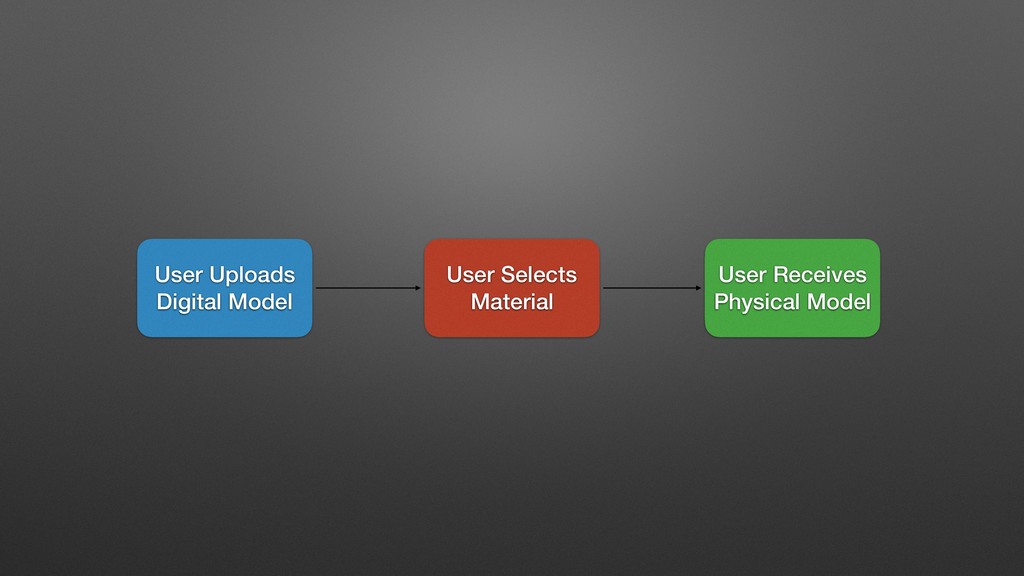
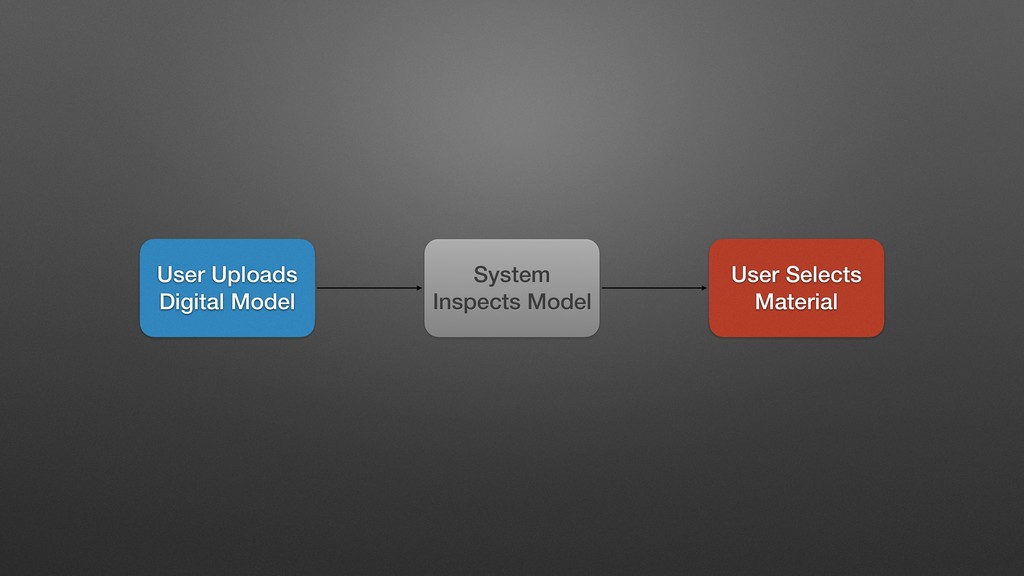
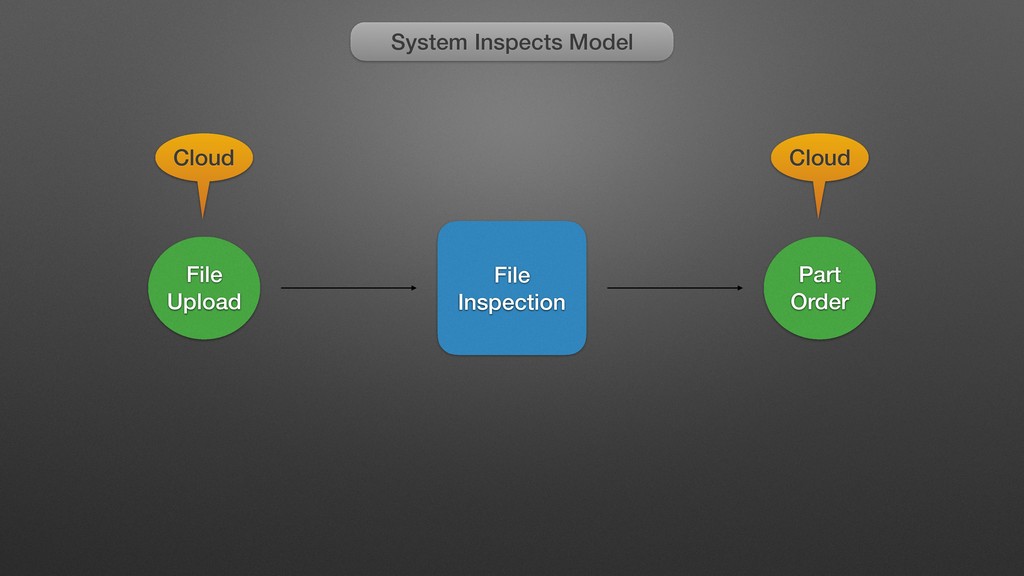
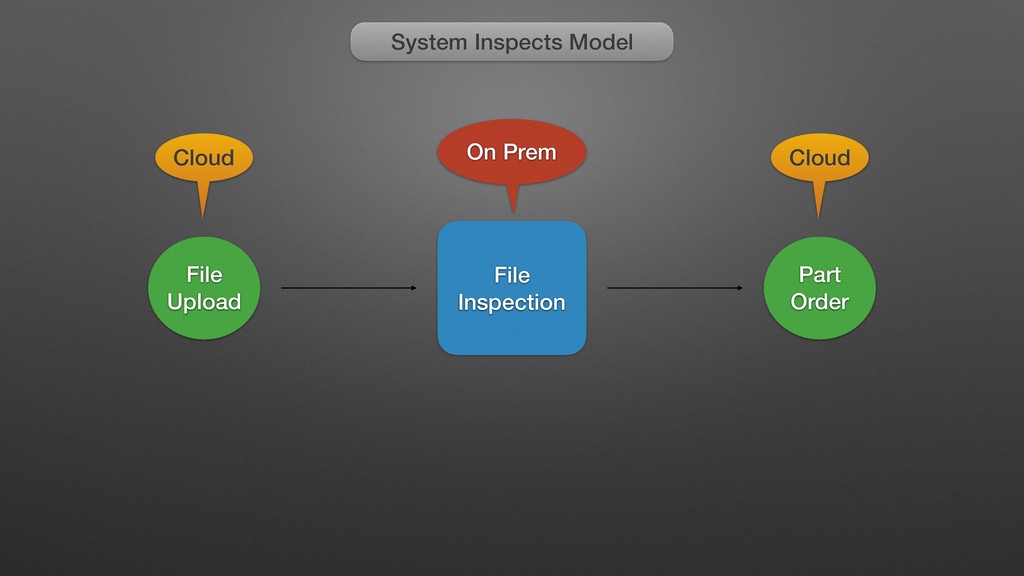
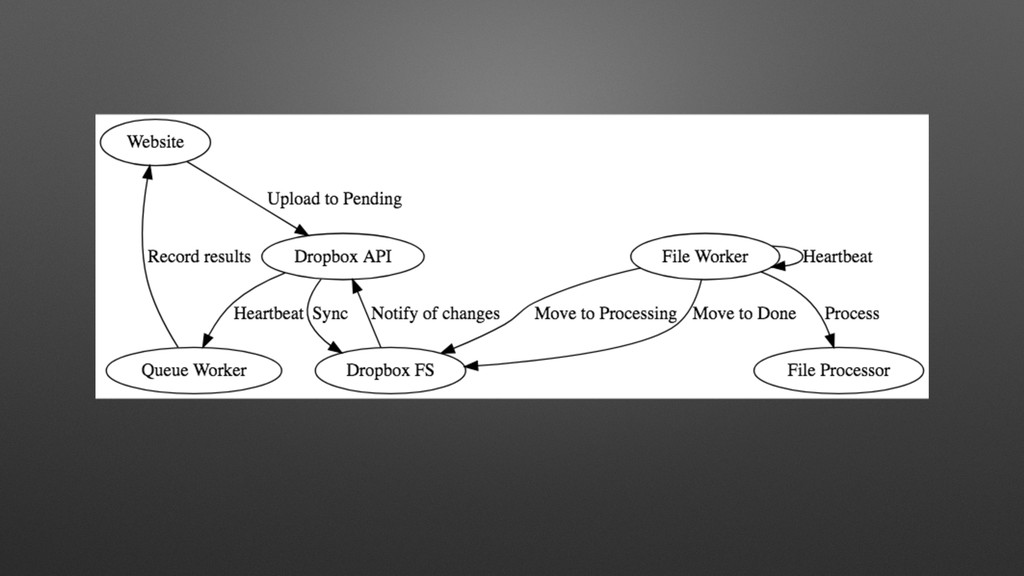
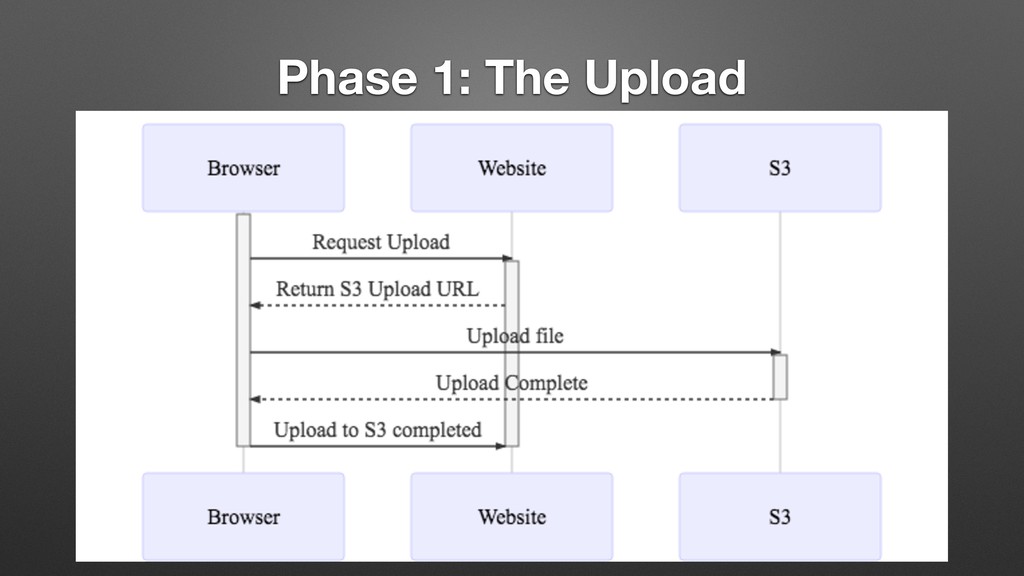
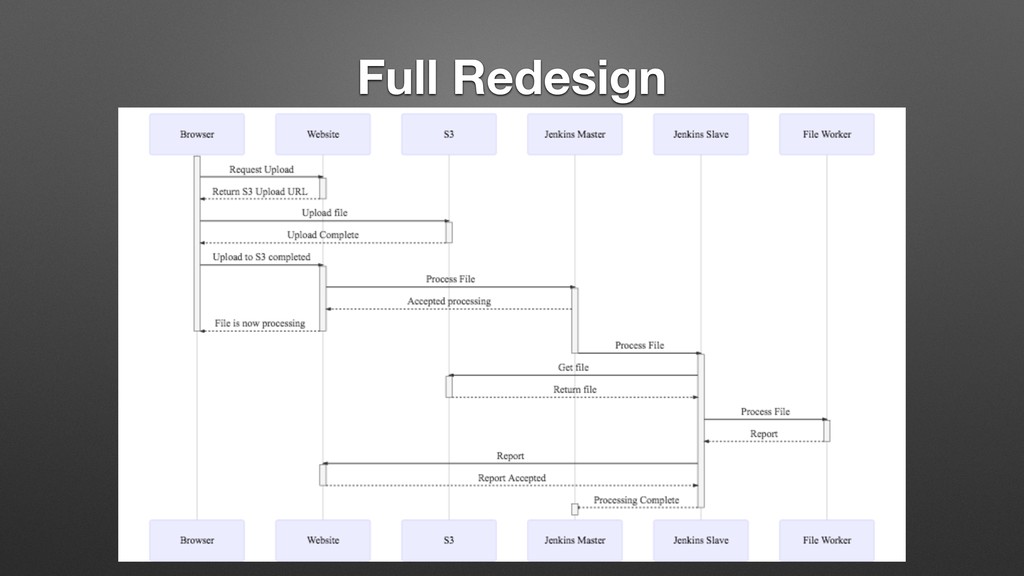
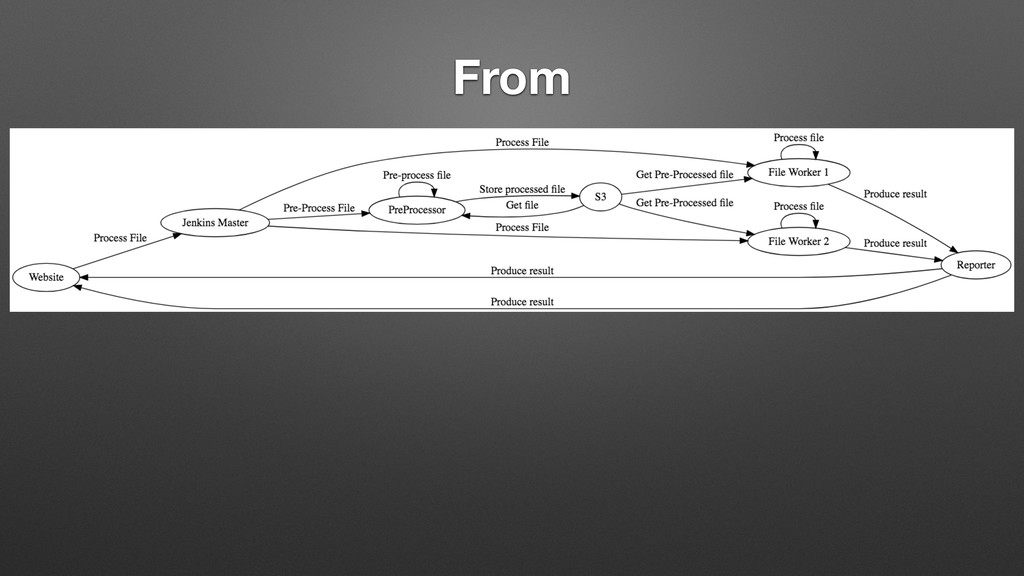
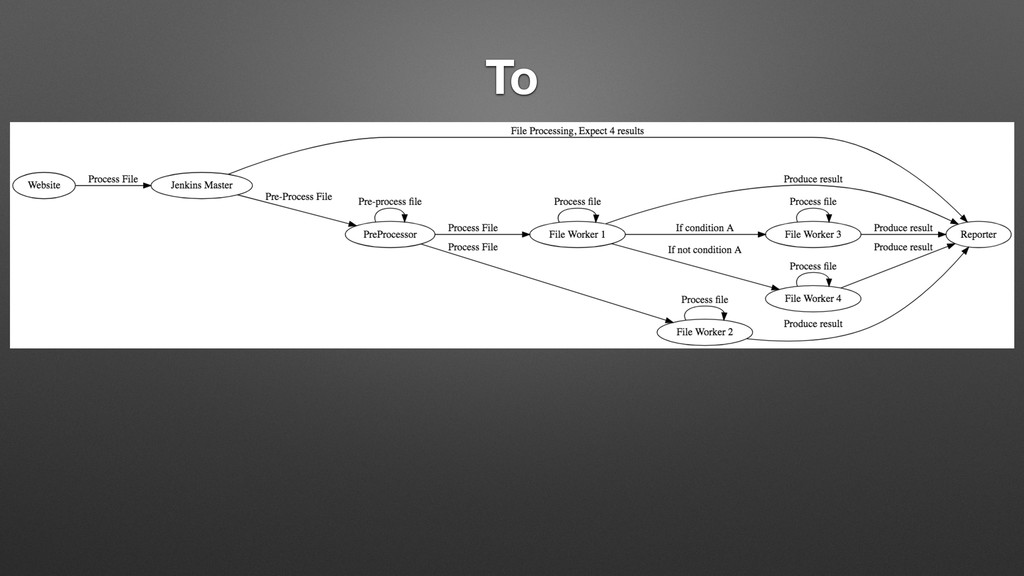
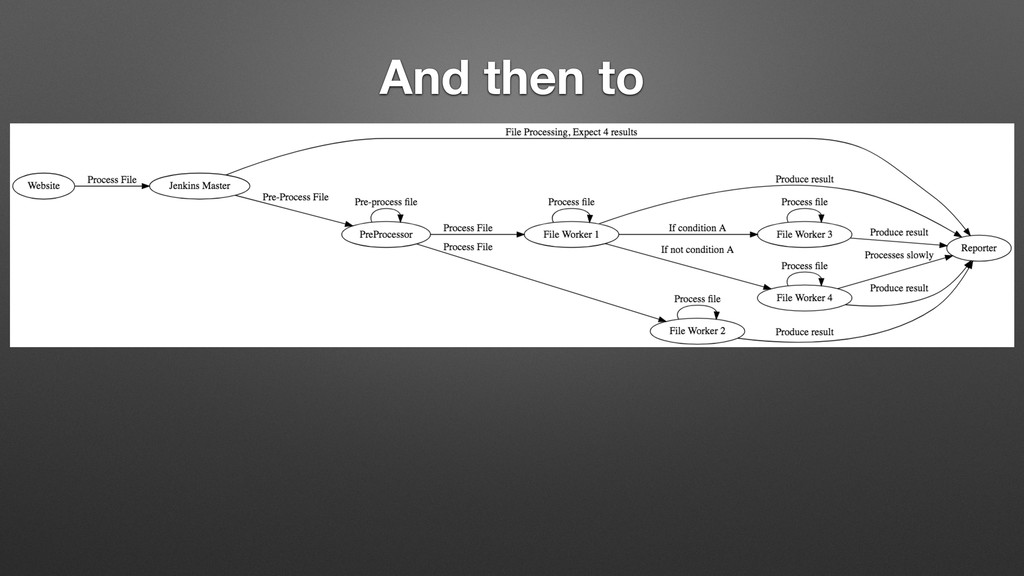
My last job was with a distributed manufacturing platform for turning digital ideas into physical products. They enabled customers to upload 3D models, have the models manufactured into physical goods, and delivered into the customer's hands, all within 24 hours. Every time a digital model is uploaded, we processed the file with an array of tools that inspect the model and make determinations about its manufacturability, size, and perhaps most importantly price. One of the very first things I did there was to completely overhaul this process, converting it from a mystical black box to a clear set of discrete processes with copious amounts of highly visible logging. While there are many possible ways to do this, I chose Jenkins, and in supporting this system for over a year, while I may use different tools to do it now, Jenkins bought us a lot of time in the interim, and I left them with quite a bit of runway before any changes would be required.
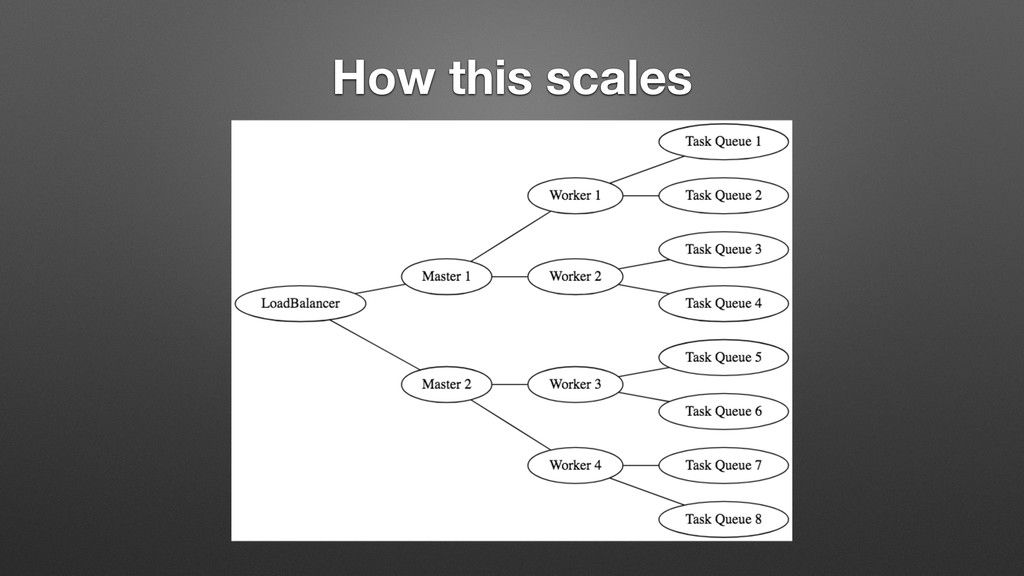
In this talk I will cover where we started, why I chose Jenkins, why it works so well for this use case, and how to use these same patterns to solve your asynchronous parallel processing problems, regardless of your platform. Our use patterns showed us that managing jobs in Jenkins can be a very similar experience to managing code deployed to server-less solutions such as AWS Lambda. Let me show you how.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
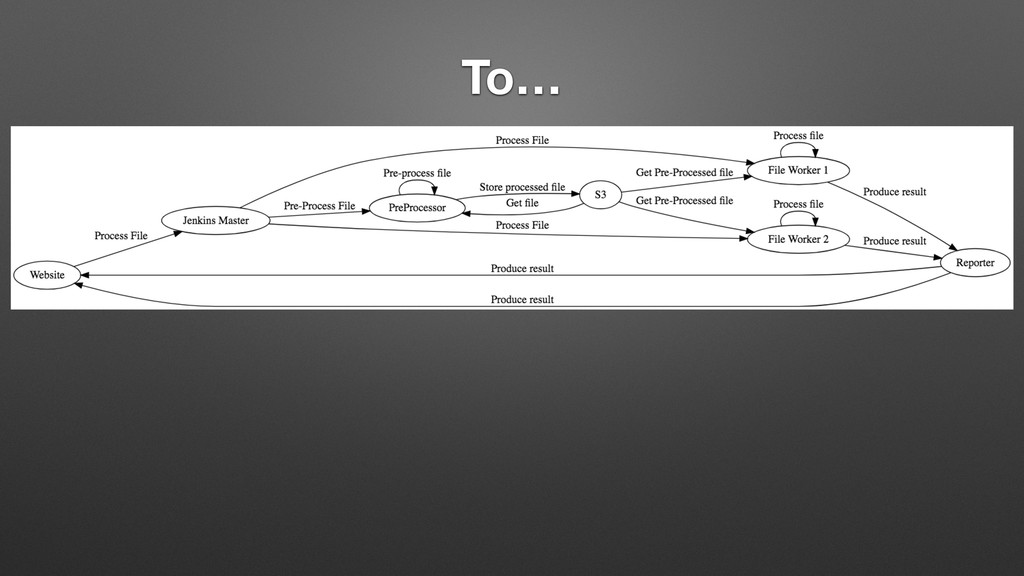{kind=link}
{kind=link}
{kind=link}
{kind=link}
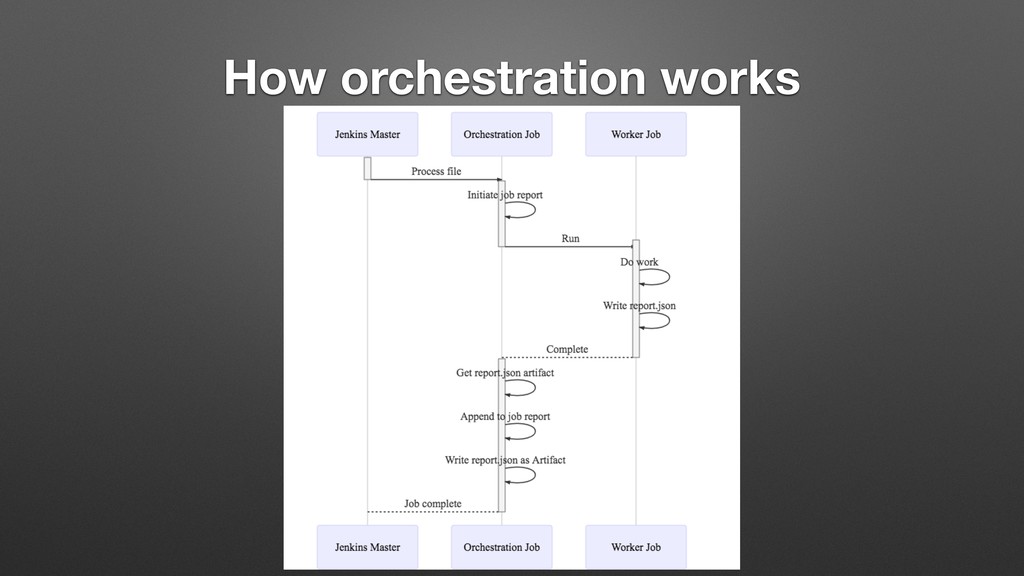{kind=link}
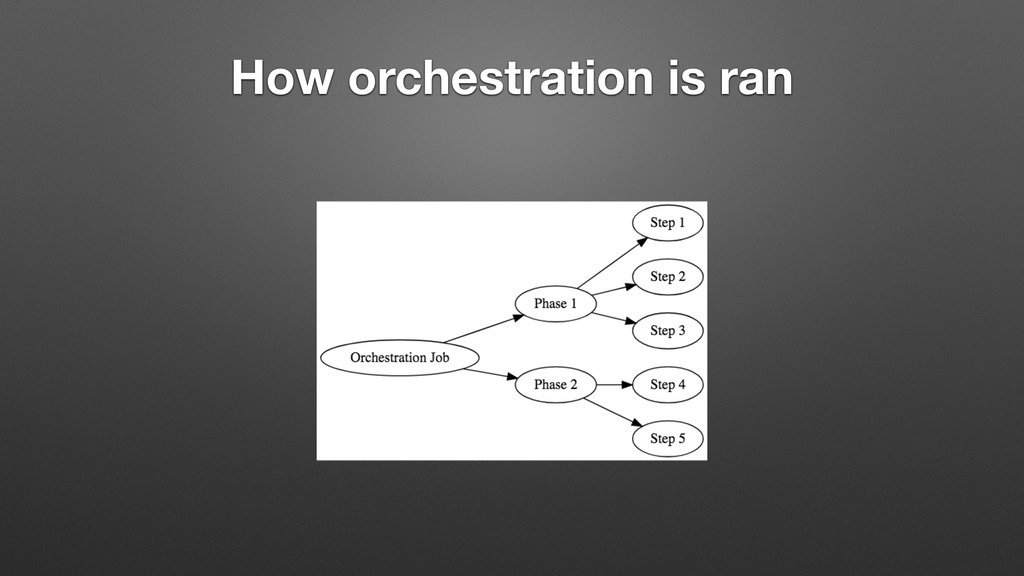{kind=link}
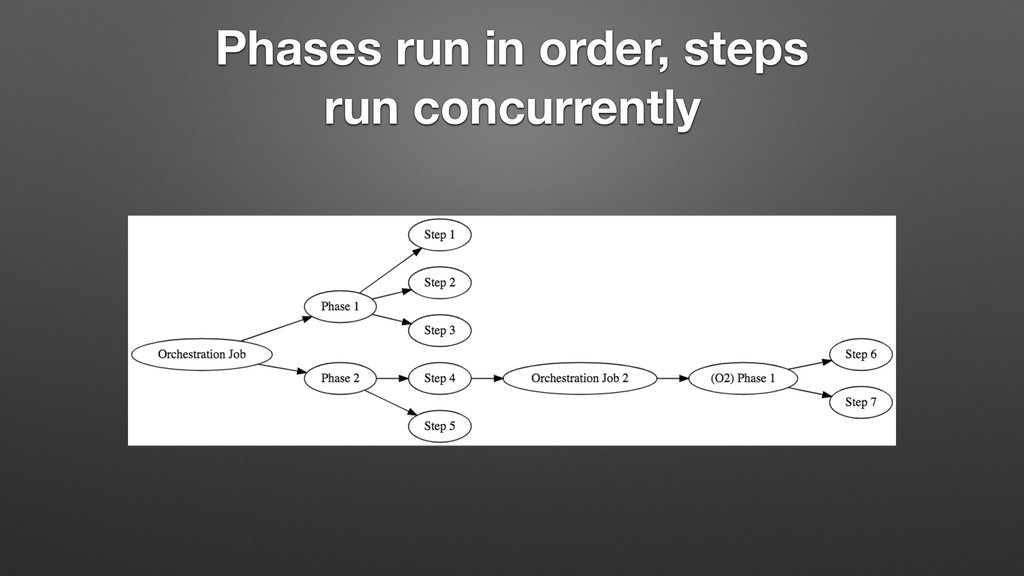{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}