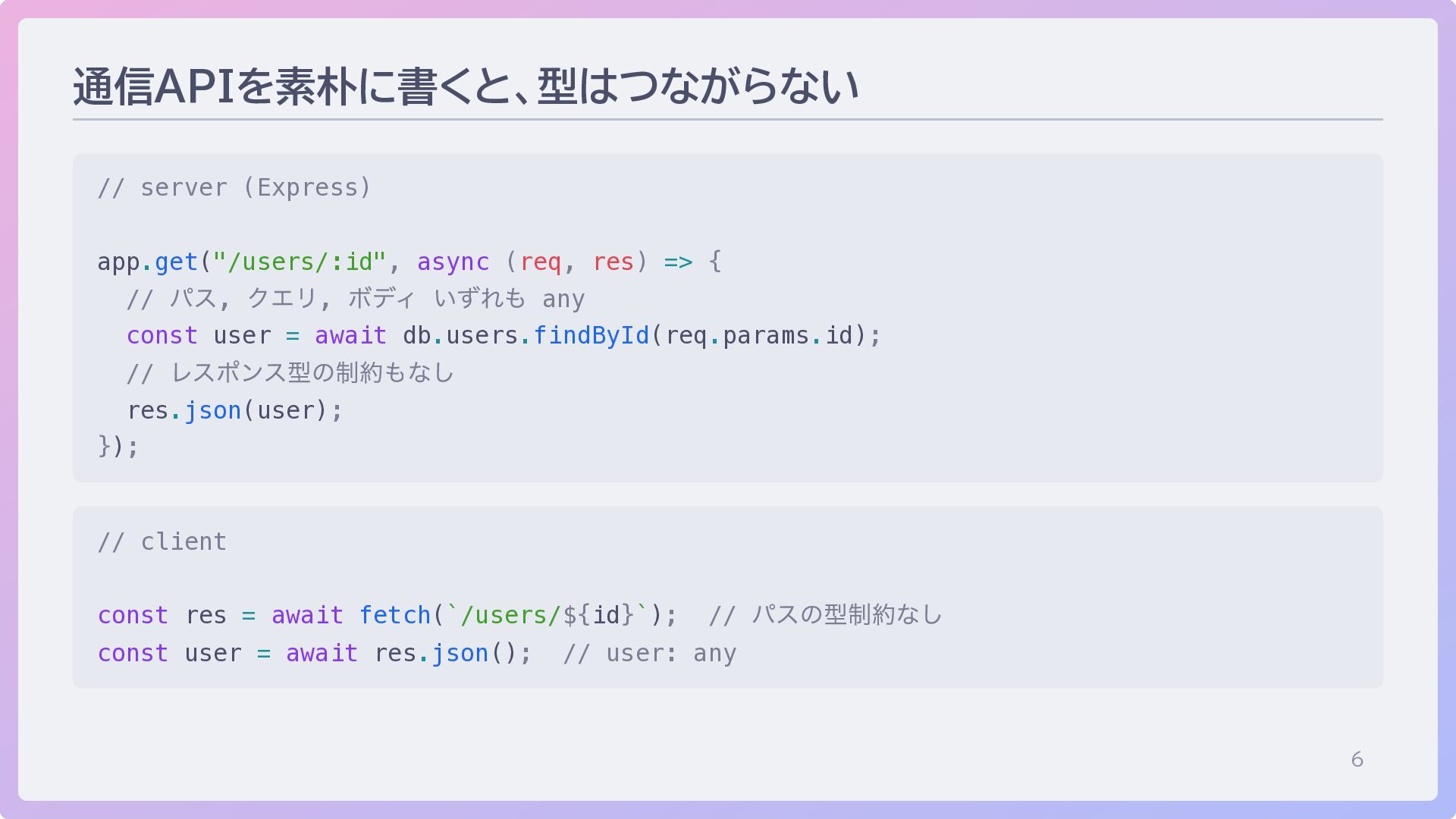
6 通信APIを素朴に書くと、型はつながらない // server (Express) app.get("/users/:id", async (req, res) =>
{ // パス, クエリ, ボディ いずれも any const user = await db.users.findById(req.params.id); // レスポンス型の制約もなし res.json(user); }); // client const res = await fetch(`/users/${id}`); // パスの型制約なし const user = await res.json(); // user: any
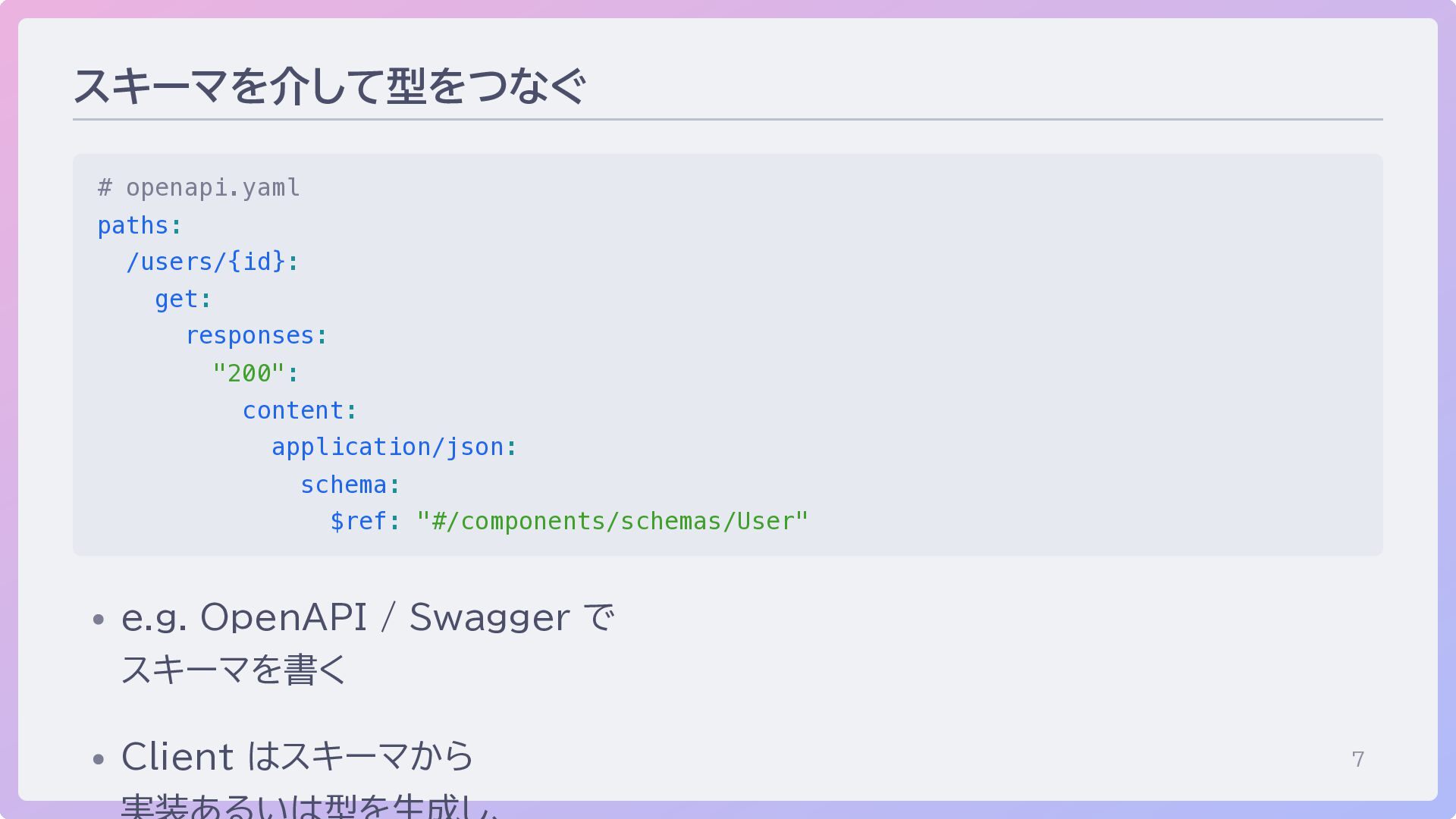
7 スキーマを介して型をつなぐ # openapi.yaml paths: /users/{id}: get: responses: "200": content:
application/json: schema: $ref: "#/components/schemas/User" e.g. OpenAPI / Swagger で スキーマを書く Client はスキーマから
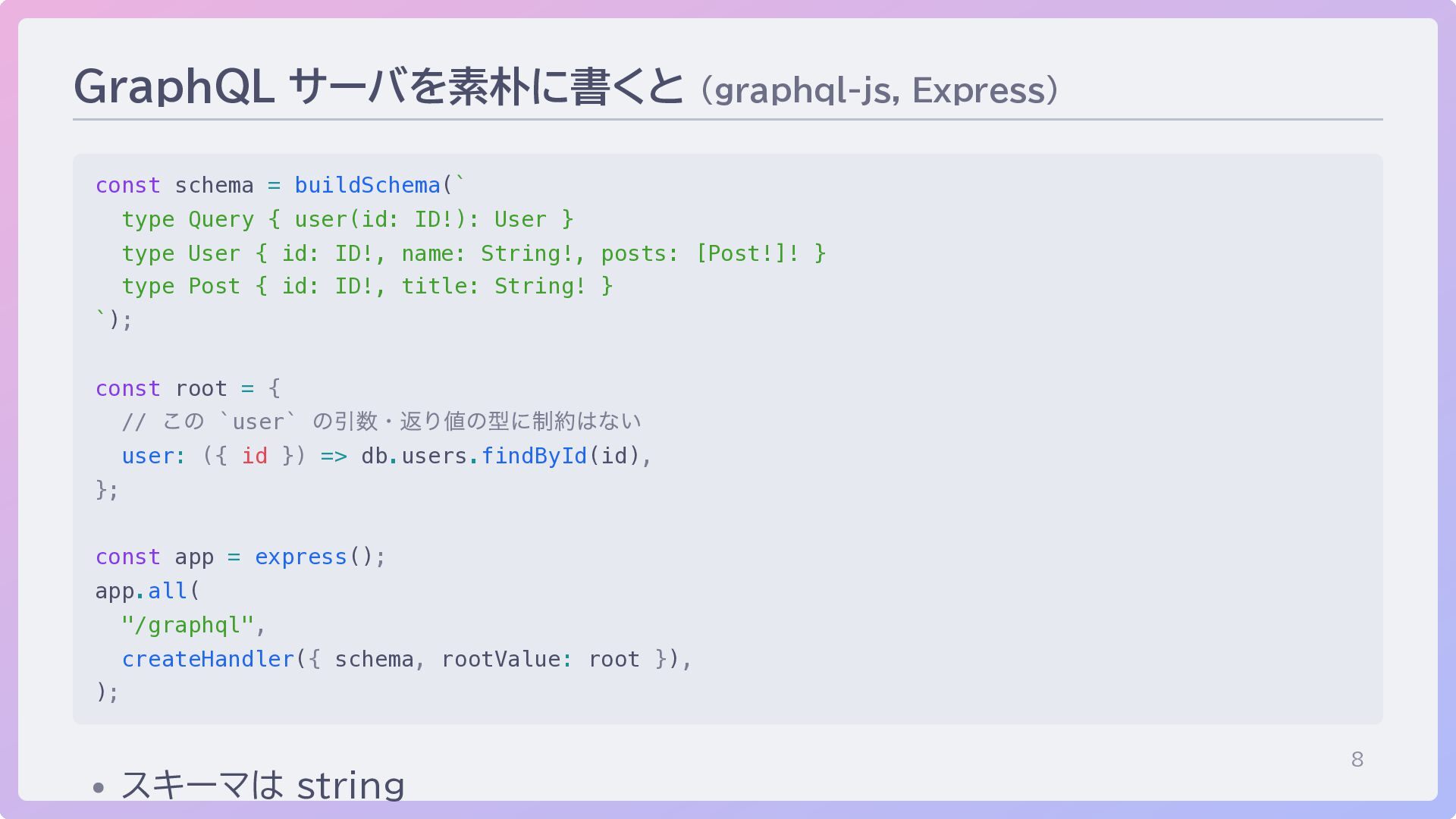
8 GraphQL サーバを素朴に書くと (graphql-js, Express) const schema = buildSchema(` type
Query { user(id: ID!): User } type User { id: ID!, name: String!, posts: [Post!]! } type Post { id: ID!, title: String! } `); const root = { // この `user` の引数・返り値の型に制約はない user: ({ id }) => db.users.findById(id), }; const app = express(); app.all( "/graphql", createHandler({ schema, rootValue: root }), ); スキーマは string
9 「スキーマとサーバ実装の整合性」は普遍的な課題 OpenAPI / GraphQL / tRPC / Connect RPC
/ TypeSpec など、 通信APIを作るスキーマやフレームワークはいくつもある クライアントはコード生成するか、サーバのコード(型)を参照できるかがほとんど サーバについて、スキーマと実装の整合性を保つ方法はライブラリの設計次第 このライブラリ API の設計次第で、整合性の保ち方も開発者の思考も変わる
10 通信APIのサーバ側を作るライブラリのAPIのパターンを いくつか見ていきましょう
11 パターン A: schema-first (GraphQL) // schema.graphql は別ファイル / 型は
codegen で生成 import type { Resolvers } from "./generated/graphql"; export const resolvers: Resolvers = { Query: { // args: user query の引数から生成された TypeScript 型 user: (_parent, args, ctx) => ctx.db.users.findById(args.id), }, User: { // parent: User type から生成された TypeScript 型 posts: (parent, _args, ctx) => ctx.postLoader.loadByUserId(parent.id), }, }; graphql-codegen + typescript-resolvers
12 パターン A: schema-first (他通信 API) message User { string
id = 1; string name = 2; repeated Post posts = 3; } message Post { /* ... */ } message GetUserRequest { string id = 1; } service UserService { rpc GetUser(GetUserRequest) returns (User); } Connect RPC / Protocol Buffers
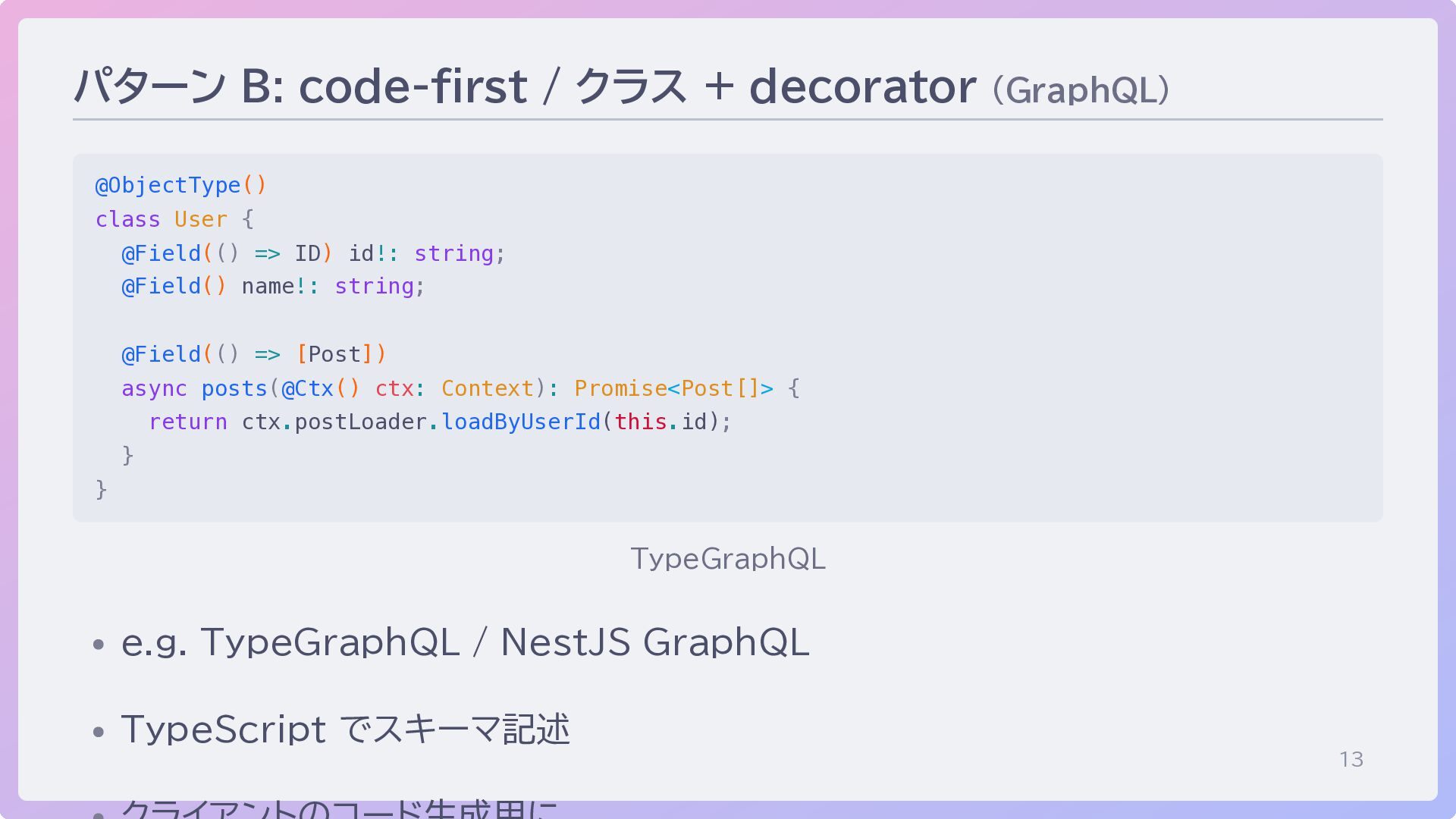
13 パターン B: code-first / クラス + decorator (GraphQL) @ObjectType()
class User { @Field(() => ID) id!: string; @Field() name!: string; @Field(() => [Post]) async posts(@Ctx() ctx: Context): Promise<Post[]> { return ctx.postLoader.loadByUserId(this.id); } } TypeGraphQL e.g. TypeGraphQL / NestJS GraphQL TypeScript でスキーマ記述
14 パターン B: code-first / クラス + decorator(他通信 API) class
User { @ApiProperty() id!: string; @ApiProperty() name!: string; @ApiProperty({ type: [Post] }) posts!: Post[]; } @Controller("users") class UsersController { @Get(":id") @ApiResponse({ status: 200, type: User }) async getUser(@Param("id") id: string): Promise<User> { return this.db.users.findById(id); } } NestJS REST e.g. NestJS REST, tsoa
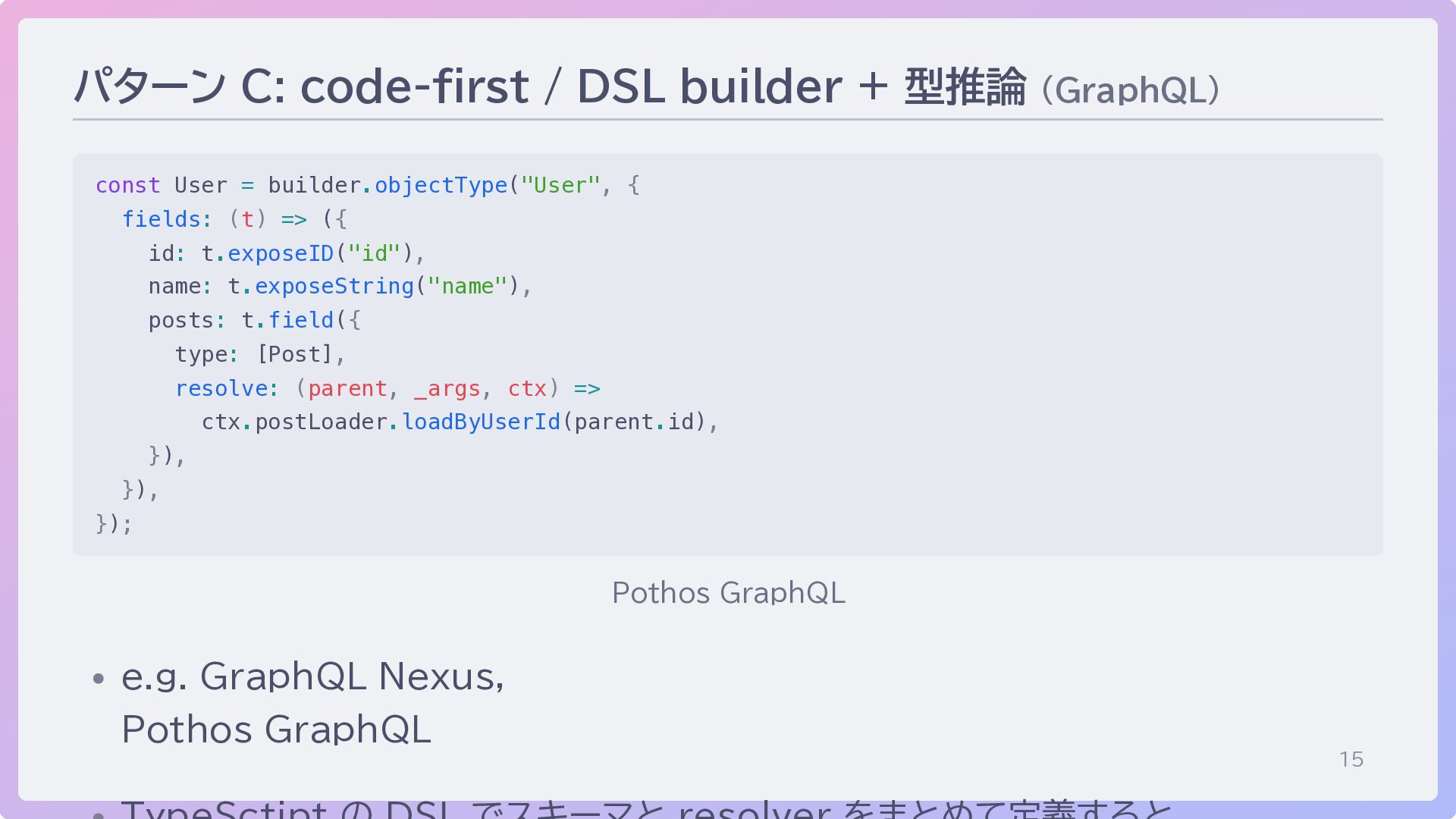
15 パターン C: code-first / DSL builder + 型推論 (GraphQL)
const User = builder.objectType("User", { fields: (t) => ({ id: t.exposeID("id"), name: t.exposeString("name"), posts: t.field({ type: [Post], resolve: (parent, _args, ctx) => ctx.postLoader.loadByUserId(parent.id), }), }), }); Pothos GraphQL e.g. GraphQL Nexus, Pothos GraphQL
16 パターン C: code-first / DSL builder + 型推論 (他通信
API) // oRPC: builder で書き、OpenAPI スキーマも自動生成 const getUser = os .route({ method: "GET", path: "/users/{id}" }) .input(z.object({ id: z.string() })) .output(UserSchema) .handler(async ({ input }) => db.users.findById(input.id) ); oRPC e.g. oRPC, Hono OpenAPI, ts-rest
17 パターン C': code-first / サーバの型をクライアントで使う // tRPC: TS の型そのものを「スキーマ」として使う
const usersRouter = t.router({ getUser: t.procedure .input(z.object({ id: z.string() })) .query(({ input }) => { return db.users.findById(input.id); }), }); // クライアントは AppRouter 型を import するだけで型がつく type AppRouter = typeof usersRouter; tRPC e.g. tRPC, Hono RPC クライアントも TS 前提で、
18 ライブラリ API が左右するもの いずれも「通信APIのスキーマを保証するようにサーバを実装する」という点で同じ 問題を解いている しかし、ライブラリAPIによって書き味も思考の単位もまったく違う スキーマの主体(server - client
共有 / server 主体) スキーマと実装の思考や着手の単位・順序 型のつなぎ方 (codegen / DSL 型推論) ... もちろん、そもそものスキーマの特性によっても違いはある (※ 今回は扱わない) 思考の単位 (field / object / endpoint / procedure) ...
19 ライブラリ API が左右するもの いずれも「通信APIのスキーマを保証するようにサーバを実装する」という点で同じ 問題を解いている しかし、ライブラリAPIによって書き味も思考の単位もまったく違う 設計の考え方・開発の進め方・開発の体験を大きく左右する
ライブラリAPIパターン比較
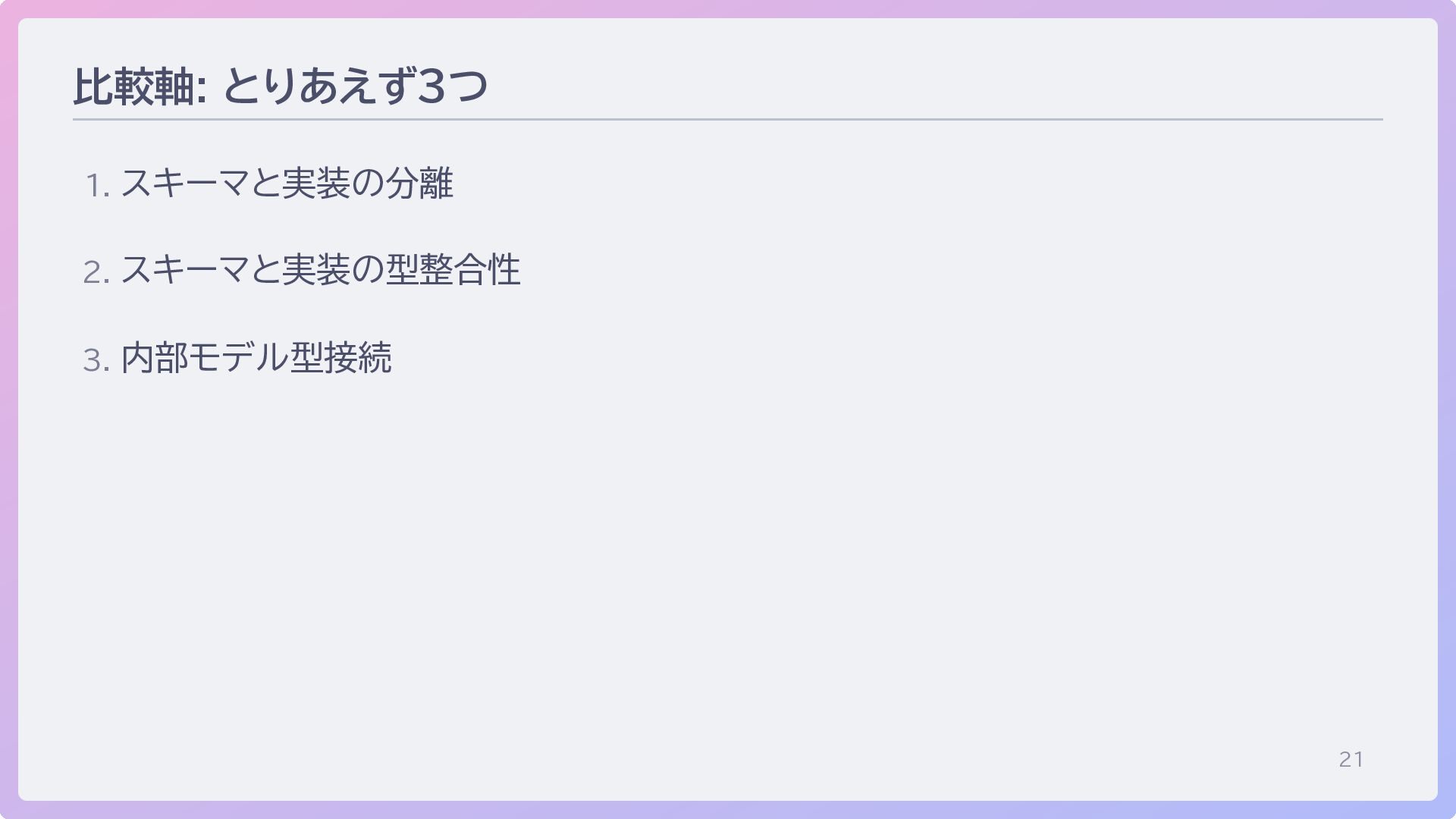
21 比較軸: とりあえず3つ 1. スキーマと実装の分離 2. スキーマと実装の型整合性 3. 内部モデル型接続
22 比較軸1: スキーマと実装の分離
23 スキーマと実装の分離 通信 API スキーマと実装を、コード上で分離するか・併記するか。 記述時の影響: どこに何が書かれているかの集中度 継続メンテ時の影響: 部分把握時のコンテキスト負荷 人間にも
AI にもコンテキスト負荷に直結
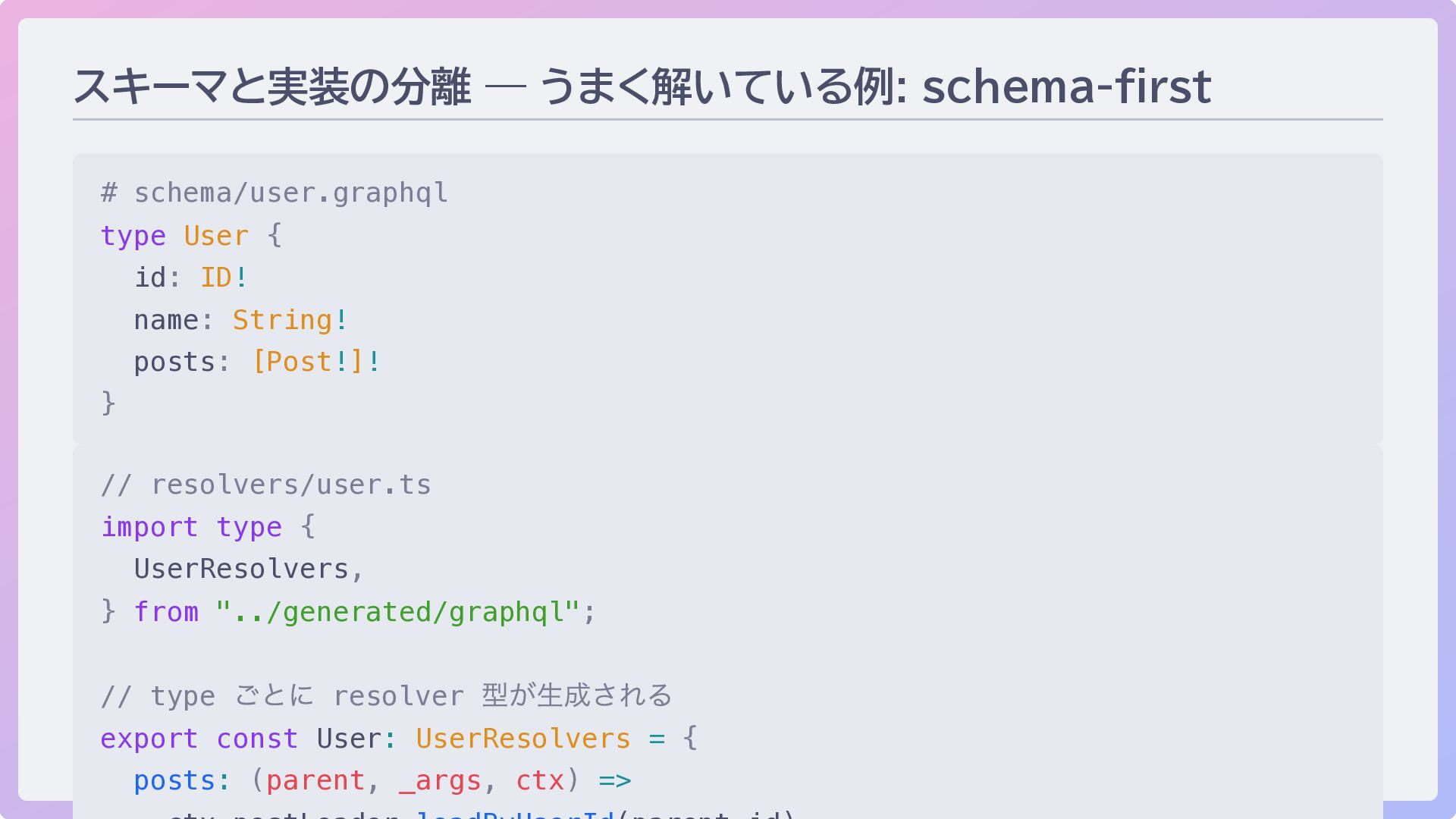
24 スキーマと実装の分離 — 各パターンの解き方 schema-first: SDL とコードを完全分離 (別ファイル) code-first: コード内でスキーマ定義と実装を併記することが多い
クラス + decorator: クラス内で併記 DSL builder: builder 内で併記
25 スキーマと実装の分離 — うまく解いている例: schema-first # schema/user.graphql type User {
id: ID! name: String! posts: [Post!]! } // resolvers/user.ts import type { UserResolvers, } from "../generated/graphql"; // type ごとに resolver 型が生成される export const User: UserResolvers = { posts: (parent, _args, ctx) =>
26 スキーマと実装の分離 — トレードオフ 「スキーマと実装を分離して考える」ことをどれだけ重要視するか 「バックエンド・フロントエンドに関わらず全エンジニアがスキーマに責任を持つ」場合は 分離のモチベーションは強い 分離モチベーションが強い場合は Schema-first が便利
バックエンドの設計や実装に引きづられない バックエンド実装言語を知らなくても書きやすい Code-first の場合、スキーマ自体の見通しはライブラリAPIの書き味に左右される 後述するが、書きやすさと型安全性のバランスを取るのは意外と難しい
27 比較軸2: スキーマと実装の型整合性
28 スキーマと実装の型整合性 スキーマと実装のあいだの型整合性を、どうやって担保するか。 候補: コード生成 / DSL の型システム / 外付け生成
+ Linter 「徹底させる」強制力に差がある
29 スキーマと実装の型整合性 — 各パターンの解き方 schema-first codegen (SDL → TS 型
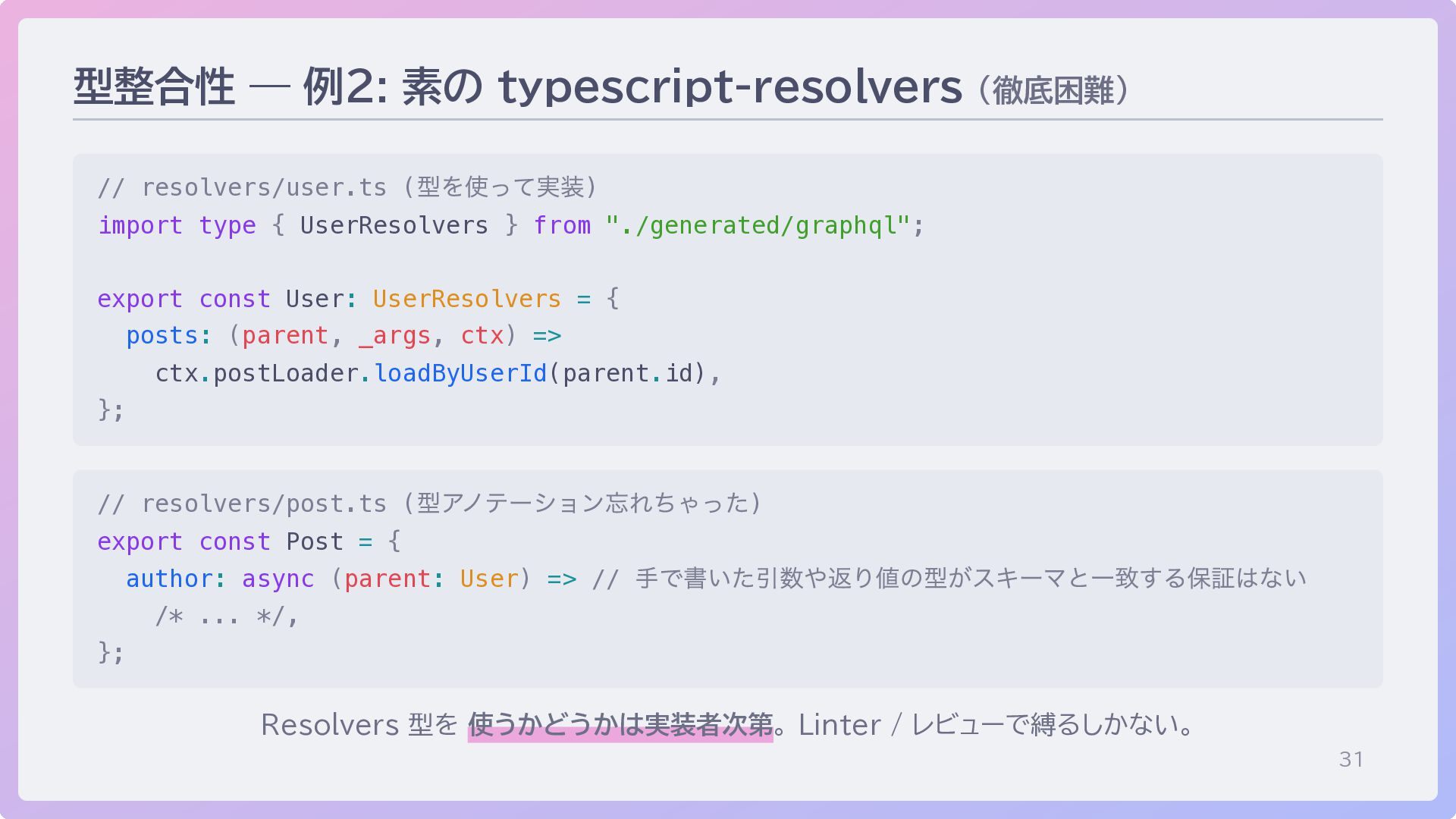
→ 実装が型に従う) code-first / クラス + decorator decorator metadata から型生成 (外付け、Linter で補強) code-first / DSL builder DSL の型推論だけで完結 もしくは codegen との組み合わせ
30 型整合性 — 例1: decorator ベース(乖離リスク) @ObjectType() class User {
@Field(() => String) // `nullable: true` がないので schema 上は String! middleName: string | null; // でも TS 上は nullable @Field(() => String) // schema 上 は `String!` rating: number; // TypeScript 上は number } decorator の型情報と TS の型情報が独立 ずれてもコンパイル時に検出できないケースがある (Linter / reflect-metadata で部分的に補強できるが完全ではない)
31 型整合性 — 例2: 素の typescript-resolvers (徹底困難) // resolvers/user.ts (
型を使って実装) import type { UserResolvers } from "./generated/graphql"; export const User: UserResolvers = { posts: (parent, _args, ctx) => ctx.postLoader.loadByUserId(parent.id), }; // resolvers/post.ts ( 型アノテーション忘れちゃった) export const Post = { author: async (parent: User) => // 手で書いた引数や返り値の型がスキーマと一致する保証はない /* ... */, }; Resolvers 型を 使うかどうかは実装者次第。 Linter / レビューで縛るしかない。
32 型整合性 — 例3: graphql-codegen server preset # codegen.yml schema:
schema/**/*.graphql generates: src/__generated__/resolvers.ts: preset: server-preset // resolvers/user.ts (resolver 型だけでなく、 resolver の実装スケルトンまで出てくる) import type { UserResolvers } from "../__generated__/resolvers"; export const User: UserResolvers = { posts: (parent, _args, ctx) => { /* 開発者は生成された空の関数を実装する */ }, }; server preset は ファイル構成まで scaffold することで、型が自然に利用される・守られる状態を作る。
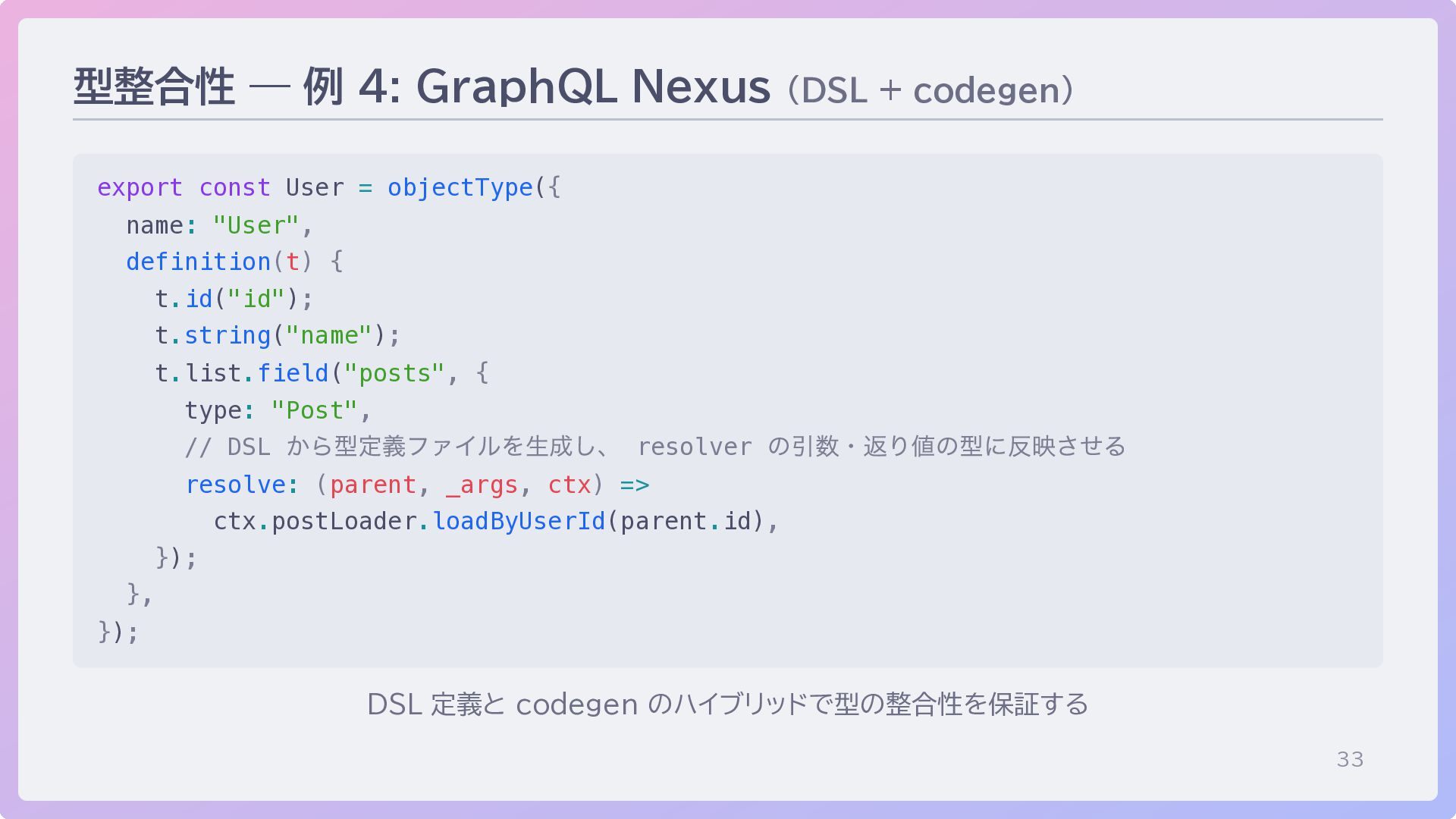
33 型整合性 — 例 4: GraphQL Nexus (DSL + codegen)
export const User = objectType({ name: "User", definition(t) { t.id("id"); t.string("name"); t.list.field("posts", { type: "Post", // DSL から型定義ファイルを生成し、 resolver の引数・返り値の型に反映させる resolve: (parent, _args, ctx) => ctx.postLoader.loadByUserId(parent.id), }); }, }); DSL 定義と codegen のハイブリッドで型の整合性を保証する
34 型整合性 — 例 5: Pothos GraphQL (パワフル型推論) const User
= builder.objectType("User", { fields: (t) => ({ id: t.exposeID("id"), // type: [Post] と宣言 → resolve の返り値型が Post[] にガードされる posts: t.field({ type: [Post], // parent, args, 返り値も objectType や field 定義から型推論される resolve: (parent, _args, ctx) => ctx.postLoader.loadByUserId(parent.id), }), }), }); codegen なし。DSL の型推論が、書いた瞬間に整合性を担保。
35 スキーマと実装の型整合性 — トレードオフ 「サーバ実装がスキーマと整合している」と言い切るためには、 ミスに気づける仕組みは必須 graphql-codegen server preset や
Pothos GraphQL は、これをうまく解く decorator ベースのものなどは追加の仕組みが必要になる graphql-codegen server preset のような scaffolding ベースのものは 「スキーマ定義 → 生成 → 実装 → ...」というループが必要 人間にとってはエディタを離れる手間 AI に対しては生成を漏らさないハーネスの工夫が必要 Pothos GraphQL のような型推論ベースのものは、 まあまあ無茶してるので型エラーが難解になりがち
36 比較軸3: 内部モデル型接続
37 内部モデル型接続 "通信APIを実装する" というのは 「バックエンドモデルをクライアントにどう見せるかを決めて」 「バックエンドモデルをクライアント向けのモデル(API上の型)に変換する作業」 これは裏側が RDB だろうがマイクロサービスであろうが構造としては同じ このインピーダンスミスマッチをどう解消するか
38 内部モデル型接続 — 各パターンの解き方 schema-first / graphql-codegen server preset mappers
config で宣言 DSL builder objectRef<T> (Pothos) / sourceType (Nexus) で DSL 内に宣言
39 内部モデル型接続 — 例1: schema-first (困るパターン) # `User` は `posts`
を持つ type User { id: ID!, name: String!, posts: [Post!]! } const user: QueryResolvers["user"] = async (_p, { id }) => { // DB 上では user と post は別テーブルなので、型が合わない return db.users.findById(id); // 常に posts を JOIN してると、posts 使わないときに無駄 return db.users.findById(id, { include: { posts: true } }); }; バックエンドでは内部に「モデル」を持ってるはずで、その内部モデルと GraphQL の型を合わせるのが難しい
40 内部モデル型接続 — 例 2: server preset と mappers //
schema.mappers.ts // 内部モデル。 例えば Prisma や Drizzle のテーブルから生成する型。 export type UserMapper = DbUser; // { id: string; name: string } export const User: UserResolvers = { // mappers で定義した型に「存在しないフィールド」の resolver が scaffold される // 漏れると型エラーになる posts: (parent, _args, ctx) => { return ctx.postLoader.loadByUserId(parent.id), // DataLoader で N+1 回避 } }; mappers が内部モデルと GraphQL type のマッピングを定義し、 codegen はそれを見て差分を吸収するように resolver 型とスケルトンを生成する
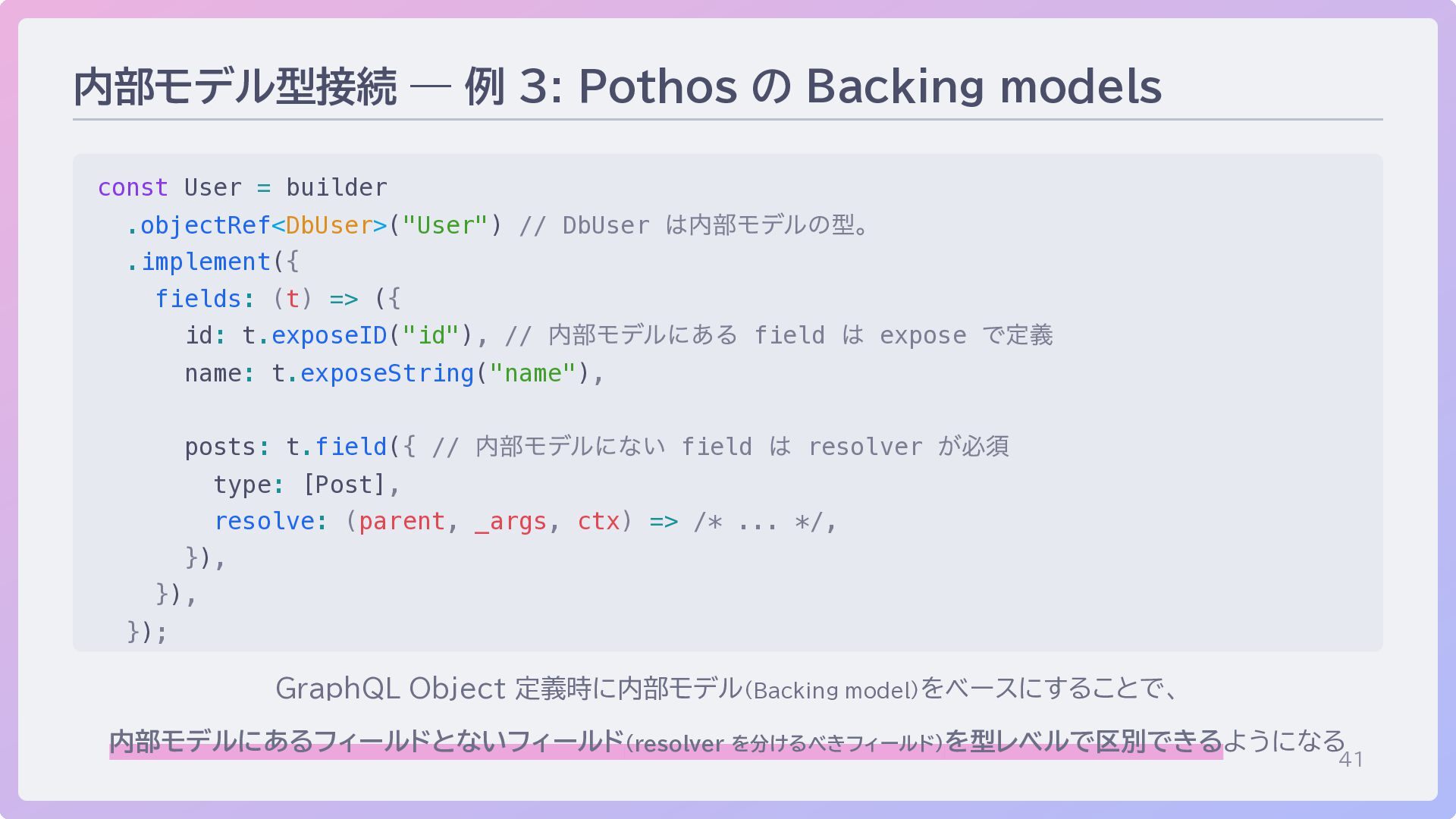
41 内部モデル型接続 — 例 3: Pothos の Backing models const
User = builder .objectRef<DbUser>("User") // DbUser は内部モデルの型。 .implement({ fields: (t) => ({ id: t.exposeID("id"), // 内部モデルにある field は expose で定義 name: t.exposeString("name"), posts: t.field({ // 内部モデルにない field は resolver が必須 type: [Post], resolve: (parent, _args, ctx) => /* ... */, }), }), }); GraphQL Object 定義時に内部モデル(Backing model)をベースにすることで、 内部モデルにあるフィールドとないフィールド(resolver を分けるべきフィールド)を型レベルで区別できるようになる
42 内部モデル型接続 mappers や Backing model のような仕組みは、 単に内部モデル - API
モデルのマッピングを定義するだけはない 「内部モデルにないフィールドは resolver が必須」というルールを型レベルで強制 する」 という効果が地味に重要 GraphQL は N+1 問題が起きやすい… という言説があるが、 この 「resolver が必須化されたフィールド」はN+1問題を起こしうるシグナル resolver での DataLoader 利用を徹底すれば、 N+1問題はむしろ検知・回避しやすいまであるのでは?
43 パターンと軸のまとめ 1. スキーマと実装の分離 schema-first vs code-first スキーマの主体は誰か 2. スキーマと実装の型整合性
型生成・scaffold ベース vs 型推論ベース 型生成を含むループになるか, 魔術的型推論の難解エラーに立ち向かうか 3. 内部モデル型接続 mappers, Backing model, Source type のような仕組みの有無 内部モデル(e.g. ORM)とAPIモデルのズレが型レベルで浮かび上がる価値が大きい
gqlkit - 「普通の TS の関数で GraphQL を書きたい」を実現する一案 隙間を埋める
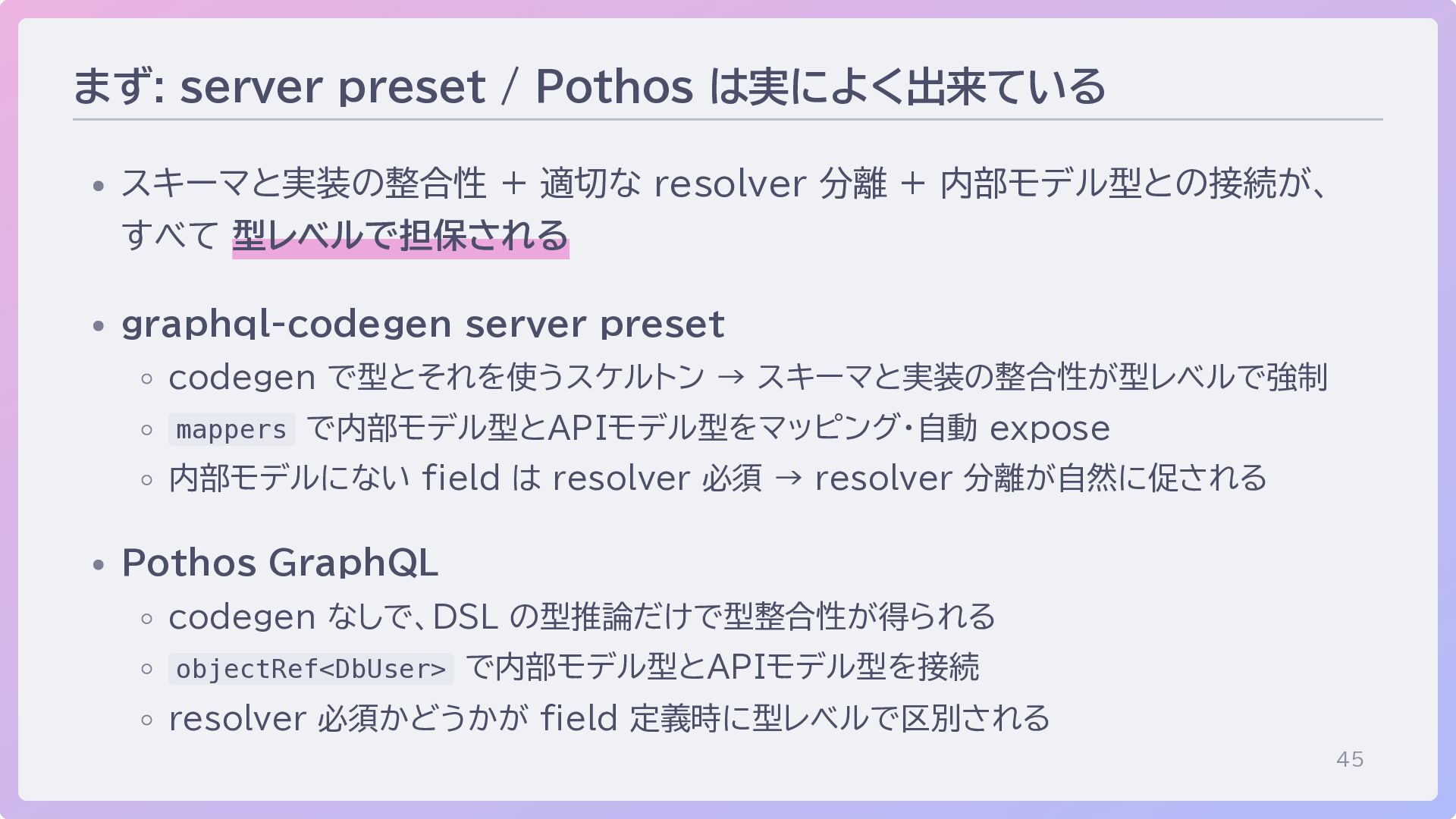
45 まず: server preset / Pothos は実によく出来ている スキーマと実装の整合性 + 適切な
resolver 分離 + 内部モデル型との接続が、 すべて 型レベルで担保される graphql-codegen server preset codegen で型とそれを使うスケルトン → スキーマと実装の整合性が型レベルで強制 mappers で内部モデル型とAPIモデル型をマッピング・自動 expose 内部モデルにない field は resolver 必須 → resolver 分離が自然に促される Pothos GraphQL codegen なしで、DSL の型推論だけで型整合性が得られる objectRef<DbUser> で内部モデル型とAPIモデル型を接続 resolver 必須かどうかが field 定義時に型レベルで区別される
46 それでも、 実装者目線で残る難しさ 型生成を含むループになるか, 魔術的型推論の難解エラーに立ち向かうか graphql-codegen server preset resolver 分けたい
/ mapper 追加したいなどで codegen 実装の試行錯誤ループ 「resolver 分離」「mapper 設定」を如何に徹底するか Pothos GraphQL DSL が独特・複雑で、 SDL + 単純な resolver 関数に比べると可読性は落ちる 型レベルで頑張った代償として 複雑な型エラー が出る 共通して「普通の TS コード」とは違うリズム・読みづらさは否めない
47 「普通の TS コード」 DSLがほぼなく、普通に型定義して、普通に関数を定義・実装して…
48 ないなら試しに作ってみよう
49 目指す状態 Server preset や Pothos が達成していることはできるだけ維持 codegen で型とそれを使うスケルトン →
スキーマと実装の整合性が型レベルで強制 mappers で内部モデル型とAPIモデル型をマッピング・自動 expose 内部モデルにない field は resolver 必須 → resolver 分離が自然に促される コード生成ループや複雑な型推論をできるだけ回避 TS の type 宣言と関数だけで GraphQLSchema を作れないか?
50 github.com/izumin5210/gqlkit
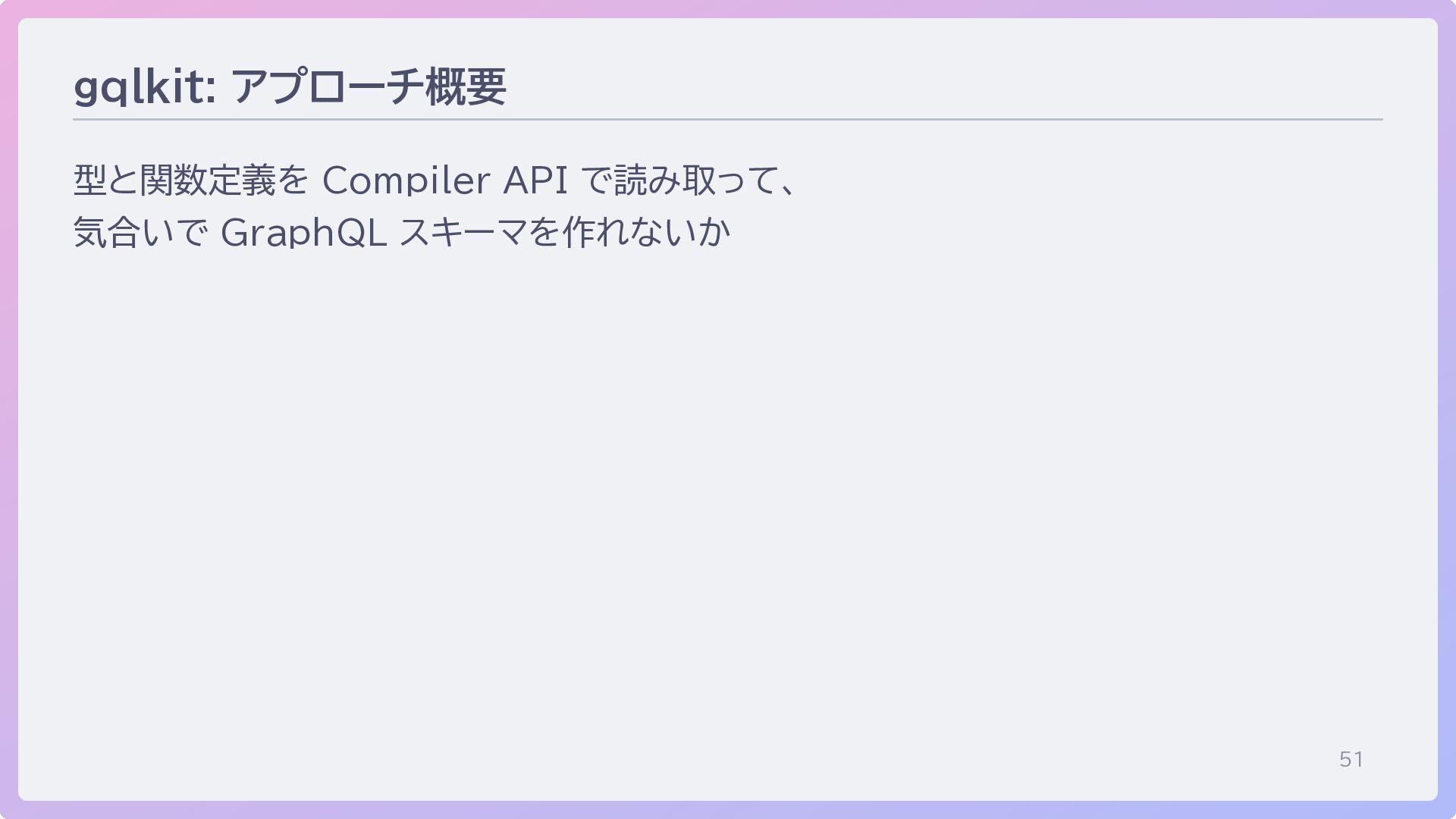
51 gqlkit: アプローチ概要 型と関数定義を Compiler API で読み取って、 気合いで GraphQL スキーマを作れないか
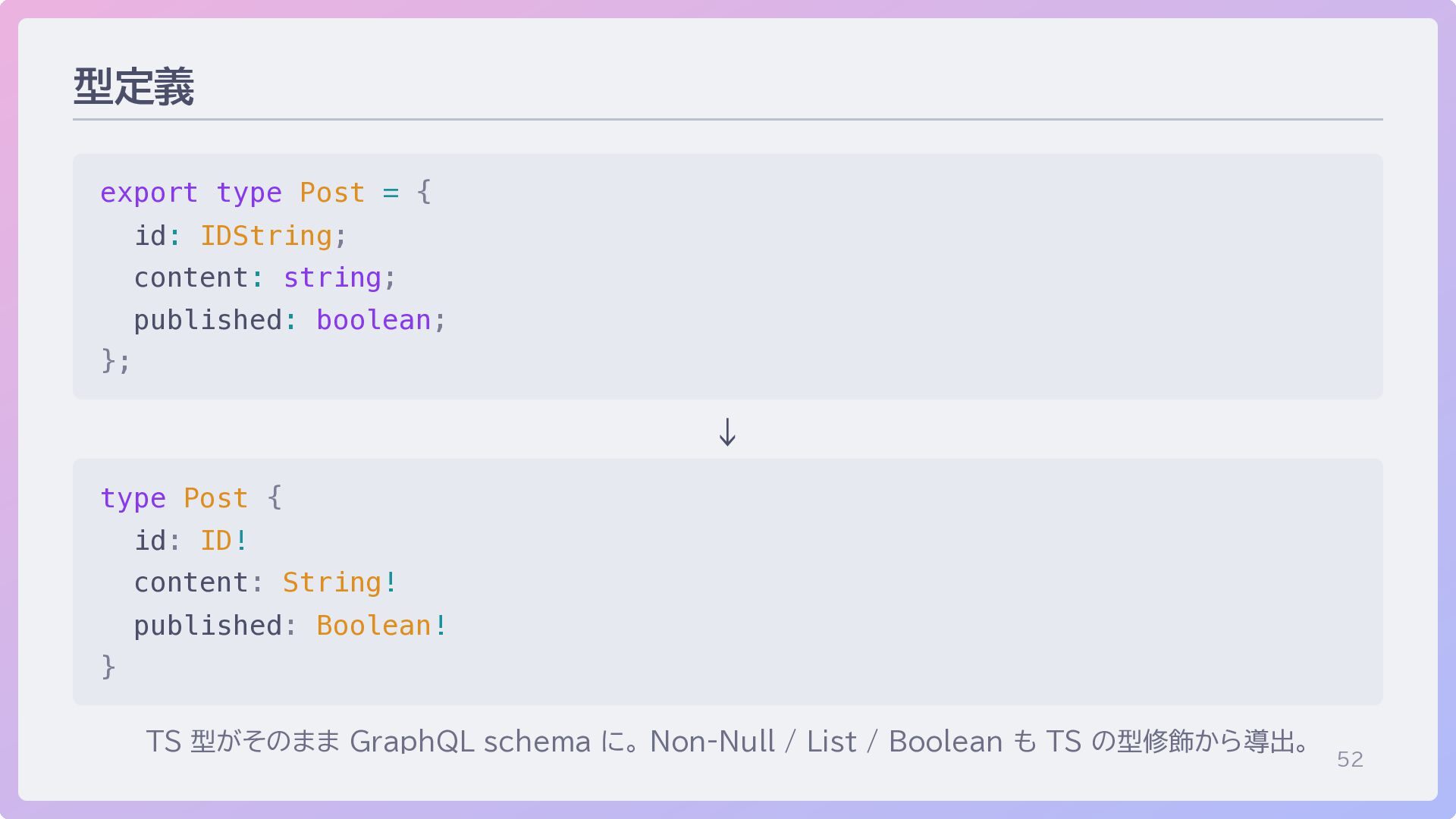
52 型定義 export type Post = { id: IDString; content:
string; published: boolean; }; ↓ type Post { id: ID! content: String! published: Boolean! } TS 型がそのまま GraphQL schema に。 Non-Null / List / Boolean も TS の型修飾から導出。
53 Query定義 export const posts = defineQuery<NoArgs, Post[]>( async (_root,
_args, ctx) => fetchPosts(ctx.db), ); graphql-js が要求する引数リストを満たしやすいように、クエリ定義関数を使う (DSL回避失敗) ↓ type Query { posts: [Post!] }
54 Mutation, Input 定義 export const createPost = defineMutation< {
input: { content: string } }, Post >( async (_root, { input }, ctx) => savePost(ctx.db, { content: input.content }), ); ↓ input CreatePostInput { content: String! } type Mutation { createPost(input: CreatePostInput!): Post! } Queryと同じくMutation定義関数を使う。 地味な改善として、 input 型は関数の引数から生成可能。 だってみんな TypeScript 書くとき関数の引数を毎回は外に定義しないよね?
55 表現力: e.g. string literal union → GraphQL enum export
type PostStatus = "draft" | "in_review" | "published"; export type Post = { id: IDString; content: string; status: PostStatus; }; ↓ enum PostStatus { DRAFT, IN_REVIEW, PUBLISHED } TS の string literal union がそのまま GraphQL enum に。 命名変換 (snake_case → SCREAMING_SNAKE_CASE) も自動。
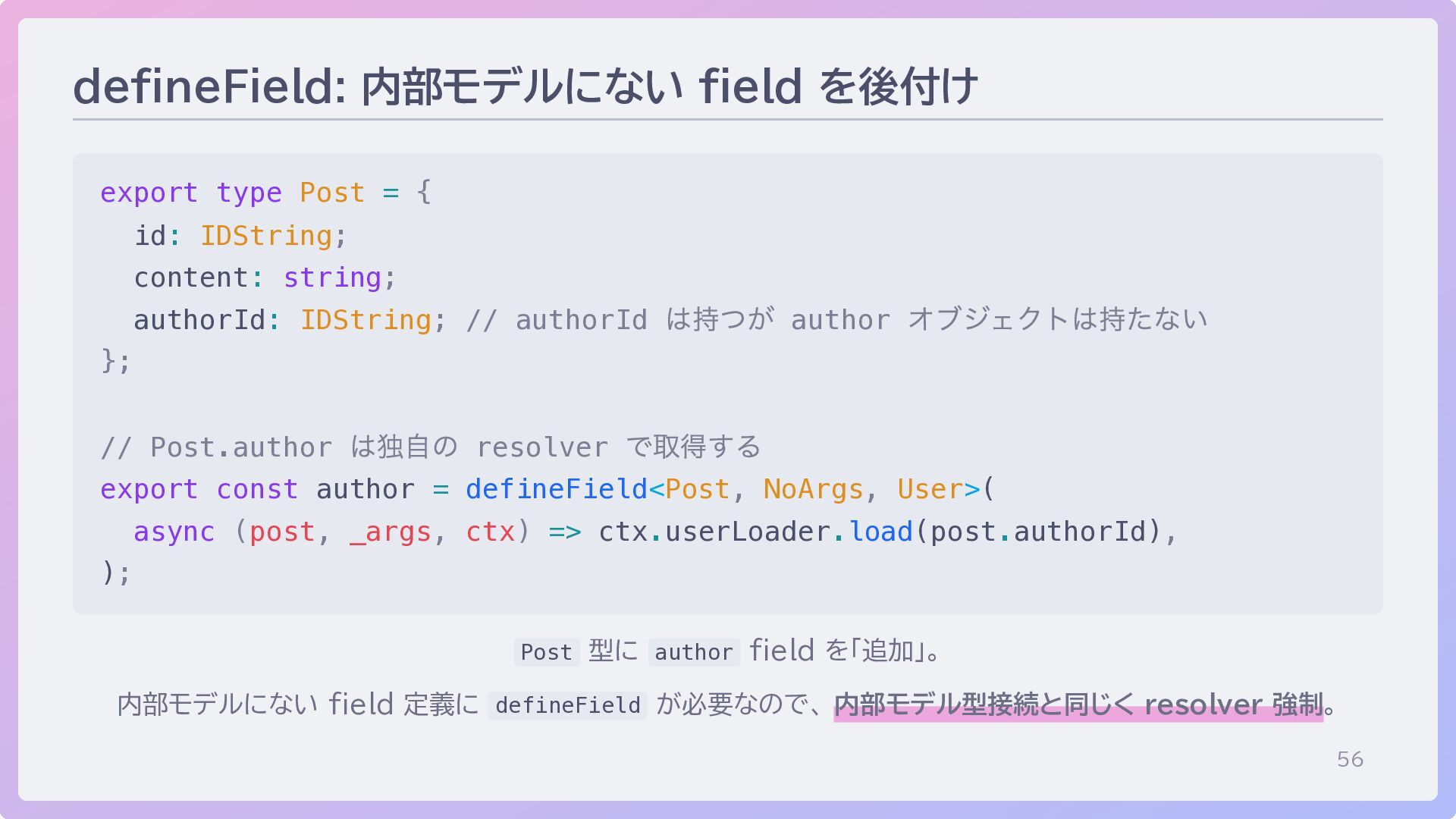
56 defineField: 内部モデルにない field を後付け export type Post = {
id: IDString; content: string; authorId: IDString; // authorId は持つが author オブジェクトは持たない }; // Post.author は独自の resolver で取得する export const author = defineField<Post, NoArgs, User>( async (post, _args, ctx) => ctx.userLoader.load(post.authorId), ); Post 型に author field を「追加」。 内部モデルにない field 定義に defineField が必要なので、 内部モデル型接続と同じく resolver 強制。
57 ORM 型をそのまま GraphQL 型に export const postsTable = pgTable("posts",
{ id: uuid().primaryKey().defaultRandom(), content: text(), status: text({ enum: ["draft", "in_review", "published"] }).notNull(), authorId: uuid().notNull(), }); export type Post = InferSelectModel<typeof postsTable>; 上記の例では Drizzle ORM の型 ( InferSelectModel ) からそのまま GraphQL Post 型に。 これと defineField を組み合わせてグラフを構築できる。 内部モデル === API モデル を常に仮定するのはモデリング観点で危険な点には注意。
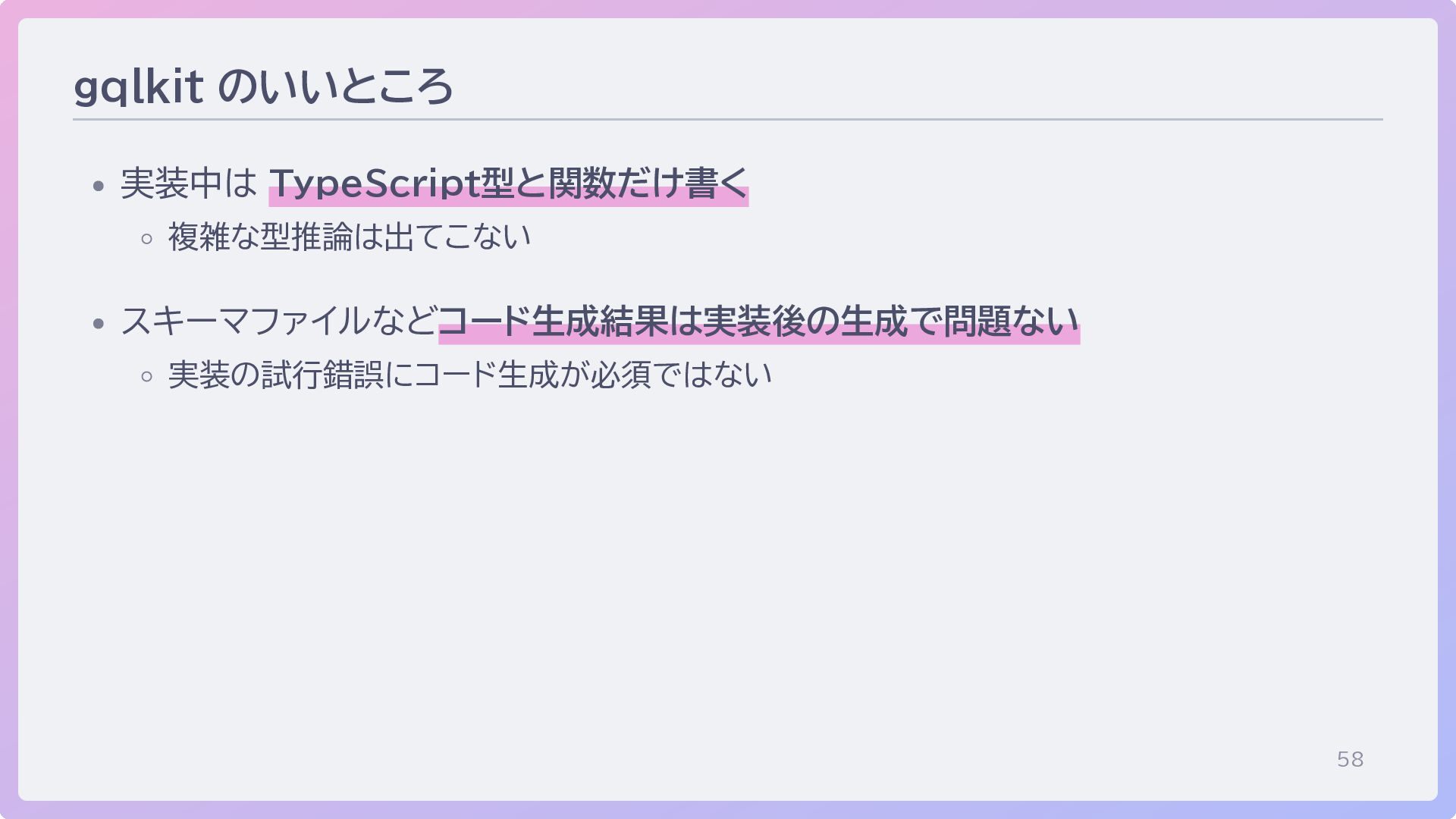
58 gqlkit のいいところ 実装中は TypeScript型と関数だけ書く 複雑な型推論は出てこない スキーマファイルなどコード生成結果は実装後の生成で問題ない 実装の試行錯誤にコード生成が必須ではない
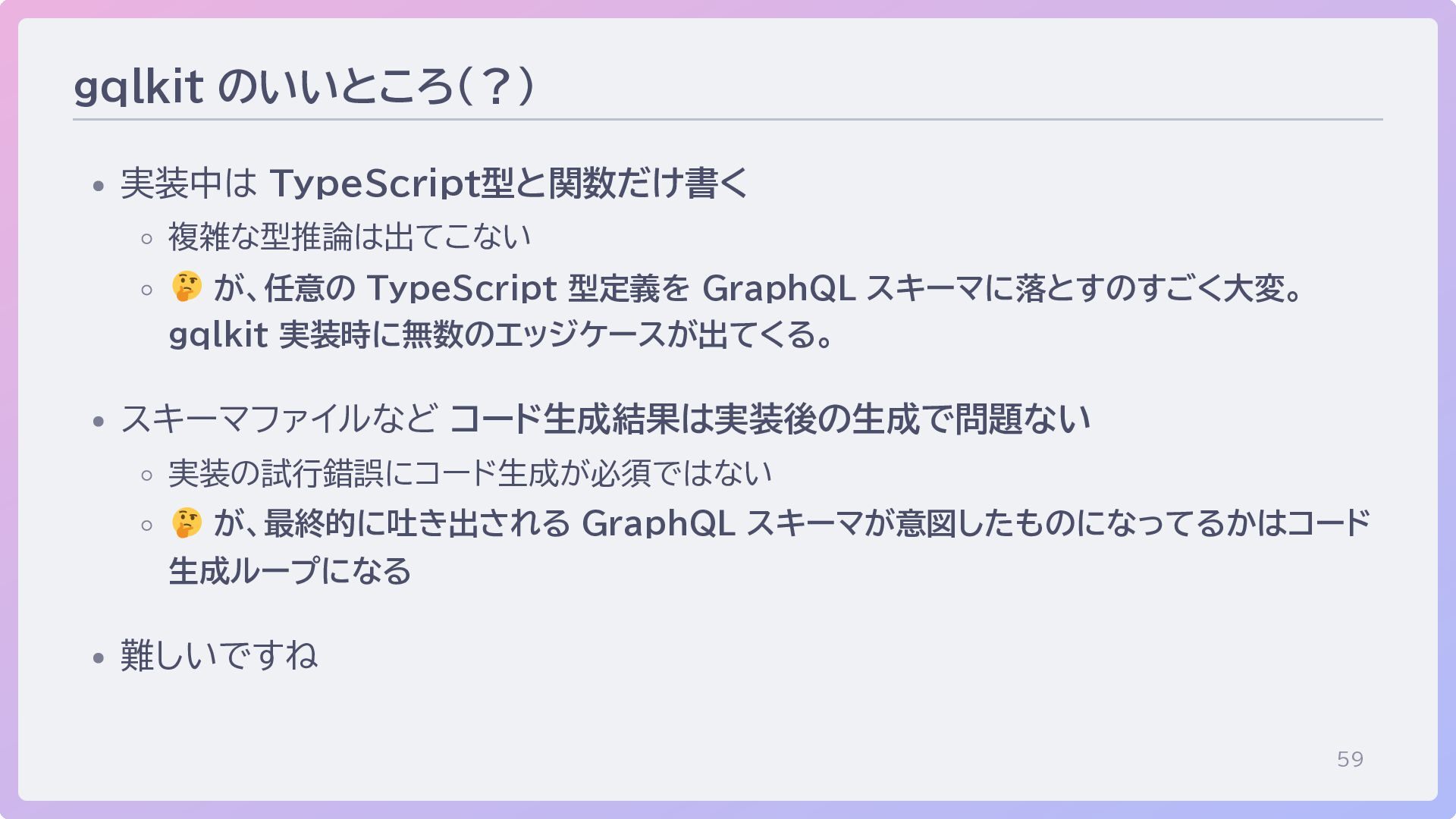
59 gqlkit のいいところ(?) 実装中は TypeScript型と関数だけ書く 複雑な型推論は出てこない が、任意の TypeScript 型定義を GraphQL
スキーマに落とすのすごく大変。 gqlkit 実装時に無数のエッジケースが出てくる。 スキーマファイルなど コード生成結果は実装後の生成で問題ない 実装の試行錯誤にコード生成が必須ではない が、最終的に吐き出される GraphQL スキーマが意図したものになってるかはコード 生成ループになる 難しいですね
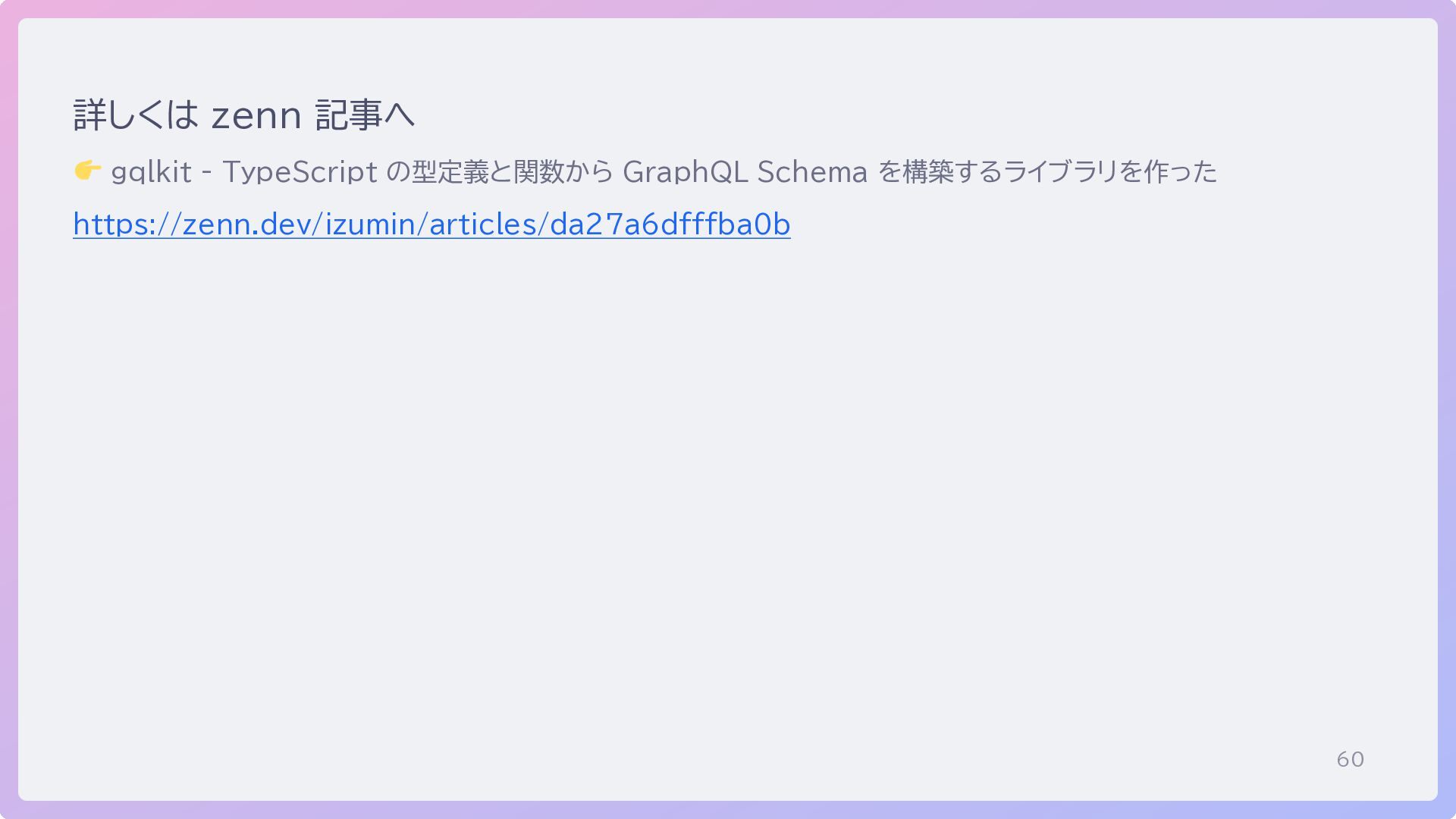
60 詳しくは zenn 記事へ gqlkit - TypeScript の型定義と関数から GraphQL Schema
を構築するライブラリを作った https://zenn.dev/izumin/articles/da27a6dfffba0b
ライブラリを AI Coding Agent にどう使ってもらうか おまけ: Agentic Coding 時代の library/framework
62 AI が「扱えるライブラリ」と「扱えないライブラリ」 今できたものを AI は知らない 既存の主要ライブラリ AI が学習データに含んでいる →
ある程度扱える前提 新規 / マイナーライブラリ 学習データになく、AI には未知 AI にとっての扱いやすさ 特定の開発フローが必須になるとき、それをどうやって AI に守らせるか AI が失敗を検知・理解できるようになっているか ...
63 新規ライブラリを AI に扱わせるには そもそも AI が使いやすいものを作る AI が使いづらいものは人間にもだいたい使いづらい より不満の閾値を下げて考える
AI が利用中バージョンのライブラリAPIや仕様を理解できるようにする e.g. skill の同梱: Gunshi, Hono, AI SDK など
64 gqlkit と Agentic Coding そもそもコード生成ループや DSL, 複雑な型エラー回避は AI にとっても嬉しい(は
ず。たぶん。) Gunshi などと同じく、Skill を同梱してあげる
65 Eval: AI はライブラリをうまく使ってくれるか gqlkit で API の工夫や Skill 同梱などやってるが、どれくらい意味あるんだろ
う? Eval (評価) してみる 検証したい仮説 プレーンな gqlkit (=README のみ) は、学習データに含まれる graphql-codegen / Pothos に対して劣る gqlkit + skill 同梱 で、 server preset / Pothos と同等以上の品質が出せる
66 eval の設計 agent: claude-code × model: claude-sonnet-4-6 2 task
× 4 setup × 5 runs = 40 runs (各 setup は隔離サンドボックスで並列実行) setup graphql-codegen server preset / Pothos / gqlkit (skill なし/あり) task 01-crud: User / Post の基本 CRUD (機微情報 email を非公開) 02-relation: User.posts / Post.author リレーション (N+1 回避を要求) 採点: サンドボックス内で AI が実装 → 採点 使用ツール: @vercel/agent-eval
67 結果① — 全 40 run pass eval codegen Pothos
gqlkit (plain) gqlkit + skill 01-crud 4/4 × 5 ✓ 4/4 × 5 ✓ 4/4 × 5 ✓ 5/5 × 5 ✓ 02-relation 6/6 × 5 ✓ 6/6 × 5 ✓ 6/6 × 5 ✓ 7/7 × 5 ✓ 全 setup × 全 run が 100% pass — どのライブラリでも AI は最終的に正解 にたどり着く N+1 回避 (DataLoader) は 02-relation の 15/15 run で達成 (プレーン gqlkit でも) 機微情報 email の除外 は 40/40 run で達成 (backing 型に乗っていても漏ら さない)
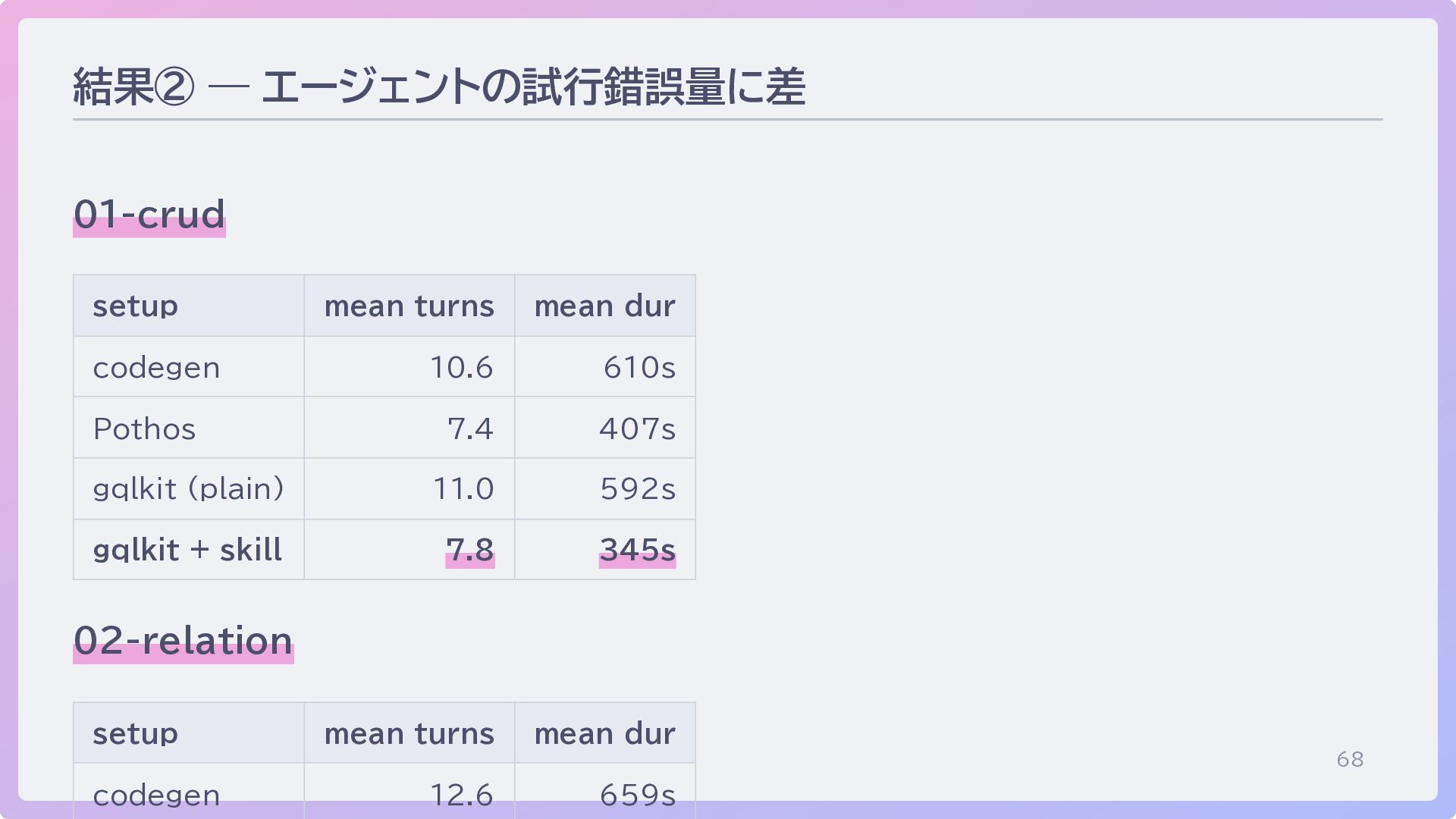
68 結果② — エージェントの試行錯誤量に差 01-crud setup mean turns mean dur
codegen 10.6 610s Pothos 7.4 407s gqlkit (plain) 11.0 592s gqlkit + skill 7.8 345s 02-relation setup mean turns mean dur codegen 12.6 659s
69 eval からの示唆 どのライブラリでも書ける時代 — 正答率では意外と差が出ない (今回は全 pass) 差は 「コード生成までの試行錯誤量」
に出る = エージェントの所要時間とコスト 未知のライブラリ でも、 skill 1 ファイル で「最速」になり得る ライブラリ作者の責務 — API 設計だけでなく「同梱する知識」も最適化対象に 「ライブラリ自体の設計」+「ライブラリに同梱する知識」のセットで考える時代
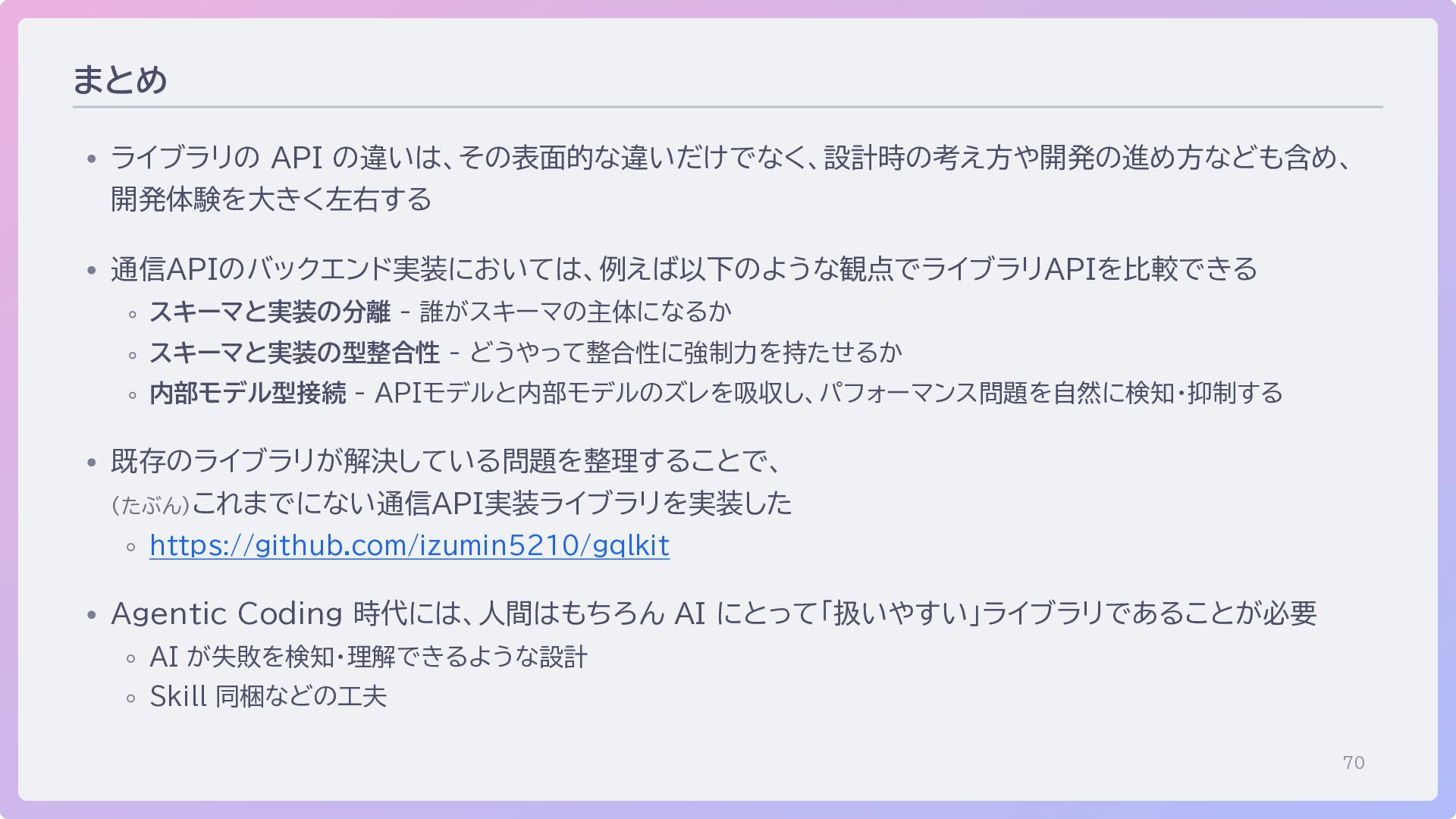
70 まとめ ライブラリの API の違いは、その表面的な違いだけでなく、設計時の考え方や開発の進め方なども含め、 開発体験を大きく左右する 通信APIのバックエンド実装においては、例えば以下のような観点でライブラリAPIを比較できる スキーマと実装の分離 - 誰がスキーマの主体になるか
スキーマと実装の型整合性 - どうやって整合性に強制力を持たせるか 内部モデル型接続 - APIモデルと内部モデルのズレを吸収し、パフォーマンス問題を自然に検知・抑制する 既存のライブラリが解決している問題を整理することで、 (たぶん)これまでにない通信API実装ライブラリを実装した https://github.com/izumin5210/gqlkit Agentic Coding 時代には、人間はもちろん AI にとって「扱いやすい」ライブラリであることが必要 AI が失敗を検知・理解できるような設計 Skill 同梱などの工夫
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![53 Query定義 export const posts = defineQuery<NoArgs, Post[]>( async (_root,](https://files.speakerdeck.com/presentations/44c90c8d04a94a8c94dd17cb21fa6aa4/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}