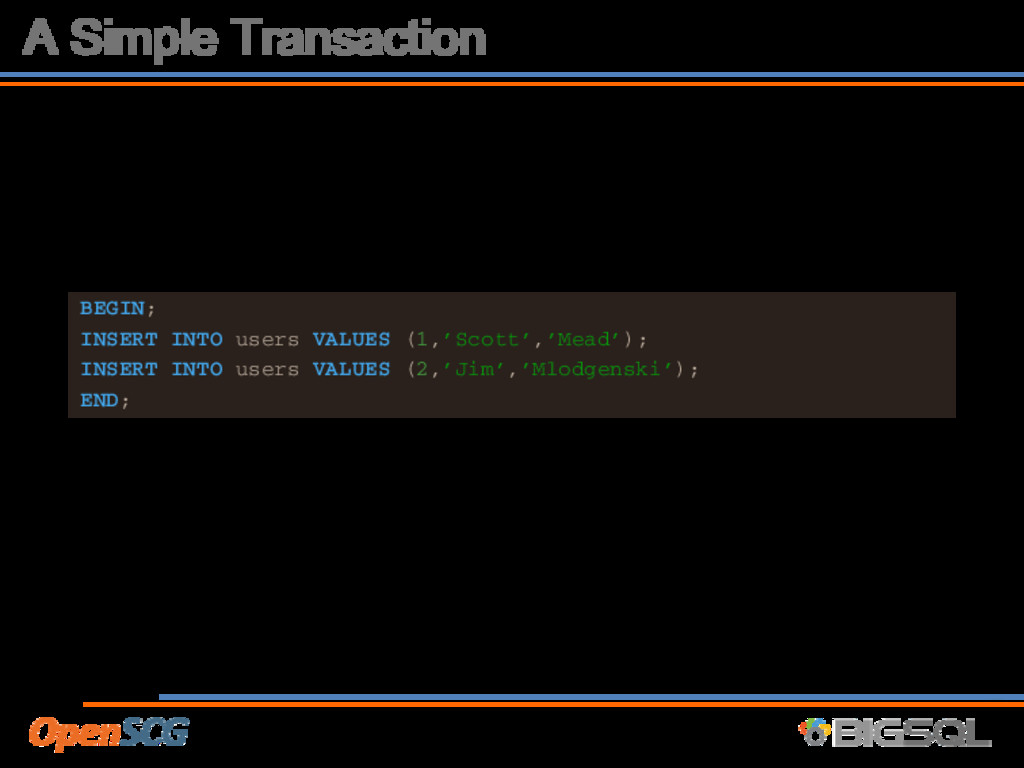
• Consistency • A transaction brings the database from one valid state to another • Isolation • Concurrent transactions execute isolated from each other • Tunable with ‘transaction_isolation’ • Durability • Once a COMMIT has completed, the data is safe, even in the event of power loss or crash.
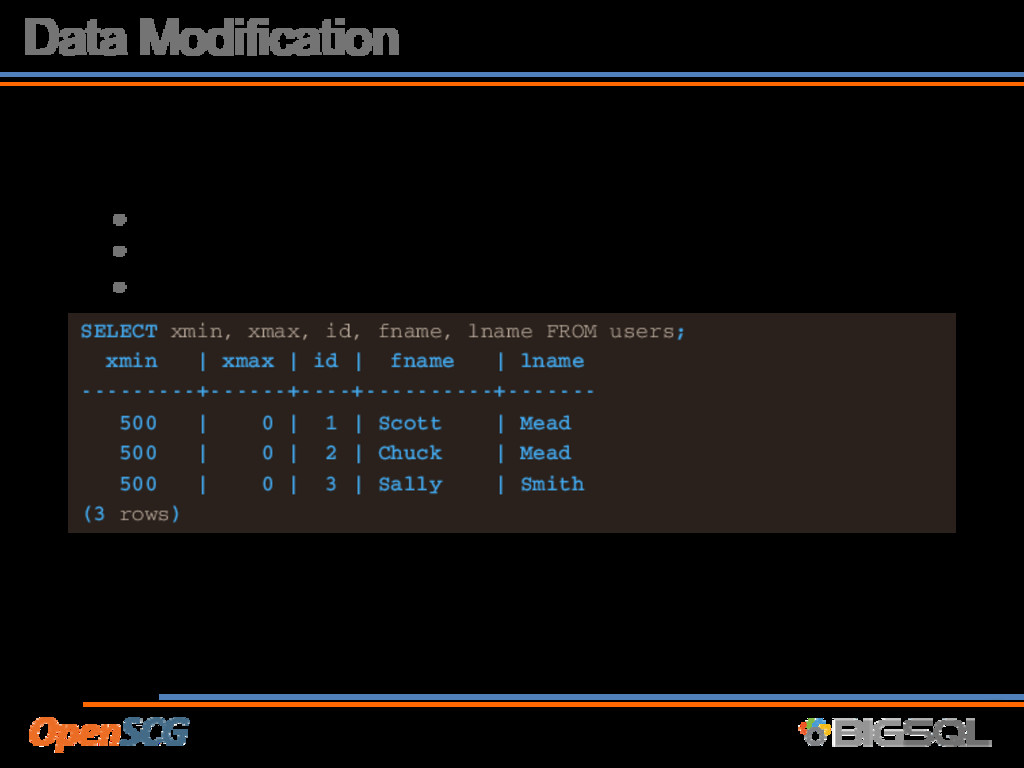
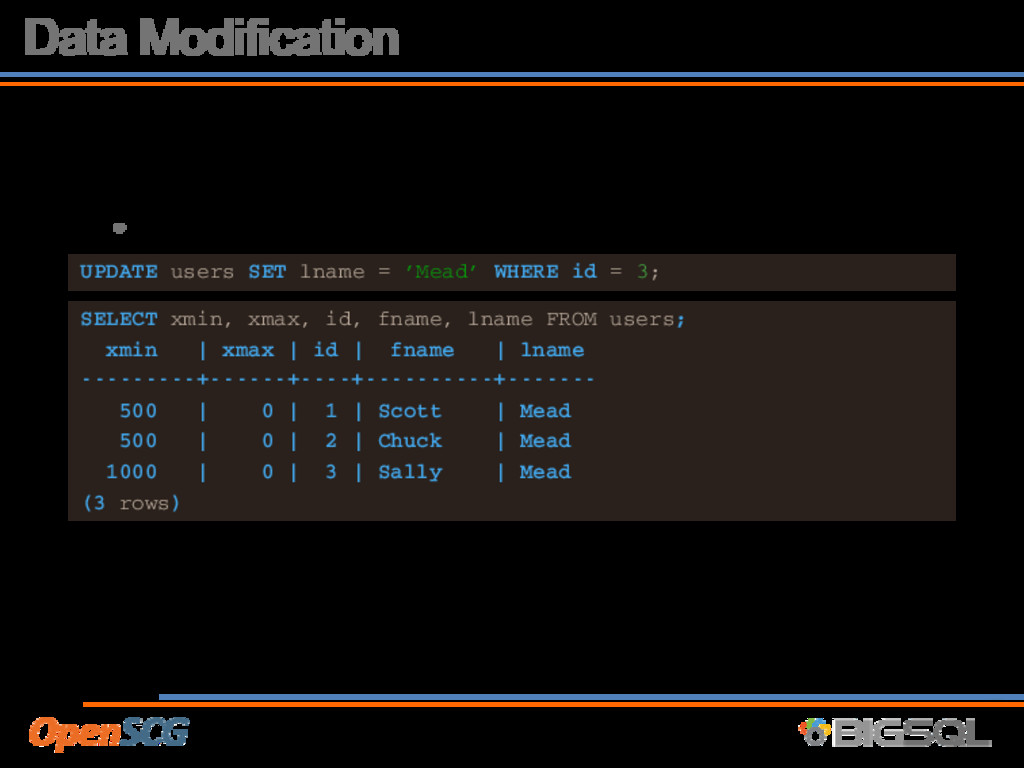
B xid=1000 • Transaction A will see • xmin <= xid < xmax • So in this case, A sees Sally Smith ~~ 500 | 1000 | 3 | Sally | Smith ~~ old row version 1000 | 0 | 3 | Sally | Mead Ummm… Why VACUUM?
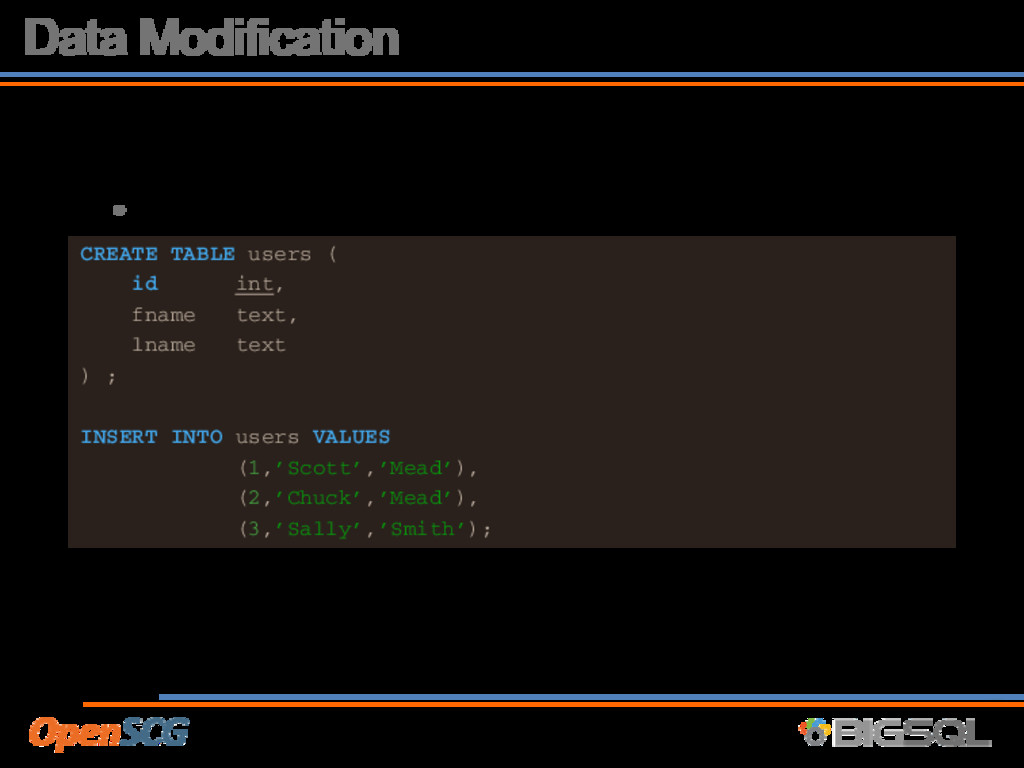
of ACID, postgres leaves multiple row versions • After some time, these row versions are not visible to anybody • Typically referred to as ‘bloat’ or ‘fragmentation’
Allocated space that we can re-use • Too much can be a problem • Find these old rows and mark them as available • FSM (Free Space Map) • Future transactions can re-use the space • VACUUM can also: • Update Planner statistics • Protect against xid wrap-around (FREEZE) That’s VACUUM… what about AUTOvacuum?
killed it” • “When Autovacuum runs, performance sucks, I kill it” • “Slow! -> Outage (full dump / restore).” • Things run GREAT after that! • For a while… • “I see autovacuum running for days at a time” • “After I purge my logging table, autovacuum runs for days” • “Autovacuum is constantly running on table X,Y,Z”
basic algorithms • A DBA would examine your workload and build a strategy • It’s still a machine, and operates based on conservative defaults • Workload defaults • vacuum_threshold = 50 • vacuum_scale_factor = 0.2 (20%) • vacuum_cost_delay = 20 (ms)
autovacuum SELECT name, setting, unit, short_desc FROM pg_settings WHERE name ilike ’%vacuum%’; • Controls are available for: • ANALYZE • FREEZE • Memory Utilization
does it cost? • vacuum_cost_page_hit = 1 • vacuum_cost_page_miss = 10 • vacuum_cost_page_dirty = 20 • After accumulating cost, what to do? • autovacuum_vacuum_cost_limit = 200 • autovacuum_vacuum_cost_delay = 20 (ms) • sleep for this many milliseconds
- 100x the next largest workload • Tuning autovacuum: 1. Increase the number of autovacuum_max_workers • Adds capacity to vacuum • Provides ‘dedicated’ workers for busy tables 2. Increase the ‘vacuum_threshold’ • Prevents autovacuum from constantly tending to a table • Allows other tables a chance to be vacuumed
Monitor for tables not vacuumed within 7 days • 7 days is somewhat arbitrary, but a good start • This shows both starvation and the quietest tables • Monitor logs for VACUUM times / behavior • Configure • log_line_prefix • log_autovacuum_min_duration • Use pgbadger to visualize autovacuum behavior • Look at length of vacuums and # of them
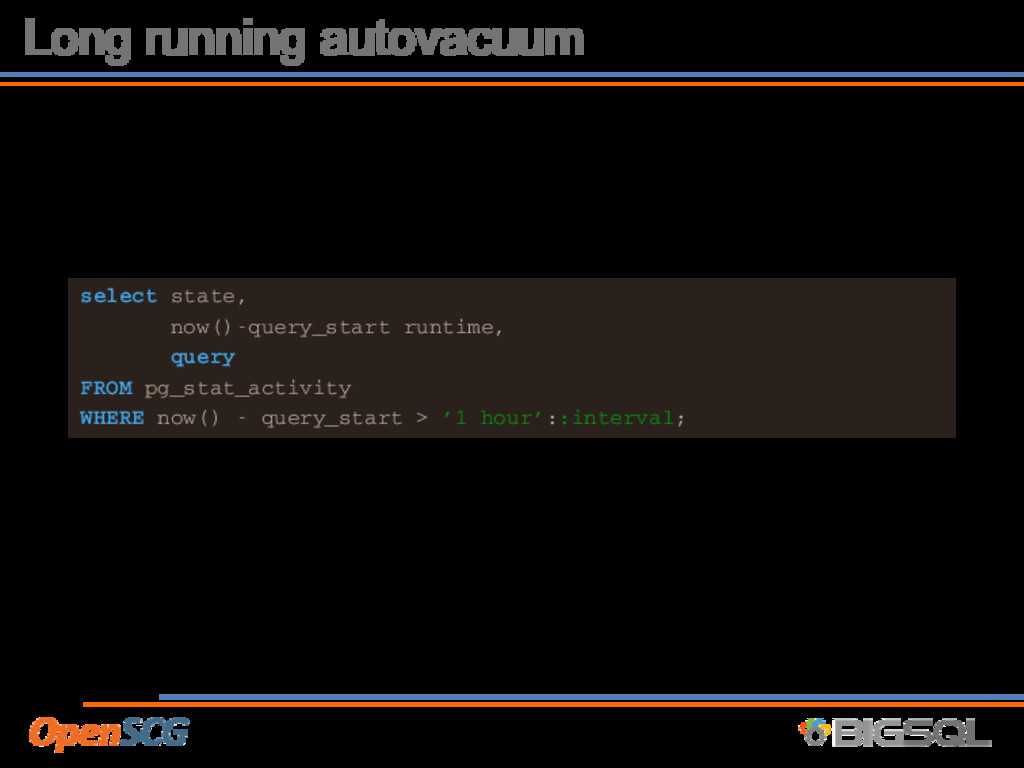
A number of ways to monitor • Typically complex queries, but give good insight • Monitor for long-running vacuum • Too long between vacuum (high threshold) • Throttle is too high • Monitor I/O subsystem • Vacuum demands I/O bandwidth, monitor and throughput to avoid starving the database server’s query activity
high bloat and/or long-running vacuums • Marry the data to your workload analysis • If the thresholds are normal, lower the throttle • If the thresholds are high, lower them
• custom vacuum cron-job for ultra-high fliers • Logging tables like special attention • Typical logging tables have high INSERT with perdiodic, large bulk DELETE • Partition • Use ‘truncate table ’ instead of DELETE • No VACUUM required
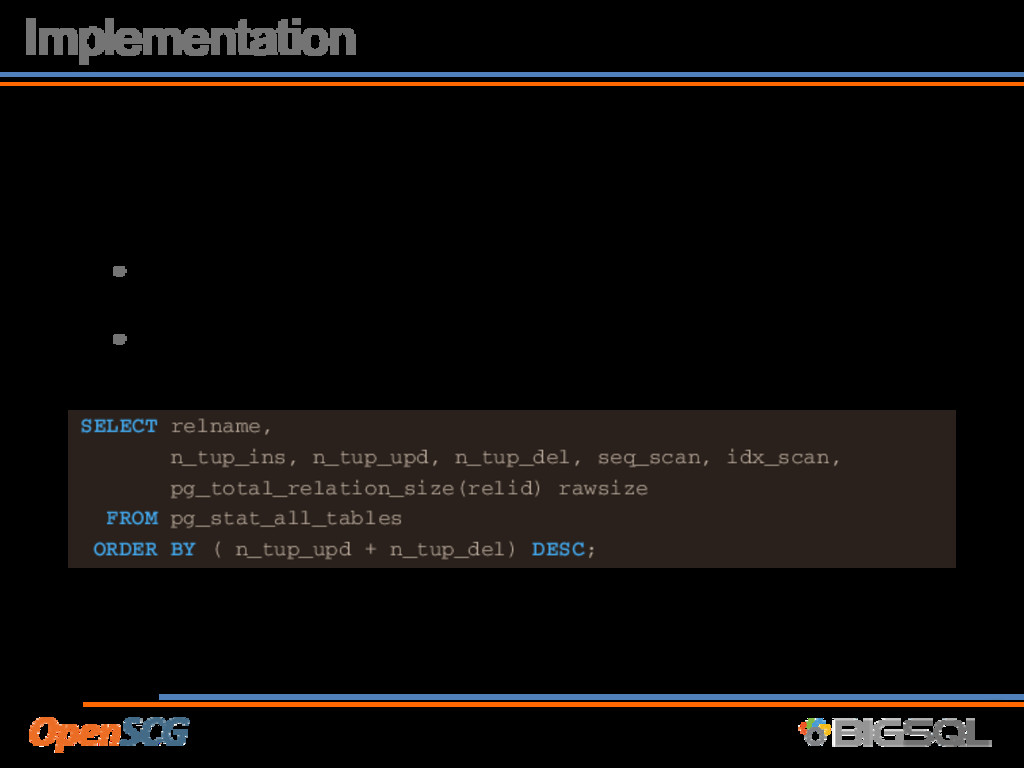
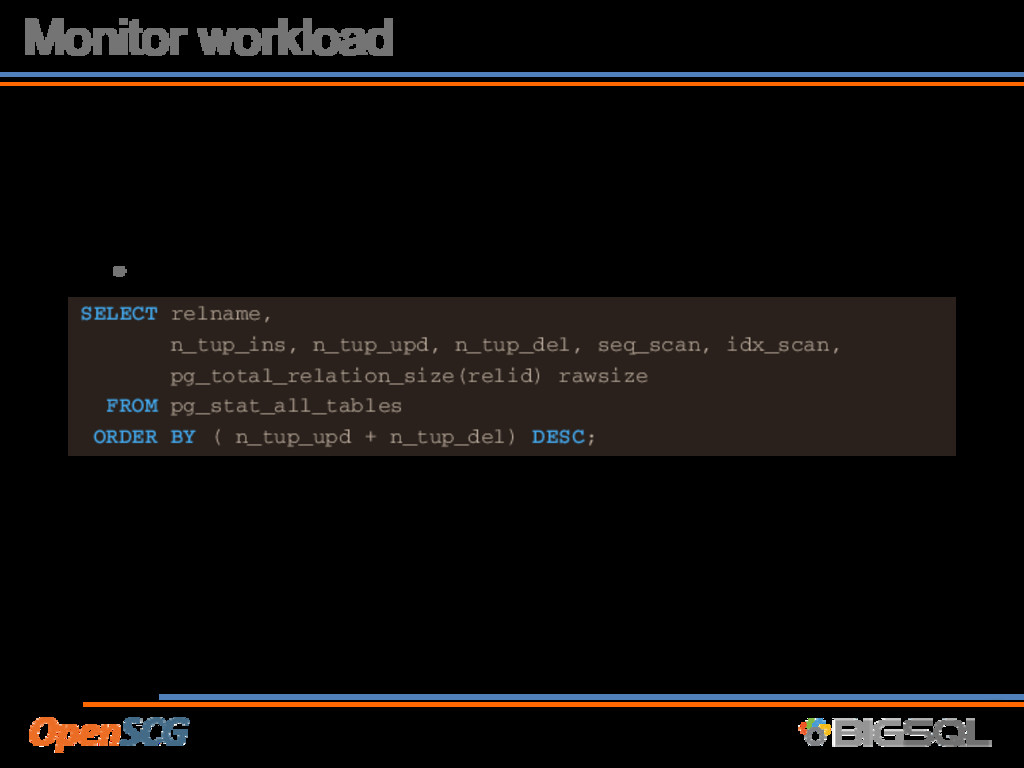
and DELETE workloads • Look at table usage by most updated + deleted SELECT relname, n_tup_ins, n_tup_upd, n_tup_del, seq_scan, idx_scan, pg_total_relation_size(relid) rawsize FROM pg_stat_all_tables ORDER BY ( n_tup_upd + n_tup_del) DESC;
orders magnitude higher updates than the next table • If this traffic continues around the clock, then the pgbench tables will require all 3 of our autovacuum workers, all the time • Since only a few tables are demanding time, let’s optimize those away
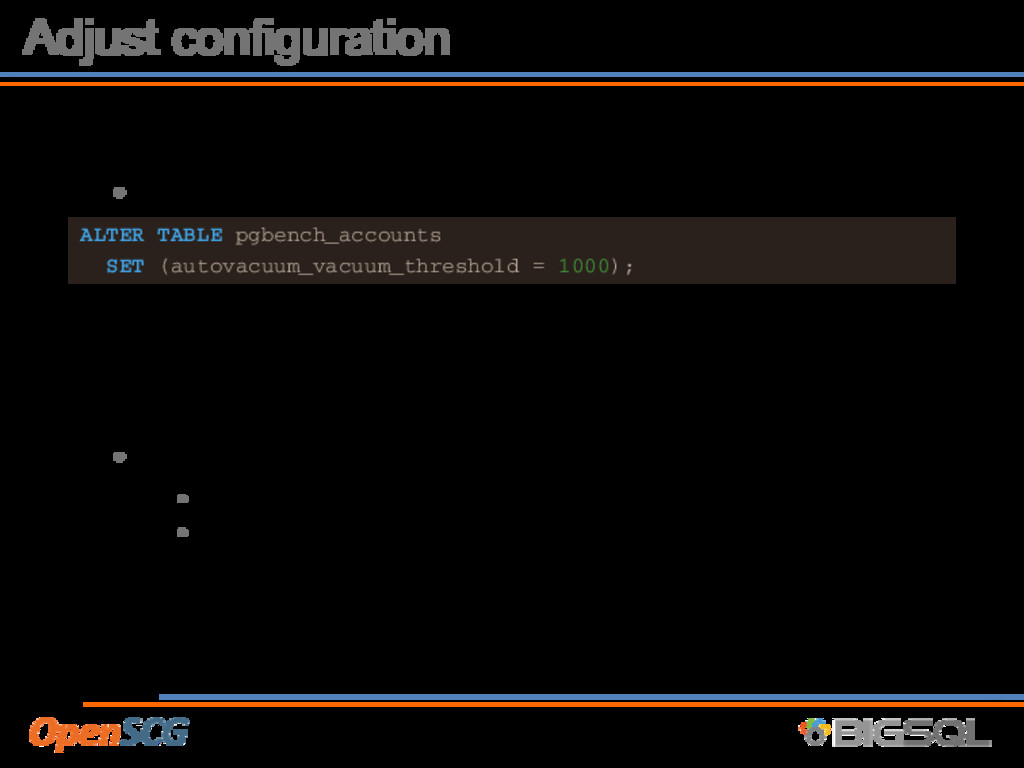
1000); We want to pick a threshold that will allow other tables to be vacuumed without ignoring our critical tables too long. • Number of workers • Add to the pool of available vacuum processes • We need to be mindful of I/O
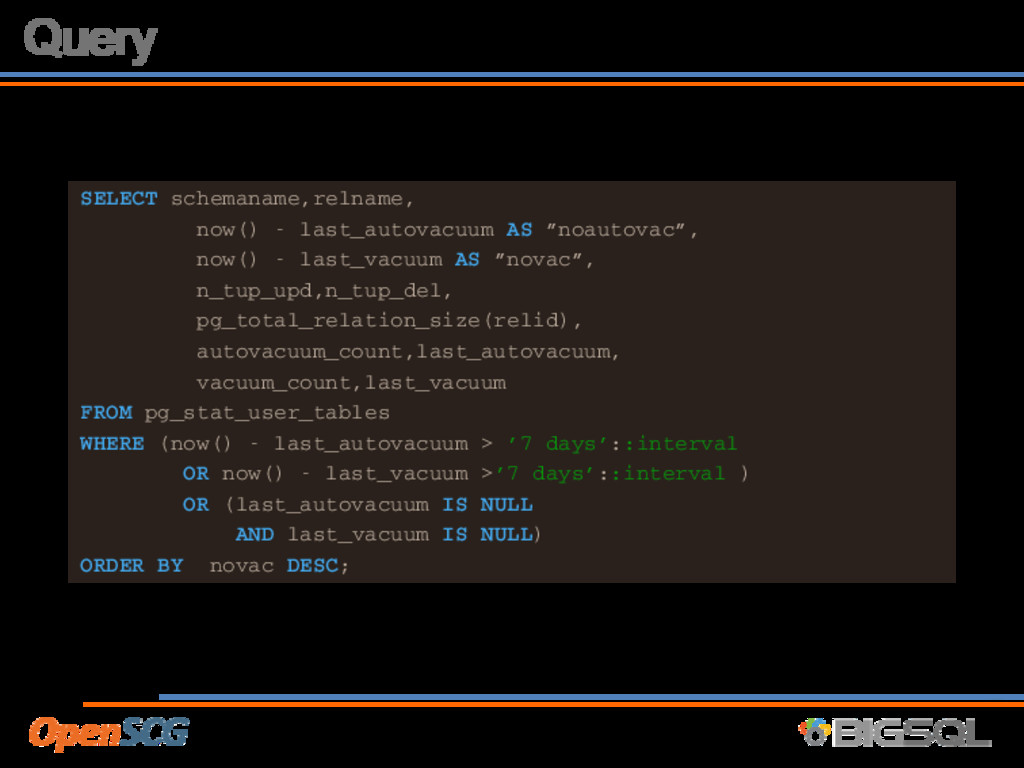
not been vacuumed in 7 days • Have not been autovacuumed in 7 days • Have never been vacuumed or autovacuumed • 7 days is a starting point, adjust as necessary
last_vacuum AS ”novac”, n_tup_upd,n_tup_del, pg_total_relation_size(relid), autovacuum_count,last_autovacuum, vacuum_count,last_vacuum FROM pg_stat_user_tables WHERE (now() - last_autovacuum > ’7 days’::interval OR now() - last_vacuum >’7 days’::interval ) OR (last_autovacuum IS NULL AND last_vacuum IS NULL) ORDER BY novac DESC;
days • Table traffic too low to warrant vacuum • Lower thresholds for specific tables • Starvation (heavy tables need higher thresholds) • Raise thresholds for busiest tables
vacuums high • Lower thresholds • Autovacuum heavily throttled • Lower throttle per-table ALTER TABLE pgbench_accounts SET (autovacuum_vacuum_cost_delay = 0); Note: The ‘cost_delay’ setting is effective in 10ms increments, 0 means unthrottled
• Typcially workload dependent • High UPDATE / DELETE, new rows don’t fit freespace • Ultra-high rate of change • VACUUM can’t complete fast enough for new rows • Remediation • Change workload • Lower throttles on these • Move to separate disk • Disable autovacuum, move to ‘cron-based’ vacuum • Partition
• Disable autovacuum & run manual vacuum • Logging tables like special attention • Typical logging tables have high INSERT with perdiodic, large bulk DELETE • Partition • Use ‘truncate table ’ instead of DELETE • No VACUUM required • Modify globals • If you’ve made it this far, you’ll have an understanding for the impact of lowering the thresholds or the throttle. In many cases, it does make sense to modify these conservative defaults. Again, use your workload analysis.
{kind=link}
![Who am I? • Jim Mlodgenski • [email protected] • @jim_mlodgenski](https://files.speakerdeck.com/presentations/49dff120eaa2407e97bca4582319ad4c/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? [email protected] @jim_mlodgenski](https://files.speakerdeck.com/presentations/49dff120eaa2407e97bca4582319ad4c/slide_53.jpg){kind=link}