the Python process contains the cluster manager, which contains the only references to the resources created. This makes sense if the scheduler and workers are subprocesses on the same machine. But less so when they are remote and independent resources on a cloud or HPC platform. Python Process Remote Cluster resources
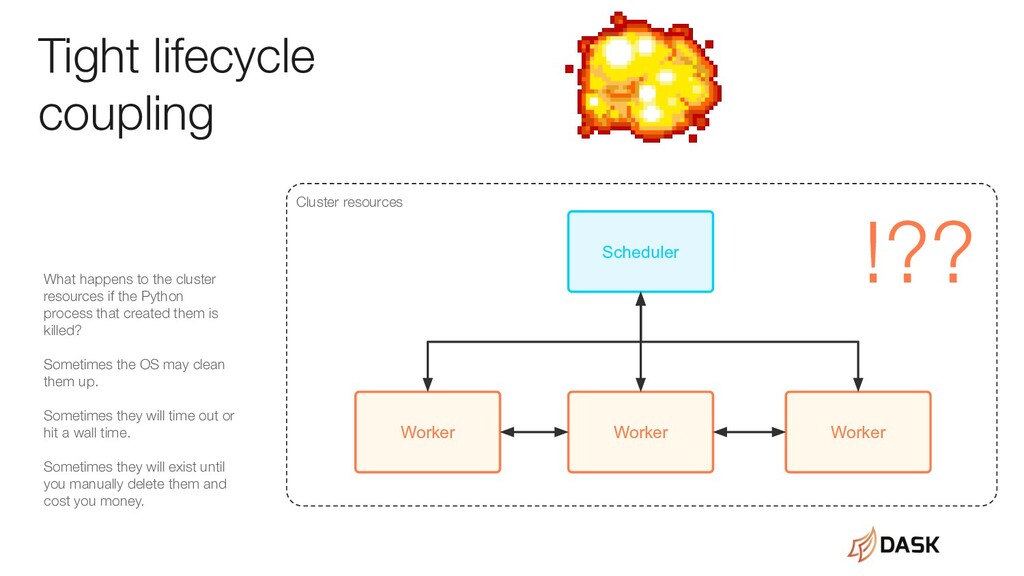
the cluster resources if the Python process that created them is killed? Sometimes the OS may clean them up. Sometimes they will time out or hit a wall time. Sometimes they will exist until you manually delete them and cost you money. Cluster resources !??
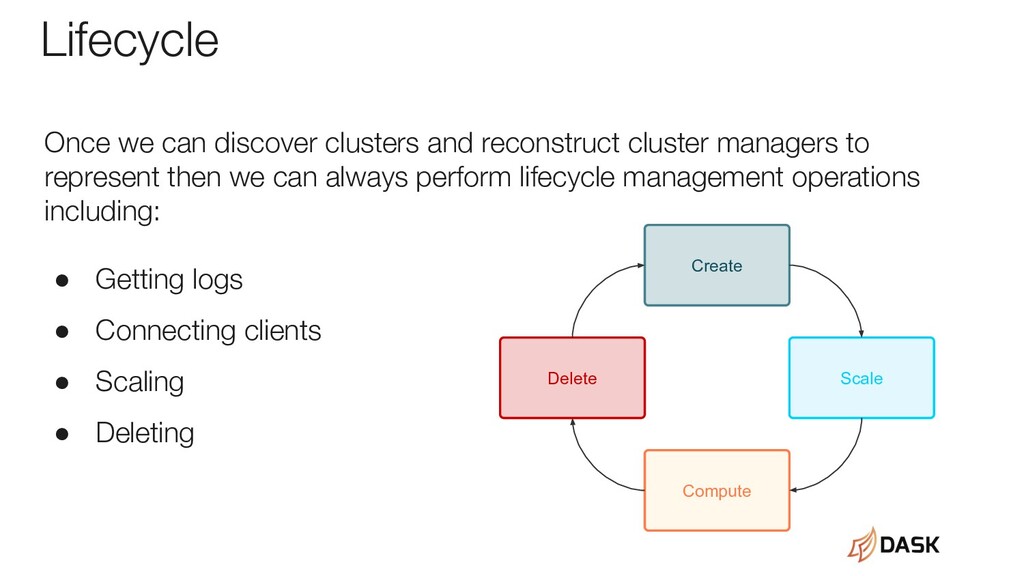
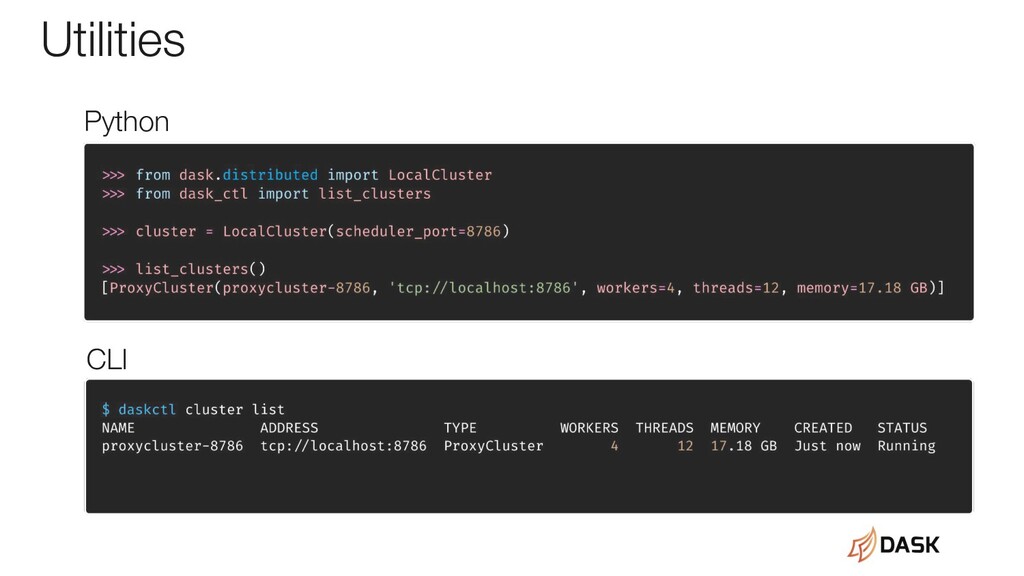
able to discover existing clusters and then reconstruct the cluster manager which represents them. With dask-ctl cluster managers can register a discovery method via the dask_cluster_discovery entrypoint. To support dask-ctl cluster managers should implement this entrypoint and search for clusters (by listing jobs/pods/vm/etc looking for Dask cluster resources) and then return an iterable of cluster names and cluster managers which can recreate them.
need to have a way of reconstructing the representation by the clusters name/uuid. In dask-ctl we try to call a ClusterManager.from_name(name/uuid) class method to reconstruct the cluster object. To support dask-ctl cluster managers also need to implement this method.
managers as possible. • Add support for cluster discovery to the Dask Jupyter Lab Extension so that discovered clusters are listed in the sidebar. • Stabilize things and move from dask-contrib org to dask.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}