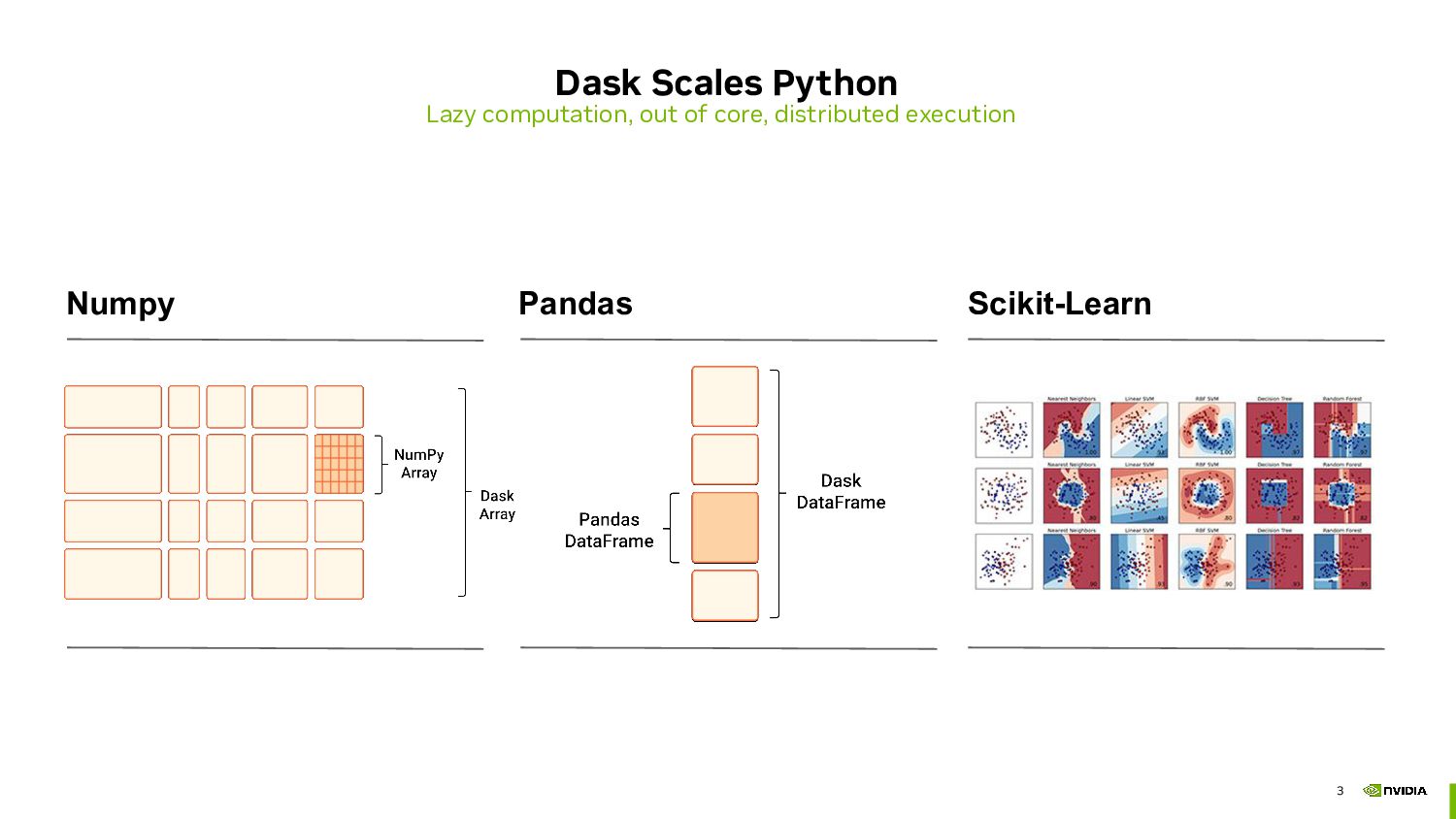
Dask is a popular Python framework for scaling your workloads, whether you want to leverage all of the cores on your laptop and stream large datasets through memory, or scale your workload out to thousands of cores on large compute clusters. Dask allows you to distribute code using familiar APIs such as pandas, NumPy and scikit-learn or write your own distributed code with powerful parallel task-based programming primitives.
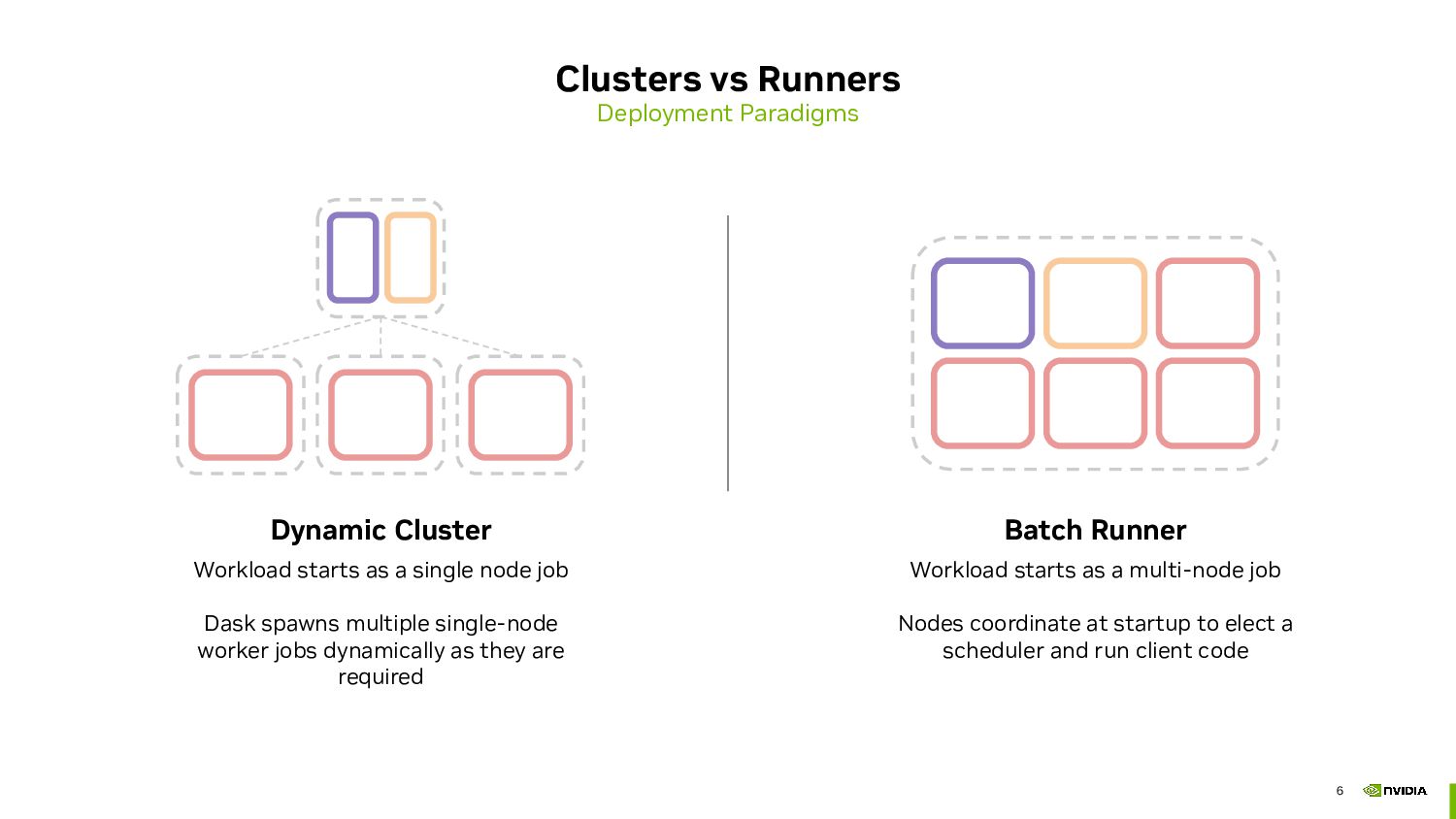
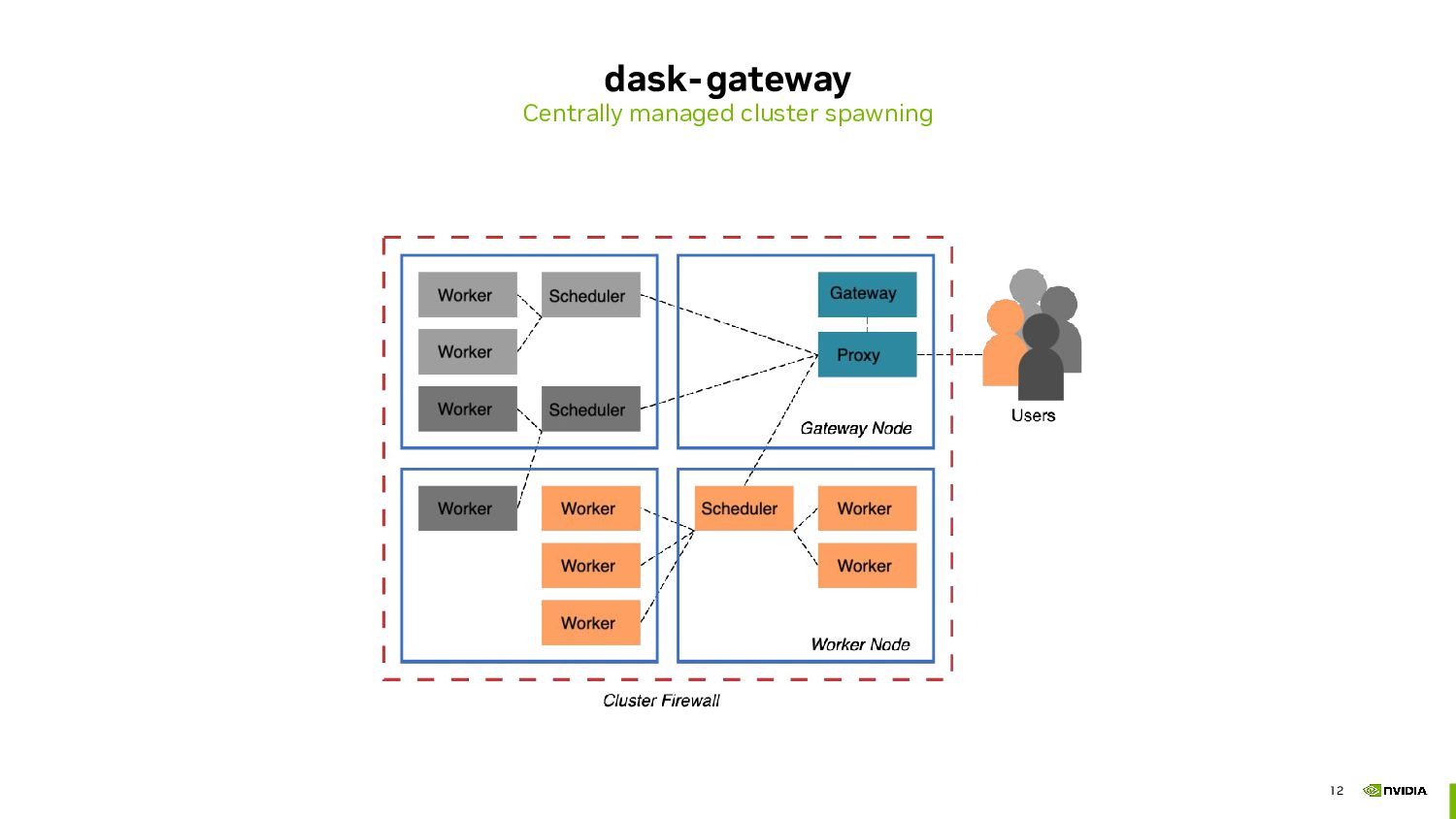
We will start by exploring the concept of adaptive clusters, which allow for dynamic scaling of resources based on the workload's demands. Adaptive clusters automatically submit and manage many jobs to an HPC queue, ensuring efficient resource utilisation and cost-effectiveness. This method is particularly useful for workloads with varying computational requirements, as it adjusts the number of active workers in real-time.
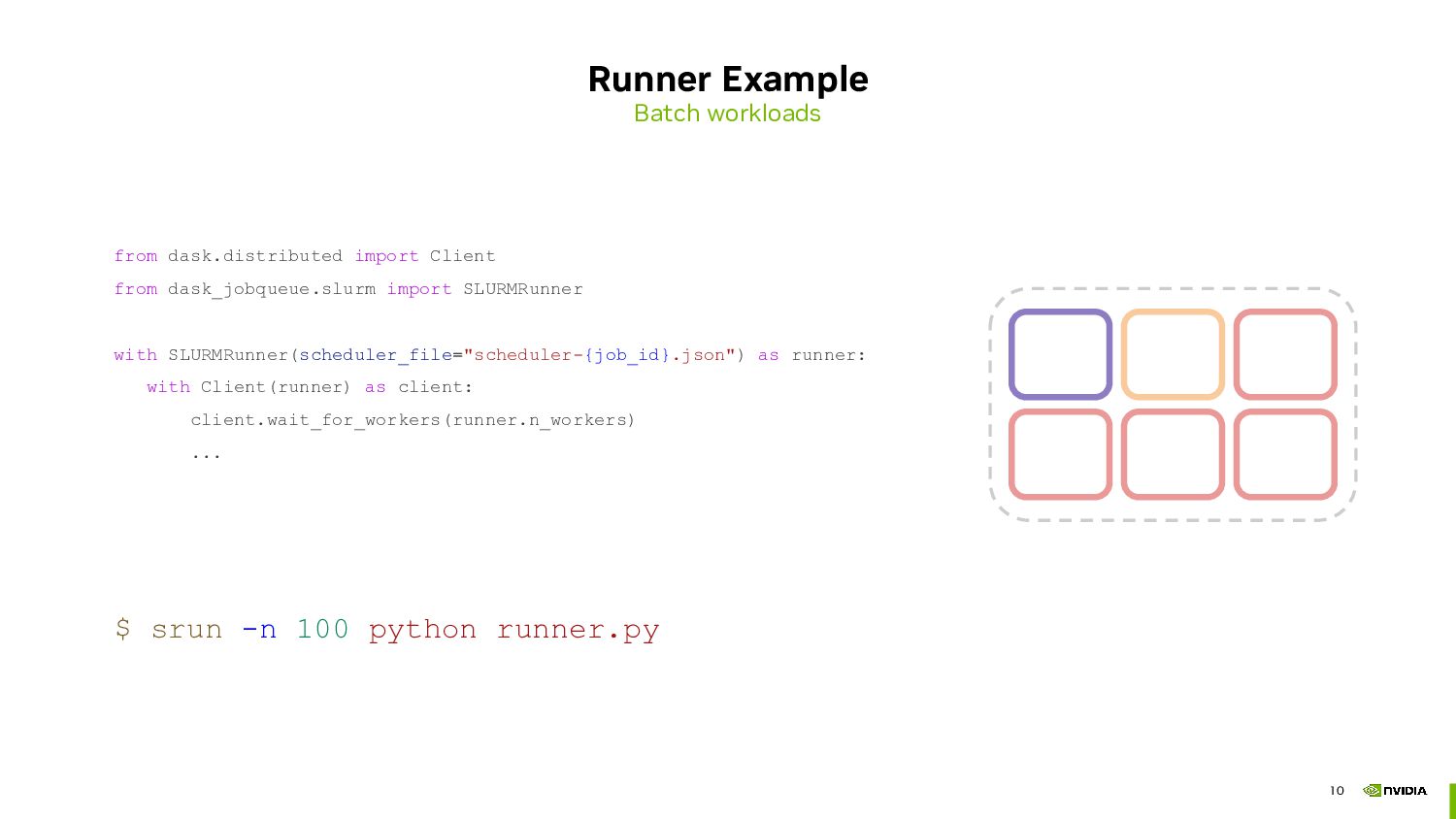
Next, we will dive into using runners that leverage parallel execution environments such as MPI or job schedulers like SLURM to bootstrap Dask clusters within a single large job allocation. Submitting a single job offers some benefits (aside from the fact that HPC administrators often prefer this approach), including better node locality, as the scheduler places processes on nodes that are physically closer together. This results in more efficient communication and reduced latency. Additionally, launching all workers simultaneously ensures balanced data distribution across the cluster.
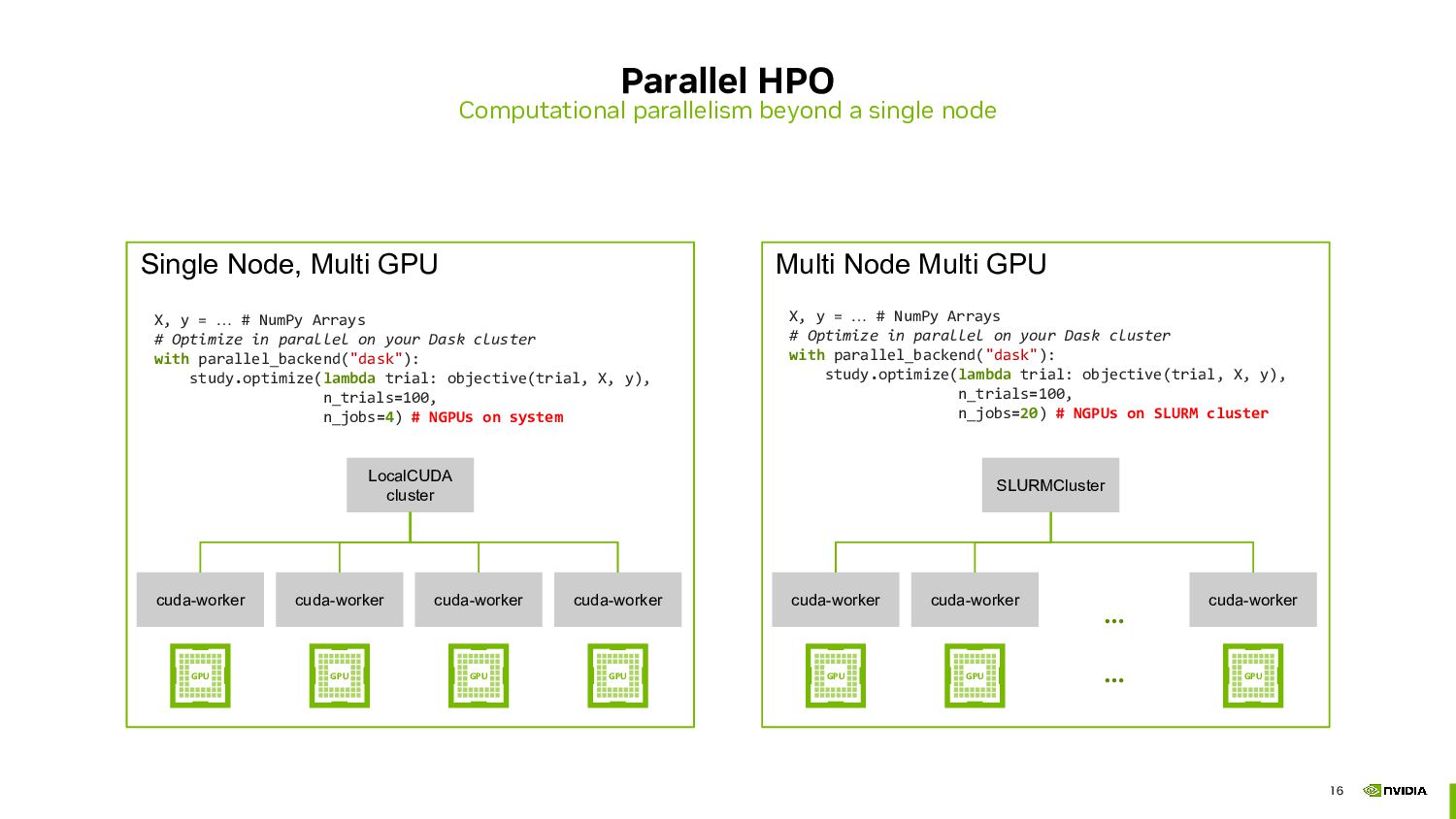
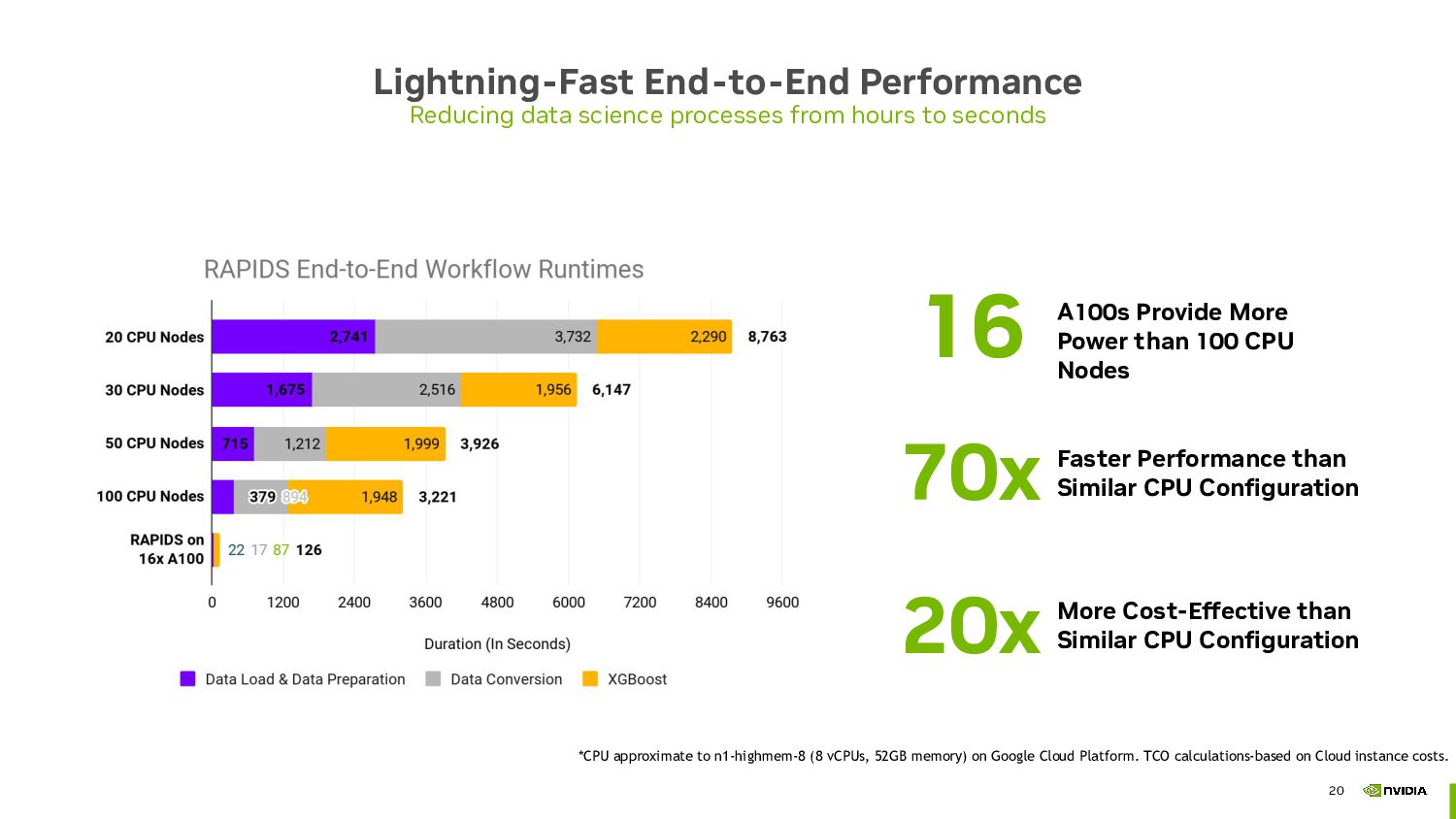
The session will then shift focus to the accelerated side of Dask, demonstrating how to harness the power of GPUs to significantly boost computation speed. We will introduce Dask CUDA, part of RAPIDS, a suite of open-source libraries designed to execute end-to-end data science and analytics pipelines entirely on GPUs. By integrating Dask CUDA, users can achieve unprecedented levels of performance, particularly for data-intensive tasks such as machine learning and data preprocessing.
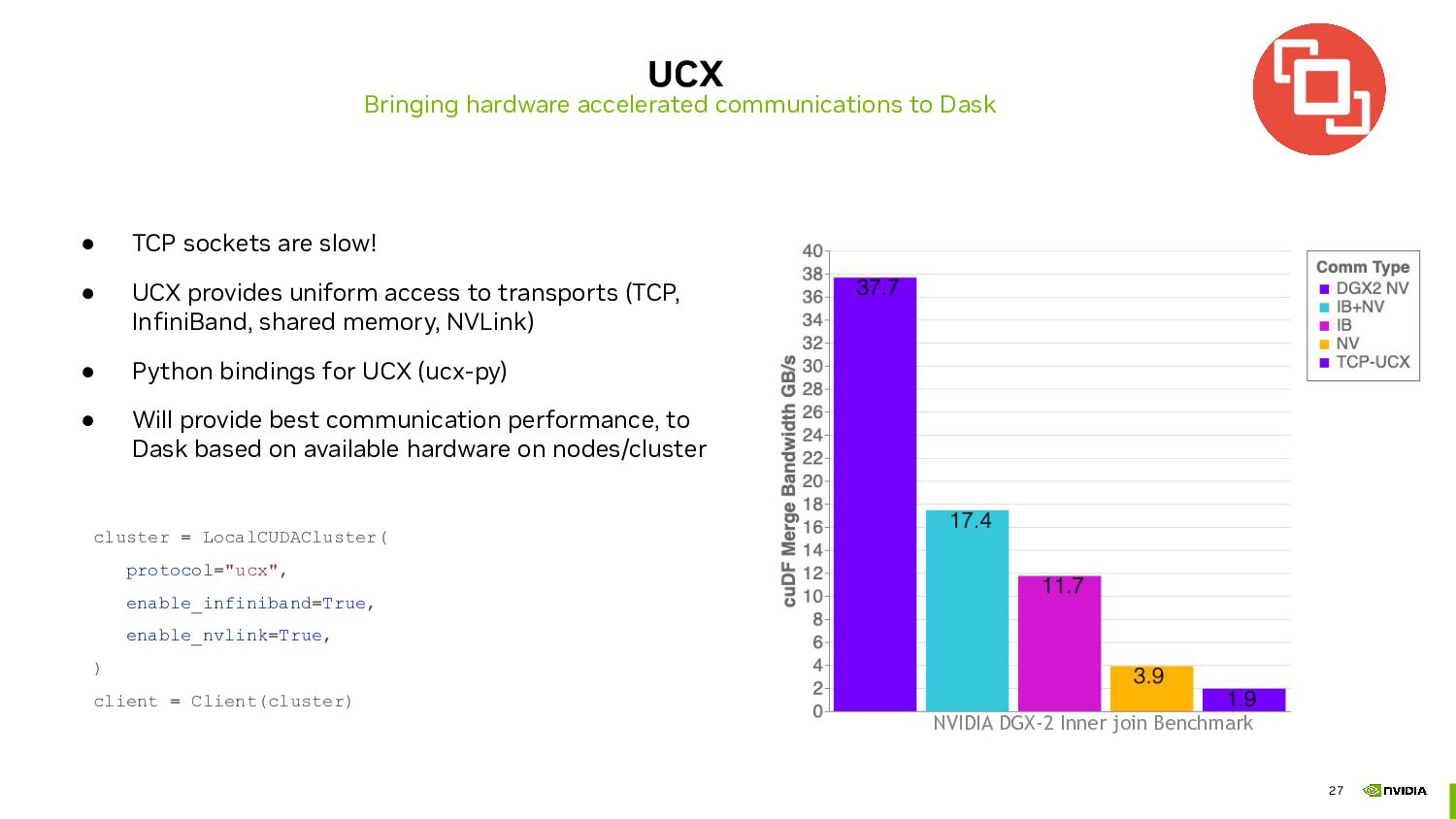
We will also explore the advantages of using UCX (Unified Communication X) to enhance Dask's performance on HPC systems with advanced networking technologies. UCX provides a high-performance communication layer that supports various network transports, including Infiniband and NVLink. By leveraging these accelerated networking options, users can achieve lower latency and higher bandwidth, resulting in faster data transfers between Dask workers and more efficient parallel computations.
Outline:
- Overview of Dask
- Scaling out Pandas and NumPy
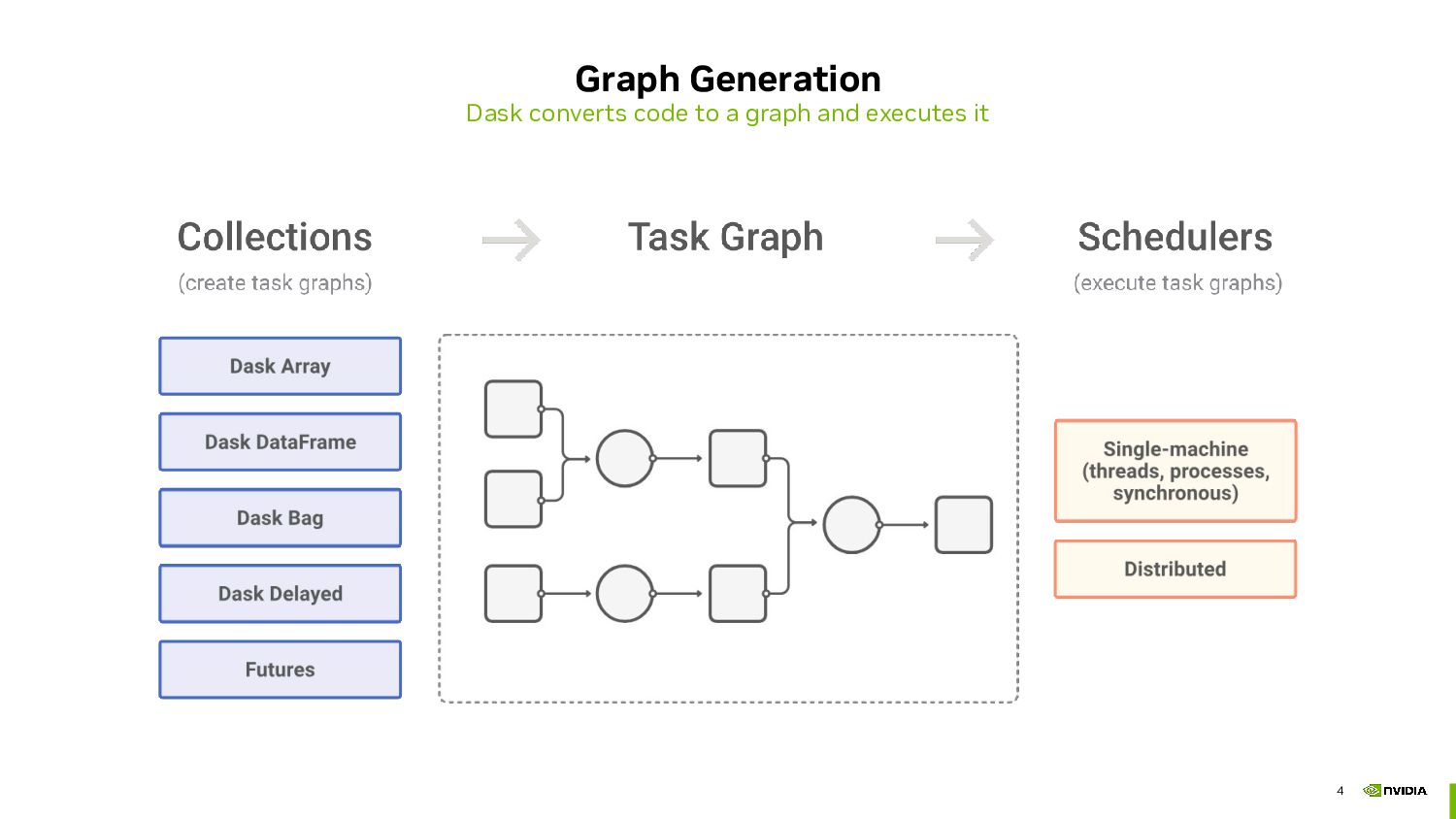
- Custom parallel code
- Workflow engines
- Machine learning and AI applications
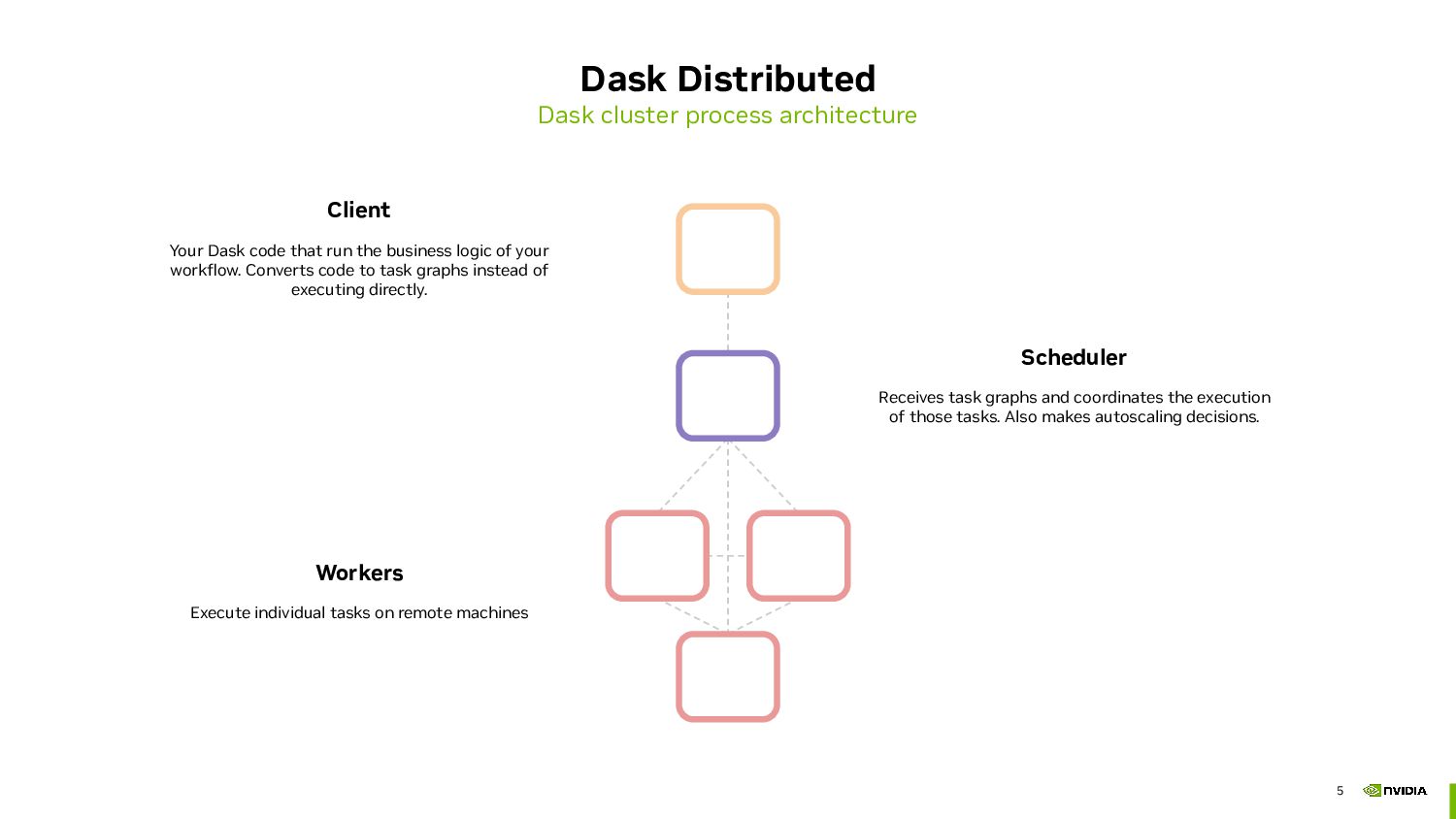
- Deploying Dask on HPC
- Adaptive clusters
- Fixed size runners
- Accelerating Dask on HPC
- RAPIDS and Dask CUDA
- UCX
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}