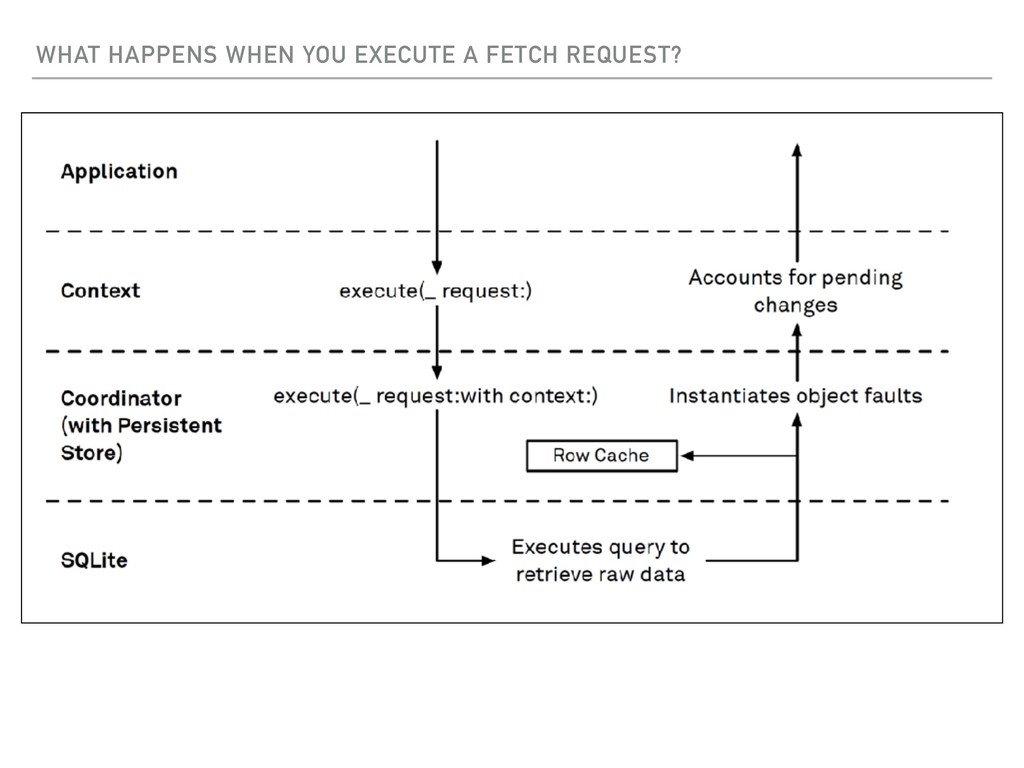
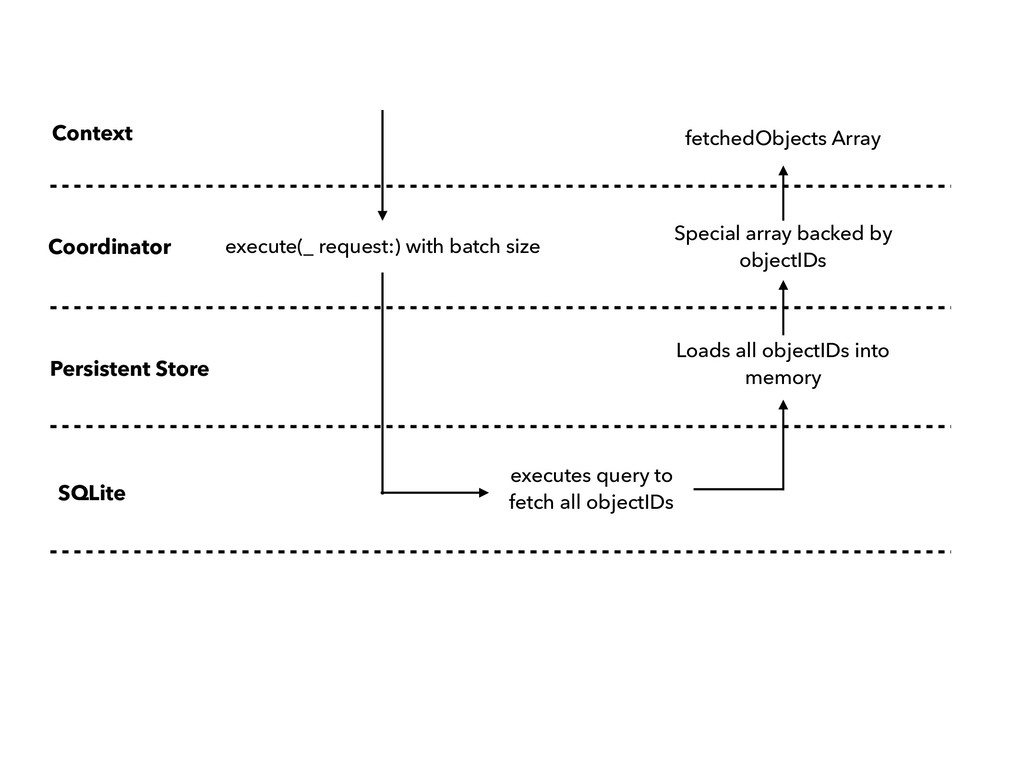
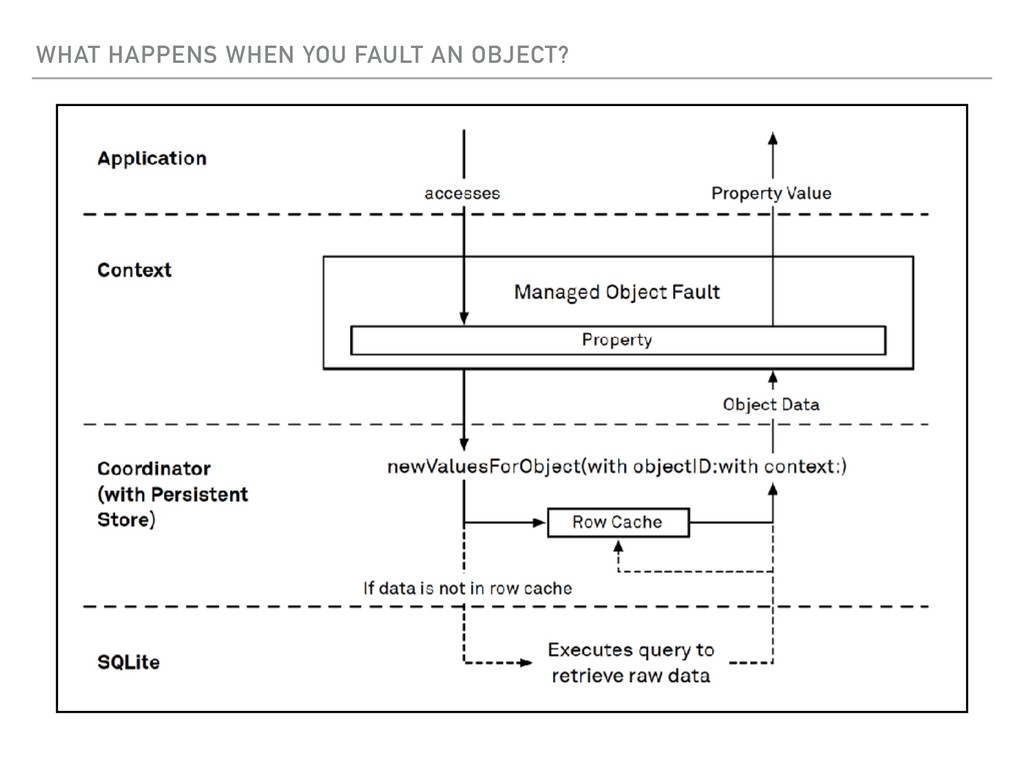
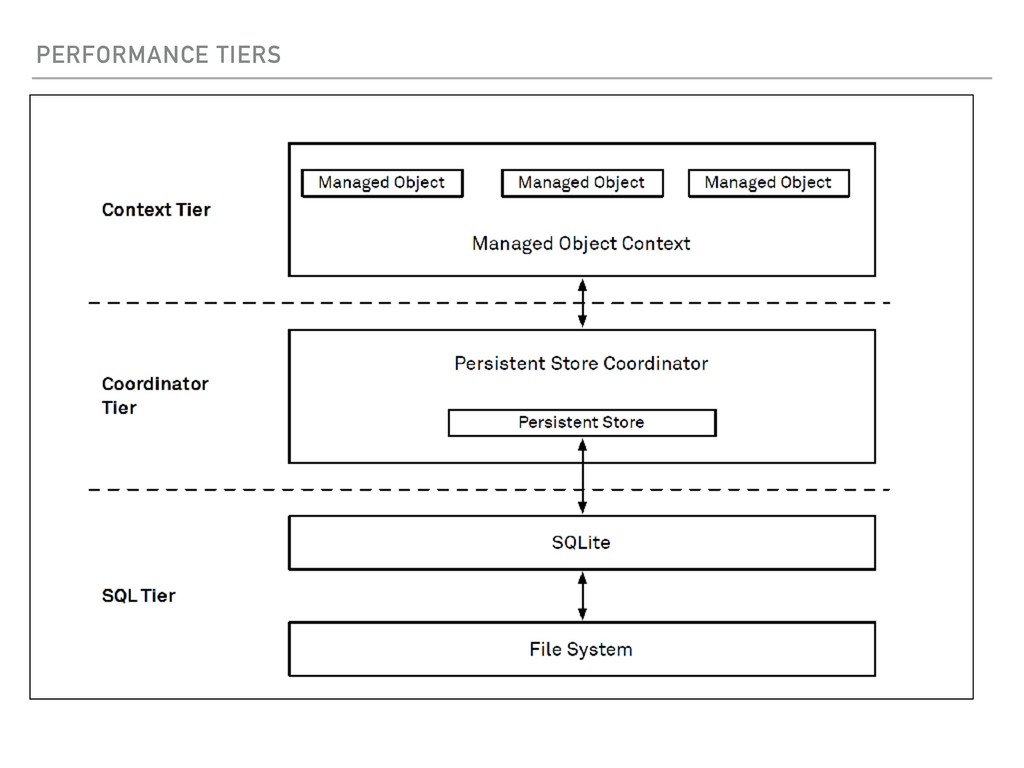
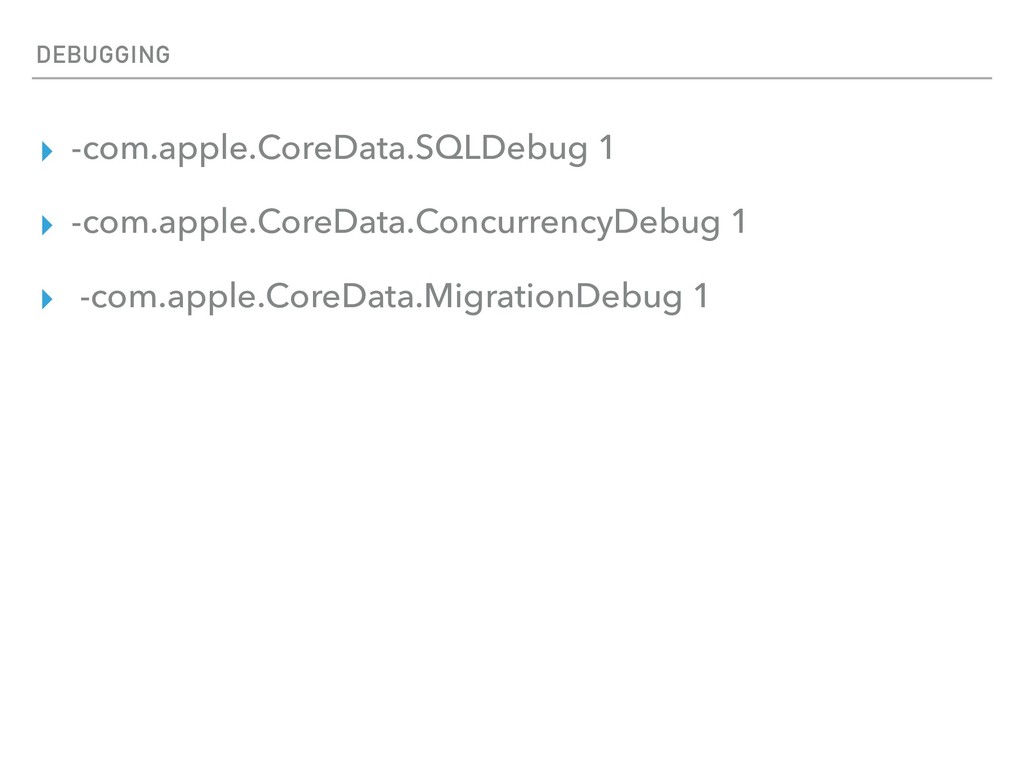
Request work? ▸ How does Fetch Batch Size work? ▸ How does a Fetch Batch Request work? ▸ What happens when you ‘Fault’ an object? ▸ Extra Special - Relationship faults ▸ Performance characteristics of Core Data ▸ Tips for High Performance with Core Data
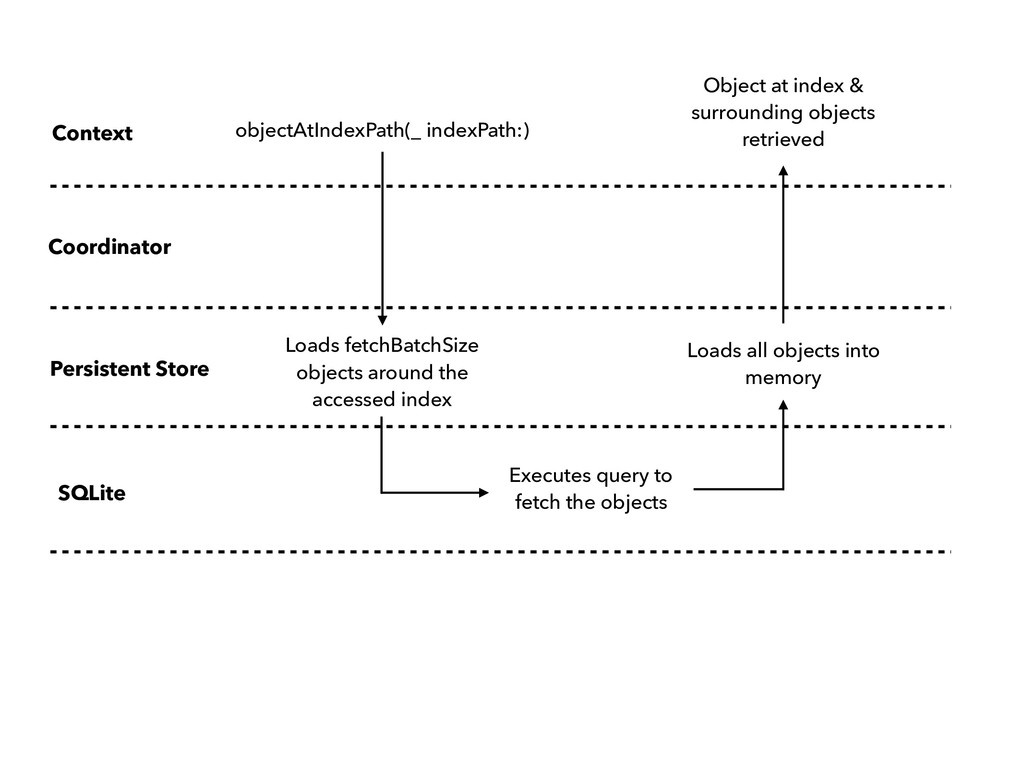
objects Loads all objects into memory Object at index & surrounding objects retrieved objectAtIndexPath(_ indexPath:) Loads fetchBatchSize objects around the accessed index
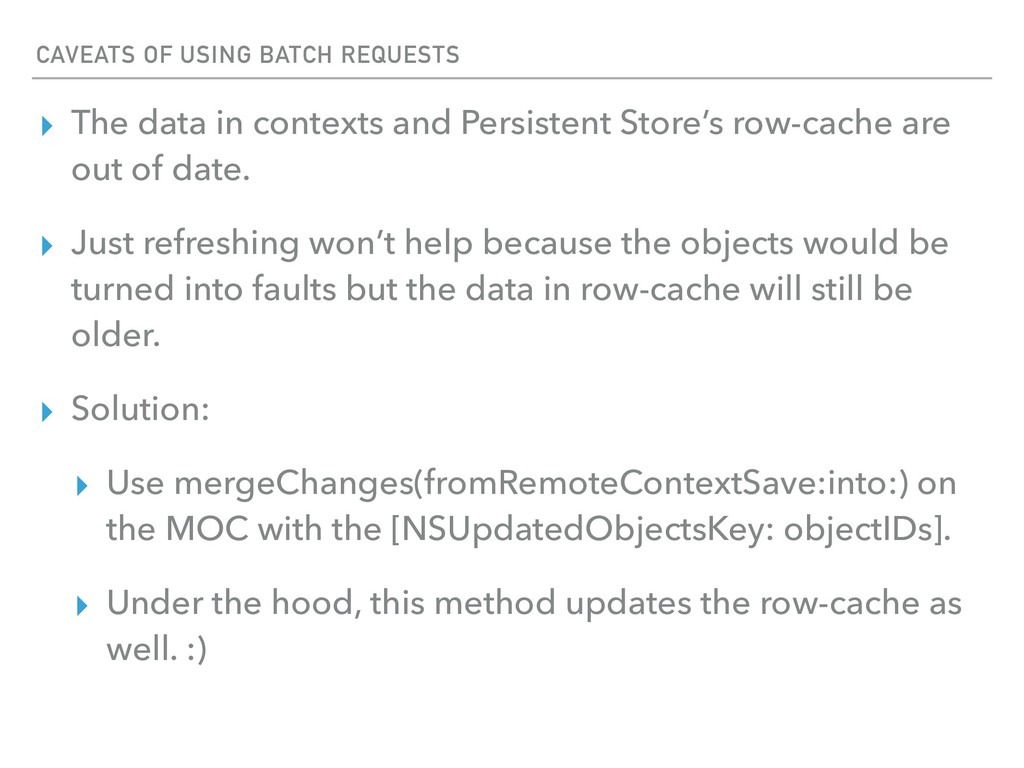
and Persistent Store’s row-cache are out of date. ▸ Just refreshing won’t help because the objects would be turned into faults but the data in row-cache will still be older. ▸ Solution: ▸ Use mergeChanges(fromRemoteContextSave:into:) on the MOC with the [NSUpdatedObjectsKey: objectIDs]. ▸ Under the hood, this method updates the row-cache as well. :)
relationships have objectIDs through which faults are fulfilled. ▸ To-many relationships work on two-level faulting. First when you access the relationship, the first level fault is fired and objectIDs for the relationship are loaded into the memory. ▸ Second-level faulting occurs like normal fault when any relationship object’s property is being accessed.
Use indexing and compound indexing. ▸ It’s okay to do de-normalization in order to make your UI faster. ▸ Put simpler and more performant predicates first as it reduces the sample set. ▸ Use batch requests. It’s a little difficult to get right but once you get a hang of it. It just works. :)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}