V súčasnosti sa venuje nemalé úsilie získavaniu rôznych informácií zo zdrojových textov programov, ako aj podporných nástrojov pre tvorbu softvéru. Medzi tieto informácie patria aj tie, ktoré súvisia so zmenami zdrojových textov v čase. Tie nachádzajú uplatnenie napríklad pri detekcii miest zdrojového textu náchylných na chyby, pri plánovaní projektu, manažmente rizík, rozdeľovaní ľudských zdrojov, monitorovaní projektu a mnohých ďalších.
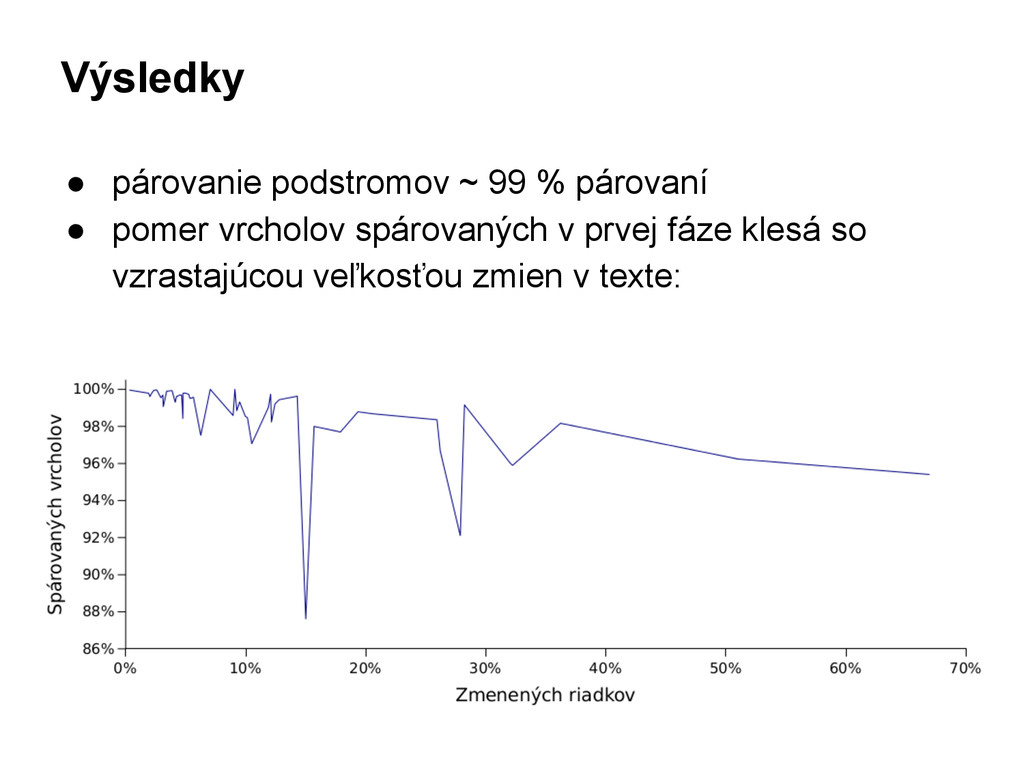
V tejto práci sa zaoberáme problémom analýzy časovej evolúcie zdrojových textov softvérových systémov. Hierarchickú štruktúru zdrojových textov reprezentujeme prostredníctvom syntaktických stromov. Analyzujeme existujúce riešenia a prístupy v tejto oblasti a na základe vykonanej analýzy navrhujeme vlastné riešenie. To umožňuje detekciu zmien zdrojového textu porovnávaním dvoch verzií toho istého textu. Toto porovnávanie a následné párovanie príslušných vrcholov stromov je založené na troch rôznych prístupoch – párovanie založené na podstromoch, párovanie vnútorných vrcholov a párovanie listov. Navrhnutú metódu v práci overujeme na zdrojových textoch reálnych softvérov.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}