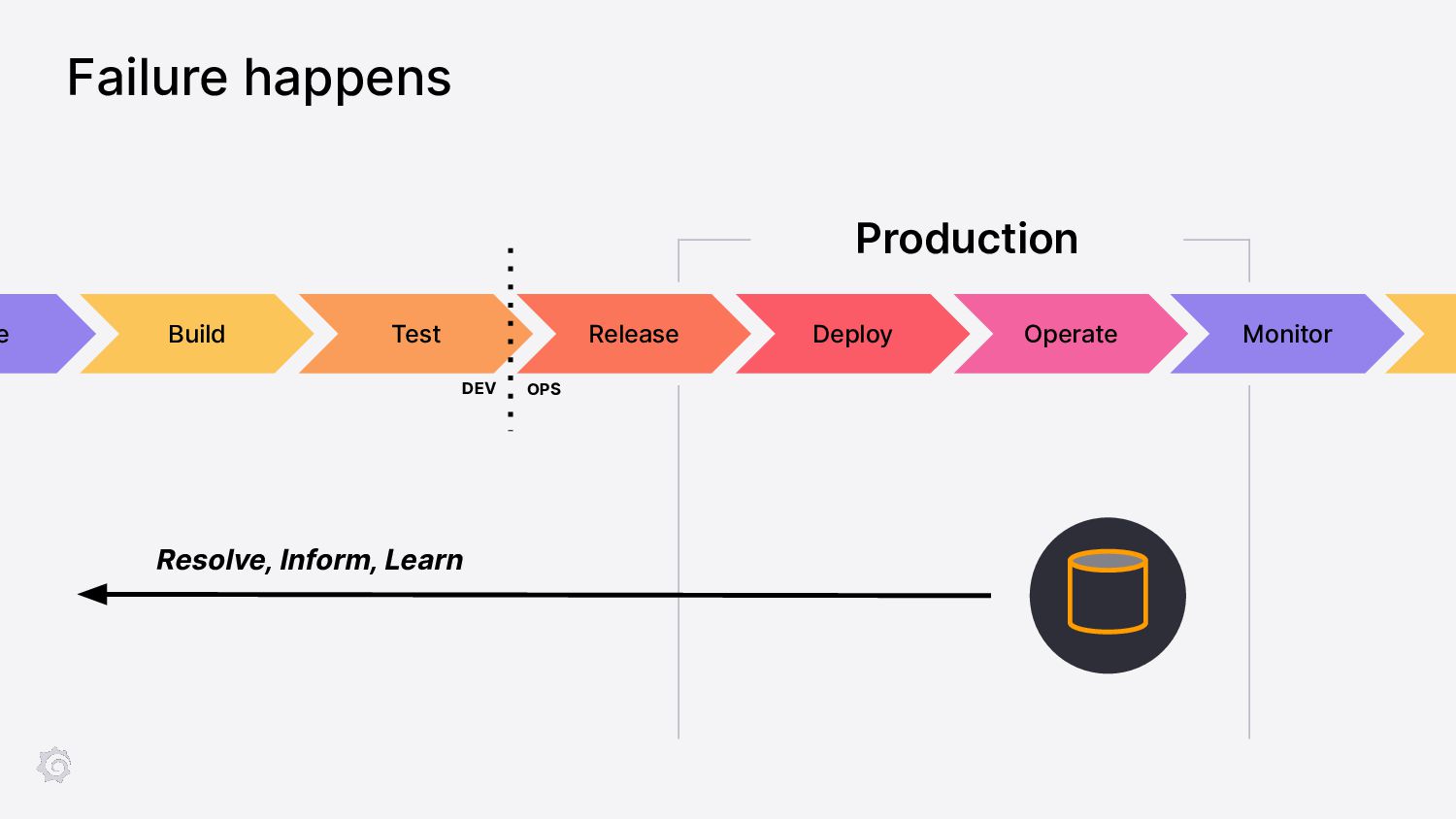
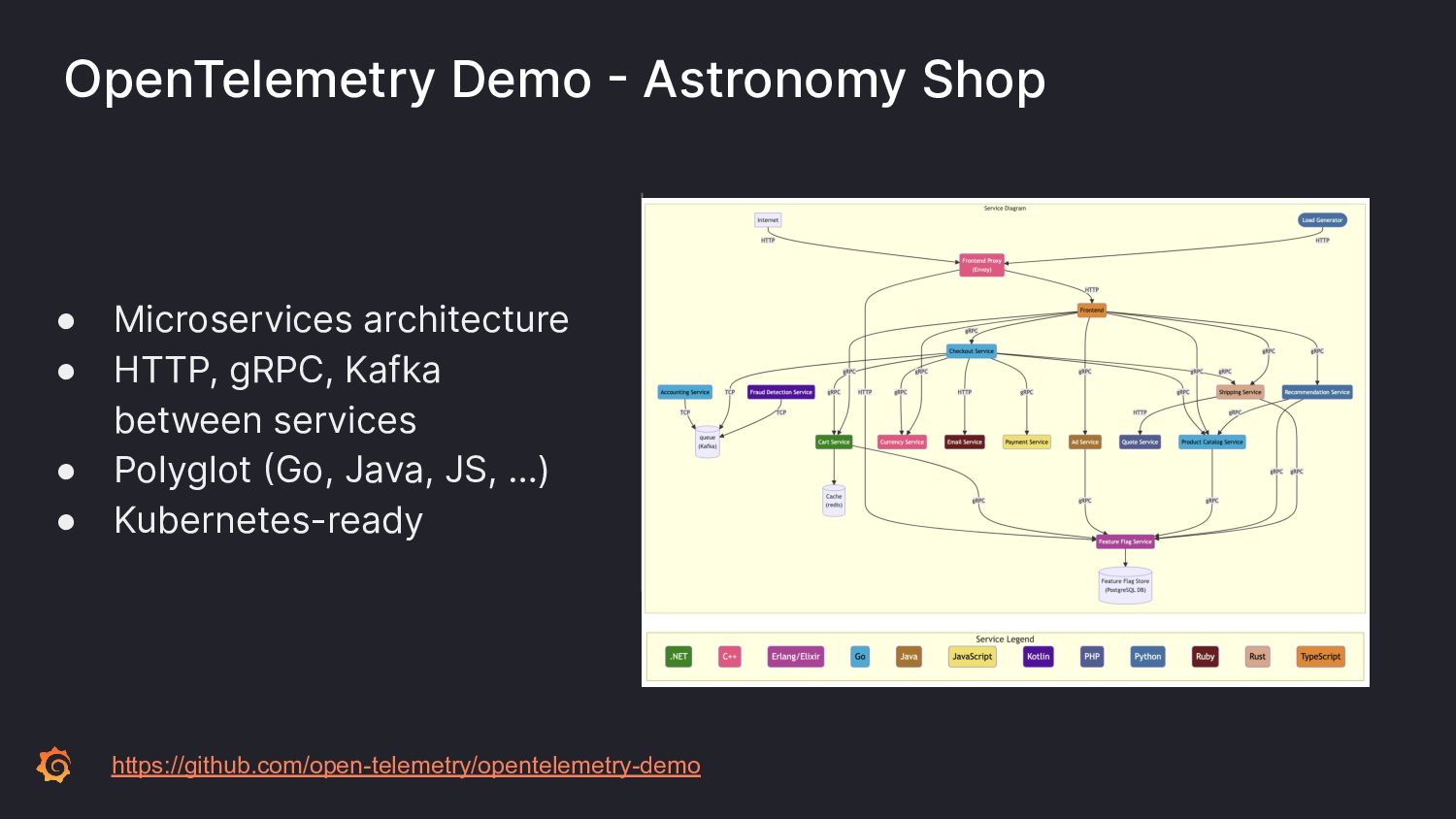
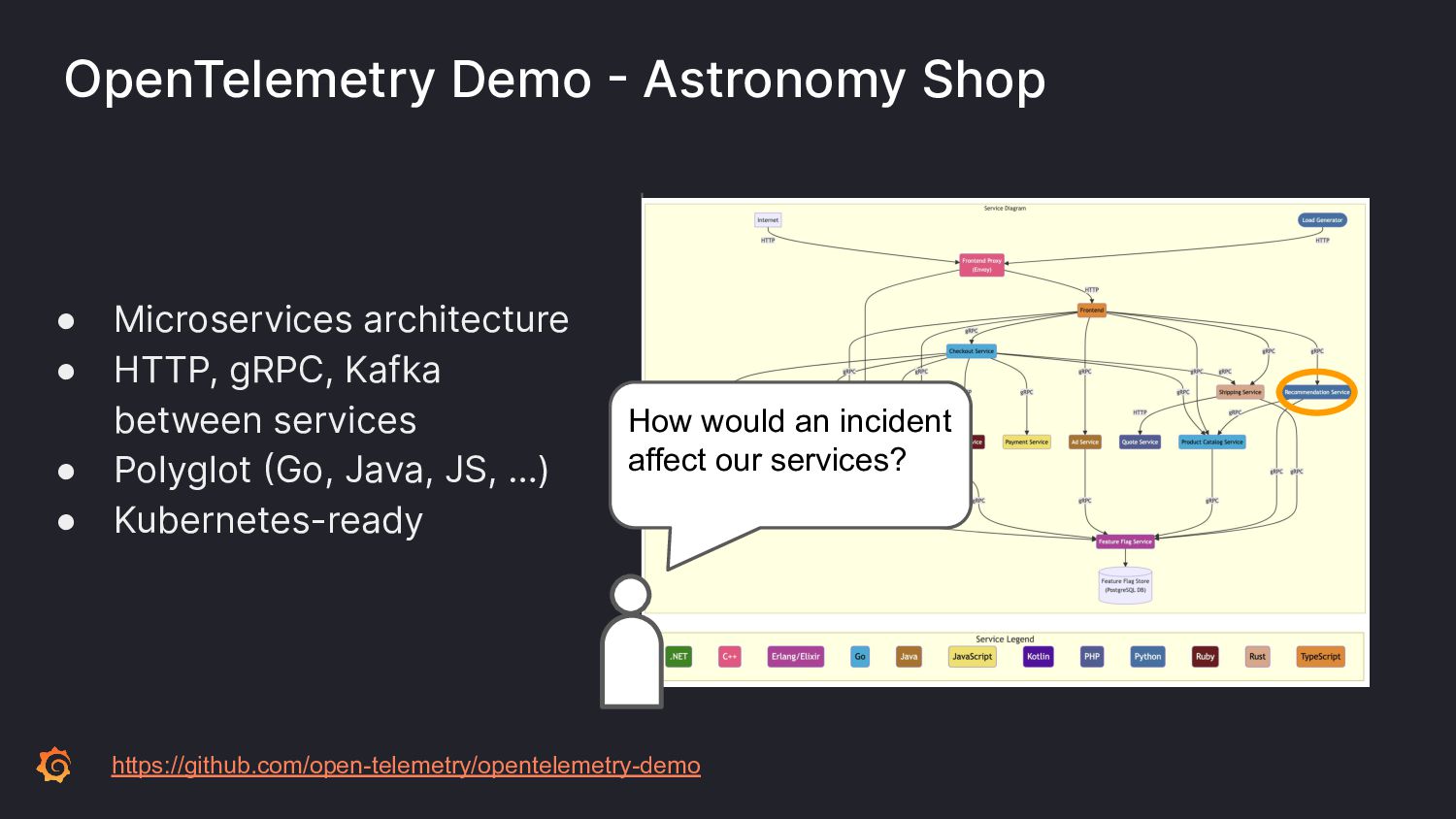
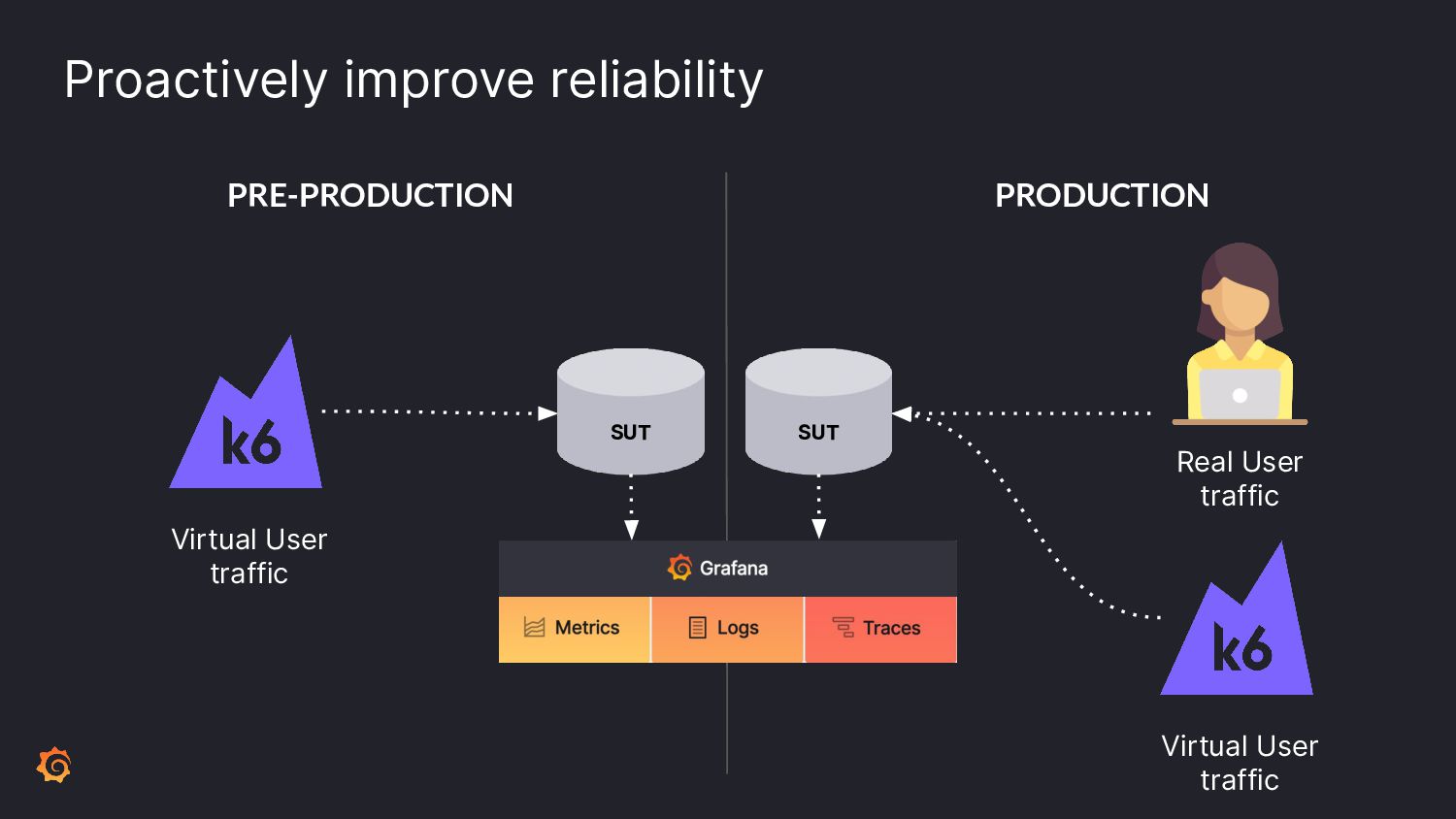
As software systems have become more distributed and complex, the "shift-left" movement brings reliability testing to earlier stages of development. Ensuring reliability goes beyond simple end-to-end tests.
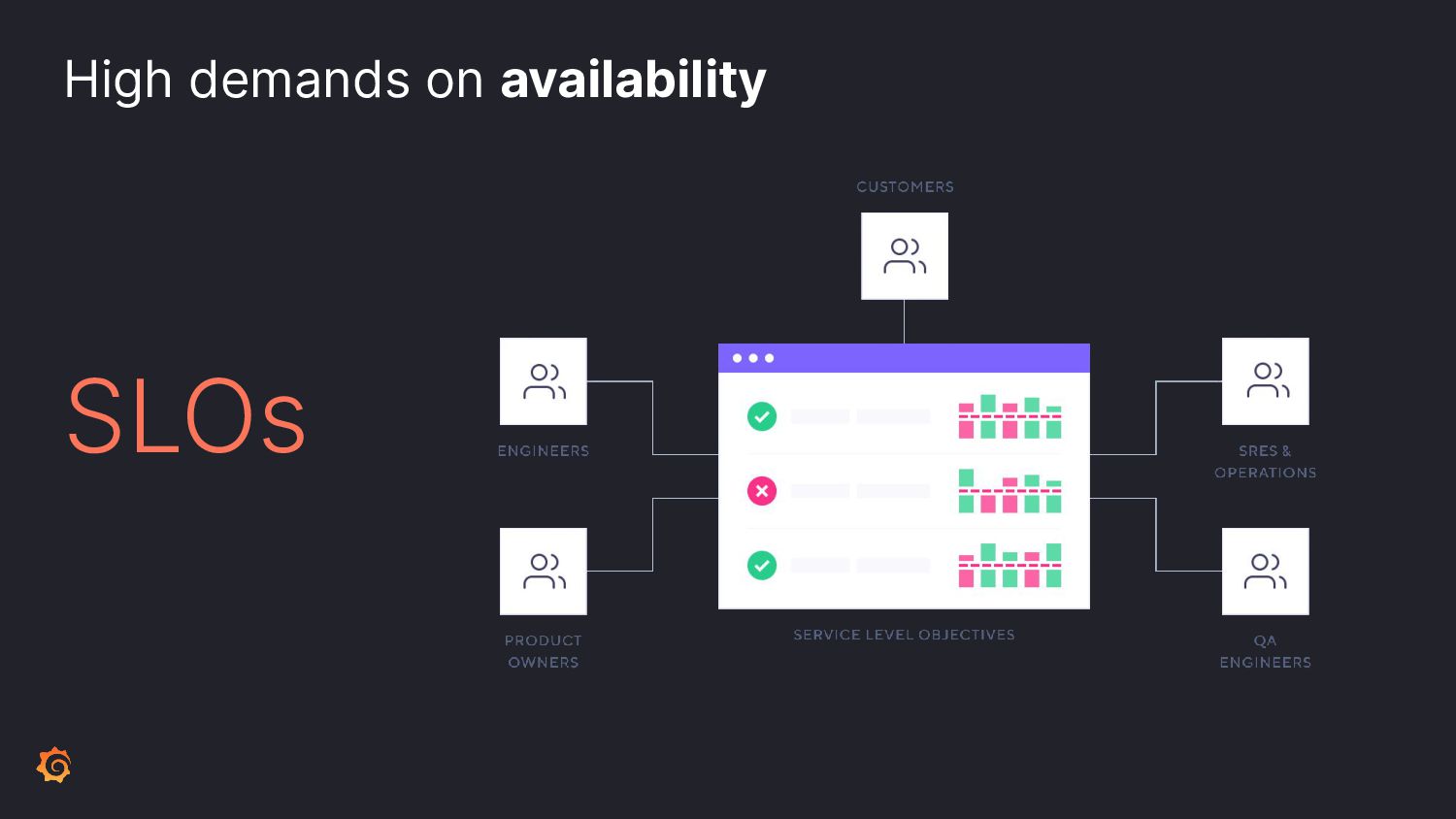
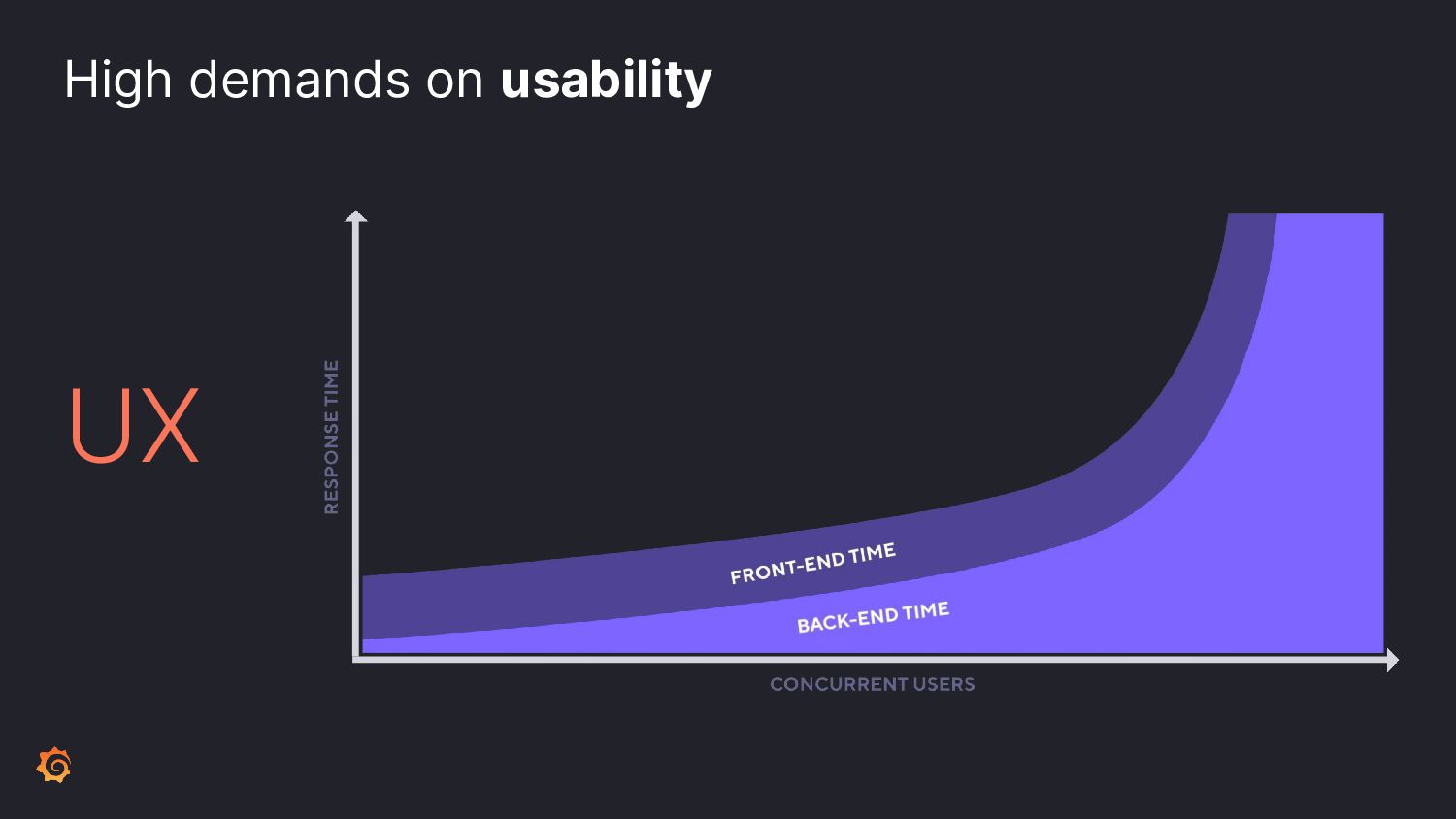
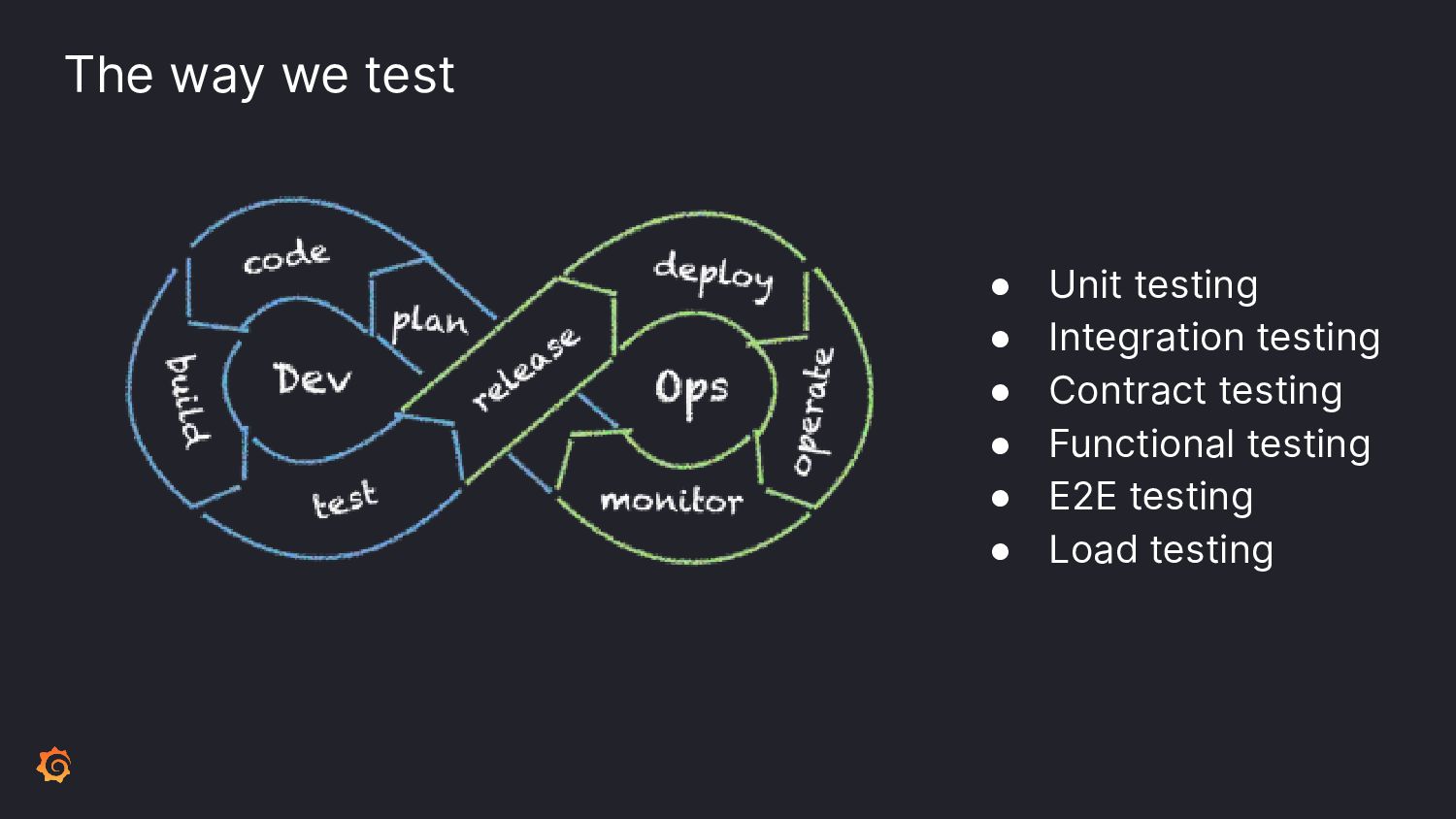
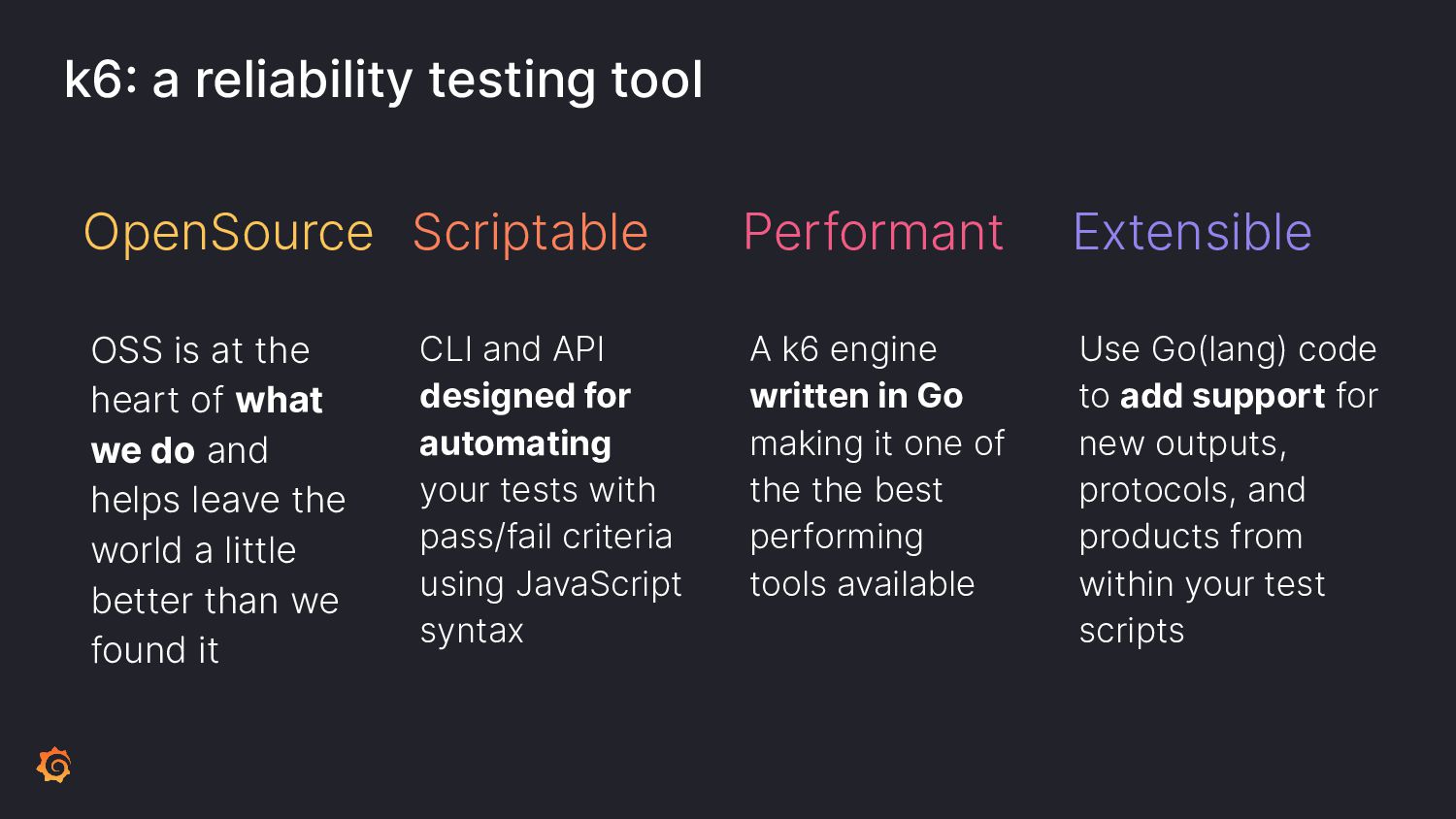
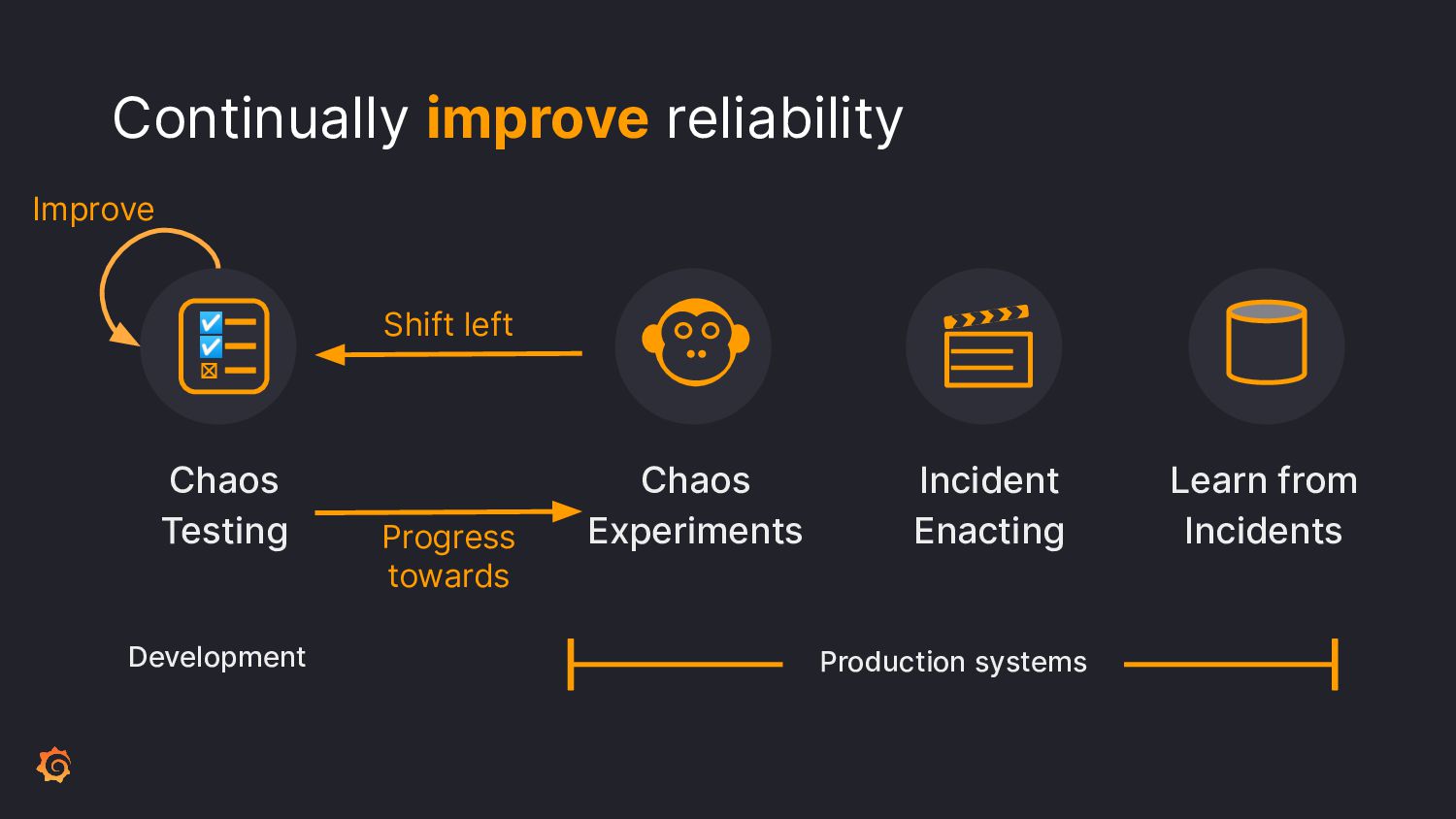
To ensure the highest levels of reliability, you must perform a suite of testing types. Incorporate contract tests to validate APIs; load tests for scaling predictability. But how to test for those inevitable failures? Let's learn from Chaos Engineering principles by incorporating disruptive behavior into your system before production.
Join Paul as we learn ways to incorporate a plethora of testing into your software development pipeline. We'll discuss the pros and cons of each and what you can do to add these to your processes. By embracing a little disruption, you can significantly improve the reliability of your system.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}