California, Berkeley. Theano Overview • Not specifically designed for NN. • Write computation in symbolic representation (in Python code) • Theano compiles the python code into CUDA code. • The framework provides low level API (e.g., shared memory, and gradient descent etc.) • Heavily rely on a python mathematical library called numpy
California, Berkeley. Theano Pros / Cons • Pros: – Python is a high level PL (comparing to Caffee) – Symbolic Representation of Computation (SymR) – Automatic gradient descent based on (SymR) – Fast prototyping (comparing with Caffee) – Allow fine tweaking and tuning of the model • Cons: – Not particularly designed for NN – Hard to scale – Not suitable in production development (comparing with Caffee) – Assembly a complex CNN or LSTM purely using Theano is tedious and error-prone
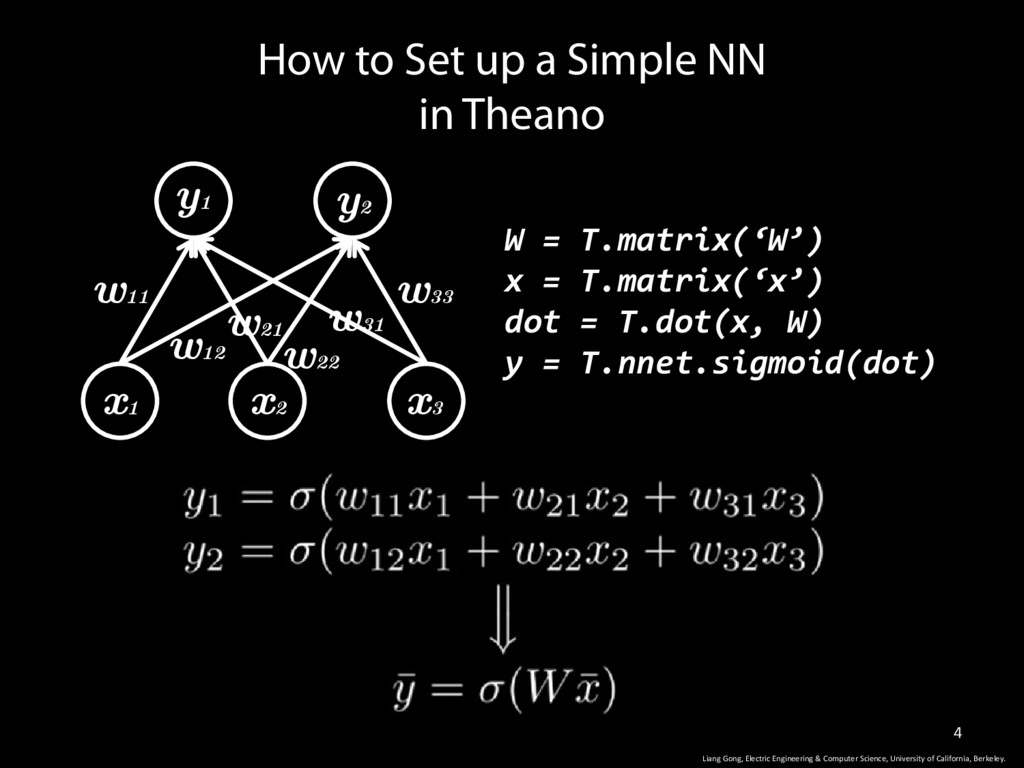
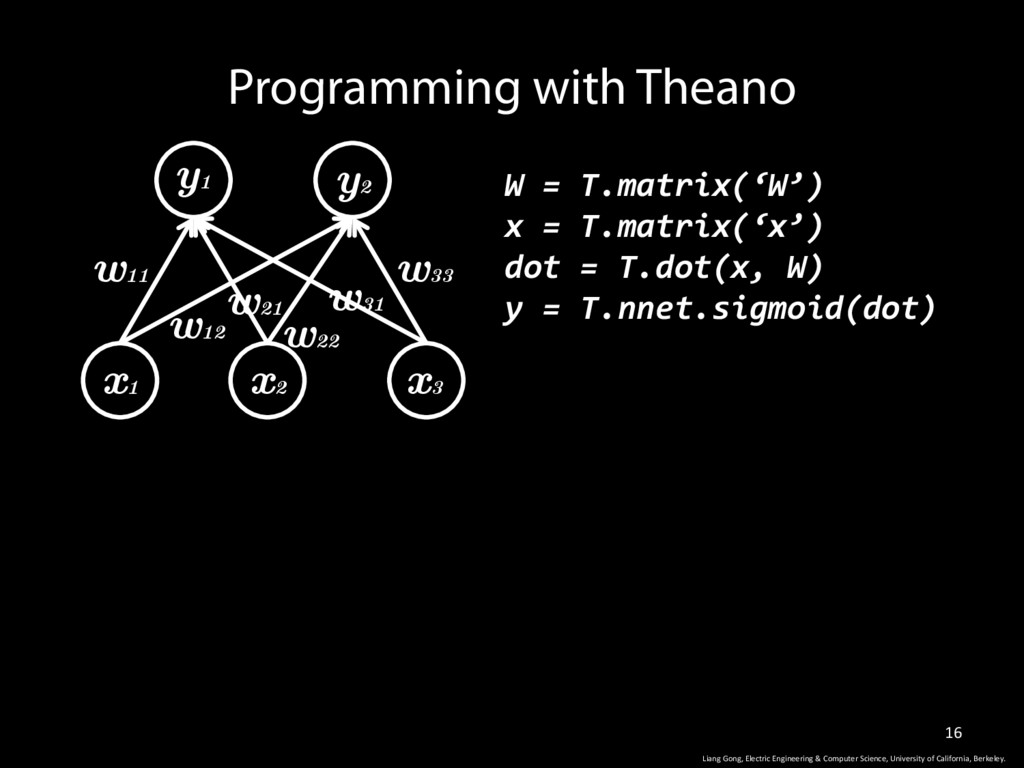
W) y = T.nnet.sigmoid(dot) How to Set up a Simple NN in Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley.
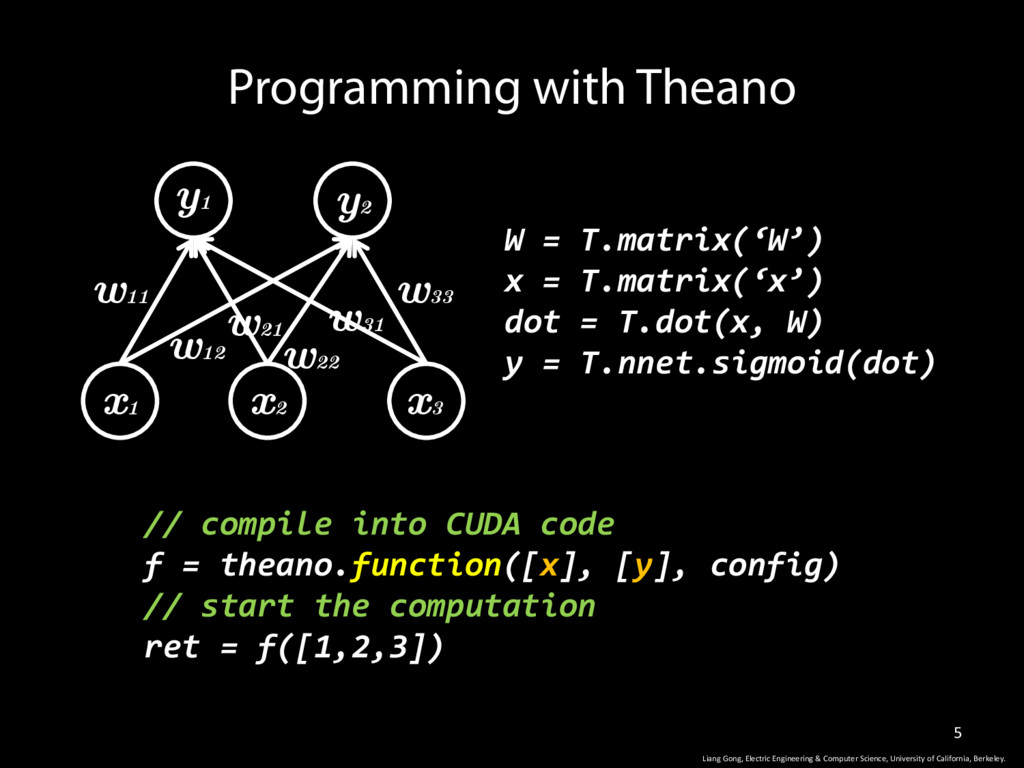
W) y = T.nnet.sigmoid(dot) Programming with Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. // compile into CUDA code f = theano.function([x], [y], config) // start the computation ret = f([1,2,3])
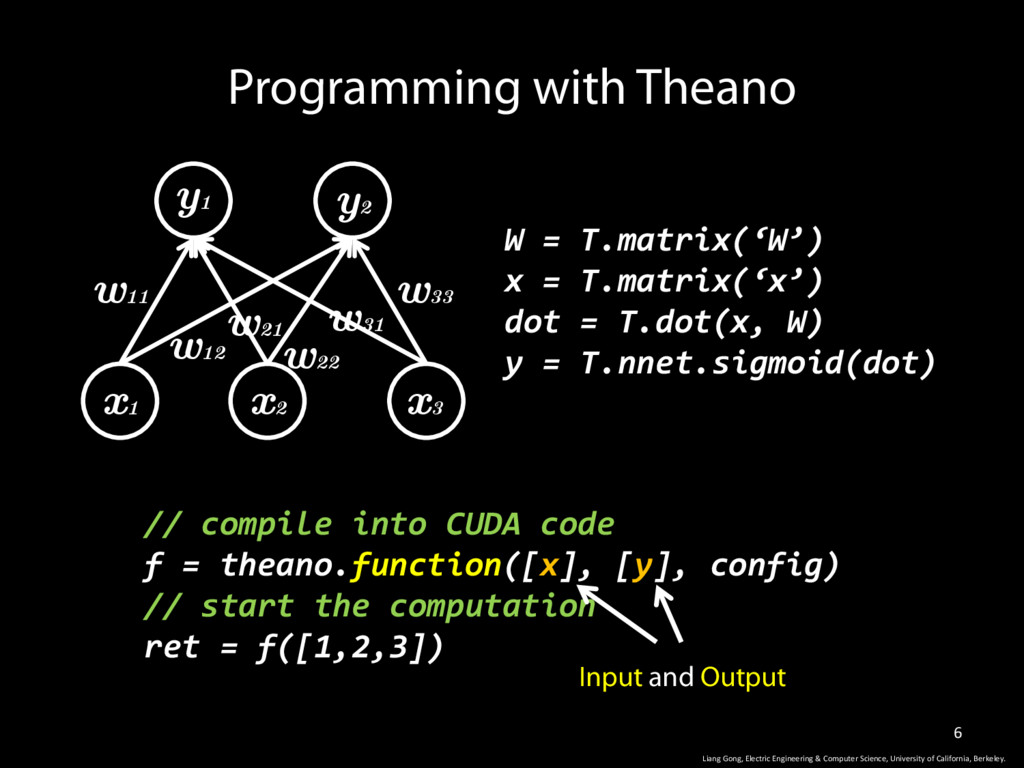
W) y = T.nnet.sigmoid(dot) Programming with Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. // compile into CUDA code f = theano.function([x], [y], config) // start the computation ret = f([1,2,3]) Input and Output
California, Berkeley. Scaling + Data Movement • Shared variable (data is stored in GPU memory) value = numpy.random.uniform(low, high, size) W = theano.shared(value)
California, Berkeley. Scaling + Data Movement • Shared variable (data is stored in GPU memory) value = numpy.random.uniform(low, high, size) W = theano.shared(value) Create a random array in CPU
California, Berkeley. Scaling + Data Movement • Shared variable (data is stored in GPU memory) value = numpy.random.uniform(low, high, size) W = theano.shared(value) Create a random array in CPU Lower bound, higher bound of values
California, Berkeley. Scaling + Data Movement • Shared variable (data is stored in GPU memory) value = numpy.random.uniform(low, high, size) W = theano.shared(value) Create a random array in CPU Lower bound, higher bound of values The number of values
California, Berkeley. Scaling + Data Movement • Shared variable (data is stored in GPU memory) value = numpy.random.uniform(low, high, size) W = theano.shared(value) Create a random array in CPU Lower bound, higher bound of values The number of values Symbolic representation of parameters
California, Berkeley. Scaling + Data Movement • Shared variable (data is stored in GPU memory) value = numpy.random.uniform(low, high, size) W = theano.shared(value) Create a random array in CPU Lower bound, higher bound of values The number of values Symbolic representation of parameters Data is in GPU memory during the computation.
California, Berkeley. Scaling + Data Movement • Shared variable (data is stored in GPU memory) value = numpy.random.uniform(low, high, size) W = theano.shared(value) w = W.get_value() // move data to main memory W.set_value(w) // move data to GPU memory Create a random array in CPU Lower bound, higher bound of values The number of values
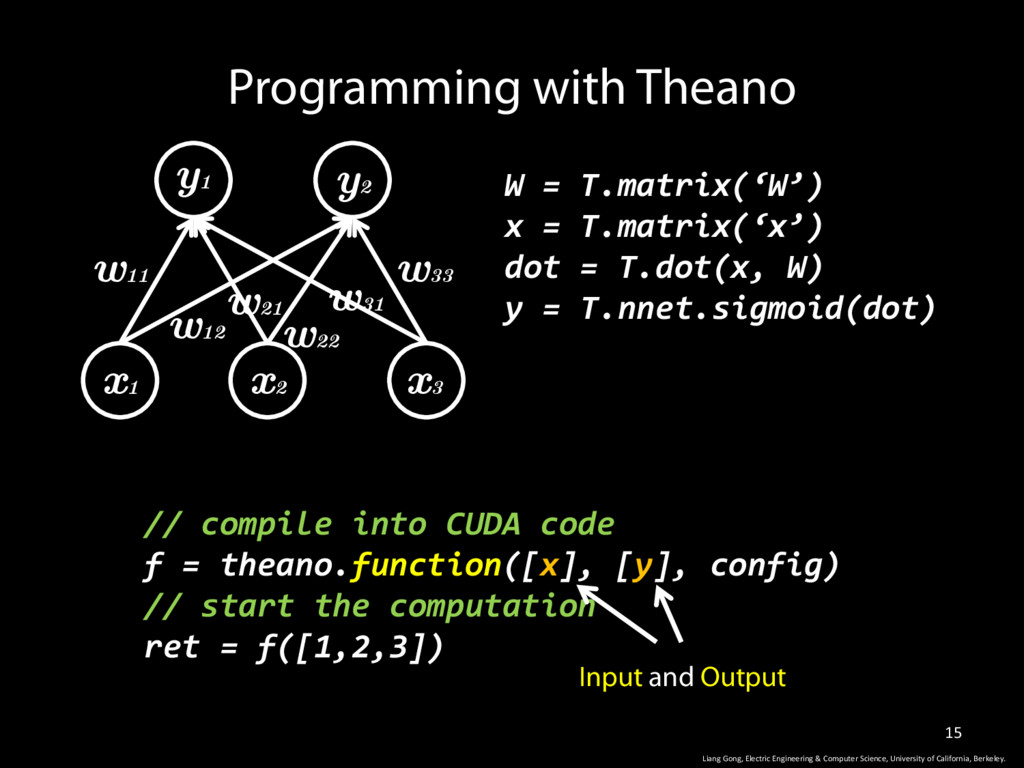
W) y = T.nnet.sigmoid(dot) Programming with Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. // compile into CUDA code f = theano.function([x], [y], config) // start the computation ret = f([1,2,3]) Input and Output
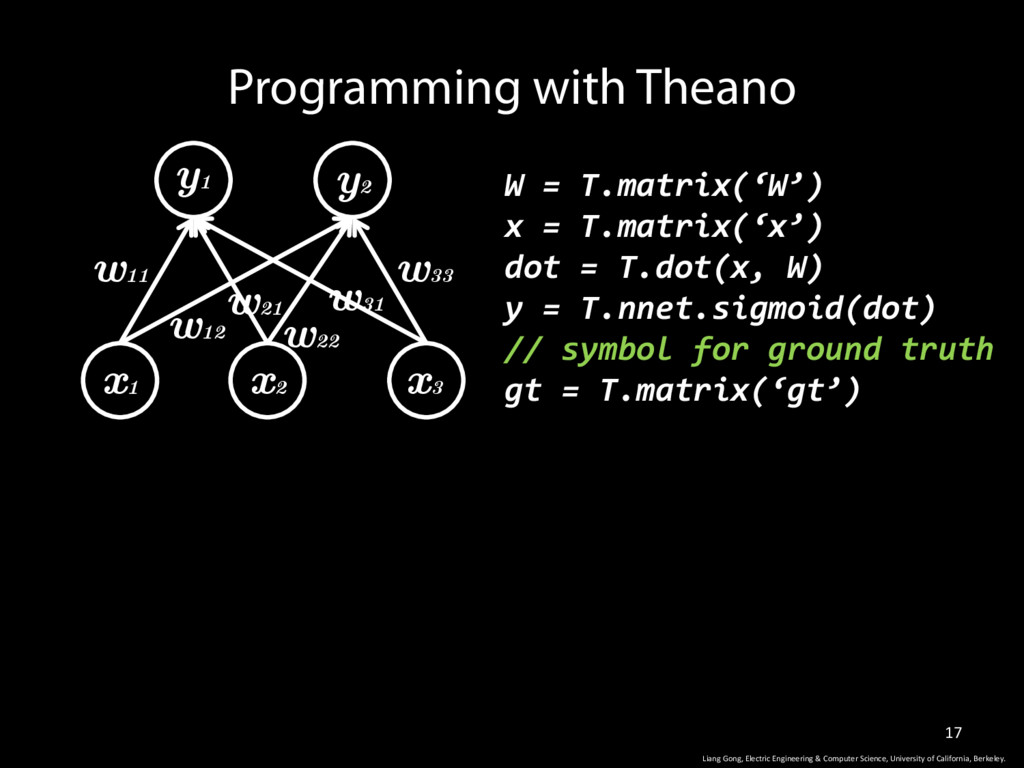
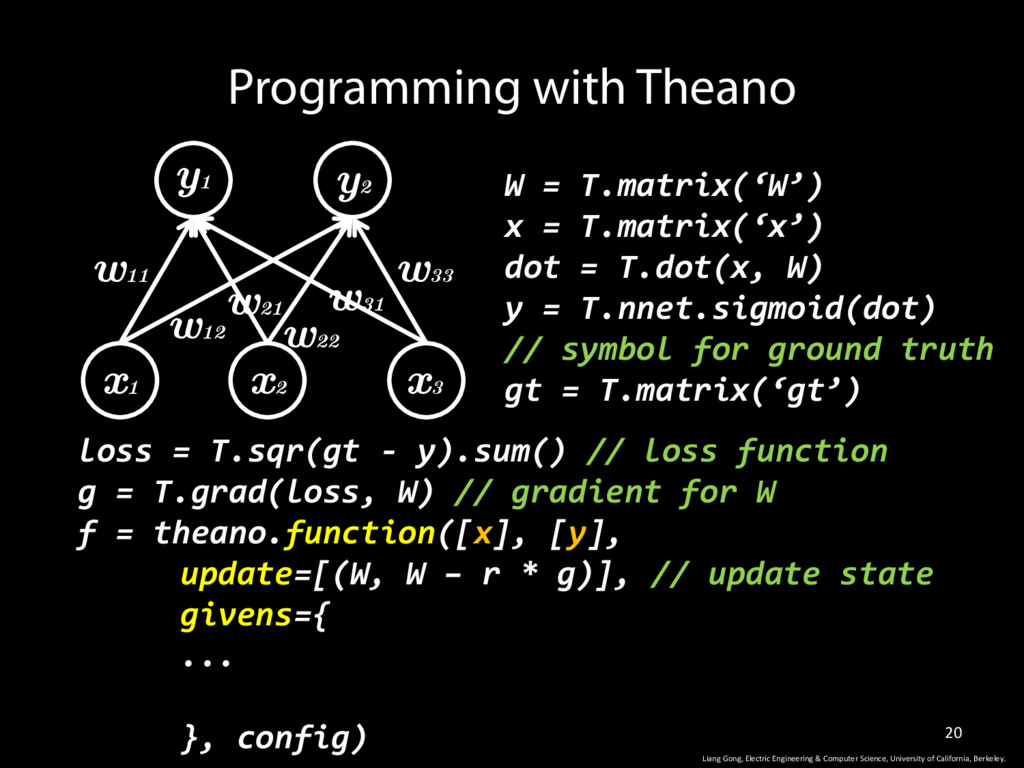
W) y = T.nnet.sigmoid(dot) // symbol for ground truth gt = T.matrix(‘gt’) Programming with Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley.
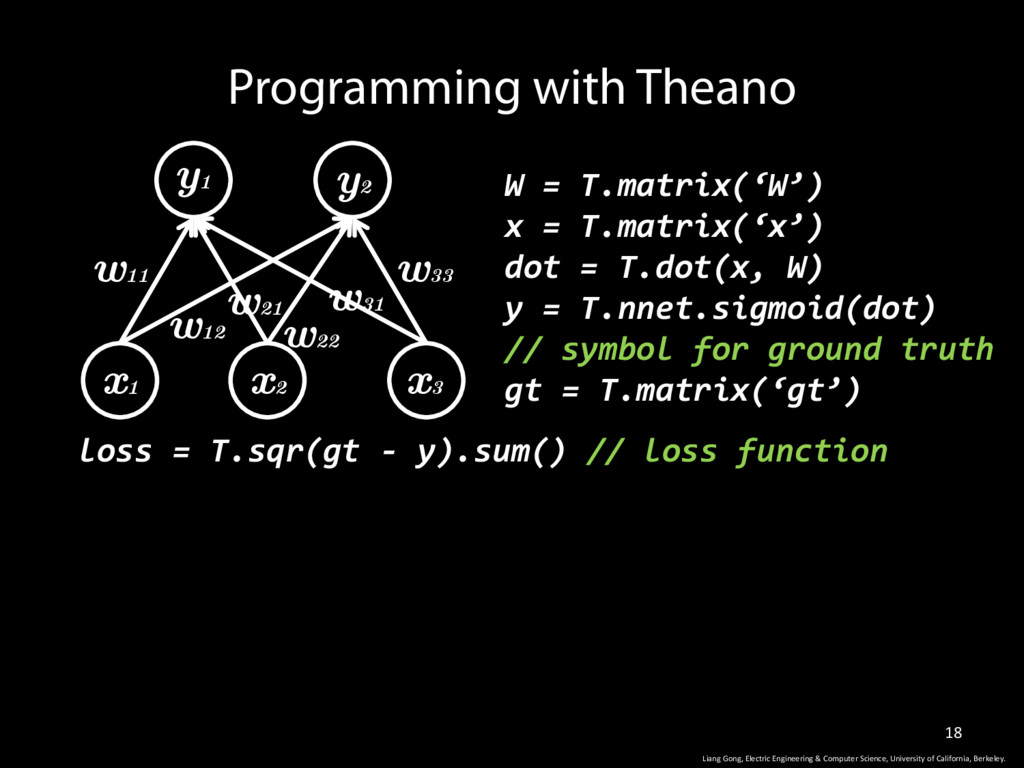
W) y = T.nnet.sigmoid(dot) // symbol for ground truth gt = T.matrix(‘gt’) Programming with Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. loss = T.sqr(gt - y).sum() // loss function
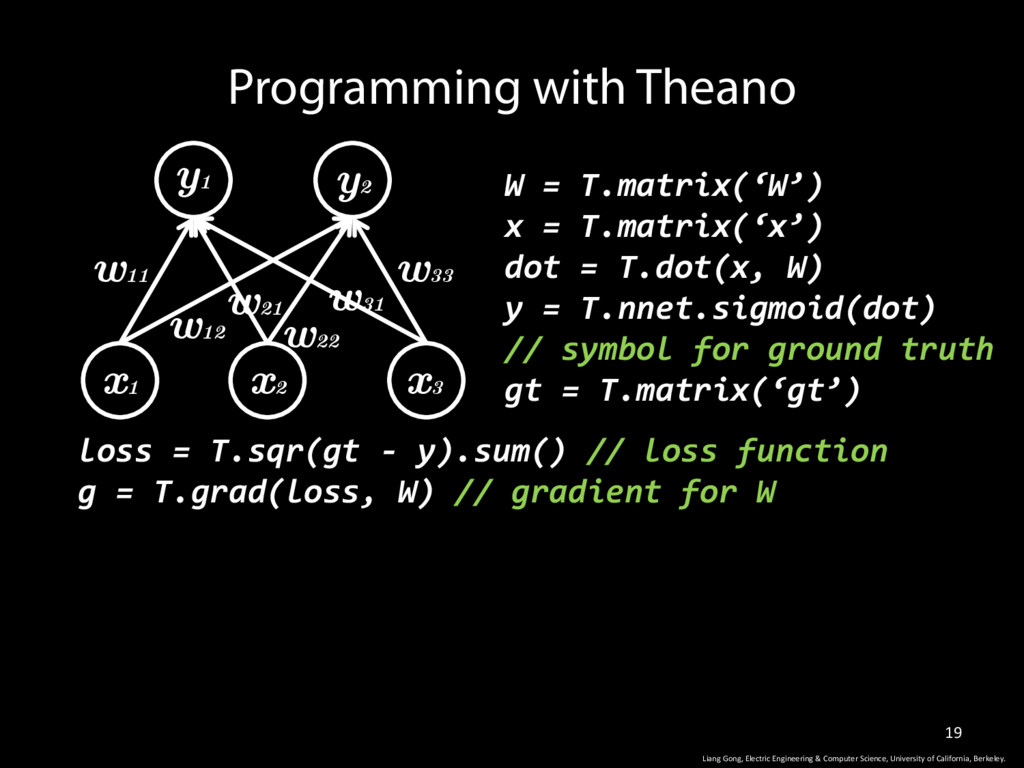
W) y = T.nnet.sigmoid(dot) // symbol for ground truth gt = T.matrix(‘gt’) Programming with Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. loss = T.sqr(gt - y).sum() // loss function g = T.grad(loss, W) // gradient for W
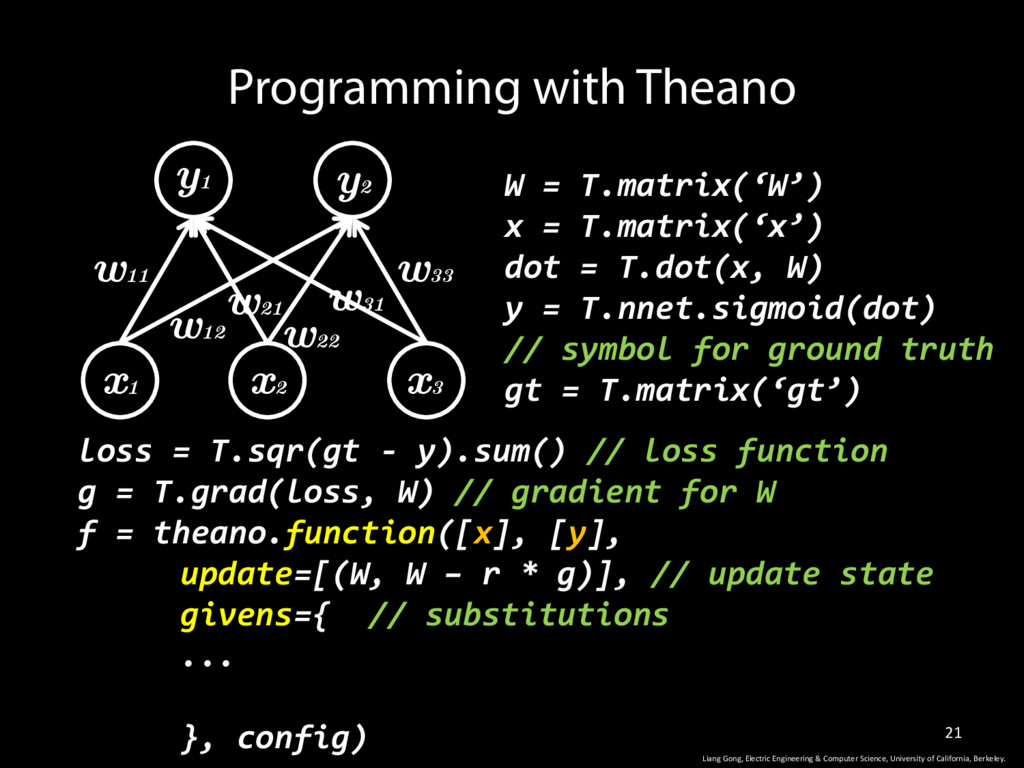
W) y = T.nnet.sigmoid(dot) // symbol for ground truth gt = T.matrix(‘gt’) Programming with Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. loss = T.sqr(gt - y).sum() // loss function g = T.grad(loss, W) // gradient for W f = theano.function([x], [y], update=[(W, W – r * g)], // update state givens={ ... }, config)
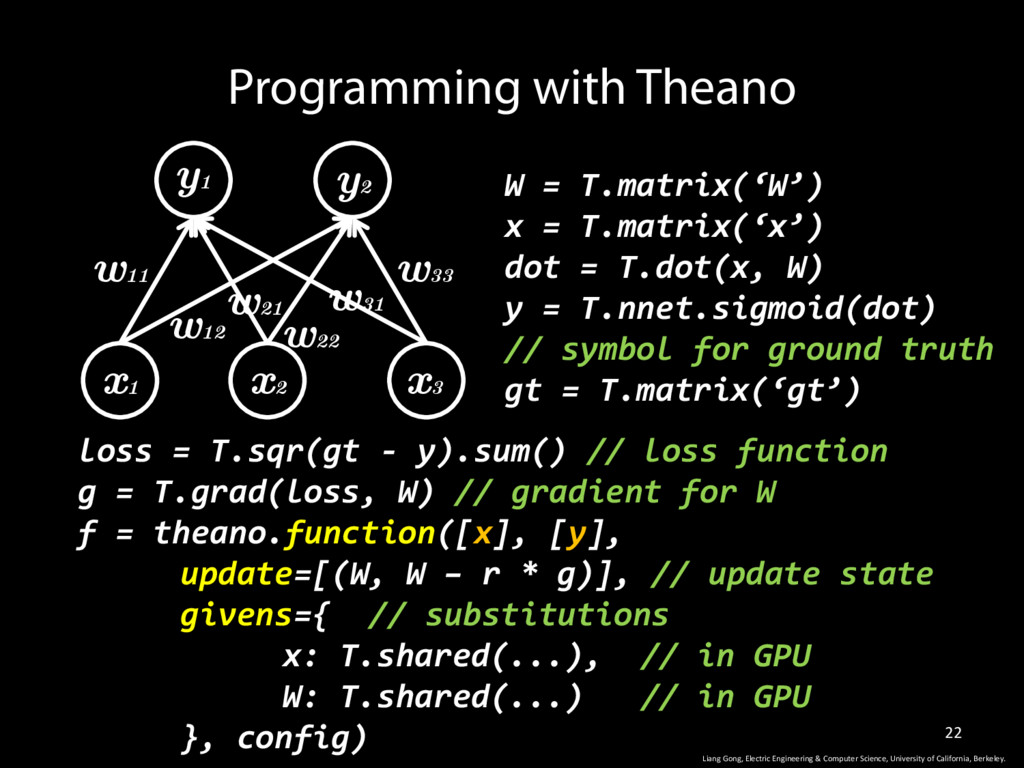
W) y = T.nnet.sigmoid(dot) // symbol for ground truth gt = T.matrix(‘gt’) Programming with Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. loss = T.sqr(gt - y).sum() // loss function g = T.grad(loss, W) // gradient for W f = theano.function([x], [y], update=[(W, W – r * g)], // update state givens={ // substitutions ... }, config)
W) y = T.nnet.sigmoid(dot) // symbol for ground truth gt = T.matrix(‘gt’) Programming with Theano w11 w12 w33 w31 w22 w21 y1 y2 x1 x2 x3 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. loss = T.sqr(gt - y).sum() // loss function g = T.grad(loss, W) // gradient for W f = theano.function([x], [y], update=[(W, W – r * g)], // update state givens={ // substitutions x: T.shared(...), // in GPU W: T.shared(...) // in GPU }, config)
of California, Berkeley. 25 • Provide some support for multiple GPUs import numpy import theano v01 = theano.shared(value1, target='dev0') // on the first GPU v02 = theano.shared(value2, target='dev0') // on the first GPU v11 = theano.shared(value3, target='dev1') // on the second GPU v12 = theano.shared(value4, target='dev1') // on the second GPU // compile into CUDA code f = theano.function([], [theano.tensor.dot(v01, v02), theano.tensor.dot(v11, v12)]) // start computating ret = f() http://deeplearning.net/software/theano/tutorial/using_multi_gpu.html
California, Berkeley. High Level Libraries • Keras is a minimalist, highly modular neural network library in the spirit of Torch, written in Python, that uses Theano under the hood for optimized tensor manipulation on GPU and CPU. • Pylearn2 is a library that wraps a lot of models and training algorithms such as Stochastic Gradient Descent that are commonly used in Deep Learning. Its functional libraries are built on top of Theano. • Lasagne is a lightweight library to build and train neural networks in Theano. It is governed by simplicity, transparency, modularity, pragmatism , focus and restraint principles. • Blocks a framework that helps you build neural network models on top of Theano. http://www.teglor.com/b/deep-learning-libraries-language-cm569/
California, Berkeley. Keras • A high level python library that is built on top of Theano (and works with Tensorflow) • Designed for NN • Modular, and easy to expand • Based on layers and their input / output http://www.teglor.com/b/deep-learning-libraries-language-cm569/
University of California, Berkeley. 29 • Mutual Parts: • python as API language • symbolic mathematical representation -> computation graph • support automated symbolic differentiation • TensorFlow In addition: • supports parallel computation • has capability to partition the compuation graph • provides coordination mechanism for parallel computation • Supports heterogeneous hardware • automatically allocates devices (gpu, cpu, mobile) to computation node • has visualization module (TensorBoard) • Implementation: • Theano complies python code into C or CUDA internal modules • TensorFlow is a C++ library that has a thin Python interface
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}