entreprise Jean-Philippe Boily @jipiboily | jipiboily.com http://metrics.watch Philippe Lafoucrière @plafoucriere https://gemnasium.com [JP] Explain that the presentation will be about microservices and especially the migration from a monolithic application to distributed micro-services
Google Analytics) • Consultant for SaaS conversion funnels implementation & improvement • Working remotely for US-based SaaS startups, last one being Rainforest QA (YC backed) [JP] • MW - Flexible & near real time alerts for GA • Now consultant, code or code+marketing (funnel & conversion improvement) • Tell more about experience at Rainforest QA • employee #2 • first remote • Engineering Lead • helped build the distributed team, product and more
Microservices: approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms. [JP]
Small steps, no long term goals to rewrite [JP] Rainforest is a company that does Continuous QA, full QA in ~20 minutes Onboarding was harder and harder Experience that started in between, not micro services but having some parts of the app as external services, without a full blown micro service architecture New application aside, instead of extending the existing one Social accounts Many microservices in production now, using Ruby, Go, Elixir, Crystal and maybe even more…?
lot of traffic • Easy to extract [JP] It was the smallest part to extract with a big impact on performance, and a good candidate for experimenting micro-services (very few interactions with the rest of the code base).
needed something solid and well maintained. Choice: OpenShift [PL] Tested: Deis, Flynn, Docker Compose + Swarm not tested: Mesos Openshift is based on Docker and Kubernetes, and was chosen because it was fitting all our needs and requirements.
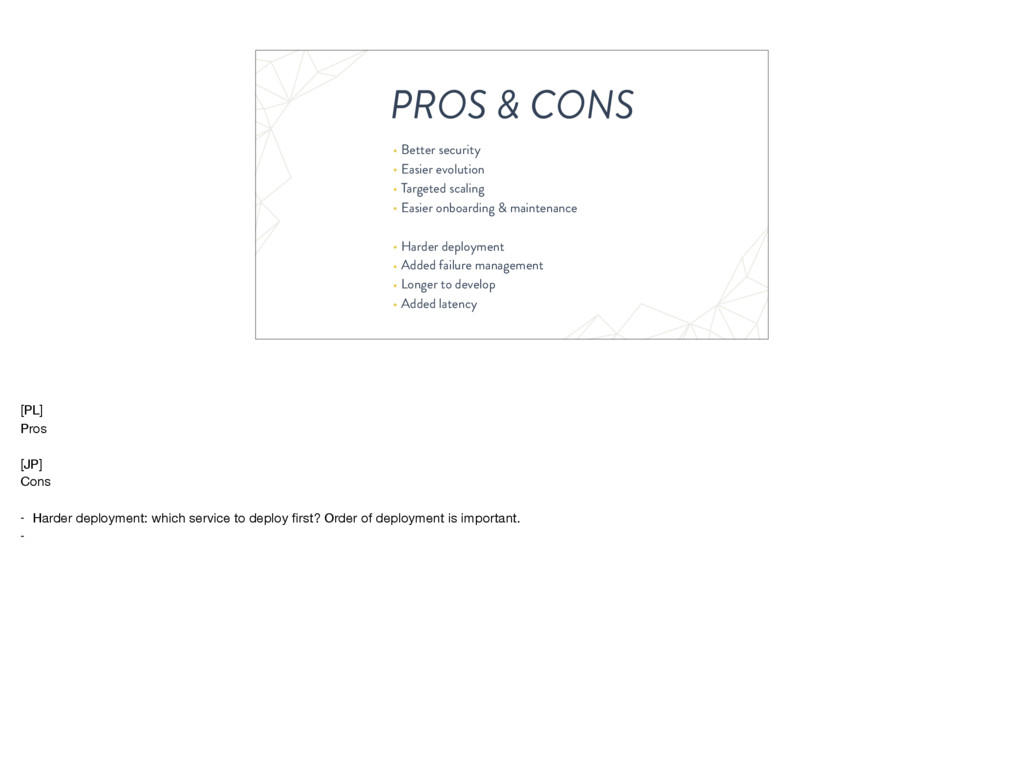
How do we rollback, in case of failure? * A critical piece of the new procedures * It wasn’t possible with docker-compose + swarm, at least not without maintaining a lot of scripts Reduce downtime as much as possible during deploys * Openshift (kubernetes) has a smart way to load balance trafic on containers, with absolutely zero downtime
not robust enough, because nodes can fail * Automatic? * Openshift has great load balancing features, and can automatically scale the app (with openshift metrics)
data, in case of emergency * Must rewrite procedures accordingly * Ensure data is correctly backup * Openshift/k8s is using “Persistent Volumes” on glusterfs (distributed fs)
Metrics from the infrastructure (CPU, RAM, I/O,…) * Integration with our existing monitoring systems (omd + newrelic) * Openshift has an internal metrics system to monitoring services and take actions if necessary
Clear * Not a requirement at first, but became one after experimentations * Openshift has a GREAT documentation, very complete (created by RedHat employees)
released every week. We prefer to keep it simple, and stay with vanilla Go, no need for a framework. We like to separate the infrastructure configuration from our business logic code. Every service is independent, and can’t start without a registry service (but still needs a DB, etc.)
documented protocol, that supports versions. UPGRADING WITHOUT [JP] I/O must be defined by a common protocol. We try to avoid multiple versions of the protocol. Multiple versions is also more code to maintain, and sometimes just to avoid a small downtime. Not always worth the extra work.
for secrets [PL] We follow 12factors methodology for our services. All configuration is passed using env vars. The network info (addr, ports) are passed automatically by openshift to each container. No need for a central registry. Every service is a command line tool, and a web server (default). Some options are passed in the CMD of the container. Sensitive information, like db credentials, are passed using mounted secret volumes. Credentials don’t appear in the container inspect info. Secret volumes are shared between services, like SMTP config. Each Service has a dedicated PG credential.
end to end testing. [JP] Each service has unit test, like any other project. E2E tests are more complex to achieve. Testing API with Go can be sometimes painful without framework.
in mind many instances can co-exist. [JP] Nothing specific in the code, because we don’t write files on FS. All services can be ran several times behind a LB
break one day. [PL] Even if k8s is smart enough to not send trafic to a non-valid pod, things can quickly become unstable and unavailable. We need to anticipate failure in every workflow: - Idempotent tasks (i.e., do not insert twice if runs twice, or do not send the same email twice, for example) - Check writes (DB, NSQ, etc.) - Retry - Hot retry (inside the running instance, with exp. backoff) - Cold retry (instance can be killed, and the backoff with it, so retry every task that should be finished already) Advice: Keep it simple at the beginning!
and more metrics will be needed when debugging, or just monitoring Ex: Number of signups, Number of failures during project sync, number of notifications (by channel), number of API calls to a provider like Google Analytics. Librato is a good and simple (SaaS) tool for custom metrics, with alerts and dashboards. [PL] We’re using Graylog because we need a tool inside our network (and logs shouldn’t be elsewhere). Graylog is an opensource and free log aggregator with lots of features (dashboards, alerts, search graphs, etc.). We use Graylog for alerts based on number of occurence, and Airbrake for the first error.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![WHY? [JP]](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![GENESIS [JP]](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![CRITERIA FOR ARCHITECTURE [PL] New architecture is not only a](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_11.jpg){kind=link}
![SECURITY [PL] User authentication? Services isolation? Openshift has a great](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_12.jpg){kind=link}
![DEPLOYMENT [JP] From semi-auto deploys with Capistrano to continuous deploy](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_13.jpg){kind=link}
![SCALING * [PL] * Horizontal or vertical? * Only vertical:](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_14.jpg){kind=link}
![LOGGING * [JP] * Must be centralized * Must store](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_15.jpg){kind=link}
![BACKUPS * [PL] * Not only backup, but also restore](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_16.jpg){kind=link}
![MONITORING * [JP] * Detect service failure * restart *](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_17.jpg){kind=link}
![DOCUMENTATION * [PL] * Complete * Up to date *](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_18.jpg){kind=link}
![ANATOMY OF A MICROSERVICE [PL]](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_19.jpg){kind=link}
![NO FRAMEWORK! Just Plain Old Go [PL] Lots of frameworks](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_20.jpg){kind=link}
![HOW TO CONSUME IT? HTTP? Queueing? Protobufs? [JP] Mostly HTTP](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MONITORING & ALERTING Metrics, metrics, metrics. Librato Graylog [JP] More](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_27.jpg){kind=link}
![CONCLUSION [PL]](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_28.jpg){kind=link}
{kind=link}
![START WITH A MONOLITH [JP] Easier to start with, and](https://files.speakerdeck.com/presentations/ee126cd374fa47a09ab939c07046628e/slide_30.jpg){kind=link}
{kind=link}