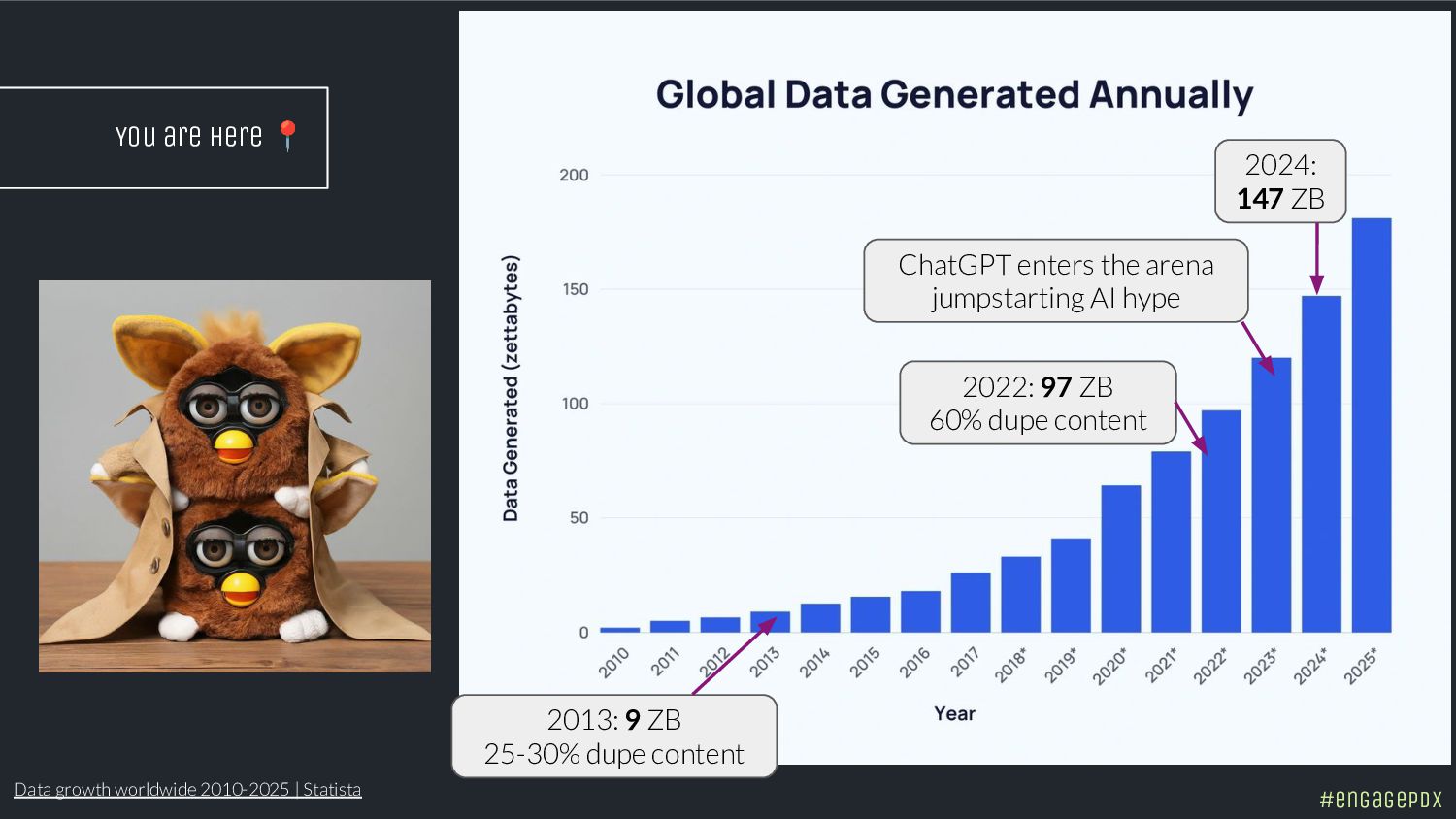
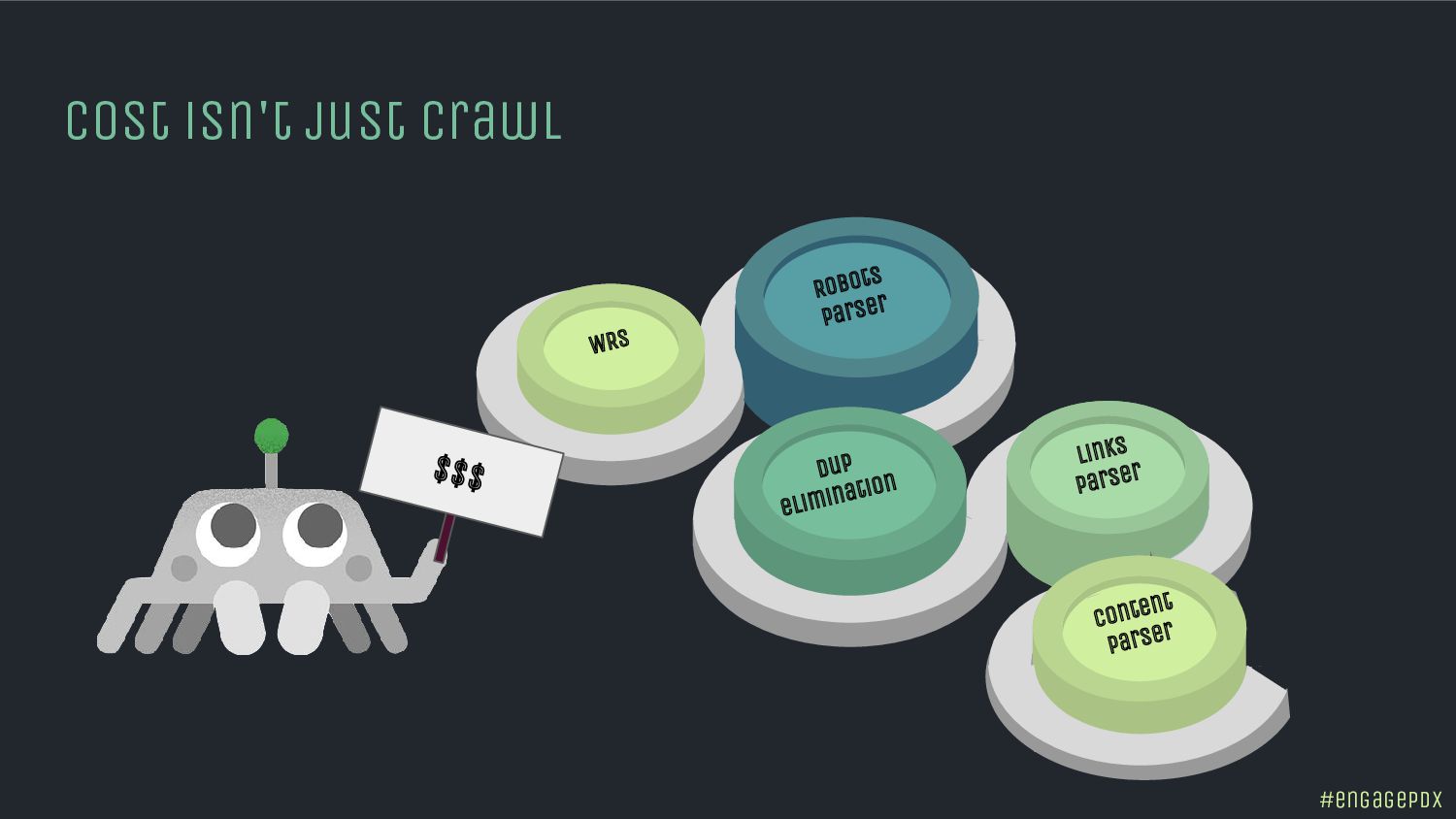
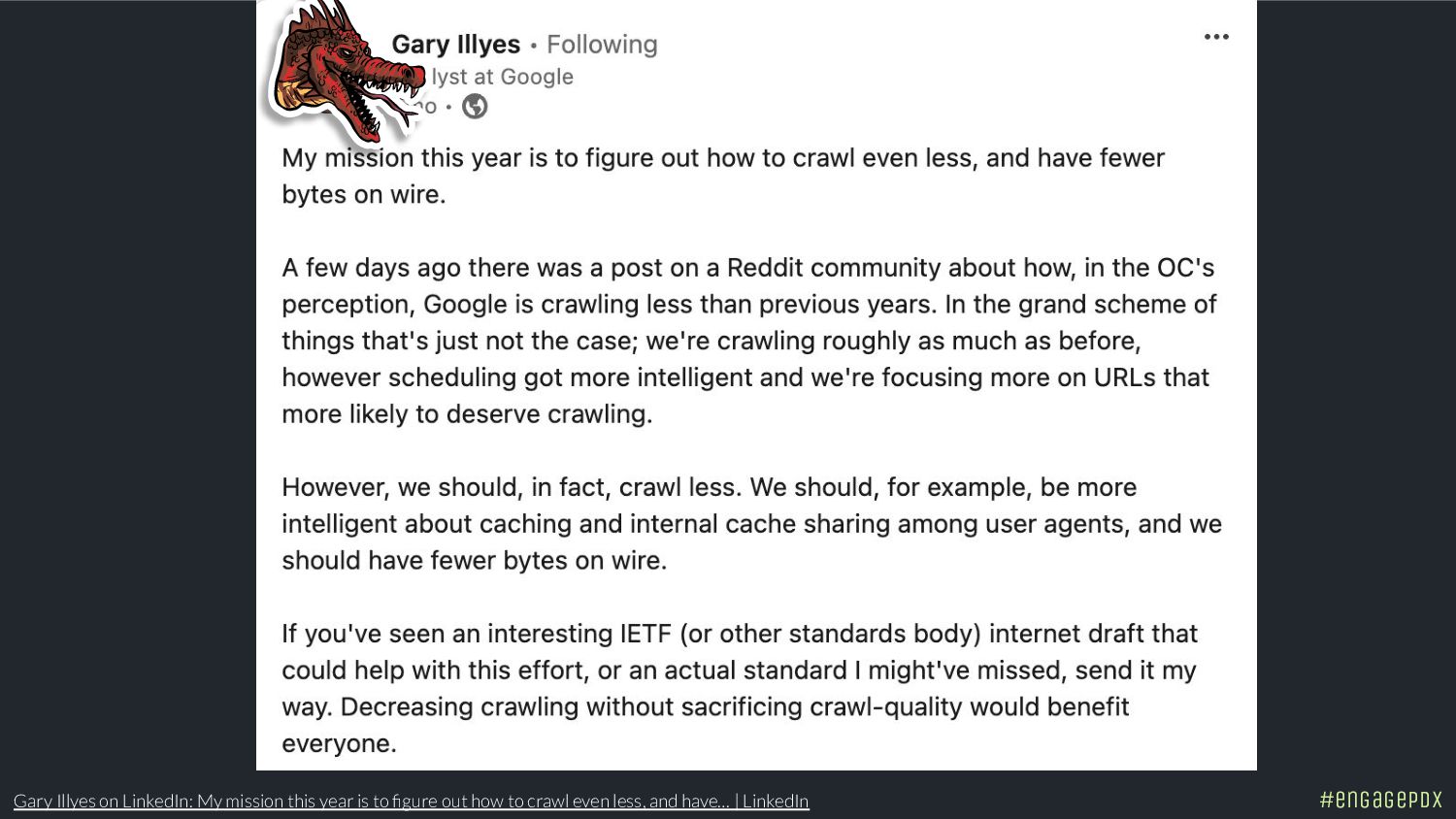
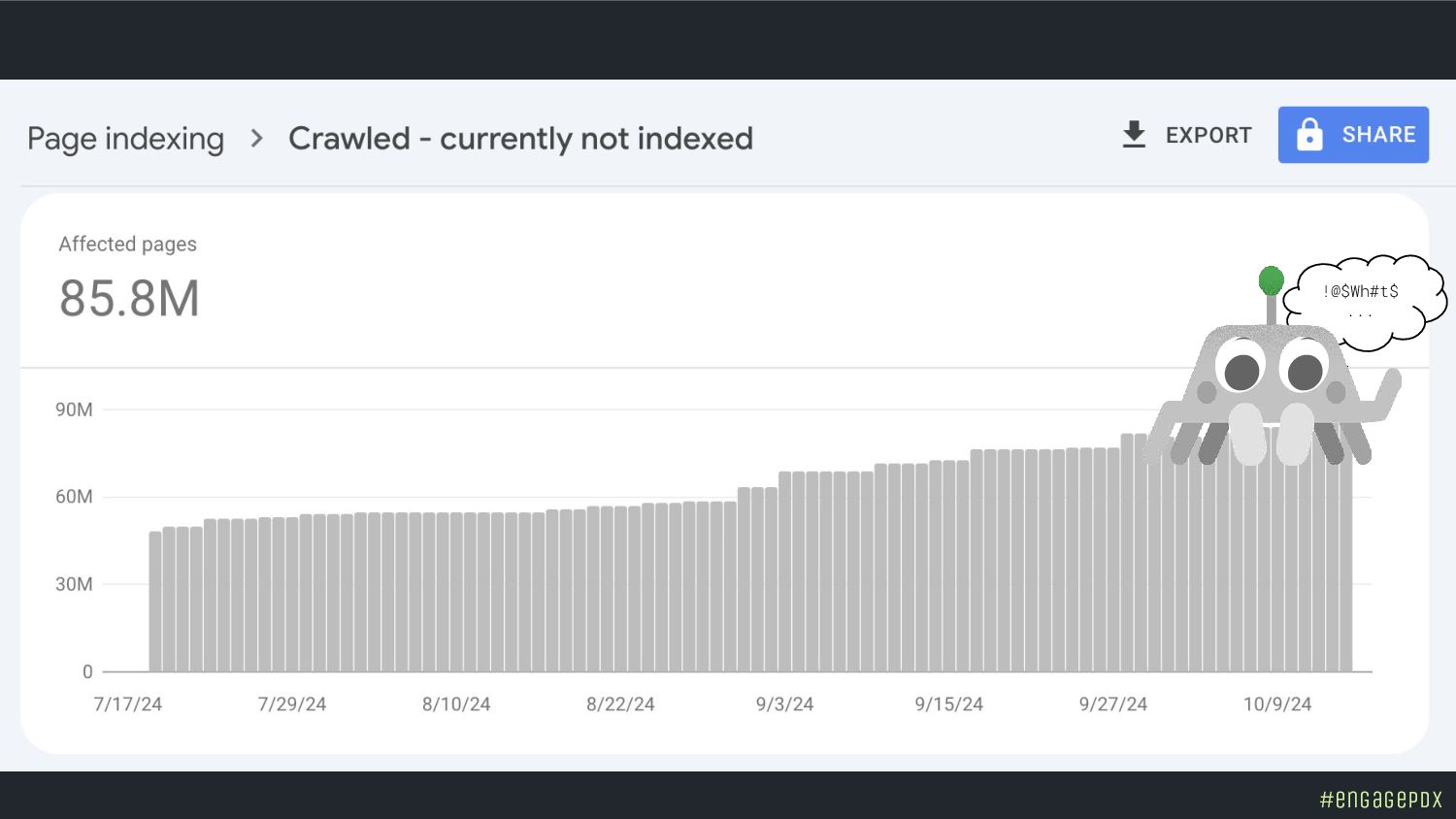
In 2022, Googler Gary Illyes said 60% of the web is duplicate content. The next year, Bing discovered 70 billion new pages daily. That was before generative AI exploded. The latest studies estimate that 400 million terabytes of content are created daily. Now Google wants to crawl less. Getting indexed is the new boss fight and ChatGPT isn't going to save you.
Join Jamie Indigo, Director of Technical SEO for Cox Automotive, for this session where she'll share actionable strategies to help you ensure your pages will be crawled by Google and avoid traps that will negatively affect your ranking.
After this session, you'll be able to:
- Understand Google's new crawl priorities
- Know what makes your site worth a search engine's investment
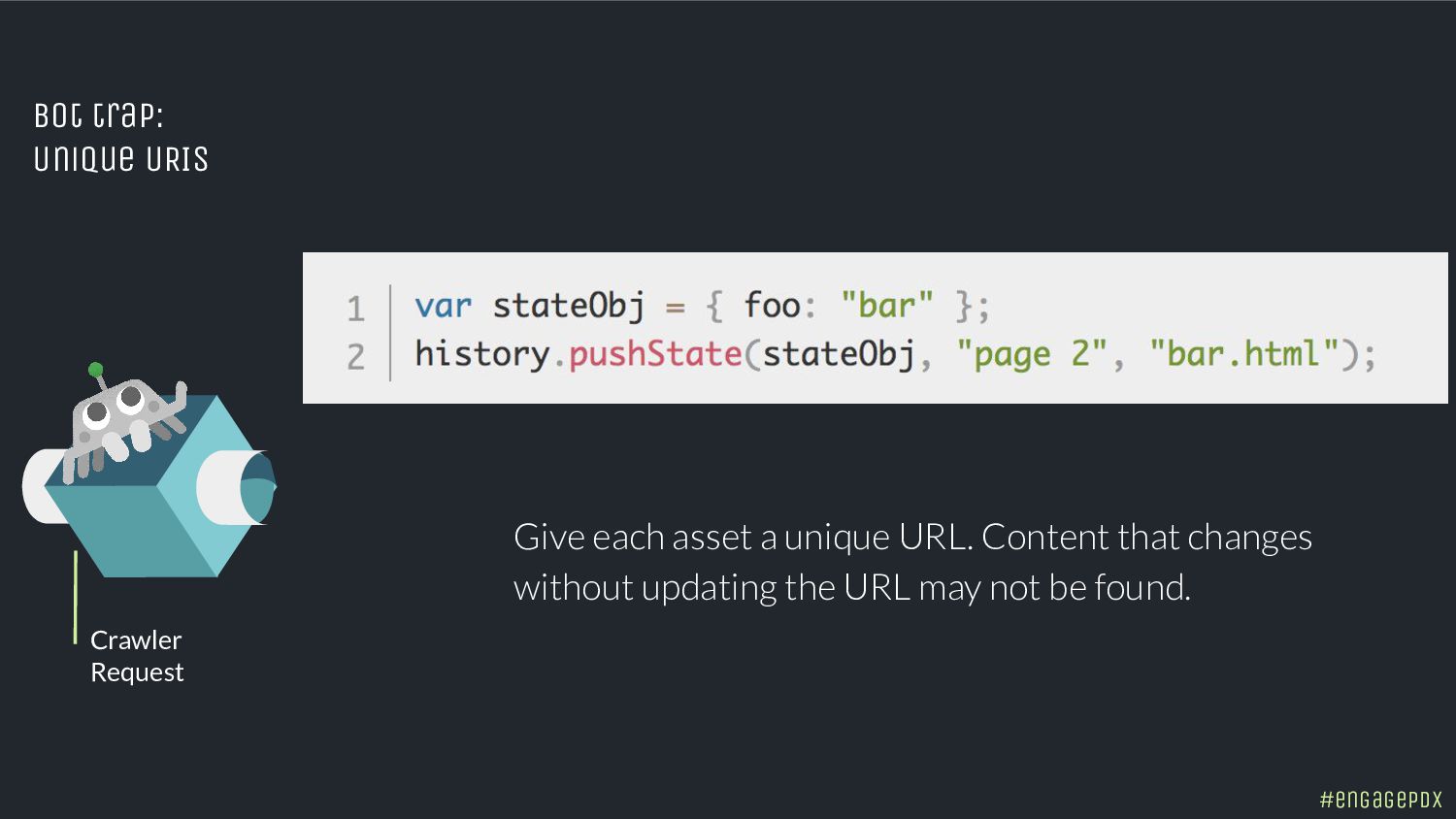
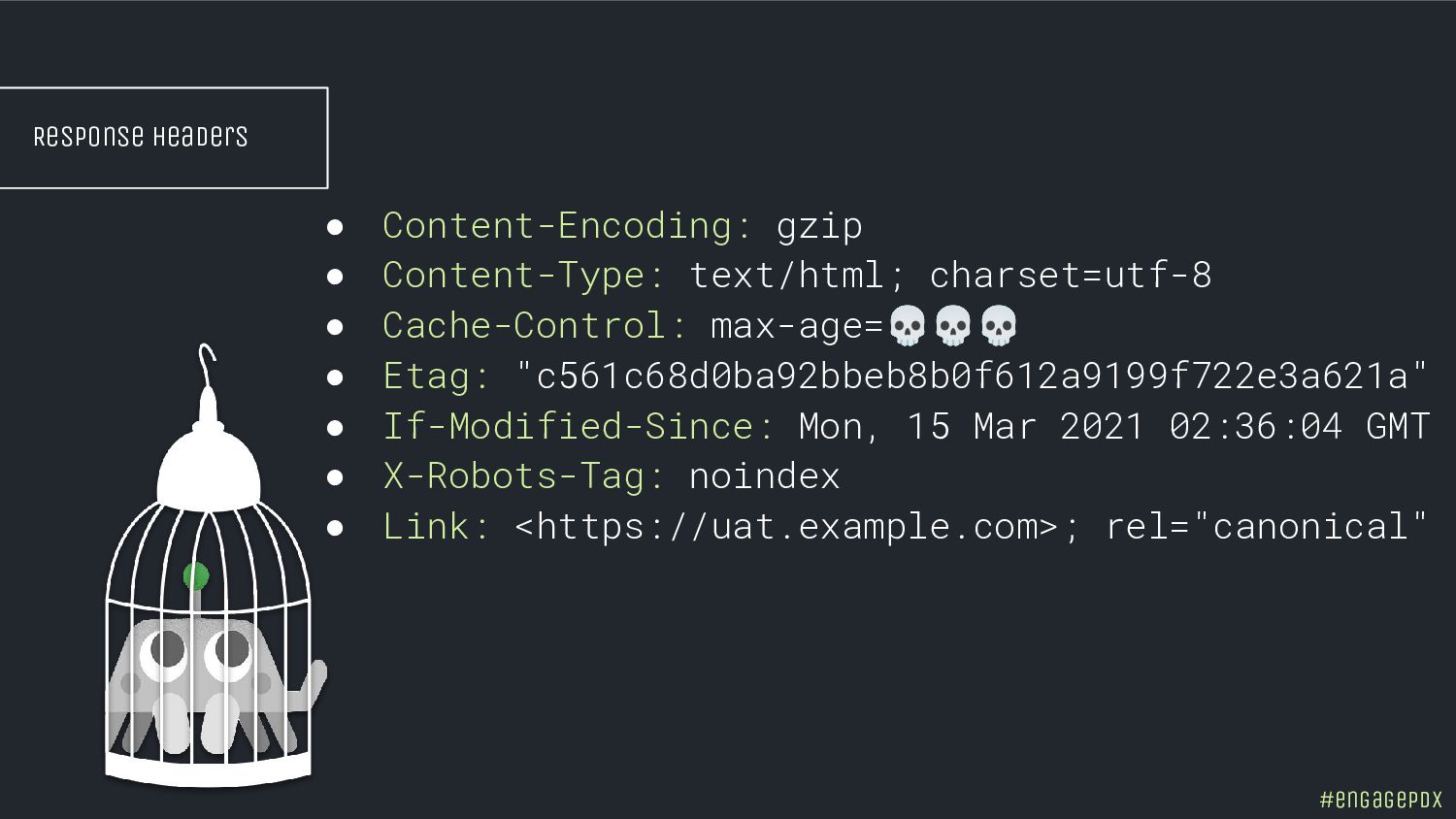
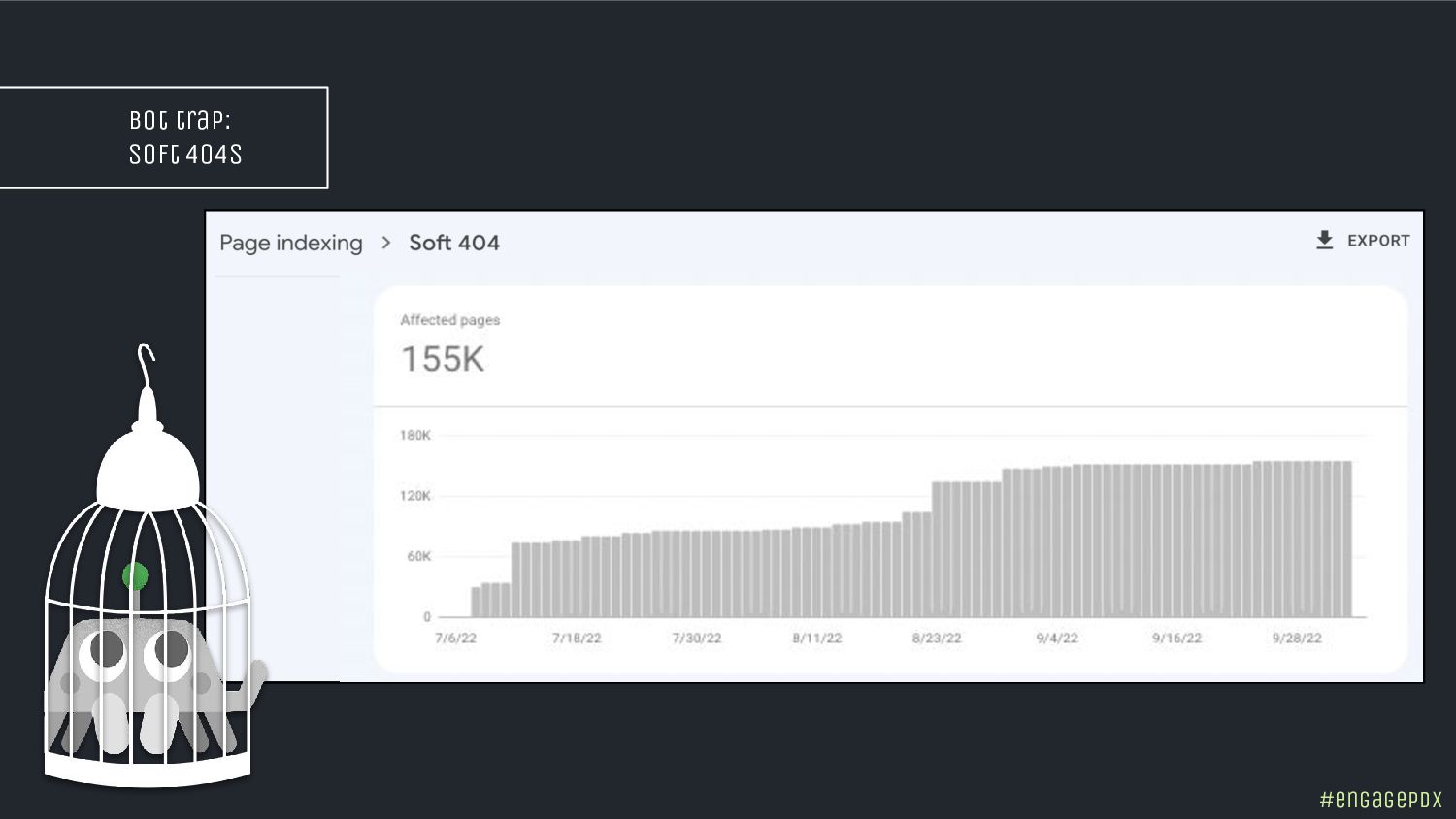
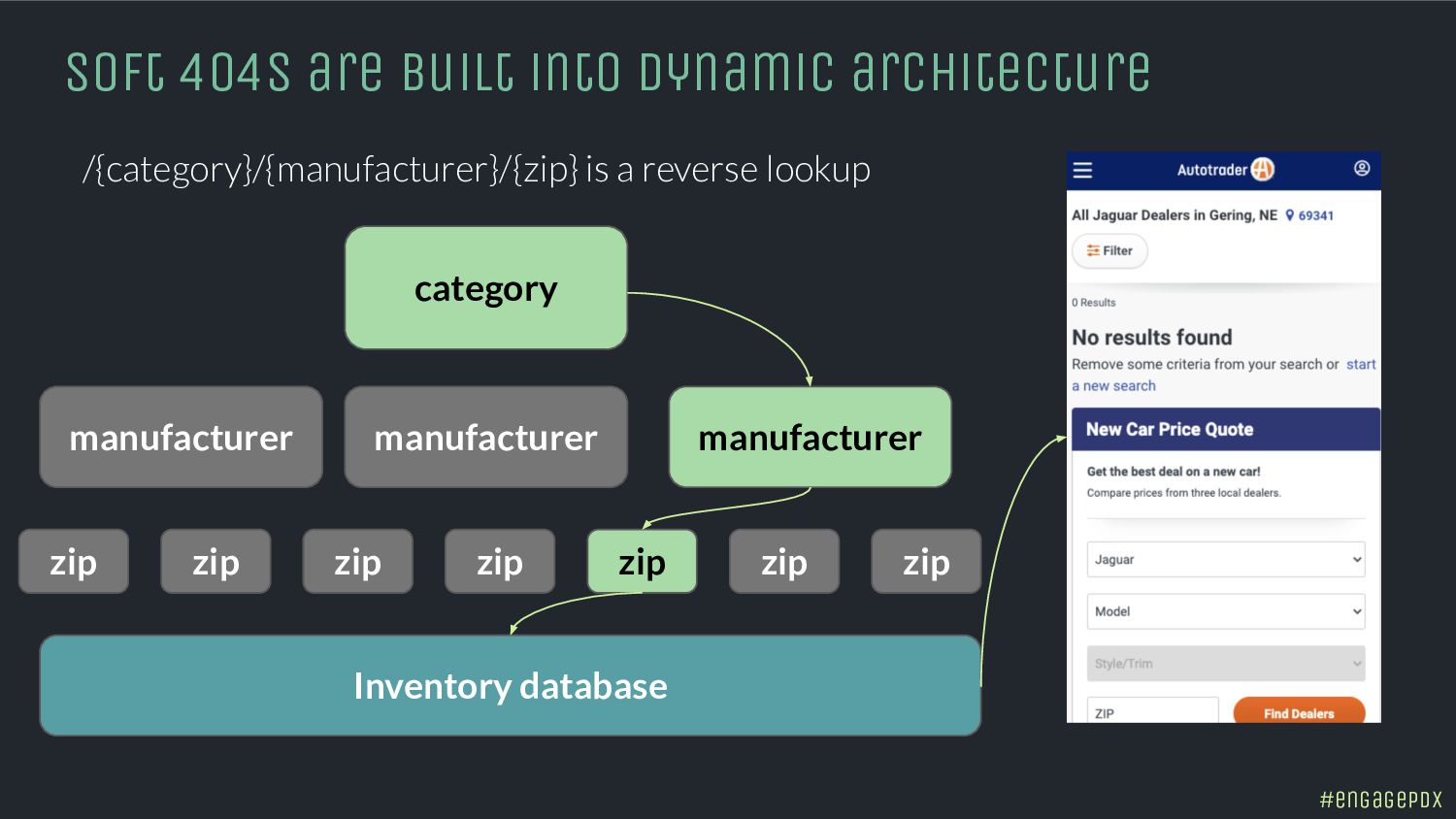
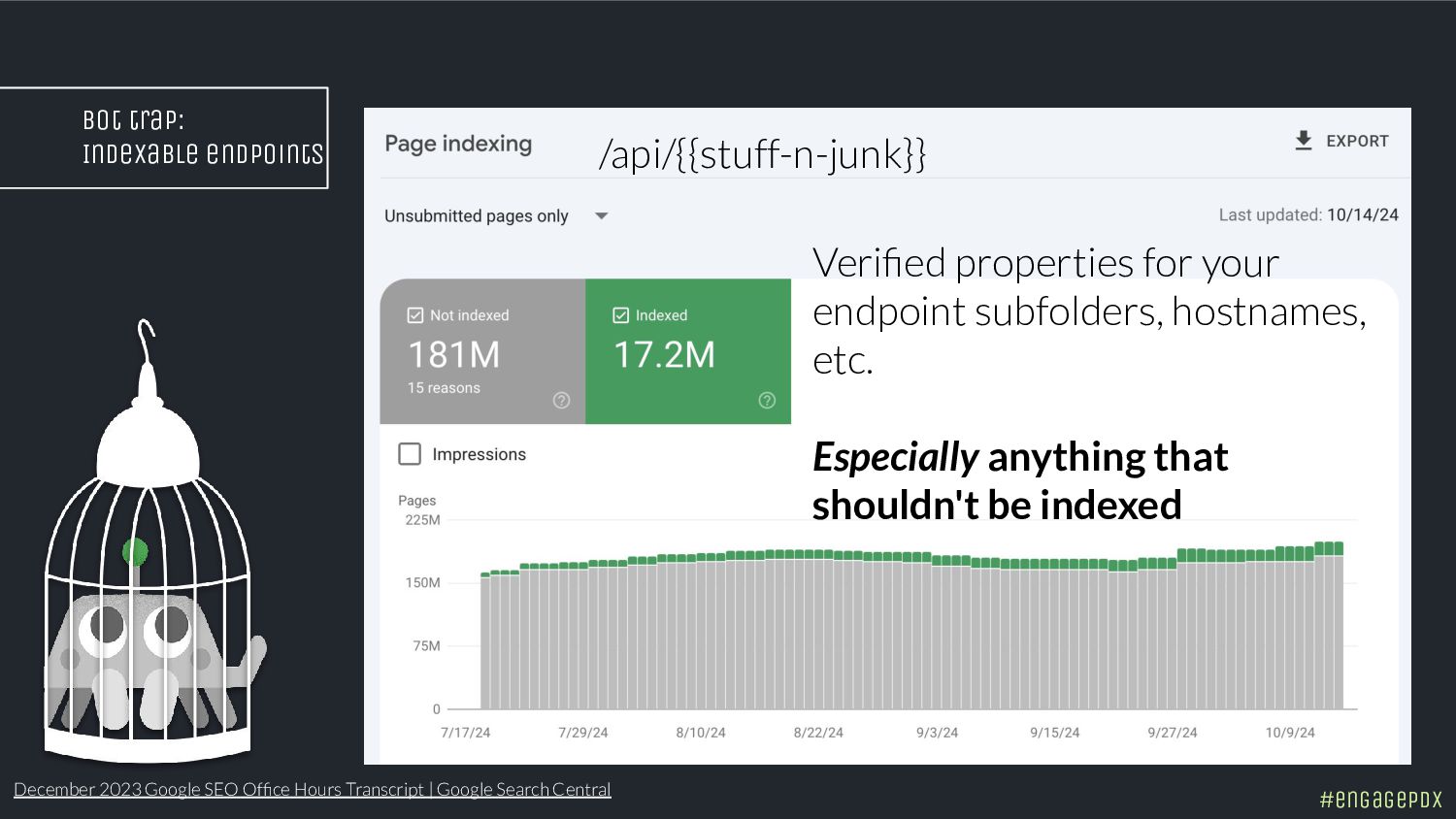
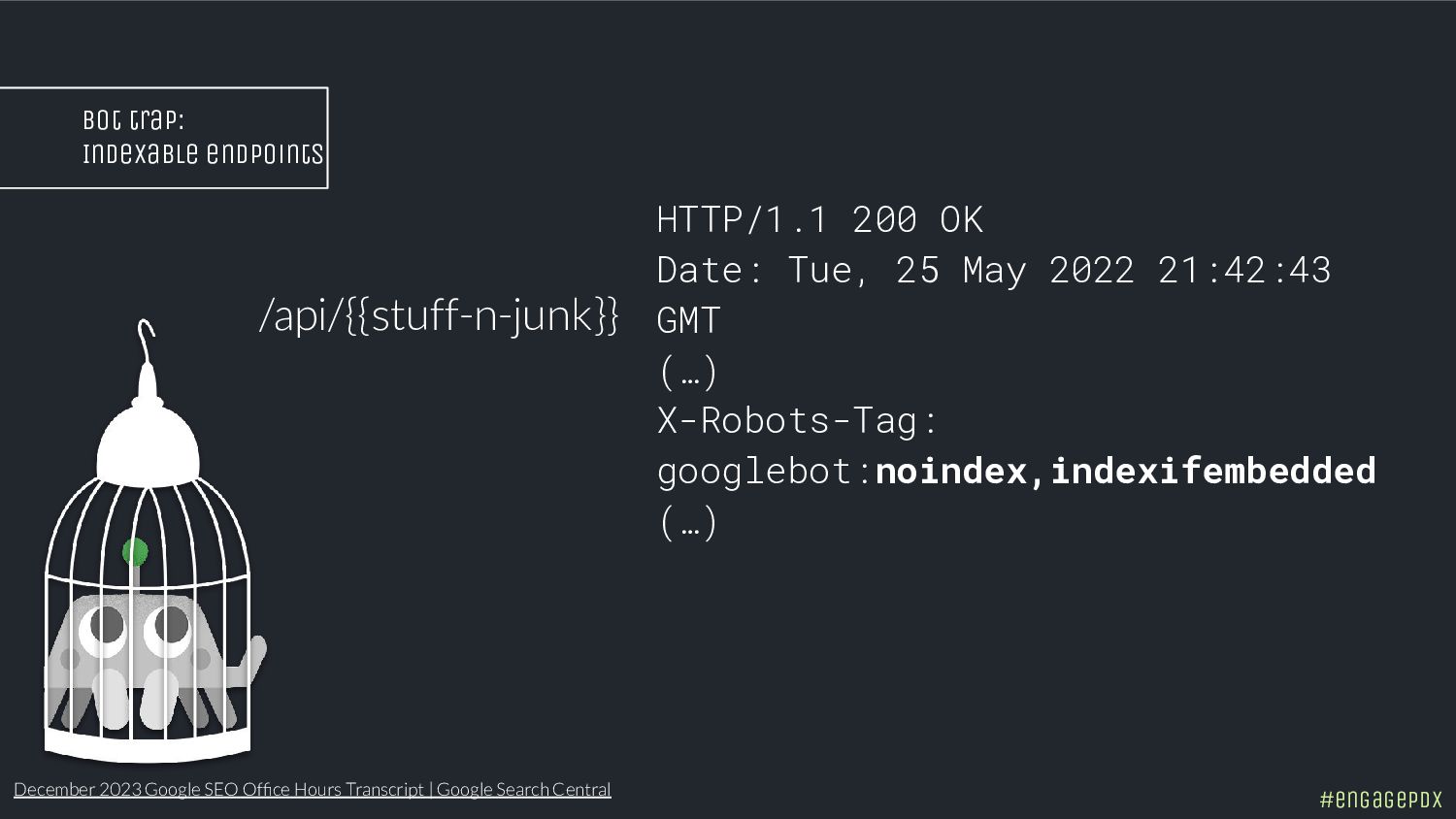
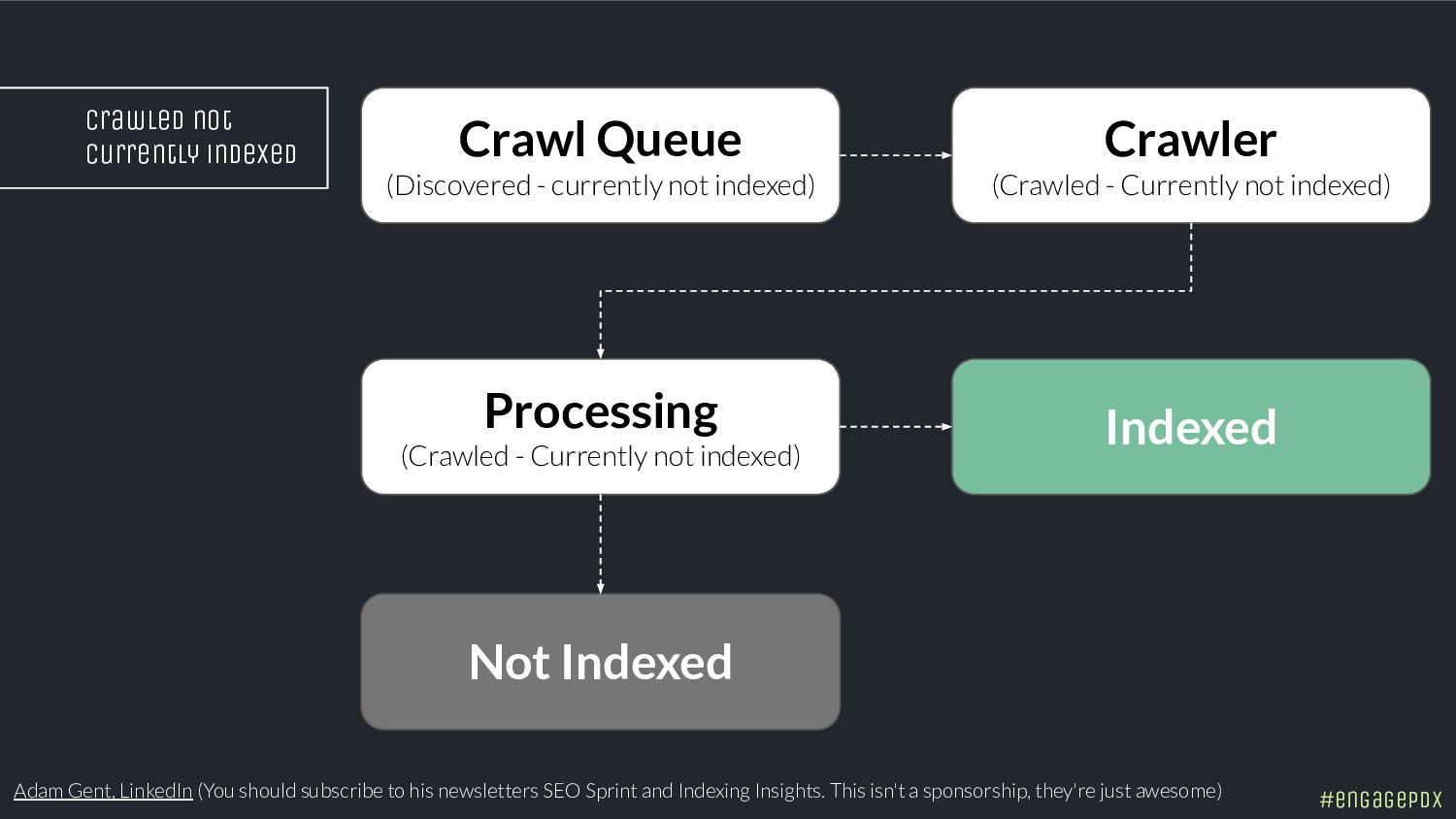
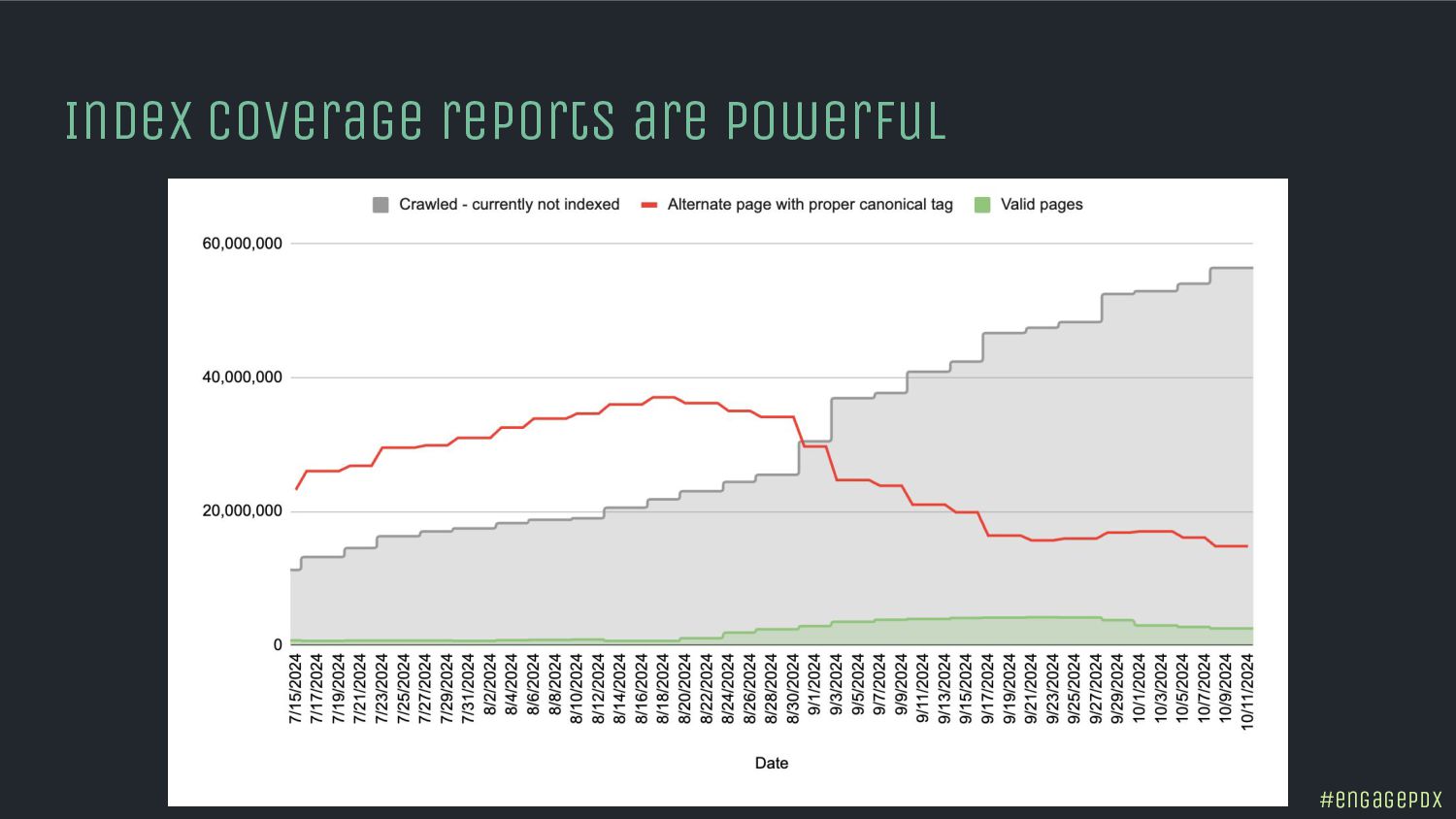
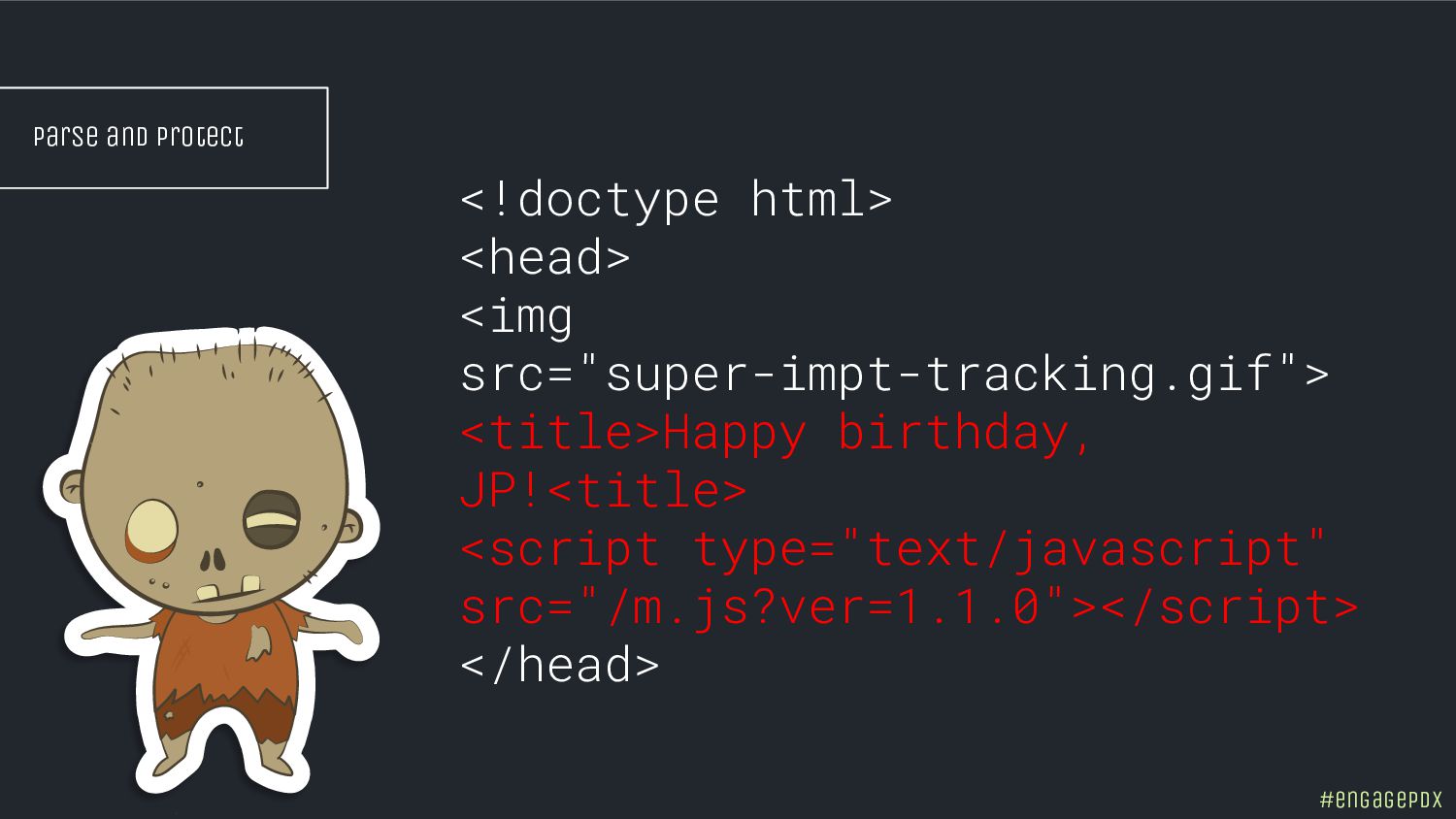
- Spot hidden indexing traps and crawling perils
- Control the configurations to curate your index
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}